[Deep Reinforcement Learning]
1.[Deep Reinforcement Learning] 2강 Markov property

오승상 강화학습 02 Markov property
2.[Deep Reinforcement Learning] 3강 Markov Decision Process
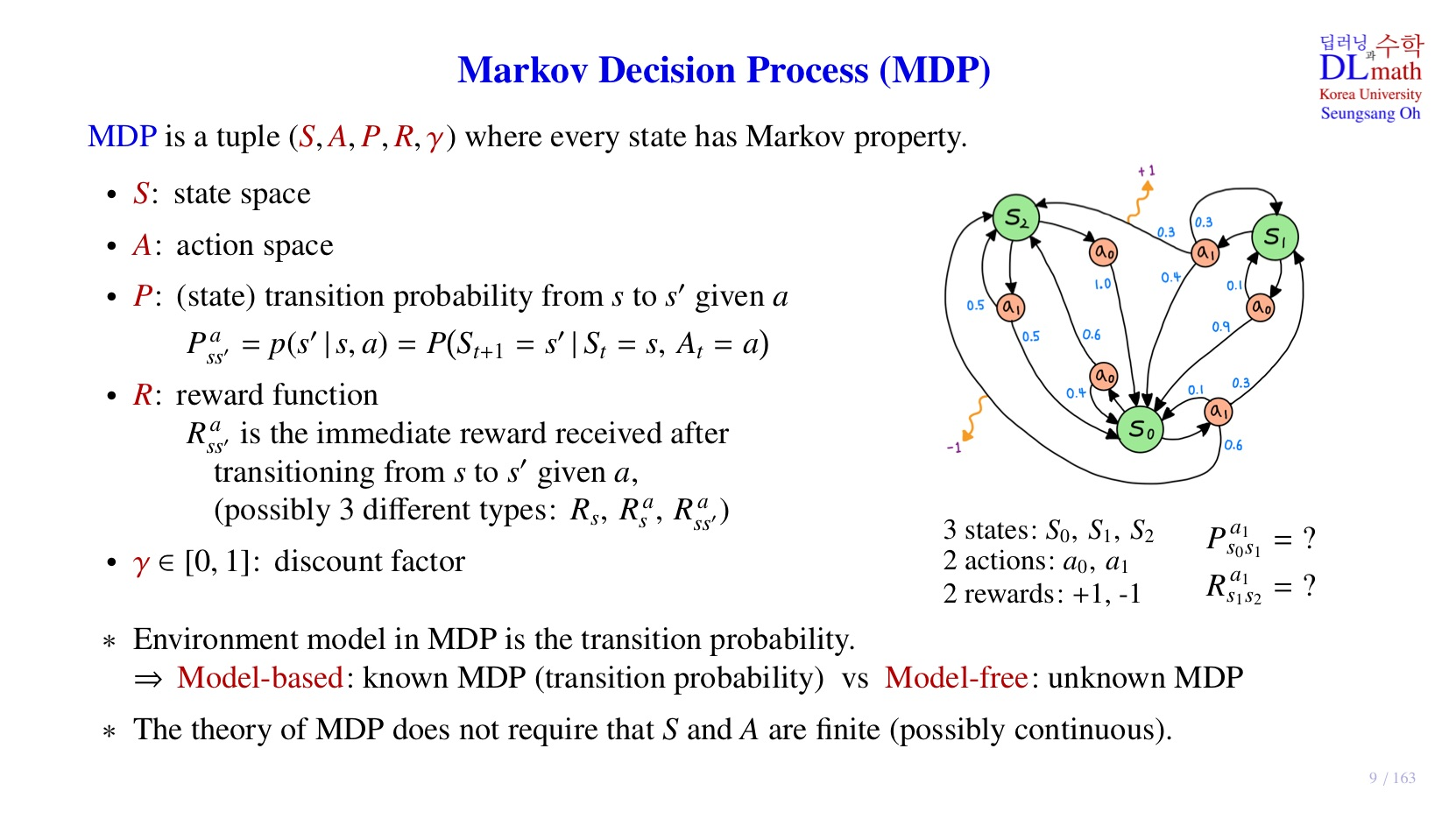
오승상 강화학습 03 Markov Decision Process
3.[Deep Reinforcement Learning] 4강 Reward and Policy

오승상 강화학습 04 Reward and Policy
4.[Deep Reinforcement Learning] 5강 Bellman equation 1

오승상 강화학습 05 Bellman equation 1
5.[Deep Reinforcement Learning] 6강 Bellman equation 2

오승상 강화학습 06 Bellman equation 2
6.[Deep Reinforcement Learning] 7강 Dynamic Programming

오승상 강화학습 07 Dynamic Programming
7.[Deep Reinforcement Learning] 8강 Value Iteration

오승상 강화학습 08 Value Iteration
8.[Deep Reinforcement Learning] 9강 Policy Iteration

오승상 강화학습 09 Policy Iteration
9.[Deep Reinforcement Learning] 10강 Reinforcement Learning

오승상 강화학습 10 Reinforcement Learning
10.[Deep Reinforcement Learning] 11강 Monte Carlo method1

오승상 강화학습 11 Monte Carlo method 1
11.[Deep Reinforcement Learning] 12강 Monte Carlo method2

오승상 강화학습 12 Monte Carlo method 2
12.[Deep Reinforcement Learning] 13강 Temporal Difference Learning 1

오승상 강화학습 13 Temporal Difference Learning 1
13.[Deep Reinforcement Learning] 14강 Temporal Difference Learning 2

오승상 강화학습 14 Temporal Difference Learning 2
14.[Deep Reinforcement Learning] 15강 Temporal Difference Learning 3

오승상 강화학습 15 Temporal Difference Learning 3
15.[Deep Reinforcement Learning] 16강 Deep Reinforcement Learning

오승상 강화학습 16 Deep Reinforcement Learning
16.[Deep Reinforcement Learning] 17강 DQN 1
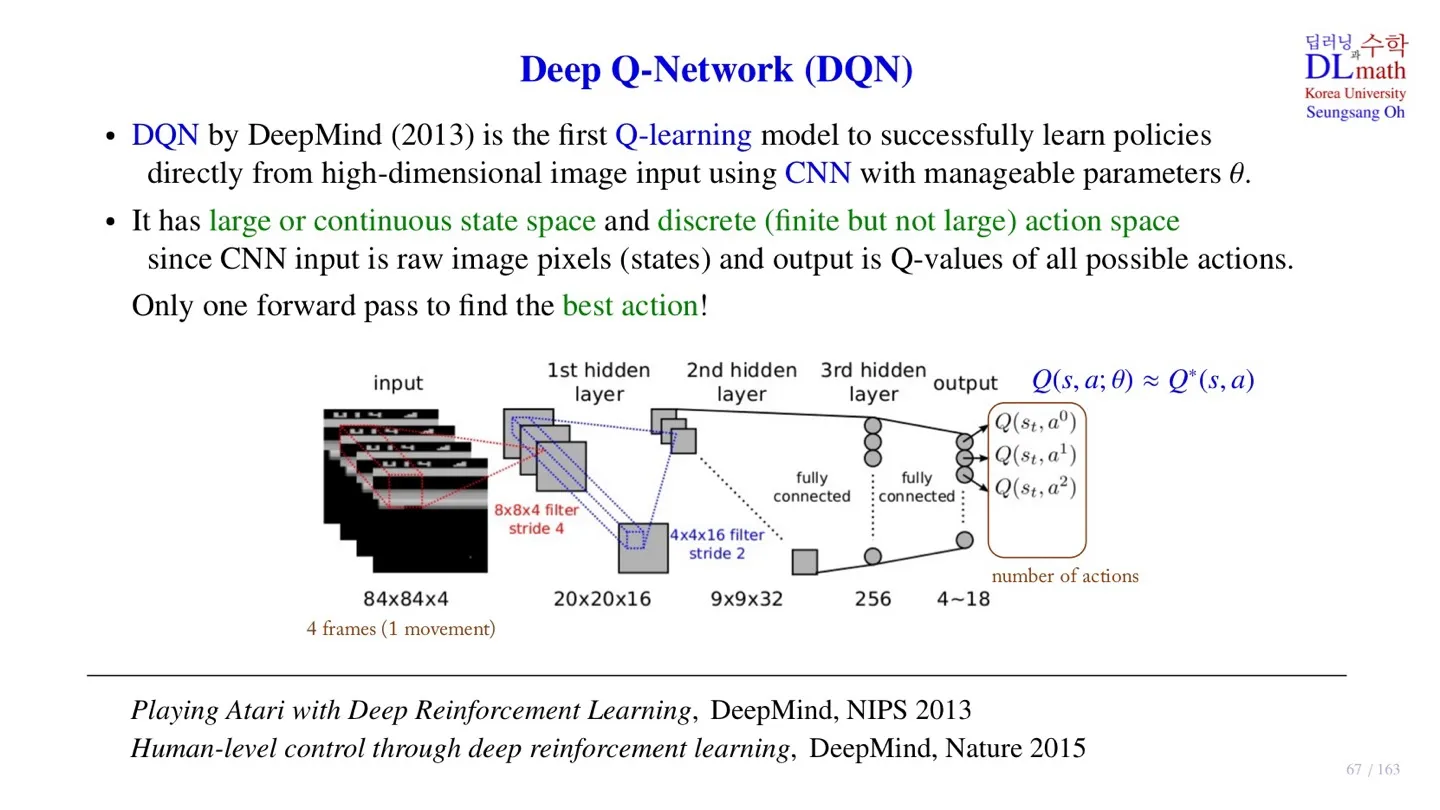
오승상 강화학습 17 DQN 1
17.[Deep Reinforcement Learning] 18강 DQN 2

오승상 강화학습 18 DQN 2
18.[Deep Reinforcement Learning] 19강 DQN variant

오승상 강화학습 19 DQN variant
19.[Deep Reinforcement Learning] 20강 Dueling DQN

오승상 강화학습 20 Dueling DQN
20.[Deep Reinforcement Learning] 21강 Policy Gradient algorithm

오승상 강화학습 21 Policy Gradient algorithm
21.[Deep Reinforcement Learning] 22강 REINFORCE

오승상 강화학습 22 REINFORCE
22.[Deep Reinforcement Learning] 23강 Actor-Critic method
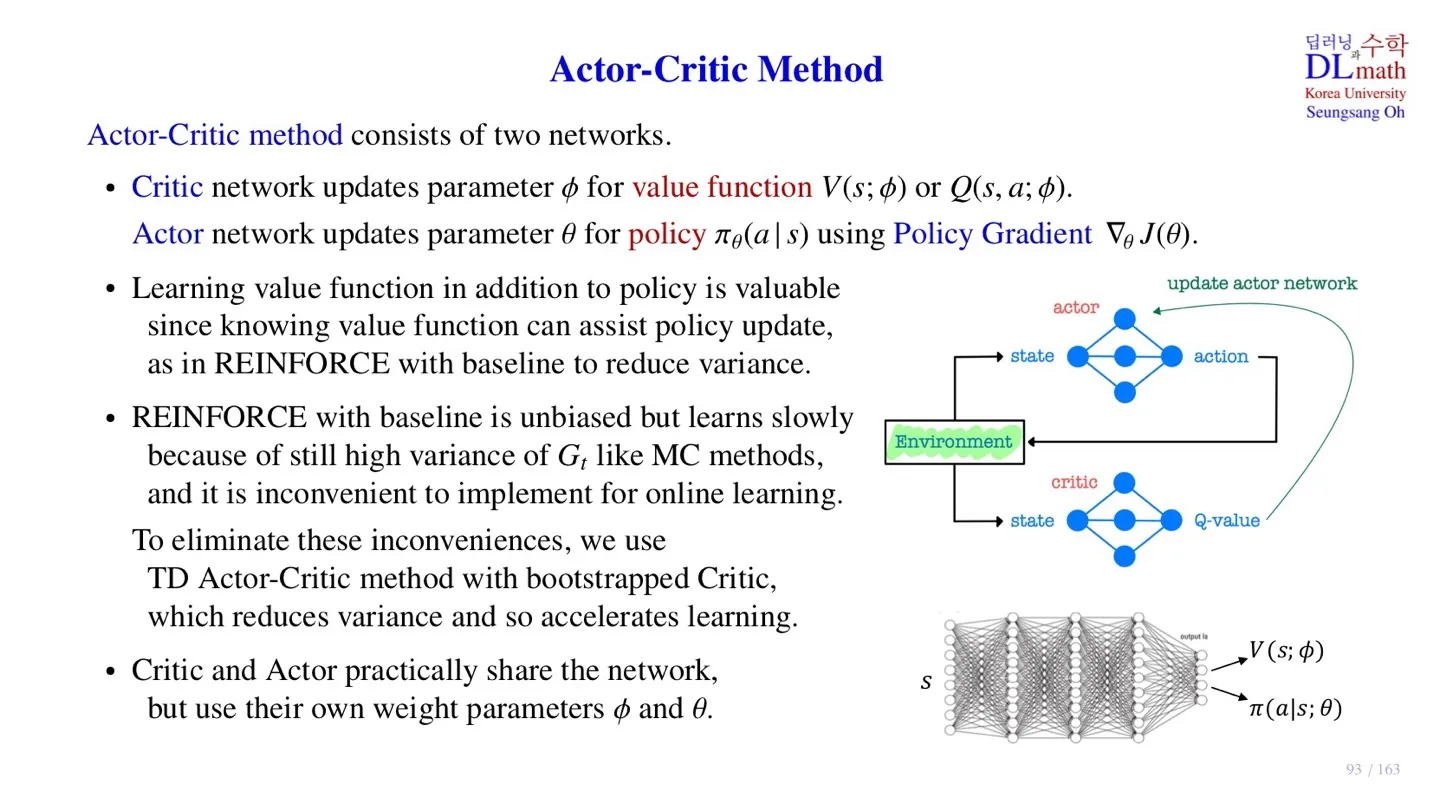
오승상 강화학습 23 Actor-Critic method
23.[Deep Reinforcement Learning] 24강 A3C 1

오승상 강화학습 24 A3C 1
24.[Deep Reinforcement Learning] 25강 A3C 2

오승상 강화학습 25 A3C 2
25.[Deep Reinforcement Learning] 26강 DDPG

오승상 강화학습 26 DDPG
26.[Deep Reinforcement Learning] 27강 TRPO 1

오승상 강화학습 27 TRPO 1
27.[Deep Reinforcement Learning] 28강 TRPO 2

오승상 강화학습 28 TRPO 2
28.[Deep Reinforcement Learning] 29강 TRPO 3

오승상 강화학습 29 TRPO 3
29.[Deep Reinforcement Learning] 30강 PPO

오승상 강화학습 30 PPO
30.[Deep Reinforcement Learning] 31강 Distributional Reinforcement Learning

오승상 강화학습 31 Distributional Reinforcement Learning
31.[Deep Reinforcement Learning] 32강 C51
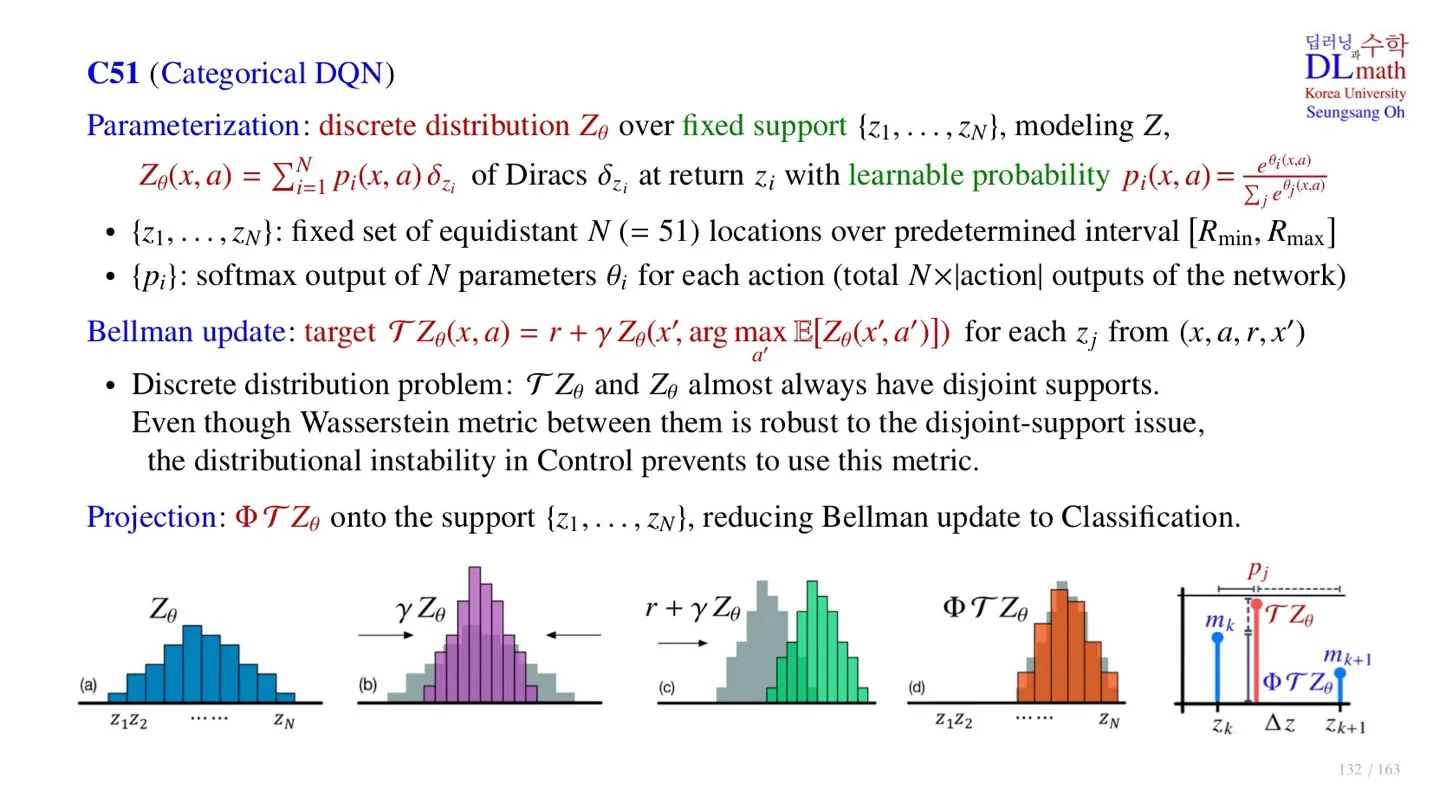
오승상 강화학습 32 C51
32.[Deep Reinforcement Learning] 33강 QR-DQN
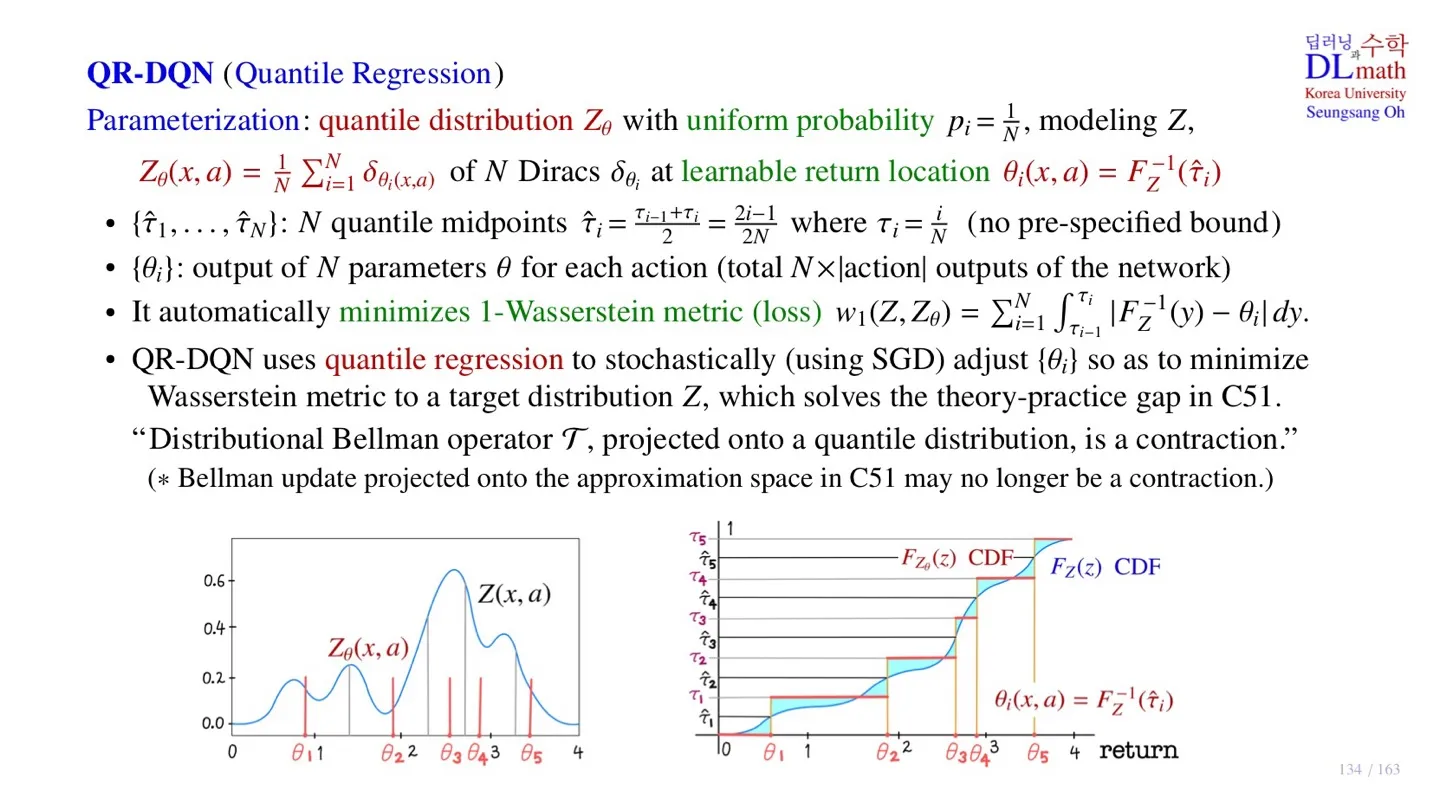
오승상 강화학습 33 QR-DQN
33.[Deep Reinforcement Learning] 34강 IQN

오승상 강화학습 34 IQN