
⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜
💡A Survey on Multimodal Large Language Models
🔗 https://arxiv.org/pdf/2306.13549
⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜
0️⃣ Abstract
최근 GPT-4V를 중심으로 Multimodal Large Language Model(MLLM) 분야가 떠오르고 있습니다. MLLM은 LLM 모델을 두뇌로 사용하여 입력된 이미지를 기반으로 스토리를 작성하거나, 글자에 대한 OCR 없이 수학 문제를 푸는 등 기존의 멀티모달 기술로는 어려웠던 문제를 해결하고 있습니다. 이러한 발전으로 인간은 인공 일반 지능(AGI)에 조금 더 다가가고 있습니다. 그 결과 최근에는 학계와 산업계 모두 GPT-4V를 넘어서는 MLLM을 개발하기 위해 노력 중이며, 자연스럽게 MLLM 분야는 굉장히 빠른 속도로 발전하고 있습니다.
이번 논문에서는 MLLM의 기본 아키텍처, 훈련 전략 및 데이터, 평가 방식 등 MLLM 관련 개념을 알아보고, MLLM이 어떻게 더 확장될 수 있는지, 최근에 직면한 과제는 무엇인지, 또 어떤 연구 방향이 유망한지에 대해서 알아보도록 하겠습니다.
MLLM에 대한 최신 관련 논문은 아래의 링크에서 확인할 수 있습니다.
https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models
1️⃣ Introduction
최근 몇 년간 데이터 증가와 모델 크기 확장으로 LLM 모델이 놀라운 속도로 발전하고 있습니다. 그 결과 LLM 모델은 In-Context Learning(ICL), Chain of Thought (CoT), Instruction following 등 기존에는 없던 특별한 능력을 획득하였습니다. 또한 LLM모델은 zero/few shot에서 놀라운 추론 능력을 보여줍니다. 하지만 LLM 모델은 텍스트 데이터만 이해할 수 있다는 한계가 존재합니다. 반면 Large Vision Models(LVMs)는 추론 능력은 떨어지지만, 이미지 데이터를 명확하게 이해할 수 있다는 강점이 있습니다.
❗여기서 잠깐! ICL, CoT, Instruction following은 뭐죠?
- In-Context Learning (ICL): 문맥 내 학습이라는 의미로, 모델이 매개변수(weight)를 업데이트하지 않고, 프롬프트 내에서 몇 가지 예시를 보여주는 것만으로 새로운 작업을 수행할 수 있도록 유도하는 기술을 의미합니다.
- Chain of Thought (CoT): 사고의 사슬이라는 의미로, 모델에게 최종 답변을 바로 내놓게 하는 대신, 중간 추론 과정을 단계별로 설명하도록 유도하는 프롬프트 엔지니어링 기술을 의미합니다.
- Instruction following: 지시 따르기라는 의미로, 사용자가 자연어로 제공하는 특정 지시나 제약사항을 모델이 정확히 이해하고 따르는 능력을 의미합니다. ex) 50단어 이내로 답변해줘, JSON 형태로 출력해줘.
이러한 LLM과 LVM의 강점을 상호보완하여 등장한 분야가 바로 Multimodal Large Language Model (MLLM) 입니다. MLLM은 LLM 모델을 기반으로 하되, multimodal 정보를 입력, 추론, 출력할 수 있는 모델을 의미합니다.
1-1 기존 multimodal 연구
물론 기존에도 multimodal 분야는 활발히 연구되고 있었습니다. 기존 multimodal 분야는 discriminative(판별)과 generative(생성)으로 연구 분야를 나눌 수 있습니다. 많이 알고 계시는 CLIP 모델이 대표적인 discriminative 모델입니다. CLIP은 이미지 데이터와 텍스트 데이터를 같은 차원의 공간에 projection하는 모델입니다.
반면 generative 분야의 대표적인 모델은 OFA입니다. OFA(One-for-All)은 transformer 모델처럼 원하는 출력을 생성할 수 있는 모델인데, 입-출력에서 이미지와 텍스트 데이터를 모두 다룰 수 있는 모델입니다. 핵심 아이디어는 Vision transformer처럼 입력 이미지 역시 패치로 분할하여 토큰으로 만드는 것입니다. 텍스트와 이미지 모두 동일한 차원의 토큰 벡터로 만들 수 있기 때문에 데이터의 종류에 관계없이 학습을 진행할 수 있습니다. 입-출력 데이터 모두 토큰 시퀀스이기 때문에, OFA 모델은 Sequence-to-Sequence 모델이라고 할 수 있습니다.
1-2 MLLM만의 특징
MLLM 역시 Sequence 작동 방식과 유사하지만, 기존의 방식과는 결정적인 차이점이 존재합니다.
- MLLM 모델은 기존의 모델과 달리 수십억개의 파라미터를 가진 LLM 모델을 기반으로 작동합니다.
- MLLM 모델은 새로운 Instruction에 잘 따르도록 학습하기 위해, multimodal instruction tuning이라는 새로운 훈련 방식을 사용합니다.
이러한 차이점을 통해 MLLM 모델은 웹 사이트 이미지만 보고 코드 작성하기, SNS 속 밈의 의미 이해하기, OCR 없이 수학 문제 풀기 등 어려운 문제를 해결할 수 있는 능력을 얻었습니다.
1-3 MLLM의 확장
MLLM 모델은 초기에 텍스트, 이미지, 오디오 데이터를 입력으로 넣으면, 텍스트를 생성하는 작업을 중심으로 연구되었지만, 이후 MLLM 모델의 능력은 더욱 확장되었습니다.
- Granularity Support (더 세밀한 정보 처리): 단순히 이미지에 대한 설명을 요구하는 것이 아닌, 이미지 속 특정 영역에 상자를 만들거나, 클릭을 하여 원하는 대상을 지정하는 것이 가능합니다.
-
다양한 입출력 방식 지원(Enhanced Modality Support)
- 이미지, 비디오, 오디오 외에도 3D 점군(point cloud)을 입력으로 처리하는 모델이 등장하였습니다.
출처: https://www.mathworks.com/help/lidar/ref/pc2surfacemesh.html
- 텍스트 외에도, 이미지, 오디오, 비디오 등 출력 modality가 다양해지고 있습니다. ex) 지브리 그림 그려줘. → 그림 생성
- 이미지, 비디오, 오디오 외에도 3D 점군(point cloud)을 입력으로 처리하는 모델이 등장하였습니다.
-
여러 언어 지원(Improved Language Support): 기존에는 MLLM 모델이 영어 데이터로 훈련되어 다른 언어에는 약했지만, 최근에는 다양한 언어를 학습하여 다른 언어에도 그 능력을 확장하려는 노력이 이루어지고 있습니다.
-
다양한 분야 및 시나리오 적용(Extension to more realms and usage scenarios)
- 전문 분야로 확장: 의료 분야
- 현실 세계와 상호작용: embodied 에이전트와 같은 로봇 개발 적용.
⏰MLLM 타임라인
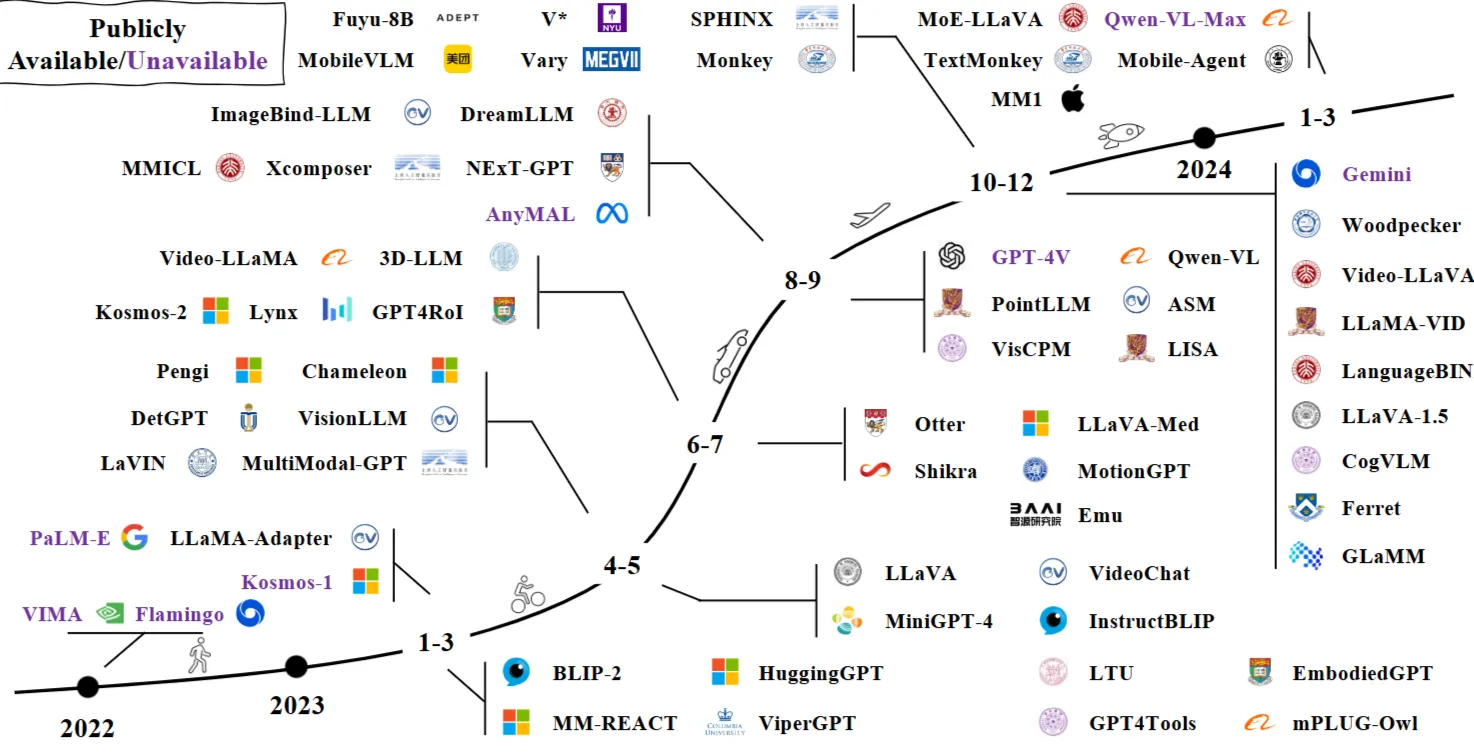
Fig. 1: A timeline of representative MLLMs. We are witnessing rapid growth in this field. More works can be found in our released GitHub page, which is updated daily.
1-4 앞으로의 전개 방향
해당 논문은 MLLM에 대한 첫 survey이며, 아래의 내용을 다룰 예정입니다.
2장. MLLM을 구성하는 기본 구조에 대해 살펴봅니다.
3장. MLLM의 3가지 학습 방법에 대해 살펴봅니다.
4장. 모델 성능 평가 방법에 대해 알아봅니다.
5장. MLLM의 개선점과 확장 방향에 대해 알아봅니다.
6장. Multimodal hallucination 문제 완화 방법에 대해 알아봅니다.
7장. 세가지 주요 기술울 살펴봅니다.
8장. MLLM의 현재 한계와 향후 연구 방향에 대해 알아봅니다.
9장. 논문을 마무리합니다.
2️⃣ Architecture
해당 장에서는 멀티모달 대형 언어 모델(MLLM)의 일반적인 아키텍처에 대해 설명합니다.
2-1 MLLM 모델의 대표적인 주요 모듈
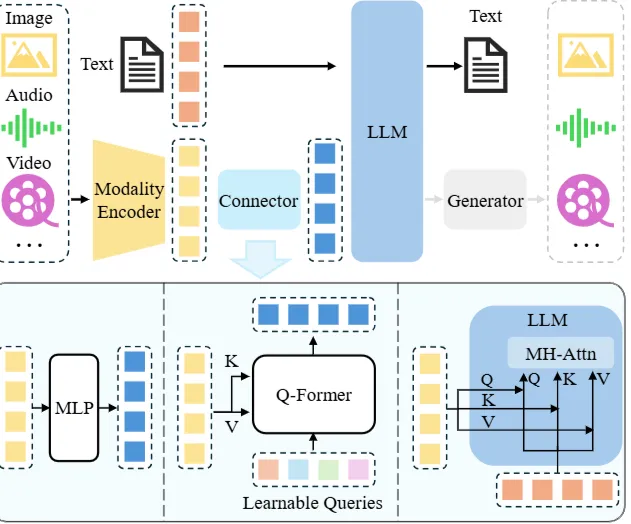
Fig. 2: An illustration of typical MLLM architecture. It includes an encoder, a connector, and a LLM. An optional generator can be attached to the LLM to generate more modalities besides text. The encoder takes in images, audios or videos and outputs features, which are processed by the connector so that the LLM can better understand. There are broadly three types of connectors: projection-based, querybased, and fusion-based connectors. The former two types adopt token-level fusion, processing features into tokens to be sent along with text tokens, while the last type enables a feature-level fusion inside the LLM.
🔷 Modality encoder
- 사람의 눈과 귀의 역할을 합니다.
- 이미지, 음성 데이터를 이해합니다.
🔷 LLM
- 사람의 뇌 역할을 수행합니다.
- 눈과 귀과 이해한 시각, 청각 정보를 통해 생각하고 추론합니다.
🔷 Modality interface
- 서로 다른 데이터가 의미를 공유할 수 있도록 연결-변환해주는 역할을 수행합니다.
- 소방차 사이렌 소리(Audio modality), 소방차 사진(Image modality), 소방관(Text modality) 등 다른 형태의 데이터를 서로 이해할 수 있는 정보로 만들어주는 역할을 수행합니다.
🔷 Generator
- 텍스트 데이터 외의 다른 종류의 데이터를 출력하고 싶을 때 사용합니다.
- 필수 모듈은 아닙니다.
2-2 Modality encoder
🔷 Modality encoder의 역할
이미지, 오디오 등 raw 데이터를 vector로 변환하는 역할을 수행합니다.
🔷 Modality encoder의 기본적인 특징
- 일반적으로 서로 다른 종류의 데이터를 함께 학습한, 사전 훈련된 모델을 사용합니다.
- 대표적으로 CLIP 모델이 이미지-텍스트 쌍이 사전 훈련된 모델입니다.
- Fuye-8B와 같은 encoder-free 모델에서는 modality encoder가 존재하지 않는 경우도 존재합니다. (이때는 이미지를 패치로 쪼갠 후 신경망에 넣어 처리합니다.)
🔷 다양한 종류의 Image encoder

TABLE 1: A summary of commonly used image encoders.
🔷 Image encoder를 선택할 때 고려사항
🔻 1. 해상도 (resolution)
- 성능에 가장 큰 영향을 끼치는 요소입니다.
- 고해상도 데이터를 사용할수록 성능이 향상됩니다.
- 입력 해상도를 확장하는 방법
- Direct scaling
- patch-division
🔻 2. Parameter size
- 해상도에 비해 중요성이 떨어집니다.
🔻 3. pretraining corpus
- 해상도에 비해 중요성이 떨어집니다.
🔷 그 외의 Modality encoder
- Pengi: Audio data를 처리하는 모델입니다.
- CLAP: Audio data를 처리하는 모델입니다.
- ImageBind: 이미지, 텍스트 오디오, 깊이, 열, IMU data를 처리하는 모델입니다.
IMU(Inertial Measurement Unit): 관성 측정 장치, 가속도, 각속도, 자기장을 측정할 수 있다. 즉 물체의 움직임을 측정할 수 있는 장치입니다.
2-3 Pre-trained LLM
🔷LLM 모델의 역할
방대한 양의 corpus를 학습하여 풍부한 세계 지식을 통해 입력된 데이터를 이해하고 추론합니다.
🔷LLM 모델의 기본적인 특징
- 사전 훈련된 LLM 모델을 사용하는 것이 효율적입니다.
- LLM의 파라미터를 늘리는 것이 모델의 성능을 크게 결정합니다.
🔷다양한 LLM 모델

TABLE 2: A summary of commonly used open-sourced LLMs. en, zh, fr, and de stand for English, Chinese, French, and German, respectively.
-
FlanT5: BLIP-2 및 InstructBLIP과 함께 사용된 초기 LLM 모델입니다.
-
LLaMA 및 Vicuna : 주로 영어 corpus에서 pre-trained되어 다국어 지원이 제한된 LLM 모델입니다.
-
Qwen: 영어와 중국어에 대한 이해도가 높은 Bilingual LLM 모델입니다.
🔷LLM 모델의 파라미터
- 모델 성능 향상
- LLM 모델의 파라미터를 7B에서 13B로 확장한 결과 다양한 벤치마크에서 성능이 향상되었습니다.
- 34B LLM을 사용하면 영어 corpus만으로 학습하더라도, 중국어 zero-shot 능력을 획득하게 되었습니다.
- Deployment on mobile Device
- LLM 모델의 파라미터 크기를 줄여 모바일 장치에 배포할 수 있도록 연구되고 있습니다.
- 대표적으로 MobileLLaMA 1.4B/2.7B는 모바일 프로세스에서 효율적인 추론을 수행합니다.
🔷MoE Architecture
MoE(Mixture of Experts)란 전문가(Experts)와 게이트(Gate)를 구조를 활용하여 모델의 파라미터를 효율적으로 확장하는 아키텍처입니다.
- 전문가(Expert): 독립적인 신경망 블록.
- 특정 유형의 데이터나 task를 처리하는 데 특화된 신경망입니다.
- 예를 들어, 어떤 신경망 블록은 수학 계산에, 다른 신경망 블록은 문법 교정에 뛰어난 성능을 보입니다 .
- 게이트(Gate): 입력된 데이터를 분석하여, 어떤 전문가(Experts)에게 데이터 처리를 맞길 지 결정하는 역할을 수행합니다.
MoE Architecture를 이용하면 LLM 모델이 일부 신경망만 사용하여 데이터를 처리하기 때문에, 총 파라미터를 늘리더라도 계산 비용이 크게 늘어나지 않는다.
이러한 방식으로 통해 LLM 모델의 전체 파라미터 수를 효율적으로 증가시켜 모델의 성능을 향상시킬 수 있습니다.
2-4 Modality interface
🔷Modality interface의 역할
서로 다른 modality를 연결하는 역할을 수행합니다. 구체적으로 encoder가 처리한 이미지, 음성 데이터를 모두 LLM 모델이 이해할 수 있는 특정 차원으로 projection 하는 역할을 수행합니다.
🔷대표적인 연결 방식
🔻 1. Token-level fusion
Encoder가 처리한 다른 modality의 vector를 토큰으로 변환한 후, 텍스트 token과 concat하여 LLM에 입력으로 전달하는 방식입니다.
Encoder가 처리한 다른 modality의 vector를 단순 Linear projection 방식으로 처리하는지, Cross-attention 방식으로 처리하는지에 따라 2가지 방식으로 나뉩니다.
🟠 MLP 방식
1) MLP 레이어를 아용하여 encoder가 전달한 다른 modality의 차원을 LLM의 임베딩 차원에 맞게 조정합니다.
2) 변환된 Visual token vector와 text token vector를 concat하여 LLM 모델의 입력으로 전달합니다.
3) LLaVA 모델에서 주로 사용됩니다.
🟠 Q-Former 방식
1) 학습 가능한 Query token과 encoder에서 출력된 vector 사이에 Cross-attention을 수행합니다.
2) 이때 Query를 다른 modality의 어떤 특징에 집중해야 하는지 질문하는 역할을 수행합니다.
3) Cross-attention을 통해 중요한 특징으로 구성된 token을 출력합니다.
4) 출력된 visual token vector와 text token vector를 concat하여 LLM 모델의 입력으로 전달합니다.
5) Query token을 활용하는 방식은 BLIP 모델에서 처음 구현되었습니다.
🔻 2. Feature-level fusion
Encoder가 처리한 다른 modality의 vector를 LLM 모델의 중간 레이어에 주입하는 방식입니다.
대표적인 모델은 아래와 같습니다.
Flamingo:Cross-Attention 방식을 사용하여 다른 Modality를 참조하는 모델 (직접 참조)
CogVLM: Visual Expert Module를 사용하여 다른 Modality를 참조하는 모델 (병렬 융합)
LLaMA-Adapter: Adapter를 사용하여 다른 Modality를 참조하는 모델 (프롬프트 주입 방식)
🔷Modality interface의 파라미터 크기
Modality interface는 encoder나 LLM 모델에 비해 작은 양의 파라미터를 차지하고 있습니다.
예를 들어, Qwen-VL 모델의 경우 Q-Former의 파라미터 크기는 0.08B로 전체 파라미터의 1% 미만을 차지합니다.
🔷물론 다른 방식도 존재
지금까지 다룬 Modality encoder → Modality interface → LLM 구조에서는 인코더가 추출한 특징 벡터가 인터페이스를 통해 비주얼 토큰 벡터 형태로 변환되어 LLM에 전달됩니다. 반면, Expert Model 방식에서는 Modality interface 대신, 별도의 전문가 모델을 활용하여 인코더가 전달한 정보를 자연어 텍스트 그 자체로 변환하여 LLM에 전달하기도 합니다. 하지만 후자의 방식은 시공간적 관계와 같은 세부 정보가 손실될 수 있다는 한계가 있습니다.
3️⃣ Training Strategy And Data
해당 장에서는 MLLM의 3가지 학습 방식과 각 학습 방식의 목표, 필요한 데이터 수집 방법 및 특성에 대해 설명합니다.
3-1 Pre-training
3-1-1 Training Detail
🔷Pre-training의 목표
Pre-training 학습 단계에서는 서로 다른 modality를 정렬하고, multimodal 세계 지식을 학습하는 것을 목표로 합니다. 이때 정렬이란 서로 다른 modality, 예를 들어 사과 이미지와 사과라는 텍스트가 의미론적으로 동일하다는 것을 학습하는 것을 의미합니다. (사과이미지, 사과 글자), (바나나이미지, 바나나글자) 이런 식으로 의미가 유사한 것을 함께 이해한다고 생각하시면 됩니다.
🔷Pre-training의 학습 방식
- 일반적으로 사전 학습된 modality encoder와 LLM의 가중치는 고정하고, 두 module을 연결해주는 modality interface만 학습을 진행합니다.
- 눈, 귀, 코와 같이 다른 modality를 이해하는 encoder, 뇌처럼 똑똑하게 생각할 수 있는 LLM은 그대로 두고, 두 기관을 연결해주는, 통역관 같은 modality interface만 학습하는 것입니다.
- MLLM 모델에게 Audio, Imgae 등 다른 modality data를 입력하면, 해당 data에 대해 text로 설명할 수 있는 것을 목표로 합니다.
- 따라서 (입력: Audio, 출력: Audio에 대한 설명), (입력: Image, 출력: Image에 대한 설명) 방식으로 작동하기 때문에 학습 데이터의 구조 역시 Table3처럼 raw data와 그에 대한 caption으로 구성되어 있습니다.

TABLE 3: A simplified template to structure the caption data. { } is the placeholder for the visual tokens, and {caption} is the caption for the image. Note that only the part marked in red is used for loss calculation.
유의할 점은 짧고, 노이즈가 많은 caption에서는 저해상도 이미지를, 길고 깨끗한 caption에서는 고해상도의 이미지를 사용해야 학습속도를 높이고, hallucination을 완화할 수 있습니다.
3-1-2 Data
🔷Pre-training data의 2가지 종류
Pre-training data는 text caption이 구체적인지, 대략적인지에 따라 2가지 종류로 나눌 수 있습니다.
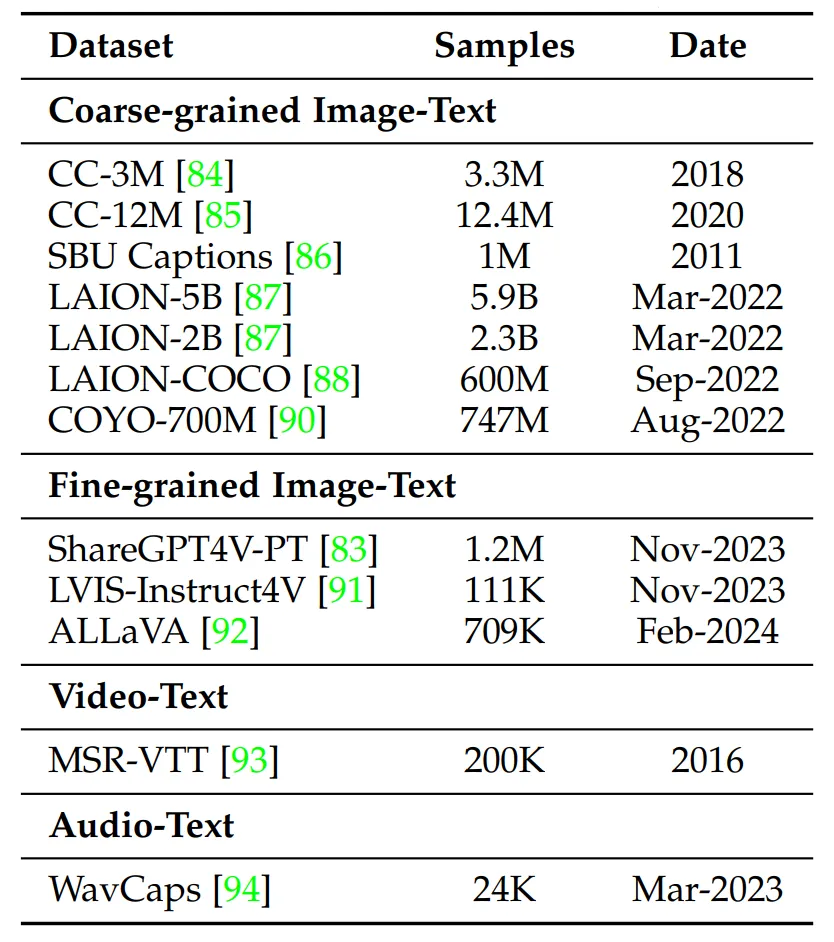
TABLE 4: Common datasets used for pre-training.
🔷1. Coarse-grained 데이터
- 인터넷 웹 상에서 수집된 데이터로, caption이 짧고 노이즈가 많습니다.
- 인터넷 웹 상에서 수집되었기 때문에 데이터 규모가 큽니다.
- CLIP 모델처럼 이미지와 텍스트의 관계를 판별(discriminate)할 수 있는 모델을 통해 필터링할 수 있습니다.
🔻 Coarse-grained 데이터의 종류
- CC (Conceptual Captions - Google AI)
- 웹 상에서 수집된 데이터입니다. 3단계의 필터링 단계를 통해 데이터를 정제하였습니다.
- 노이즈가 있는 이미지, 비율이 망가진 이미지를 필터링하였습니다.
- caption에 관련 없는 내용이 담긴 데이터를 필터링하였습니다.
- 분류기를 통해 이미지에 라벨 선정 후 caption과 비교하여 관련이 없을 경우 필터링하였습니다.
- 종류
- CC-3M : 330만개의 image-caption 쌍으로 구성된 데이터 세트입니다.
- CC-12M: 1,240만개의 image-caption 쌍으로 구성된 데이터 세트입니다.
- CC 데이터 예시
출처: https://ai.google.com/research/ConceptualCaptions/download
- SBU Captions
- 사진 공유 웹사이트 Flichr에서 수집된 사진-캡션 데이터입니다.
- 100만장 규모의 데이터입니다.
- 2 단계의 정제 과정을 거쳤습니다.
- 사람이 직접 관찰하여, 적절한 길이의 caption을 가진 데이터를 제외하고는 필터링하였습니다.
- 미리 정해준 단어와 on, in과 같은 공간적 관계를 나타내는 단어가 없는 경우 필터링하였습니다. 공간적 관계를 통해 이미지 속 상황을 더 구체적으로 학습할 수 있기 때문입니다.
- SBU 데이터 예시

출처: https://tamaraberg.com/papers/generation_nips2011.pdf
- LAION
- 인터네셍서 무작위로 수집된 이미지와 해당 이미지의 alt-text를 통해 캡션을 구성한 데이터입니다.
- 3단계의 필터링 과정을 거쳤습니다.
- 너무 짧거나 긴 caption 혹은 너무 작거나 큰 이미지의 데이터는 필터링합니다.
- 중복된 이미지를 필터링합니다.
- CLIP 모델을 활용하여 불법 콘텐츠 및 image-text 유사성이 낮은 데이터를 필터링합니다.
- 종류
- LAION-5B: 58억 5천만개의 이미지-텍스트 쌍 데이터 세트입니다. 현재까지 공개된 데이터 중 가장 큰 규모 중 하나입니다.
- LAION-COCO: LAION-5B의 영어 서브셋 중 6억개를 추출한 데이터 세트입니다. 캡션은 BLIP 모델을 통해 수정하였습니다.
- LAION-5B 예시

출처: https://arxiv.org/pdf/2210.08402
- COYO-700M
- 스냅샷 웹페이지 CommomCrawl에서 수집한 7억 4천 7백만개의 이미지-텍스트 쌍으로 이루어진 데이터 세트입니다.
- 3단계의 필터링 과정을 거쳤습니다.
- 저품질 이미지를 필터링하였습니다.
- 영어와 적절한 내용의 caption을 제외하고는 필터링하였습니다.
- 중복된 데이터를 필터링하였습니다.
🔷 2. Fine-grained 데이터
- Coarse-grained 데이터에 비해, 더 길고 정확한 설명으로 구성되어 있습니다.
- GPT-4V와 같은 MLLM 모델을 활용하여, 데이터를 생성하는 경우가 많습니다.
- MLLM을 통해 생성하는 경우가 많아, 데이터 규모가 작은 편입니다.
- ShareGPT4V
- MLLM을 학습하기 위해 GPT-4V를 통해 만든 고품질 데이터 세트입니다.
- 120만개의 이미지 - 텍스트로 구성되어 있습니다.
- 예시

출처: https://github.com/ShareGPT4Omni/ShareGPT4V?tab=readme-ov-file
3-2 Instruction-tuning
3-2-1 Introduction
🔷 Instruction-tuning이란?
Instruction은 작업에 대한 구체적인 지시라고 이해하시면 됩니다. 예를 들어, 이미지 속 빨간 모자를 쓴 사람을 찾아줘 등을 생각해볼 수 있습니다.
Instruction-tuning은 모델이 사용자가 요구하는 instruction을 더 잘 수행할 수 있도록 학습하는 기법입니다.
🔷 기존 학습 방식과 Instruction-tuning 방식 비교하기
- Fine-tuning
- task마다 많은 양의 데이터가 필요합니다.
- Prompting
- 적은 양의 데이터로 학습할 수 있다는 장점이 있습니다.
- few-shot의 성능은 향상되었지만, zero-shot에서는 미미한 성능을 보인다는 한계가 있습니다.
- Instruction-tuning
- 특정 작업에 적합되는 것이 아닌, 처음 보는 작업을 잘 처리하는 방법에 대해 학습합니다.
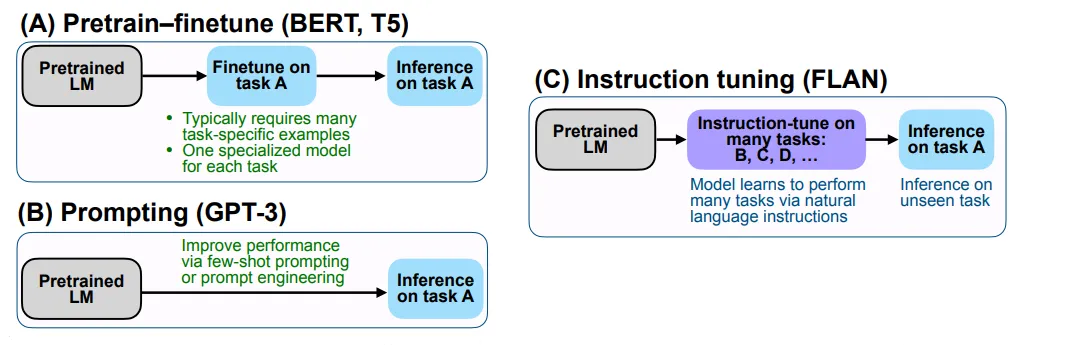
Fig. 3: Comparison of three typical learning paradigms. The image is from [19].
3-2-2 Training Detail
🔷 Instruction-Tuning data 구성
- Instruction: 모델이 수행해야 할 작업을 설명하는 자연어 문장압니다.
- Input: 이미지-텍스트쌍 혹은 이미지 등 multimodal 데이터입니다.
- Output: Instruction과 Input에 대한 결과입니다.

TABLE 5: A simplified template to structure the multimodal instruction data. {instruction} is a textual description of the task. ({image}, {text}) and {output} are input and output from the data sample. Note that {text} in the input may be missed for some datasets, such as image caption datasets merely have {image}.
🔷 Sample Data
- Instruction
- Multimodal Input
- Ground Truth Response
🔷 MLLM 모델
- MLLM이 예측한 답변
- MLLM 모델
- 모델의 파라미터
수식의 의미: 모델 가 주어진 지시 와 멀티모달 입력 을 사용하여, 모델의 파라미터 에 기반하여 예측 답변 를 생성합니다.
🔷 Loss function
- 모델 파라미터 에 대한 Loss
- 모델이 생성한 이전 토큰들, LLM 모델이 Auto-regressive한 방식으로 텍스트를 생성하기 때문에 이전 출력을 참고합니다.
- 수식의 의미: 주어진 지시 , 멀티모달 입력 , 그리고 이전에 생성된 토큰들 을 조건으로 했을 때, 올바른 다음 토큰 이 나타날 확률을 모델이 얼마나 잘 예측하는지를 측정합니다. 이 정답이기 때문에 값은 1에 가까워지도록 학습합니다.
3-2-3 Data Collection
Instruction-tuning은 데이터 형식을 더 유연하게 구성할 수 있고, 다양한 task에 대한 데이터를 수집해야 하기 때문에 많은 비용이 필요합니다.
저희는 3가지 Instruction data 수집 방법에 대해 알아보도록 하겠습니다.
🔷 1. Data Adaption
- 기존 데이터를 Instruction-tuning을 위해 적절한 형식으로 바꾸는 방법입니다.
- VQA (Visual Question Answering) 데이터셋을 활용합니다.
- VQA: (이미지, 질문) → (답변) 형태로 구성되어 있습니다.
- (이미지, 질문) 을 멀티모달 입력 으로, 답변을 로 구성합니다.
- 지시 는 사람 혹은 GPT를 이용하여 생성합니다.
- 형태로 구성합니다.
- 아래의 tempate처럼 과 은 자유로운 형태로 구성할 수 있습니다.
Instruction이 포함된 입력 teamplate

TABLE 6: Instruction templates for VQA datasets, cited from [60]. and {Question} are the image and the question in the original VQA datasets, respectively
🔷 2. Self-Instruction
- LLM, MLLM 모델을 활용하여 데이터를 직접 생성하는 방식입니다.
- Multi-round conversation (다중 턴 대화) 형태의 데이터를 생성할 수 있습니다.
- 현실세계에서는 여러 번의 질문, 답변이 오가기 때문에 multi-round conversation 구조는 모델 학습에 효과적입니다.
- 데이터 생성 방식
- 사람이 직접 몇 가지 좋은 데이터를 생성합니다.
- 제작한 데이터를 MLLM, LLM 모델에게 프롬프트로 전달하여, 유사한 구조의 새로운 데이터 쌍을 생산하도록 합니다.
- LLaVA-Instruct-150k: GPT-4를 통해 생성한 데이터 세트입니다.
- 예시

출처: https://arxiv.org/pdf/2304.08485
Self-Instruction으로 생성된 데이터
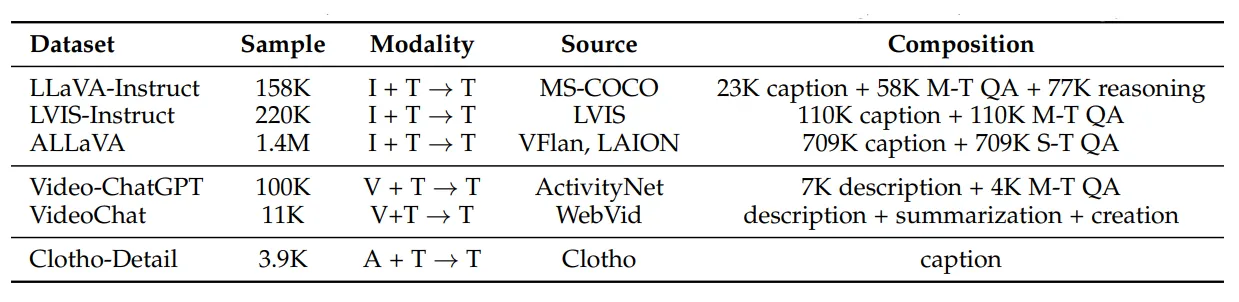
TABLE 7: A summary of popular datasets generated by self-instruction. For input/output modalities, I: Image, T: Text, V: Video, A: Audio. For data composition, M-T and S-T denote multi-turn and single-turn, respectively.
🔷 3. Data Mixture
- 멀티모달 데이터와 텍스트만으로 이루어진 데이터를 함께 섞어서 데이터를 구성하는 방식입니다.
- 데이터를 최종적으로 처리하는 LLM 모델의 언어능력을 보강할 수 있습니다.
3-2-4 Data Quality
🔷 데이터 품질의 중요성
- 최근 연구에서 데이터의 품질이 데이터의 양보다 더 중요다는 것이 밝혀졌습니다.
- 실제로 양질의 적은 데이터로학습한 모델이, 대규모의 noisy한 데이터로 학습한 모델보다 좋은 성능을 보였습니다.
🔷 데이터 품질 2가지
- Prompt Diversity: 데이터를 다양한 Instruction으로 구성하는 것이 모델의 일반화 능력을 크게 향상시킨다는 경험적 결과가 있습니다.
- Task Coverage: Instruction이 복잡할수록 더 좋은 성능을 보임이 확인되었습니다. 예를 들어 단순히 “저 사진은 고양이야?” 라고 묻는 것보다, “저 고양이는 옆의 강아지 보다 실제로 더 큰가?” 라는 노리적 사고를 요구할수록 모델 성능이 더욱 향상된다고 이해할 수 있습니다.
3-3 Alignment tuning
❗여기서 잠깐! 환각 현상(Hallucination)이 뭔가요?
환각현상이란 MLLM 모델이 이미지에 존재하지 않는 것을 있다고 말하거나, 잘못된 색깔, 모양으로 표현하거나, 잘못된 주장을 하는 것을 말합니다.
예시
- 사진에 없는 사자를 봤다고 말하는 경우
- 빨간색 자동차를 파란색이라고 말하는 경우
- 서로 떨어져 있는 두 물체가 붙어 있다고 말하는 경우
3-3-1 Introduction
🔷 Alignment Tuning의 목적
Alignment Tuning은 MLLM이 lallucination 없이, 사용자가 원하는 의도에 맞는 결과를 정확하게 출력할 수 있도록 모델을 조정하는 과정입니다.
🔷 대표적인 학습 방법
- RLHF (Reinforcement Learning with Human Feedback) : 인간의 피드백을 통한 강화학습 방법입니다.
- DPO (Direct Preference Optimization) : 인간의 선호도가 라벨링된 데이터를 통해 학습하는 방법입니다.
3-3-2 Training Detail
🔷 1. RLHF
- 인간 피드백을 통한 강화학습 방식으로, 인간이 더 원하는 답변을 생성할 수 있도록 학습하는 방법입니다.
- 3단계의 과정을 통해 학습이 진행됩니다.
🔻 1. Supervised Fine-Tuning (SFT)
- MLLM 모델이 사람의 지시를 따르도록 학습하는 과정입니다.
- 앞서 살펴본 Instruct-tuning이라고 이해하시면 됩니다.
- Instruct-tuning을 마친 MLLM 모델을 정책모델 이라 합니다.
🔻 2. Reward Modeling (RM)
- 이 생성한 결과에 대한 인간의 선호도를 학습하는, “별도의 모델”을 설계합니다. 이를 보상모델 이라 합니다.
- 사람이 MLLM 모델이 생성한 여러 답변 후보에 선호도 순위를 부여합니다.
🟠 보상 모델의 학습 데이터
- 보상모델 가 학습할 데이터
- MLLM의 입력 데이터
- 선호하는 응답, MLLM의 생성물
- 선호하지 않는 응답, MLLM의 생성물
🟠 보상모델의 Loss function
- 보상 모델의 손실함수
- 선호하는 응답에 대한 보상점수
- 선호하지 않는 응답에 대한 보상점수
- 두 점수의 차이, 두 점수가 최대한 멀어지도록 학습합니다.
- 학습 데이터 에서 sampling
- 기대값, 각 데이터 Loss의 평균 Loss를 계산한다는 의미입니다.
- 수식의 의미: 보상 모델이 선호되는 응답에는 높은 보상 점수를, 선호되지 않는 응답에는 낮은 보상 점수를 부여하도록 학습합니다.
🔻 3. Reinforcement Learning
- 보상 모델을 활용하여 에 대한 강화학습을 수행합니다.
- 강화 학습은 PPO (Proximal Policy Optimization) 알고리즘을 사용합니다.
- 이때 모델이 이상한 방향으로 강화학습 되지 않도록 KL penalty 항슬 추가합니다.
- PPO와 KL 발산에 대해서는 다른 글에서 다뤄보도록 하겠습니다.
🔻 RLHF 방법의 대표적인 모델
- LLaVA-RLHF
🔷 2. DPO (Direct Preference Optimization)
- “직접 선호 최적화”라는 의미로 RLHF와 달리 보상 모델 없이 2단계로 간단하게 인간의 선호를 학습하는 방법입니다.
- 보상 모델 없이 데이터를 통헤 “직접” 학습을 수행합니다.
- 핵심 아이디어는 모델에게 “A답변이 B답변보다 좋다” 라는 이진적인 선택을 학습시키는 것입니다.
- 따라서 학습 과정 역시 이진 분류 형태의 단순한 형태입니다.
- 2단계를 통해 학습이 이루어집니다.
🔻 1. Human Preference Data Collection
- 인간 선호 데이터를 수집하는 과정입니다.
- 사람들에게 AI가 생성산 답변 중 어떤 답변이 더 좋은지 선택하도록 요청합니다.
- 이러한 과정을 통해 RLHF와 동일한 형태의 데이터를 수집합니다.
🔻 2. Preference Learning
- MLLM 모델이 사람들이 더 선호하는 답변을 생성할 수 있도록 학습시킵니다.
- 구체적으로 이 선호하는 응답 을 생성할 확률이 선호하지 않는 응답 을 생성할 확률보다 훨씬 높아지도록 학습합니다.
- 훈련되는 의 손실 함수입니다. 이 값을 최소화하는 방향으로 모델이 학습됩니다.
- 현재 훈련 중인 모델이 프롬프트 x에 대해 응답 y를 생성할 확률입니다.
- 훈련 시작 전의 초기 모델(참조 모델)이 응답 y를 생성할 확률입니다. 이전 능력에서 너무 멀리 벗어나지 않게 하는 기준점 역할을 수행합니다. 위 식은 손실함수에서 분모에 위치하게 되는데 이러한 구조를 KL발산이라고 합니다. KL발산에 대해서는 다음에 자세히 다뤄보도록 하겠습니다.
- 현재 모델이 초기 모델 대비 해당 응답을 얼마나 더/덜 선호하는지를 나타내는 지표입니다. 이 값이 커지면 해당 응답을 더 선호하는 것이고, 작아지면 덜 선호하는 것입니다.
- 선호하는 응답( )의 점수에서 선호하지 않는 응답()의 점수를 뺀 값이 커지도록 모델이 학습됩니다. 이 차이가 클수록 시그모이드 출력이 1에 가까워지고, 손실은 0에 가까워집니다. 즉, 를 보다 더 선호하도록 '분류'하는 방향으로 모델을 직접 최적화합니다.
🔻 DPO 방법의 대표적인 모델
- RLHF-V
- Silkie
3-3-3 Data
🔷 Alignment tuning data 수집의 목적
Alignment tuning은 MLLM이 환각 현상 없이 인간이 원하는 답변을 생성할 수 있도록 학습시키는 것이다. 따라서 MLLM의 생성 답변에 대한 피드백이 담긴 데이터를 수집하는 것이 중요하다.
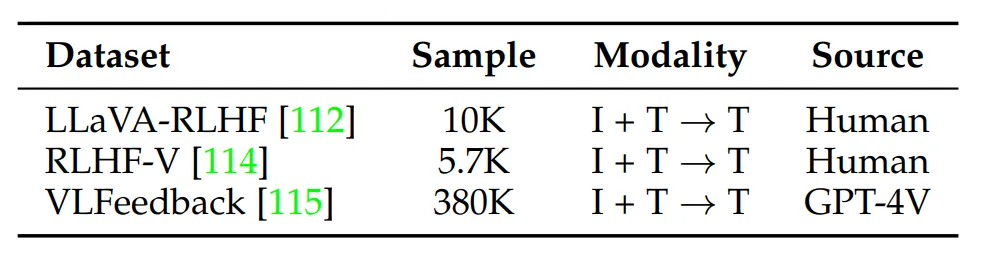
TABLE 8: A summary of datasets for alignment-tuning. For input/output modalities, I: Image, T: Text.
🔷 주요 데이터셋
🔻 1. LLaVA-RLHF: 답변의 솔직함, 유용성 측면에서 피드맥 된 1만개의 선호도 쌍 데이터 세트입니다.
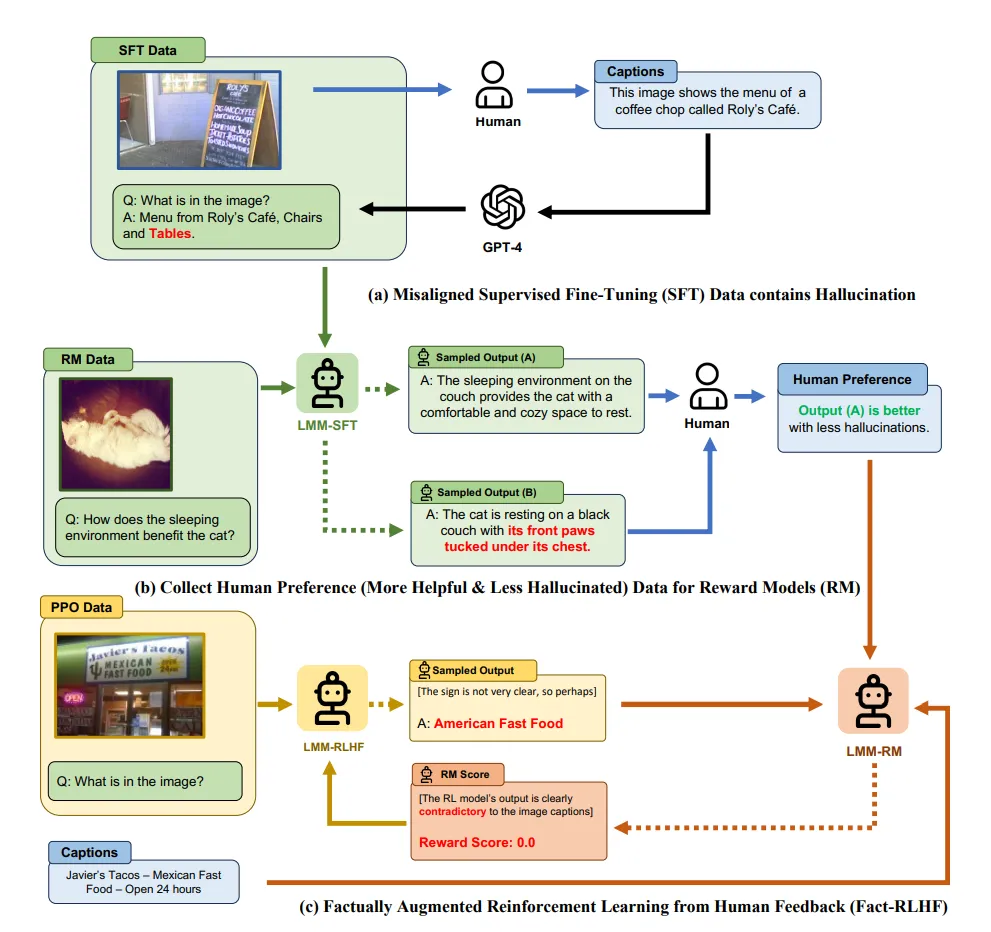
출처: https://arxiv.org/pdf/2309.14525
🔻 2. RLHF-V: Segment level에서 이미지의 환각 현상에 대한 피드백 데이터 세트입니다. 5.7천개의 규모입니다.
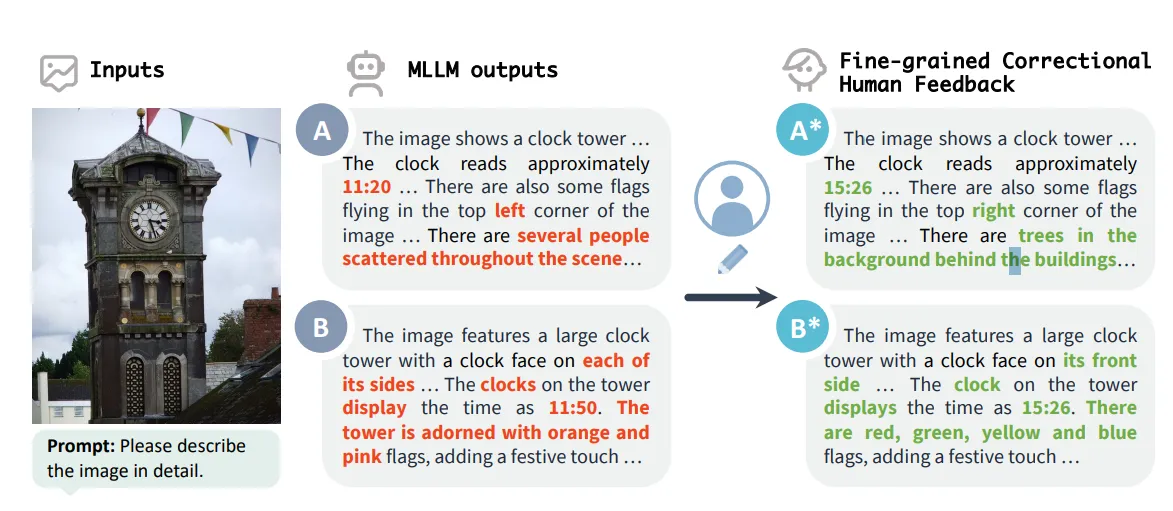
출처: https://arxiv.org/pdf/2312.00849
🔻 3. VLFeedback: GPT-4V가 유용성, 충실도, 윤리적 측면에서 점수를 매긴 38만개 이상의 데이터 세트입니다.
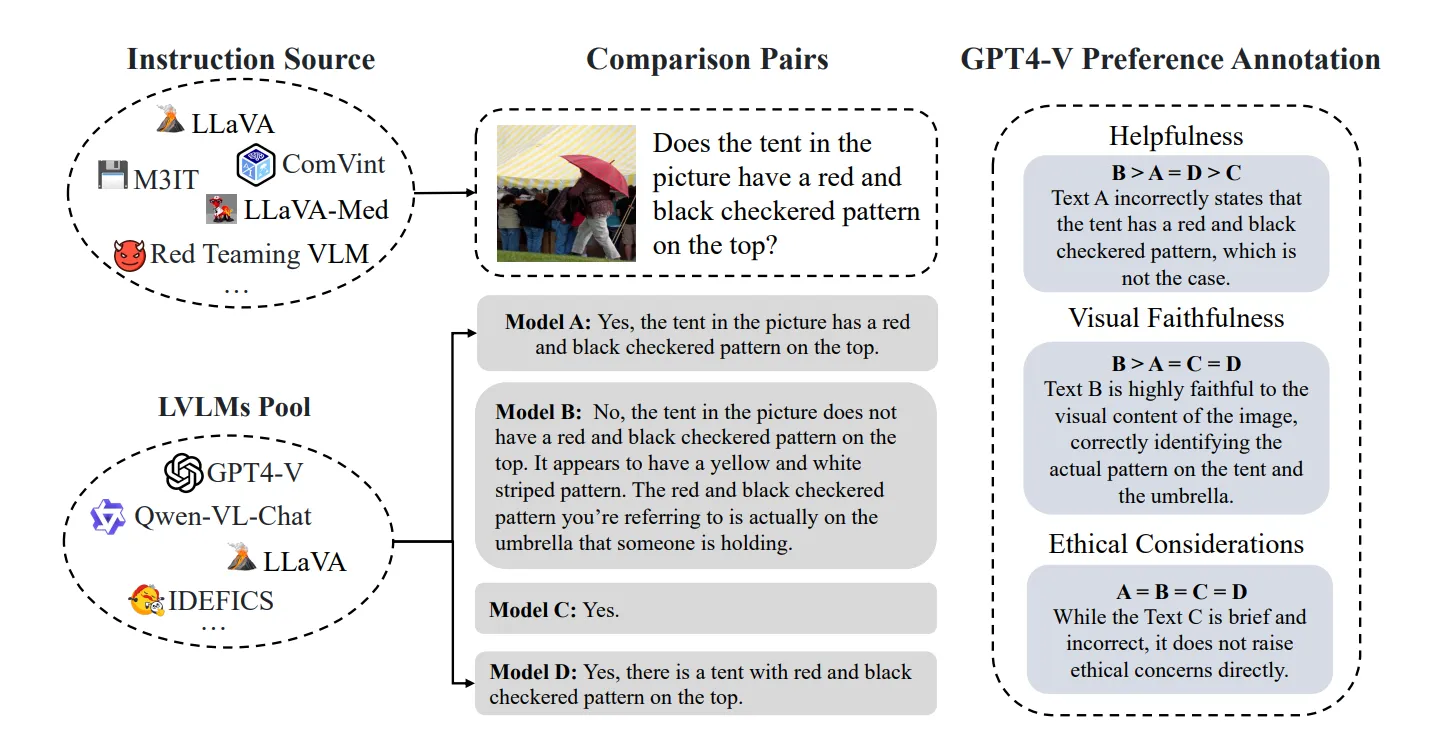
출처: https://arxiv.org/pdf/2410.09421
4️⃣ Evaluation
이번 장에서는 Multimodal Large Language Model (MLLM)의 평가 방법에 대해서 설명합니다.
평가는 MLLM의 최적화를 위해 필수적인 단계이다. MLLM은 여러 능력을 가지고 있으므로 포괄적인 평가가 중요하며, 새로운 기능이 많아 새로운 평가 체계가 필요하다.
우리는 질문 형태에 따라 평가 방식을 2가지로 구분할 수 있다.
4-1 Closed-Set
- 선택지가 정해져 있는 질문으로 평가하는 방식입니다.
- 주관식 답변이더라도, 답변의 범위가 정해져 있다면 Closed-set 방식입니다.
- 답변이 명확하기 때문에 모델의 성능을 수치로 정확하게 측정할 수 있습니다.
4-1-1 평가하기
🔷 1. 사용 데이터
- VQA나 이미지 캡션과 같이 특정 작업에 특화된 데이터셋을 사용합니다.
- InstructBLIP 모델은 과학 문제 Q-A 데이터인 ScienceQA를 통해 accuracy를 측정하고, 이미지 캡션 데이터 NoCaps와 Flickr30K는 CIDEr 점수로 평가하였다.
🔷 2. 평가 종류
- Zero-shot 평가: MLLM이 한 번도 보지 못한 새로운 작업이나 데이터에서 얼마나 잘 작동하는지 평가하는 방식입니다.
- Fine-tuning 평가: 특정 task나 domain에 파인튜닝 후, 해당 영역의 평가 데이터로 성능을 측정합니다.
4-1-2 새로운 Benchmark
🔷 MME
- 14가지의 인식 및 인지 작업에 해당하는 질문-답변 쌍들로 구성된 평가 방법입니다.
- MME는 모델이 이미 학습한 데이터로 평가받아 점수가 부풀려지는 현상을 피하기 위해 모든 질문-답변 쌍을 사람이 직접 만들었습니다.

출처: https://arxiv.org/pdf/2306.13394
🔷 MMBench
- 모델의 다양한 능력을 평가하기 위해 설계된 벤치마크입니다.
- MLLM이 답변하면, ChatGPT 같은 LLM이 답변을 미리 정해진 선택지와 맞춰서 점수를 매깁니다.

출처: https://github.com/open-compass/MMBench?tab=readme-ov-file
🔷 Video-ChatGPT, Video-Bench
- 비디오 데이터를 다루는 MLLM의 성능을 평가하기 위해 만들어진 전문 벤치마크 및 평가 도구입니다.

출처: https://arxiv.org/pdf/2311.16103
🔷 POPE (Prediction Outlier PErplexity)
- 모델의 환각 현상 정도를 평가하기 위해 설계된 평가 방법입니다.
- 이미지에 특정 객체가 존재하는지, 존재하지 않는지 질문합니다.
4-2 Open-Set
- 사람과 대화하듯이 자유로운 형태의 질문으로 평가합니다.
- “이 사진 속 고양이는 어떤 감정을 느끼고 있을까?”나 “이 상황에서 다음에 무슨 일이 일어날 것 같아?” 와 같은 답변이 정해져 있지 않는 질문으로 구성됩니다.
- 답변이 정해져 있지 않기 때문에 Closed-Set 방식에 비해 평가하기 까다롭습니다.
4-2-1 평가 방식
- Manual Scoring: 사람이 직접 평가하는 방식입니다.
- GPT-Scoring: GPT를 이용하여 평가하는 방식입니다.
- Case Study: 조금 더 복잡하고 어려운 질문을 통해 모델의 성능을 심층적으로 평가하는 방식입니다.
5️⃣ Extensions
이번 장에서는 Multimodal Large Language Model (MLLM)의 기능을 확장하기 위한 최근 연구 동향을 설명합니다
5-1 Granularity Support
모델과 사용자의 상호작용 과정을 더욱 개선하기 위하여 모델 입-출력을 더 디테일하게 처리할 수 있도록 노력하고 있습니다.
Granularity: 세분성
5-1-1 입력차원
- 입력 이미지의 특정영역을 바운딩 박스나 픽셀 단위로 입력받을 수 있습니다.
- Ferret은 특정 점, 박스, 스케치를 입력으로 이해할 수 있습니다.
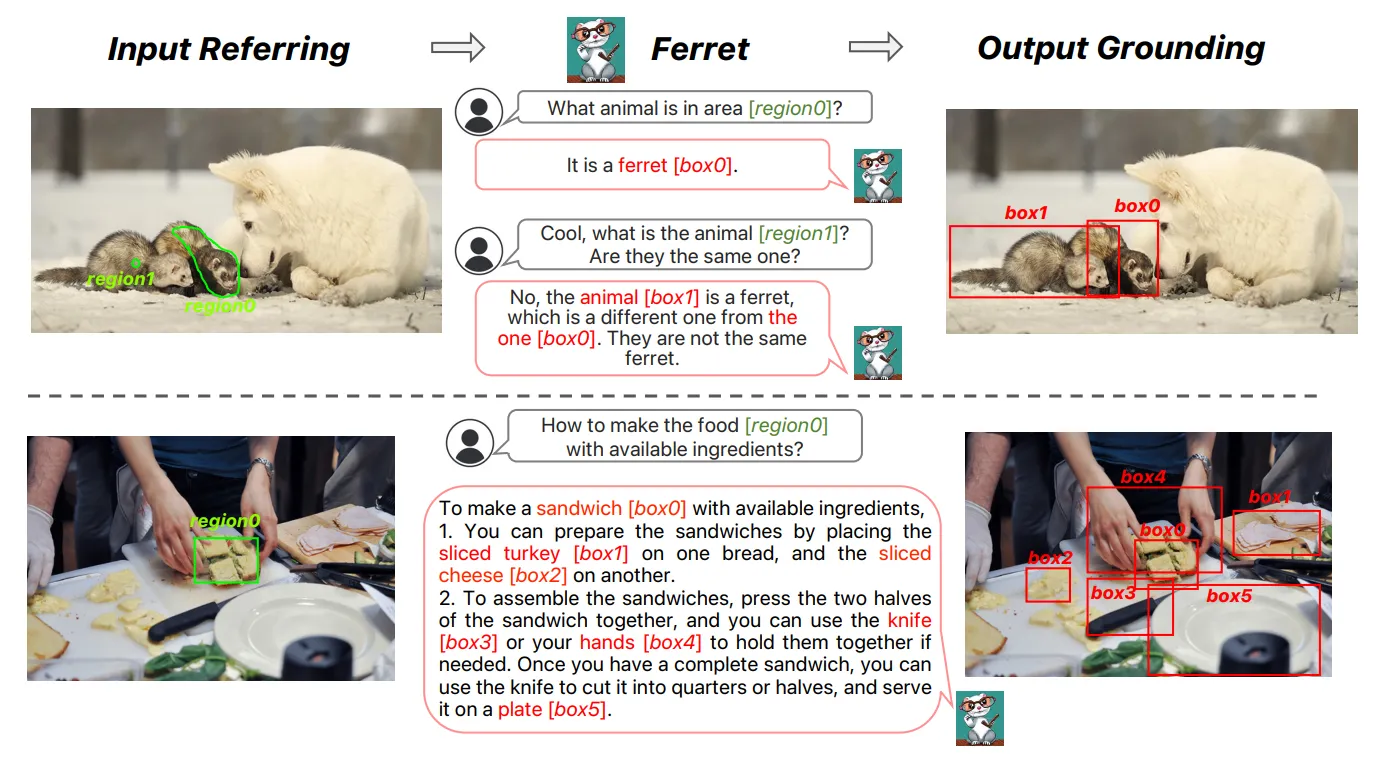
출처: https://arxiv.org/pdf/2310.07704
5-1-2 출력차원
- Shikra는 이미지 속 객체의 BBox의 좌표를 출력할 수 있습니다.

출처: https://arxiv.org/pdf/2306.15195
- LISA (Reasoning Segmentation via Large Language Model)는 해당 객체의 위치를 픽셀 좌표 단위로 출력할 수 있습니다.

출처: https://arxiv.org/pdf/2308.00692
5-2 Modality Support
- MLLM이 이미지, 오디오 외에 더 다양한 정보를 입력으로 처리할 수 있도록 연구되고 있습니다.
- Instruction에서 간단하게 설명했으므로 넘어가도록 하겠습니다.
5-3 Language Support
- 대부분의 MLLM 모델이 영어 데이터를 통해 학습했기 때문에, 다른 언어에서는 성능이 많이 떨어진다는 한계가 존재합니다.
- MLLM이 영어 외에 더 다양한 언어를 이해할 수 있도록 연구하고 있습니다.
- Qwen-VL은 영어와 중국어를 모두 지원하는 대표적인 Bilingual 모델이다.
5-4 Scenario/Task Extension
5-4-1 현실 세계에 맞게 AI 최적화
- MobileVLM: 모바일 기기에서 작동할 수 있는 MLLM을 개발하고 있습니다.
- GUI 에이전트: 사용자 대신 컴퓨터 화면 속 앱을 실행하거나, 클릭 및 타이핑을 해주는 AI 비서입니다.
- Embodied Agents: 로봇처럼 현실세계에서 작동하는 AI입니다.
5-4-2 전문 분야로 MLLM 능력 확장
- MLLM의 modality 이해 능력과 특정 도메인 전문 지식을 결합하여 해당 분야 전문가처럼 행동하도록 개발하고 있습니다.
- mPLUG-DocOwl: 문서 속 차트, 표 등을 이해할 수 있는 모델입니다.
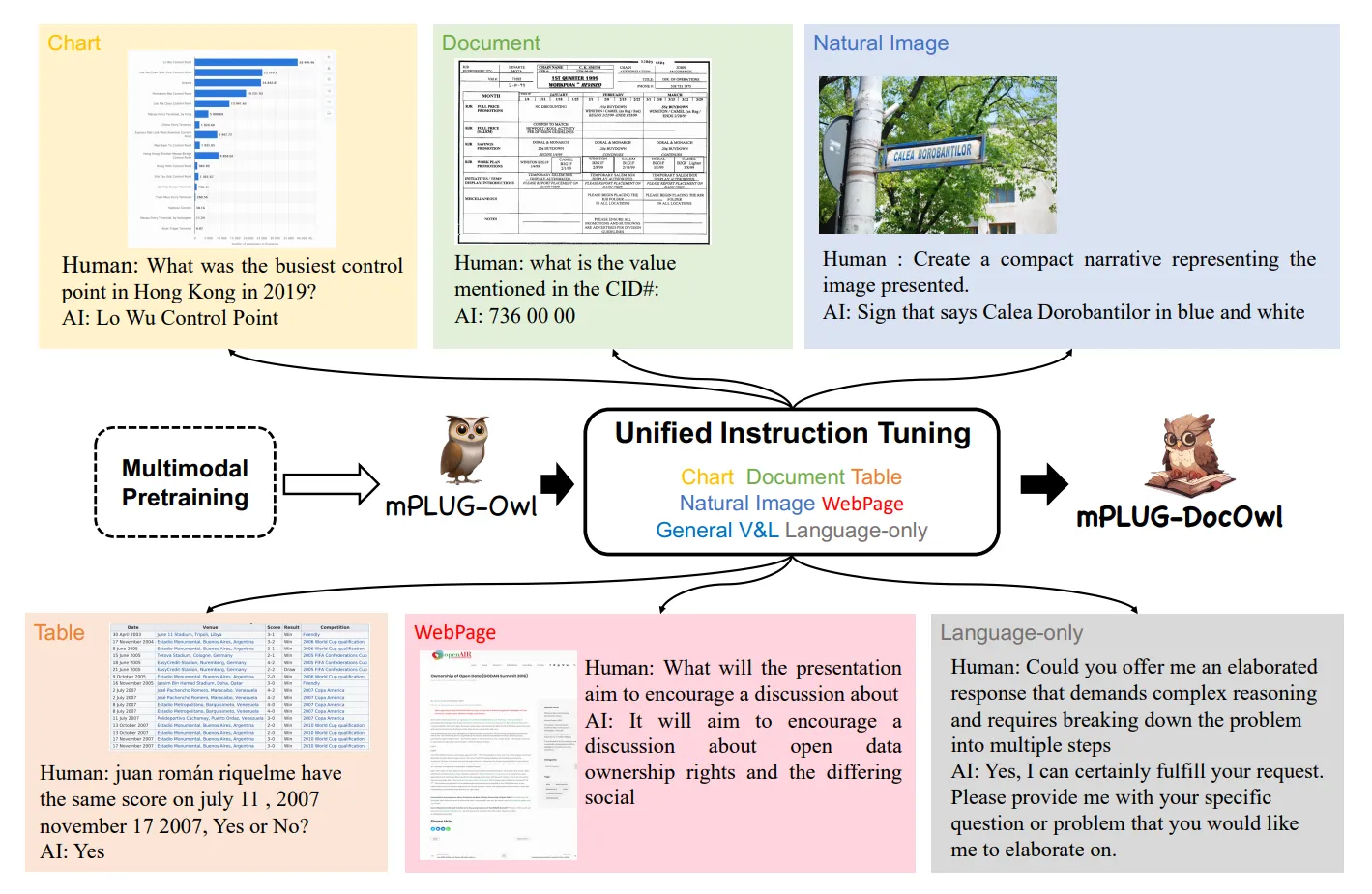
출처: https://arxiv.org/pdf/2307.02499
- LLaVA-Med: LLaVA 모델에 의료 관련 지식을 추가한 모델입니다.
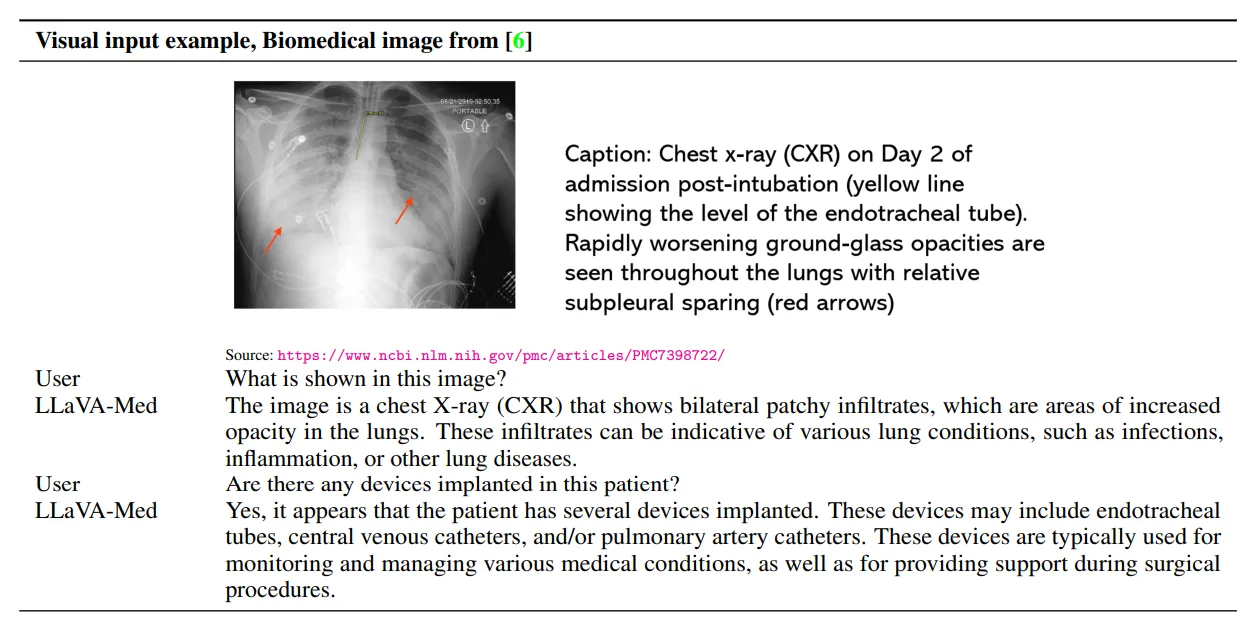
출처: https://arxiv.org/pdf/2306.00890
6️⃣ Multimodal Hallucination
이번 장에서는 MLLM에서 나타하는 Multimodal Hallucination에 대해 살펴봅니다.
6-1 Preliminaries
Multimodal Hallucination은 3가지 유형으로 분류할 수 있습니다.
6-1-1 Existence Hallucination
- 모델이 이미지에 존재하지 않는 특정 객체가 있다고 잘못 주장하는 경우입니다.
6-1-2 Attribute Hallucination
- 모델이 이미지 속 특정 객체의 속성을 잘못 설명하는 경우입니다.
- 빨간색 공을 파란색 공이라고 주장하는 경우가 여기에 해당합니다.
6-1-3 Relationship Hallucination
- 모델이 객체 간의 관계를 잘못 설명하는 경우입니다.
- 강아지가 상자 안에 있는데 옆에 있다고 말하는 경우가 여기에 해당합니다.
6-2 Evaluation Methods
6-2-1 초기방식
- CHIAR: MLLM이 생성한 문장들 중 환각적인 객체가 포함된 문장의 비율, 언급된 모든 객체 중 환각적인 객체의 비율을 측정합니다.
- POPE: 이미지에 특정 객체가 있는지, 없는지 이진 질문의 하여 환각 현상을 측정합니다.
6-2-2 AI 모델 활용
- HaELM: LLM 모델을 이용하여 AI가 생성한 답변과 정답을 비교하여 측정합니다.
- Woodpecker: GPT-4V를 할용하여 MLLM이 생성한 답변을 평가합니다.
6-2-3 더 정교한 평가 지표
- FaithScore: MLLM이 생성한 문장을 여러 개의 작은 '하위 문장'으로 쪼갠 다음, 각 하위 문장이 이미지 내용과 얼마나 일치하는지를 개별적으로 평가하여 종합 점수를 매깁니다.
- AMBER: LLM을 평가자로 사용하지 않고, 이미지 분류, 객체 감지 등 다른 비전 모델의 결과를 활용하여 환각 여부를 판단합니다.
6-3 Mitigation Methods
Multimodal Hallucination을 완하하는 방법은 크게 3가지로 나눌 수 있습니다.
6-3-1 Pre-correction
- 모델이 환각을 학습하지 않도록, 실제 이미지와 내용이 다른 negative 데이터를 포함시켜 주의하도록 학습시키는 방법입니다.
- LRV-Instruction: 사진에 없는 것을 물어보거나, 주어진 설명이 잘못된 이유에 물어보는 등 ‘부정적인 지시’를 통해 환각 현상을 막는 Instruction-tuning 기법입니다.
- LLaVA-RLHF: 앞서 살펴본 강화학습을 통한 alignment tuning 방법입니다.
6-3-2 In-process-correction
- 모델이 답변을 생성하는 ‘중간 과정’이나 ‘내부 구조’를 변경하여 환각 현상을 줄이는 방법입니다.
- HallE-Switch: modality encoder가 정확하게 파악하지 못한 데이터를 LLM 모델이 상상력을 이용하여 추론하는 과정에서 환각 현상이 발생한다고 생각하여, LLM 모델의 상상력 정도를 조절할 수 있는 기능을 추가하는 방법입니다.
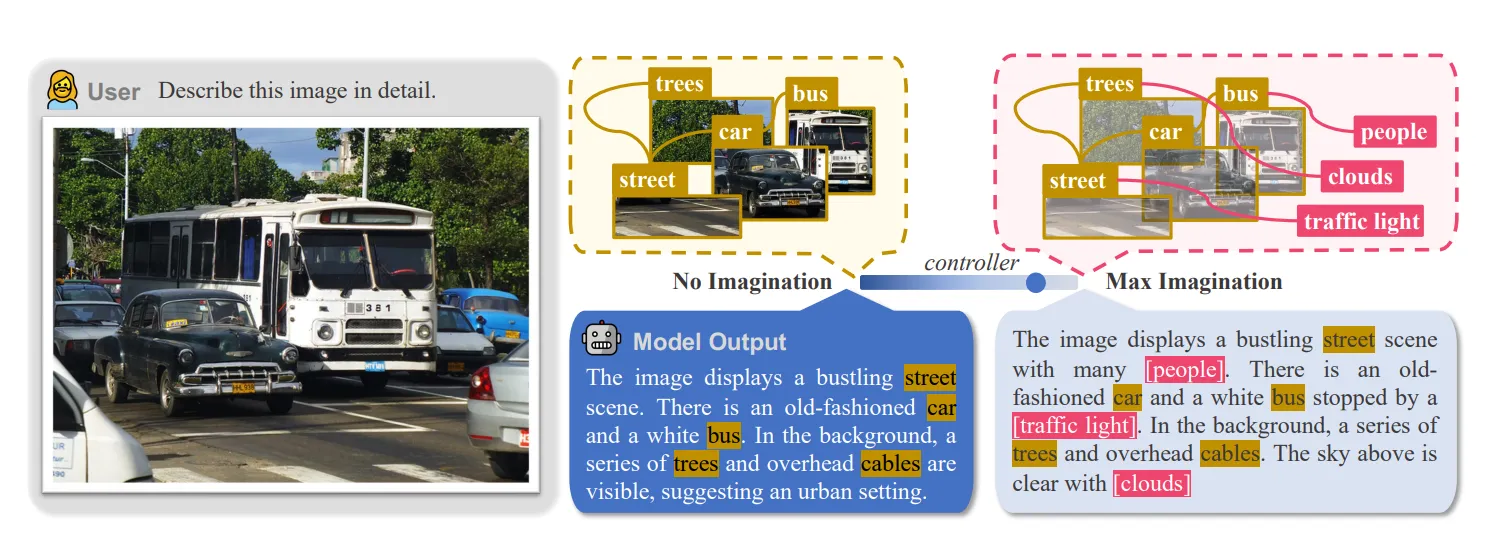
출처: https://arxiv.org/pdf/2310.01779
- VCD (Vision-Language Contrastive Decoding)
- 훈련 데이터에 특정 데이터가 많은 통계적 편향과 LLM 모델의 언어적 편향에 의해 환각 현상이 발생한다고 가정합니다.
- 이를 막기 위해 Amplify-then-contrast decoding 기법을 사용합니다.
- 간단하게 비유하면 모델에게 강한 편향으로 입력 데이터를 추론시킨 후 해당 결과를 제외하고 다시 추론을 시키는 방법입니다.
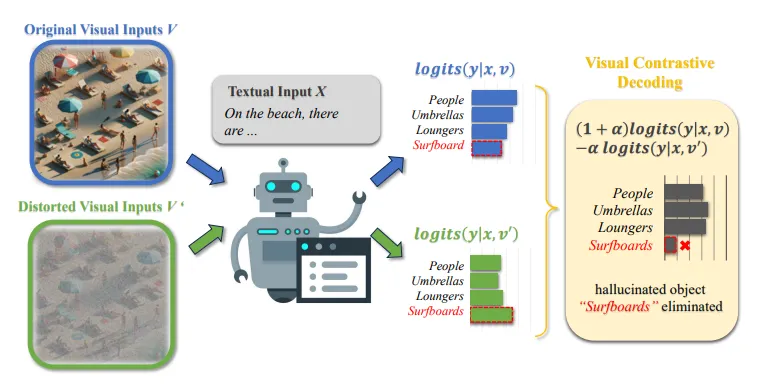
출처: https://arxiv.org/pdf/2311.16922
- HACL: MLLM 모델의 임베딩 공간을 조사한 후, 대조학습(contrastive learning)을 통해 다른 modality의 데이터가 의미적으로 유사하도록 학습시키는 방법입니다.
6-3-3 Post-correction
- 모델이 생성한 답변에서 환각을 수정하는 방법입니다.
- Woodpecker: MLLM이 생성한 답변을 전문가 모델이 검증한 후 답변을 수정하는 방법입니다. 이때 전문가 모델은 모두 개별적으로 사전 훈련된 개별적인 모델입니다.

출처: https://arxiv.org/pdf/2310.16045
- LURE: MLLM의 환각 현상을 수정할 수 있도록 따로 훈련시킨 수정 전문가(Revisor)를 사용하여 환각 현상을 해결하는 방법입니다.
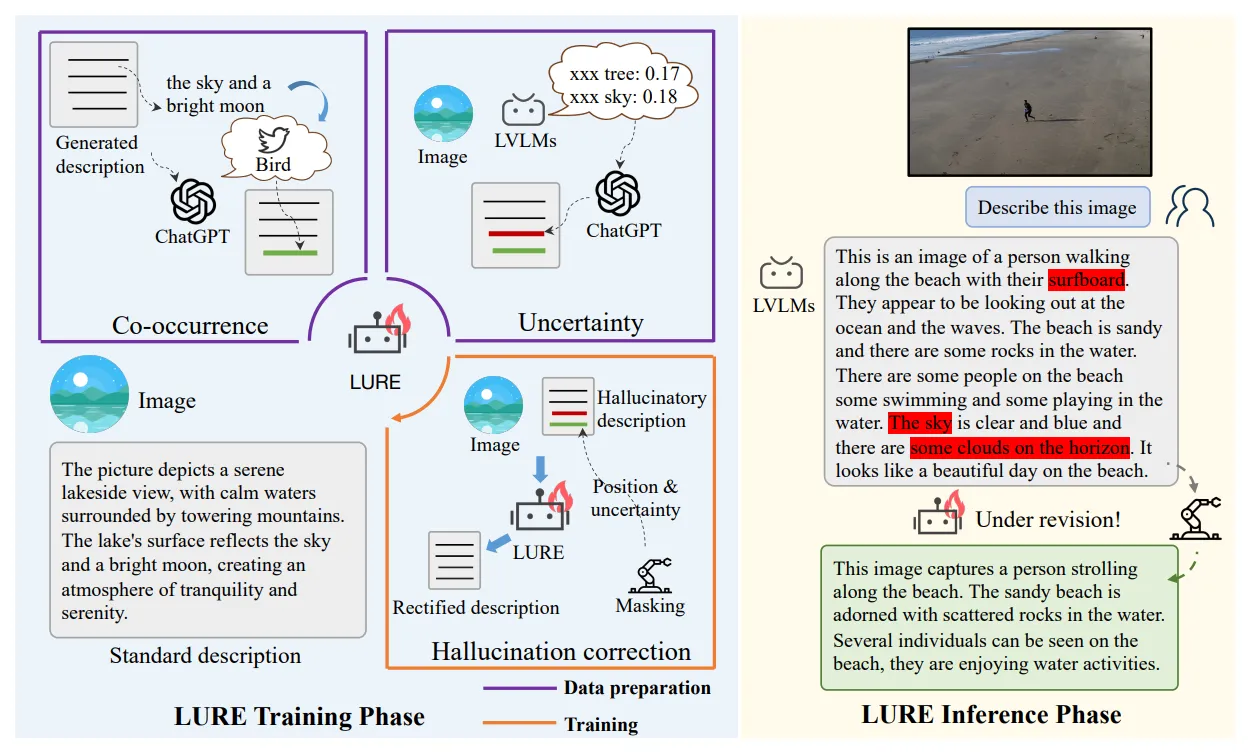
출력: https://arxiv.org/pdf/2310.00754
7️⃣ Extended Techniques
7-1 Multimodal In-Context Learning
🔷In-Context Learning (ICL)의 특징
- ICL은 기존의 학습과 달리, 데이터를 보고 유추를 통해 학습을 하는 방법입니다.
- LLM이 few-shot 방식으로 기존에 보지 못했던 문제를 해결하는 것이 이에 해당합니다.
- Few-shot 방식으로 학습하기 때문에, 별도의 train이 필요하지 않습니다.
- Instruction-tuning을 통해 ICL의 능력을 향상시킬 수 있습니다.
🔷M-ICL
- ICL의 능력을 MLLM으로 확장시킨 것이 Multimodal ICL (M-ICL)입니다.
- 모델을 추가 학습시키지 않고, 프롬프트 내에 몇 가지 멀티모달 예시를 함께 보여줌으로써 새로운 작업을 수행하게 하는 기술입니다.
- 예시는 아래의 template처럼 구현될 수 있습니다.
- 모델의 성능은 예시의 순서에 민감하게 반응하는 모습을 보입니다.

TABLE 9: A simplified example of the template to structure an M-ICL query, adapted from [98]. For illustration, we list two in-context examples and a query divided by a dashed line. {instruction} and {response} are texts from the data sample. is a placeholder to represent the multimodal input (an image in this case). and are tokens denoting the start and the end of the input to the LLM, respectively.
7-1-1 Improvement on ICL capabilities
- MIMIC-IT: Multimodal-Instruction 데이터 세트를 만들어서 Instruction-tuning을 진행합니다.
- Emu: 모델에 stable Diffusion과 같은 이미지 생성 디코더를 추가한 후, 텍스트에 맞는 이미지를 생성하는 지도학습을 통해 추론 능력을 향상시켰습니다.
- Link-context learning: 예시에 인과적인 정보를 추가하여 추론할 수 있도록 하는 방법입니다. 단순히 답변 형식이 아닌 왜 이러한 답변이 나왔는지 학습할 수 있도록 rew-shot을 설계합니다.
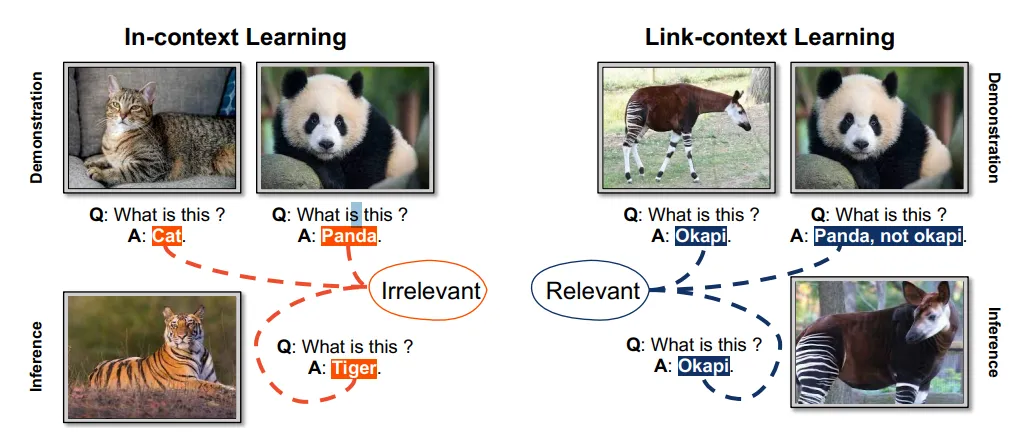
출처: https://arxiv.org/pdf/2308.07891
- MMICL: 여러 장의 관련 있는 이미지를 함께 제공하여, Instruction-tuning을 통해 모델의 M-ICL 능력을 향상시키는 방법입니다.
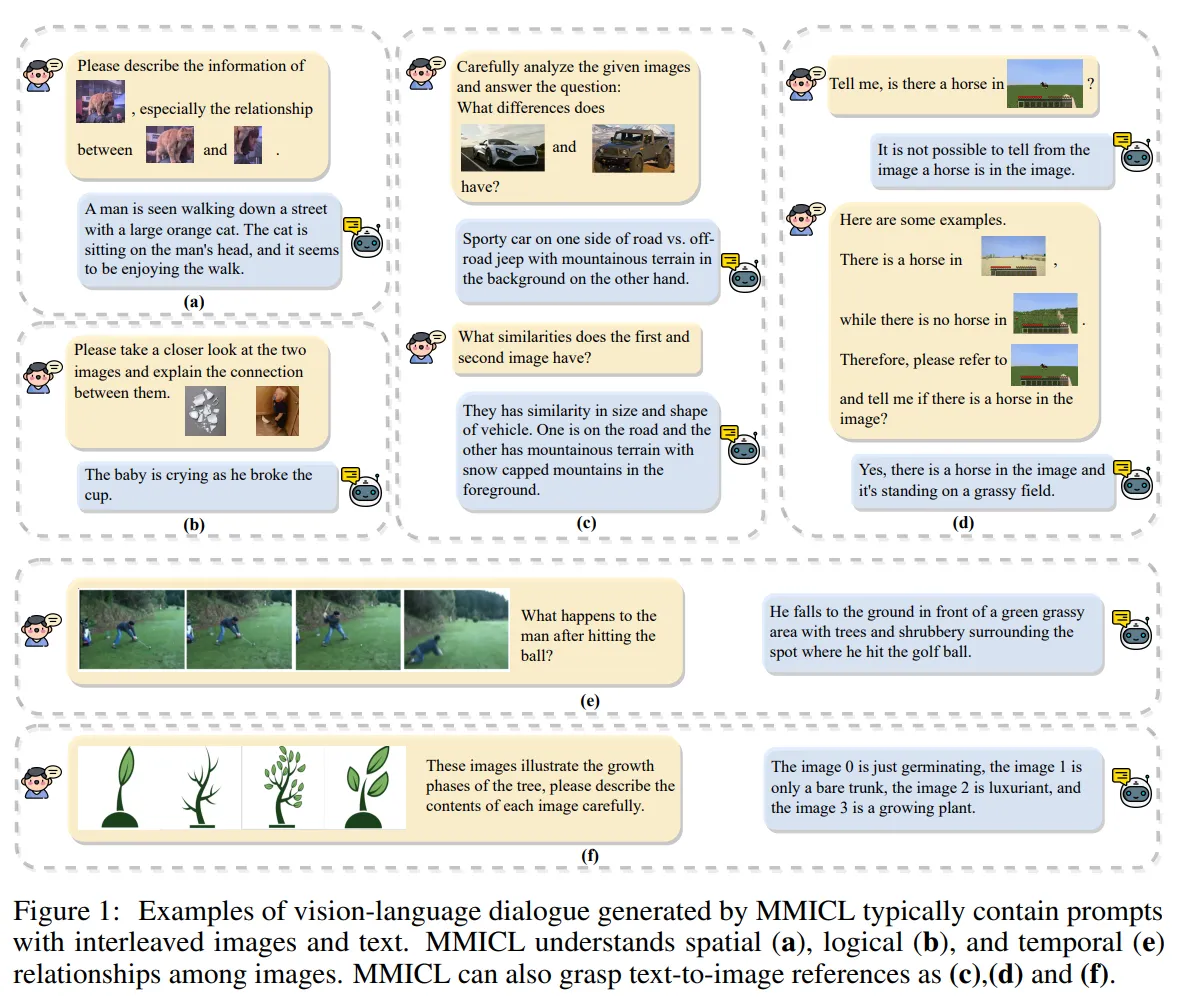
출처: https://arxiv.org/pdf/2309.07915
7-1-2 Application
- M-ICL을 통해 다양한 시각적 추론 작업을 해결할 수 있습니다.
- 모델이 외부 도구 사용법을 가르칠 수 있습니다.
7-2 Multimodal Chain of Thought
🔷Chain of Thought (CoT)
- CoT는 LLM이 최종 답변뿐만 아니라 그 답변에 도달하기까지의 중간 추론 과정을 함께 출력하도록 유도하는 기법입니다.
- 인간의 사고 과정과 유사하며, 복잡한 추론 작업을 수행하는데 효과적인 방법입니다.
🔷M-CoT
- CoT의 개념을 MLLM으로 확장한 것입니다.
- MLLM이 멀티모달 입력을 바탕으로 추론 과정을 단계별로 도출하고 최종 답변을 생성합니다.
7-2-1 Learning Paradigms
M-CoT의 학습 방식은 학습 데이터의 양에 따라 3가지로 나눌 수 있습니다.
🔷 Fine-tuning
- 설명이 포함된 데이터를 통해 모델이 생각하는 과정을 직접 학습할 수 있도록 합니다.
- Multimodal-CoT: ScienceQA 데이터를 사용하여, 풀이과정과 최종답변을 2 단계로 나누어 생성하도록 학습합니다.
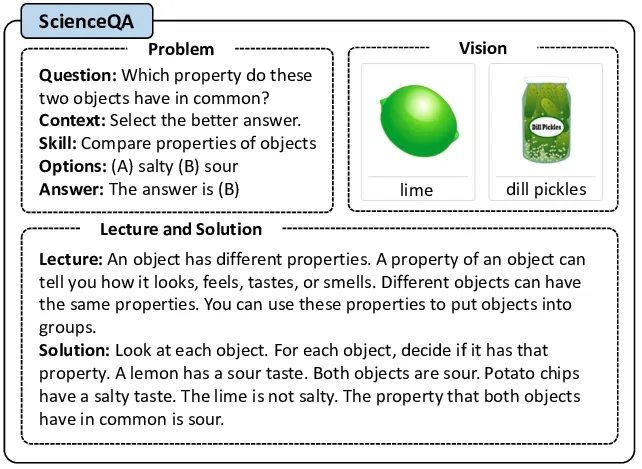
출처: https://www.researchgate.net/figure/Example-of-ScienceQA-dataset-Each-data-example-includes-input-from-multiple-modalities_fig1_370593869
🔷 Few-shot learning
- 프롬프트에 ‘단계적 풀이 과정이 포함된 예시’를 몇 가지 추가하는 방식입니다.
- 모델은 프롬프트에 입력된 예시를 통해 패턴을 파악합니다.
🔷 Zero-shot learning
- 모델에게 특별한 예시 없이 ‘단계적 풀이 과정’을 생각하라고 지시하는 방식입니다.
- 모델이 가지고 있는 지식과 추론 능력을 활용하기에 모델의 일반화 능력에 성능이 좌우됩니다.
7-2-2 Chain Configuration
🔷 Structure (추론 체인)
- Single-chain: 단계별 추론 과정이 하나의 질문-이유-답변 체인으로 형성됩니다.
- Tree-shape chain: 질문을 여러 개의 하위 질문으로 분해하고, 각 하위 질문은 LLM 자체 또는 시각 전문가를 통해 해결하여 이유를 생성합니다. 그런 다음 LLM이 이 이유들을 종합하여 최종 답변을 도출합니다.
🔷 Length (추론 체인의 길이)
- Adaptive formation: LLM이 스스로 추론 체인을 언제 중단할지 결정하는 방식입니다.
- Pre-defined formation: 미리 정의된 길이에서 체인을 중단하는 방식입니다.
7-2-3 Generation Patterns
🔷 Infilling-based pattern
- 추론 과정의 이전 단계와 이후 단계 사이의 "빈칸"을 채우는 방식입니다.
- 논리적 연결이 끊어진 부분을 메우기 위해 주변 문맥을 기반으로 중간 단계를 추론하여 채워 넣습니다
<프롬프트 형식>
문제: ...
1단계: [이전 단계 내용]
2단계: [빈칸] <-- 모델이 채워야 할 부분
3단계: [다음 단계 내용]
최종 답변: ...

출처: https://arxiv.org/pdf/2305.02317
🔷 Predicting-based pattern
- MLLM이 현재까지의 정보와 지침을 바탕으로 다음의 논리적 단계를 생성하는 방식입니다.
<프롬프트 형식>
문제: ...
1단계: [이전 단계 내용]
다음 단계를 설명해줘: <-- 모델이 다음 단계를 예측하고 이어서 생성해야 할 부분
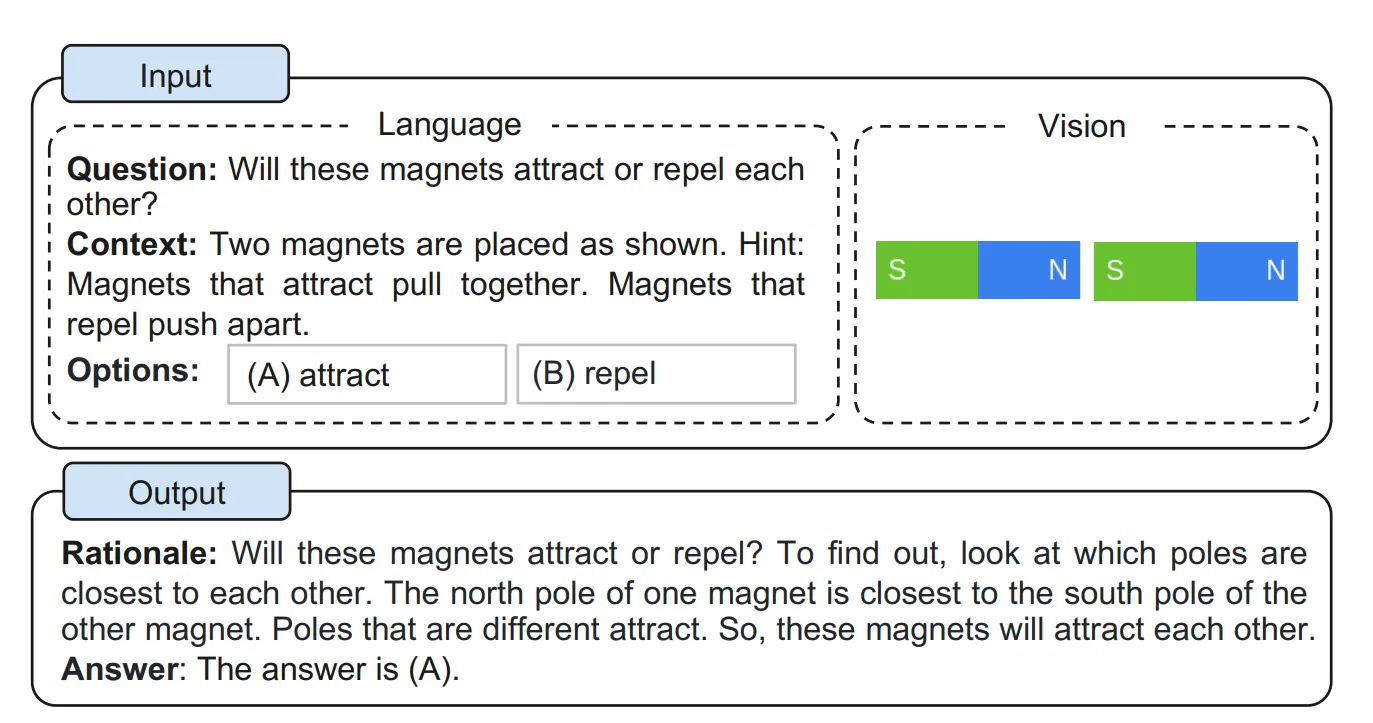
출처: https://arxiv.org/pdf/2302.00923
7-3 LLM-Aided Visual Reasoning
7-3-1 Introduction
LLM을 활용하여 시각적 추론을 진행할 때 기존의 시각 모델과 비교하여 아래와 같은 강점을 가집니다.
🔷 Strong generalization abilities
- LLM은 방대한 데이터로 사전 학습되어 세상에 대한 풍부한 지식을 가지고 있습니다.
- 이 덕분에 놀라운 zero-shot, few-shot 등 높은 일반화 능력을 보여줍니다.
🔷 Emergent abilities
- LLM이 가진 강력한 '추론 능력' 덕분에, 이 시스템들은 매우 복잡한 작업도 수행할 수 있습니다.
- MM-REACT처럼, 이미지를 보고 단순히 무엇이 있는지 설명하는 것을 넘어, "이 밈(meme)이 왜 웃긴지"처럼 겉으로 드러나지 않는 '숨겨진 의미'까지 해석할 수 있습니다.

출처: https://arxiv.org/pdf/2303.11381
🔷 Better interactivity and control
- 기존 모델은 사용자가 제어할 수 있는 방법이 제한적이고, 많은 훈련 비용이 필요했습니다.
- 하지만 LLM 기반 시스템은 '사용자 친화적인 인터페이스'를 통해 세밀한 제어가 가능합니다.
7-3-2 Training Paradigms
학습 패러다임은 크게 2가지로 나눌 수 있다.
🔷 Training-free
- 사전 학습된 LLM 모델이 이미 놀라운 성능을 보이기 때문에 추가적인 학습이 필요하지 않습니다.
- 대신 Few-shot, Zero-shot을 통해 적은 비용으로 모델을 유연하게 활용할 수 있습니다.
🔷 Finetuning
- LLM, 특정 작업이나 도구 사용을 더 잘 하도록 만들기 위해 추가적인 훈련을 시키는 방식입니다.
- GPT4Tools는 LLM이 외부 도구를 더 효과적으로 '계획하고 사용하는' 능력을 향상시키기 위해, 도구 사용과 관련된 새로운 지시어 훈련 데이터셋을 만들어서 모델을 파인튜닝했습니다.
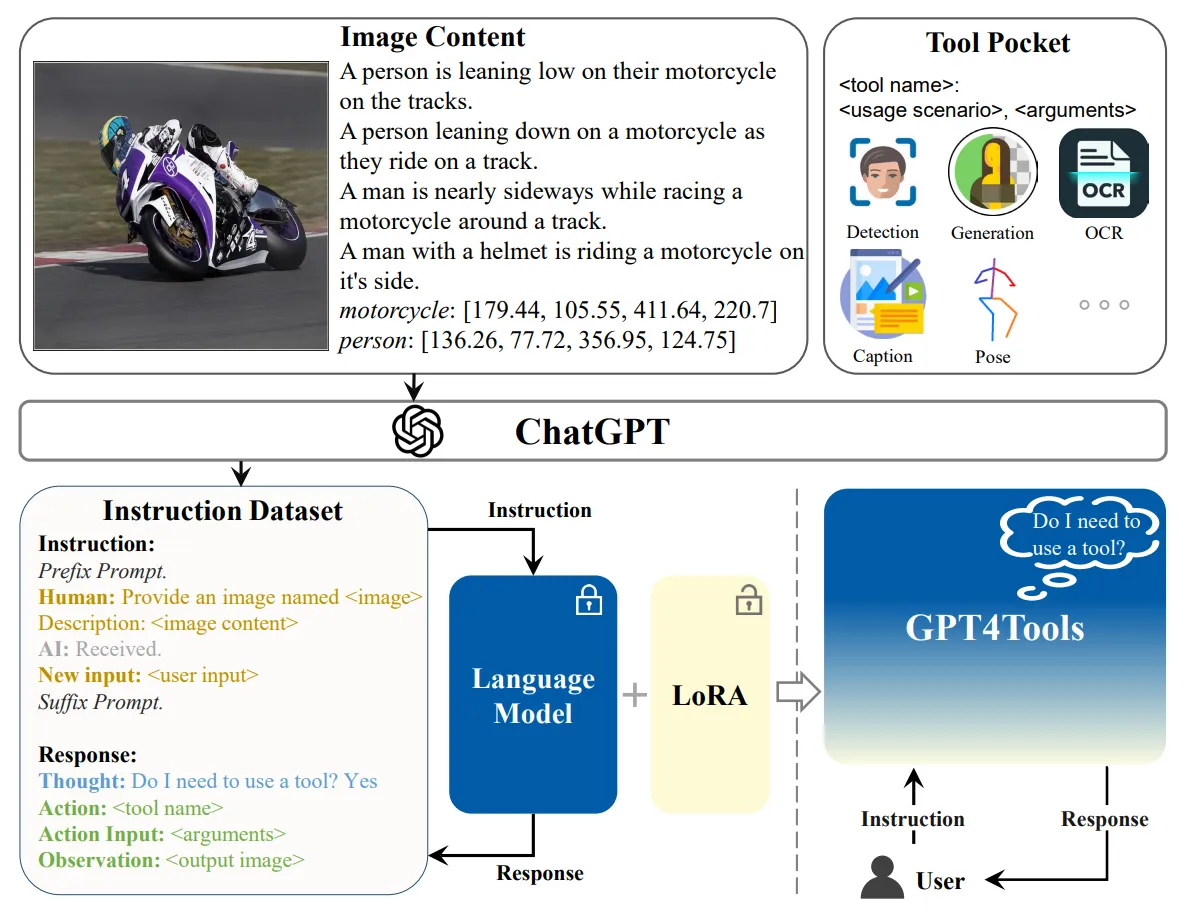
출처: https://arxiv.org/pdf/2305.18752
7-3-3 Functions
추론 시스템에서 LLM은 3가지 역할을 수행합니다.
🔷 Controller
- LLM 모델은 주어진 작업에 가장 적합한 외부 도구나 다른 전문가 AI 모듈에게 지시를 내리는 역할
- CoT 능력을 활용하여, 주어진 복잡한 문제를 간단한 하위 문제로 분해하는 역할을 수행합니다.
- 각 하위 작업을 적절한 외부 도구에 전달합니다.
🔷 Decision Maker
- 지금까지 처리한 데이터를 요약하고, 현재 주어진 작업을 해결하기 위해 추가적인 정보가 필요한지 여부를 결정합니다.
- 최종 답변을 사용자가 이해하기 쉬운 형태로 정리하는 역할을 수행합니다.
🔷 Semantics Refiner
- 다른 modality 도구들이 전달한 정보와 LLM이 가진 지식을 활용하여 자연스러운 답변을 생성하는 역할을 수행합니다.
- 사용자가 원하는 형태의 답변을 생성할 수 있도록 데이터를 수정하는 역할을 수행합니다.
8️⃣ Challenges and Future Directions
이번 장에서는 Multimodal Large Language Model (MLLM)의 현재 한계점과 앞으로 연구해야 할 유망한 방향을 설명합니다.
8-1 Limited in long context
- 한계: 아직까지 긴 비디오나, 이미지가 있는 긴 문서를 처리하는데는 한계가 있습니다.
- 발전 방향: 더 긴 비디오나 문서를 한번에 처리할 수 있는 모델을 개발해야 합니다.
8-2 Complicated Instructions
- 한계: 아직까지 사람의 복잡한 지시(Instruction)을 완벽하게 이해하고 따르지 못합니다.
- 발전 방향: 복잡한 지시를 따를 수 있는 모델을 개발해야 합니다.
8-3 M-ICL & M-CoT Improvement
- 한계: M-ICL과 M-CoT는 아직까지 초기 단계입니다.
- 발전 방향: MLLM의 few-shot능력과 깊이 사고할 수 있는 능력을 개선시켜야 합니다.
8-4 Embodied Agents
- 세상과 상호작용할 수 있는 Embodied agent를 개발하는 것은 아주 유망한 분야입니다.
8-5 Safety Issues
- 한계: MLLM 역시 특정 편향이나 유해한 정보에 오염될 수 있습니다.
- 발전 방향: 모델이 오용되지 않도록 모델의 안정성을 키워야 합니다.
9️⃣ Conclusion
본 논문에서는 MLLM의 기본 구성 요소와 확장, 앞으로의 연구 방향을 제시하였습니다.
독자들이 해당 Survey를 통해 MLLM의 발전 방향에 대해 더 잘 이해하기를 바랍니다.
