인공지능 모델은 새로운 데이터를 학습하면 기존의 성능은 떨어지게 됩니다. 가중치가 변하기 때문이죠. 이번 논문은 어떻게 이러한 문제를 해결할 것인지에 대해 다루는 논문입니다.
Abstract
지속적 학습(Continual Learning)
- 지속적으로 변화하는 데이터 스트림으로부터 점진적으로 학습하는 것을 의미합니다.
- 한마디로 새로운 데이터를 계속 배우는 것이죠.
- 인간의 두뇌에게는 자연스러운 능력이지만, 인공 신경망에게는 매우 어려운 과제입니다.
재앙적 망각 (Catastrophic Forgetting)
- 인공 신경망이 새로운 것을 학습할 때 이전에 학습한 내용을 빠르고 극단적으로 잊어버리는 현상을 말합니다.
1. Introduction
세상은 끊임없이 변화합니다. 따라서 새로운 정보를 지속적으로 학습하는 것은 변화하는 환경에서 살아남기 위해 필수적입니다.
인간은 이러한 능력을 잘 갖추고 있습니다. 새로운 정보를 학습한다고 해서 기존의 기억을 잊어버리지 않습니다. 또한 과거의 기억과 최근에 알게 된 사실을 연결하는 능력 역시 가지고 있습니다. 파이썬에서 배운 지식을 C언어에서 활용할 수 있는 것처럼 말이죠.
AI는 Task를 수행하는데 있어서 인간과 필적한 지능을 가지고 있지만, 새로운 정보를 계속 학습하는 것은 잘하지 못합니다. 새로운 정보를 배우면 기존에 학습했던 것을 잊어버리기 때문이다.
우리는 이러한 현상을 “Catastrophic Forgetting”이라고 부릅니다. 치명적일 정도로 잊어버린다는 것이죠.
그렇다면 우리는 왜 Catastrophic Forgetting 문제를 해결해야 할까요? 이 문제를 해결하면 어떤 점이 좋을까요?
- 계산 비용을 줄여준다.
- 현재 우리는 변화하는 세상에 대응하기 위해 계속 새로운 데이터를 학습해야 합니다.
- 하지만 Catastrophic Forgetting 문제로 인해 새로운 정보를 추가적으로 학습하면 기존에 학습한 능력을 잃게 됩니다.
- 이를 방지하기 위해서는 기존에 학습한 데이터와 새로운 데이터를 함께 다시 학습시켜야 합니다. 당연히 그 비용은 엄청납니다.
- 따라서 Catastrophic Forgetting를 해결할 수 있다면 이러한 계산 비용을 크게 줄일 수 있을 것이다.
- 모델에 존재하는 오류, 편향을 없앨 수 있다.
- 우리는 모델을 학습시킨 후 모델이 특정 오류나 편향을 가지고 있는 것을 확인할 수 있습니다.
- 이때 지속적 학습이 가능하다면 미세조정을 통해 이러한 오류나 편향을 없애도록 학습할 수 있습니다.
- 로컬환경에서도 잘 적응할 수 있다.
- 모델이 로컬 환경에서 사용자에 맞는 정보를 계속 수집할 수 있을 때, 지속적인 학습이 가능하다면, 클라우드를 통한 서버 연결 없이 각자 맞춤형 학습을 진행할 수 있습니다.
- 인공지능의 지속적 학습(Continual Learning)에 대한 연구는 뇌과학 학문이 발전하는 데에도 좋은 통찰을 제공합니다.
2. The Continual Learning Problem
용어정리
Non-stationary 데이터 스트림
- 데이터의 분포가 시간이 지남에 따라 변화하는 것을 의미한다.
- 즉, 학습 데이터의 특성이 고정되어 있지 않고 계속해서 바뀌는 것이다.
Incrementally 학습
- 새로운 정보를 학습할 때 기존에 학습한 내용을 덮어쓰지 않고, 지식을 축적하는 방식으로 학습해야 한다.
- 이전 지식을 보존하면서 새로운 지식을 계속해서 추가하는 것이 중요하다.
2.1 Catastrophic Forgetting
출처: https://arxiv.org/pdf/2403.05175
- 자료에서 알 수 있듯이 기존의 학습을 진행한 후 새로운 task를 학습시키면 기존의 학습한 내용을 빠르게 망각한다.
- 새로운 task를 학습하면 가중치 값들이 기존에 최적화된 값에서 멀어지기 때문이다.
- 하지만 서로 다른 task가 함께 학습되면, 두 task를 모두 잘 수행할 수 있는 최적화값에 도달할 수 있다.
2.2 Other Features Important for Continual Learning
Continual Learning을 문제의 주안점
- 새로운 학습은 기존에 학습한 것을 빠르게 망각시킨다는 문제점이 존재한다.
- 그래서 기존에 학습한 것이 잘 망각되지 않도록 접근하는 방법을 생각해볼 수 있다.
- 하지만 기존에 학습한 것이 잘 망각되지 않도록 접근하는 방법은 새로운 것을 배우는 능력을 저하시킨다.
- 이를 안정성-가소성 딜레마 (Stability-Plasticity Dilemma) 라고 한다.
- 안정성(Stability): 모델이 이전에 학습한 정보를 얼마나 잘 유지하는지를 의미한다. 높은 안정성은 과거의 지식을 잊지 않도록 한다.
- 가소성(Plasticity): 모델이 새로운 정보를 얼마나 잘 학습할 수 있는지를 의미한다. 높은 가소성은 새로운 환경이나 task에 빠르게 적응할 수 있도록 한다.
Continual Learning을 실현하기 위해 필요한 특징
- 적응성 (Adaptation)
- 순차적인 학습은 새로운 정보를 학습하는 능력을 잃게 하는 한다. (Dohare et al.(2023))
- 순차적 학습: 모델이 여러 작업을 한 번에 학습하는 것이 아니라, 작업 순서에 따라 하나씩 학습하는 방식
- 기존 학습한 내용에 맞춰진 representation space가 새로운 task에 맞춰지기 때문에 기존 학습한 내용을 설명하기 못한다.
- 따라서 논문에서는 모델이 새로운 정보에 빠르게 적응할 수 있어야 함을 강조한다.
- 순차적인 학습은 새로운 정보를 학습하는 능력을 잃게 하는 한다. (Dohare et al.(2023))
- Task 간 유사성 활용 (Exploiting task similarity)
- 모델이 새로운 task를 학습했을 때, 긍정적인 전이 (Positive transfer)가 가능해야 한다.
긍정적인 전이 (Positive transfer)란 하나의 task를 학습한 결과로 인해 다른 task의 성능이 직접적으로 향상되거나, 해당 task를 다시 학습하는 것이 더 쉬워지는 현상을 의미한다.
-
전방 전이 (Forward Transfer): 새로운 task를 학습하는 것이 미래의 task 학습을 용이하게 하는 것을 의미한다.
-
후방 전이 (Backward Transfer): 새로운 task를 학습하는 것이 이전에 학습한 task에 도움이 되는 것을 의미한다.
-
합성적 표현 학습 (Learning Compositional Representations): 작업 간 지식 전이를 개선하는 유망한 방법 중 하나로, Mendez and Eaton, 2023에서 제시되었다. 이는 여러 task에서 공통적으로 사용될 수 있는 기본 요소들을 학습하여, 새로운 task에 더 쉽게 적응할 수 있도록 합니다.
-
합성성 (Compositionality): 복잡한 개념을 더 간단한 구성 요소로 분해하고, 이러한 구성 요소들을 조합하여 새로운 개념을 학습하는 능력
-
작업 불가지론(Task agnostic)
- 모델이 자신이 수행하는 task의 종류에 대한 정보 없이 task를 잘 수행하는 능력이 필요하다.
- Task agnostic이라는 단어는 아래의 의미를 가진다.
- 테스트 시 task의 정체를 모르는 경우
- 훈련 시 task의 정체를 모르는 경우
- Task 전환에 대한 정보를 받지 못하는 경우
- 근본적인 task 집합이 존재하지 않는 경우
내 생각: 지속적인 학습 환경 속에서 데이터의 학습 목적을 끊임없이 제공하기는 힘들 것이다. 모델 스스로 데이터를 통해 task를 이해할 수 있다면 학습 비용이 훨씬 줄어들 것 같다.
-
잡음 허용 오차 (Noise tolerance)
- 일반적으로 모델은 노이즈가 제거된, 전처리된 데이터를 통해 학습한다.
- 노이즈가 많은 데이터에서 모델은 성능이 저하되고, 일반화 능력이 떨어진다.
- 하지만 지속적인 학습을 위해서는 모델 스스로 노이즈가 포함된 데이터를 잘 처리할 수 있어야 한다.
- 또한 환경이 변화하면서 기존의 데이터 분포 역시 변화할 수 있다.
- 모델은 이러한 변화하는 분포 역시 잘 학습할 수 있어야 한다.
-
효율적인 자원 사용과 지속 가능성 (Resource efficiency and substainability)
- 새로운 데이터를 계속 저장하는 것은 메모리 측면에서 문제가 될 수 있다.
- 또한 기존의 데이터와 새로운 데이터를 함께 지속적으로 학습시키는 것은 많은 자원을 요구한다.
- 논문에서는 모델의 사용 목적에 따라 모델의 성능과 자원 효율성의 중요도를 판단하여, 최적의 균형점을 찾아야 한다고 말한다.
2.3 Task-based versus Task-free Continual Learning
작업 기반 지속적 학습 (Task-based Continual Learning)
- 하나의 task를 학습시킨 후, 다음 task를 학습시키는 방식
- 장점
- 구현 용이성: task 간의 경계가 명확하므로, 각 task를 독립적으로 학습하고 관리하기가 비교적 쉽다.
- 평가 용이성: 각 task에 대한 성능을 개별적으로 측정하고 비교할 수 있어, 모델의 학습 과정을 평가하기 용이하다.
- 단점
- 현실 세계와의 괴리: 실제 세계에서는 task 간의 경계가 명확하지 않은 경우가 많으므로, 작업 기반 학습이 현실적인 시나리오를 제대로 반영하지 못할 수 있다.
- 작업 전환 의존성: task 전환 시점을 명확히 알아야 하므로, 실제 환경에서 모델이 자동으로 task를 식별하고 전환하는 데 어려움이 있을 수 있다.
- 재앙적 망각이 발생하기 쉽다.
작업 자유 지속적 학습 (Task-free Continual Learning)
- 학습하는 task가 연속적으로 변화하는 방식
- ex) 사용자가 A task에서 B task로 관심사가 변화하는 경우 (학습 데이터 종류 변화)
- ex) 계절이 변화하면 학습해야하는 기후 분포가 변화하는 방식 (데이터 분포 변화)
- 장점
- 현실 세계 반영: 작업 간의 전환이 점진적으로 이루어지는 실제 환경을 더 잘 반영합니다.
- 유연성: 모델이 작업 전환 시점을 명확히 알 필요 없이, 데이터 스트림의 변화에 따라 자연스럽게 학습할 수 있습니다.
- 단점
- 구현 복잡성: 작업 간의 경계가 불분명하므로, 학습 과정과 모델 구조를 설계하기가 더 어렵습니다.
- 평가 어려움: 작업 간의 성능을 명확히 구분하기 어려워, 모델의 학습 과정을 평가하기가 더 복잡합니다.
- 작업 식별 문제: 모델이 스스로 작업을 식별하고 적절한 학습 전략을 적용해야 하므로, 작업 식별 및 전환에 대한 추가적인 연구가 필요합니다.
MNIST 데이터 예시

출처: https://arxiv.org/pdf/2403.05175
- 자료는 MNIST 데이터를 이용하여 여러 task를 만든 예시이다. 각 task는 서로 다른 숫자를 구분하는 분류 task로 이해하면 된다.
- Task-based continual learning에서는 학습 데이터가 각 task에 맞게 명확하게 구분되어 있는 것을 확인할 수 있다.
- Task-free continual learning에서는 학습 데이터가 서서히 연속적으로 변화하는 것을 확인할 수 있다.
Task-based and task-free Continual Learning의 공식화
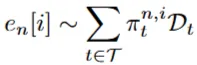
출처: https://arxiv.org/pdf/2403.05175
- 변수의 의미
- : task 집합
- : 데이터 스트림을 나타내는 경험(experiences)의 시퀀스
- : 각 경험은 특정 task를 수행하기 위해 학습해야 할 데이터로 이해하면 된다.
- : 작업 에 대한 경험
- : 작업 의 훈련 데이터 분포
- : 경험 의 데이터 포인트
- : 데이터 포인트가 작업 의 데이터 분포 에서 샘플링될 확률
- 해당 수식의 의미
- 시간 가 변화함에 따라 모델이 학습해야할 task가 변화하게 되고, 모델이 학습할 데이터 등장 분포 역시 변화함을 보여준다.
- Task-based Continual Learning에서는 각 경험에 특정 task에 대한 데이터만 있을 것이다.
- Task-free Continual Learning에서는 여러 task의 데이터가 있을 것이다.
- 경험이 가지는 의미
- 학습의 단위: 경험은 모델이 학습하는 기본 단위이므로, 경험을 어떻게 구분하느냐에 따라 모델의 학습 방식이 달라질 수 있다.
- 계산 효율성: 경험의 크기는 모델의 메모리 사용량과 계산 복잡도에 영향을 미칩니다. 적절한 경험 크기를 선택하는 것은 효율적인 학습을 위해 중요하다.
- 망각과 적응: 경험을 너무 작게 나누면 모델이 빠르게 적응할 수 있지만, 망각이 심해질 수 있다. 반대로 경험을 너무 크게 나누면 모델이 안정적으로 학습할 수 있지만, 새로운 변화에 늦게 반응할 수 있다.
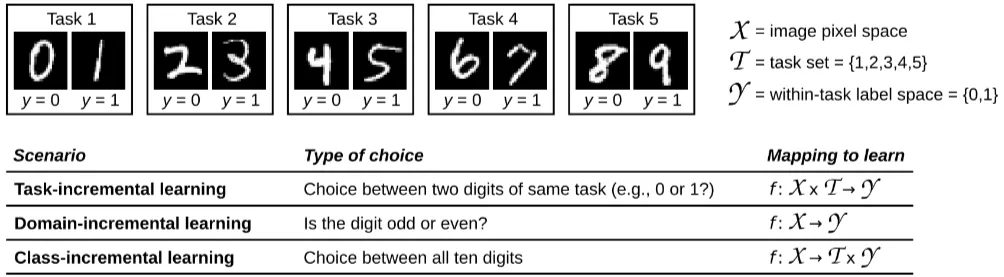
2.4 Three Continual Learning Scenarios
Continual Learning을 할 때, 모델이 겪을 수 있는 학습 시나리오를 설명한다.
출처: https://arxiv.org/pdf/2403.05175
A. Task-incremental learning (Task-IL)
- 모델이 서로 다른 task를 점진적으로 학습하는 경우
- 모델은 “서로 다른 task”라는 정보를 전달받으며, 서로 다른 task를 수행하기 위해 다른 출력 레이어를 사용할 수 있다.
- Task마다 다른 신경망을 사용할 경우, 망각이 발생하지 않을 수 있다.
- Task-IL 방식은 모델이 task마다 분리된 신경망을 사용하지 않고, 서로 학습한 표현을 공유하여 앞서 언급한 긍정적인 전이 (Positive transfer)를 달성해야 한다.
🤔왜 Task-IL 방식에만 task ID 정보를 제공할까?
- 모델이 task ID를 제공하면, 새로운 task를 학습할 때, 기존의 task를 얼마나 잘 수행하는 지 평가하기가 더 쉽다.
- 또한 현실세계에서도 다른 task를 수행할 때, task변환 신호를 제공하기 쉽기 때문에 합리적인 접근이다.
- 하지만 현실세계에서 모델 스스로 task를 인식하는 것은 많은 이점이 있기에 이 부분에도 많은 연구가 이루어지고 있다.
B. Domain-incremental learning (Domain-IL)
- 학습해야할 데이터의 구조는 동일하지만, 시간이 지나며 데이터의 분포가 변화하는 경우를 의미
- ex) 모델이 사람들의 생체리듬을 학습할 때, 계절에 따라 낮의 길이가 변하면서 사람들의 생체리듬 분포 역시 변화하는 경우
- 모델은 데이터 분포의 변화를 감지하고, 해당 데이터의 해당 분포(도메인)에서 주어진 task를 가장 잘 수행할 수 있는 방법을 학습하는데 집중한다.
- ex) 객체 인식의 경우, 맑은 날씨에서는 기존의 방식대로 데이터를 처리 ex) 데이터의 분포(도메인)이 변화하여 날씨가 흐린 경우, 이미지 대비를 높이거나, 노이즈를 제거하는 전처리 과정을 수행하여 객체 인식 성능 향상
- ex) 객체 인식의 경우, 맑은 날씨에서는 기존의 방식대로 데이터를 처리 ex) 데이터의 분포(도메인)이 변화하여 날씨가 흐린 경우, 이미지 대비를 높이거나, 노이즈를 제거하는 전처리 과정을 수행하여 객체 인식 성능 향상
- 나는 이를 위해서는 모델은 스스로 데이터의 도메인이 변화함을 인식할 수 있어야 한다고 생각한다.
- 하지만 논문에서는 도메인의 변화를 인식하는 것이 최선의 방법은 아닐 수 있다고도 언급하고 있다.
- 그래서 논문 Figure3의 Mapping to learn에서도 task set에 대한 mapping은 없는 것 같다.
C. Class-incremental learning (Class-IL)
- 점진적으로 증가하는 객체 또는 클래스를 구별하는 경우
- ex) 기존에 피아노와 기타를 분류하는 task를 모델이 학습하다가, 바이올린과 색소폰의 분류를 추가로 학습했을 때, 모델이 4가지 종목 모두를 분류할 수 있어야 한다.
- 즉 기존의 task에서 새로운 정보가 들어왔을 때, 모델이 새로운 정보를 반영하여 모델 수행 범위를 확장하는 데 집중한다.
- 이 시나리오는 기존에 피아노와 기타를 분류하는 task1과 바이올린과 색소폰을 분류하는 task2로 구분할 수 있다. 모델은 이 task1과 task2를 따로 수행하는 것이 아니라 피아노, 기타, 바이올린, 색소폰 모두를 동시에 분류할 수 있는 task3를 수행하는 것을 목표로 한다.
- 이를 위해서 모델은 스스로 새로운 객체 또는 클래스가 학습 데이터에 추가되었음을 인식할 수 있어야 한다.
- 새로운 객체인지 인식하는 방법으로는 이상 탐지 등의 방법이 있다.
Clarifying note.
데이터의 학습 상황에 대한 2가지 분류
- Task-incremental, Domain-incremental, Class-incremental learning: 학습 시나리오를 정의하는 기준
- Task-incremental learning : 작업 ID를 알고 있는 상태에서 순차적으로 학습하는 것을 의미한다.
- Domain-incremental learning : 문제의 구조는 같지만 입력 데이터의 분포가 바뀌는 상황을 의미한다.
- Class-incremental learning : 새로운 클래스를 순차적으로 학습하는 것을 의미한다.
- Task-based vs Task-free continual learning: 학습 데이터의 변화 방식에 대한 구분
- Task-based continual learning : 훈련 데이터가 작업 단위로 변화하며, 작업 간 경계가 명확하다.
- Task-free continual learning : 작업 간의 전환이 점진적으로 이루어지며, 작업 경계가 명확하지 않다.
- 해당 두 가지 분류 기준은 서로 독립적이라 어떠한 조합 역시 가능하다.
- ex) Domain-incremental learning이면서 Task-based continual learning한 상황이 발생할 수 있다.
2.5 Evaluation
지속적인 학습 (Continual Learning)에 대한 관심이 증가하면서, 지속적인 학습을 잘 하였는지 평가하기 위한 방식들이 제안되었다. 대표적인 방식은 3가지이다.
A. 성능 (Performance)
- 성능 평가와 관련해서는 2가지 논점이 있다.
- 어떻게 평가할 것인가?
- 언제 평가할 것인가?
- 논문에서는 어떻게 평가할지에 대한 질문에 아래와 같이 작성되어 있다.
- 분류를 기준으로 모든 task의 정확도(accuracy)의 평균을 통해 평가한다.
- 각 task는 동일한 가중치로 평가한다. 즉 task간 중요도의 차등을 두지 않는다.
- 하지만 이러한 방식은 각 task의 학습 상태를 파악할 수 없다는 한계가 존재한다. 이러한 한계를 극복하기 위해 2번째 평가 방식인 diagnostic analysis가 등장하였다.
- 분류를 기준으로 모든 task의 정확도(accuracy)의 평균을 통해 평가한다.
- 언제 평가할지에 대해서는 2가지 방향이 있다.
- 모든 task의 학습이 완료된 후, 평가한다.
- 학습 중간 중간에 주기적으로 성능을 평가하여,
B. 진단 분석 (Diagnostic analysis)
- 학습 정확도 (Learning Accuracy)
- 모델의 성능을 basemodel과 비교하여 평가
- 예를 들어 basemodel은 어떠한 task도 학습하지 않은 모델이다. 반면 지속적인 학습은 한 모델은 task1, task2, task3을 학습한 상태이다. 이때 두 모델이 모두 task4에 대해 학습을 수행한 후, 두 모델의 성능을 비교하는 것이다.
- 이러한 방식을 통해, 지속적인 모델이 새로운 task에 대해 얼마나 잘 적응하는지를 평가할 수 있다.
- 즉 모델의 적응력(plasticity) 평가
- 한 과목만 수업을 듣는 학생에 비해, 여러 과목을 동시에 배우는 학생이 수업을 잘 따라오고 있는지 확인하는 것
- 모델의 성능을 basemodel과 비교하여 평가
- 이전 전이 (Backward Transfer)
- 새로운 task를 학습할 때, 이전 task의 성능이 어떻게 변화하는지 측정
- 모델의 재앙적 망각(catestrophic forgetting)과 안정성(stability)에 대한 통찰력 제공.
- 즉 현재의 task 학습이 과거 task 학습에 어떤 영향을 끼쳤는지 평가
- 새로운 걸 가르치고 나서 다시 그 옛날 내용을 물어보는 것
- 순방향 전이 (Forward Transfer)
- 이전 task들을 학습한 것이 특정 task i의 성능에 미치는 영향을 측정하는 지표
- : task 1부터 i-1까지 학습한 후 task i에서의 정확도
- : 이전 task 없이 작업 i만 학습했을 때의 정확도
- 의 부호
- 양수 : 이전 task들을 학습한 것이 새로운 task i의 성능을 향상시켰다는 의미. 즉 Positive transfer가 발생했는 의미.
- 0 : 이전 task들을 학습한 것이 새로운 task i의 성능에 아무런 영향을 미치지 않았다는 의미
- 음수 : 이전 task들을 학습한 것이 오히려 새로운 task i의 성능을 저하시켰다는 의미. 즉 Negative transfor가 발생했다는 의미.
- 즉 과거의 학습이 새로운 task를 학습하는데 얼마나 도움이 되는지 평가.
- 새로운 공부를 할 때, 과거에 배운 내용을 얼마나 잘 활용하는지 평가하는 것
C. 자원 효율성 (Resource efficiency)
모델이 지속적인 학습을 수행할 때, 얼마나 효율적인 방식으로 학습을 수행하는 지 평가하는 것.
- 계산 자원 효율성 (Computational Efficiency)
- 연산량(연산 횟수)와 복잡도를 통해 측정
- 학습 단계와 추론 단계의 연산량이 다를 수 있기 때문에 구분해서 측정
- 지속 가능성 (Sustainability)
- 모델이 학습을 계속할수록 얼마나 빠르게 자원(파라미터 수, 메모리 등)이 증가하는지를 평가
- 상황에 따라 모델의 성능과 자원 사용의 균형을 조절하는 것이 중요하다.
3 Continual Learning Approache
3장에서는 지속적인 학습을 위한 접근방식을 소개한다. 지속적인 학습을 하기 위한 여러 방식이 있지만, 논문에서는 이러한 방식의 근간이 되는 계산 방식에 대해 다룬다.
출처: https://arxiv.org/pdf/2403.05175
3.1 Replay
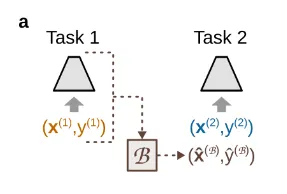
출처: https://arxiv.org/pdf/2403.05175
- Replay는 기존에 학습한 데이터를 재사용하여 학습하는 방법이다.
- 기존에 학습한 데이터의 일부와 새로운 데이터를 교차로 함께 학습하는 방식이다.
- 기존에 학습한 데이터는 해당 데이터를 잘 대표할 수 있는 데이터로 선정된다.
- 즉 과거의 경험을 다시 떠올리며, 새로운 경험과 함께 학습하는 방식이다.
- 이러한 방식은 인간의 뇌 신경 작동 방식과 유사하다.
- 이렇게 과거의 데이터를 학습하는 방식은 Catestorphic forgetting을 막는 좋은 방법이다.
- 기존의 데이터를 다시 학습하는 방법은 연산량을 증가시키지만, 가중치가 이미 기존의 가중치에 적합되어 있기 때문에 적은 데이터로도 잘 수행할 수 있다.
- 과거의 데이터를 가져오는 방식은 2가지로 나눌 수 있다.
- 기존에 학습한 데이터를 메모리에 저장한 후 다시 가져오는 방법
- 생성 모델을 활용하여, 학습할 데이터를 새로 생성하는 방법
- 생성모델을 활용할 경우 데이터의 변화에 따라 생성 모델 역시 지속적으로 학습해야 한다는 한계가 존재한다.
- 학습 방법
- : 전체 손실 함수로 현재 task와 이전 task의 정보를 동시에 반영한 최종 손실이다.
- : 현재 task의 학습을 위한 손실 함수.
- : 과거 task의 정보를 유지하기 위한 손실 함수.
- 인지과학 연구에서는 Replay를 할때, 새로 학습할 데이터와 유사한 데이터를 Replay하면 된다고 주장한다.
- 서로 관련이 없는 데이터는 간섭이 적기 때문이다. 오히려 유사한 데이터 간에 서로 영향을 줄 수 있기 때문에 함께 학습하는 것이 좋다.
- Replay 분야에서 추가적으로 진행되는 연구
- 학습한 데이터를 어떻게 저장하고 압축할 것인가?
- 어떤 형식으로 기존의 데이터를 Replay할 것인가?
- ex) raw data 학습, 모델이 처리한 feature 학습
- Replay를 다른 연산 방법과 어떻게 통합할 것인가?
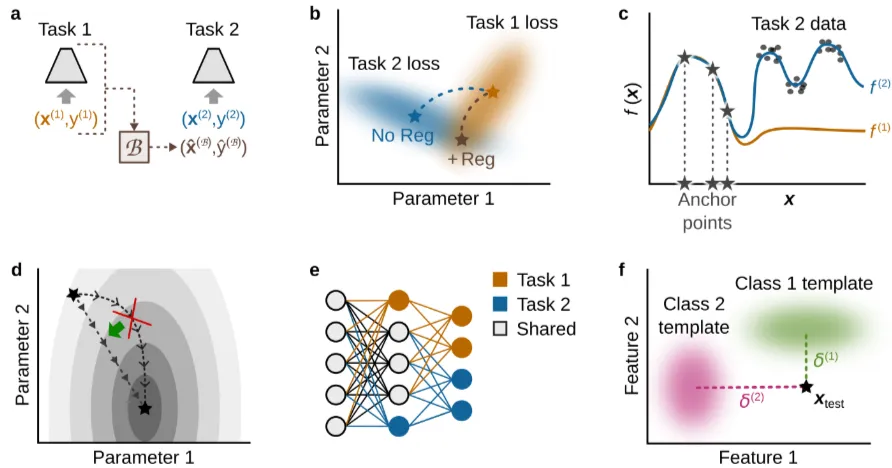
3.2 Parameter Regularization
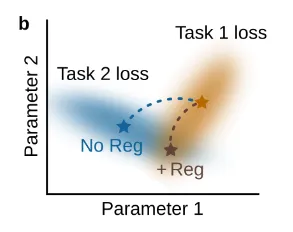
출처: https://arxiv.org/pdf/2403.05175
- 새로운 task를 학습할 때, 이전에 학습한 파라미터 중 중요한 파라미터의 변화를 억제하는 방법이다.
- 이는 신경학적 관점에서 메타가소성(metaplasticy)으로 연결될 수 있는데, 모델 파라미터의 가소성 수준을 결정하는 것으로 해석될 수 있기 때문이다.
- 베이즈적 관점으로는 새로운 task를 학습할 때, 이전에 학습한 파라미터 분포를 따르라는 조건을 준 것으로 해석할 수 있다.
- : 전체 손실 함수. 현재 task 학습과 과거 task 보존을 동시에 고려한 손실이다.
- : 현재 task의 데이터에 대한 손실 함수이다.
- : 과거 task의 파라미터를 보존하기 위한 정규화 항이다.
- : 이전 task에서 학습된 최적 파라미터
- : 각 파라미터의 중요도를 나타내는 행렬로, Fisher Information Matrix나 그 근사치로 사용
- Fisher Information Matrix는 각 매개변수의 작은 변화가 손실에 미치는 영향을 나타내는 matrix이다.
- 하지만 Fisher Information Matrix를 구하는 것은 많은 연산량을 요구하여, 학습 중 feature importance를 추출하는 다른 방식도 존재한다.
- Parameter Regularization는 task와 domain incremental 학습 문제에서 성공적인 결과를 보여주었다.
- 하지만 class incremental 학습 시나리오에서는 task 간 경계를 학습하는 데 어려움을 겪는 경우가 많다
3.3 Functional Regularization
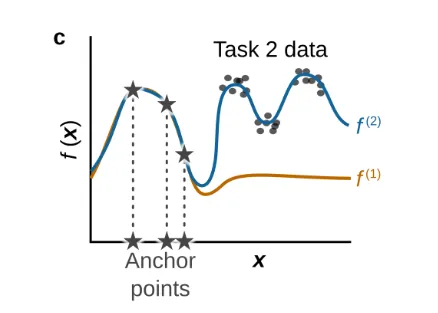
출처: https://arxiv.org/pdf/2403.05175
- 기능적 정규화는 모델의 출력분포의 변화를 통제하는 학습기법이다.
- 기존에 학습된 모델의 출력값과 새로운 학습이 진행되는 모델의 출력값이 유사하도록 규제를 가함으로써, 모델이 학습이 완료되더라도, 기존 출력 결과(모델의 출력 분포)를 유지할 수 있도록 한다.
- 앞서 살펴본 Parameter Regularization은 파라미터 값 자체의 변동에 규제를 가했다면, Funtional Regularization은 모델의 출력결과를 규제한다.
- : 현재 모델(파라미터 를 가짐)의 입력-출력 매핑(함수)을 의미.
- : 전 작업 후의 모델의 입력-출력 매핑. 는 이전 작업이 끝날 때의 파라미터 값
- : 앵커 포인트(anchor points)들의 집합. 앵커 포인트는 입력 공간에서 선택된 특정 입력 값들로, 이 지점들에서의 함수 값 변화를 규제한다.
- : 와 사이의 차이를 앵커 포인트 에서 측정하는 항입니다. 이 항은 가 $f_{\theta^}$*와 유사하도록 규제하는 역할을 합니다.
- 기본 아이디어: 신경망의 파라미터와 네트워크의 동작(함수) 사이의 복잡한 관계 때문에, 이전 작업에 중요했던 파라미터를 추정하고 제어하는 것은 매우 어렵습니다. 대신, 네트워크가 특정 입력 집합(앵커 포인트, anchor points)에 대해 이전 작업 종료 시점의 입력-출력 매핑(함수)과 크게 달라지지 않도록 제약을 가하는 것이 더 효과적일 수 있습니다.
차이 측정 방법
그렇다면 두 함수값의 출력은 어떻게 비교할 수 있을까요?
- 초기에는 두 모델의 최종 출력값의 확률 분포 간 크로스 엔트로피 차이로 계산을 하였습니다. 이 방법을 지식 증류 (Knowledge Distillation, KD)라고 합니다. 즉 수학문제를 풀 때 A학생의 정답과 답지의 정답이 같아지도록 학습하는 방법이지요.
- 하지만 이 방식은 풀이과정에 대해 검토는 없다는 맹점이 있습니다. 그래서 최근에는 모델 은닉층의 출력값 역시 계산에 포함시키는 특징 증류 (Feature Distillation) 방식을 더 사용합니다. 정답 뿐 아니라 풀이과정 역시 답지와 유사하도록 학습하는 방식입니다.
그렇다면 이때 사용되는 anchor point는 어떻게 정할 수 있을까요?
-
가장 단순한 방법은 pre-train에 사용된 모든 데이터를 anchor point로 활용하는 것일 겁니다. 하지만 이 방식은 계산량이 너무 많다는 한계가 존재합니다.
-
그래서 초기에는 데이터를 임의로 추출하는 방식을 사용하였습니다.
-
하지만 이 방식은 복잡한 task에서는 좋은 성능을 발휘하지 못했습니다. 임의로 추출한 데이터들이 복잡한 task의 특성을 잘 대표하지 못하기 때문이죠.
그래서 2가지 방법이 제시됩니다.
첫 번째는 파인튜닝에 사용되는 입력 데이터를 anchor point로 사용하자는 아이디어입니다. 이 방법은 모델이 파인튜닝을 할 때 사용하는 데이터를 활용하기 때문에 메모리 측면에서는 효율적일 수 있습니다. 하지만 하나의 입력에 대해 기존의 출려과 파인튜닝 시의 출력을 동시에 만족해야 하는 상황이기에 좋은 아이디어는 아닙니다.
두 번째는 출력 분포를 가장 잘 대표하는 값들을 추출하는 것입니다. 이 때는 각 데이터가 가지고 있는 정보량을 기준으로 정보량이 많은 데이터를 anchor point로 사용합니다. 엔트로피 개념에서 정보량은 발생 빈도가 적을수록 데이터가 가지고 있는 정보가 많다고 정의합니다. 하지만 그 외에도 다른 방식이 많아서 이 부분은 다른 글에서 조금 더 구체적으로 다뤄보도록 하겠습니다.
3.4 Optimization-based Approaches
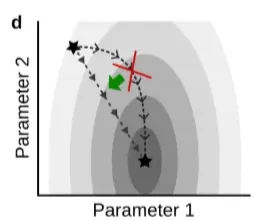
출처: https://arxiv.org/pdf/2403.05175
- 지금까지는 손실함수를 어떻게 정의하는지지에 관해 다루었다면 이제부터는 손실함수를 어떻게 최적화할지에 대해 다룬다.
- 지속적인 학습을 한다는 것은 학습 데이터가 계속 변하기 때문에, 최적화 지점이 계속해서 변한다는 것을 의미한다. 따라서 우리가 기존에 사용하던, 점점 관성을 부여하거나, 학습률을 줄여나가는 방식이 효과적이지 않을 수 있다. 예를 들어 최적화 지점에 가까이 도달할수록 학습률을 줄여나가는 optimizer를 사용한다면 시간이 지나면서 학습률을 점점 줄어들 것이다. 그런데 학습 데이터가 변하여 최적점이 멀어지면 다시 학습률을 늘려야 빠르게 최적점에 도달할수 있는 상황을 마주할 수 있다.
- 또한 지속적인 학습을 위해서는 어떤 최적점에 도달해야 하는지에 대한 연구도 발전되었다. 결론부터 말하자면 지속적인 학습을 위해서는 넓게 평탄한 최적점을 찾아야 한다. 지속적인 학습을 할 때는 가중치가 변화하기 때문에 Loss 함수 위의 점이 움직이기 마련이다. 그런데 현재 위치한 최저점이 평탄하게 넓은 최저점이라면 가중치가 움직이더라도 Loss는 둘어들지 않을 것이다.
- 지금까지 우리는 Adam SGD등의 optimizer를 통해 학습을 해왔다. gradient의 크기에 따라 학습률을 조정하는 방식이다. 이번에는 중요한 가중치 방향에 대해서는 학습률을 낮추고, 덜 중요한 가중치에 대해서는 학습률을 높이는 방식에 대해 고민해볼 수 있다.
- 그 외에도 학습률을 조절하는 대신 중요한 가중치는 확률적으로 업데이트를 진행하지 않는 방식을 적용해볼 수 있다. 중요한 가중치에 대해서는 특정확률로 학습률이 0이 된다고 이해할 수 있다. 중요한 가중치는 건드리지 말자! 라는 아이디어인 것 같다.
- 경사 투영: 가중치를 업데이트할 때 벡터가 움직이는 방식인데, 서로 직교하도록 벡터공간을 변환하면, 중요하지 않은 가중치는 움직이면서도, 중요한 가중치는 고정할 수 있다.(직교경사투영)
- 이때 중요한 가중치와 중요하지 않은 가중치는 예전에 학습한 데이터의 gradient를 기준으로 선정!
- 그 외에도 GEM , 시냅스 강화 기반 학습 방식 등 다양한 접근 방법이 연구되고 있다.
3.5 Context-dependent Processing
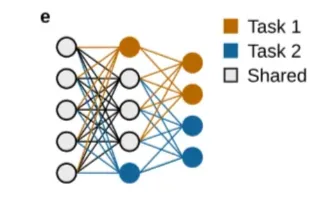
출처: https://arxiv.org/pdf/2403.05175
5번째 방식은 task별로 사용하는 신경망이 다르도록 설계를 하는 것입니다. 유사한 task끼리는 같은 신경망을 사용하고, 서로 다른 task는 신경망을 공유하지 않도록 하여, 지속적인 학습 중 task 간의 간섭을 최대한 줄이는 방식입니다. 당연히 신경망을 분리하여 학습을 진행하기 때문에 효과적인 긍정적인 전이를 기대하기는 어렵습니다. 이 방식을 적용하기 위해서는 새로운 task를 학습할 때, 새로운 신경망을 추가해야 한다는 특징이 있습니다. 이는 task간 간섭은 줄어들지만 모델의 크기는 커진다는 trade-off 문제이기도 합니다.
당연히 각 task마다 사용해야 하는 신경망이 다르기 때문에 모델이 입력 데이터가 어떤 task인지, 즉 데이터를 처리하는 현재 상황(context)에 대한 이해가 있다는 전제 하에 진행됩니다. 하지만 이러한 맥락을 파악하는 것 역시 쉽지는 않습니다.
5번째 방식은 task별로 사용하는 신경망이 다르도록 설계하는 문맥 의존적 처리(context-dependent processing) 전략입니다. 유사한 task끼리는 신경망을 공유하고, 서로 다른 task는 분리된 네트워크를 사용함으로써 task 간 간섭(interference)을 최소화합니다.
일반적으로는 새로운 task를 학습할 때마다 새로운 신경망(또는 모듈)을 동적으로 추가하는 방식으로 구현되며, 이는 점진적 네트워크 확장(dynamic network expansion)이라 불립니다. 하지만 신경망을 분리하기 때문에 긍정적인 전이(positive transfer)는 제한되고, task 수가 많아질수록 모델 크기가 비례적으로 증가한다는 단점도 존재합니다.
또한 이 방식은 각 입력이 어떤 task에 속하는지를 모델이 명확히 알고 있다는 전제 하에 작동하며, 이 전제는 현실적 환경에서는 충족되지 않는 경우가 많습니다. 이러한 이유로, context를 자동으로 식별하는 보조 알고리즘과 결합되어야 실용적으로 적용이 가능합니다.
3.6 Template-based Classification
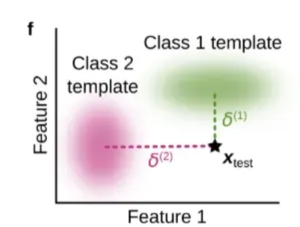
출처: https://arxiv.org/pdf/2403.05175
마지막 방식은 모델의 구조를 바꾸는 방법으로 지속적인 학습을 수행한다. 기존의 모든 분류 문제는 각 class 중 가장 확률이 큰 값을 선택한다. 그래서 모델을 학습할 때 정답 클래스의 확률이 커지도록 학습한다.
이번 방식에서는 군집화와 유사한 방식으로 분류를 수행한다. 각 class에 대해 대표적인 데이터를 선정한다. 이를 템플릿이라고 한다. 그래서 새로운 데이터가 들어오면 템플릿과의 거리가 얼마나 가까운지를 통해 분류를 수행한다. 그리고 모델이 새로운 class를 학습할 때, 해당 class에 대한 새로운 군집을 형성하여 템플릿을 만든 후 분류를 수행한다. 예를 들어 피아노, 바이올린에 대한 template(대표값)을 통해 더 가까운 class로 분류를 수행한다고 하자. 이때 드럼이라는 새로운 데이터가 들어오면 모델은 드럼 데이터 모아 새로운 템플릿을 만든다. 이런 방식은 가중치의 변화 없이도 새로운 class를 학습할 수 있다는 장점이 있다. 하지만 이 방법은 기존의 레이어가 새로운 class에 대해 군집이 잘 형성될 수 있도록 작동할 수 있을까 하는 의심이 들기도 한다.
4 Continual Learning in Deep Learning versus in Cognitive Scienc
이번 장에서는 딥러닝 분야에서의 지속적인 학습과 인지과학에서의 망각에 대해 연구가 서로 다르면서도 도움을 준다는 내용을 담고 있습니다.
인지과학에서는 새로운 기억이 생기면서 기존의 기억이 망각되는 역행 간섭(retroactive interference)이 연구되고 있습니다. 이는 딥러닝의 catasrophic forgetting과 매우 유사합니다. 생물학에서 역행 간섭을 어떻게 완화할 것인가에 대한 연구는 딥너링의 continual learning을 위한 좋은 통찰을 제공해주었습니다.
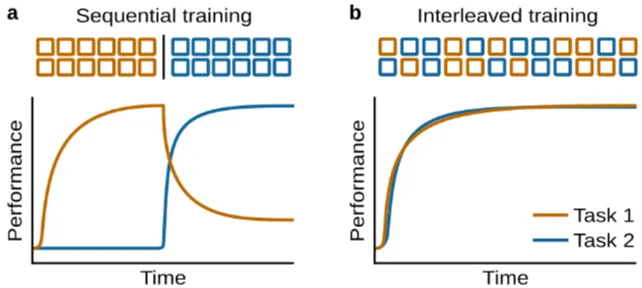
이 외에도 딥러닝 모델은 블록 방식(blocked training)에서 성능이 나빠지지만, 인간은 오히려 블록 방식일 때 더 잘 학습하고 ,인터리브(interleaved) 학습일 때 성능이 떨어진다는 연구 등 인간과 신경망을 비교하려는 시도도 꾸준히 이어지고있습니다.
논문의 저자는 이번 장에서 앞으로도 인지과학과 딥러닝이 서로 좋은 영향을 줄 수 있도록 많은 상호작용을 가지는 것이 중요하다고 말합니다.
5 Conclusion
지속적인 학습은 지속적으로 지식을 축적할 수 있는 AI를 개발하기 위한 중요한 과제입니다. 재앙적 망각은 지속적인 학습을 위해 해결해야 할 가장 큰 문제입니다. 하지만 재앙적 망각 외에도 적응성, task간 유사성 활용, 잡음 오차 허용 등 다양한 문제를 해결해야 합니다. 또한 앞서 다뤘던 Task-incremental learning, Domain-incremental learning 등 다양한 문제 상황을 잘 정의하고 이들을 평가할 기준 역시 적절하게 설계해야 합니다.
이를 위해 우리는 지속적인 학습을 위한 6가지 방법을 살펴보았습니다. 신경 과학, 인지 과학, 심리학 등 학제 간 협력은 지속적인 학습의 발전을 위해 큰 도움이 될 것입니다.
