📝 Dynamic Cheatsheet: Test-Time Learning with Adaptive Memory
🔗 논문: https://arxiv.org/abs/2504.07952
💻 GitHub : Dynamic Cheatsheet: Test-Time Learning with Adaptive Memory
✏️ 논문 정리
1. 이 논문을 읽는 이유가 무엇인가요?
⇒ AI가 과거 경험, 시행착오를 토대로 더 좋은 선택을 할 수 있도록 메모리 모듈을 구현하려고 하는데, 이 논문이 메모리 업데이트를 다루는 것 같아 읽어보았다. 메모리 모듈을 어떻게 관리하는지 이해하면 된다.
2. 논문 제목의 의미는 무엇인가요?
⇒ Dynamic Cheatsheet는 계속 바뀌는 컨닝페이퍼라는 의미이다. 모델이 메모리 속 데이터를 계속 수정하고, 또 참고할 수 있다. Test-Time은 추론 시간을 의미한다. 즉 모델이 실제로 작동하는 과정에서 메모리를 수정해나가는 것이다.
3. 논문의 등장배경은 무엇인가요?
⇒ LLM은 메모리를 가지고 있지 않아 동일한 추론이나 실수를 반복한다. 이에 LLM이 지속적이고, 계속 발전하는 메모리를 가질 수 있도록 Dynamic Cheatsheet 프레임워크를 제안한다.
4. 논문을 1~2줄로 요약하세요
⇒ 논문은 모델의 경험을 메모리에 저장하는 방식으로 DC-Cu, DC-RS 두가지 방식을 제안한다. DC-Cu는 추론 후 메모리에 추론 결과를 계속 반영하는 방식이고, DC-RS는 추론 전 현재 상황과 관련된 과거 경험을 Retrieve하여 메모리를 수정한 후 추론을 진행하는 방법이다.
0️⃣ 논문의 등장 배경
- LLM은 메모리를 가지고 있지 않아 동일한 추론이나 실수를 반복한다. 이에 LLM이 지속적이고, 계속 발전하는 메모리를 가질 수 있도록 Dynamic Cheatsheet 프레임워크를 제안한다.
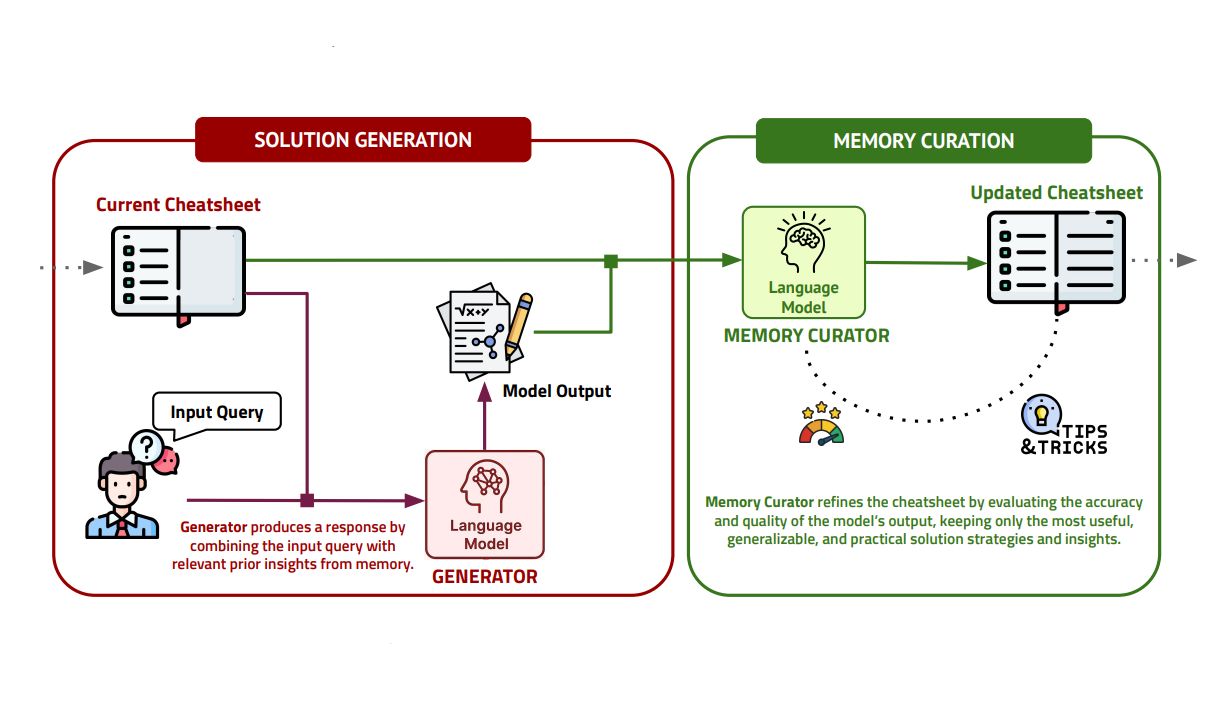
1️⃣ 핵심 방법론
🔷 DC-Cu (Dynamic Cheatsheet-Cumulative)

🔻Generator
- Gen: Generator → 메모리와 현재 Query 를 통해 출력 을 생성한다.
🔻 Curator
-
Cur: Curator → 모델의 현재 입출력을 참고하여 메모리 를 업데이트 한다.
-
작동 과정
-
현재 Query 와 출력 정보가 유용하다면 적절한 형태로 변환하여 저장한다.
-
현재 메모리 속에 저장된 정보가 잘못되었다면 수정하거나 업데이트한다.
-
메모리 속 데이터를 명료하고 간단하게 정리한다.
-
-
한계점
-
모델의 추론 과정에서 얻은 인사이트를 메모리에 반영할 수 없다. ⇒ 메모리를 업데이트할 때 모델의 입력과 출력 결과만 참고하기 때문.
-
모델이 과거에 처리했던 입출력 정보 를 참고할 수 없다.
-
🔷 DC-RS (Dynamic Cheatsheet with Retrieval & Synthesis)

🔻 Retrieval
-
Retr: Retrieval → 과거 입출력 정보 에서 필요한 정보를 가져온다.
-
작동 과정
- 과거 입출력 정보에서 Top k개를 Retrieve한다.
-
특징
-
모델이 입력 데이터를 처리하기 전에, 과거 유사한 경험을 가져와 메모리에 반영한 뒤, 메모리를 참고하여 출력 결과를 생성한다.
-
모델이 과거 모든 입출력을 확인할 수 있다.
-
3️⃣ 논문의 한계점
🔻 모델 크기에 의존
-
작은 모델은 Baseline보다 성능이 떨어지는 경우가 발생한다.
-
작은 모델이 잘못된 추론을 할 경우 메모리 내용이 망가진다.
-
작은 모델은 긴 텍스트를 이해하는 능력이 떨어진다.
🔻 메모리 소실
- 모델이 메모리를 업데이트할 때, 전체 메모리를 재생성하는데, 이때 이전 메모리가 누락되거나 요약되면서 손실되는 경우가 발생한다.
🔻 잘못된 사례 검색
- 모델이 Retrieve를 수행할 때, 겉내용은 비슷하지만 실제 다루는 내용은 전혀 다른 경우가 발생한다. → 코사인 유사도 검색이라서 그런 것 같다.
🤔현재 구조의 아쉬운 점
- 모델의 입출력만 참고하고, 왜 그렇게 출력했는지 과정이 없음.
- 데이터를 가공하여 저장하지 않고, 그대로 사용
4️⃣ 코드 구현
구현 방법이 궁금하시면 읽어보시고, 아니면 굳이 살펴보실 필요는 없습니다.
💻 Github: https://github.com/suzgunmirac/dynamic-cheatsheet
🔷 DC-Cu 구현
-
메모리는 문자열로 관리하고, LLM에게 입력, 메모리, 답변을 모두 주고 메모리를 업데이트하도록 지시
-
모델 출력은 지정된 포맷에서 필요한 정보만 파싱하도록 설계
def advanced_generate(self,
approach_name: str,
input_txt: str,
cheatsheet: str = None,
generator_template: str = None,
cheatsheet_template: str = None,
temperature: float = 0.0,
max_tokens: int = 2048,
max_num_rounds: int = 1,
allow_code_execution: bool = True,
code_execution_flag: str = "EXECUTE CODE!",
add_previous_answers_to_cheatsheet: bool = True,
original_input_corpus: List[str] = None,
original_input_embeddings: np.ndarray = None,
generator_outputs_so_far: List[str] = None,
retrieve_top_k: int = 3,
) -> Tuple[str, str, str, str]:
"""
Generate a response from the language model.
Arguments:
approach_name : str : The name of the approach to use.
input_txt : str : The input text for the model.
cheatsheet : str : The cheatsheet for the model.
generator_template : str : The template for the generator model.
cheatsheet_template : str : The template for the cheatsheet extraction model.
temperature : float : The sampling temperature for the model.
max_tokens : int : The maximum number of tokens to generate.
max_num_rounds : int : The maximum number of rounds allowed.
allow_code_execution : bool : Whether to allow code execution.
code_execution_flag : str : The flag to trigger code execution.
add_previous_answers_to_cheatsheet : bool : Whether to add the previous answers to the cheatsheet.
original_input_corpus : List[str] : The original input corpus.
original_input_embeddings : np.ndarray : The original input embeddings.
generator_outputs_so_far : List[str] : The generator outputs so far.
retrieve_top_k : int : The number of top k inputs to retrieve.
Returns:
Tuple[str, str, str, str] : The generator answer, evaluator solution, answer check, and new cheatsheet.
Raises:
ValueError : If the proper templates are not provided.
"""
elif approach_name == "DynamicCheatsheet_Cumulative":
if cheatsheet is None:
raise ValueError("Cheatsheet must be provided for dynamic_cheatsheet approach.")
if cheatsheet_template is None:
raise ValueError("Cheatsheet template must be provided for dynamic_cheatsheet approach.")
steps = []
previous_answers = []
generator_output = ''
""
# 라운드 수만큼 반복하며 지식 누적
for round in range(max(1, max_num_rounds)):
## STEP 1: Run the generator model with the input text and the cheatsheet
generator_cheatsheet_content = cheatsheet # -> 메모리라고 생각하면 된다. str 형태
# If there are previous answers, add them to the cheatsheet content for the generator
# 이전 답변을 그대로 넣을 거면 해당 if문이 True가 되어 실행
if round > 0 and add_previous_answers_to_cheatsheet:
previous_answers_txt = f"PREVIOUS ANSWERS:\n{'; '.join(previous_answers)}"
generator_cheatsheet_content = f"{generator_cheatsheet_content}\n\n{previous_answers_txt}"
# Replace 함수를 사용해서 generator template의 [[QUESTION]]와 [[CHEATSHEET]] 부분을 채운다.
generator_prompt = generator_template.replace("[[QUESTION]]", input_txt).replace("[[CHEATSHEET]]", generator_cheatsheet_content)
current_cheatsheet = cheatsheet
# Prepare the message history for the generator model
# 메모리와 질문을 포함한 프롬프트로 generator model을 실행
generator_history = [{"role": "user", "content": generator_prompt}]
# Run the generator model
generator_output = self.generate(
history=generator_history,
temperature=temperature,
max_tokens=max_tokens,
allow_code_execution=allow_code_execution,
code_execution_flag=code_execution_flag,
)
# Extract the output from the generator model
# extract_answer 함수를 사용해서 generator model의 답변을 추출 -> 필요한 부분만 가져와주는 함수
generator_answer = extract_answer(generator_output)
## STEP 2: Run the cheatsheet extraction model with the generator output and the current cheatsheet
# 모델 실행 결과와 이전 치트시트를 사용해서 새로운 치트시트를 생성
cheatsheet_prompt = cheatsheet_template.replace("[[QUESTION]]", input_txt).replace("[[MODEL_ANSWER]]", generator_output).replace("[[PREVIOUS_CHEATSHEET]]", current_cheatsheet)
cheatsheet_history = [{"role": "user", "content": cheatsheet_prompt}]
cheatsheet_output = self.generate(
history=cheatsheet_history,
temperature=temperature,
max_tokens=2*max_tokens,
allow_code_execution=False,
)
# Extract the new cheatsheet from the output (if present); otherwise, return the old cheatsheet
# 모델 출력 중 새로운 치트시트 부분을 추출
new_cheatsheet = extract_cheatsheet(response=cheatsheet_output, old_cheatsheet=current_cheatsheet)
cheatsheet = new_cheatsheet
previous_answers.append(f"Round {round+1}: {generator_answer}")
steps.append({
"round": round,
"generator_prompt": generator_prompt,
"generator_output": generator_output,
"generator_answer": generator_answer,
"current_cheatsheet": current_cheatsheet,
"new_cheatsheet": new_cheatsheet,
})
return {
"input_txt": input_txt,
"steps": steps,
"previous_answers": previous_answers,
"final_answer": generator_answer,
"final_cheatsheet": new_cheatsheet,
"final_output": generator_output,
}🔷 DC-RS 구현
-
DC-Cu의
advanced_generate코드를 보면 입력으로 임베딩 값을 받는다. -
입력된 임베딩으로 코사인 유사도 계산
elif approach_name in ["Dynamic_Retrieval", "DynamicCheatsheet_RetrievalSynthesis"]:
# Get the current original input embedding
# 유사도 계산을 위해 입력 데이터의 임베딩을 사용
current_original_input_embedding = original_input_embeddings[-1] # Current original input embedding
# 이전 입력 데이터의 임베딩을 가져옴
prev_original_input_embeddings = original_input_embeddings[:-1] # Note that this can be empty
# Retrieve the most similar k input-output pairs from the previous inputs and outputs
if len(prev_original_input_embeddings) > 0:
# 코사인 유사도를 사용하여 가장 유사한 이전 입력을 찾음
similarities = cosine_similarity([current_original_input_embedding], prev_original_input_embeddings)
top_k_indices = np.argsort(similarities[0])[::-1][:retrieve_top_k]
# 가장 유사한 k개의 이전 입력과 출력을 가져옴(텍스트 형태)
top_k_original_inputs = [original_input_corpus[i] for i in top_k_indices]
top_k_original_outputs = [generator_outputs_so_far[i] for i in top_k_indices]
top_k_similar_values = similarities[0][top_k_indices]
# Use the retrieved pairs to curate the cheatsheet for the generator model
# 이전 데이터를 사용하여 치트시트를 구성하도록 하는 템플릿
curated_cheatsheet = "### PREVIOUS SOLUTIONS (START)\n\nNote: The input-output pairs listed below are taken from previous test cases and are meant to assist you in understanding potential solution strategies or tool usages. While they can offer insight and inspiration, they should not be blindly copied, as they may contain errors or may not fit your specific use case. Approach them with a critical mindset—analyze their logic, verify their correctness, and adapt them as needed. Your goal should be to develop a well-reasoned solution that best addresses the problem at hand.\n\n"
else:
# 이전 입력값이 없으면 그냥 바로 빈 값으로 초기화
top_k_original_inputs = []
top_k_original_outputs = []
top_k_similar_values = []
curated_cheatsheet = '(empty)'
# The following only adds the previous input-output pairs to the cheatsheet
# 만약 이전 입력-출력 쌍이 존재한다면 치트시트에 추가
for i, (previous_input_txt, previous_output_txt, similarity) in enumerate(zip(top_k_original_inputs[::-1], top_k_original_outputs[::-1], top_k_similar_values[::-1])):
curated_cheatsheet += f"#### Previous Input #{i+1} (Similarity: {similarity:.2f}):\n\n{previous_input_txt}\n\n#### Model Solution to Previous Input #{i+1}:\n\n{previous_output_txt}\n---\n---\n\n"
curated_cheatsheet = curated_cheatsheet.strip()
# If it is empty, we should not add the "PREVIOUS SOLUTIONS (END)" to the cheatsheet
if curated_cheatsheet != '(empty)':
curated_cheatsheet += "\n\n#### PREVIOUS SOLUTIONS (END)"
# Run the Generator model with the input text and the curated cheatsheet (input-output pairs) to generate a better (more tailored) cheatsheet
previous_cheatsheet = cheatsheet
if approach_name == "DynamicCheatsheet_RetrievalSynthesis":
# First, we need to make the necessary replacements in the cheatsheet template
# DC-RS 템플릿에 이전 입력-출력 쌍, 현재 입력, 이전 메모리를 넣음
cheatsheet_prompt = cheatsheet_template.replace("[[PREVIOUS_INPUT_OUTPUT_PAIRS]]", curated_cheatsheet) # 이전 입력-출력 쌍
cheatsheet_prompt = cheatsheet_prompt.replace("[[NEXT_INPUT]]", input_txt) # 현재 입력
cheatsheet_prompt = cheatsheet_prompt.replace("[[PREVIOUS_CHEATSHEET]]", previous_cheatsheet) # 이전 메모리
# 이전 데이터와 입력, 기존 메모리를 넣은 프롬프트를 모델에 입력
# Now, we are ready to run the cheatsheet curator model
cheatsheet_history = [{"role": "user", "content": cheatsheet_prompt}]
cheatsheet_output = self.generate(
history=cheatsheet_history,
temperature=temperature,
max_tokens=2*max_tokens,
allow_code_execution=False,
)
# Finally, extract the new cheatsheet from the output (if present); otherwise, return the old cheatsheet
new_cheatsheet = extract_cheatsheet(response=cheatsheet_output, old_cheatsheet=curated_cheatsheet)
curated_cheatsheet = new_cheatsheet
# Replace the relevant placeholders in the generator template with the input text and the curated cheatsheet and then run the generator model
generator_prompt = generator_template.replace("[[QUESTION]]", input_txt).replace("[[CHEATSHEET]]", curated_cheatsheet)
generator_history = [{"role": "user", "content": generator_prompt}]
generator_output = self.generate(
history=generator_history,
temperature=temperature,
max_tokens=max_tokens,
allow_code_execution=allow_code_execution,
code_execution_flag=code_execution_flag,
)
# Extract the answer from the generator model
generator_answer = extract_answer(generator_output)
return {
"input_txt": input_txt,
"steps": [
{
"round": 0,
"generator_prompt": generator_prompt,
"generator_output": generator_output,
"generator_answer": generator_answer,
"current_cheatsheet": curated_cheatsheet,
"new_cheatsheet": None,
}
],
"top_k_original_inputs": top_k_original_inputs,
"top_k_original_outputs": top_k_original_outputs,
"final_answer": generator_answer,
"final_output": generator_output,
"final_cheatsheet": curated_cheatsheet,
}🔷 Generator_prompt.txt
# GENERATOR (PROBLEM SOLVER)
Instruction: You are an expert problem-solving assistant tasked with analyzing and solving various questions using a combination of your expertise and provided reference materials. Each task will include:
1. A specific question or problem to solve
2. A cheatsheet containing relevant strategies, patterns, and examples from similar problems
---
## 1. ANALYSIS & STRATEGY
- Carefully analyze both the question and cheatsheet before starting
- Search for and identify any applicable patterns, strategies, or examples within the cheatsheet
- Create a structured approach to solving the problem at hand
- Review and document any limitations in the provided reference materials
##### 메모리 속 데이터를 분석하고, 검토하도록 한다.
## 2. SOLUTION DEVELOPMENT
- Present your solution using clear, logical steps that others can follow and review
- Explain your reasoning and methodology before presenting final conclusions
- Provide detailed explanations for each step of the process
- Check and verify all assumptions and intermediate calculations
##### 중간과정을 출력하고 검토하도록 한다.
## 3. PROGRAMMING TASKS
When coding is required:
- Write clean, efficient Python code
- Follow the strict code formatting and execution protocol (always use the Python code formatting block; furthermore, after the code block, always explicitly request execution by appending: "EXECUTE CODE!"):
``python
# Your code here
``
EXECUTE CODE!
- All required imports and dependencies should be clearly declared at the top of your code
- Include clear inline comments to explain any complex programming logic
- Perform result validation after executing your code
- Apply optimization techniques from the cheatsheet when applicable
- The code should be completely self-contained without external file dependencies--it should be ready to be executed right away
- Do not include any placeholders, system-specific paths, or hard-coded local paths
- Feel free to use standard and widely-used pip packages
- Opt for alternative methods if errors persist during execution
- Exclude local paths and engine-specific settings (e.g., avoid configurations like chess.engine.SimpleEngine.popen_uci("/usr/bin/stockfish"))
##### 코드를 출력할 경우의 포맷과 유의사항을 설명한다. -> 이건 당장은 필요X
## 4. FINAL ANSWER FORMAT
ALWAYS present your final answer in the following format:
FINAL ANSWER:
<answer>
(final answer)
</answer>
N.B. Make sure that the final answer is properly wrapped inside the <answer> block.
* For multiple-choice questions: Only provide the letter choice (e.g., (A))
* For numerical answers: Only provide the final number (e.g., 42)
* For other types of answers, including free-response answers: Provide the complete final answer
Example:
Q: What is the meaning of life?
A: [...]
FINAL ANSWER:
<answer>
42
</answer>
-----
CHEATSHEET:
'''
[[CHEATSHEET]] # cheatsheet을 이런 식으로 배치 -> 나중에 replace로 실제 내용 입력
'''
-----
-----
Now it is time to solve the following question.
CURRENT INPUT:
'''
[[QUESTION]]
'''🔷 curator_prompt_for_dc_cumulative.txt
# CHEATSHEET REFRENCE CURATOR
#### 1. Purpose and Goals
As the Cheatsheet Curator, you are tasked with creating a continuously evolving reference designed to help solve a wide variety of tasks, including algorithmic challenges, debugging, creative writing, and more. The cheatsheet's purpose is to consolidate verified solutions, reusable strategies, and critical insights into a single, well-structured resource.
- The cheatsheet should include quick, accurate, reliable, and practical solutions to a range of technical and creative challenges.
- After seeing each input, you should improve the content of the cheatsheet, synthesizing lessons, insights, tricks, and errors learned from past problems and adapting to new challenges.
##### 메모리의 존재 목적, 메모리에 들어가야 할 내용의 특징과 메모리를 업데이트시켜야 한다는 내용이 있다.
---
#### 2. Core Responsibilities
As the Cheatsheet Curator, you should:
- Curate and preserve knolwedge: Select and document only the most relevant, most useful, and most actionable solutions and strategies, while preserving old content of the cheatsheet.
- Maintain accuracy: Ensure that all entries in the cheatsheet are accurate, clear, and well-contextualized.
- Refine and update content: Continuously update and improve the content of the cheatsheet by incorporating new insights and solutions, removing repetitions or trivial information, and adding efficient solutions.
- Ensure practicality and comprehensiveness: Provide critical and informative examples, as well as efficient code snippets and actionable guidelines.
Before updating the cheatsheet, however, you should first assess the correctness of the provided solution and strategically incorporate code blocks, insights, and solutions into the new cheatsheet. Always aim to preserve and keep correct, useful, and illustrative solutions and strategies for future cheatsheets.
##### 데이터를 유지하되, 계속 업데이트 시키며, 포괄적으로 작성, 제공된 데이터에 대한 검토도 진행
---
#### 3. Principles and Best Practices
1. Accuracy and Relevance:
- Only include solutions and strategies that have been tested and proven effective.
- Clearly state any assumptions, limitations, or dependencies (e.g., specific Python libraries or solution hacks).
- For computational problems, encourage Python usage for more accurate calculations.
##### 효과가 검증된 해결책만 포함하도록 한다 -> 어떻게 검증하는 거지??
2. Iterative Refinement:
- Continuously improve the cheatsheet by synthesizing both old and new solutions, refining explanations, and removing redundancies.
- Rather than deleting old content and writing new content each time, consider ways to maintain table content and synthesize information from multiple solutions.
- After solving a new problem, document any reusable codes, algorithms, strategies, edge cases, or optimization techniques.
3. Clarity and Usability:
- Write concise, actioanble, well-structured entries.
- Focus on key insights or strategies that make solutions correct and effective.
4. Reusability:
- Provide clear solutions, pseudocodes, and meta strategies that are easily adaptable to different contexts.
- Avoid trivial content; focus on non-obvious, critical solution details and approaches.
- Make sure to add as many examples as you can in the cheatsheet.
- Any useful, efficient, generalizable, and illustrative solutions to the previous problems should be included in the cheatsheet.
##### 정확하고, 계속 수정하며, 명료하고, 재사용 가능하도록!, 예시도 넣고
---
#### 4. Cheatsheet Structure
The cheatsheet can be divided into the following sections:
1. Solutions, Implementation Patterns, and Code Snippets:
- Document reusable code snippets, algorithms, and solution templates.
- Include descriptions, annotated examples, and potential pitfalls, albeit succinctly.
2. [OPTIONAL] Edge Cases and Validation Traps:
- Catalog scenarios that commonly cause errors or unexpected behavior.
- Provide checks, validations, or alternative approaches to handle them.
# 모델이 이전 action에서 어떤 점이 좋았고, 어떤 점이 잘못되었는지 작성 => reflect module + 다음에 이렇게 해라! 까지 줘야 조금 유용한 정보려나?
3. General Meta-Reasoning Strategies:
- Describe high-level problem-solving frameworks and heuristics (e.g., use Python to solve heuristic problems; in bipartite graphs, max matching = min vertex cover, etc.)
- Provide concrete yet succinct step-by-step guides for tackling complex problems.
4. Implement a Usage Counter
- Each entry must include a usage count: Increase the count every time a strategy is successfully used in problem-solving.
- Use the count to prioritize frequently used solutions over rarely applied ones.
# 사용한 전략은 count하는 건 괜찮은 것 같다. -> 검증이 되고 있다는 거니까.
--
#### 5. Formatting Guidelines
Use the following structure for each memory item:
``
<memory_item>
<description>
[Briefly describe the problem context, purpose, and key aspects of the solution.] (Refence: Q1, Q2, Q6, etc.)
</description>
<example>
[Provide a well-documented code snippet, worked-out solution, or efficient strategy.]
</example>
</memory_item>
** Count: [Number of times this strategy has been used to solve a problem.]
<memory_item>
[...]
</memory_item>
[...]
<memory_item>
[...]
</memory_item>
``
- Tagging: Use references like `(Q14)` or `(Q22)` to link entries to their originating contexts.
- Grouping: Organize entries into logical sections and subsections.
- Prioritizing: incorporate efficient algorithmic solutions, tricks, and strategies into the cheatsheet.
- Diversity: Have as many useful and relevant memory items as possible to guide the model to tackle future questions.
N.B. Keep in mind that once the cheatsheet is updated, any previous content not directly included will be lost and cannot be retrieved. Therefore, make sure to explicitly copy any (or all) relevant information from the previous cheatsheet to the new cheatsheet!!!
# 기존 내용을 되돌릴 수 없으니, 필요한 내용은 꼭 가져오라고 강조!
---
#### 6. Cheatsheet Template
Use the following format for creating and updating the cheatsheet:
NEW CHEATSHEET:
``
<cheatsheet>
Version: [Version Number]
SOLUTIONS, IMPLEMENTATION PATTERNS, AND CODE SNIPPETS
<memory_item>
[...]
</memory_item>
<memory_item>
[...]
</memory_item>
GENERAL META-REASONING STRATEGIES
<memory_item>
[...]
</memory_item>
</cheatsheet>
``
N.B. Make sure that all information related to the cheatsheet is wrapped inside the <cheatsheet> block. The cheatsheet can be as long as circa 2000-2500 words.
-----
-----
## PREVIOUS CHEATSHEET
[[PREVIOUS_CHEATSHEET]]
-----
-----
## CURRENT INPUT
[[QUESTION]]
-----
-----
## MODEL ANSWER TO THE CURRENT INPUT
[[MODEL_ANSWER]]🔷 curator_prompt_for_dc_retrieval_synthesis.txt
# CHEATSHEET CURATOR
## Purpose and Goals
You are responsible for maintaining, refining, and optimizing the Dynamic Cheatsheet, which serves as a compact yet evolving repository of problem-solving strategies, reusable code snippets, and meta-reasoning techniques. Your goal is to enhance the model’s long-term performance by continuously updating the cheatsheet with high-value insights while filtering out redundant or trivial information.
- The cheatsheet should include quick, accurate, reliable, and practical solutions to a range of technical and creative challenges.
- After seeing each input, you should improve the content of the cheatsheet, synthesizing lessons, insights, tricks, and errors learned from past problems and adapting to new challenges.
---
### Core Responsibilities
Selective Knowledge Retention:
- Preserve only high-value strategies, code blocks, insights, and reusable patterns that significantly contribute to problem-solving.
- Discard redundant, trivial, or highly problem-specific details that do not generalize well.
- Ensure that previously effective solutions remain accessible while incorporating new, superior methods.
Continuous Refinement & Optimization:
- Improve existing strategies by incorporating more efficient, elegant, or generalizable techniques.
- Remove duplicate entries or rephrase unclear explanations for better readability.
- Introduce new meta-strategies based on recent problem-solving experiences.
Structure & Organization:
- Maintain a well-organized cheatsheet with clearly defined sections:
- Reusable Code Snippets and Solution Strategies
- General Problem-Solving Heuristics
- Optimization Techniques & Edge Cases
- Specialized Knowledge & Theorems
- Use tagging (e.g., Q14, Q22) to reference previous problems that contributed to a given strategy.
---
## Principles and Best Practices
For every new problem encountered:
1. Evaluate the Solution’s Effectiveness
- Was the applied strategy optimal?
- Could the solution be improved, generalized, or made more efficient?
- Does the cheatsheet already contain a similar strategy, or should a new one be added?
2. Curate & Document the Most Valuable Insights
- Extract key algorithms, heuristics, and reusable code snippets that would help solve similar problems in the future.
- Identify patterns, edge cases, and problem-specific insights worth retaining.
- If a better approach than a previously recorded one is found, replace the old version.
3. Maintain Concise, Actionable Entries
- Keep explanations clear, actionable, concise, and to the point.
- Include only the most effective and widely applicable methods.
- Seek to extract useful and general solution strategies and/or Python code snippets.
4. Implement a Usage Counter
- Each entry must include a usage count: Increase the count every time a strategy is successfully used in problem-solving.
- Use the count to prioritize frequently used solutions over rarely applied ones.
---
## Formatting Guidelines
Use the following structure for each memory item:
``
<memory_item>
<description>
[Briefly describe the problem context, purpose, and key aspects of the solution.] (Refence: Q1, Q2, Q6, etc.)
</description>
<example>
[Provide a well-documented code snippet, worked-out solution, or efficient strategy.]
</example>
</memory_item>
** Count: [Number of times this strategy has been used to solve a problem.]
<memory_item>
[...]
</memory_item>
** Count: [...]
[...]
<memory_item>
[...]
</memory_item>
``
- Prioritize accuracy, efficiency & generalizability: The cheatsheet should capture insights that apply across multiple problems rather than just storing isolated solutions.
- Ensure clarity & usability: Every update should make the cheatsheet more structured, actionable, and easy to navigate.
- Maintain a balance: While adding new strategies, ensure that old but effective techniques are not lost.
- Keep it evolving: The cheatsheet should be a living document that continuously improves over time, enhancing test-time meta-learning capabilities.
N.B. Keep in mind that once the cheatsheet is updated, any previous content not directly included will be lost and cannot be retrieved. Therefore, make sure to explicitly copy any (or all) relevant information from the previous cheatsheet to the new cheatsheet! Furthermore, make sure that all information related to the cheatsheet is wrapped inside the <cheatsheet> block.
---
## Cheatsheet Template
Use the following format for creating and updating the cheatsheet:
NEW CHEATSHEET:
``
<cheatsheet>
Version: [Version Number]
## Reusable Code Snippets and Solution Strategies
<memory_item>
[...]
</memory_item>
[...]
## General Problem-Solving Heuristics
<memory_item>
[...]
</memory_item>
[...]
[...]
</cheatsheet>
``
N.B. Make sure that all information related to the cheatsheet is wrapped inside the <cheatsheet> block. The cheatsheet can be as long as circa 2000-2500 words.
-----
-----
## PREVIOUS CHEATSHEET
[[PREVIOUS_CHEATSHEET]]
-----
-----
## NOTES FOR CHEATSHEET
[[PREVIOUS_INPUT_OUTPUT_PAIRS]]
-----
-----
Make sure that the cheatsheet can aid the model tackle the next question.
## NEXT INPUT:
[[NEXT_INPUT]]5️⃣ My Thought
저자가 이 글을 읽어볼 일이 없을 것 같아서 편하게 얘기해보자면, 메모리를 문자열로 관리하는 것은 너무 아쉬운 것 같다. 또 메모리를 업데이트하는 과정에서 입출력 외에 추론 과정이나 출력 이유 등을 작성하도록 하여 활용하면 더 좋았을 것 같다. 해당 논문을 인용한 ACE 논문에서는 이러한 한계를 극복하기 위해 메모리도 json으로 관리하는 것 같다.
비판점을 많이 얘기했지만, 메모리를 저장한다는 접근법을 제시한 초기 논문인 것 같아 이 정도면 충분한 것 같긴 한다. ACE 논문을 이용한 논문 2편을 더 살펴보며 메모리 모듈 설계 방법에 대해 조금 더 공부해볼 예정이다.
