🎞️ T*: Re-thinking Temporal Search for Long-Form Video Understanding
🔗 논문: https://arxiv.org/abs/2504.02259
💻 GitHub : T*: Re-thinking Temporal Search for Long-Form Video Understanding
🧐 학회: CVPR 2025
✏️ 논문 정리
1. 이 논문을 읽는 이유가 무엇인가요?
⇒ 예전에 주제 탐색을 위해 다양한 멀티모달 관련 논문을 읽어보았다. 자율주행차, Avatar, GUI 등 흥미로운 주제가 많았는데, 그 중에서도 이 논문의 아이디어가 가장 눈에 띄어 읽게 되었다.
2. 논문 제목의 의미는 무엇인가요?
⇒ Re-thinking한다는 것은 다시 생각한다는 의미인 것 같다. 그래서 현재 긴 비디오를 이해하기 위한 Temporal Search 방식에 대해 고민하고 새로운 프레임워크인 T*를 제안한다는 의미이다.
3. 논문의 등장배경은 무엇인가요?
⇒ 논문은 긴 비디오를 효율적을 잘 이해하는 것을 목표로 하고 있다. 기존의 Temporal Search 방식보다 더 적은 계산비용으로 효율적으로 필요한 프레임을 찾아 비디오 내용에 대한 질문에 잘 대답하는 것을 목표로 한다.
4. 논문을 1~2줄로 요약하세요
⇒ 논문은 Temporal Search 능력을 평가할 수 있는 LV-HAYSTRACK 벤치마크를 제작하였다. 해당 벤치마크는 대부분이 1인칭 시점의 데이터라는 특징이 있다. 그리고 비디오 이해를 위한 Temporal Search 능력을 향상시키기 위해 비디오 프레임을 넓게 펼쳐서 검색을 수행하는 T* 프레임워크를 제안한다.
0️⃣ Abstract
🔷 Long Form Video가 뭐죠? 긴가요??
-
비디오 데이터를 구분하는 기준으로 여러가지 있겠지만, 비디오의 길이에 따라 종류를 구분할 수 있다.
-
논문의 Table 4를 보면 LongVideoBench에서 15~60분 길이의 비디오를 Long form으로 구분한 것을 확인할 수 있다.
🔷 논문은 Long form Video에서 어떤 문제에 집중하였나요?
🔻 Long Video Haystack Problem 정의
-
Haystrack은 건초더미라는 뜻으로 바늘찾기라는 관용구와 함께 쓰이며, 복잡한 곳에서 찾기 어려운 목표를 찾는 일로 생각하면 된다.
-
논문의 저자는 수만 프레임의 긴 비디오에서 원하는 프레임을 찾는 것을 Long Video Haystack Problem으로 정의하였다.
-
이 논문은 Long Video Haystack Problem을 해결하기 위해 작성된 논문이다.
🔶 용어 정리
Temporal Search : 긴 비디오 데이터에서 질문이나 작업과 관련된 프레임을 찾는 과정
🔷 논문의 핵심 2가지
🔻 LV-HAYSTACK Benchmark
-
모델의 Temporal Search 능력을 훈련하고 평가할 수 있는 벤치마크이다.
-
총 480시간 길이의 비디오로, 15,092개의 사람이 직접 단 주석이 있다.
🔻 Temporal Search Framework
-
모델의 Temporal Search 능력을 향상시키기 위해 논문의 저자가 제안하는 프레임워크이다.
-
시간적 탐색을 공간적 탐색으로 바꿔서 더 효율적으로 탐색할 수 있도록 한다.
-
핵심 기술로 visual localization과 adaptive zooming-in mechanism이 있다.
🔷 논문의 성과
-
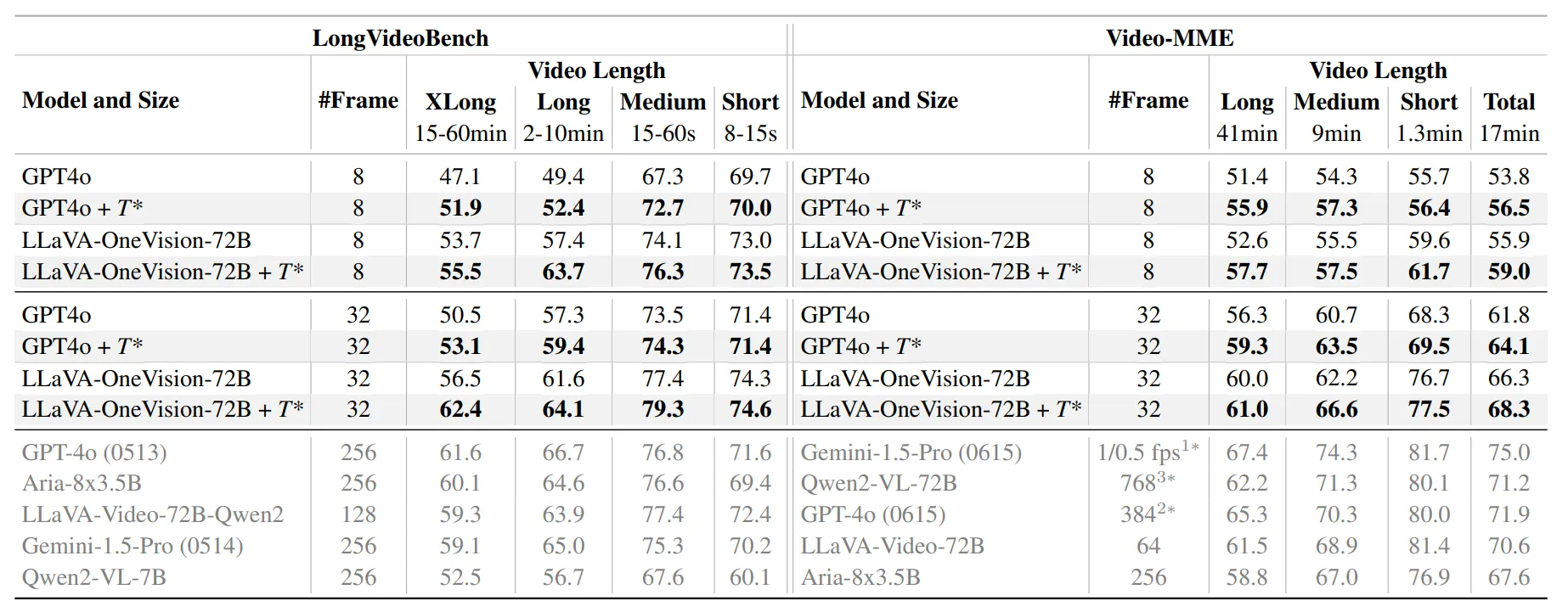
실험 결과 논문에서 제시한 Temporal Search Framework 를 적용하였을 경우 각 모델의 성능 향상은 아래와 같다.
-
GPT-4o : 50.5% → 53.1%
-
LLaVA-OneVision-OV-72B : 56.5% → 62.4%
-
1️⃣ Introduction
🔷 긴 비디오 데이터의 등장과 기술의 발전
🔻 긴 비디오의 문제
-
비디오 데이터는 초 단위에서 시간 단위까지 다양한다.
-
보통 VLM(Vision Language Model)은 이미지 1프레임을 처리하는데 576 토큰을 사용한다.
-
긴 비디오는 수천에서 수만 프레임을 처리해야 하므로 많은 계산량을 요구한다.
🔻 이에 대응하는 기술들
-
Temporal Localization : 긴 비디오에서 비디오 이해를 위해 필요한 구간을 찾는 것, [시작 시점, 끝 시점]

📃 참조 논문 : QVHIGHLIGHTS: Detecting Moments and Highlights in Videos via Natural Language Queries
-
Temporal Seach : 긴 비디오에서 비디오 이해를 위해 필요한 프레임을 찾는 것

📃 참조 논문 : NEEDLE IN A VIDEO HAYSTACK: A SCALABLE SYNTHETIC EVALUATOR FOR VIDEO MLLMS
🔷 Temporal Search를 평가하기 위한 벤치마크, LV-HAYSTACK
🔻 LV-HAYSTACK의 특징
-
LV-HAYSTACK는 인위적이지 않고, 현실세계 시나리오를 중심의 비디오를 다룬다.
-
LV-HAYSTACK는 Ego4D 데이터와 LongVideoBench 데이터를 활용하여 구축되었다.
-
데이터 속 비디오에 대한 질문은 답변과 핵심 프레임을 반드시 가진다.
🔶 비디오 종류 정리
-
Egocentric Video : 1인칭 시점 비디오

📃 참조 논문 : Ego4D: Around the World in 3,000 Hours of Egocentric Video
- Allocentic Video : 3인칭 시점 Video
- LongVideoBench의 데이터가 이에 해당한다.
🔷 논문의 핵심 아이디어
🔻 아이디어의 시작
-
논문의 저자는 앞서 제작한 LV-HAYSTACK으로 VLM 모델의 Temporal Search 능력을 평가하였다.
-
이후 Visual Search 와 같은 기술에 영감을 받아 를 개발하게 되었다.
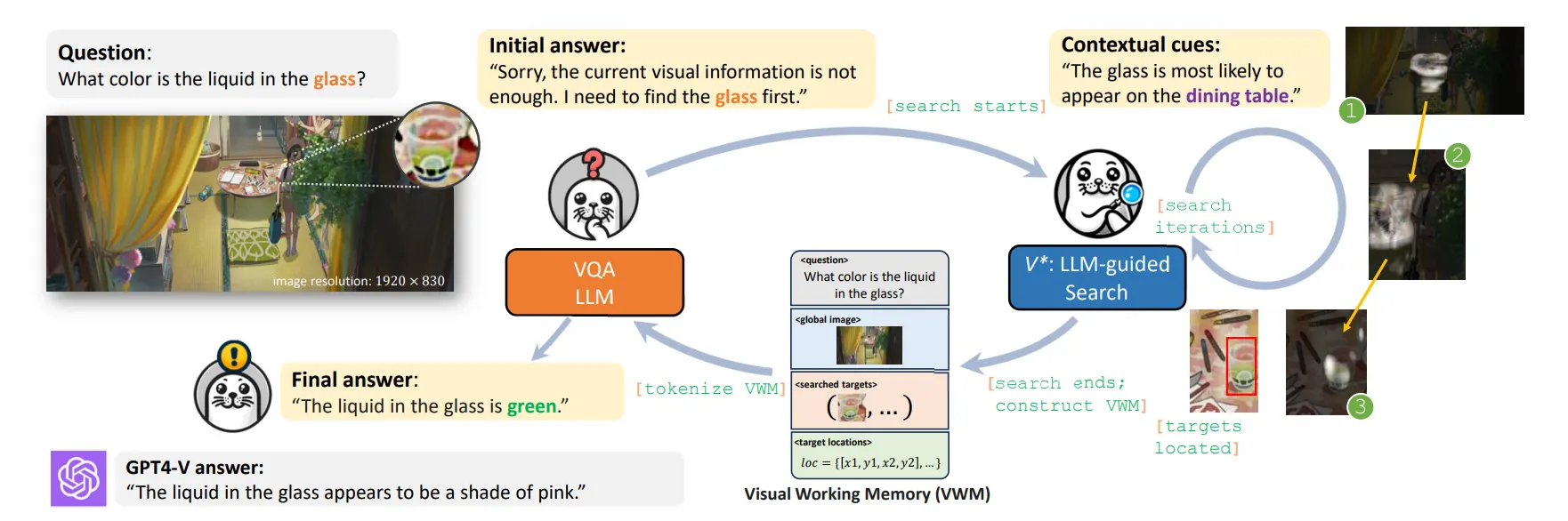
📃 참조 논문 : : Guided Visual Search as a Core Mechanism in Multimodal LLMs
-
는 Temporal Search 방식에 Spatial Dimension을 확장한 탐색 방식이다.
🔻 의 메커니즘
- 이 부분은 이후 내용에서 자세히 다뤄보겠다.
🔻 를 통한 성능 향상
-
를 통해 VLM이 Temporal Search를 더 효율적으로 할 수 있게 되었다.
-
궁극적으로 효율적인 Long form Video 이해를 달성하였다.
2️⃣ Temporal Search in Video Understanding
2장에서는 Temporal Search에 대해 정의한 후 LV-HAYSTACK Benchmark에 대해 설명한다.
🔷 1. Temporal Search
🔻 1-1 Temporal Search란?
-
Temporal Search는 VLM이 ⭐긴 비디오를 이해하기 위해 필요한 프레임을 찾는 것⭐이다.
-
VLM이 질문을 받았을 때, 답변하기 위해 필요한 비디오 프레임을 찾는 과정이다.
🔻 1-2 Temporal Search의 수학적 표현
-
Video : → 개의 Frame으로 구성
-
Question :
-
Keyframes :
-
는 에 대한 답을 가지고 있어야 한다.
-
는 필요한 frame만 가지고 있는 가장 작은 집합이어야 한다.
-
🔷2. LV-HAYSTACK Benchmark
🔻 2-1. LV-HAYSTACK 목표
- LV-HAYSTACK는 VLM의 Temporal Search 능력을 평가하기 위해 제작되었다.
🔻 2-2. LV-HAYSTACK의 데이터 구조
-
각 데이터는 아래의 튜플 형식의 구조로 이루어져 있다.
-
🔻 2-3. LV-HAYSTACK 데이터 구성
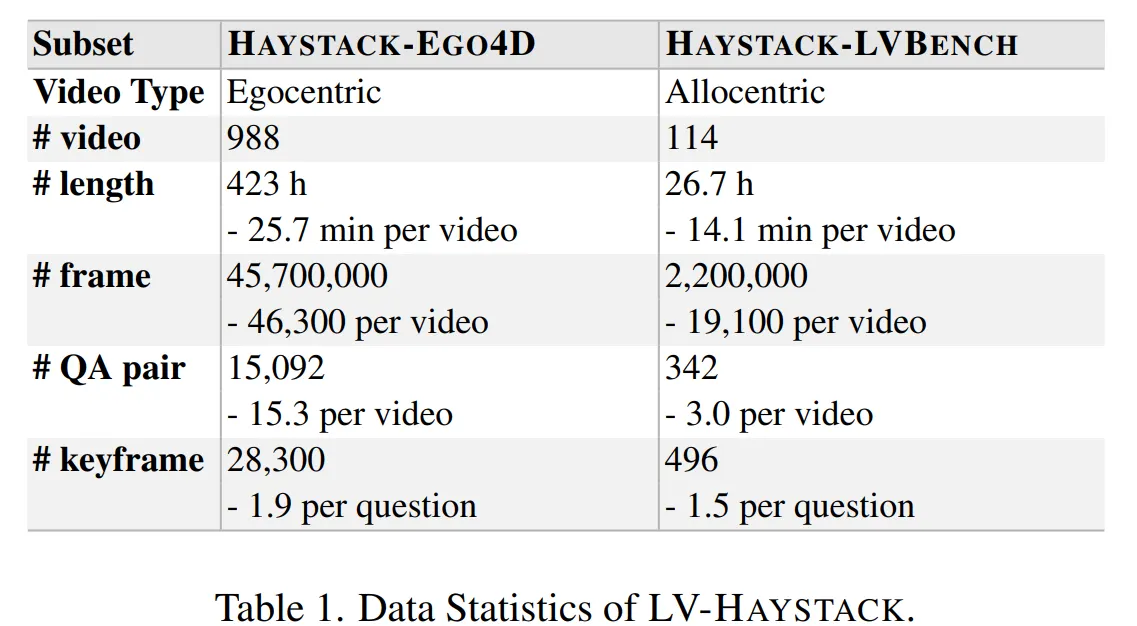
- LV-HAYSTACK는 Egocentric Video와 Allocentric Video로 이루어져 있다.
-
HAYSTACK-EGO4D
-
Ego4D NLQ의 validation 데이터를 통해 구축되었다.
-
각 Video는 평균 8.3분 길이이며, 물건을 찾거나, 쇼핑을 하는 등 다양한 시나리오로 이루어져 있다.
-
-
HAYSTACK-LVBENCH
- LongVideoBench의 기존 annotation을 수정하여 구축되었다.
🤔 LV-HAYSTACK 데이터가 적용될 수 있는 범위는?
LV-HAYSTACK의 데이터 양을 보면 HAYSTACK-EGO4D가 압도적으로 많은 것을 알 수 있다. Video 시간으로 계산해보니 94%의 데이터가 Egocentric한 Video이다. 그렇다면 HAYSTACK-EGO4D 데이터셋 스마트 안경처럼 1인칭 시점에서 녹화한 비디오를 처리하는데 적합하지만, 자율주행차, CCTV와 같은 3인칭 시점의 Task에는 조금 더 보완이 필요할 것 같다는 생각이 든다.
🔷 3. Evaluation Metric for Search Utility
🔻 3-1. Search Utility Metric의 평가 목표
- Temporal Search 알고리즘이 얼마나 정확한 정보를 잘 찾아내는지 평가한다.
🔻 3-2. 평가 방식
- LV-HAYSTACK는 정답 프레임과 모델이 예측한 프레임을 2가지 방식으로 비교한다.
-
Temporal Similarity : 모델이 예측한 프레임과 정답 프레임 간의 시간적 차이를 비교한다.
- 두 프레임 간의 시간적 차이를 임계점을 설정한 후 이진 방식으로 평가한다.
-
Visual Similarity : 모델이 예측한 프레임과 정답 프레임 간의 시각적 유사성을 비교한다.
-
SSIM(Structural Similarity Index Measure) 방식으로 비교한다.
-
SSIM은 이미지의 밝기, 대비, 구조를 고려하여 이미지를 비교하는 방식으로 0~1의 값을 가진다.
-
🔻 3-3. 실제 평가 Metric
-
실제 모델 추론 시 정답 프레임 집합과 모델이 예측한 프레임 집합, 즉 집합 간 비교가 이루어진다.
-
집합 간 비교 시 Precision 방식과 Recall 방식을 활용하여 score를 구한다.
🔶 Precision(정밀도)
-
모델의 예측이 정답과 얼마나 유사한지, 검색 관련성을 평가한다.
-
모델이 예측한 Key Frame
-
정답 Key Frame
-
모델이 예측한 Key Frame의 수
-
예측 프레임과 정답 프레임 사이의 유사도 측정, 앞서 설명한 Temporal Similarlity 혹은 Visual Similarity를 사용한다.
🔶 Recall(재현율)
- 모델의 예측이 얼마나 정답을 잘 포함하는지, 검색 포괄성을 평가한다.
🔶 score
- 정밀도와 재현율의 균형을 평가한다.
🔷 4. Evaluation Metrics for Search Efficiency
🔻 4-1. Search Efficiency Metric의 평가 목표
- Temporal Search 알고리즘이 얼마나 빠르고 적은 연산량으로 작동하는지 평가한다.
🔻 4-2. 평가 Metric
-
Frame Cost : VLM이 얼마나 적은 Frame을 사용하여 프레임을 찾는지 평가한다..
-
FLOPs : VLM이 얼마나 적은 계산으로 Frame을 찾는지 평갛나다.
-
Latency : VLM이 얼마나 빠르게 Frame을 찾는지 평가한다.
3️⃣ : Efficient Temporal Search
3장에서는 의 작동 방식에 대해 설명한다.
🔷 1. 의 목표와 프로세스
🔻 1-1. 의 목표
- 는 VLM의 Temporal Search 능력 향상을 목표로 한다.
🔻 1-2. 의 프로세스
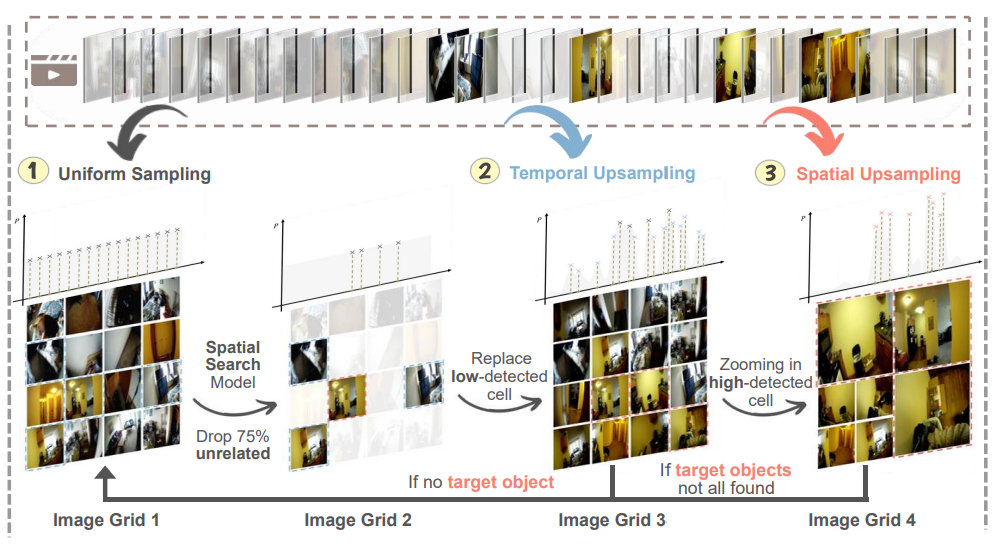
-
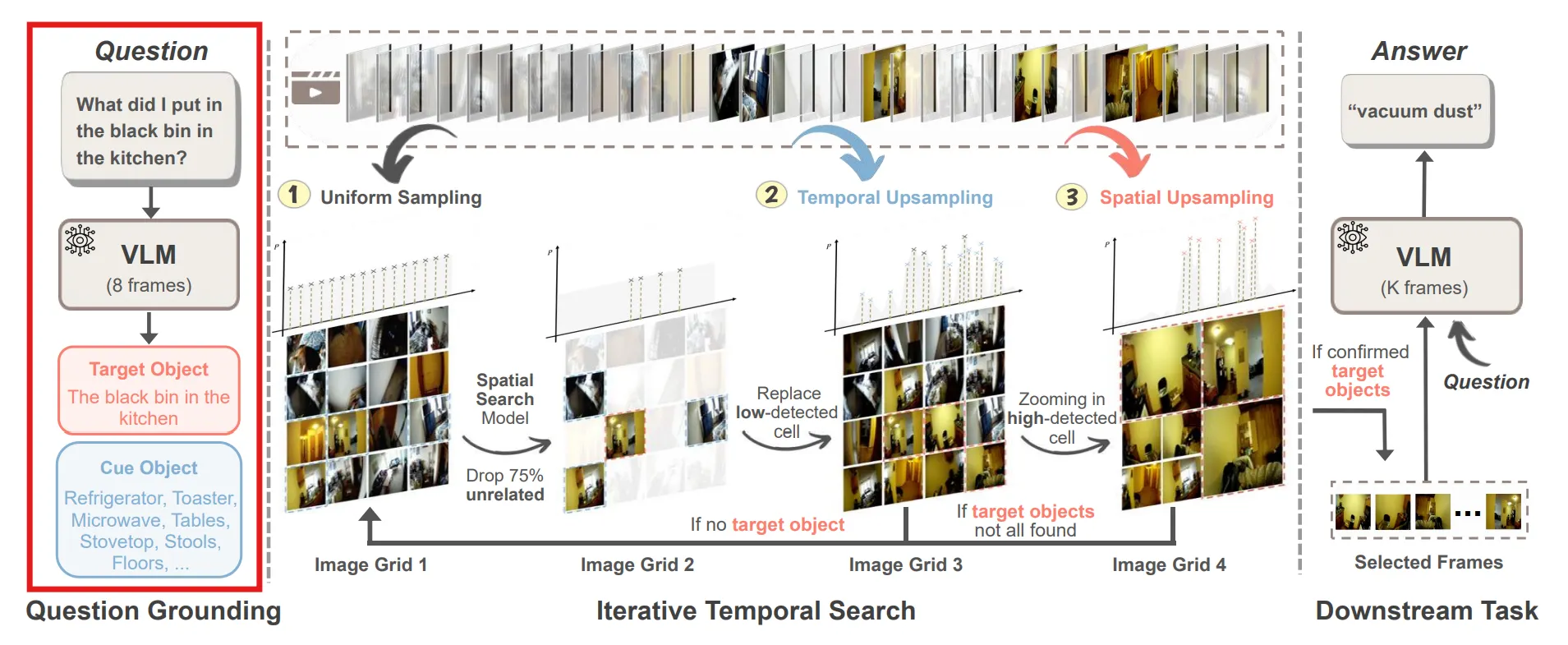
Question Grounding : Question에 대한 Answer를 얻기 위해 Video에서 Target Object와 Cue Object를 구한다.
-
Iterative Temporal Search : Video의 프레임을 넓게 펼친 후 선정된 Target Object가 있는 프레임을 찾는다.
-
Downstream Task Completion : 선정된 프레임을 통해 VLM이 Question에 대한 Answer를 구한다.
🔷 2. Question Grounding
-
Question Grounding에서는 VLM을 이용하여 Question과 관련된 목표 Object와 단서 Object를 선정한다.
-
: 일정한 간격으로 수집된 개의 프레임
-
: 질문
-
Target Object : 질문에 대한 답을 구하기 위해 직접적으로 관련된 대상
-
Cue Object : 질문과 관련된 대상
🔷 3. Iterative Temporal Search
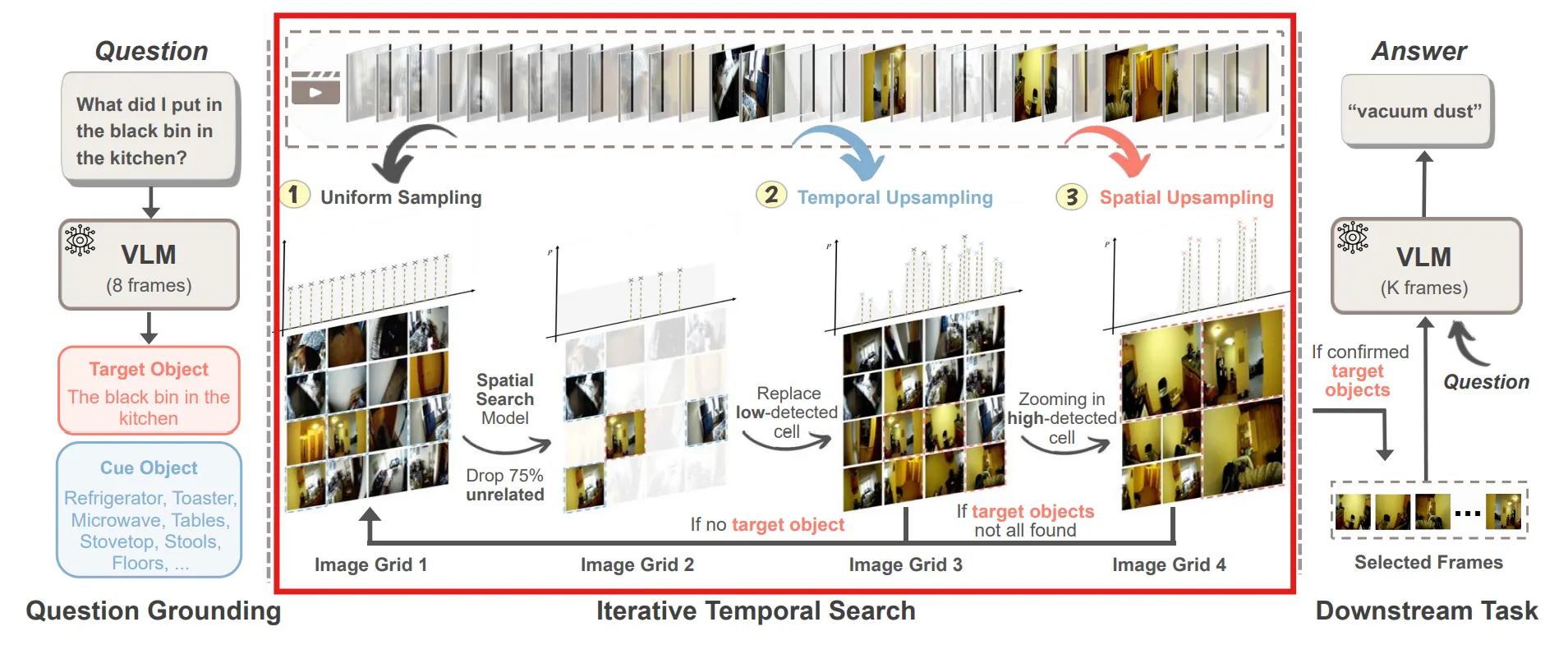
- Iterative Temporal Search에서는 Target Object를 모두 찾거나, 지정한 탐색 자원을 넘기 전까지 🔻3-1 ~ 3-3을 반복한다.
🔻 3-1. Frame Sampling and Grid Construction
-
현재 Video에서 확률분포 를 통해 샘플링한다. → 는 처음에는 균등분포로 설정되고, 이후에 계속 업데이트된다.
-
샘플링된 이미지를 Grid 안에 넣는다.
🔻 3-2. Object Detection and Scoring
-
사전 학습된 Object Detection 모델을 사용하여 Grid 속에서 Target Object와 Cue Object를 찾는다.
-
각 탐지된 프레임은 신뢰도와 함께 구한다.
-
탐지된 프레임은 Key Frame으로 저장되고, 해당 프레임은 이후에 탐색되지 않도록 목표 리스트에서 제거한다.
🔻 3-3. Distribution Update
-
앞서 구한 신뢰도에 가중치(Target은 1, Cue는 0.5)를 곱하여 점수 로 저장한다.
-
해당 프레임 주변에도 중요한 정보가 있을 수 있으니, ⭐주변 프레임에도 점수를 조금씩 부여⭐한다.
-
해당 점수를 통해 확률변수 를 Spline 보간법을 통해 업데이트한다.
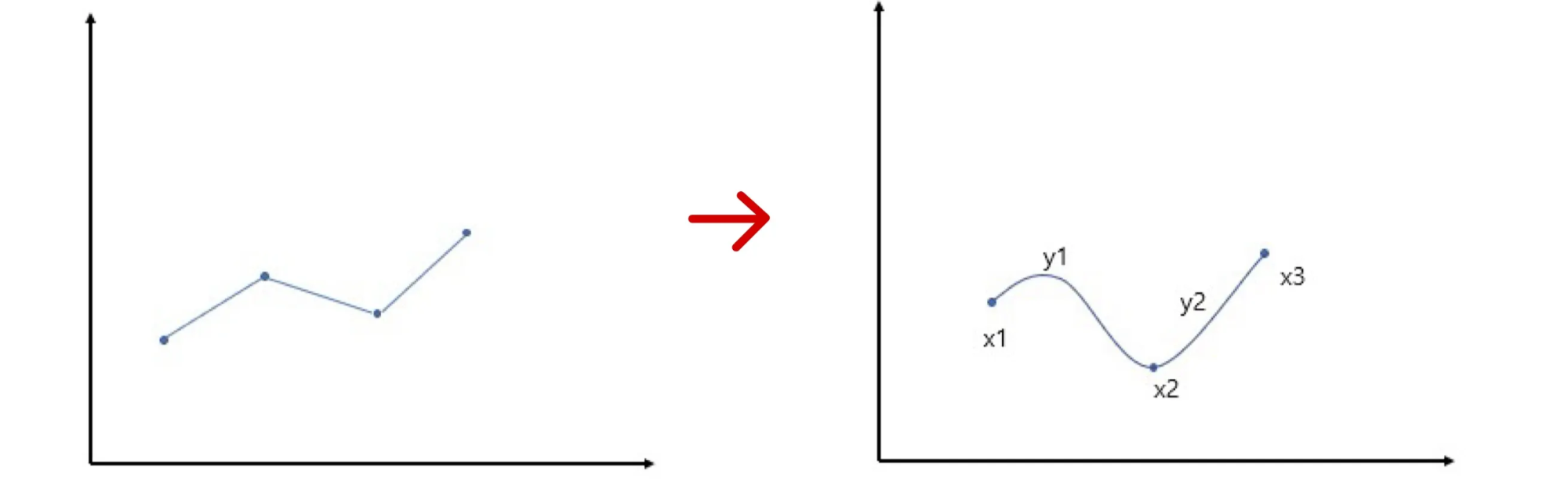
🔶 Spline Interpolation
-
우리가 구한 점수를 지나가도록 자연스럽게 분포를 생성한다고 이해하면 된다.
-
점수가 높을수록 그 부분의 확률이 올라가서 더 많이 샘플링되도록 한다.
🤔 Iterative Temporal Search의 철학
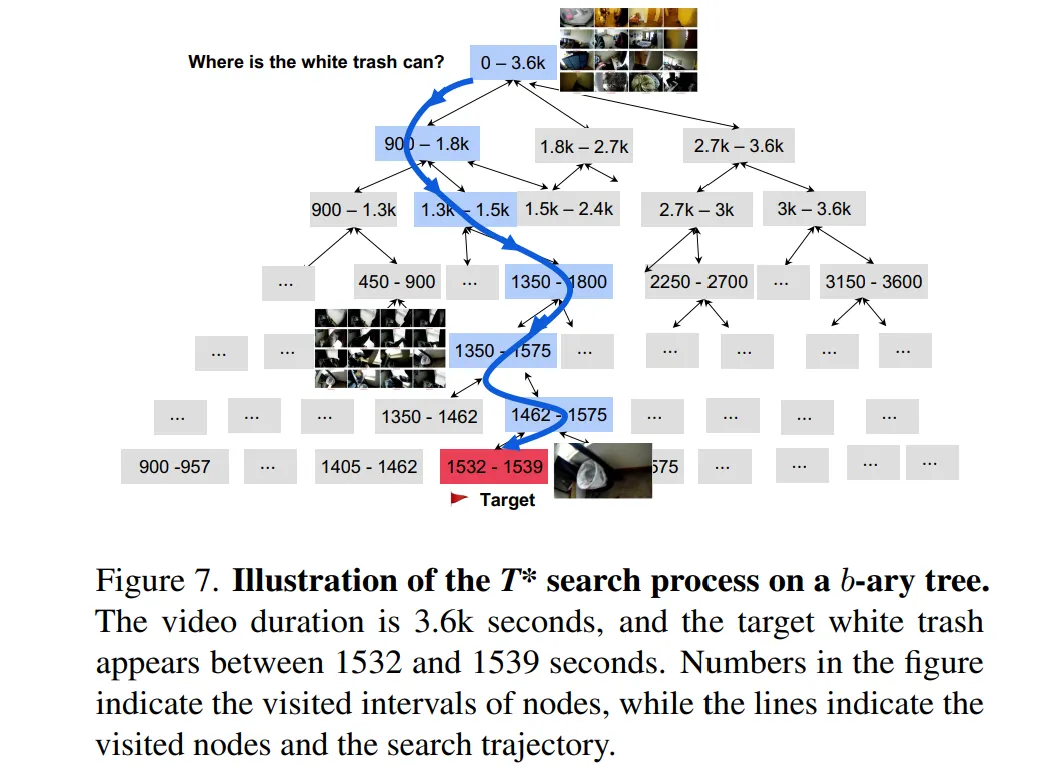
Iterative Temporal Search은 처음에 Video를 균등하게 샘플링하여 펼쳐본다. 이후 중요한 물체가 있는 프레임을 선정한다. 선정된 프레임과 시간적으로 가까운 즉 주변 시간대에도 점수를 부여하여 Temporal Localization을 확보한다. 그리고 중요한 물체가 발견된 프레임이 더 자주 샘플링되도록 확률분포를 업데이트한다. 즉 Adaptive zooming-in mechanism을 구현한다. 사람으로 생각하면 비디오를 슥 훑어본 후 중요한 부분 주변을 계속해서 관찰하는 것이라 생각할 수 있다. 이때 긴 비디오의 경우 시간 순서대로 보면 오래걸릴 수 있기 때문에 프레임을 넓게 펼쳐서 여러 시간대를 동시에 보며 빠르게 필요한 부분을 찾는다고 생각하면 될 것 같다.
🔷 4. Downstream Task Completion
-
Iterative Temporal Search를 통해 선정된 Key 프레임에서 TopK를 선정한다.
-
선정된 프레임과 해당 프레임의 시간 정보를 반환한다.
-
이후에는 이 데이터가 VLM에게 전달되어 Question에 대한 Answer를 구한다.
4️⃣ Experimental Setup
4장에서는 실험에 사용한 모델, Metric 등 설정값에 대해 설명한다.
🔷 1. Evaluations on Search Utility and Efficiency
의 ⭐검색 능력과 효율성을 평가⭐하기 위해 설계된 실험이다.
🔻 1-1. Dataset
-
실험을 진행할 때, 논문 저자가 제작한 LV-HAYSTACK를 사용하여 평가를 진행하였다.
-
HAYSTACK-EGO4D: 1인칭 시점 (Egocentric) 비디오
-
HAYSTACK-LVBENCH: 3인칭 시점 (Allocentric) 비디오
-
🔻 1-2. Models
-
Iterative Temporal Search에서 Object Detection을 위해 3가지 종류의 모델을 사용한다.
-
Attention based using VLM’ Attention matrix : VLM 내부 Attention map을 활용하여 Object(텍스트)와 프레임(이미지)의 유사도 점수로 중요한 프레임 판단
-
Detector based using object detector : 사전 학습된 Object Detection 모델 사용 ex) YOLO-world
-
Training based using custom trained model : Video QA를 잘하는 방향으로 파인튜닝된 Object Detection 모델
-
🔻 1-3. Evaluation and Metric
- 평가 방식과 Metric은 앞서 설명한 내용을 따른다.
🔻 1-4. Baselines
VLM이 질문에 답하기 위해 Video 전체를 볼 수는 없다. 그래서 일부 프레임을 선정해서 제공해야 하는데 이때 3가지 방식으로 프레임을 선정하여 서로의 성능을 비교한다.
-
Uniform Sampling : 일정 개수의 비디오 프레임을 균등분포로 샘플링한다.
-
Temporal Search Method(Video Agent) : 기존의 Temporal Search 방식을 사용한다.
-
Retrieval based method : 비디오의 모든 프레임과 질문의 벡터 유사도를 구하여 상위 K개의 프레임을 가져온다.
🔷 2. Evaluations on Downstream Tasks : Video QA
를 통해 ⭐Video를 잘 이해한다는 궁극적인 목표⭐를 잘 달성하였는지 평가한다.
🔻 1-1. Dataset
-
VLM의 QA 능력 향상은 다양한 데이터를 통해 평가되었다.
- LongVideoBench
- Video-MME
- EgoSchema
- NExT-QA
- Ego4DLongVideo QA
-
Video의 길이는 15초에서 60분까지 다양한다.
-
시간에 따른 행동 추론, 인과추론, 1인칭 이해 중심의 Task를 다룬다.
🔻 1-2. Baselines
-
평가는 다양한 Open/Closed source VLM을 활용하여 진행되었다.
-
VLM에 제공되는 프레임은 8/32로 고정하였다.
5️⃣ Experimental Results
5장에서는 의 검색 정확도, 검색 효율성, Video QA에서의 성능 향상을 평가한다.
🔷 1. Results on LV-HAYSTACK Search Performance
🔻 1-1. Search Utility
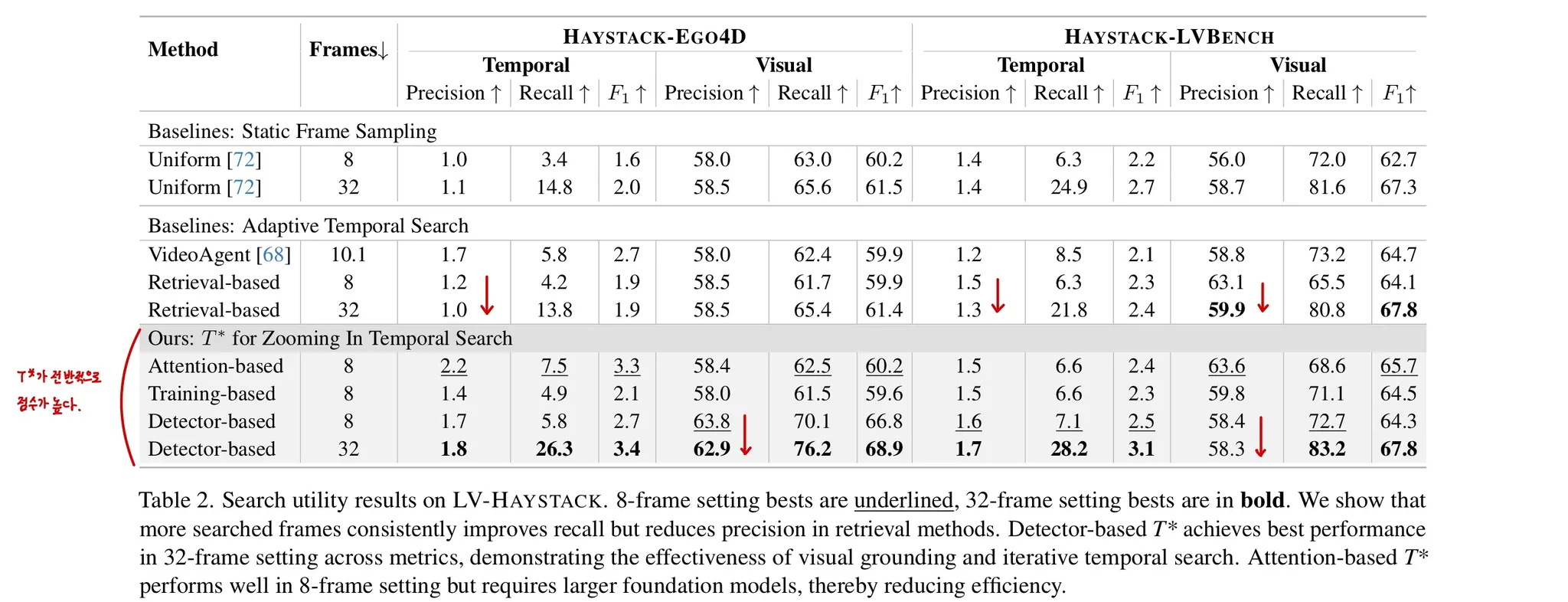
-
Table 2는 의 검색 정확성을 중심으로 결과를 살펴보면 된다.
-
8프레임만 제공하였을 경우, Attention matrix로 Object를 검색할 경우 가장 좋은 성능을 보였다.
-
제공하는 프레임 수를 늘리면 Recall은 증가하지만, Precision이 떨어지는 경향성이 관측된다.
🔻 1-2. Search Efficiency
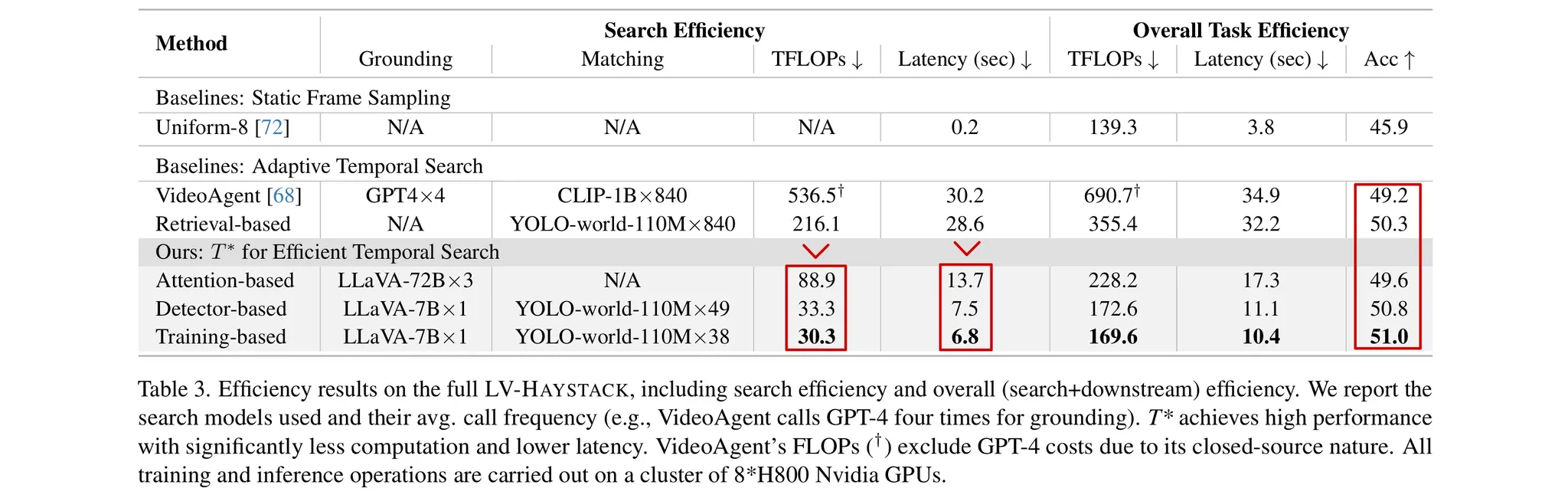
-
Table 3을 보면 를 적용하였을 경우 연산량도 줄어들고, 검색 속도도 빨라진 것을 확인할 수 있다.
-
가장 오른쪽의 Accuracy는 차이가 미미한 것을 확인할 수 있다.
-
Table 2에서 확인한 검색 정확성의 향상이 “QA에 영향을 주기에는 애매한가?”라는 생각이 들었다.
🔷 2. Results on Downstream Tasks: Long Video QA
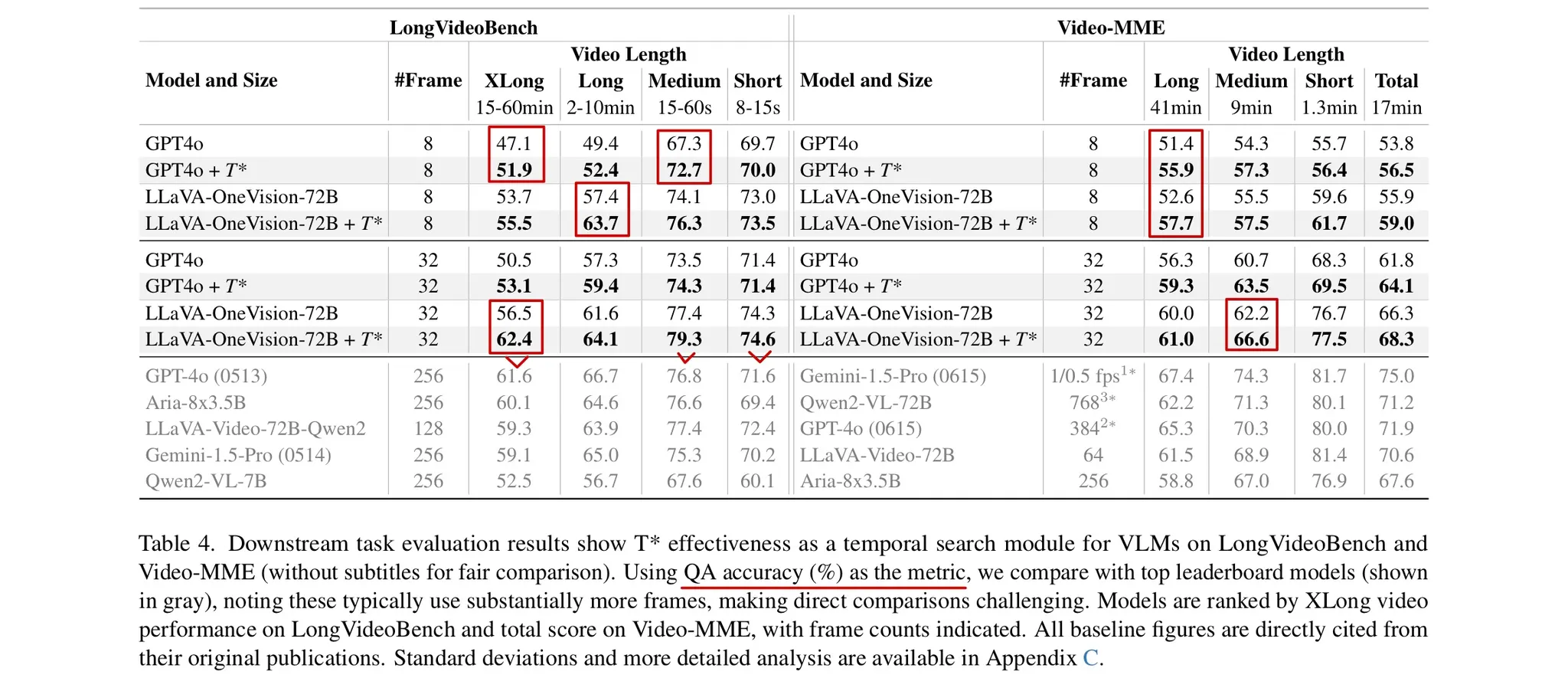
-
Table 4에서 를 적용하였을 경우 다른 비디오 데이터셋에서 QA 성능이 향상된 것을 확인할 수 있다.
-
긴 비디오일수록, 더 적은 프레임만 제공된 상황에서 성능 향상이 도드라졌다.
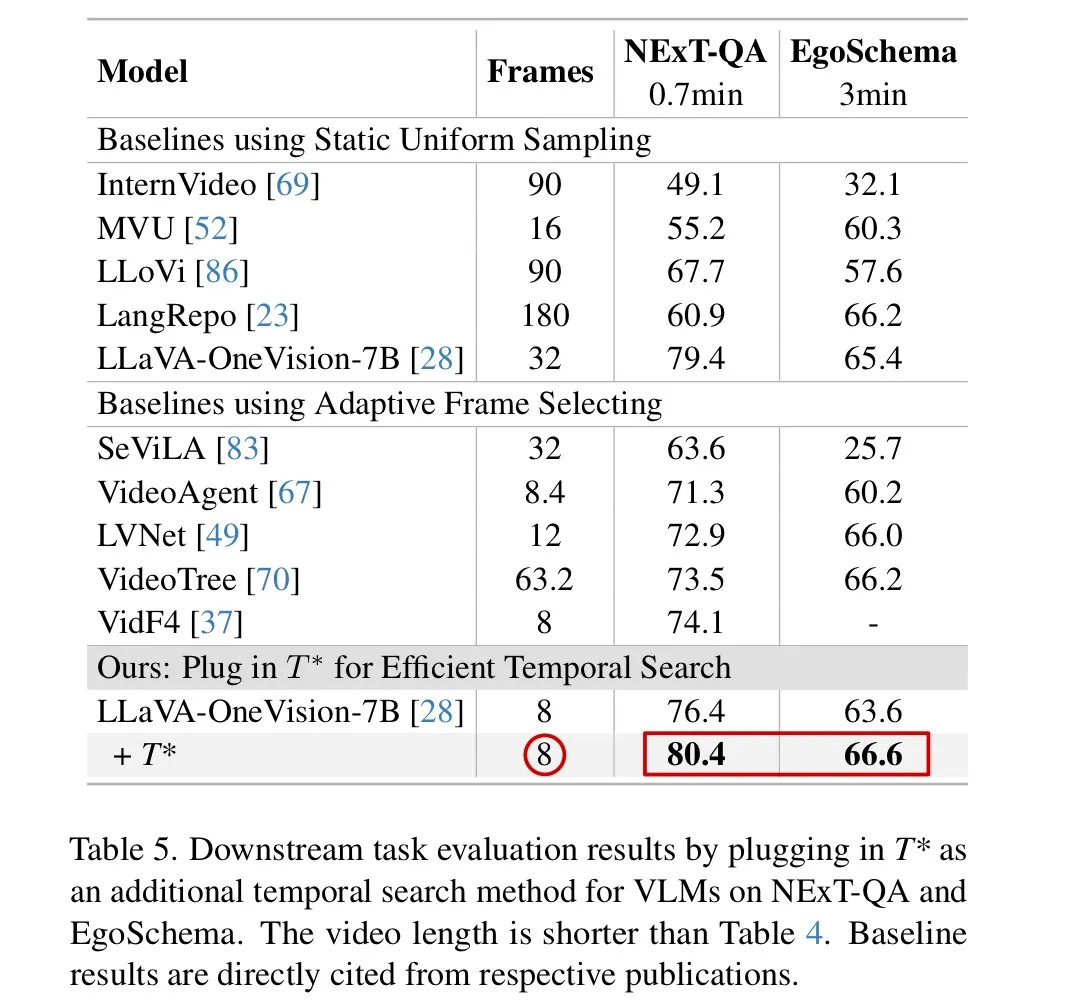
- Table 5의 NExT-QA와 EgoSchema 데이터셋에서는 를 적용하였을 경우, 가장 적은 프레임으로 가장 좋은 성능을 발휘하였다.
🔷 3. Results on Ego4D LongVideo QA
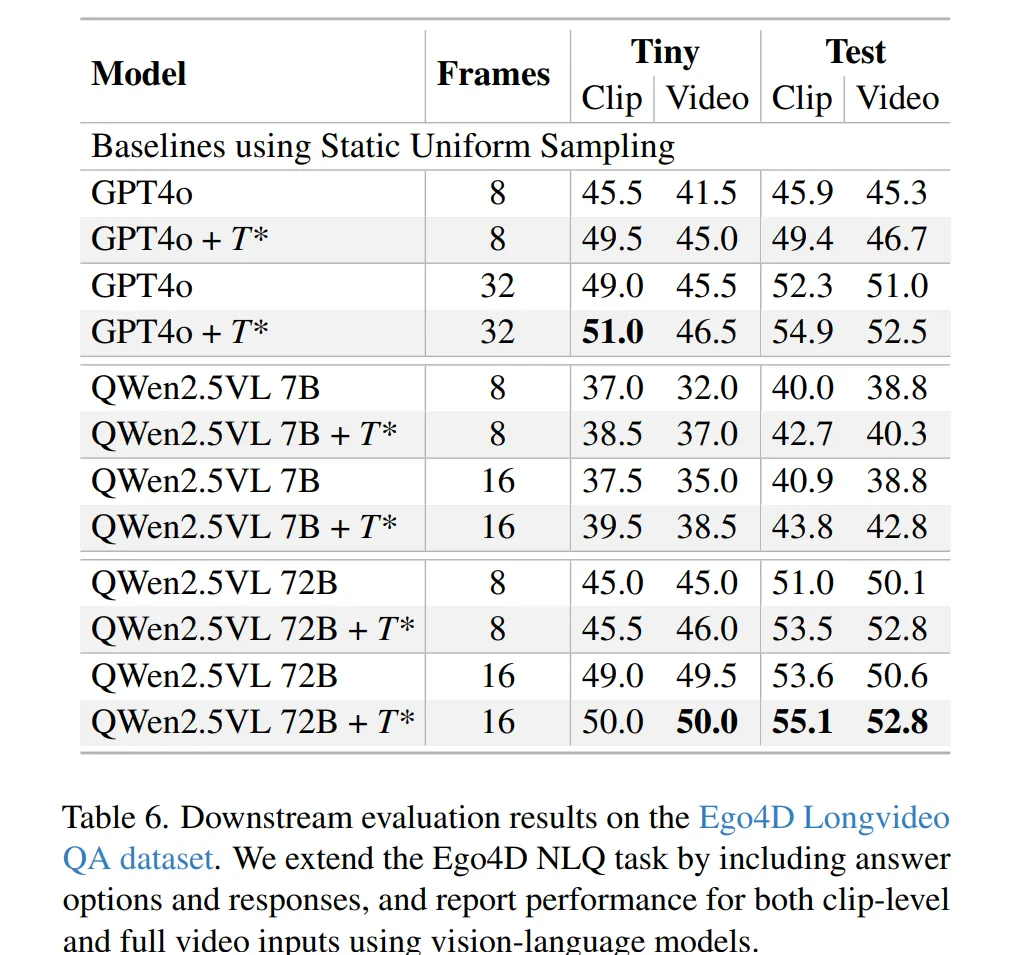
- Table 6는 질문과 관련된 비디오 일부(CLIP)를 제공한 경우와 Video 전체를 제공한 경우의 성능을 비교한다.
6️⃣ Analysis
6장에서는 을 Iteration수와 Key 프레임을 기준으로 분석합니다.
🔷 1. Sampling Iteration Dynamics
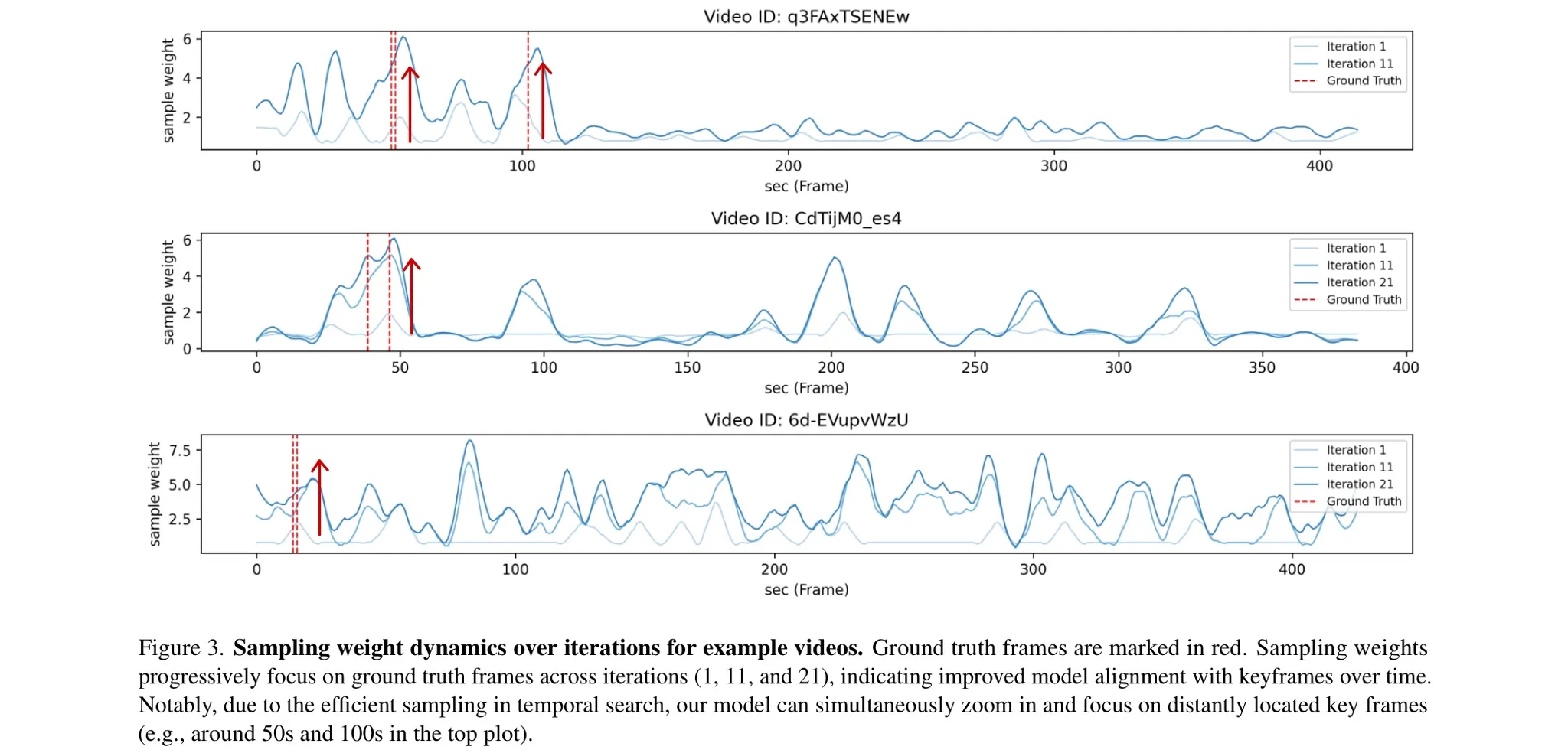
-
Figure 3을 보면 Iterative Temporal Search 과정이 반복될수록 정답 프레임을 샘플링할 확룔이 증가하고 있다.
-
첫 번째 그래프를 보면 정답이 떨어져 있는 경우에도 두 영역 모두 동시에 샘플링할 확률이 증가하는 것을 확인할 수 있다.
🔷 2. Effect of Search Frame Count on Accuracy
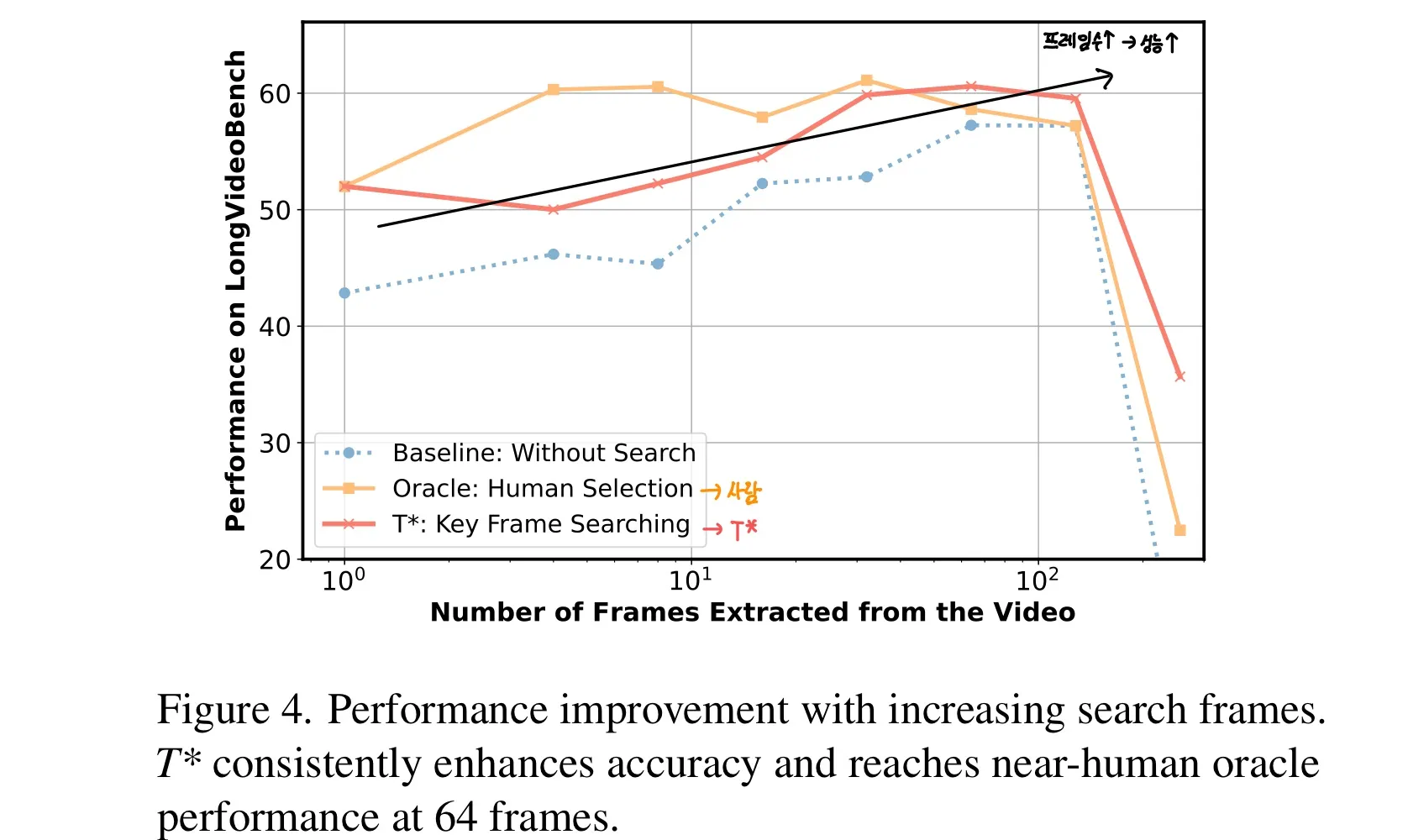
-
Figure 4를 보면 검색된 Key 프레임의 수, 즉 VLM이 질문에 답하기 위해 사용하는 프레임 수가 증가할수록 성능이 향상된다.
-
64개의 프레임을 사용할 경우 인간과 동등한 수준의 성능을 발휘함을 확인할 수 있다.
7️⃣ Conclusion
7장에서는 논문의 기여하는 바를 3가지로 요약한다.
-
Long Video Haystack problem에 대해 정의하였다.
-
Long Video Haystack problem를 평가하기 위한 벤치마크 LV-HAYSTACK를 제작하였다.
-
조금 더 효율적인 Temporal Search를 위해 lightweight temporal search 프레임워크 를 개발하였다.
8️⃣ My Thought
비디오 데이터를 다루는 논문은 처음 읽어봤는데, 논문의 발상이 신선해서 재미있게 읽었던 것 같다. 이 논문은 AI의 대모, Fei-Fei Li 교수님의 연구실에서 제출한 논문이라 더 기대하고 봤던 것 같다. 최근 Fei-Fei Li 교수님이 World 모델에 대한 영상을 봤었는데, 현재 내가 하고 있는 연구, Video Understanding, Action 등이 모두 조금씩 비슷한 것 같아 더욱 인상깊었다.
이번 논문은 Video 자체에서도 중요하지만, 다른 분야와 연결하면 더욱 큰 시너지를 발휘할 것 같다. 예를 들어 웨어러블 AI에서 스마트 안경이 내가 보고 있는 것을 계속 실시간으로 저장하고, 예전에 내가 본 것 중 뭘 찾아달라고 물어볼 때, 와 같은 경량화된 알고리즘을 사용하면, 더욱 성능이 좋은 제품을 개발할 수 있을 것 같다.
