[논문리뷰] Kandinsky: an Improved Text-to-Image Synthesis with Image Prior and Latent Diffusion
[논문리뷰]

⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜
🎨 Kandinsky: an Improved Text-to-Image Synthesis with Image Prior and Latent Diffusion
🔗 https://arxiv.org/pdf/2310.03502
⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛
Abstract
텍스트를 통한 이미지 생성은 상당한 발전을 이루고 있습니다. 이미지를 생성하는 것은 픽셀 수준에서 이루어지기도 하고, Latent space라고 불리는 잠재 수준에서 이루어지기도 합니다. 저희는 잠재수준에서 이미지를 생성하는 Kandinsky1을 제안합니다.
Kandinsky1은 Image prior 모델과 Latent diffusion 모델을 결합한 아키텍처입니다.
여기서 Image prior 모델은 CLIP 모델이 만든 텍스트 임베딩을 이미지 임베딩으로 바꾸어주는 역할을 합니다. 또 Latent diffusion 모델은 입력된 정보를 토대로 이미지를 생성해주는 모델입니다.
📕 따라서 간단한 프로세스를 정리해보면 다음과 같습니다.
- 입력된 텍스트가 CLIP 모델을 통해 텍스트 벡터로 임베딩된다.
- CLIP 모델을 통해 변경된 텍스트 벡터가 Image prior 모델을 통해 이미지 벡터로 임베딩된다.
- 변경된 이미지 임베딩을 조건으로 Latent diffusion이 조건에 맞게 이미지를 생성한다.
- 결론: 입력된 텍스트에 따라 이미지가 생성된다.
저희가 설계한 모델은 3.3B개의 파라미터로 구성되어 있습니다. 또한 저희는 개발한 모델을 오픈소스로 공개하였으며, 체크포인트 역시 제공하였습니다.
Kandinsky 모델은 실험 결과 FID 점수에서 8.03으로 높은 점수를 보였으며, COCO-30K에서 오픈 소스 모델 중 SOTA 의 성능을 보였습니다.
Ⅰ. Introduction
텍스트를 통한 이미지 생성 모델은 빠르게 발전해왔습니다. 생성물의 퀄리티는 높아졌고, 빠른 속도로 생성했으며, 다양한 플랫폼과 AI 그래픽 편집기에서도 사용되고 있는 중입니다.
저희는 잠재 확산(latent diffusion) 구조에 새로운 설계 방법을 제시하여 혁신적인 관점을 제공합니다.🙂
따라서 본 논문에서는 새로운 설계 방법이 무엇인지, 또 생성된 이미지 품질을 어떻게 평가하는지 이야기할 예정입니다.
이번 논문을 통해 저희가 기여한 바는 다음과 같습니다.
- Image prior 모델과 Latent diffusion 모델을 결합한 최초의 이미지-텍스트 모델입니다.
- FID 평가지표에서 Stabe Diffusion, IF, DALL-E2와 견줄만한 성능을 보였으며, 기존 모든 오픈 소스 모델 중 SOTA 점수를 달성하였습니다.
- 텍스트 이미지 생성을 위한 최첨단 소프트웨어 구현을 제공하고, 최고 성능의 모델 체크포인트를 제공합니다. 따라서 Apache 2.0 license를 통해 상업적, 비상업적 목적으로 모델을 사용할 수 있습니다.
- Kandinsky모델을 사용한 웹 이미지 편집기 응용프로그램을 개발하였습니다.
링크: https://www.youtube.com/watch?v=c7zHPc59cWU
Ⅱ. Related Work
해당 문단에서는 Kandinsky 모델과 관련된 기존 연구들을 소개합니다. 초기 텍스트-이미지 생성 모델부터 최신 Diffusion 모델까지의 발전 과정과 어떻게 이러한 모델들이 이미지 품질을 향상시켰는지, 그리고 어떻게 다양한 응용 분야로 확장되었는지 다룹니다.
1. 초기 텍스트-이미지 생성 모델
초기 이미지 생성 모델: DALL-E, CogView, Parti
초기 이미지 생성 모델들은 자기 회귀적(Autoregressive) 방식을 통해 이미지를 예측합니다.
일반적으로 자기 회귀적 방식은 언어 모델에서 사용되는 방식입니다. 언어 모델은 이전에 예측한 토큰을 바탕으로 다음 토큰을 예측합니다.
이미지 생성 모델에서는 이전에 생성한 픽셀을 바탕으로 다음 픽셀의 값을 예측합니다. 즉 이미지의 각 부분을 순차적으로 예측합니다.
하지만 이미지 데이터와 텍스트 데이터는 그 구조가 달라 이미지에 자귀 회귀적 방식을 적용할 경우 문제가 발생합니다.😥 이미지에 자귀 회귀적 방식을 적용하기 위해서는 2차원 데이터를 1차원 데이터로 바꿔야 하는데 이때 공간적 정보가 많이 손상됩니다. 이로 인해 artifact(이미지 왜곡) 문제가 발생합니다.
이러한 한계를 극복하기 위해 DIffusion 모델이 등장하게 됩니다.
2. Diffusion 모델의 등장
Diffusion 모델: DALLE 2, Imagen, Stable Diffusion6
Diffusion 모델은 이미지에 점진적으로 noise를 추가한 다음, Noise를 제거하는 과정을 통해 이미지를 학습하는 모델입니다.
출처: 밑바닥부터 시작하는 딥러닝5
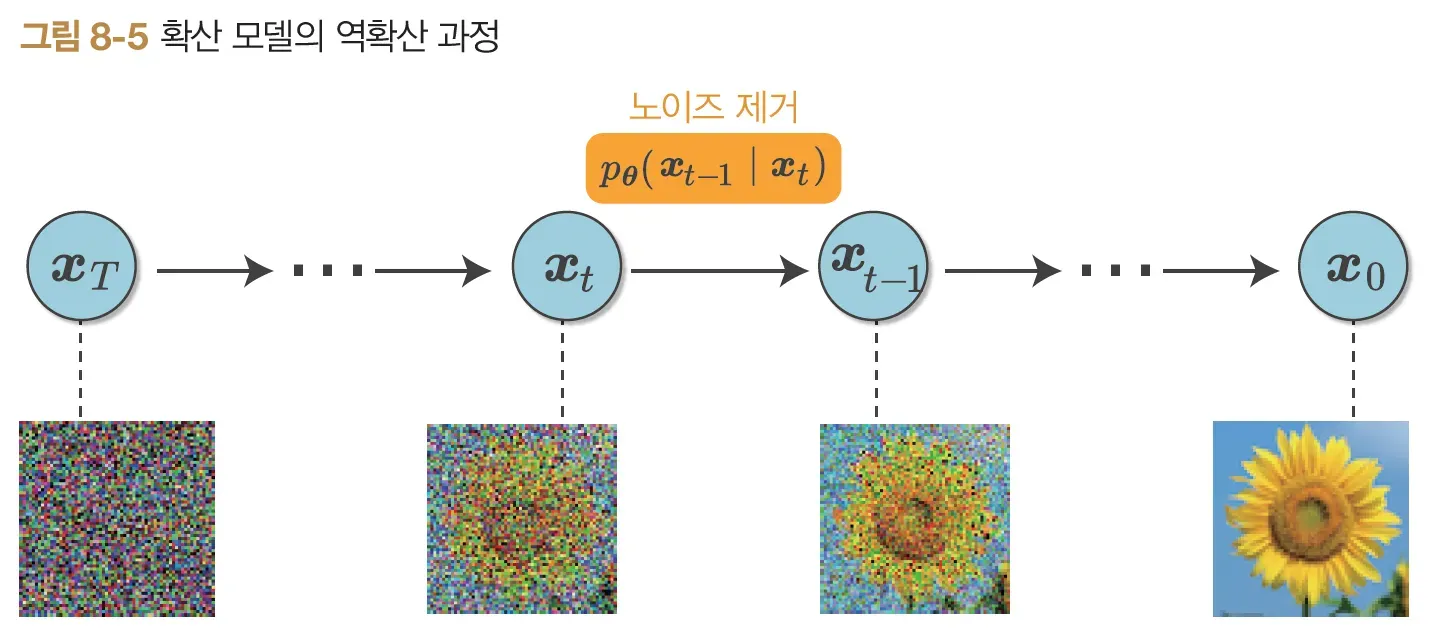
"노이즈를 제거하는 방식을 통해 이미지를 생성한다" 라는 Diffusion 모델의 철학이 왜 더 효율적인지는 아직까지 이해하기 못하여, 이 부분에 대해서는 다음에 다뤄보도록 하겠습니다.
3. 오픈 소스 모델 적용 기술 발전
생성 모델의 발전으로 DreamBooth나 DreamPose와 같은 생성 모델을 활용한 응용프로그램이 등장하기 시작했습니다. 이를 통해 사람들은 생성 모델을 원하는 방식으로 활용할 수 있게 되었습니다.
이는 Diffusion 기반 생성 모델의 발전을 더욱 촉진하였습니다.
4. 다양한 응용 분야로 확장
이후 이미지 생성 분야는 3D 합성, 비디오 생성, 이미지 편집 등 광범위한 분야로 확장되었습니다. 또한 Diffusion 모델은 기존의 GAN보다 좋은 성능을 보이며 Inpainting, Outpainting, 화질 개선 등 다양한 분야에 활용되었습니다.
텍스트-이미지 생성 분야는 diffusion 모델과 Classifierfree guidance algorithm 모델을 통해 텍스트 조건을 간단하게 통합할 수 있게 되었습니다.
Classifierfree guiddance algorithm은 텍스트 프롬프트(조건)의 영향력을 강력하게 높여서, 생성된 이미지가 텍스트 내용을 반영하도록 돕는 기술을 의미한다.
조건부 학습(Conditional Training)이라고 하는데, 텍스트 프롬프트가 주어졌을 때, 그 프롬프트에 맞게 노이즈를 제거하는 방법을 학습하는 것이다.
Ⅲ. Demo System
논문의 저자는 Kandinsky 모델을 활용하여 이미징 서비스를 구현하였습니다.
1. 주요 인터페이스
- Telegram 봇: 텔레그램 봇을 통해 텍스트-이미지 생성, 이미지 융합, 이미지 variation 생성 등 제공
- FusionBrain 웹사이트: 웹 기반 이미지 편집기, 지우개 도구, 줌 기능, 당야한 스타일 선택 기능 제공
Figure 3: Kandinsky web interface for “a corgi gliding on the wave”: generation (left) and in/outpainting (right)
출처: https://arxiv.org/pdf/2310.03502
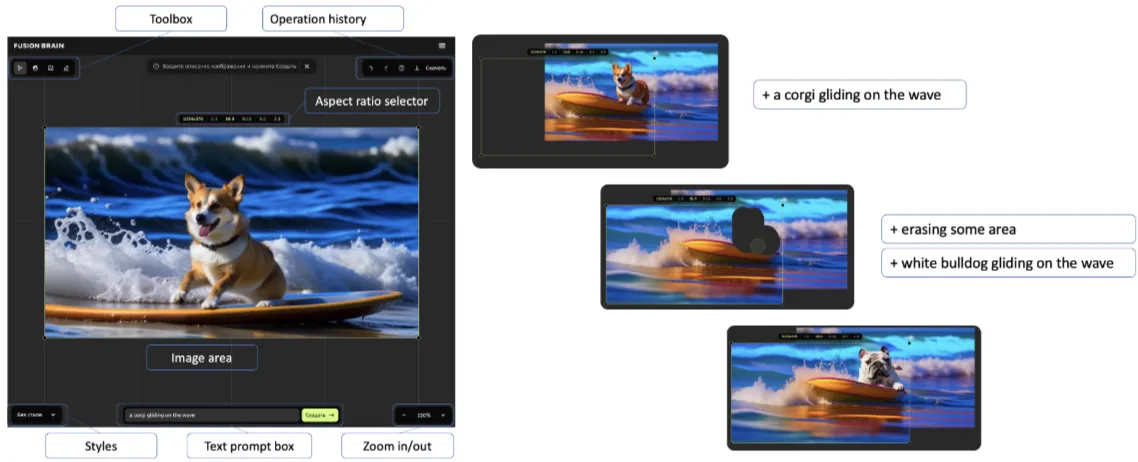
2. 기능
- Impainting: 지우개 도구를 사용하여 이미지의 특정 부분 제거한 후 자동 또는 원하는 방식으로 채우기
- Outpainting: 그림의 바깥쪽 부분을 확장해서 생성하는 기술
- text-to-image 생성: 이미지와 텍스트를 입력하여, 텍스트의 지시에 따라 새로운 이미지를 만드는 것
- 이미지 융합: 기본 이미지와 조건이 되는 이미지를 함께 넣어 두 이미지를 융합하여 생성하는 것.
- 이미지 변형: 사용자가 이미지를 입력하면, 그 이미지와 유사한 이미지가 생성되는 것
Figure 2: Examples of inference regimes using Kandinsky mode
출처: https://arxiv.org/pdf/2310.03502

Ⅳ. Kandinsky Architecture
해당 문단에서는 Kandinsky 모델의 아키텍처에 대해 설명합니다.
Figure 1: Image prior scheme and inference regimes of the Kandinsky mode
출처: https://arxiv.org/pdf/2310.03502
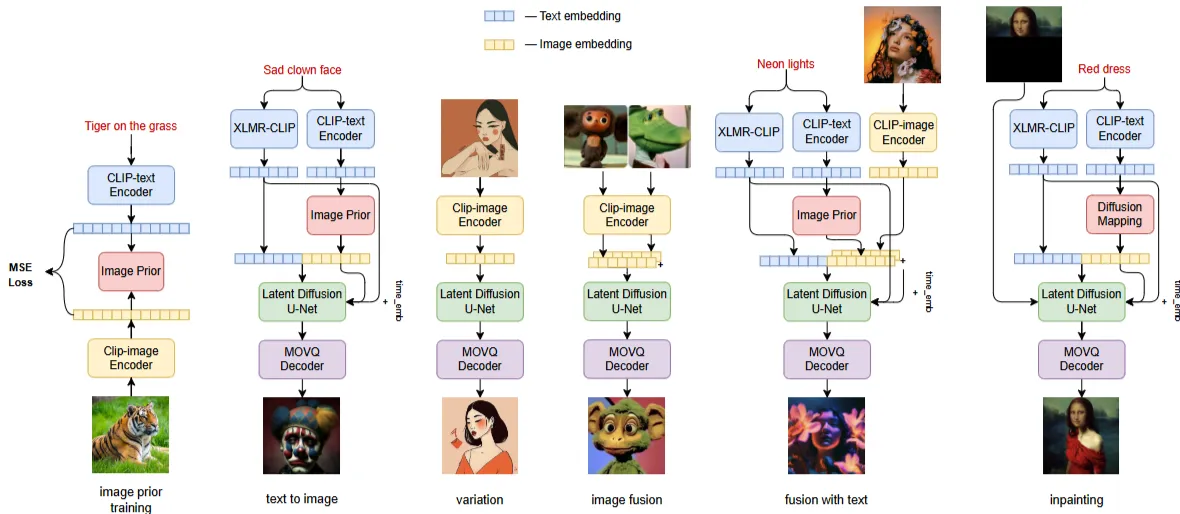
1. 전체적인 프로세스
- 입력된 텍스트 데이터 임베딩
- 텍스트 데이터 임베딩을 이미지 임베딩으로 변환
- 변형된 이미지 임베딩을 통해 이미지 생성
2. 텍스트 임베딩 프로세스
1) 초기 단계
텍스트 데이터를 모델에게 전달하기 위해서는 임베딩을 수행해야 합니다. 논문의 저자는 초기에는 mT5, XLMR과 같은 다양한 텍스트 인코더로 임베딩을 수행했습니다.
2) 채택된 텍스트 임베딩 모델 CLIP
연구 결과 단순히 언어모델을 통해 텍스트 임베딩을 하는 것보다, 텍스트와 이미지 모두를 이해하는 CLIP 모델을 통해 임베딩을 하는 것이 더 성능이 좋다는 것을 발견합니다.💡
여기서 중요한 것은 CLIP 모델의 출력결과가 텍스트 임베딩이라는 것입니다. CLIP 모델은 텍스트 데이터와 이미지 데이터를 모두 이해하고 같은 공간에 임베딩할 수 있지만 텍스트 임베딩과 이미지 임베딩은 분명히 다릅니다.
출처: https://kr.freepik.com/premium-vector/card-with-image-red-apple-lettering_41566964.htm
예를 들어 사과라는 글자와 사과 이미지를 CLIP 모델을 통해 임베딩을 했다고 합시다. 그러면 두 벡터는 분명 유사한 방향을 띄고 있습니다. 그 의미가 같기 때문입니다. 하지만 각 임베딩이 가지고 있는 정보의 성격은 전혀 다릅니다. 텍스트 임베딩은 사과, 빨간색, 과일 등 의미론적인 정보를 가지고 있습니다. 하지만 이미지 임베딩은 사과의 색상, 질감, 배경과의 관계 등 시각적인 정보를 담고 있습니다.

생성 모델이 이미지를 생성할 때는 의미론적인 정보와 시각적인 정보 중 어떤 정보가 더 필요할까요? 당연히 시각적인 정보가 더 필요할 것입니다. 따라서 논문의 저자는 텍스트 임베딩을 이미지 임베딩으로 바꿀 것을 제안합니다.💡
⭐3. Image prior 프로세스
논문의 저자는 텍스트 임베딩을 이미지 임베딩으로 바꾸어 줄 모델로 Transformer Encoder를 제안합니다. 그리고 특별한 학습 방법을 통해 해당 모델이 텍스트 임베딩을 이미지 임베딩으로 바꿀 수 있도록 훈련합니다. 우선 학습 데이터는 CLIP-VIT-L14가 만든 텍스트 임베딩과 이미지 임베딩입니다. 여기서 CLIP-VIT-L14는 VIT-L14 모델로 구성된 CLIP 모델 정도로 이해하시면 됩니다.
해당 데이터를 학습데이터로 사용하여 transformer encoder를 Diffusion 방식으로 학습합니다. 우선은 텍스트 임베딩을 이미지 임베딩으로 mapping하는 방법을 배운다고 이해하시면 됩니다.
논문의 저자는 학습 효율을 높이기 위해 정규화 과정 역시 수행했다고 말합니다.i
정리하면 image prior 모델은 앞서 CLIP 모델이 생성한 텍스트 임베딩을 CLIP 모델의 이미지 임베딩으로 바꾸어주는 매핑 모델입니다.
4. Latent Diffusion 프로세스
해당 과정에서는 앞선 정보를 바탕으로 이미지를 생성해줍니다. 해당 과정을 이해하기 전에 필요한 모델을 몇가지 살펴보도록 하겠습니다.
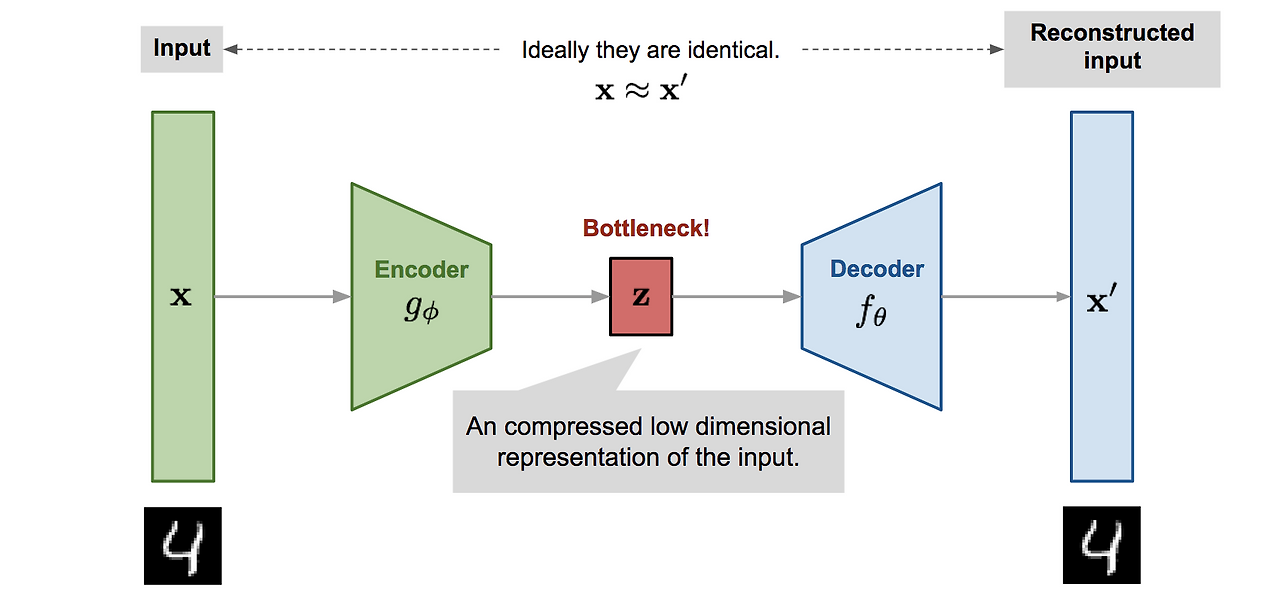
- Autoencoder: 이미지의 특징을 압축하고, 또 압축된 정보를 원래 이미지로 복구하는데 최적화된 모델
autoencoder는 이미지의 특징을 벡터로 잘 변환하고, 또 주어진 벡터를 이미지를 정교하게 복원하는 모델이라고 이해하시면 됩니다. Kandinsky 모델은 Sber-MoVQGAN 모델을 autoencoder로 사용합니다.
- U-Net: U-Net은 컴퓨터 비전 분야에서 다양한 방식으로 활용되는 모델입니다. 생성 분야에서는 이미지, 또는 이미지 벡터를 실제로 생성하는데 활용되고 있습니다. 현재 저희는 U-Net 모델에 텍스트, 이미지 임베딩을 입력으로 제공하기 때문에 U-Net이 생성하는 것은 이미지 임베딩입니다.
U-Net은 앞서 image prior 모델이 만든 이미지 임베딩과 CLIP 모델이 생성한 텍스트 임베딩을 입력으로 받으면 해당 조건에 맞는 이미지 임베딩을 생성해줍니다.
Latent diffusion 프로세스에서는 두 모델을 활용하여 최종 이미지를 생성합니다. 우선 Image prior 모델이 만든 텍스트에 대한 이미지 임베딩을 조건으로 받습니다. 그 외에도 사용자가 추가로 이미지를 넣고 싶다면 Sber-MoVQGAN 모델을 통해 이미지 임베딩을 생성합니다. 해당 정보를 U-Net 넣어주면 U-Net은 조건에 맞는 이미지 임베딩을 생성해줍니다. 최종적으로 이미지 임베딩은 다시 Sber-MoVQGAN 모델을 통해 실제 이미지로 복원됩니다.
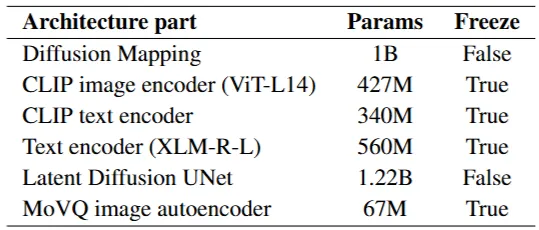
5. 모델 크기
Kandinsky 모델은 총 3.3B개의 매개변수로 구성되어 있습니다. (33억개)
Table 2: Kandinsky model parameters
출처: https://arxiv.org/pdf/2310.03502
Ⅴ. Experiments
해당 문단에서는 논문의 저자가 자신들이 개발한 모델의 성능을 어떻게 평가했는지 실험 및 평가 방법론에 대해 설명합니다.
1. 평가 방법
1) 자동 평가 지표 (Automatic Metrics): FID-CLIP 곡선
- FID (Frechet Inception Distance): 두 데이터가 통계적으로 얼마나 유사한지 평가하는 지표로 점수가 낮을수록 비슷하다는 의미. 생성된 이미지가 실제와 유사할수록 좋은 품질.
- CLIP: 해당 FID를 계산할 때 CLIP 임베딩을 사용. 두 벡터가 유사할수록 FID 점수가 낮음.
- FID-CLIP 곡선: 파라미터에 따라 출력된 FID 점수를 연결한 것. 최소점이 가장 좋은 성능.
- 사용 데이터: COCO-30K dataset

2) 인간 평가 (Human Evaluation): 블라인드 평가
- 평가 지표를 통한 평가와 사람의 평가는 다를 수 있기 때문에 수행.
- 블라인드 방식을 통해 이미지 품질 평가
2. 평가 수행
1) FID-CLIP 곡선을 통해 guidance-scale 파라미터 성능평가
- guidance-scale: 모델이 이미지를 생성할 때, 입력된 조건을 얼마나 반영할지 조절하는 파라미터
- FID-CLIP 곡선을 통해 최적의 guidance-scale 추출, 논문에는 없음.
2) 다른 모델들과의 성능 비교
Table 1: Proposed architecture comparison by FID on COCO-30K validation set on 256×256 resolution. * For the IF model we reported reproduced results on COCO-30K, but authors provide FID of 7.19
출처: https://arxiv.org/pdf/2310.03502
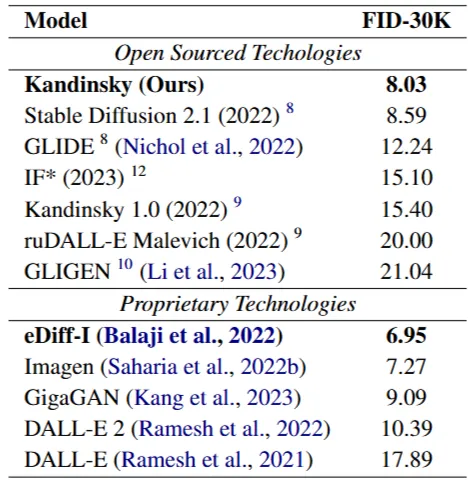
표를 보시면 Open Sourced Techologies에서 가장 좋은 성능을 보이고 있음을 확인할 수 있습니다.
3) Image prior 모델 성능평가
Image prior 모델은 텍스트 임베딩을 이미지 임베딩으로 바꿔주는 모델입니다. 논문의 저자는 Image prior 모델로 다양한 모델을 사용한 후 성능평가를 수행하였습니다.
Figure 4: CLIP-FID curves for different setups
출처: https://arxiv.org/pdf/2310.03502
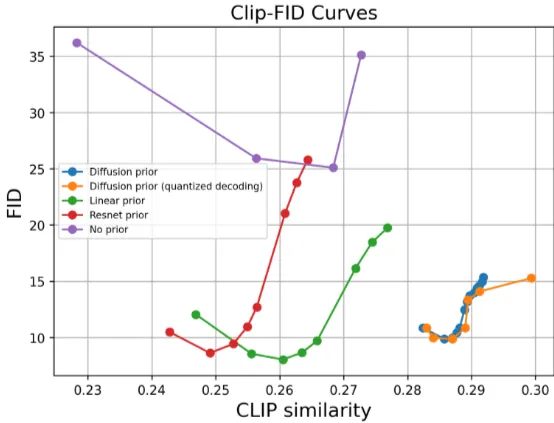
그 결과 놀랍게도 단순한 선형변환이 가장 낮은 FID 점수를 보였습니다. 이는 텍스트 임베딩을 이미지 임베딩으로 전환할 때, 복잡한 과정이 필요하지 않다고 이해할 수도 있습니다.
4) Human Evaluation을 통한 모델 성능 비교
Figure 6: Human evaluation: competitors vs Kandinsky with diffusion prior on Drawbench. The total count of votes is 5000.
출처: https://arxiv.org/pdf/2310.03502
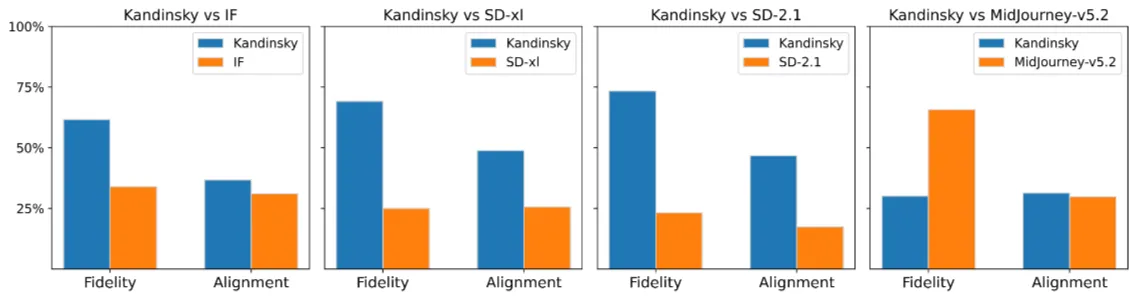
- Fidelity: 생성된 이미지의 품질, 얼마나 사실적인지 평가
- Alignment: 프롬프트 일치도, 생성된 이미지가 얼마나 의도에 맞게 만들어졌는지 평가
미드저니를 제외하고는 Kandinsky 모델이 Human Evaluation에서 좋은 성능을 보이고 있음을 확인할 수 있습니다.
Ⅵ. Results
Kandinsky 모델은 COCO-30K 검증 세트에서 8.03 FID 점수를 달성하여 오픈 소스 모델 중에서는 최고의 성능을 보였습니다.
또한 최고의 FID 점수 8.03은 Image prior 모델이 Linear mapping일 때 달성되었는데, 이는 텍스트 임베딩 벡터 공간과 이미지 임베딩 벡터 공간 사이에 선형 관계가 존재할 수 있음을 시사합니다.🤔
해당 가설을 검증하기 위해 논문의 저자는 추가적인 실험을 수행합니다. 텍스트 임베딩과 이미지 임베딩 사이에 정말 선형관계가 있다면, 적은 수의 데이터로 단순하게 학습된 선형 레이어에서도 좋은 성능을 보일 것입니다.
Figure 5: Image generation results with prompt "astro-naut riding a horse" for original image prior and linear prior trained on 500 pairs of images with cats
출처: https://arxiv.org/pdf/2310.03502

논문의 저자는 요청된 “말을 타고있는 우주비행사”와 무관한 고양이 사진 500개로 선형레이어를 학습하였고, 그 결과 꽤 괜찮은 성능을 확인하였습니다.
Ⅶ. Conclusion
1. 논문의 기여
- 본 논문에서는 새로운 Latent diffusion model을 기반으로 다양한 이미지 생성 및 처리 모델 Kandinsky모델을 제안합니다.
- Kandinsky모델은 오픈 소스 모델 중 SOTA를 기록하였습니다.
- 본 논문에서는 Image prior에 대한 ablation study를 통해 Image prior 모델이 모델 전체 성능에 미치는 영향을 분석합니다.
- Kandinsky 모델은 Telegram 메신저 봇 등 무료 인터페이스를 제공합니다.
- Kandinsky모델은 Hugging Face에서 사용할 수 있으며, 허용된 라이선스 하에서 상업적으로 이용 가능합니다.
2. 향후 연구
- 이미지 인코더, 텍스트 프롬프트 이해, U-Net 아키텍처 성능 개선
- 악의적인 콘텐츠 생성 억제 방법 강구
- 실시간 조정 레이어 개발
- 분류기 개발
Ⅷ.Limitations
- 입력된 텍스트와 의미론적 일관성이 있는 이미지를 생성하기 위해 추가 연구 필요
- Human Evaluation을 기준으로 FID 및 이미지 품질의 절대값을 개선하기 위한 연구 필요
Ⅸ. Ethical Considerations
논문의 저자는 불쾌한 생성물이 만들어지지 않도록, Kandinsky모델을 학습하는 과정에서 train data 중 유해한 이미지와 텍스트 데이터를 제거했다고 말합니다.
실험 결과 Kandinsky 모델은 불쾌한 생성물을 거의 만들지 않는 것으로 확인되었지만, 100% 보장하기는 힘들다고 말합니다.
따라서 논문의 저자는 이러한 콘텐츠를 분류할 수 있는 분류기, 또는 특정 방향으로 이미지와 텍스트를 변환해주는 레이어를 추가할 것을 제안합니다.
내 생각😅
세 번째 프로젝트에서 다뤘던 모델에 대해서 겨우 이해한 것 같다. 사실 Diffusion 모델, U-Net의 Cross-attention 등 디테일한 원리에 대해서는 만족할 만큼 이해하지는 못했다. 이 부분은 다음에 꼭 다뤄보도록 하겠다.
