
⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜
👨🏫Visual Instruction Tuning
🔗 논문: https://arxiv.org/pdf/2304.08485
⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜
✏️ 논문 요약
❓ 이 논문은 왜 나왔죠?
- Instruction tuning으로 학습된 LLM 모델이 기존에 학습하지 않았던 새로운 task에서 few shot없이 뛰어난 성능을 발휘한 연구결과가 있다.
⇒ 한마디로 LLM 모델이 사람이 시키는 일을 더 잘 이해할 수 있도록 훈련하는 과정이다.
- 이번 논문은 LLM 모델에 사용되었던 Instruction tuning 학습 방식이 Visual 영역으로 확장된 것이다.
⇒ 즉 이미지와 언어를 이해할 수 있는 모델 만들었는데 지시한 말을 잘 이해 못하는 경우가 많아서, 이를 해결하기 위해 모델이 사람의 지시를 더 잘 이해할 수 있도록 추가 학습을 시켰다는 내용이다.
☝️ 그래서 논문에서 한 것!
- GPT-4 모델을 통해 "이미지를 이용하여 구체적인 task를 수행하는 데이터셋" LLaVA-Instruct-150K를 만들었다.
- LLaVA-Instruct-150K을 이용하여 LLaVA 모델을 개발하였다.

0️⃣ Abstract
Abstract에서는 논문의 내용을 간단하게 요약하고 있다.
🔷 논문의 내용
-
Instruction Tuning을 위한 LLaVA-Instruct-150K 데이터셋을 구축하였다.
-
LLaVA-Instruct-150K를 활용하여 LLaVA 모델을 개발하였다.
-
멀티모달 모델의 Instruction following 능력을 평가하기 위한 벤치마크 2개를 구축하였다.
-
Science QA 데이터셋에서 92.53%로 SoTA 달성를 달성하였다.
-
데이터, 모델 코드를 오픈소스로 공개하였다.
1️⃣ Instruction
1장에서는 논문의 등장배경에 대해 다룬다.
🔷 논문의 등장배경
🔻 Vision-Language 모델에 대한 사람들의 기대
- 사람들은 자신들이 요구하는 명령을 잘 따르면서 시각, 언어에 대한 높은 이해를 가진 모델을 원하고 있다.
🔻 현재 Vision 모델 상황
-
현재 Vision model은 dectection, segmentation, captioning과 같이 특정 task를 위해 설계된 경우가 많다.
-
이러한 모델은 인간의 지시사항을 학습과정 자체에 녹여내기 때문에 학습 방법 외에 인간과 상호작용하기 어렵다.
🔻 상호작용 능력이 뛰어난 언어모델
-
반면 LLM 모델은 인간과 언어로 소통하며 지시사항을 명확하게 전달받을 수 있다.
-
즉 상호작용 능력이 뛰어나다.
-
또한 Instruction Tuning 학습을 통해 LLM 모델이 사용자의 의도에 맞게 행동하는 능력을 향상되었다는 연구결과가 있다.
📃해당 논문: https://arxiv.org/pdf/2109.01652
⇒ 이러한 배경에 따라 논문의 저자는 Instruction tuning을 vision 분야로 확장한 Vision Instruction tuning 방법을 제안한다.
2️⃣ Related Work
2장에서는 LLaVA와 Instruction tuning과 관련된 연구에 대해 간단하게 소개합니다.
🔷 1. Multimodal Instruction-following Agents
🔻 1-1 End-to-end 학습 모델
- 특정 task 수행을 위해 End-to-end 방식으로 학습된 모델이다.
- 이미지와 언어에 대한 정보를 입력받으면 특정 task를 수행하는 모델이다.
🔸 예시 모델
- Vision-and-Language Navigation : 말로 하는 길 안내를 듣고, 눈앞에 보이는 실제 환경을 인식하며 목적지까지 찾아가는 로봇을 위한 모델이다.

📃해당 논문: https://arxiv.org/pdf/1711.07280
-
InstructPix2Pix : 사용자가 작성한 텍스트 지시에 따라 이미지를 편집하는 모델이다.

📃해당 논문: https://arxiv.org/pdf/2211.09800
🔻 1-2 Langchain, LLM을 통한 모델 협업 시스템
-
LLM 모델이나 Langchain을 활용하여 사용자의 지시에 따라 필요한 이미지 모델을 불러와 사용하는 시스템이다.
-
여러 task를 수행하기 위해서는 여러 모델이 필요하다.
⇒ LLaVA는 단일 모델로 end to end 학습을 통해 여러 task를 수행할 수 있도록 설계되었다.
🔷 2. Instruction Tuning
🔻 2-1 자연어처리 분야에서의 연구
-
LLM 모델이 사용자의 지시를 잘 따를 수 있도록 few-shot과 같은 기법이 연구되고 있다.
-
최근 Instruction Tuning을 통해 few-shot 없이도 사용자의 지시를 잘 따른다는 연구결과가 있다.
🔻 2-2 컴퓨터비전 영역으로 확장
- Flaming, BLIP-2, KosMos-1같은 모델은 이미지 텍스트 쌍으로 학습을 하였지만 다양한 task를 처리하는 능력이 LLM 모델이 비해 떨어진다.
⇒ Instruciton Tuning 방법을 통해 LLaVA 모델 학습하여 다양한 task 지시를 잘 따를 수 있도록 학습하였다.
3️⃣ GPT-assisted Visual Instruction Data Generation
3장에서는 GPT-4를 통해 어떻게 LLaVA-Instruct-150K 데이터를 구축하였는지 설명한다.
🔷 1. 데이터 구축 배경
-
최근 CC에서 LAION까지 다양한 이미지-텍스트 데이터가 공유되고 있다.
-
하지만 Instruction following에 관한 데이터는 부족하다.
-
사람이 Instruction following 데이터를 구축하는 것은 시간이 오래걸릴 뿐더러 쉽지 않다.
-
또한 어떤 instruction을 중심으로 데이터를 구축할지에 대해서도 명확한 답이 없다.
⇒ 이에 따라 논문의 저자는 “GPT를 활용한 텍스트 주석 생성 작업”을 보고 GPT-4를 활용하여 instruction following 데이터를 만들기를 제안한다.
🔷 2. 데이터 구축 과정
🔻 2-1 사용 모델 & 사용 데이터
- 텍스트 GPT-4를 사용하였다.
- 텍스트 GPT-4는 이미지를 이해할 수 없기 때문에, 이미지 캡션과 이미지 속 객체의 Bounding Box를 입력으로 제공하였다.
- COCO 데이터셋을 사용하였다.
🔻 2-2 데이터 생성

-
하나의 이미지에 대해 대화, 상세 설명, 복합 추론, 총 3가지 유형의 Instruction-following 데이터를 구축하였다.
-
총 158K의 데이터 생성 : 대화 58K, 상세 설명 23K, 복합추론 77K
-
대화의 경우 멀티턴으로 구축되었다.
-
상세 설명과 복합추론은 싱글턴으로 구성되었다.
4️⃣ Visual Instruction Tuning
4장에서는 LLaVA 모델의 Architecture와 학습방법에 대해 설명한다.
🔷 1. Architecture
LLaVA 모델은 이미지 인코더, LLM, 두 모델을 연결하는 신경망으로 구성되어 있다.
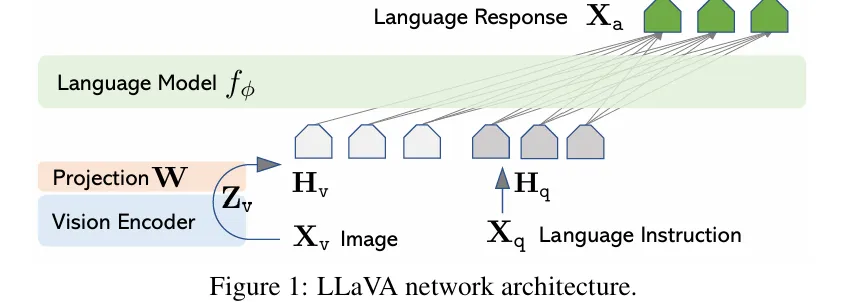
🔻 1-1. Image Encoder
-
LLaVA 모델은 이미지 인코더로 CLIP-ViT-L/1 모델을 사용하였다.
-
사전 학습된 CLIP을 가져와서 추가적인 학습을 진행하지 않는다.
🔻 1-2. LLM
- LLaVA 모델은 LLM 모델로 사전 학습된 Vicuna 모델을 사용한다.
📃관련 자료: https://lmsys.org/blog/2023-03-30-vicuna/
🤔 Vicuna 모델이 무엇인가요?
Vicuna 모델은 LLaMA 모델을 “Chat GPT와 사람들의 대화기록 데이터”로 파인튜닝한 Decoder 기반 LLM 모델입니다. Vicuna 모델은 사람들의 대화기록을 통한 파인튜닝을 통해 아래의 강점을 가지고 있는 모델입니다.
- 다양한 종류의 지시사항을 잘 따릅니다.
- 멀티턴 대화 구조에 강인합니다.
- 사람들의 의도를 잘 파악합니다.

🔻 1-3. 선형 레이어
-
LLaVA 모델은 CLIP 모델이 출력한 이미지 특징을 LLM 모델이 이해할 수 있는 단어 임베딩 공간으로 연결하기 위한 projection layer를 사용하였다.
-
선형 레이어를 통해 이미지 특징은 언어 임베딩 토큰으로 변환된다.
🤔 데이터 변환 과정에서의 고찰
-
논문의 저자는 CLIP 모델의 최종 출력을 LLM 모델에게 전달할 때보다, CLIP 모델의 최종 출력과 바로 앞 레이어의 hidden state를 함께 LLM 모델에게 전달할 때 더 좋은 성능을 발휘하는 것을 확인할 수 있었다.
-
CLIP 모델은 이미지 데이터를 압축하는 과정에서 디테일한 정보보다 이미지 전체에 대한 포괄적인 데이터를 전달한다.
-
모델 중간 데이터를 활용하면 이미지의 디테일한 정보 역시 함께 전달할 수 있다는 점을 생각해볼 수 있다.
☝️ 논문 저자의 한마디
-
이미지 데이터를 언어모델에게 전달하는 방식은 조금 더 고민해볼 수 있을 것 같다.
-
Flamingo는 gated cross-attention 방식을, BLIP-2는 Q-Former 방식을 사용하는 것을 생각해볼 수 있다.
🔷 2. Training
LLaVA 모델은 Feature Alignment와 Instruction tuning, 총 2단계의 학습 과정을 거친다.
🔻 2-1. Pre-training for Feature Alignment
-
학습 목표 : 신경망 레이어가 이미지 특징을 언어 임베딩으로 잘 변환할 수 있도록 학습한다.
-
학습 대상 : CLIP과 LLM의 파라미터는 고정한 채, 신경망 레이어만 학습한다.
-
학습 데이터 : CC595K 이미지-캡션 데이터셋을 사용한다.
🔻 2-2. Fine-tuning End-to-End
-
학습 목표 : LLaVA 모델이 이미지를 활용한 지시사항을 잘 따를 수 있도록 학습한다.
-
학습 대상 : CLIP 모델의 파라미터는 고정한 채, 신경망 레이어와 LLM 모델의 파라미터를 학습한다.
-
학습 데이터 : 앞서 구축한 LLaVA-Instruct-150K를 사용한다.
-
참고사항 : 추가적으로 5장에서 다루는 ScienceQA 실험에서는 LLaVA-Instruct-150K와 함께 Science QA 데이터 역시 Instruction tuning 단계에서 학습한다.
-
ScienceQA는 과학적 이해가 필요하며, 문제를 풀기 위한 다양한 요구사항이 많아 Instruction Tuning의 취지와 잘 맞아떨어진다.
🔷 3. Loss function에 대한 간략한 정리
🔻 3-1. Multi-turn
- LLaVA-Instruct-150K에는 하나의 이미지에 대하여 Multi-turn으로 구성된 데이터가 있다.
- 즉 이미지 하나에 대하여 Instruction1, Instruction2 등이 있다고 이해하면된다.
🔻 3-2. Autoregressive
- 실제 Loss function을 계산하기 위해서는 LLM 모델의 출력을 활용한다.
- 현재 예측하려고 하는 단어
- 입력 이미지
- 사용자의 Instruction, Multi-turn일 경우 지금까지의 모든 지시사항
- 지금까지 LLM 모델이 생성한 단어
- 해당 프로세스를 통해 LLM 모델은 Autoregressive한 방식으로 단어를 생성한다.

- LLaVA는 토큰까지 생성하도록 학습하여 문장이 언제 끝나야하는지 학습한다.
- 따라서 토큰 역시 Loss function에 포함된다.
5️⃣ Experiments
5장에서는 LLaVA가 지시사항을 얼마나 잘 따르는지, 시각적 추론 능력이 얼마나 뛰어난지를 평가한다.
🔷 1. Multimodal Chatbot
이번 실험에서는 LLaVA의 멀티모달 챗봇으로서의 이미지 이해 및 대화 능력을 평가한다.
🔻 1. Qualitative Evaluation
-
평가 방법 : GPT4, BLIP-2, Open Flamingo 모델들의 대답과 비교한다.
-
때때로 GPT-4 멀티모달 모델보다 더 좋은 응답을 보이는 경우가 있다.
-
다른 모델들과 달리 LLaVA는 사용자의 지시를 정확하게 따르면서도 더 포괄적인 답변을 제공한다.
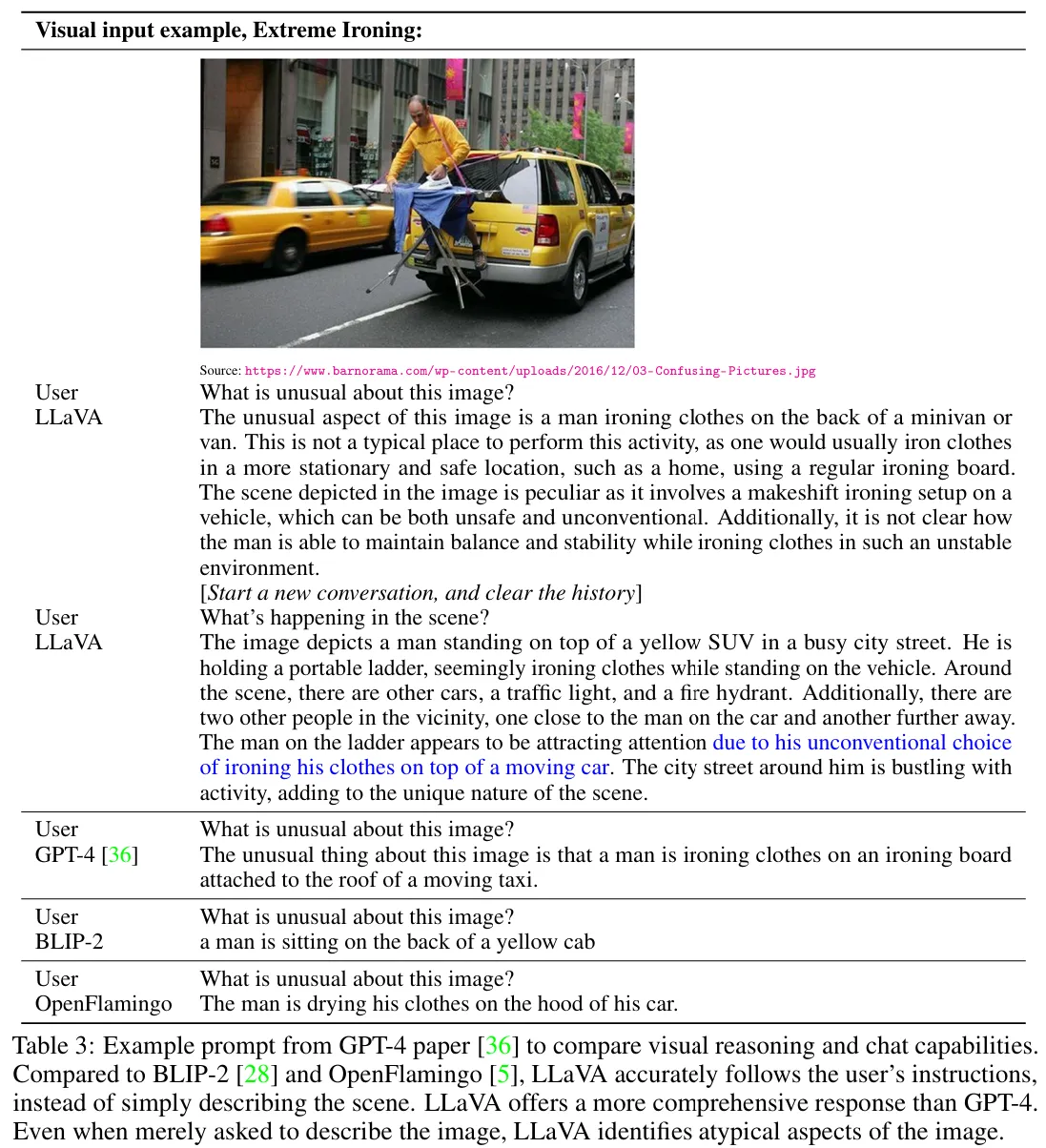
🔻 2. Quantitative Evaluation
- 평가 방법: GPT-4 모델을 활용하여 평가한다.
- 판정자 GPT-4는 다른 GPT-4가 만든 예상 답변과 비교하여 1~10 척도의 평가를 진행한다.
🔸 1. LLaVA-Bench (COCO)
- COCO val 2014 데이터 30개를 중심으로 3가지 유형의 질문을 만들어서 총 90개의 벤치마크를 구축하였다.
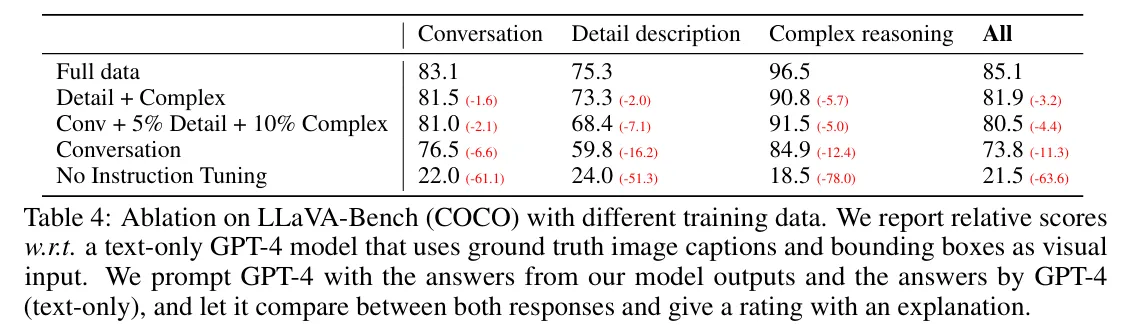
- Instruction Tuning 유무에 따라 성능이 50점 이상 차이나는 것을 확인할 수 있다.
- 3가지 유형의 Instruction Tuning을 모두 진행하였을 때 가장 좋은 성능을 발휘함을 확인할 수 있다.
🤔 의심하기
- 그냥 학습 데이터가 많아질수록 성능이 개선되는 구조일 수도 있지 않을까?
- Conversation 없이 Detail + Complex만 더 늘리면 어떻게 될까?
- 멀티턴 길이는 모델 성능에 어떤 식으로 영향을 줄까?
🔸 2. LLava-Bench (In the wild)
-
LLaVA 모델의 일반화 능력과 추론 능력을 평가하기 위해 실내외 장면, 밈, 그림 24가지를 통해 총 60개의 질문으로 벤치마크를 구축하였다.
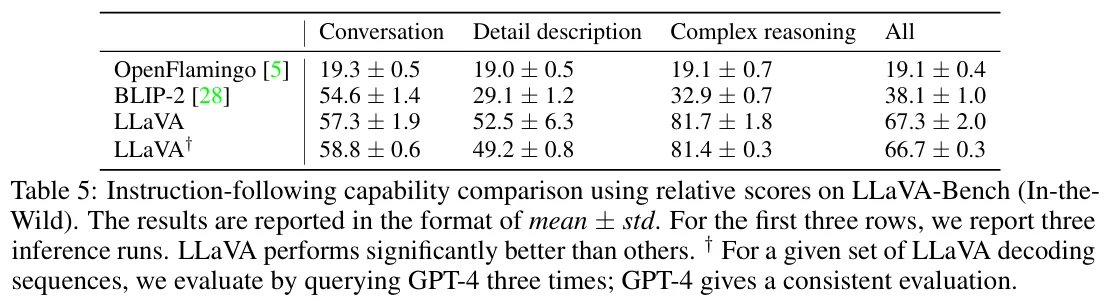
- BLIP-2, OpenFlamingo보다 훨씬 우수한 성능을 보이는 것을 확인할 수 있다.
- LLaVA+는 GPT-4 평가방식의 신뢰성을 위해 출력결과에 대해 3번 반복하여 평가를 진행한 것이다.
- 일관된 평가를 통해 평가방식의 신뢰성을 확보하였다.
🔻 LLaVA 모델의 Limitation

- LLava-Bench (In-the-Wild)는 LLaVA의 약점을 확인하기 위해 높은 난이도로 설계되었다.
- LLaVA 모델이 해당 Benchmark를 해결하기 위해서는 아래의 능력이 추가적으로 필요하다.
- 이미지 속 다국어에 대한 이해가 필요하다.
- 이미지 속 제품의 브랜드명을 이해할 수 있는 배경지식이 필요하다.
-
또한 딸기와 요거트가 있는 오른쪽 자료에 “딸기 요커드가 있는가?” 라는 질문에 Yes라는 답변을 하였다.
-
이는 이미지 데이터를 개별 조각의 모음으로 이해한다는 것을 확인할 수 있다.
-
LLaVA 모델이 이미지의 더 복잡한 의미를 파악할 수 있도록 성능 개선이 필요함을 알 수 있다.
🔷 2. ScienceQA
🔻 2-1. ScienceQA란?
-
데이터 규모 : 21,000개의 객관식 질문으로 구성되어 있다.
-
데이터 구성 : 3개의 주제, 26개 토픽, 127개의 카테고리, 379개의 스킬에 걸친 다양한 도메인으로 구성되어 있다.
-
데이터 분할 : 훈련 데이터 12,726개 / 검증 데이터 4,241개 / 테스트 데이터 4,241개
🔻 2-2. Experiment
- 비교 모델 : GPT-3, LLaMA-Adapter, MM-CoT
- LLaVA 모델 추가 파인튜닝 : ScienceQA 데이터셋을 활용하여 12 epoch 파인튜닝을 진행하였다.
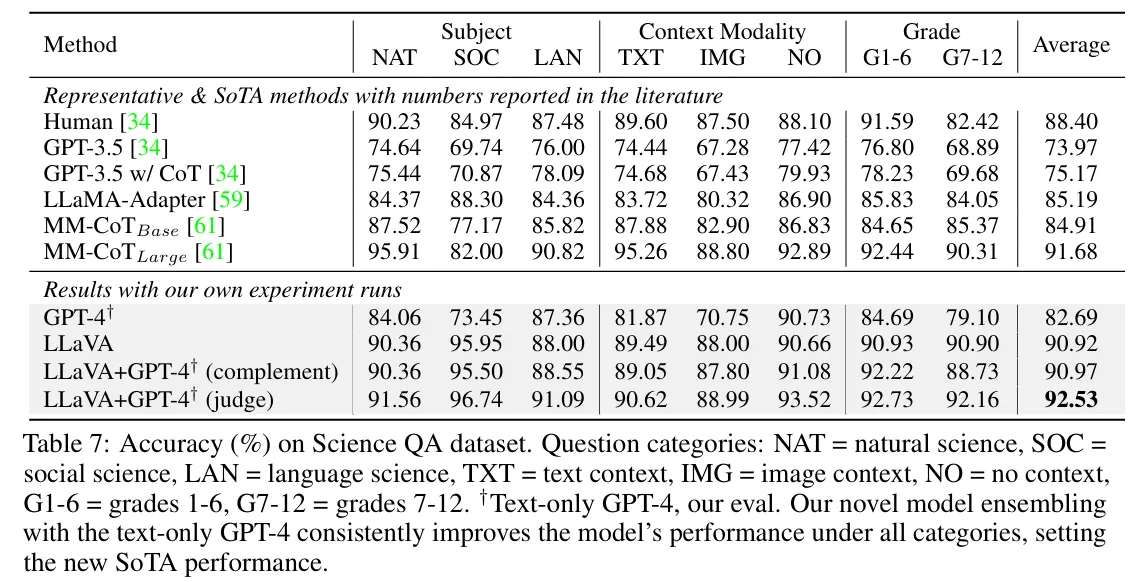
-
LLaVA 단일 모델은 90.92%의 정확도로 SoTA인 MM-CoT의 91.68에 근접하였다.
→ 이때 CLIP 모델의 마지막 레이어 바로 앞 hidden state를 추가로 활용하였다.
⇒ 디테일한 이미지 특징을 추가할 경우 성능이 향상됨을 알 수 있다. -
텍스트 GPT-4는 82.69의 점수를 기록하였다.
-
이때 GPT-4 모델과 LLaVA 모델을 앙상블하여 92.53의 SoTA 기록을 달성하였다.
→ GPT-4모델에게 LLaVA와 GPT결과가 다를 경우 각 모델의 답변과 질문을 제공하여 최종 답변을 선택하도록 설계하였다.
🔷 3. Ablation
LLaVA 모델의 성능 개선을 위한 다양한 실험을 진행하였다.
🔻 3-1. CLIP 모델 중간 hidden state 활용
-
CLIP 모델의 중간 hidden state를 활용할 경우 성능이 개선됨을 확인할 수 있다.
-
이를 통해 이미지 데이터의 디테일한 정보를 잘 전달하는 것이 중요하다는 것을 알 수 있다.
🔻 3-2. CoT를 활용한 학습
-
ScienceQA 파인튜닝에서 추론과정을 생각한 후 답변을 생성하도록 학습과정을 구축하였다.
-
모델의 학습 속도가 약 2배는 빨라졌지만, 더 뛰어난 성능에 도달하지는 않았다.
🔻 3-3. 사전학습 없기 ScienceQA 학습
-
Pre-training for Feature Alignment과정이 없다면 모델의 성능 대폭 저하하는 것을 확인할 수 있다.
🔻 3-4. LLM 모델 크기 변경
-
사용하는 LLM 모델은 클수록 뛰어난 성능을 발휘한다.
6️⃣ Conclusion
6장에서는 논문의 내용을 간단하게 요약하였다.
- Instruction following 데이터를 생성하는 파이프라인을 구축하였다.
- Instruction tuning을 통해 LLaVA를 학습하였다.
- ScienceQA에서 SoTA를 달성하였다.
- Instruction following 연구를 위한 Benchmark 구축하였다.
🧐 내 생각
내 생각에 Instruction Tuning의 실체는 언어모델의 확률분포를 조정하는 것이다. 기존에 LLM 모델은 다양한 조건부 확률분포를 학습하였지만, "이미지의 내용을 구체적으로 다루는" 언어 시퀀스는 많이 경험하지 못했을 것이다. 이미지 Captioning 학습을 하더라도 해당 시퀀스는 다양한 task의 조건을 대표하기에는 부족했던 것 같다. 그래서 조금 더 다양한 Instruction 데이터 시퀀스 추가하여 모델이 인간의 지시 조건에 대한 확률분포를 잘 학습할 수 있도록 한 것 같다.
