⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜
🕵️EscapeBench: Towards Advancing Creative Intelligence of Language Model Agents
🔗 논문: https://arxiv.org/abs/2412.13549
⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜
✏️ 논문 정리
1. 이 논문을 읽는 이유가 무엇인가요?
⇒ 모델이 어떻게 창의적인 생각을 할 수 있는지 궁금하다. + 연구 분야 정하기
2. 논문 제목의 의미는 무엇인가요?
⇒ Escape Bench는 논문에서 제안하는 Benchmark이다. 또한 논문은 언어모델의 창의적 능력을 향상시키는데 목표를 두고 있다.
3. 논문의 등장배경은 무엇인가요?
⇒ LLM 모델의 창의적 능력을 평가하는 Benchmark가 부족하다.
4. 논문을 1~2줄로 요약하세요
⇒ EscapeBench는 AI 모델의 도구 사용 능력, 제작 능력 등 창의적 능력을 평가한다. 또한 도구에 대한 가설 설정 모듈, 해결하지 않은 Task를 정리해준 리스트를 통해 모델의 창의적 사고와 숨겨진 목표 탐색 능력을 향상시킨 EscapeAgent 프레임워크를 제안한다.
0️⃣ Abstract
🔷 기존 모델의 특징
-
명시적인 목표가 있는 목표 지향적인 작업에 특화되어 있다.
-
반대로 목표가 주어지지 않고, 창의적 지능이 필요한 상황에서 좋은 성능을 발휘하지 못한다.
🔷 창의적 사고가 필요한 EscapeBench
-
EscapeBench는 방탈출 환경으로 구성되어 있다.
-
EscapeBench는 창의적 추론, 창의적 도구사용, 숨겨진 목표 탐색 능력을 요구한다.
-
LM 모델에 CoT와 working memory를 사용하더라도 추가적인 도움이 없다면 평균적으로 15%의 진행률만 달성하였다.
-
Working memory는 데이터를 일시적으로 저장하고, 조작할 수 있는 능력이다.
🔷 창의성을 향상시킨 프레임워크, EscapeAgent
-
EscapeAgent는 언어모델에 Foresight모듈과 Reflection 모듈을 추가시킨 프레임워크이다.
-
Foresight는 도구를 창의적으로 사용할 수 있도록 돕는 모듈이다.
-
Reflection은 숨겨진 목표를 찾는 모듈이다.
🔷 기존보다 뛰어난 성능
-
EscapeAgent를 통해 기존보다 40% 적은 힌트를 통해 게임을 완료하였다.
-
EscapeAgent는 더 효율적이고 혁신적인 퍼즐 해결 전략을 제시한다.
1️⃣ Introduction
🔷 현재 Agent의 연구 방향
-
Agent가 스스로 계획을 세운 후 추론을 수행할 수 있도록 개발하는 것을 목표로 한다.
-
현재 Agent가 기억을 잘 정리한 후 활용하는 능력, 복잡한 추론, 계획 설계, 반성을 잘 수행할 수 있도록 연구하고 있다.
-
이러한 능력을 통해 Agent가 웹, 게임, 현실사회에서 행동하고 도구를 사용할 수 있도록 개발되고 있다.
🔷 현재 Benchmark의 한계
-
현재 공개된 Benchmark는 목표지향적이며, 계획 설계, 추론 능력에 초점이 맞춰져 있다.
-
반면 모델이 낯선 환경에서 창의적인 능력을 발휘하는 것에 대한 비중이 적다.
-
모델이 주어진 도구를 학습된 방식대로 사용하는 것에만 집중하여, 새로운 활용 능력이 떨어진다.
-
현재 공개된 Benchmark는 모델의 분석적, 실용적 능력을 평가하는 데 초점이 맞춰져 있다.
🔷 EscapeBench
-
방탈출 게임에서 영감을 얻어 모델의 창의적 도구 사용 능력과 숨겨진 목표를 찾는 능력을 평가한다.
-
모델의 창의적 능력을 평가하는데 초점이 맞춰져 있다.
-
예를 들어 Figure1에서 나무막대기를 “찌르는” 용도가 아닌 뚜껑을 들어올리는 용도(일반적이지 않은 사용법)로 사용하도록 요구하는 것을 확인할 수 있습니다.
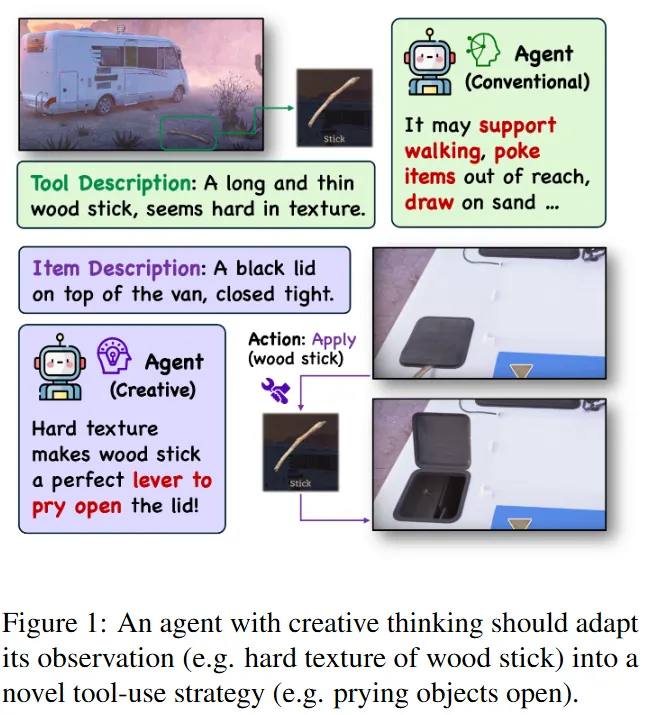
🔻 Creative Tool Use
-
언어모델이 기존에 학습하지 않은 방식으로 도구를 사용해야 한다.
-
EscapeBench는 모델이 관찰하여 알게 된 사실을 현재 목표에 적용할 수 있도록 요구한다.
🔻 Uncertain Goal Pathways
-
EscapeBench에서 모델은 방탈출이 최종 목적이지만, 중간 단계의 목표는 알 수 없다.
-
따라서 장기적인 계획을 세울 수 없으며, 그때그때 시행착오를 통해 전략을 세워야 한다.
🔻 Super-Long Reasoning Chain
-
Benchmark의 중간 목표, 단서 등 모든 정보를 알고 있는 Agent 역시 문제를 해결하기 위해 100단계 이상의 절차가 필요할 정도로 복잡하다.
-
해결하지 못하면 다음 단계로 넘어갈 수 없는 문제(Key Step)가 40개 이상 존재한다.
🔷 EscapeAgent
-
모델이 더 창의적으로 도구를 사용하고, 숨겨진 목표를 찾을 수 있도록 2가지 모듈을 제안한다.
-
Foresight는 모델이 행동하기 전 도구 사용 가설을 제안하고 평가할 수 있도록 한다.
-
Reflection은 앞으로의 행동 전략을 위해 현재 해결되지 않은 문제를 기억하도록 한다.
🔷 논문의 기여
-
LLM Agent의 창의성을 평가하기 위한 EscapeBench를 구축하였다.
-
숨겨진 목표를 찾고, 창의적인 추론 능력을 향상시킨 EscapeAgent를 개발하였다.
-
도구 사용과 제작 능력을 평가하는 방식을 통해 Agent의 성능을 측정하는 새로운 metric을 제안한다.
2️⃣ Related Work
2장에서는 기존 agent 평가 방식의 한계와 논문이 기여한 바에 대해 설명한다. Introduction과 유사하여 겹치지 않은 부분만 간단하게 정리하였다.
🔷 현재 AI 모델의 창의적 능력 활용
-
AI 모델은 이야기, 시 등을 생성하는 창의적 능력을 보여주고 있다.
-
대화를 통해 사람이 창의성을 발휘할 수 있도록 돕습니다.
-
도구를 설계하고 생성하는데 뛰어난 성능을 발휘합니다.
🔷 창의성에 대한 논의
-
LLM의 창의성은 조합적, 탐색적, 변혁적으로 구분된다.
-
이 중 변혁적 창의성이 가장 어렵다고 평가받는다.
📃관련 논문: On the Creativity of Large Language Models
3️⃣ EscapeBench Construction
3장에서는 EscapeBench의 구성요소에 대해 설명한다.
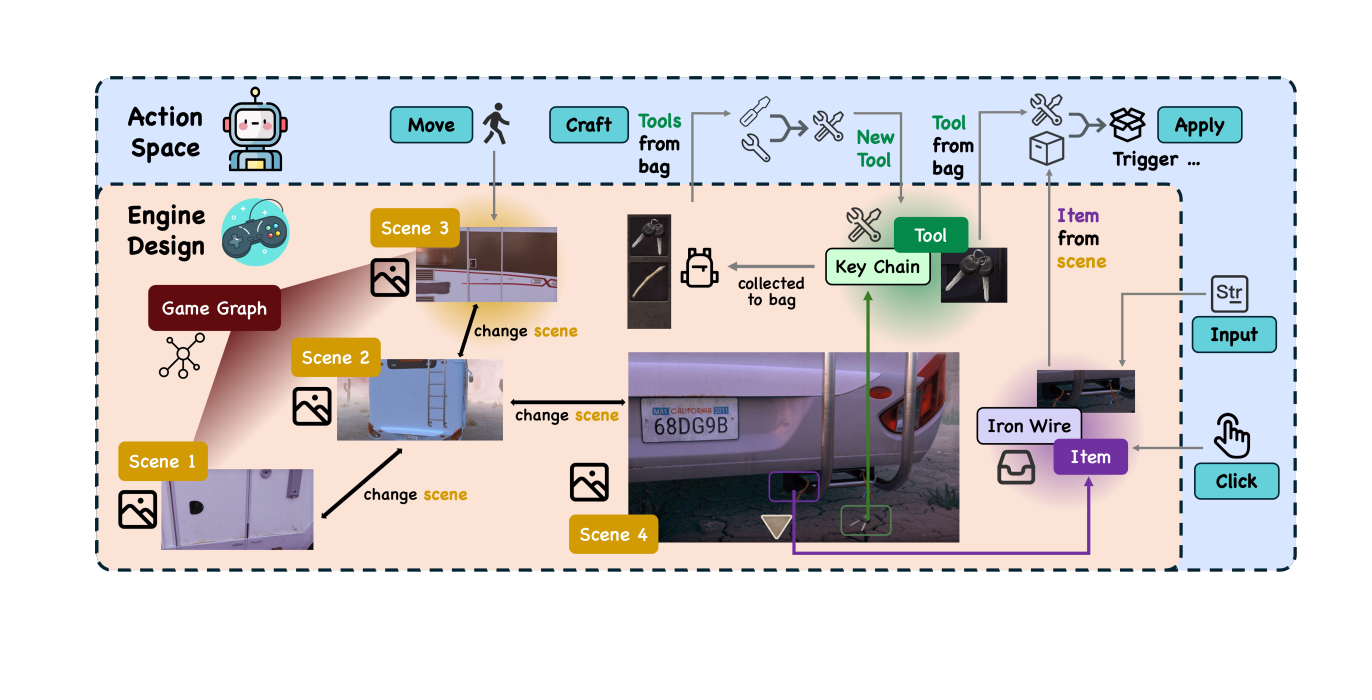
🔷 1. Engine Design
Engine Design에서는 방 탈출 게임 환경의 핵심 구성 요소들을 설명한다.
🔻 1-1. Scene
-
Agent가 환경과 상호작용하는 물리적 위치이다.
-
Agent가 있는 공간 정도로 이해하면 될 것 같다.
-
도구, 아이템이 담겨진 공간이다.
🔻 1-2. Items
-
Agent가 Scene 속에서 상호작용 가능한 객체
-
Agent는 Tool를 사용하거나 특정 행동을 통해 Item 상태를 변화시킬 수 있다.
-
예를 들어 잠겨있는 문, 디지털 자물쇠 등이 있다.
🔻 1-3. Tools
-
Agent가 Scene 속에서 수집하여 사용할 수 있는 객체이다.
-
Items에 적용하거나, 또 다른 Tool과 결합하여 새로운 Tool을 만들 수 있다.
🔻 구성 요소 연결하여 이해하기
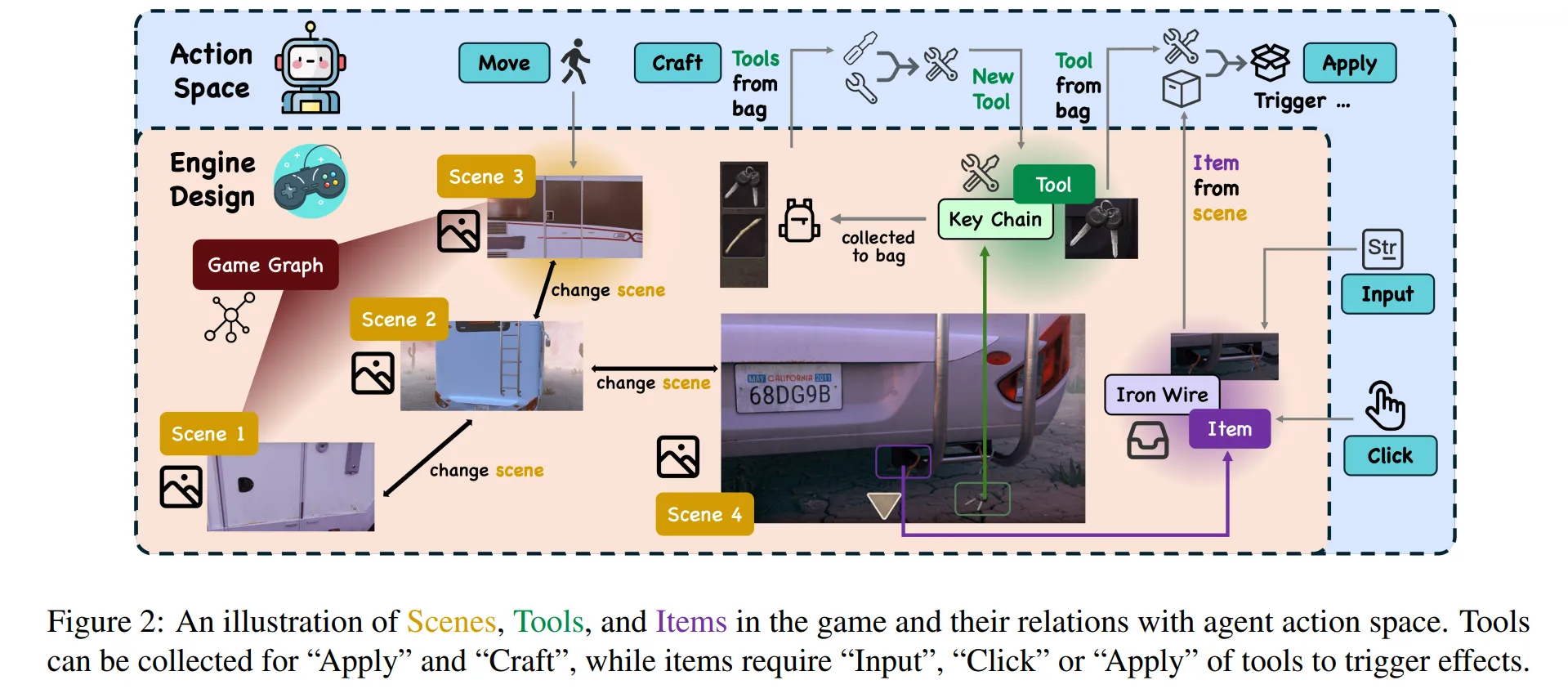
-
각 Scene들은 그래프 형태로 서로 연결되어 있다.
-
Agent가 이동하고, Tool을 Craft하여 New Tool을 얻고, Tools를 가방에 넣어두는 것을 확인할 수 있다.
🔷 2. Action space
Action space에서는 Agent가 취할 수 있는 행동의 종류에 대해 설명한다.
🔻 2-1. Move (Scene)
- 에이전트가 인접한 Scene으로 이동합니다.
🔻 2-2. Click (Item)
- Scene 속에 있는 Item과 간단한 상호작용을 하는 Action이다.
🔻 2-3. Apply (Tool, Item)
-
Bag 속에 있는 Tool을 Item에 적용하는 Action이다.
-
예를 들어 열쇠(Tool)를 이용하여 좌물쇠(Item)를 푸는 action을 생각해볼 수 있다.
🔻 2-4. Input (str, Item)
-
Item에 문자열(str)을 입력하는 action이다.
-
비밀번호나 코드를 입력하는 상황을 생각해볼 수 있다.
🔻 2-5. Craft (Tool, Tool)
-
Bag 속 두 개의 도구(Tool)를 통해 새로운 도구(Tool)를 만드는 Action이다.
-
배터리와 리모컨이 있다면 둘을 결합하여 충전된 리모콘을 만들 수 있다.
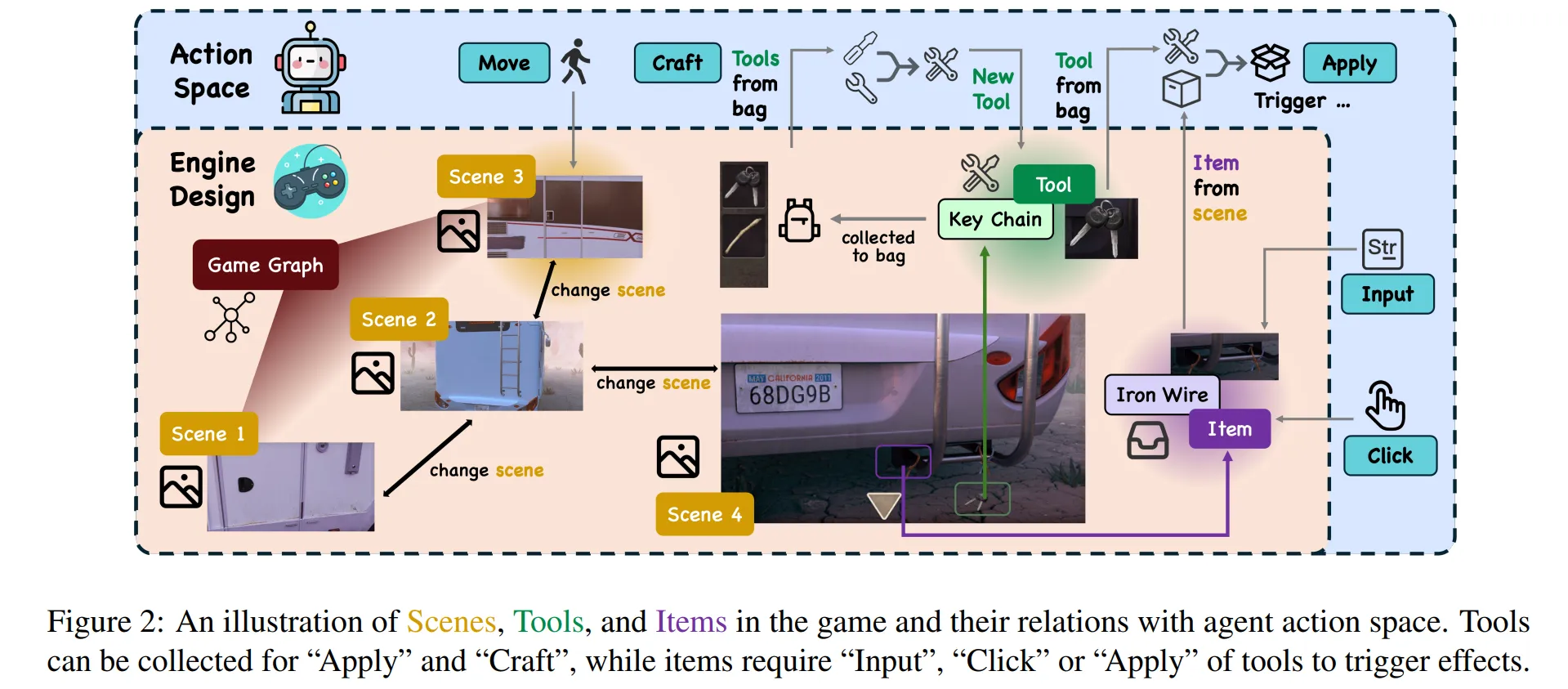
-
Figure2에서 Craft와 Apply가 있는 것을 확인할 수 있다.
-
Craft와 Apply가 모델이 기존에 학습하지 않은 행동을 취하는 가장 혁신적인 Action으로 이해하면 된다.
-
모델은 앞서 설계된 환경(Scene, Item, Tool)에서 Action space의 행동을 통해 동적 상호작용을 수행한다.
🔷 3. Annotation and Statistics
Annotation and Statistics에서는 EscapeBench의 제작 방식과 구성 통계를 설명한다.
🔻 3-1. Annotation & 데이터 구조
-
데이터의 품질을 위하여 모든 내용은 수작업으로 만들어졌다.
-
EscapeBench는 36개의 게임 설정과 3단계의 난이도로 구성되어 있다.

-
Desc는 Item이나 Tool에 대한 설명을 의미한다.
-
Env는 현재 Scene에서의 피드백을 제공한다.
-
Table1은 보면 난이도에 따라 제공하는 설명, 피드백의 디테일, 유무가 결정되는 것을 확인할 수 있다.
🔻 3-2. Statistics
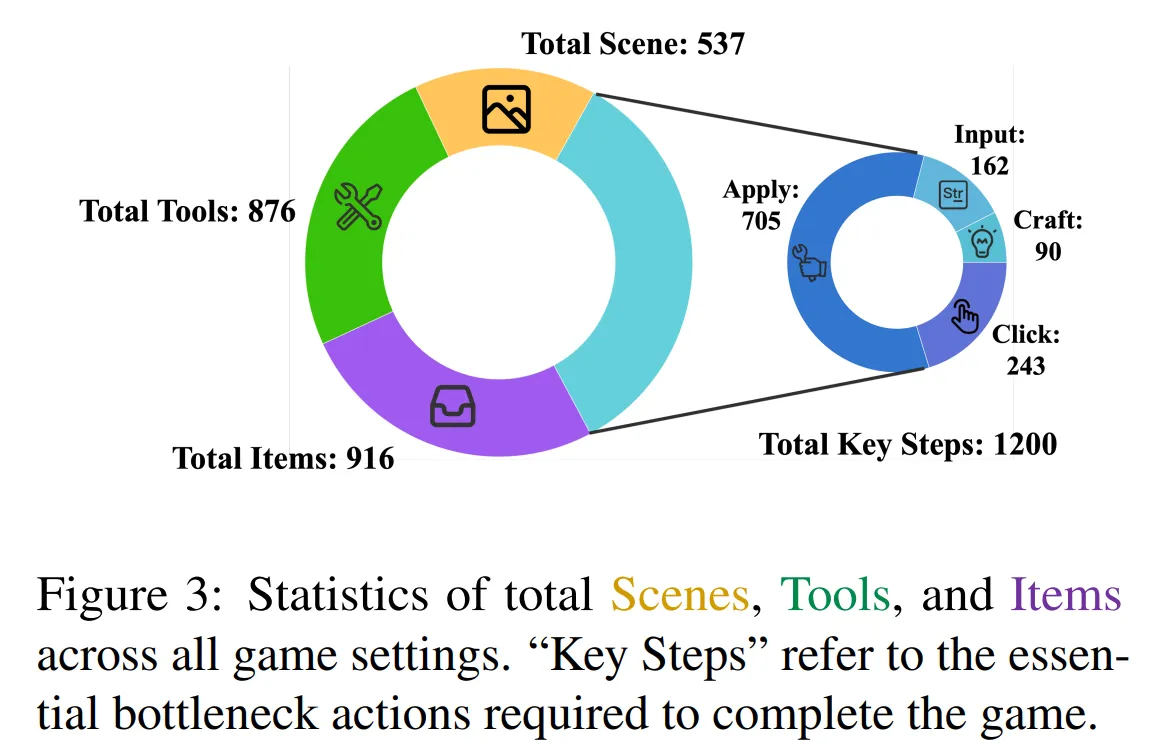
-
데이터 환경과 Action space는 Figure3처럼 구성되어 있는 것을 확인할 수 있다.
-
오른쪽 Total Key Steps는 시나리오를 진행하기 위해 꼭 수행해야 하는 action을 의미합니다.
-
당연히 Total Key Steps 외에도 Agent가 다양한 창의적인 Action을 취할 수 있습니다.
🔷 4. Preliminary Study
Preliminary Study에서는 EscapeBench의 효과를 평가하기 위해 언어모델을 사용한 사전연구 결과에 대해 설명한다.

-
사전연구에서 GPT-4o와 LLaMA-3.1-70B 모델을 사용하였다.
-
가장 오른쪽 컬럼이 정답인 창의적 행동이다.
-
두 모델 모두 창의적 행동에 어려움을 겪는 것을 확인할 수 있다.
4️⃣ EscapeAgent Design
4장에서는 Preliminary Study에서 발견한 기존 언어모델의 한계를 극복하기 위해 제안된 EscapeAgent 프레임워크를 설명한다.
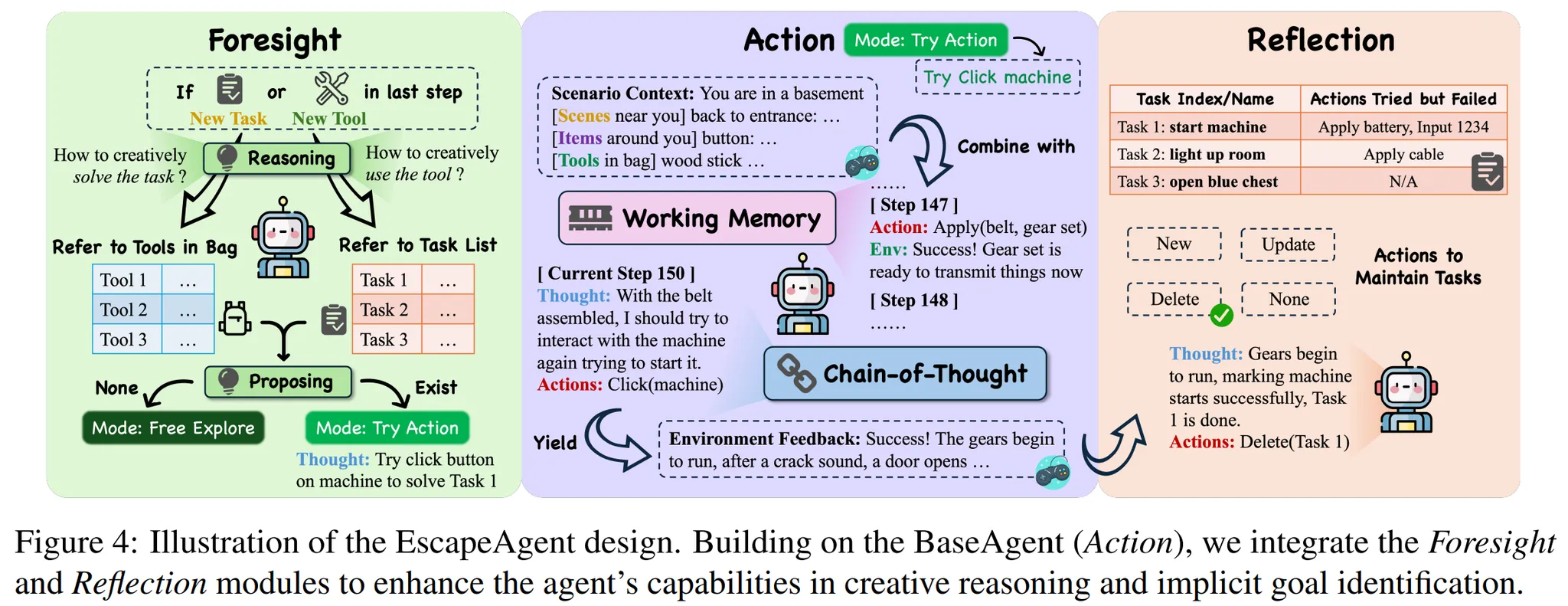
잠시 쉬어가시면서 그림 한번 보시죠!😄
Foresight가 “이런 식으로 도구 사용해보는건 어떨까?” 모듈이고,
Reflection이 “요런 task가 아직 남아있네. 이제 어떤 걸 해볼까?” 모듈이라고 생각하시면 됩니다. 가운데 Action은 Agent라고 생각하시면 되는데 Working Memory에 지금까지 행동과 피드백 등을 저장하고, CoT를 통해 정교하게 판단하고 이해하시면 됩니다.
🔷 1. BaseAgent
- 실제 행동을 취하는 Agent입니다.
- Working Memory를 통해 과거의 행동과 피드백을 저장하여 이를 학습할 수 있도록 합니다.
- BaseAgent는 CoT를 통해 다음 Action을 결정합니다.
🔷 2. Reflection Module
🔻 2-1. Reflection Module의 목적
- 해야할 Task를 정리하여, 앞으로의 행동에 대한 방향성을 제공한다.
🔻 2-2. 작업 목록 관리
- New : 새로운 Task를 발견하면 작업 목록에 저장한다.
- Update : Task별 실패한 Action을 기록한다. 같은 실수를 반복하지 않도록 한다.
- Delete : 해결된 Task를 작업 목록에서 제거한다. Agent가 남아있는 Task에 집중할 수 있도록 한다.
- Figure 4를 보면 Actions Tried but Failed에 실패한 기록이 저장된 걸 확인할 수 있다.
🔷 3. Foresight Module
🔻 3-1. Foresight Module의 목적
- 모델이 창의적 추론을 수행할 수 있도록 한다.
🔻 3-2. Foresight Module 작동 조건
- New Task Identified : Agent가 해결되지 않은 Task를 발견하면, 현재 Tool을 이용하여 취할 수 있는 Action들의 가설을 설정한다.
- New Tool Collected : Agent가 새로운 Tool을 발견하면, 해당 Tool을 통해 기존의 Task를 해결할 수 있는지, 현재 가지고 있는 Tool와 Craft하여 새로운 Tool을 만들 수 있는지 확인한다.
🔻 3-3. 작동 과정
- 작동 조건 과정에서 유효한 가설이 제기되면 “Try Action” 상태로 변환 후 해당 가설을 Task에 적용한다.
- 유효한 가설이 없을 때는 “Free Explore” 상태에서 BaseAgent처럼 작동한다.
- Figure 4의 초록색 영역을 보면 Proposing 중 괜찮은 가설이 있다면 “Try Action” 상태로 변화는 것을 확인할 수 있다.
5️⃣ Experiments
5장에서는 BaseAgent와 EscapeAgent를 나누어 실험을 진행하였다.
🔷 1. Settings
🔻 1. Environment
- 실험은 36개의 게임 설정에서 수행된다.
- Agent가 50회 연속해서 Key step이나 새로운 도구 수집을 못할 경우 Hint를 제공받거나 게임이 종료된다.
🔻 2. Models
- 사용 모델은 Closed source, Open source 모두 사용하였다.
- Closed source : GPT-4o, GPT-4o-mini, Claude-3.5-Sonnet, Gemini-1.5-pro
- Open source : Llama-3.1, Qwen-2.5, DeepSeek-LLM, Yi-1.5, Phi-3.5, Ministral
- 7B 미만의 모델은 성능이 떨어져 제외하였다.
🔻 3. Metrics
🔶 Main Metrics
- Hints Used : 게임에서 사용된 총 힌트 수
- Total Steps : 게임에서 수행한 총 Action 수
🔶 Auxiliary Metrics
- Early Exit Progress : 첫번째 Hint 전까지 수행한 Key step과 도구 수집 비율
- Tool Hints Used(%) : 총 도구 수 중 도구 수집을 위해 사용한 Hint 수
- Key step Hints Used(%) : 총 Key Steps 중 Hint를 사용하여 통과한 Key step의 수
🔷 2. Benchmarking Results
Benchmarking Results에서는 BaseAgent에 대한 평가가 진행되었습니다.
👨🔬 실험 결과를 잠시 살펴보도록 하겠습니다.
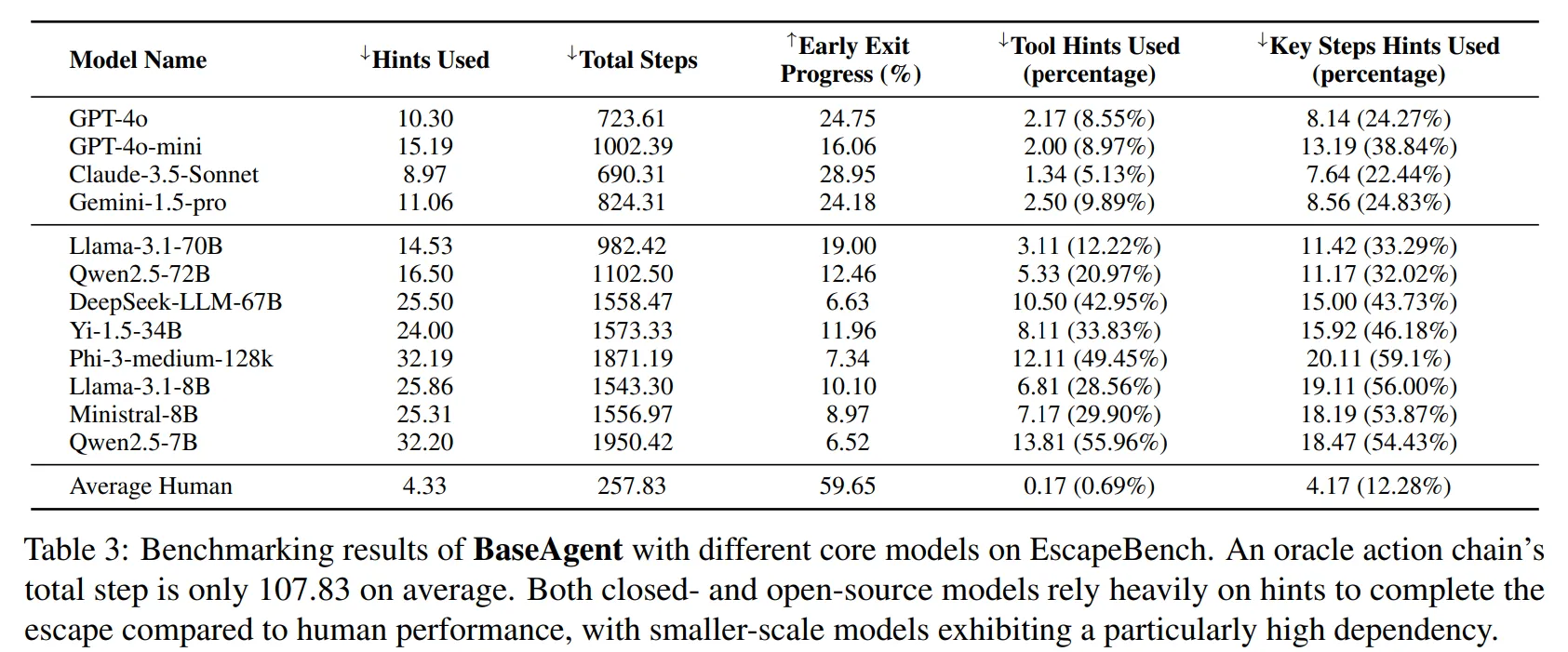
-
Table 3을 보면 Closed source 모델이 상대적으로 뛰어난 성능을 발휘함을 알 수 있습니다.
-
실험 결과 대부분의 Hint는 창의적 행동 추론 요구 단계에서 사용된 것을 확인할 수 있다.
-
모델은 평균적인 사람보다 더 많은 step이 필요하며, 최적의 경로 대비 최대 20배 많은 step를 사용하였다.
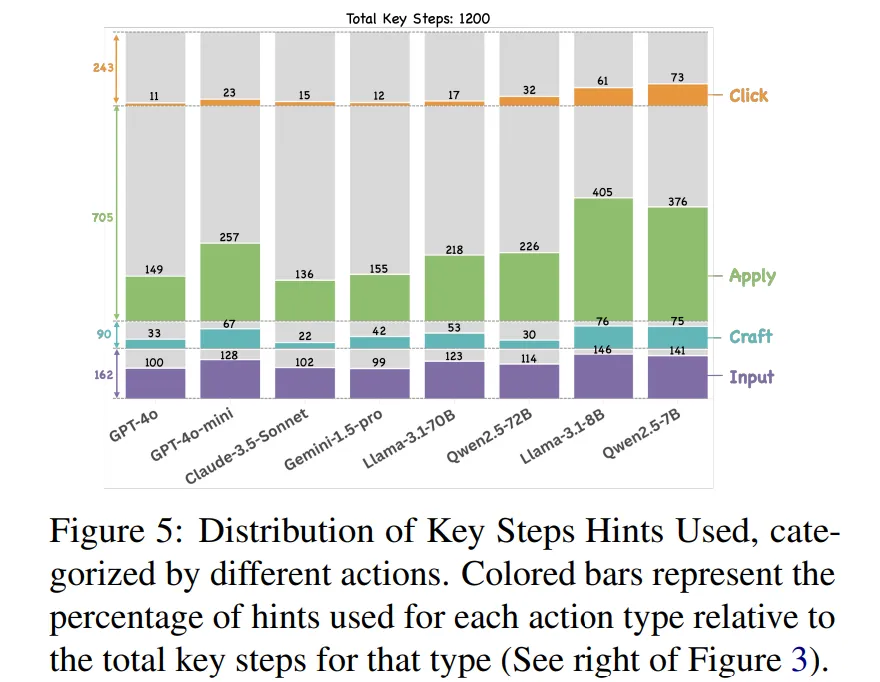
-
Figure 5는 모델별 Action 유형에 따라 사용한 Hint 개수이다.
-
절대적인 사용량은 Apply가 많지만, 각 Action 유형별 사용 비율을 보면 Craft와 Input의 비율이 가장 높은 것을 확인할 수 있다.
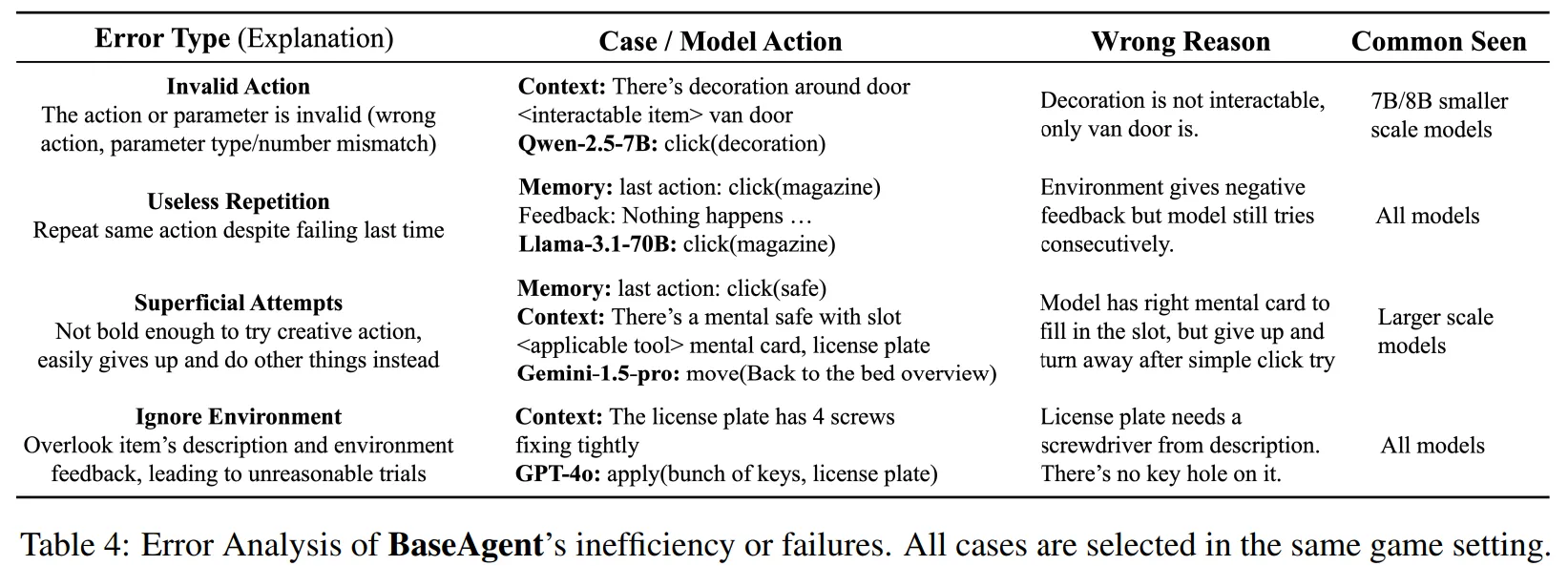
-
Table 4에서 BaseAgent들이 어떤 유형의 오류를 많이 겪으며, 어떤 유형의 모델이 이러한 문제를 많이 겪는지 설명한다.
-
Invalid Action : 모델이 게임 규칙을 제대로 이해하지 못하여 규칙에 어긋한 행동을 하는 경우 ⇒ 파라미터가 작은 모델에서 자주 발생.
-
Useless Repetition : 모델이 피드백을 받았음에도 불구하고 실패한 Action을 반복하는 경우 ⇒ 모든 모델에서 관찰
-
Superficial Attempts : 모델이 Action 실패 시 쉽게 포기하는 경우 ⇒ 큰 모델에서 관찰
-
Ignore Environment : 주어진 환경을 무시하고 잘못된 행동을 하는 경우 ⇒ 모든 모델에서 관찰
🔻 2-1. Challenging Action : Input and Craft
-
Hint 사용 비율을 통해 Input과 Craft가 가장 어려운 Action임을 알 수 있습니다.
-
이는 각 action이 모델에게 창의적 행동을 요구하는 것으로 이해할 수 있습니다.
🔻 2-2. Error analysis
-
Table 3의 Key step Hints Used 비율을 보면, 대부분의 Hint가 Tool 수집이 아닌 창의적 사고를 요구하는데 사용된 것을 확인할 수 있다.
-
Table 4를 통해 작은 모델은 게임 규칙을 이해하는데, 큰 모델은 포기하지 않고 창의적 사고를 하는 것에 어려움을 겪는 것을 확인할 수 있다.
🔷 3. EscapeAgent Results
EscapeAgent Results에서는 EscapeAgent의 실험 결과를 설명합니다.
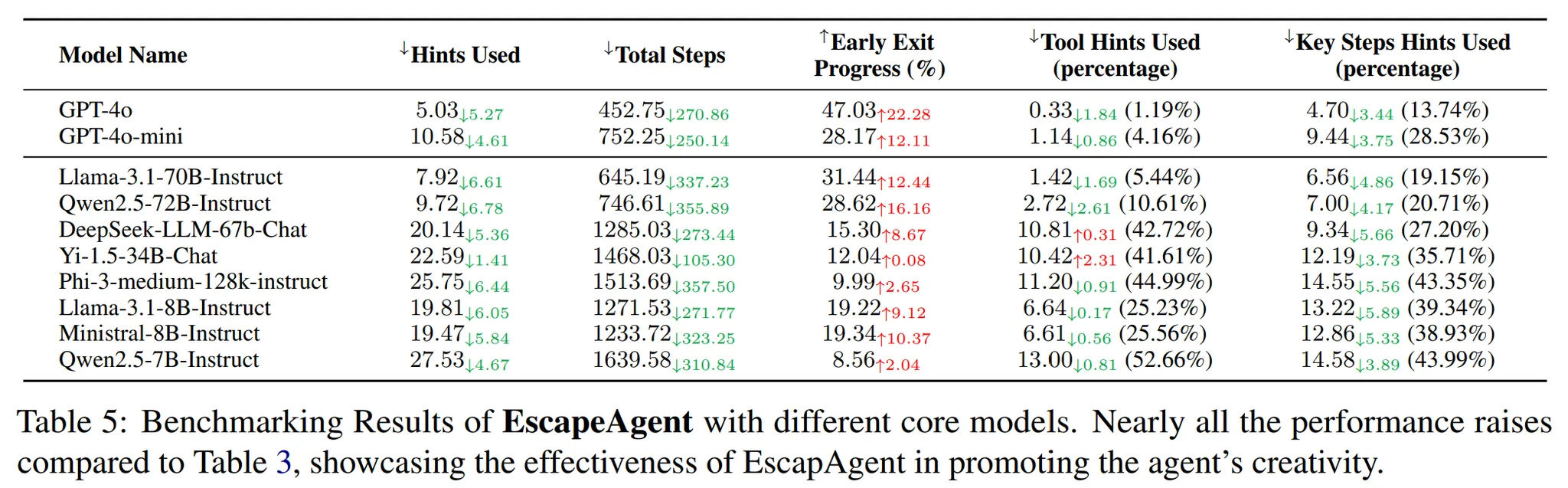
-
Table 5를 보면 EscapeAgent 프레임워크를 도입하였을 때 더 적은 Hint를 사용하고, 더 적은 단계로 Key step을 해결한 것을 확인할 수 있다.
-
크기가 큰 모델이 더 좋은 성능을 발휘하는 것을 확인할 수 있다. ⇒ 여전히 Core 모델이 중요하다는 것을 알 수 있다.
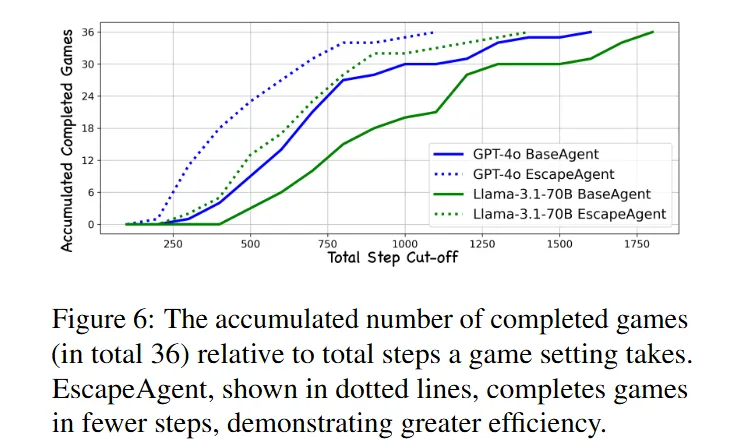
- Figure 6을 보면 EscapeAgent가 더 적은 step으로 게임을 빠르게 진행하는 것을 확인할 수 있다.
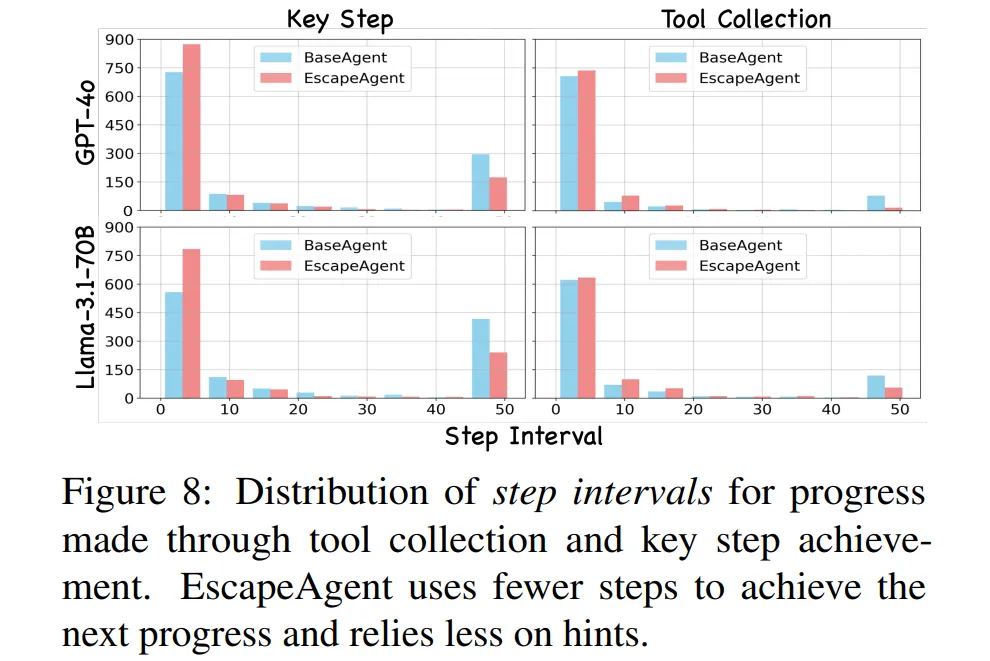
-
Figure 8에서 역시 EscapeAgent가 더 적은 step을 통해 Key Step을 해결하고, Tool을 수집한 것을 확인할 수 있다.
-
Step 50에서는 Hint를 사용하여 해결하지 못한 Key Step이나 Tool 수집을 수행한 것을 관측할 수 있다.
-
15 step 이후에는 BaseAgent와 EscapeAgent 모두 게임을 진행하지 못하는 모습을 관측할 수 있다. ⇒ 인간에게 존재하는 창의성이 아직 부족하다는 것을 의미한다.
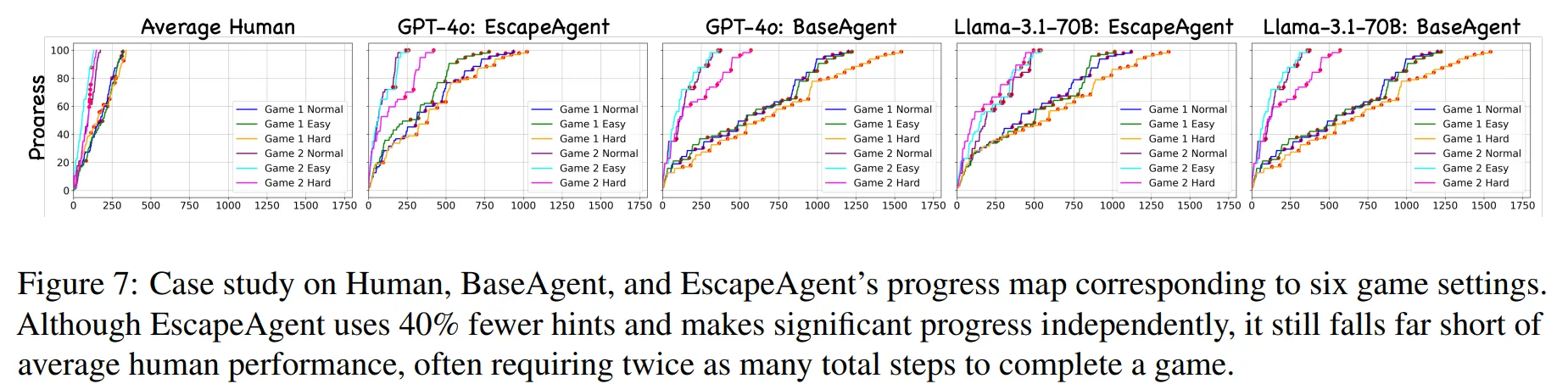
-
Figure 7은 사람과 BaseAgent, EscapeAgent의 성능을 비교한다.
-
그래프 속 빨간색 점이 사용된 Hint를 의미한다.
-
EscapeAgent가 BaseAgent와 비교하여 더 적은 Hint로 빠르게 EscapeBench를 진행하는 것을 확인할 수 있다.
-
하지만 사람과 비교하여, 단기기억, 긴 맥락 이해, 창의적 도구 사용 등 개선사항이 있음을 알 수 있다.
6️⃣ Further Analysis
6장에서는 EscapeBench와 EscapeAgent에 대한 분석 결과를 설명한다.
🔷 1. Evaluation across Diverse Models
🔻 1-1. 분석 목표
- 다양한 크기와 도메인 모델을 사용하여 EscapleAgent 프레임워크의 확장성 및 일반화 능력을 분석한다.
🔻 1-2. 분석 결과
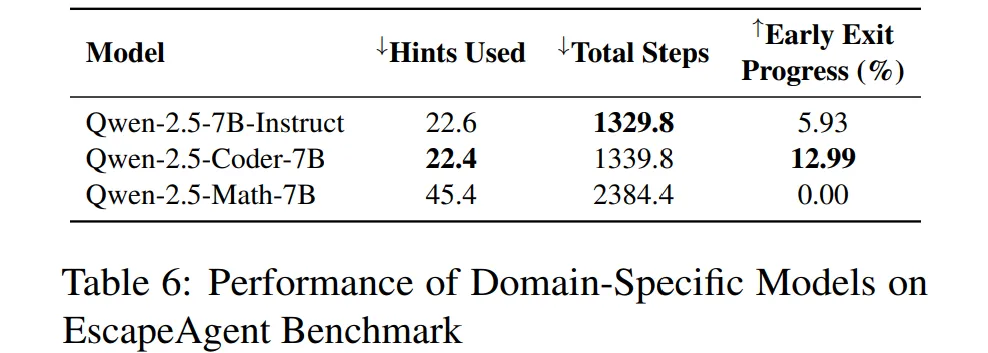
-
적어도 7B 이상의 모델부터 EscapeBench에 대한 유의미한 평가가 가능하다.
-
Qwen-2.5-Coder-7B과 같은 코딩 도메인 모델은 별다른 어려움 없이 추론 능력을 유지하였다.
-
Qwen2.5-Math-7B와 같은 지나친 전문적 도메인은 모델의 창의적 다단계 능력을 훼손하였다.
🔷 2. Ablation Study on Key Modules
🔻 2-1. 분석 목표
- EscapeAgent 프레임워크의 핵심 모듈인 Foresight와 Reflection이 각각 전체 성능에 어느 정도 기여하는지 분석한다.
🔻 2-2. 분석 결과
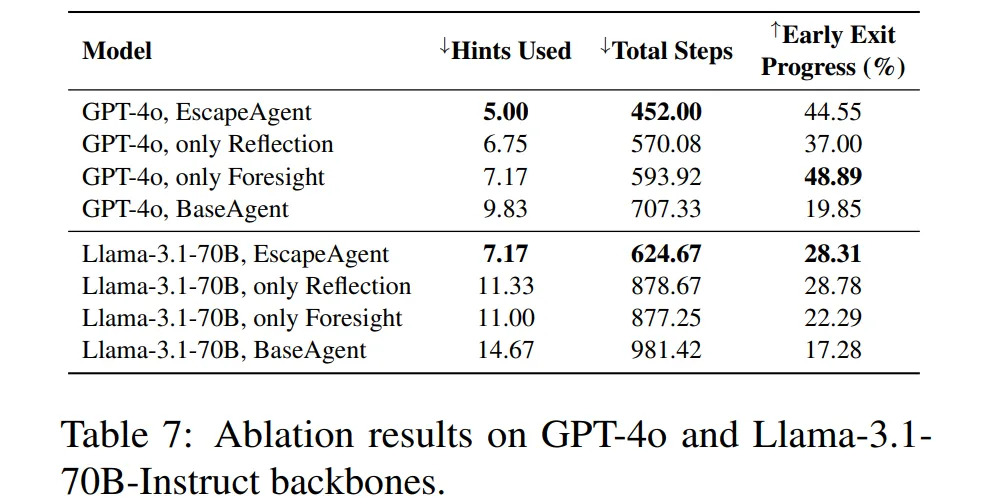
-
Foresight와 Reflection 모듈을 모두 사용하였을 때 가장 뛰어난 성능을 발휘한다.
-
논문에서는 Reflection이 더 중요하다고 설명하지만, 개인적으로 Table 7만 보았을 때는 잘 모르겠다.
7️⃣ Discussions and Future Directions
7장에서는 현재 LLM 모델의 창의성 한계와 앞으로의 연구 방향에 대해 이야기한다.
🔷 1. LM’s creativity for benchmarking
-
EscapeAgent를 사용하더라도, 평균적인 사람보다 더 많은 Hint와 단계가 필요하다.
-
LLM 모델의 창의성을 향상시키기 위해 모델이 사물의 속성을 이해하고, 지식을 객체와 연결하는 능력을 키워야 한다.
🔷 2. Theoretical Foundations for AI Creativity
-
인간의 창의성은 확률적 신경 노이즈와 구조화된 지식 사이의 상호작용으로 발현된다.
-
반면 AI의 창의성은 훈련된 데이터 패턴과 알고리즘에 의존한다.
-
심리학 및 신경과학의 통찰력을 토대로 AI의 창의성을 향상시킬 수 있다.
🔷 3. Human-AI Collaboration
-
인간은 AI가 생각하지 못한 통찰이나 아이디어를 제공한다.
-
AI는 정보 수집과 논리적 사고에 뛰어나다.
-
인간의 창의성과 AI의 추론 능력을 합하면 뛰어난 문제 해결 능력을 이끌어낼 수 있다.
8️⃣ Conclusion
8장에서는 논문의 기여와 앞으로의 연구방향에 대해 설명한다.
🔷 1. 논문의 기여
-
창의적 지능 향상을 위한 최초의 벤치마크 EscapeBench를 구축하였다.
-
EscapeAgent를 통해 창의적 도구 사용과 목표 탐색 능력을 향상시켰다.
🔷 2. 앞으로의 연구 방향
-
Multi-Modal Perception 연구를 통해 모델의 창의적 추론 능력을 향상시킬 수 있다.
-
강화학습 알고리즘을 적용하여 창의적 추론 능력을 향상시킬 수 있다.
9️⃣ 내 생각
AI의 창의성에 대한 논문은 처음 읽어봐서 생각보다 더 흥미롭게 논문을 읽었다. 논문 중간에 Instruction Tuning된 모델이 사용되는 것을 본 후, 모델이 환경에 대한 피드백, 창의적 사고를 유도할 수 있는 파인튜닝 데이터셋을 만들어보면 재밌을 것 같다는 생각이 들었다. 논문을 읽을수록 결국 BackBone 모델이 LLM이라 LLM 관련 지식이 많이 필요하다는 것이 느껴졌다.
