
🥴 Pandas (7)
📌 결측값 채우기
💛 원하는 값을 채우는 fillna
df["원하는 칼럼"] = df["원하는 칼럼"].fillna(원하는 값) # 새로운 변수에 할당 안 하고 inplace = True를 사용할 수 있다 # if 특정 칼럼의 통계값을 넣고 싶은 경우 height_mean = df["키"].mean() df["키"].fillna(height_mean)
💛 빈 값이 있는 행을 제거하는 dropna
1. df.dropna() # 빈 값이 있는 행을 모두 제거하기 2. df.dropna(axis=0) # 빈 값이 있는 경우에 행을 제거해준다 3. df.dropna(axis=1) # 빈 값이 있는 경우에 열을 제거해준다 4. df.dropna(axis=0, how='any') # 빈 값이 1개라도 있는 경우에 행을 제거해준다 # 4번 == 2번 5. df.dropna(axis=0, how='all') # 빈 값이 모두 없는 경우에 행을 제거해준다
💛 중복된 값을 제거하는 drop_duplicates
기본적으로 처음에 나온 값은 유지되고 그 뒤에 나온 값이 삭제된다.
1. df["원하는 칼럼명"].drop_duplicates() 2. df["원하는 칼럼명"].drop_duplicates(keep = "first") # 1번 == 2번 3. df["원하는 칼럼명"].drop_duplicates(keep = "last") 4. df.drop_duplicates("원하는 행") # 원하는 행에서 겹치는 값을 모두 제거시켜준다.
💛 column 제거하는 df.drop
df.drop("원하는 칼럼", axis=1) df.drop(["원하는 칼럼1", "원하는 칼럼2"], axis=1)
💛 row 제거하는 df.drop
df.drop("원하는 인덱스 번호", axis=0) df.drop(["원하는 인덱스 번호1", "원하는 인덱스 번호2"], axis=0)
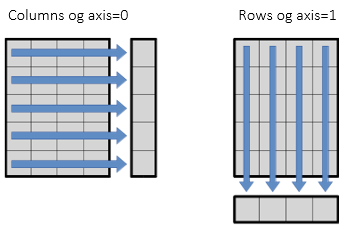
정리하자면
- axis=0
행을 의미한다. - axis=1
열을 의미한다.
이게 가끔 헷갈릴 때가 있으니까 주의하자.

알고리즘과 데이터 과학과 웹 개발을 공부하는 대학생