
[ML] 머신러닝 기본기 정리하기
1. 머신러닝의 정의와 용어
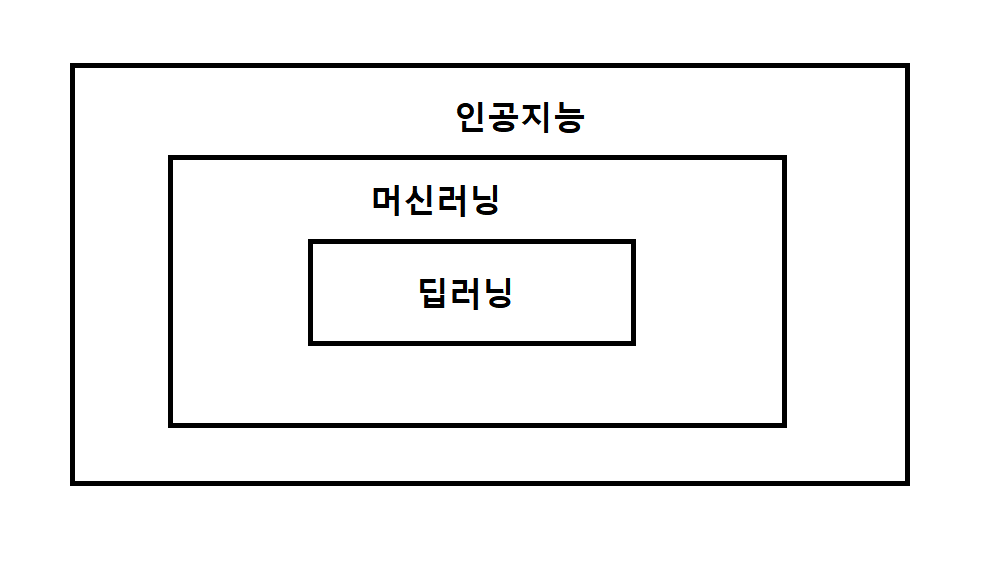
- AI (인공지능) : 인간의 뇌 모방하여 복잡한 일 처리할 수 있도록 기계를 만드는 것이다.
- 머신러닝 : 알고리즘 이용 > 학습 > 예측 및 판단한다. 사람이 직접 feature를 선택해야 한다.
- 딥러닝 : 머신러닝의 한 종류이고 사람이 직접 feature를 선택하지 않아도 된다.
-
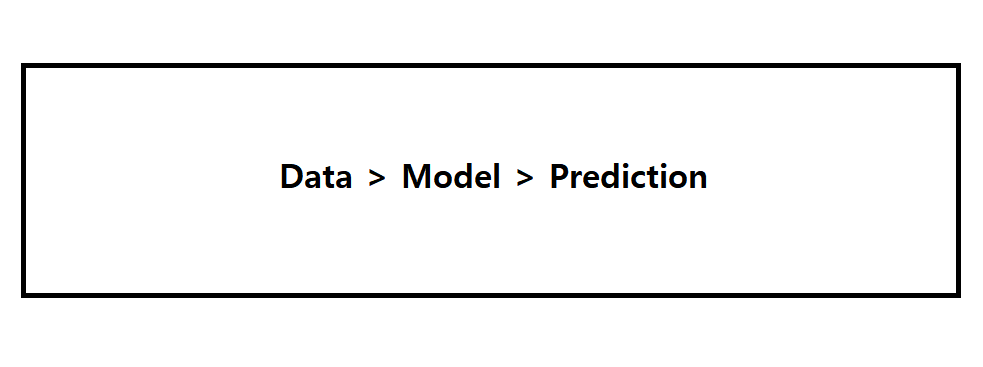
머신러닝의 원리 :
데이터 기반으로 패턴학습을 하여 예측한다.즉 데이터와 예측해야할 값만 알면 알아서 예측한다. 이 때 양질의 풍부한 데이터와 (EDA가 필요하다.) 적절한 알고리즘이 필요하다. -
블랙박스 현상 : 인공지능이 어떤 근거로 판단하는지 알 수 없다.
-
과거에는 사람이 직접 알고리즘을 짰다. 하지만 현재에는 데이터와 예측해야할 값만 존재한다면 AI가 패턴학습을 통해 학습한다.
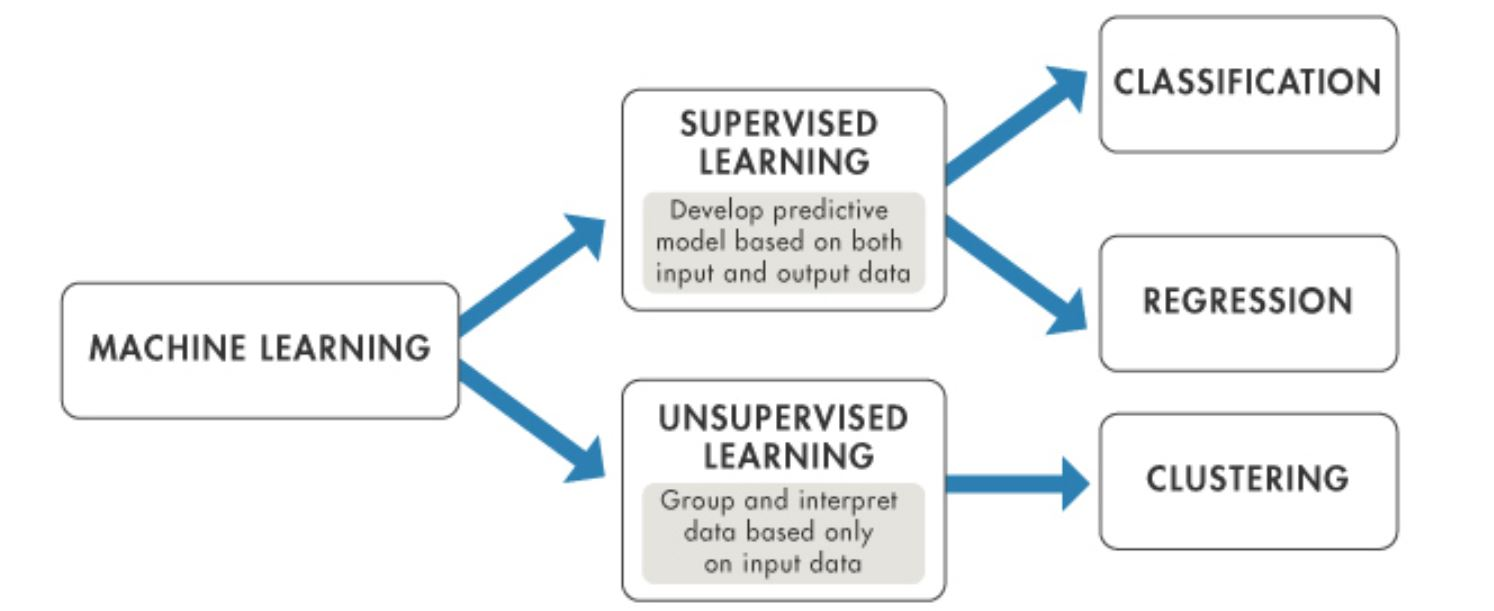
머신러닝은 지도학습과 비지도학습으로 나뉜다. (cf. 강화학습도 있다.)
- 지도학습 (y-label이 있는 경우) : 분류(이산형)와 회귀(연속형)이 있다. (예를 들면 분류의 예시는 강아지/고양이 분류, 회귀의 예시는 집값 예측 등이 있다.)
- 비지도학습 (y-label이 없는 경우) : 클러스터링과 차원 축소가 있다.
머신러닝에서 가장 중요한 것 : 풍부한 양질의 데이터 (전처리 과정이 반드시 필요하다.) + 적절한 알고리즘
2. 머신러닝 원리
가설함수, 비용, 손실함수에 대하여 알아보자.
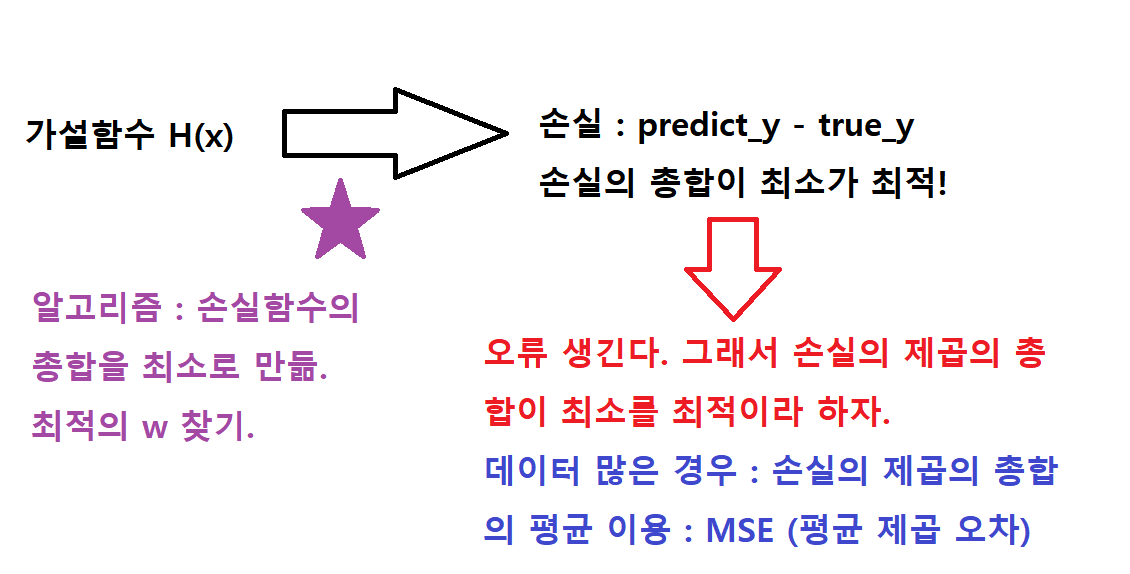
- 가설함수 : H(x)이다. 가설함수를 세운 후, 머신러닝으로 예측한다. 여기서 predict_y의 값을 얻을 수 있다.
- 손실 (loss) : predict_y - true_y 이다. 오차라고도 한다.
- 손실함수 : H(x) - y = (wx + b) - y
- 손실의 총합의 제곱의 오차 : 손실의 제곱의 총합을 의미한다. 작을수록 최적이다.
- 평균 제곱 오차 :
데이터의 개수가 많은 경우, 손실함수의 제곱의 총합의 평균을 이용한다. 작을수록 최적이다.

머신러닝 원리는 손실이 최소가 되는 최적의 w를 찾는 것이다.
학습을 하면서 저 별표 지점 (손실이 최소가 되는 지점) 까지 도달해야 학습이 잘 된 모델이 된다.
3. Sklearn 사이킷런
필요한 모듈은 미리 모두 불러오기.
Step 1. 모델 선언하기.
모델()Step 2. 모델 학습하기.
모델.fit(train_x, train_y)Step 3. 모델 예측하기.
모델.predict(train_x)4. 학습 데이터과 테스트 데이터
- 학습 데이터 : 학습할 때에 사용한다. (train_x, train_y)
- 테스트 데이터 : 테스트 시에 이용된다.
학습 시에는 반드시 이용하면 안된다.
Step 1. x, y 구하기. (예측할 값의 유무)
difference 이용하여 예측할 값을 찾아내서 x, y를 나눠준다.Step 2. train, test 구하기. (train에는 feature, label 모두 존재하고 test에는 feature만 존재한다.)
sklearn의 train_test_split를 이용하여 나눠준다.- 학습 (feature, label) : train_x, train_y
- 테스트 (label) : test_x
5. 검증 데이터 (Validation)
- overfitting (과대 적합, 일반화가 잘 되지 않은 경우)
- optimum (최적의 성능, 몇 개의 오차는 있을 수 있다.)
- underfitting (과소 적합, 학습이 잘 되지 않은 경우)
훈련 데이터로 학습한 것을 테스트 데이터로 확인하면 위와 같은 현상들이 발생할 수 있다.
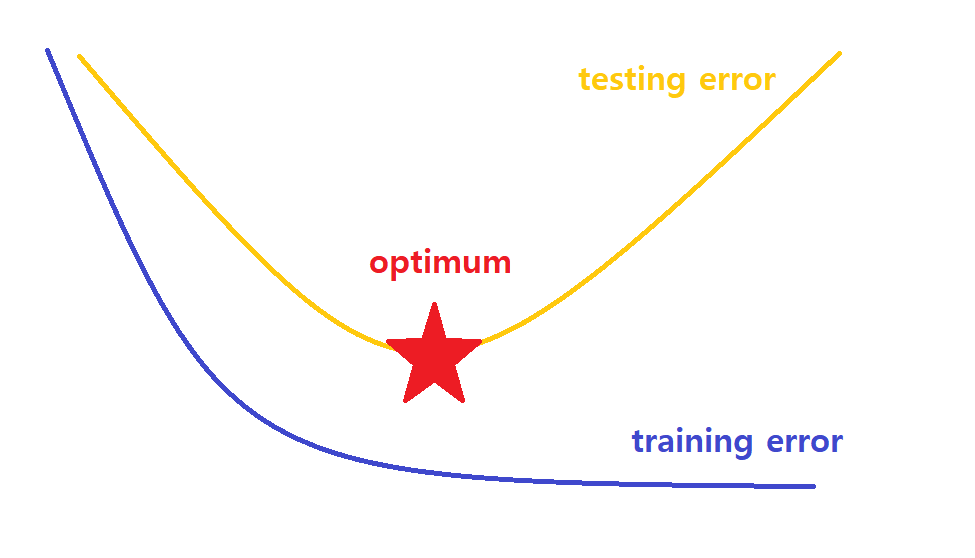
파란색 선이 training error, 노란색 선이 testing error이다. training error는 학습이 진행되면서 줄어들지만, testing error는 어느 순간에 다시 올라가는 것을 볼 수 있다. 따라서 testing error가 최소인 지점이 optimum이다.
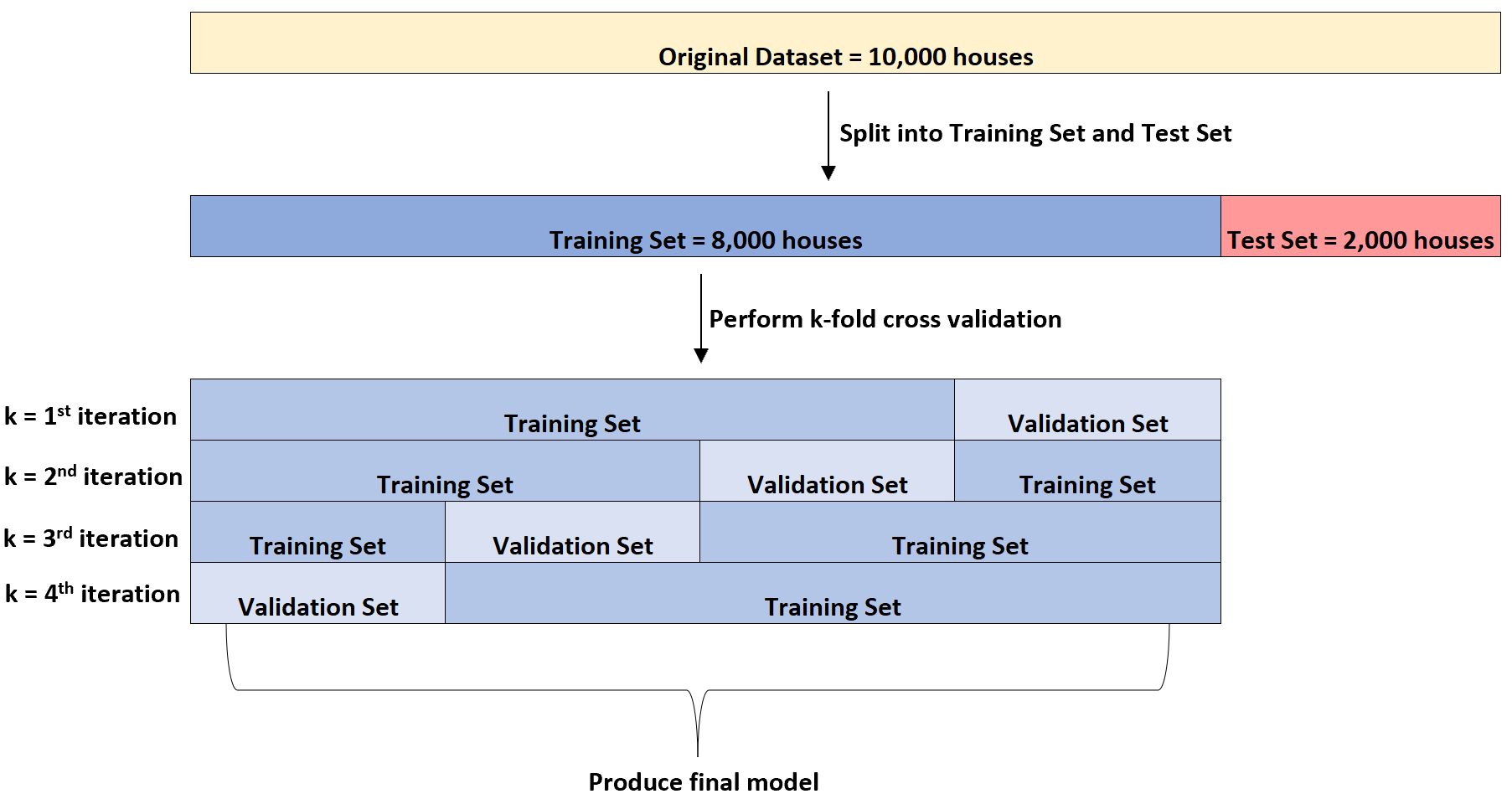
-
검증 데이터 :
모의고사이다.optimum을 찾기 위한 핵심적인 기술이다.일반적으로 학습 데이터와 검증 데이터 비율은 8 : 2이다. 그리고 학습 시 검증 데이터가 관여하면 안된다. -
검증 데이터로부터 optimum 찾는 방법 :
validation error가 증가하는 시점이 optimum이다. (위와 같은 논리이다. training error ~ testing error)
train_test_split를 이용하여 훈련 데이터와 검증 데이터 나눠준다.
검증 데이터의 생성에 의하여 학습 데이터의 양이 적어졌기 때문에 교차 검증을 이용하여 데이터를 분리한다.
6. 데이터 전처리 (pre-processing)
Garbage In, Garbage Out을 막기 위해 데이터를 전처리 한다. 이상치가 많거나 데이터 모양이 모두 다른 경우 이용된다.
- 결측치 처리 - Imputer
- 이상치 처리
- 정규화 - Normalization (0 ~ 1 사이의 값으로 맞춰주기.)
: (예시)동일 scale 분포 안에 넣고 싶은 경우, 값 차이가 너무 큰 경우 (머신러닝의 성능을 낮출 수 있기 때문이다.) - 표준화 - Standardization (평균이 0, 표준편차를 1로 맞춰주기.)
- 샘플링 (Over Sampling 또는 Under Sampling)
: (예시 1) 정상 환자에 비해 암 환자가 극히 적은 경우 (정상인과 샘플을 맞춰주는 작업을 진행한다.) ∴ over sampling
(예시 2) 지나치게 샘플이 많은 경우 ∴ under sampling
∴ 샘플링은 데이터의 편향성을 고려해줘서데이터의 개수를 맞춰주는 역할을 한다. - 피처 공학 (Feature Engineering)
: (예시) feature + feature = new feature 등
[실전] 데이터 전처리 예시 코드
타이타닉 데이터를 이용하여 전처리를 해보겠다.
Step 1. train / valid 데이터 나누기.
- X, y 나누기.
- train_x, train_y, valid_x, valid_y 나누기. 대체로 8 : 2로 나누는 편이다.
stratify = y를 이용하면 y의 라벨을 고려하여 나눠주는 편이다.
from sklearn.model_selection import train_test_split
train_x, valid_x, train_y, valid_y = train_test_split(X, y,
test_size=0.2, stratify=y)이 데이터에서는 feature를 Pclass, Sex, Age, Fare만 이용한다.
Step 2. [전처리] 결측치 처리하기.
from sklearn.impute import SimpleImputer[방법 1] 수치형 데이터 결측치 처리하기.
imputer = SimpleImputer(strategy = "mean")
imputer.fit(train[["Age", "Pclass"]])
result=imputer.transform(train[["Age", "Pclass"]])
train[["Age", "Pclass"]] = result위와 같이 fit, transform을 따로 사용할 수도 있지만, fit_transform을 이용할 수도 있다.
imputer = SimpleImputer(strategy = "mean")
result = imputer.fit_transform(train[["Age", "Pclass"]])
train[["Age", "Pclass"]] = resultstrategy는 원하는 것으로 변경 가능하다.
[방법 2] 범주형 데이터 결측치 처리하기.
imputer = SimpleImputer(strategy = "most_frequent" )
result = imputer.fit_transform(train[["Embarked", "Cabin"]])
train[["Embarked", "Cabin"]] = resultStep 3. [결측치] 문자를 수치형으로 변환하기.
라벨 인코딩을 이용하여 문자 데이터를 수치형 데이터로 변경하자. 컴퓨터는 수치형만 읽을 수 있기 때문에, 라벨 인코딩을 이용하여 수치형으로 변경하는 것이 좋다.
from sklearn.preprocessing import LabelEncoderSex와 Embarked가 문자 데이터이기 때문에 수치형으로 변경해야 한다.
le = LabelEncoder()
train["Sex_num"] = le.fit_transform(train["Sex"])inverse_transform()을 이용하여 수치형 데이터에서 문자 데이터로 복구 가능하다.
train["Sex num to str"] = le.inverse_transform(train["Sex_num"])np.nan 값이 존재하면 LabelEncoder가 잘 안되기 때문에 반드시 결측치 처리 후 라벨 인코딩 진행하기.
Step 4. [결측치] 숫자를 독립적으로 만들어주기.
원핫인코딩을 이용하여 숫자를 독립적으로 만들어야 한다.
Embarked를 라벨 인코딩을 해주면 {"S" : 2, "C" : 0, "Q" : 1} 이라고 처리된다.
하지만 독립적이지 않기 때문에 S = Q + Q가 아님에도 불구하고 숫자형 데이터에서는 만족해버린다. 따라서 독립적인 수치형 데이터로 만들기 위하여 원핫인코딩 작업이 필요하다.
one_hot = pd.get_dummies(train['Embarked_num'])one_hot에 Embarked_num이 원핫인코딩 처리되어 데이터프레임으로 되어있다.
Step 5. 정규화와 표준화
- 정규화 : 칼럼 간 다른 min, max를 가지는 경우에 정규화를 통하여 동일한 scale로 맞춰준다.
- 표준화 : 평균을 0, 표준편차를 1로 만들어준다. (이상치가 있는 경우 이용한다.)
from sklearn.preprocessing import MinMaxScaler # 정규화
from sklearn.preprocessing import StandardScaler # 표준화
ms = MinMaxScaler()
result = ms.fit_transform(data)
pd.DataFrame(result, columns=[필요한 칼럼명 넣어주기.])
ss = StandardScaler()
result=ss.fit_transform(data)
pd.DataFrame(result, columns=[필요한 칼럼명 넣어주기.])위의 예제에서는 사용되지 않았지만 많이 이용되는 기술이기 때문에 기억해두기.
