
[ML] Iris 데이터를 이용한 분류 모델
0. Iris 데이터 처리 및 시각화
Step 1. Iris 데이터 프레임 만들기.
from sklearn.datasets import load_iris
iris = load_iris()iris 데이터를 불러왔는데, dictionary 형태이다. 데이터 프레임 형태로 변경해야 모델 학습 및 예측이 용이하기 때문에, 데이터 프레임 형태로 고쳐보자.
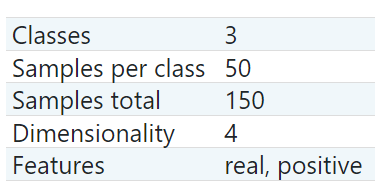
DESCR: 데이터셋의 정보를 보여준다. (description)data: feature datafeature_names: feature data의 컬럼 이름target: label data (수치형)target_names: label의 이름 (문자형)
data의 형태는 (150, 4)이고 target의 형태는 (150, )인 벡터이다. 그리고 feature (dimensionality)는 4개이며, class는 3개이다.
data=iris.data # iris feature data
target=iris.target # iris target data
feature_names=iris.feature_names # iris feature names
target_names=iris.target_names # iris target names
df_iris=pd.DataFrame(data, columns=feature_names)
# feature data dataframe
df_iris["target"]=target # add target data
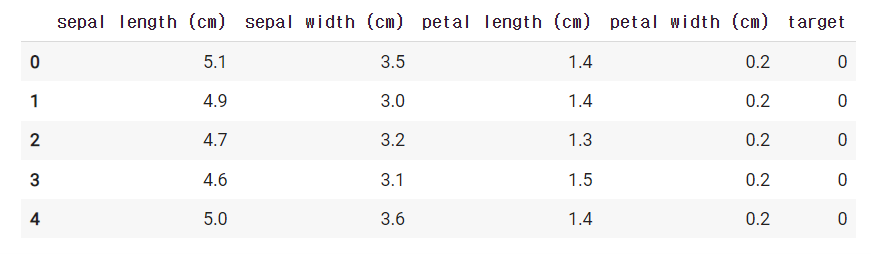
df_iris.head()iris 데이터를 df_iris 라는 데이터 프레임으로 만들어주었다.
Step 2. Iris 데이터 시각화하기.
df_iris는 target이 숫자로 되어있어 시각화하는 경우에 보기가 불편하다. 따라서 숫자를 target_names로 변경하여 df_iris_visual 데이터 프레임을 만들자.
df_iris_visual=df_iris.copy()
df_iris_visual.head()
df_iris_visual["target"]=df_iris_visual["target"].map({0:'setosa', 1:'versicolor', 2:'virginica'})
df_iris_visual.head()이렇게 직접 숫자와 target_names를 넣을 수도 있지만, class가 많은 경우에는 하기 힘들 수 있다.
따라서 리스트 컴프리헨션을 이용하여 dict을 만들어보자.
Step 1. set을 이용하여 target에 어떤 숫자가 있는지 살펴보기.
Step 2. list + append 이용하여 key값 채우기.
Step 3. 리스트 컴프리헨션 이용하여 값이 0인 dict 만들어주기.
Step 4. dict의 값에 원하는 값 채우기.
# step 1. target에 어떤 숫자가 있는지 확인하기.
set(iris.target) # target에 들어있는 숫자 알 수 있다.
# step 2. append 이용하여 리스트에 넣어주기.
target_list=[]
for key in range(3):
target_list.append(key)
print(target_list)
# step 3. 리스트 컴프리헨션 이용하여 딕셔너리에 넣어주기.
target_dict={key : 0 for key in target_list}
target_dict # {0: 0, 1: 0, 2: 0}
# step 4. 딕셔너리 value에 값 넣어주기.
for idx in range(3):
target_dict[idx]=iris.target_names[idx]
"""
target_dict[0]=iris.target_names[0]
target_dict[1]=iris.target_names[1]
target_dict[2]=iris.target_names[2]
"""귀찮으면 리스트 컴프리헨션 이용 시에 dict의 값을 채워버릴 수도 있다.
{key : iris.target_names[key] for key in target_list}이후에는 동일하게 map을 이용하여 변경해주면 된다.
- sepal width와 sepal length 간 산점도 살펴보기.
fig = plt.figure(figsize=(6,4), dpi=200)
sns.scatterplot(data=df_iris_visual, x="sepal width (cm)"
, y="sepal length (cm)", hue="target", palette="Set1")
plt.title('Sepal')
plt.legend(fontsize=8)
plt.show()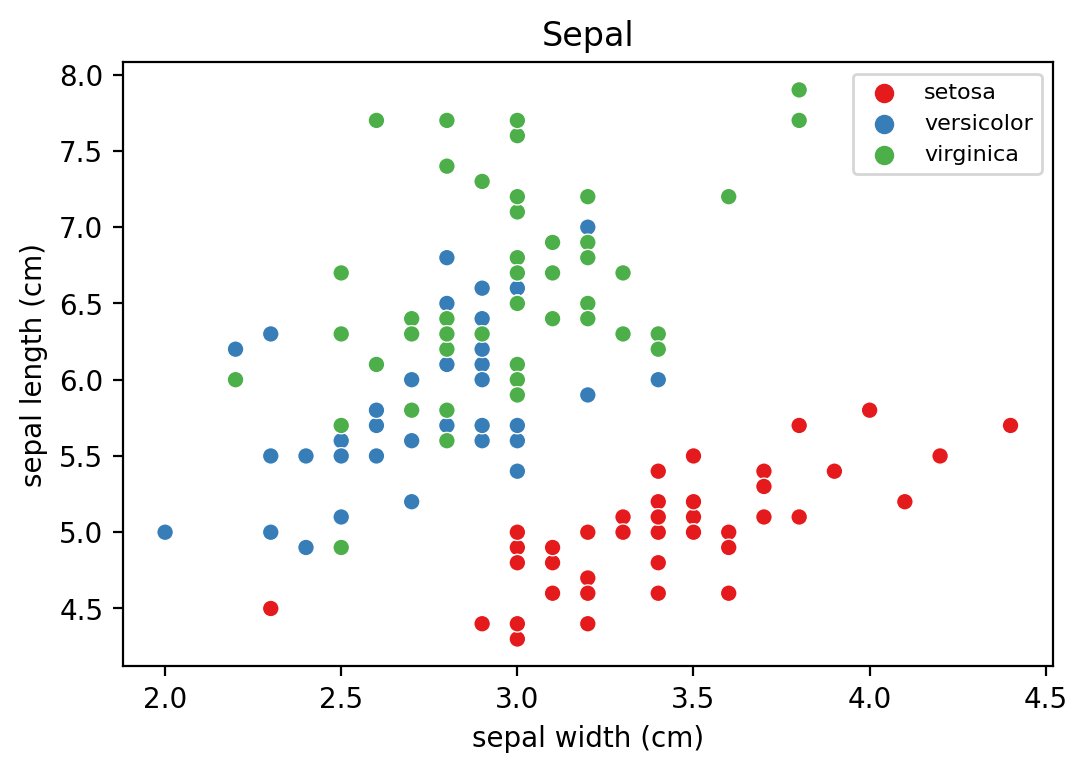
- petal width와 petal length 간 산점도 살펴보기.
fig = plt.figure(figsize=(6,4), dpi=200)
sns.scatterplot(data=df_iris_visual, x="petal length (cm)"
, y="petal width (cm)", hue="target", palette="Set1")
plt.title('Petal')
plt.legend(fontsize=8)
plt.show()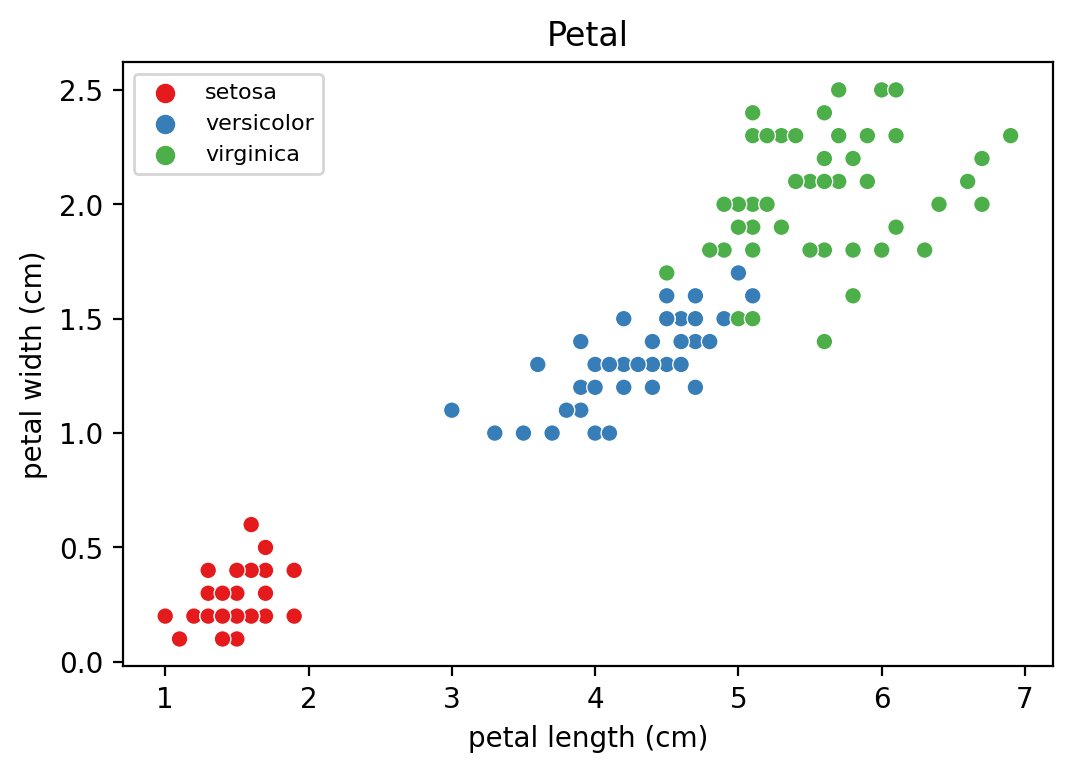
- PCA를 이용하여 차원 축소한 뒤 3D로 표현하기.
3차원은 x, y, z로 이루어져 있다.
따라서 feature가 4이므로, PCA를 이용하여 3차원으로 만들어준 뒤에 3D 그래프를 그려보았다.
from mpl_toolkits.mplot3d import Axes3D
from sklearn.decomposition import PCA
fig = plt.figure(figsize=(8, 6), dpi=200)
ax = Axes3D(fig, elev=-150, azim=110)
# elev, azim으로 각도를 조절한다.
X_reduced = PCA(n_components=3).fit_transform(df_iris.drop('target', axis=1))
# feature는 4개인데, 차원은 3차원이기 때문에 PCA 이용하여 차원 축소를 시켜준다.
ax.scatter(X_reduced[:, 0], X_reduced[:, 1], X_reduced[:, 2], c=df_iris['target'],
cmap=plt.cm.Set1, edgecolor='k', s=40) # target으로 색깔 구분하기.
ax.set_title("Iris 3D")
ax.set_xlabel("x")
ax.w_xaxis.set_ticklabels([])
ax.set_ylabel("y")
ax.w_yaxis.set_ticklabels([])
ax.set_zlabel("z")
ax.w_zaxis.set_ticklabels([])
plt.show()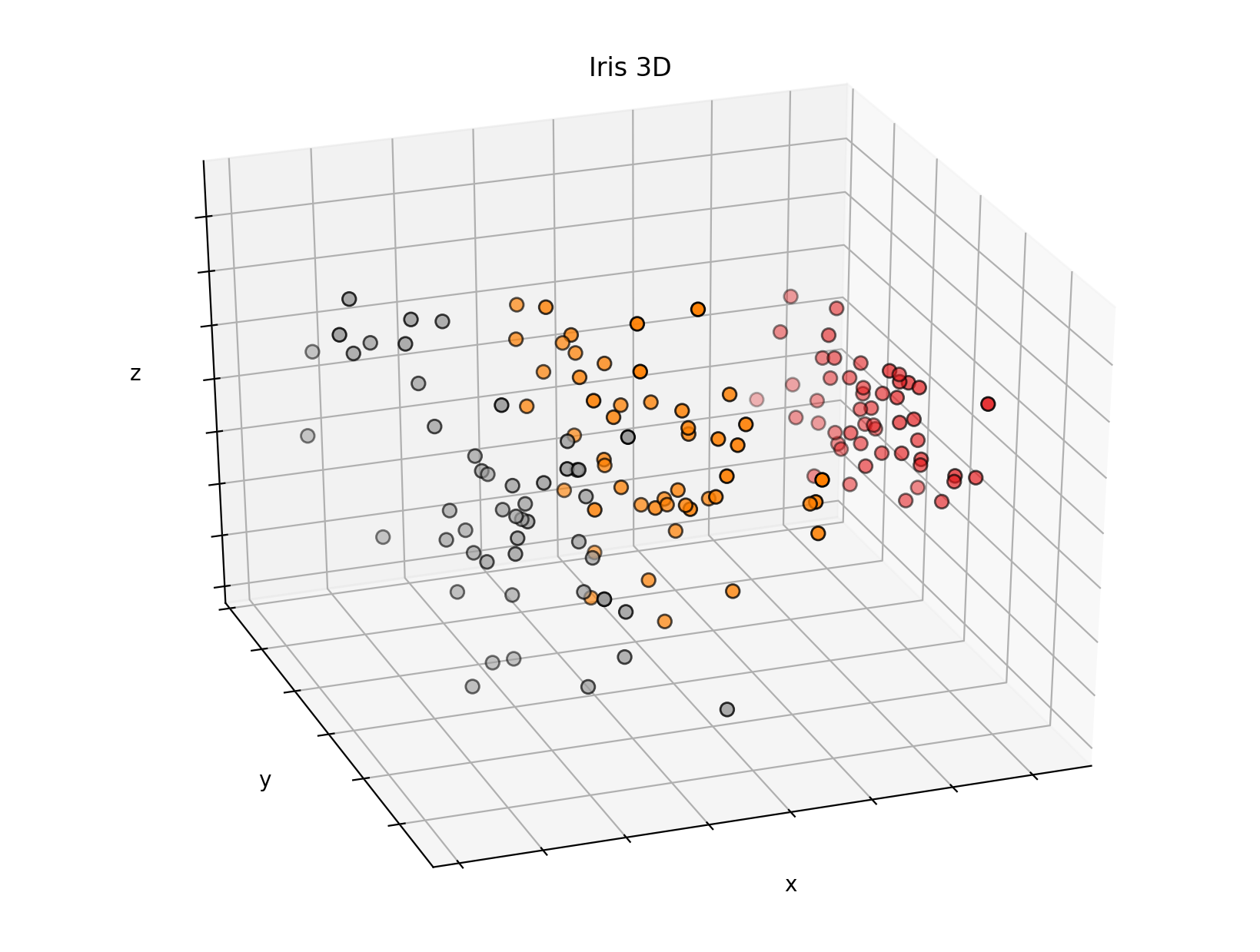
Step 3. 훈련 데이터와 검증 데이터 나누기.
일단 X, y로 나눈 뒤에 train, validation으로 나눠주자.
과정 1. X는 target을 제외한 모든 열을 의미하고, y는 target 열만 의미한다.
과정 2. train은 훈련 데이터이고, validation은 검증 데이터이다.
from sklearn.model_selection import train_test_split
feature=list(df_iris.columns.difference(["target"]))
# difference는 차집합을 의미한다.
# 즉 모든 칼럼에서 target을 뺀 칼럼이 feature이다.
X=df_iris[feature] # target 제외한 데이터
X.head()
y=df_iris["target"] # target 데이터
## 클래스의 분포 고려하지 않은 경우
x_train, x_valid, y_train, y_valid = train_test_split(X, y)
# 순서 주의하기. (x 먼저 쓰고, y 쓰기.)이 경우는 클래스의 분포를 고려하지 않고 데이터를 나눈 경우이다. stratify = y를 적용하면 클래스의 분포를 고려하여 데이터를 나눠준다.
import numpy as np
print("label count of y : ", np.bincount(y))
print("label count of train_y : ", np.bincount(y_train))
print("label count of valid_y : ", np.bincount(y_valid))np.bincount를 이용하여 각 target에 해당되는 횟수를 구하였다. class의 비율을 고려하지 않아서 y_train의 개수가 균일하지 않음을 알 수 있다. 따라서 머신 러닝의 성능 저하를 일으킬 가능성이 높다.


이번에는 클래스의 분포를 고려하여 데이터를 나누기 위하여 stratify=y (클래스의 분포 고려)를 이용하자.
## 클래스의 분포를 고려한 경우
x_train, x_valid, y_train, y_valid = train_test_split(X, y, stratify=y)
# 순서 주의하기. (x 먼저 쓰고, y 쓰기.)import numpy as np
print("label count of y : ", np.bincount(y))
print("label count of train_y : ", np.bincount(y_train))
print("label count of valid_y : ", np.bincount(y_valid))np.bincount를 이용하여 각 target에 해당되는 횟수를 구하였다. class의 비율을 고려하여 y_train의 개수가 거의 균일함을 알 수 있다. 따라서 머신 러닝의 성능 저하를 일으킬 가능성이 적다.


1. Logistic Regression 로지스틱 회귀
로지스틱 회귀 : 선형 관계에서 분류를 진행한다.
로지스틱 회귀와 SVM은 원래 이진 분류만 가능하다. 하지만 3개 이상인 경우 OvR 또는 OvO 방법을 이용한다.
- OvR (one-vs-rest) : 1개 클래스와 (k-1)개 클래스로 이진 분류에 대한 확률을 구하고, 총합을 통해 최종 클래스를 판별한다.
- OvO (one-vs-one) : 각각 1개씩 이진 분류하여 가장 많이 양성으로 선택된 클래스를 최종 클래스로 판별한다.
(ex) 봄, 여름, 가을, 겨울 : 봄-여름, 봄-가을, 봄-겨울, ... , 가을-겨울 : 총 6개의 분류기이다.
대부분 계산 과정이 적은 OvR 전략을 선호한다.
from sklearn.linear_model import LogisticRegression
## Step 1. 모델 생성하기.
lr=LogisticRegression()
## Step 2. 모델 학습하기.
lr.fit(x_train, y_train)
## Step 3. 모델 예측하기.
pred=lr.predict(x_valid)
## Step 4. 모델 평가하기.
(pred==y_valid).mean()
# 같으면 1, 다르면 0으로 지정하고 평균을 구하면 정확도가 나온다.2. SGD 확률적 경사 하강법
확률적 경사 하강법 : 경사 하강법과 비슷한 알고리즘이다.
2-1. 모델 사용하기.
from sklearn.linear_model import SGDClassifier
## Step 1. 모델 생성하기.
sgd=SGDClassifier()
## Step 2. 모델 학습하기.
sgd.fit(x_train, y_train)
## Step 3. 모델 예측하기.
pred=sgd.predict(x_valid)
## Step 4. 모델 평가하기.
(pred==y_valid).mean()2-2. 하이퍼 파라미터 튜닝하기.
sgd = SGDClassifier(penalty='elasticnet', random_state=0, n_jobs=-1)
# penalty : 오버피팅을 방지
# random_state : 고정 (임의의 숫자를 넣어주기), 반드시 고정하기.
# n_jobs : 지원하는 알고리즘에는 설정해주는 것이 좋다. -1로 지정하면 CPU 모두 사용하겠다는 의미이다.이리저리 변경하면서 코드 돌려보기.
3. KNeighborClassifier 최근접 이웃 알고리즘
최근접 이웃 알고리즘 : K 기준으로 클래스의 개수 세어줘서 많은 클래스의 개수를 갖는 쪽으로 분류하기. K는 홀수로 잡는 것이 좋다. 짝수인 경우에는 클래스의 개수가 같아지는 경우가 생길 수도 있기 때문이다.
from sklearn.neighbors import KNeighborsClassifier
## Step 1. 모델 생성하기.
knc=KNeighborsClassifier(n_jobs=-1)
## Step 2. 모델 학습하기.
knc.fit(x_train, y_train)
## Step 3. 모델 예측하기.
pred=knc.predict(x_valid)
## Step 4. 모델 평가하기.
(pred==y_valid).mean()knc = KNeighborsClassifier(n_neighbors=7, n_jobs=-1)
knc.fit(x_train, y_train)
knc_pred = knc.predict(x_valid)
(knc_pred==y_valid).mean()4. SVC 서포트 벡터 머신
서포트 벡터 머신 : 이진 분류만 가능하다. (다중 분류인 경우 OvO나 OvR 이용하기.) 경계로 표현되는 데이터들 중에서 가장 큰 폭을 가진 경계를 찾는 알고리즘이다.
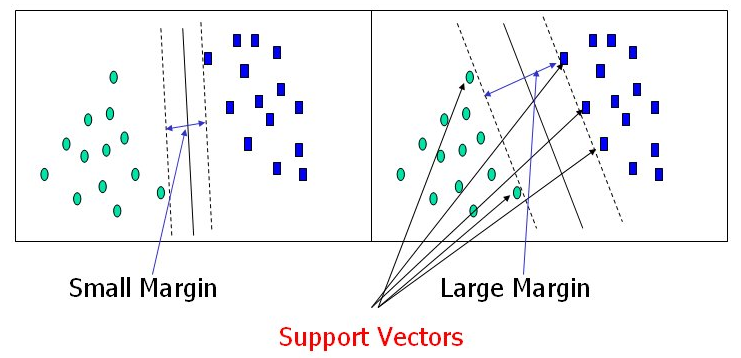
from sklearn.svm import SVC
## Step 1. 모델 생성하기.
svc=SVC(random_state=0)
## Step 2. 모델 학습하기.
svc.fit(x_train, y_train)
## Step 3. 모델 예측하기.
pred=svc.predict(x_valid)
## Step 4. 모델 평가하기.
(pred==y_valid).mean()decision_function을 이용하여 각 클래스 별 확률값을 보여줄 수 있다. 같은 행 중에서 가장 큰 확률값을 가진 클래스를 선택하기.
svc.decision_function(x_valid)[:5] # 각 클래스 별 확률값을 반환한다.5. Decision Tree 의사 결정 나무
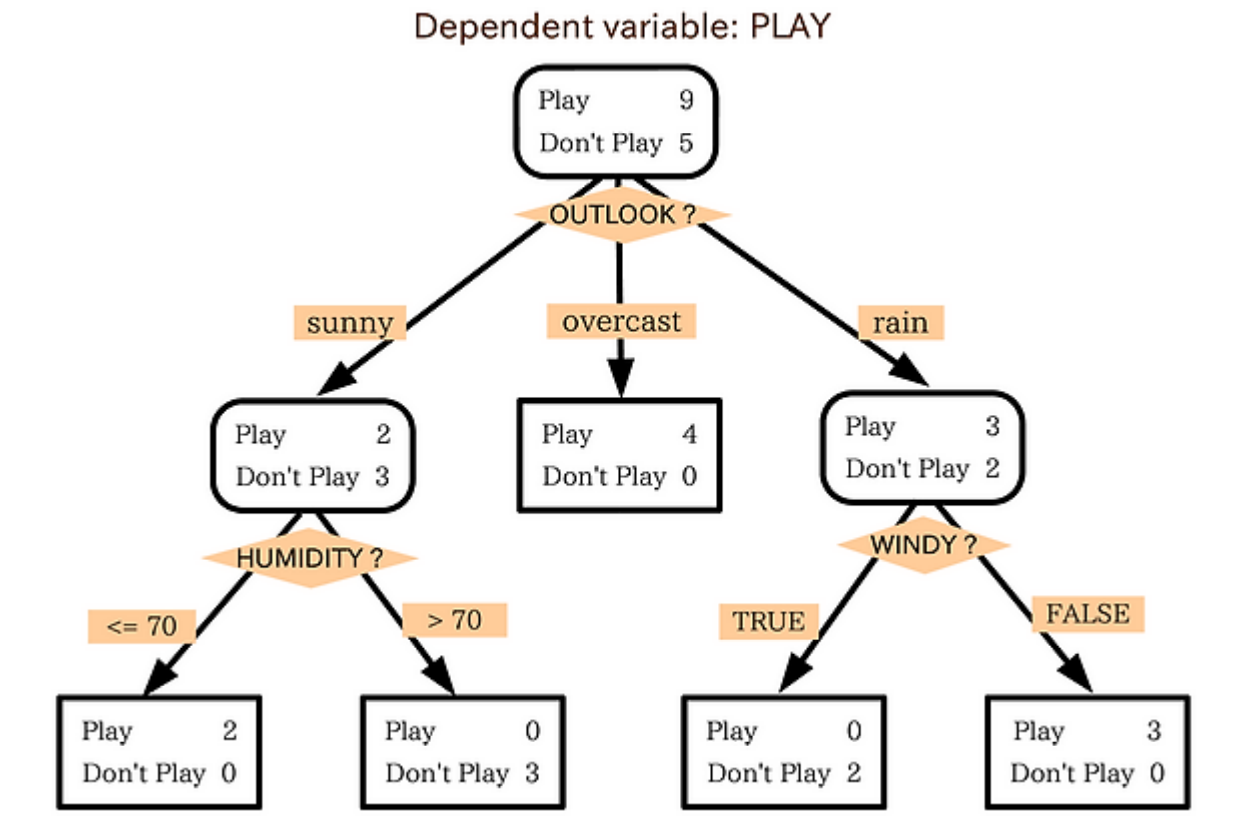
의사 결정 나무 : 스무고개처럼, 나무 가지치기를 통하여 소그룹으로 나누어 판별하는 알고리즘이다.
from sklearn.tree import DecisionTreeClassifier
## Step 1. 모델 생성하기.
dtc=DecisionTreeClassifier()
## Step 2. 모델 학습하기.
dtc.fit(x_train, y_train)
## Step 3. 모델 예측하기.
pred=dtc.predict(x_valid)
## Step 4. 모델 평가하기.
(pred==y_valid).mean()graphviz를 이용하여 의사 결정 나무 구조를 확인할 수 있다.


위의 내용을 이용하여 .png로 변환하여 의사 결정 나무 구조를 그리는 함수를 만들었다.
from sklearn.tree import export_graphviz
from subprocess import call
def graph_tree(model):
# .dot 파일로 export 해줍니다
export_graphviz(model, out_file='tree.dot')
# 생성된 .dot 파일을 .png로 변환
call(['dot', '-Tpng', 'tree.dot', '-o', 'decistion-tree.png', '-Gdpi=600'])
# .png 출력
return Image(filename = 'decistion-tree.png', width=500)
graph_tree(dtc)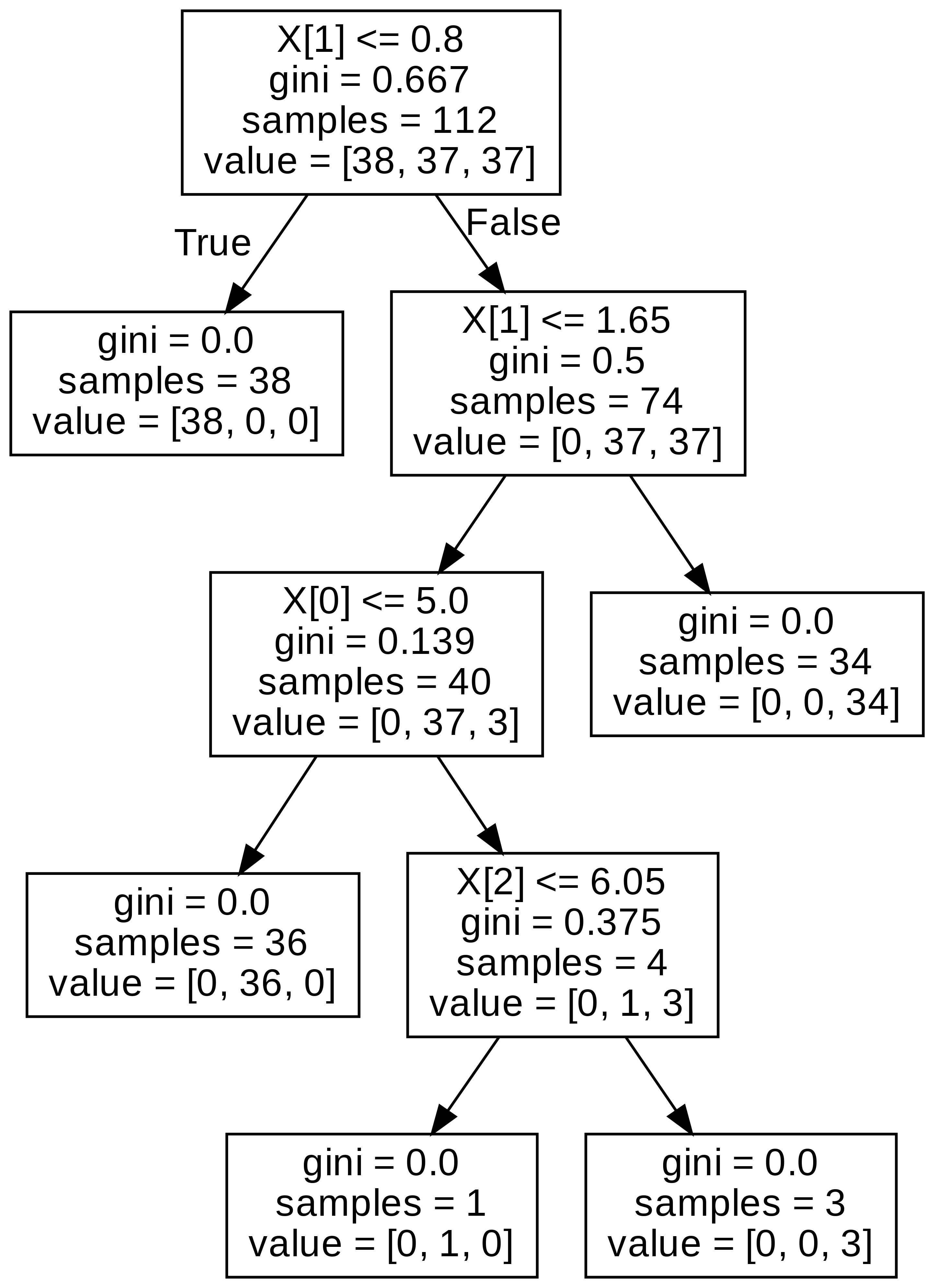
하이퍼 파라미터를 통해 깊이를 조정할 수 있다.
dtc = DecisionTreeClassifier(max_depth=2) # 깊이를 제한하기.
dtc.fit(x_train, y_train)
dtc_pred = dtc.predict(x_valid)
(dtc_pred==y_valid).mean()
graph_tree(dtc)
너무 깊게 들어가면 과적합 위험이 있기 때문에, 깊이를 조정해주는 것이다.
- (추가 방법) Windows export_graphviz Install and Use
Step 1. tree.dot으로 내보내기.
Step 2. prompt에서 export_graphviz 설치하기.
Step 3. .png로 변환하기.
## Step 1.
tree.export_graphviz(clf,
out_file="tree.dot",
feature_names = fn,
class_names=cn,
filled = True)
## Step 2.
conda install python-graphviz
## Step 3.
dot -Tpng tree.dot -o tree.png6. 오차
6-1. 정확도의 한계
breast_cancer() 데이터를 로드해서 가져왔다. 양성 데이터와 음성 데이터 5개를 이용하여 샘플 데이터를 만들고 로지스틱 회귀모형을 이용하여 분류를 하였는데 정확도가 0.98정도 나왔다. 그리고 모두 1이라고 예측을 하고 정확도가 0.99정도 나왔다.
lr=LogisticRegression()
lr.fit(train_x, train_y)
pred=lr.predict(test_x)
(pred==test_y).mean() # 0.98
my_pred=lr.predict(np.ones(shape=test_y.shape)) # 1로만 예측하기.
(my_pred==test_y).mean() # 0.99과연 1이라고만 예측한 분류기가 정말 좋은 분류기일까? 정확도로만 성능을 판단하는 것은 오류를 불러일으킬 수 있다.
그래서 실제 분류기 성능을 알기 위한 방법들이 존재한다.
- 혼동 행렬
- 정밀도
- 재현율
- f1-score
6-2. 혼동 행렬 (Confusion Metrix)
실제 분류기 성능을 알 수 있다.
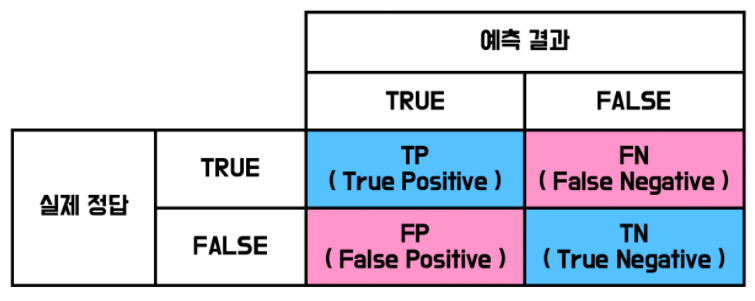
from sklearn.metrics import confusion_matrix
confusion_matrix(y_test, pred)heatmap을 이용하여 혼동 행렬을 그릴 수 있다.
plt.figure(figsize=(4,2), dpi=200)
sns.heatmap(confusion_matrix(y_test, pred), annot=True, cmap="Reds")
plt.xlabel('Predict')
plt.ylabel('Actual')
plt.show()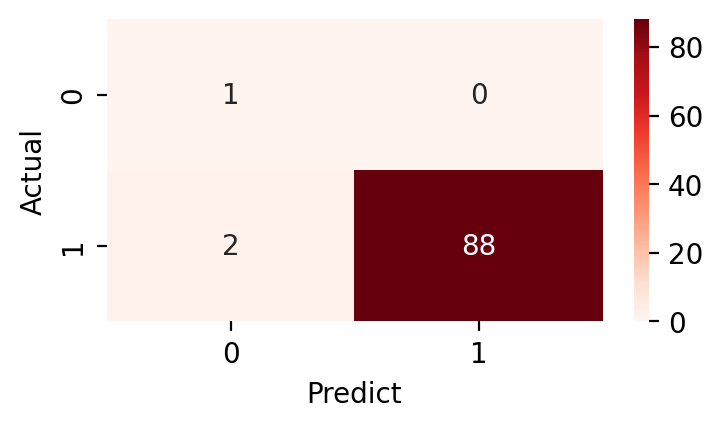
6-3. 정밀도 (Precision)
분모가 positive라고 예측한 합이다.
정밀도 = (진짜 1인 경우) / (1이라고 예측한 경우) =
from sklearn.metrics import precision_score
precision_score(y_test, pred)6-4. 재현율 (Recall)
분모가 positive의 합이다. 그래서 진짜 양성의 비율을 의미하여 TPR (True Positive Rate) 라고 불리기도 한다.
재현율 = (1이라고 예측하고 진짜 1인 경우) / (진짜 1인 경우) =
6-5. F1-Score
정밀도와 재현율은 상관 관계이다. (trade-off 관계) 한 쪽이 오르면 다른 한쪽은 떨어지는 관계를 가진다. 그래서 정밀도와 재현율의 조화 평균인 가 등장한다.
from sklearn.metrics import f1_score
f1-score(y_test, pred)그래서 공모전에서 로 성능을 체크하는 경우가 많은 것 같다.
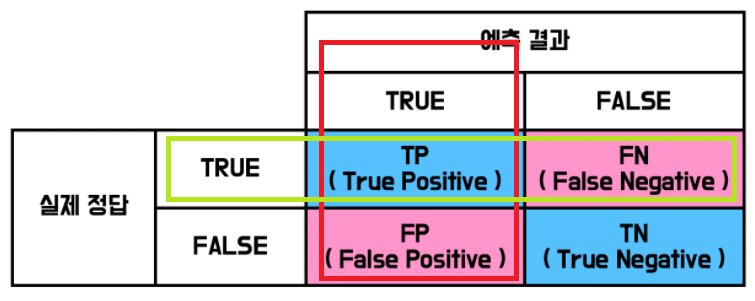
- 빨간색 부분이 정밀도와 관련이 있다. (positive라고 예측한 것의 합)
- 녹색 부분이 재현율과 관련이 있다. (진짜 positive의 합)
- f1-score는 정밀도와 재현율의 조화 평균이다.
