
개요
주제 : 음주운전의 현 주소와 근절하기 위한 앞으로의 방향 제시
내 친한 친구의 아버님이 음주운전을 지금까지 거의 4번은 걸리셔서 벌금도 강하게 물고 유치장도 다녀오셨는데 그럼에도 불구하고 가까운 거리는 아직도 술을 마시면 차를 타고 오신다고 한다. 그래서 궁금했다.
-
음주운전은 왜 이렇게 잦게 일어날까?
최근 들어 뉴스를 보게되면 연예인 및 셀럽들의 음주운전과 심지어 경찰공무원 등 국가의 일을 담당하고 있는 공무원들까지의 음주운전이 기사화되어 하루하루 뉴스를 장식한다.
음주운전은 왜 이렇게 계속해서 일어나고 빈번하게 발생하는지 분석을 해보고 싶었다. -
음주운전 최대한으로 줄이기 위해서는 어떤 조치를 취해야할까?
음주운전은 중범죄로 처리되는데 같은 중범죄 중에서도 뭔가 가벼운 느낌으로 다가오는 건가? 안걸릴 수 있다는 어떠한 확신이 있는 건가? 하는 궁금증이 생겨 분석을 해보고 싶었다.
음주운전 발생률
- 음주운전의 발생 추이 (2013 - 2022)
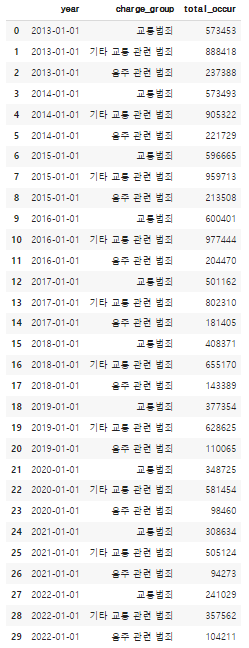
수집한 데이터를 파이썬에서 전처리 후 데이터 프레임으로 만들기.
plt.figure(figsize=(12, 6))
for charge in df_drunk['charge_group'].unique():
charge_data = df_drunk[df_drunk['charge_group'] == '음주 관련 범죄']
plt.plot(charge_data['year'], charge_data['total_occur'], marker='o')
plt.title('최근 10년 음주운전 발생 추이')
plt.xlabel('연도')
plt.ylabel('발생건수')
plt.grid(True, linestyle='--', alpha=0.5)
plt.tight_layout()
plt.show() 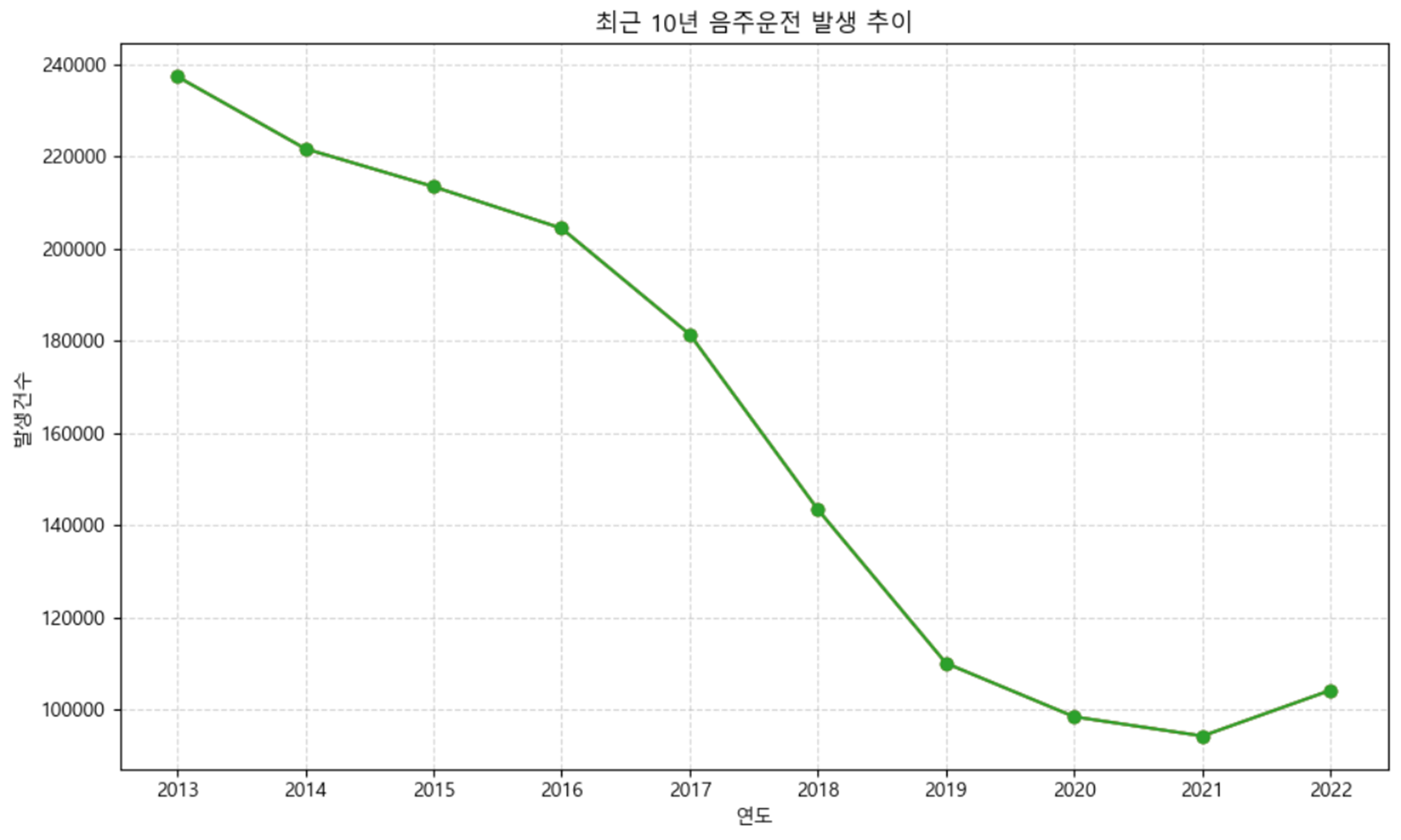
음주운전의 발생 수는 지난 10년간 꾸준히 감소되어 온 것을 확인할 수 있었다.
이것만으로는 조금 부족한 것 같아 전체 교통관련 범죄 중 음주운전의 비중을 뽑아보았다.
- 전체 교통사고 중 음주운전의 비중 (2013 - 2022)
df_ratio = df_drunk.pivot(index='year', columns='charge_group', values='total_occur').reset_index()
df_ratio['음주_비율'] = df_ratio['음주 관련 범죄'] / (df_ratio['교통범죄']) * 100
plt.figure(figsize=(12, 6))
plt.plot(df_ratio['year'], df_ratio['음주_비율'], marker='o', label='음주 관련 범죄 비율')
plt.title('최근 10년 교통범죄 중 음주 관련 범죄 비중')
plt.xlabel('발생연도')
plt.ylabel('비중(%)')
plt.legend()
plt.grid(True, linestyle='--', alpha=0.5)
for x in df_ratio['음주_비율']:
plt.text(x, y, f'{y:.1f}%', ha='center', va='bottom')
plt.tight_layout()
plt.show()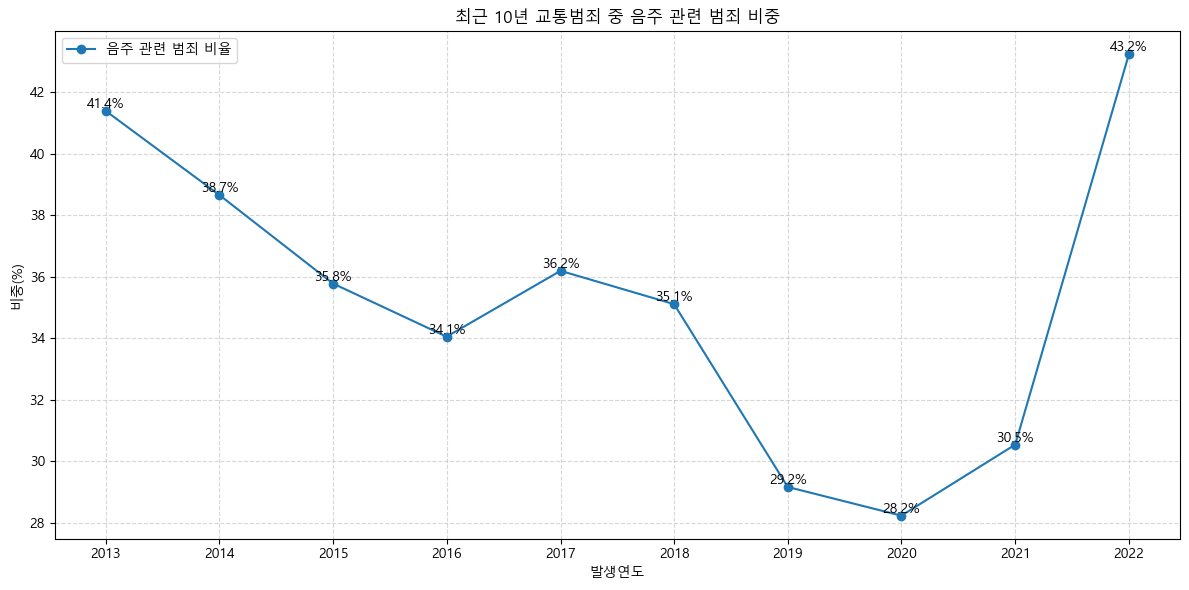
음주운전으로 인한 사고의 수 자체는 줄어들었지만, 전체 교통사고에서 음주운전의 비중은 잠깐 주춤하는 모습을 보였지만 다시 힘차게 올라가는 패턴을 확인할 수 있었다.
무엇이 원인일까?
날씨??
- 기온과 밀접한 관련이 있을까? (2010 - 2023)
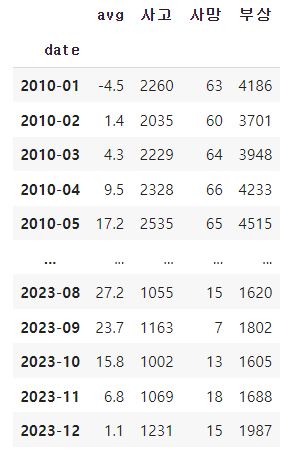
2010년부터 2023년까지 하루하루 측정한 기온값을 매 달 평균을 구하였고, 도로교통공단에서 통계를 올려놓은 값들을 가져와 전처리 후 데이터 프레임을 만들었다.
plt.style.use("seaborn-v0_8-whitegrid")
fig, ax1 = plt.subplots(figsize = (18, 8))
ax1.plot(climate_dui_df.index, climate_dui_df['avg'], 'b-', label='Climate')
ax1.set_xlabel('Date')
ax1.set_ylabel('Climate', color='b')
ax1.tick_params(axis='y', labelcolor='b')
ax1.grid(False)
_ = plt.xticks(size = 6, rotation=45, ha='right')
ax2 = ax1.twinx()
ax2.plot(climate_dui_df.index, climate_dui_df['사고'], 'r-', label='Accident')
ax2.set_ylabel('Accident', color='r')
ax2.tick_params(axis='y', labelcolor='r')
ax2.grid(False)
fig.suptitle('Average temperature and drunk driving', fontsize = 16)
fig.legend(loc='upper left', bbox_to_anchor=(0.838, 0.885))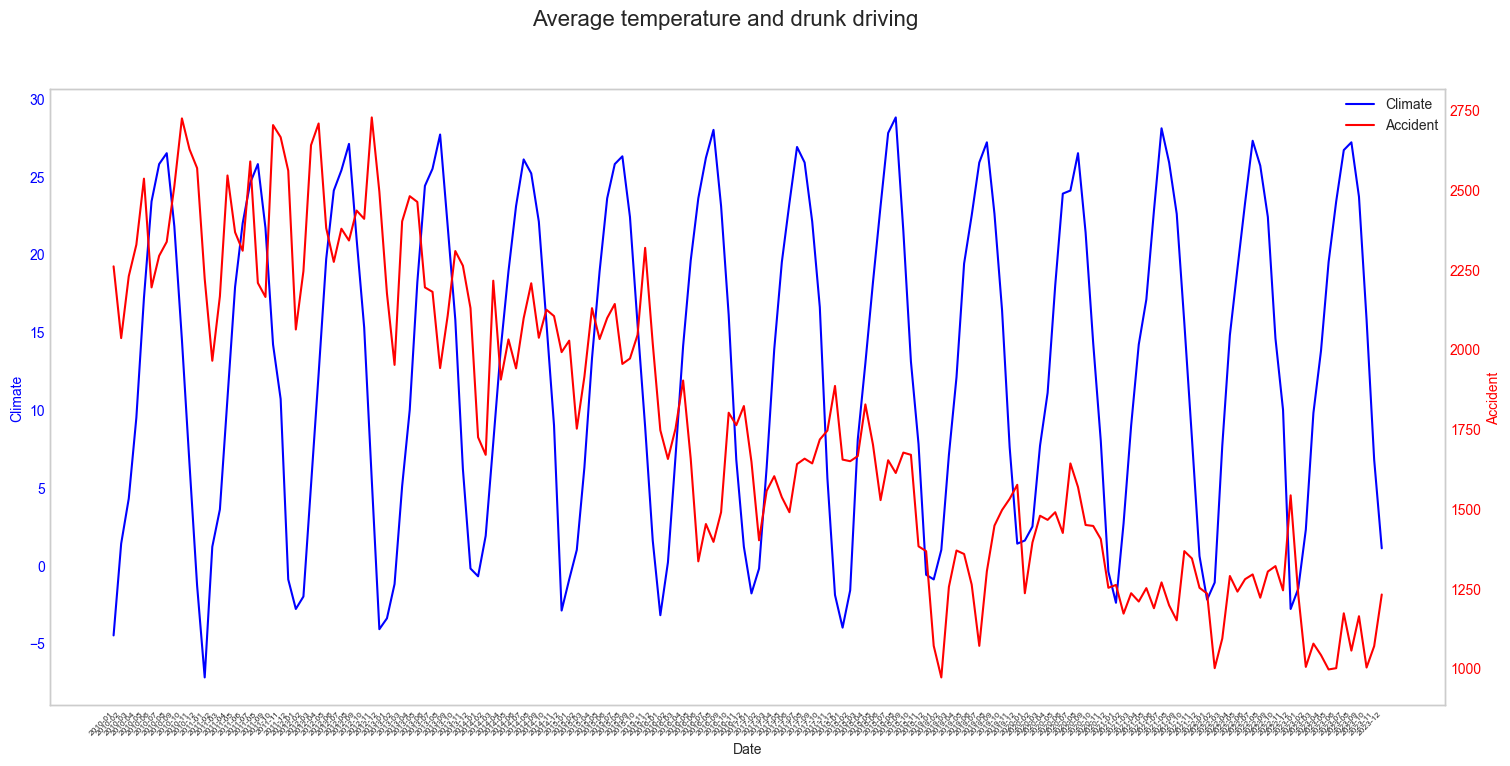
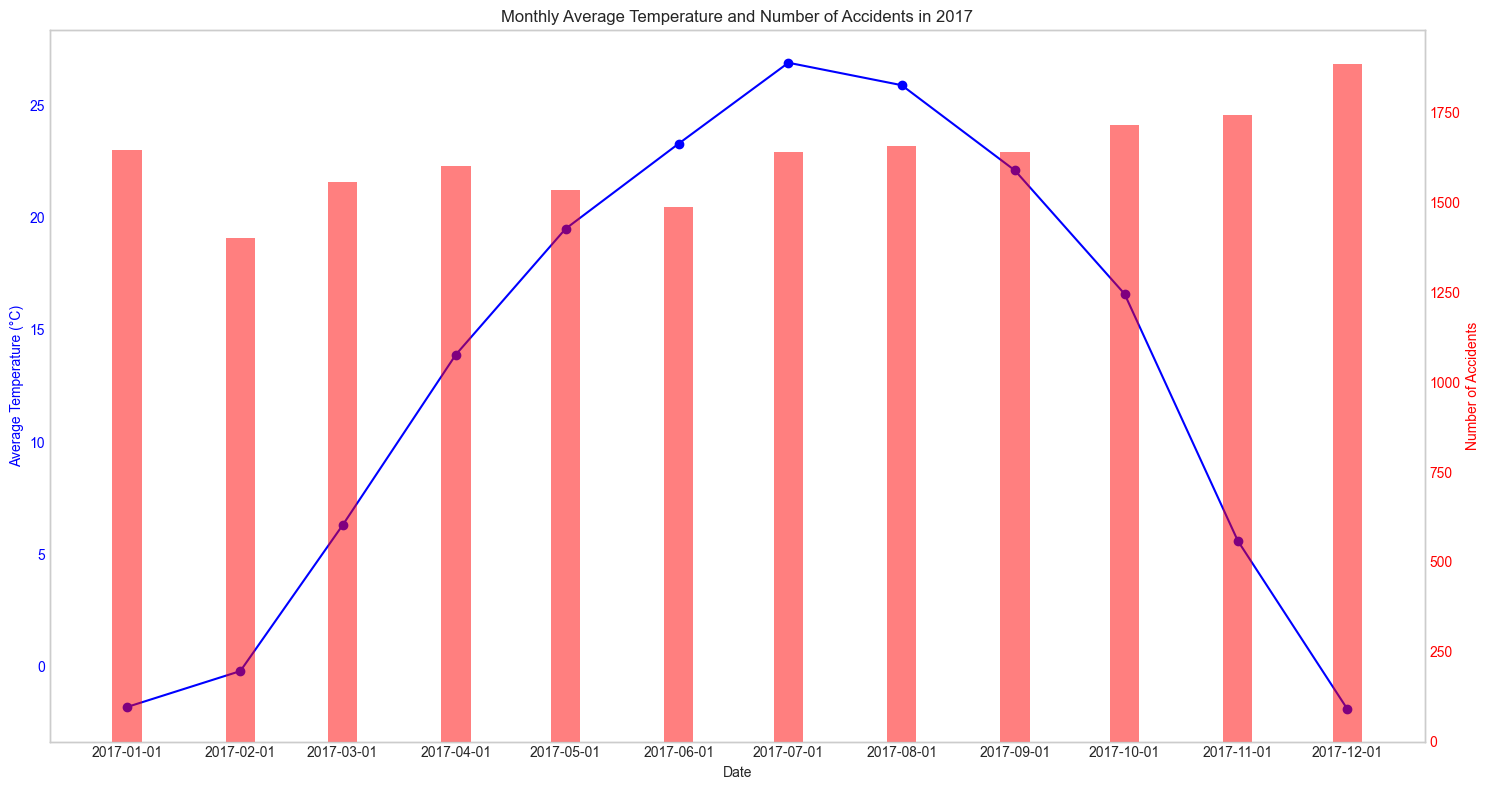
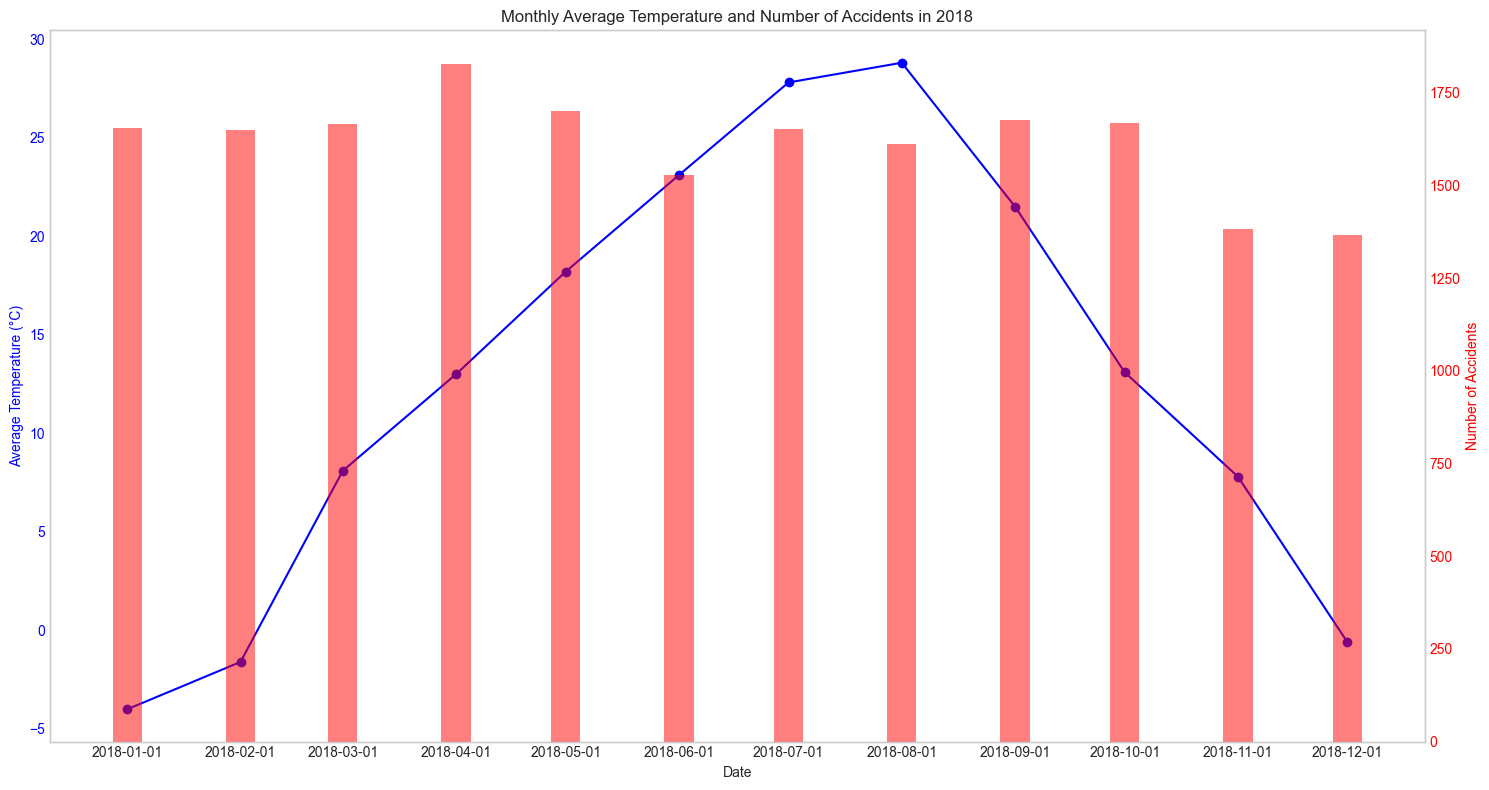
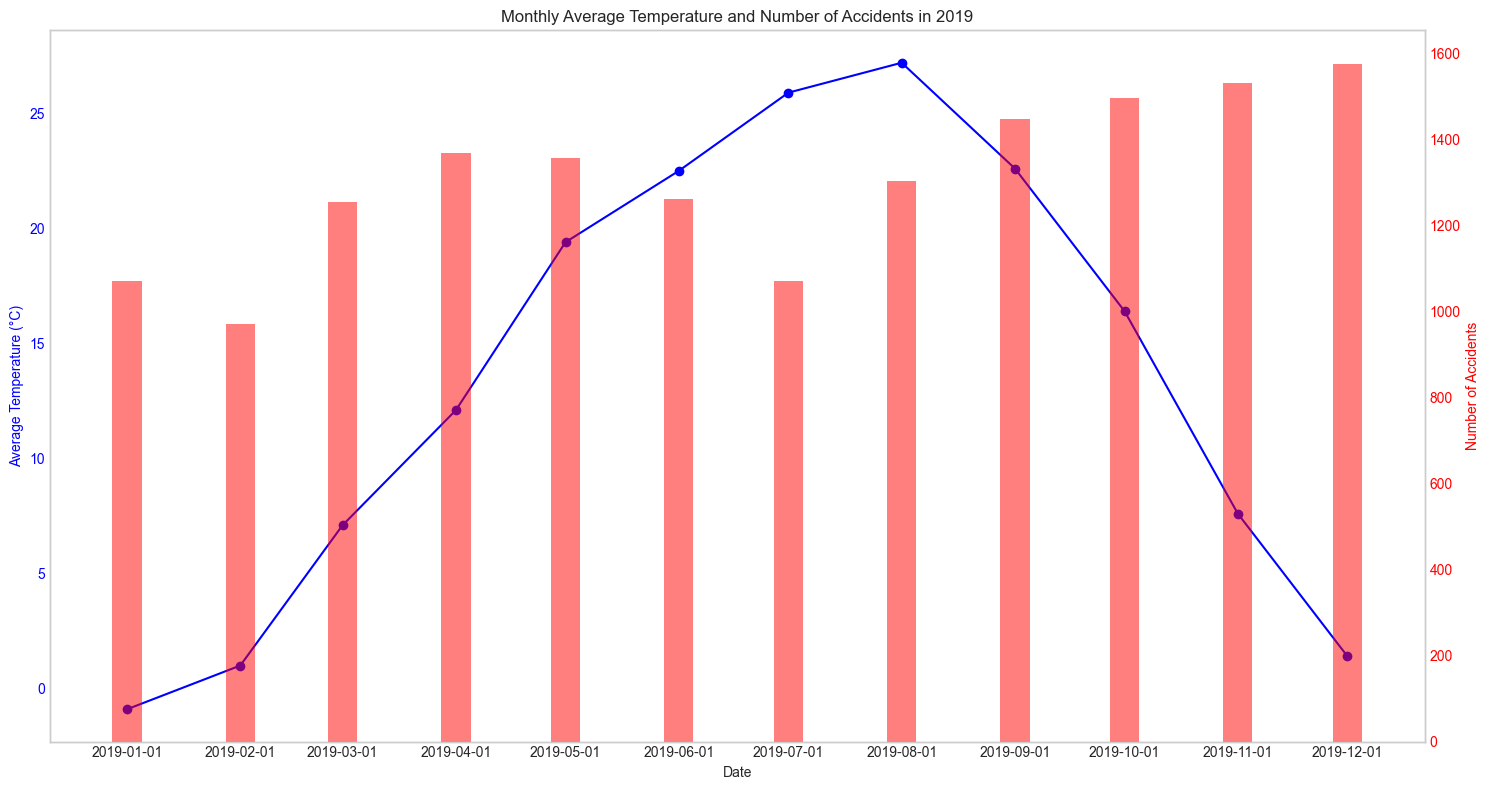
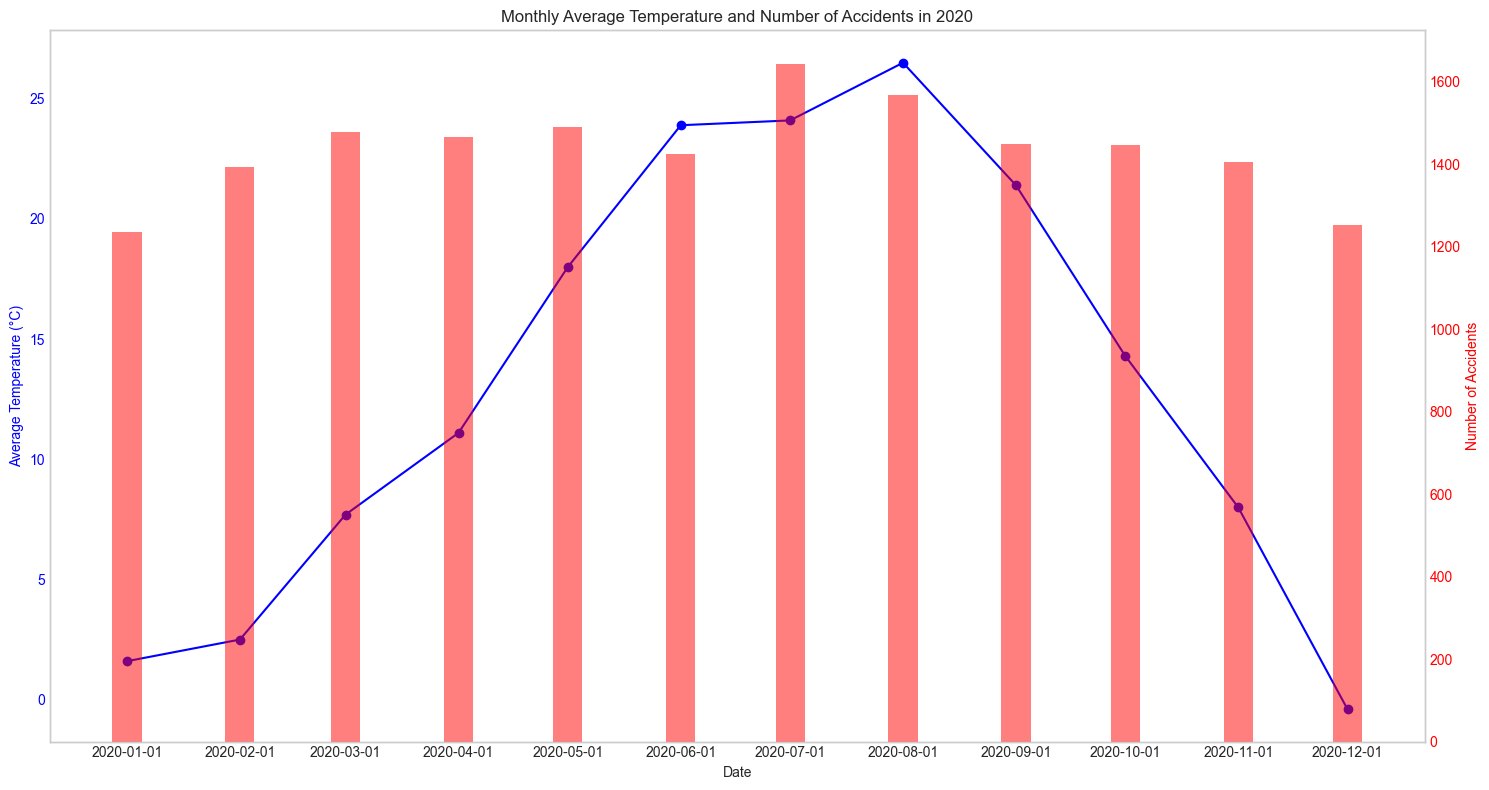
이렇게 봐서는 뭘 모르겠어서 매 년으로 나누어서 확인을 해보았다.
for year in years:
yearly_data = climate_dui_sec_df[climate_dui_sec_df['date'].dt.year == year]
fig, ax1 = plt.subplots(figsize=(15, 8))
# 온도 평균 시각화
ax1.plot(yearly_data['date'], yearly_data['avg'], 'b-', marker='o', label='Average Temperature (°C)')
ax1.set_xlabel('Date')
ax1.set_ylabel('Average Temperature (°C)', color='b')
ax1.tick_params('y', colors='b')
ax1.grid(False)
# 사고 건수 시각화 (2차 축)
ax2 = ax1.twinx()
ax2.bar(yearly_data['date'], yearly_data['사고'], color='r', width = 8, alpha=0.5, label='Number of Accidents')
ax2.set_ylabel('Number of Accidents', color='r')
ax2.tick_params('y', colors='r')
ax2.grid(False)
# 제목 및 레이블 추가
ax1.set_xticks(yearly_data['date'])
plt.title(f'Monthly Average Temperature and Number of Accidents in {year}')
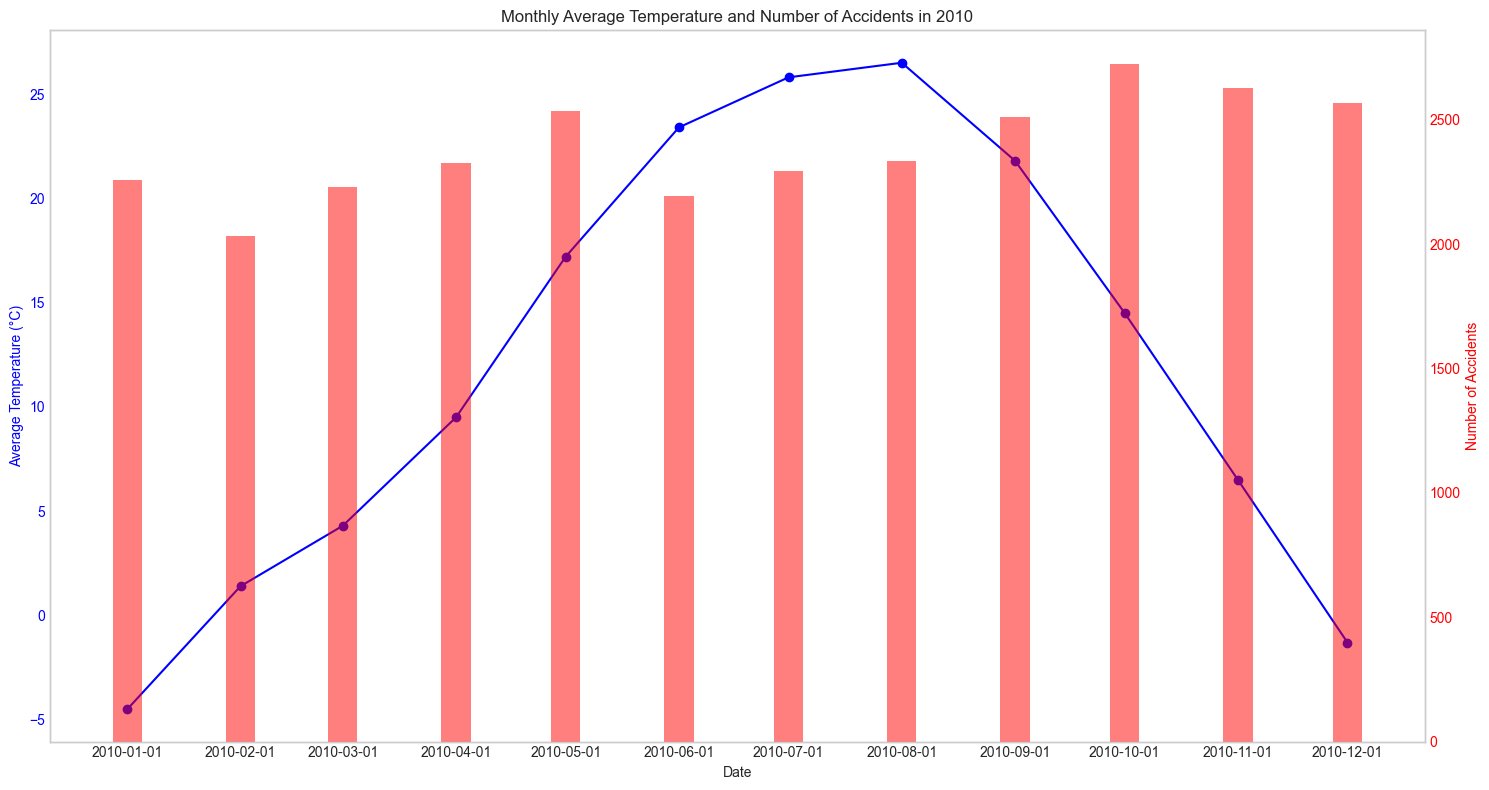
fig.tight_layout()2010년
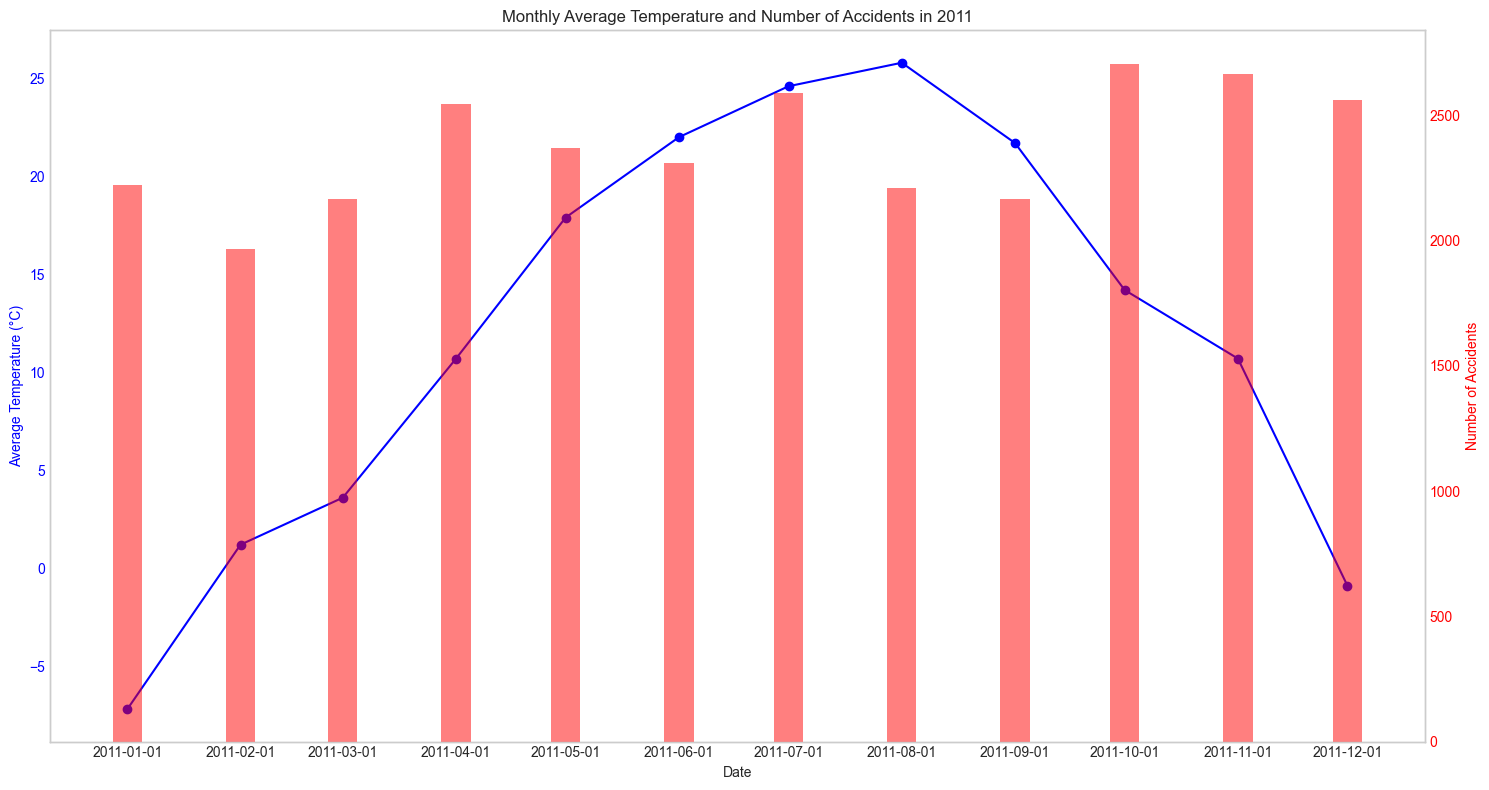
2011년
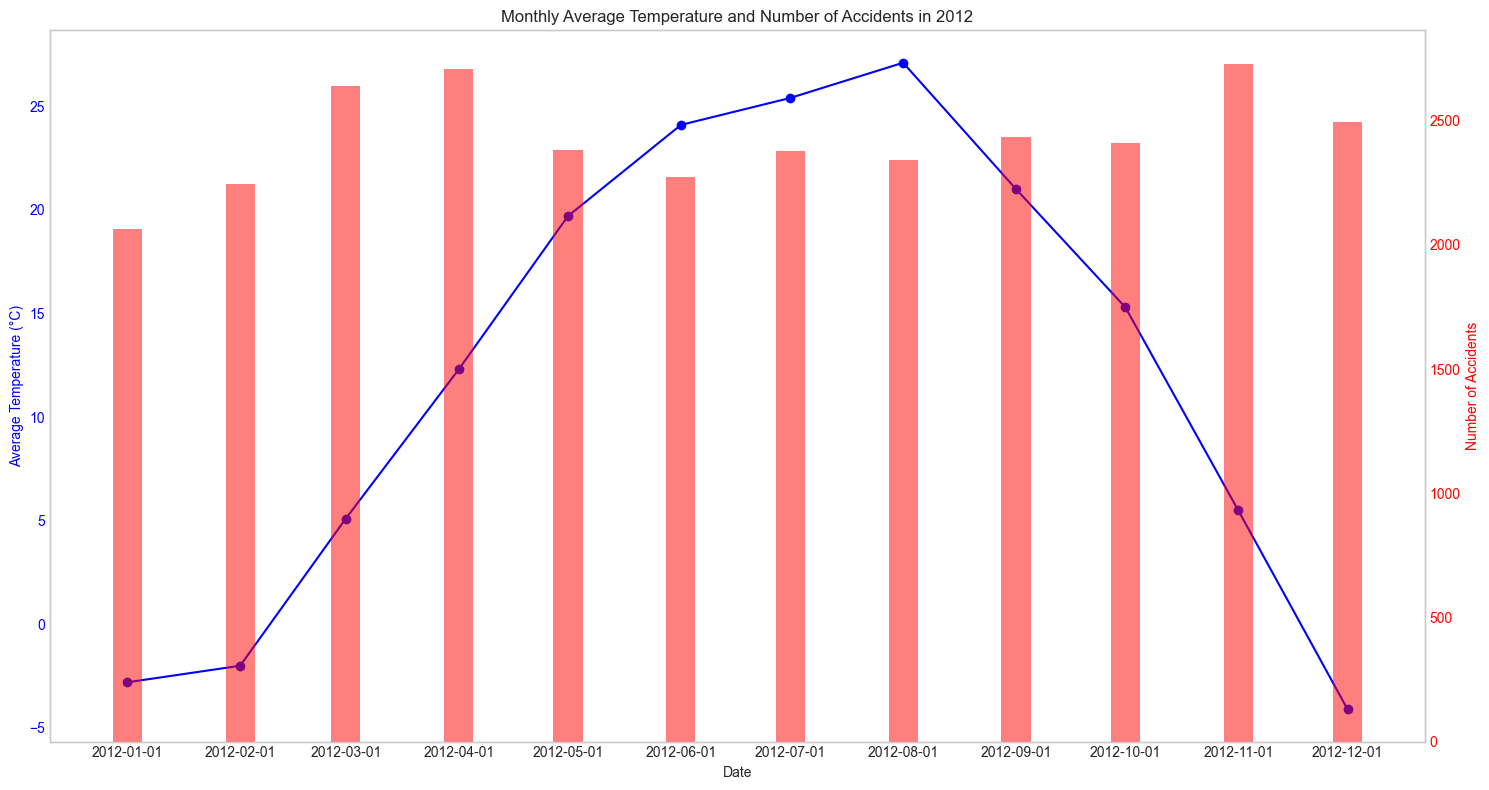
2012년
2013년
2014년
2015년
2016년
2017년
2018년
2019년
2020년
2021년
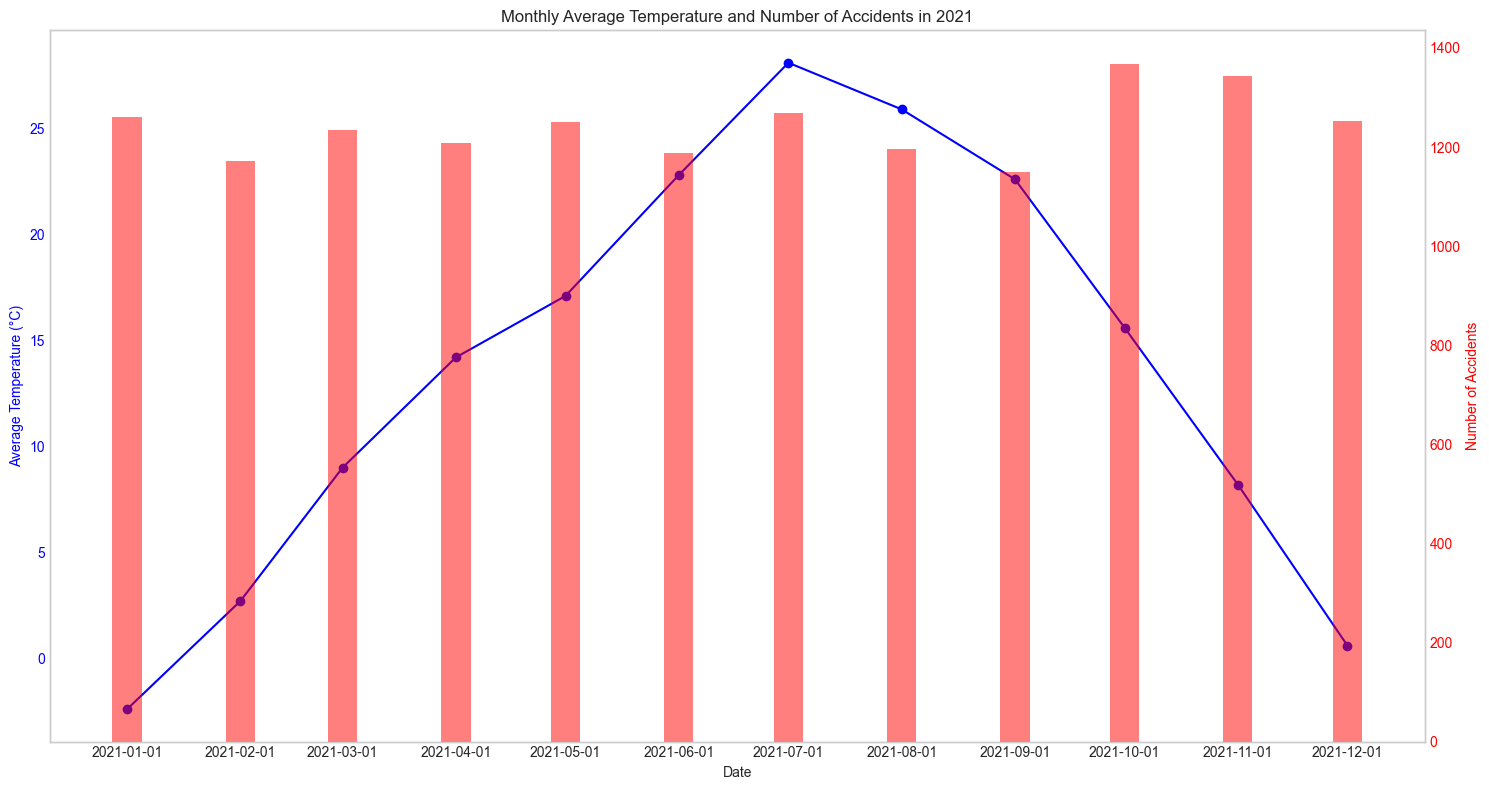
2022년
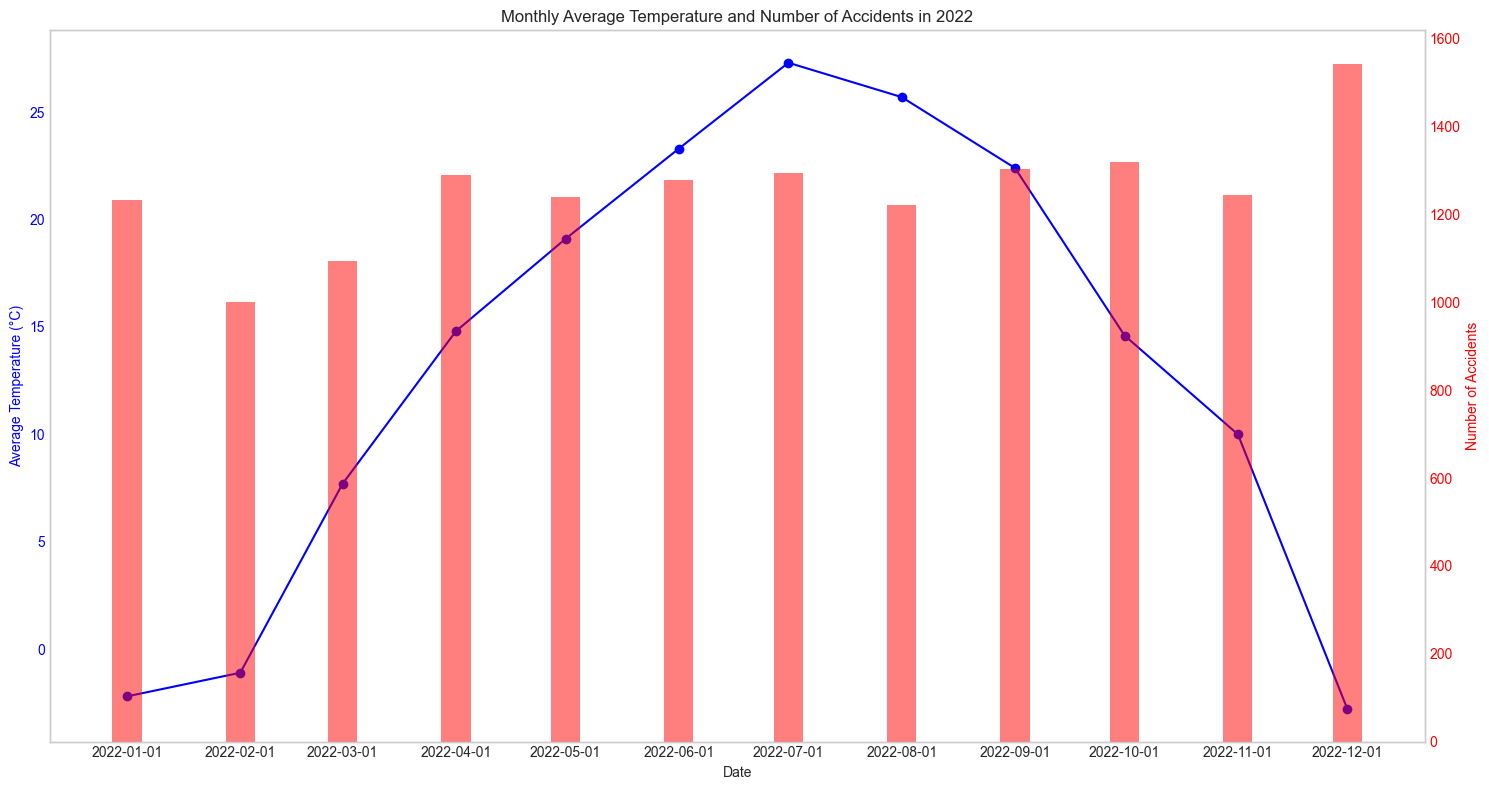
2023년
매년마다 확인해보아도 어떠한 패턴을 찾아낼 수가 없었다. 그렇다면 혹시 강수량과는 관련이 있지 않을까? 하는 생각에 강수량관련 데이터도 수집해 그래프를 그려보았다.
- 강수량과 밀접한 관련이 있을까? (2010 - 2023)
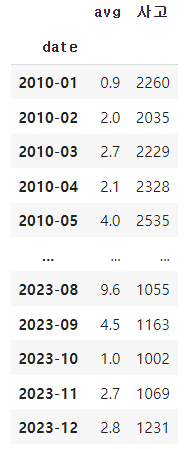
기상청에서 데이터를 제공받아 전처리 후 데이터프레임으로 만들었다.
plt.style.use("seaborn-v0_8-whitegrid")
fig, ax1 = plt.subplots(figsize = (18, 8))
ax1.plot(p_dui_df.index, p_dui_df['avg'], 'b-', label='Precipitation')
ax1.set_xlabel('Date')
ax1.set_ylabel('Precipitation', color='b')
ax1.tick_params(axis='y', labelcolor='b')
ax1.grid(False)
_ = plt.xticks(size = 6, rotation=45, ha='right')
ax2 = ax1.twinx()
ax2.plot(p_dui_df.index, p_dui_df['사고'], 'r-', label='Accident')
ax2.set_ylabel('Accident', color='r')
ax2.tick_params(axis='y', labelcolor='r')
ax2.grid(False)
fig.suptitle('Average temperature and drunk driving', fontsize = 16)
fig.legend(loc='upper left', bbox_to_anchor=(0.82, 0.885))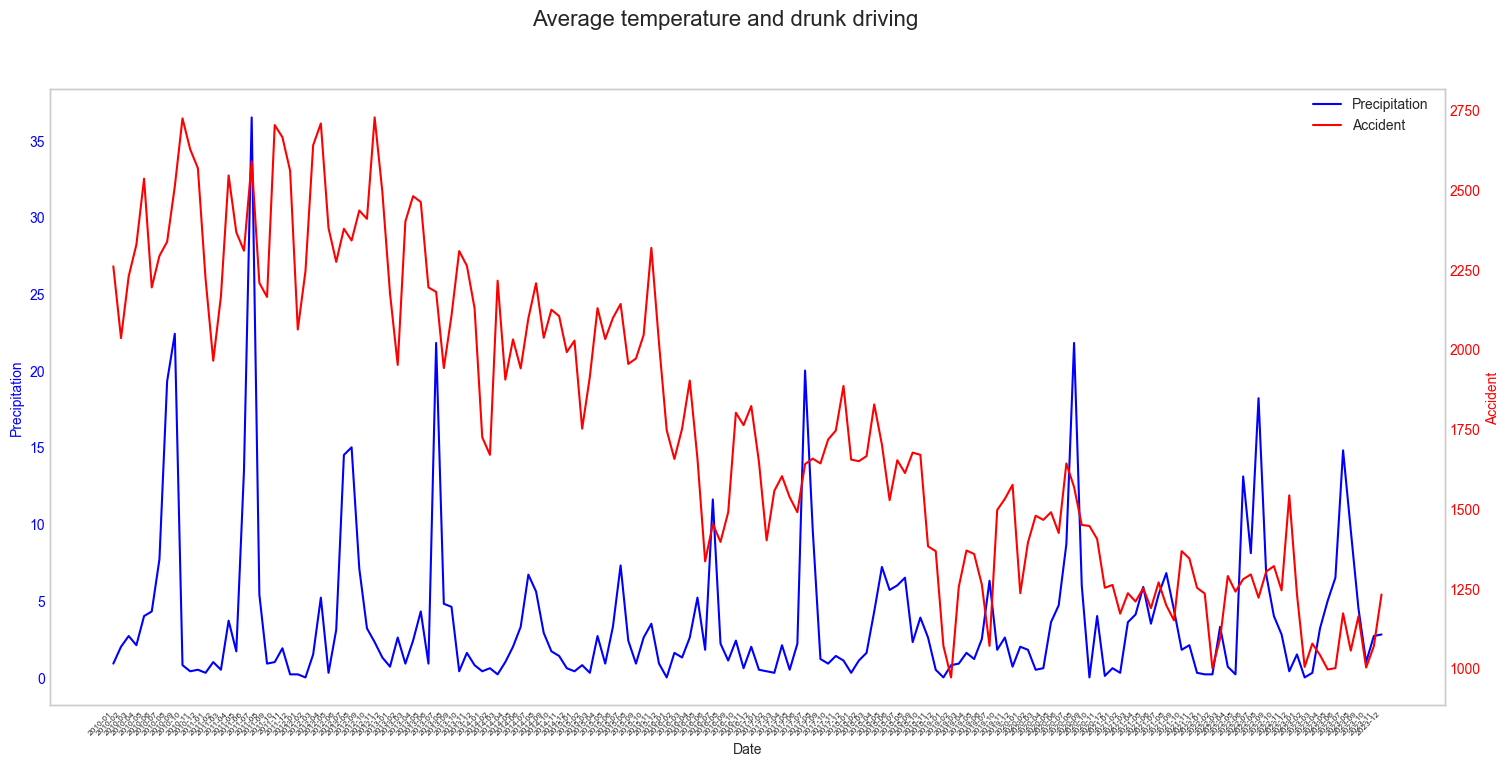
생각보다 강수량이 높은 날보다 강수량이 적은 날에 음주운전 사고 수가 많았다.
당연하게도 운전하기 어려운 날에는 차를 놓고 나가고 운전하기 괜찮은 날에는 차를 끌고나간 사람들이 많아서 그렇다고 판단해 패턴이 유의미하다고 생각하지 않고 넘어갔다.
언제??
- 주로 어떤 시간대에 일어날까?
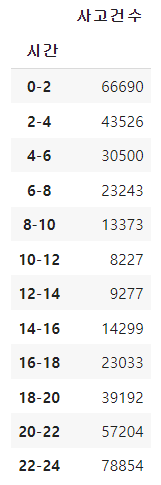
경찰청에서 제공받은 데이터로 전처리 후 데이터 프레임을 만들었다.
plt.style.use ('ggplot')
time_df.plot(kind = "bar")
_ = plt.xticks(size = 8, rotation=45, ha='right')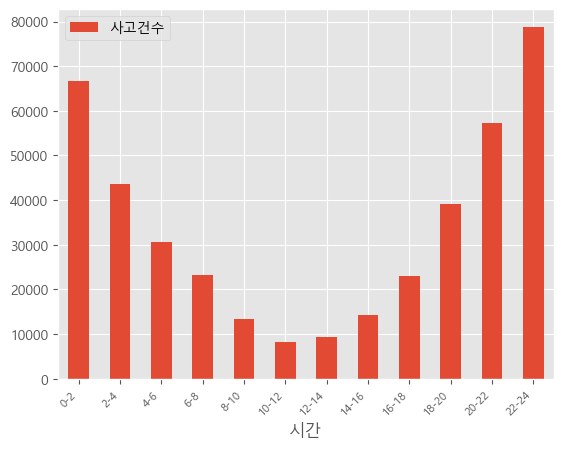
주로 20시부터 시작해서 새벽 4시까지 딱 밤 시간대에 음주운전 사고가 많이 일어난다는 것을 당연히 알고 있었지만 분석을 통해 확신할 수 있었다.
- 어떤 요일에 많이 일어날까?
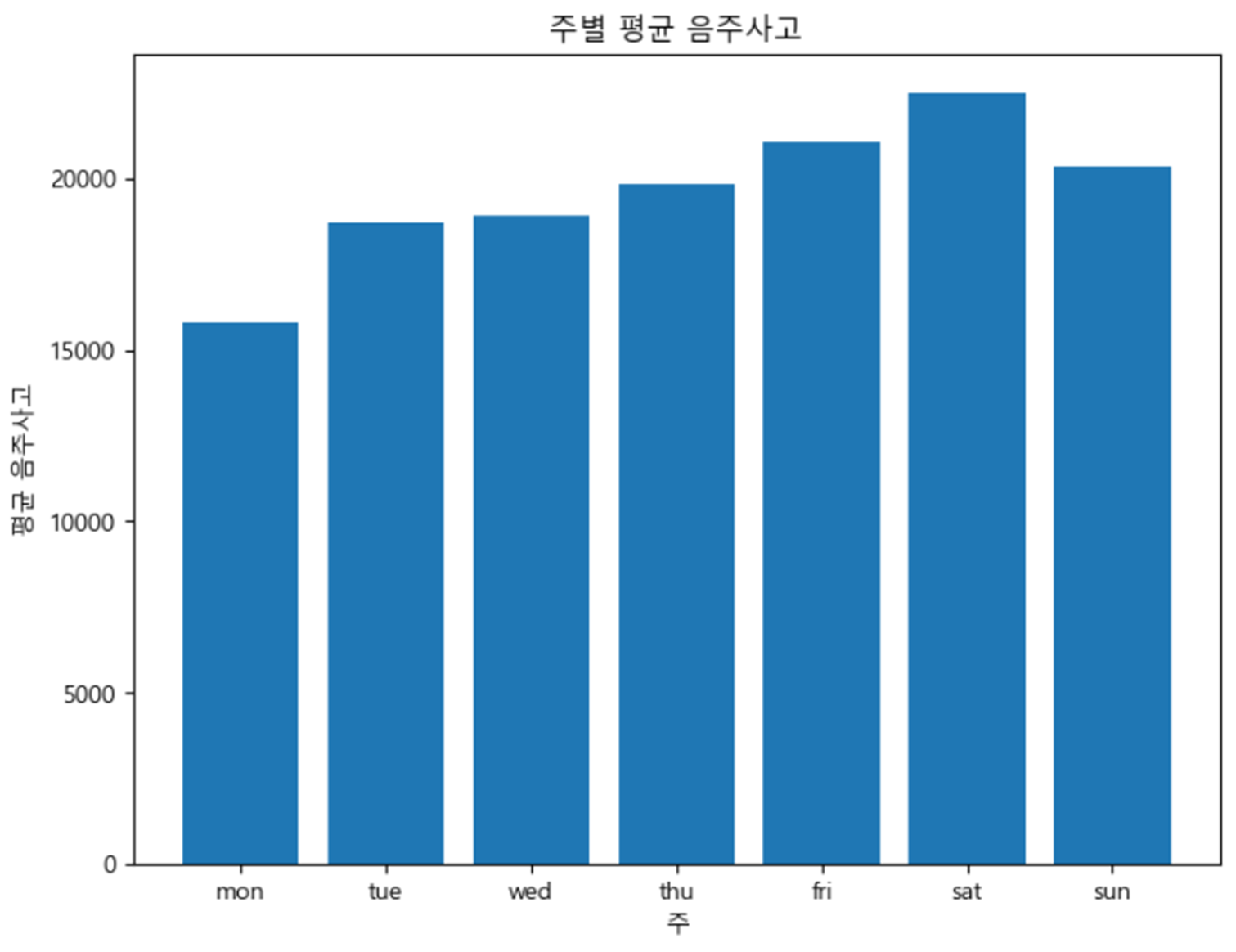
월요일을 제외하고는 전체적으로 고른 비슷한 수치를 보여줬지만 당연하게도 금, 토, 일이 가장 높은 음주운전 사고 수치를 보여줬다.
- 1년 중 무슨달에 많이 일어날까?
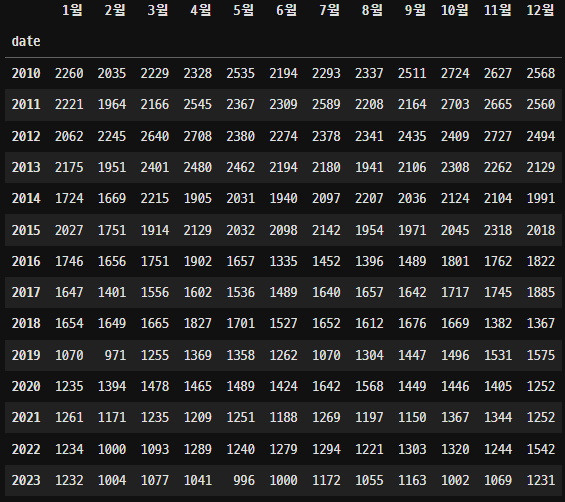
마찬가지로 경찰청에서 제공받은 데이터로 전처리 후 데이터 프레임을 만들었다.
2010년 - 2023년까지 다 그리기엔 너무 많아 각 월 별로 평균을 내어 시각화를 진행했다.
SELECT
ROUND(AVG(`1월`)) AS `1월`,
ROUND(AVG(`2월`)) AS `2월`,
ROUND(AVG(`3월`)) AS `3월`,
ROUND(AVG(`4월`)) AS `4월`,
ROUND(AVG(`5월`)) AS `5월`,
ROUND(AVG(`6월`)) AS `6월`,
ROUND(AVG(`7월`)) AS `7월`,
ROUND(AVG(`8월`)) AS `8월`,
ROUND(AVG(`9월`)) AS `9월`,
ROUND(AVG(`10월`)) AS `10월`,
ROUND(AVG(`11월`)) AS `11월`,
ROUND(AVG(`12월`)) AS `12월`
FROM
`teamproject-428905.kim.dui_month`
sql에서 가져올 때부터 평균으로 가져온 후 데이터 프레임이다.
plt.style.use ('ggplot')
avg_m_dui_df.plot()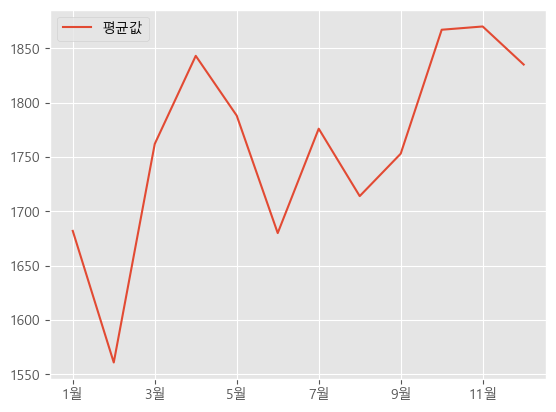
이 부분은 의외였던 것이 '당연히 연초와 연말이 가장 많이 일어났을 것이다.' 라고 생각하고 데이터를 뽑아보았는데 의외로 4월과 10월, 11월에 집중되어있었다.
날씨가 많이 추운 겨울과 많이 더운 여름이 아닌 날씨가 선선하고 야외에서 놀기 좋은
봄 / 가을에 음주운전 사고가 집중되는 것을 확인할 수 있었다.
누가??
- 어떤 연령대에서 많이 일어날까?
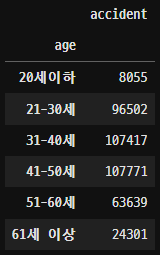
경찰청에서 수집한 데이터를 전처리 후 데이터프레임으로 만들었다.
plt.figure(figsize=(8, 10))
plt.pie(a_df['accident'], labels = a_df.index, autopct='%1.1f%%', startangle=140, colors=plt.cm.Paired.colors)
plt.title('Accidents by Age Group')
plt.axis('equal')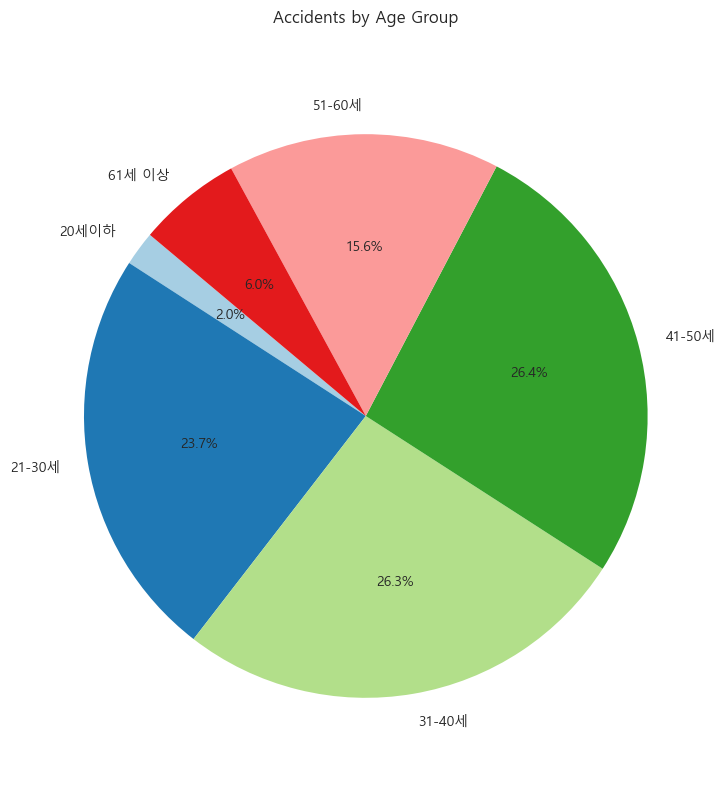
21세 ~ 50세 정도의 연령대에서 음주운전이 자주 발생하는 것을 보니 경제활동인구에서 음주운전이 잦게 일어나는 것을 확인할 수 있었다.
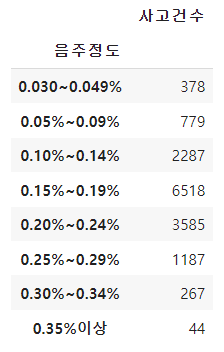
- 알콜혈중농도별로 나누어봤을 때 어떤 레벨에서 많이 일어날까?
plt.style.use ('ggplot')
level_df.plot(kind = "bar")
plt.xlabel("Drink")
plt.ylabel("Accident")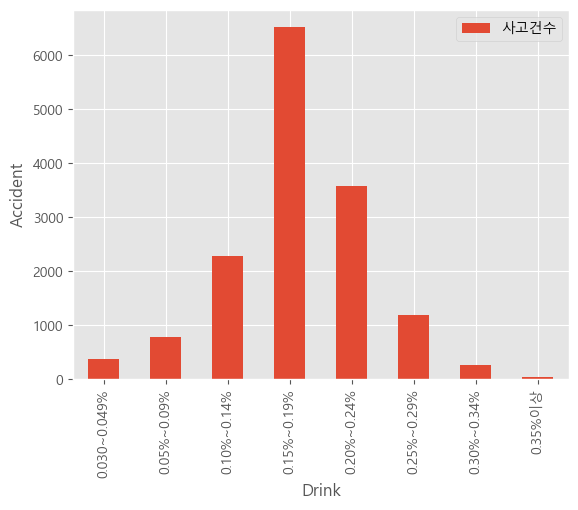
0.15% ~ 0.19% 대략 소주 1병 ~ 1병 반 정도의 양에서 음주운전률이 눈에 띄게 높았다. '이 정도면 운전해서 갈 수 있을 것 같은데?' 라는 안일한 생각을 불러오기 딱 적당한 취함이 아니었을까 하는 생각이다.
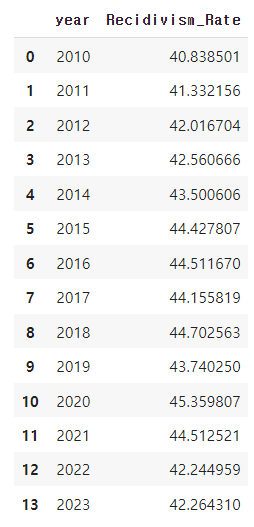
- 음주운전의 재범률은 어떻게 될까?
plt.figure(figsize=(12, 8))
plt.plot(df['year'], df['Recidivism_Rate'], marker='o', linestyle='-', color='blue')
plt.title('연도별 재범율')
plt.xlabel('연도')
plt.ylabel('재범율 (%)')
plt.grid(True)
for i in range(len(df)):
plt.text(df['year'][i], df['Recidivism_Rate'][i] + 0.5, f'{df["Recidivism_Rate"][i]:.2f}%', ha='center', va='bottom')
plt.show()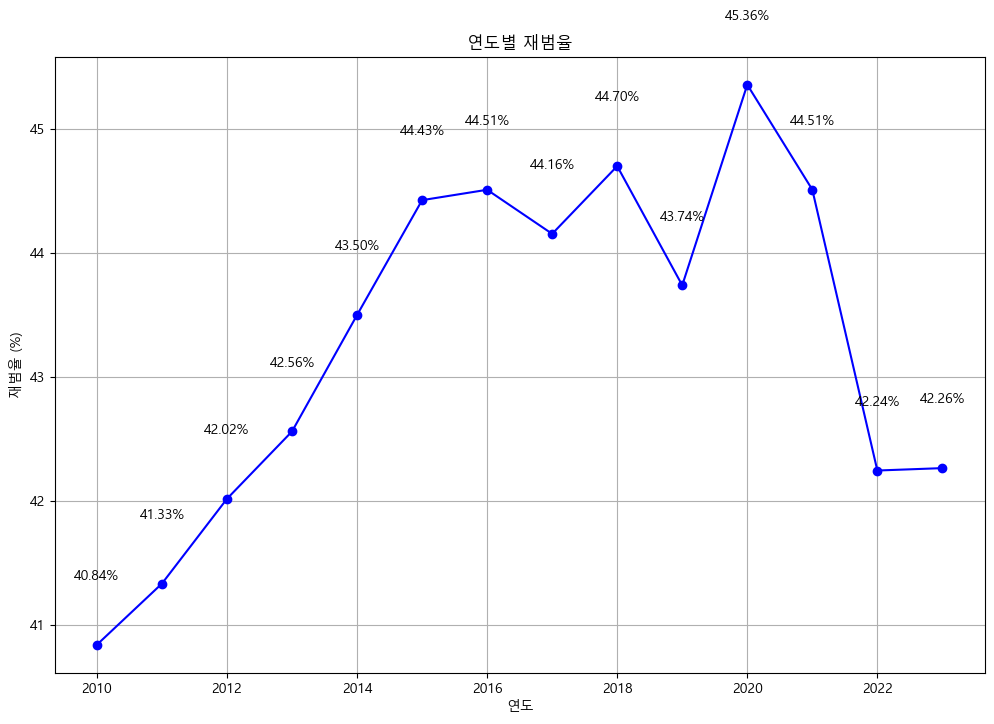
2010년 - 2023년까지 40%대를 웃돌고 있는 것을 확인할 수 있었다. 최근들어 2022년도 들어서 3%가량 줄어들긴했지만 여전히 높은 재범율을 보여주고 있었다.
- 음주운전 재범은 어느 성별에 많이 일어날까?

plt.figure(figsize=(10, 6))
bars = plt.bar(df['sex'], df['Recidivism_Rate'], color=['skyblue','pink', 'purple'])
plt.title('성별 재범율')
plt.xlabel('성별')
plt.ylabel('재범율 (%)')
plt.grid(axis='y')
for bar in bars:
yval = bar.get_height()
plt.text(bar.get_x() + bar.get_width()/2 - 0.1, yval + 0.5, round(yval, 2))
plt.show()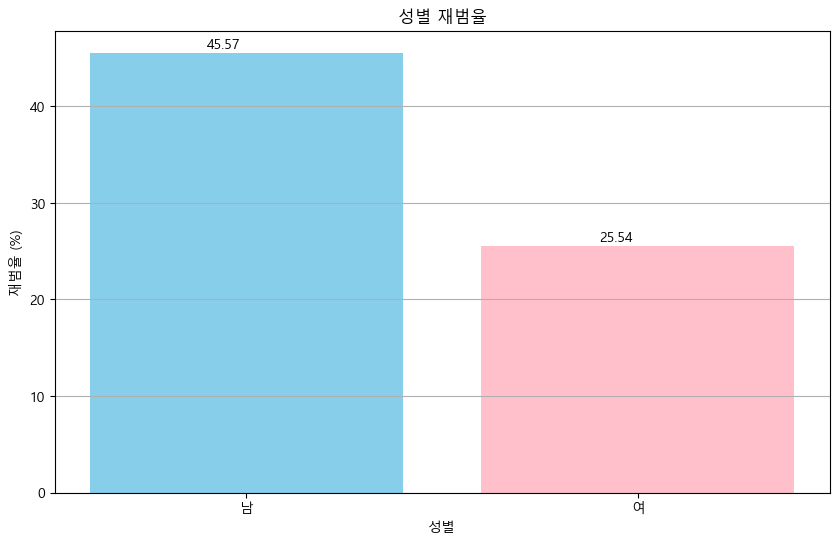
남성이 여성보다 대략 1.8배 가량 높은 수치를 보이는 것을 확인할 수 있었다.
- 그렇다면 음주운전의 재범율은 어느 연령대에서 높을까?
plt.figure(figsize=(13, 15))
colors = {'10대':'red', '20대':'blue', '30대':'green', '40대':'orange', '50대':'purple', '60대':'brown', '불상':'pink', '70대 이상':'gray'}
for age in df['age'].unique():
subset = df[df['age'] == age]
plt.scatter(subset['year'], subset['Recidivism_Rate'], color=colors[age], label=age, s=100)
plt.title('연도별 연령대별 재범율')
plt.xlabel('연도')
plt.ylabel('재범율 (%)')
plt.legend(title='연령대')
plt.grid(True)
for i in range(len(df)):
plt.text(df['year'][i], df['Recidivism_Rate'][i] + 0.5, f'{df["Recidivism_Rate"][i]:.2f}%', ha='center', va='bottom')
plt.show()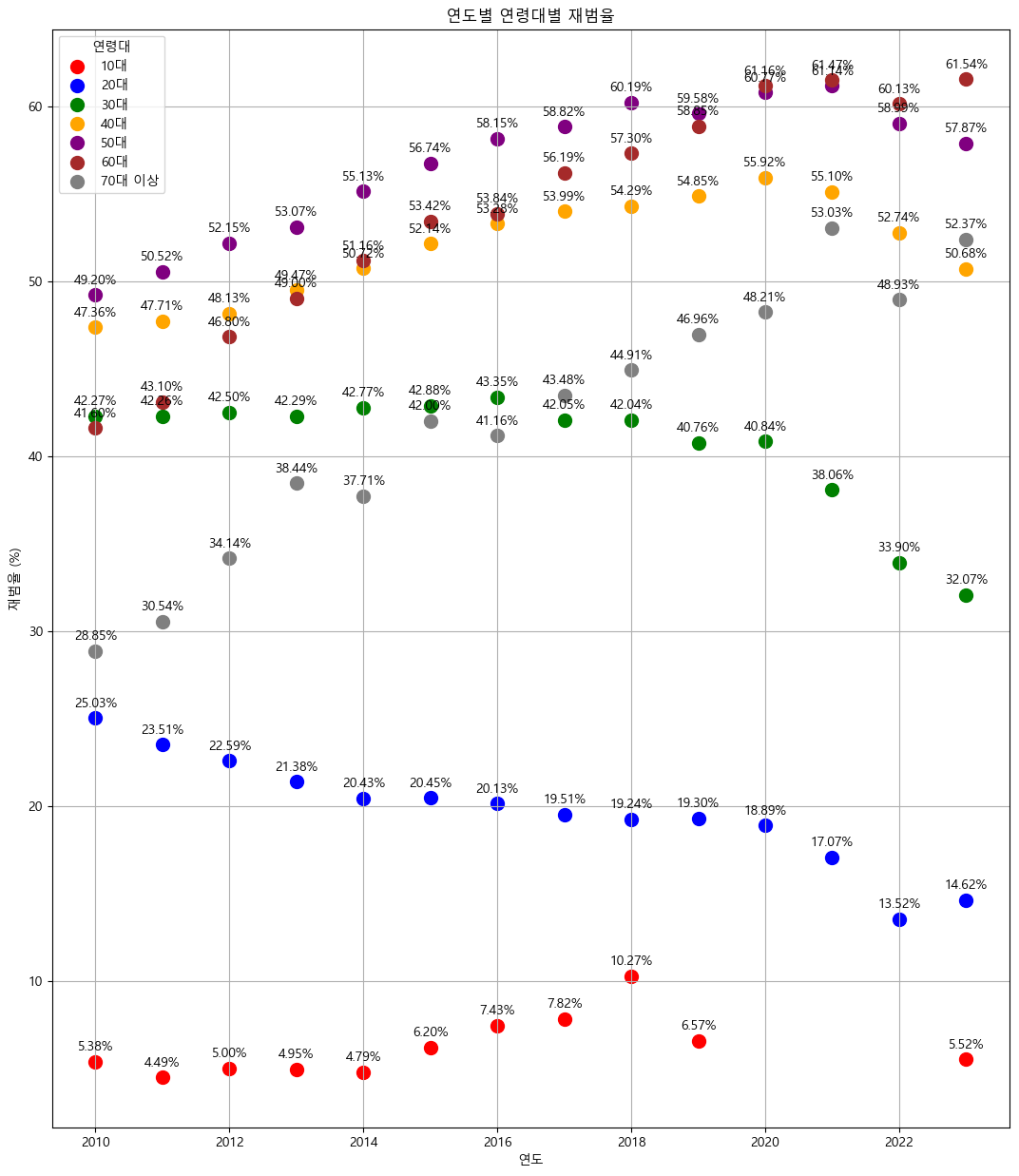
딱 봐도 연세가 어느 정도 있으신 40대 ~ 60대에서 높은 재범률을 보이는 것을 확인할 수 있었다.
어디서??
-
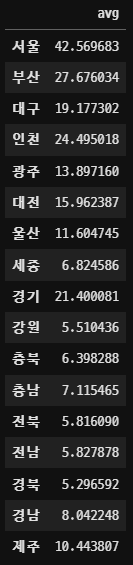
인구수 대비 음주운전이 많이 일어나는 곳은 어디일까?
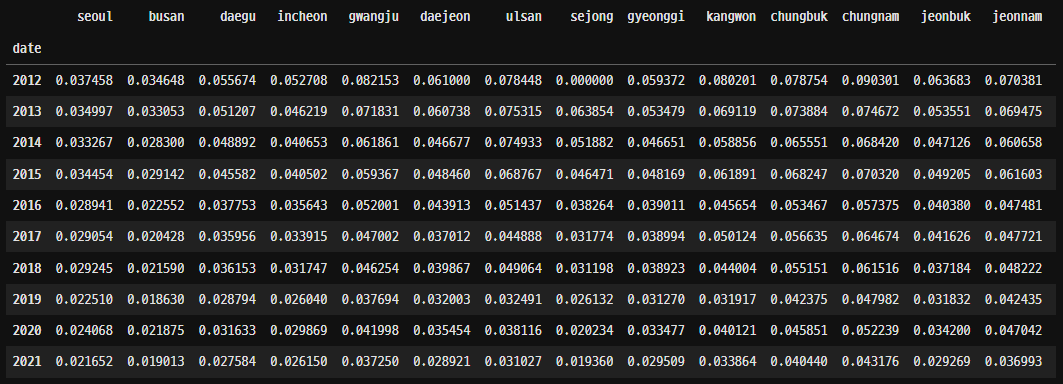
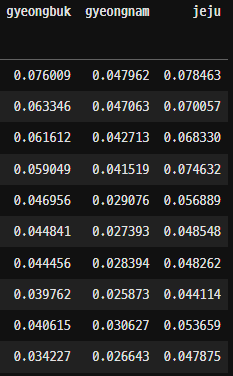
매년마다 평균을 내서 그래프를 그려보았다.
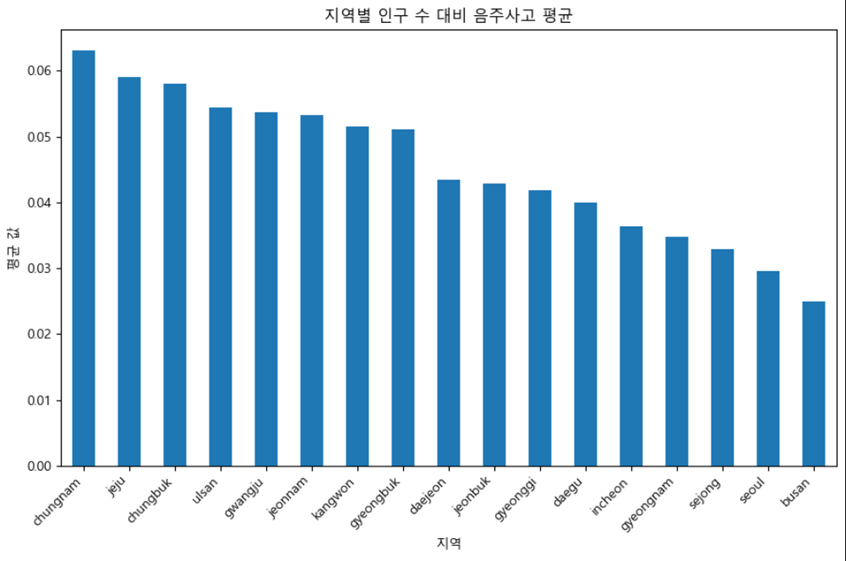
생각보다 수도권에 집중되어있을 줄 생각했던 것과는 달리 지방에서 음주운전이 잦게 일어난다는 것을 확인할 수 있었다. 기사도 찾아보고 높은 순위를 기록한 지역에 사는 사람들에게 전화해 물어보니 대체적으로 단속 자체가 거의 없다고 말하는 것을 확인할 수 있었다.
-
술을 판매하는 곳이 많은 곳이 음주운전을 많이 하지 않을까?
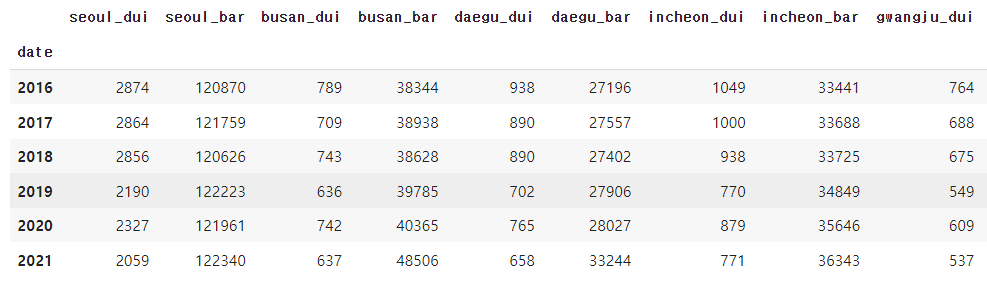
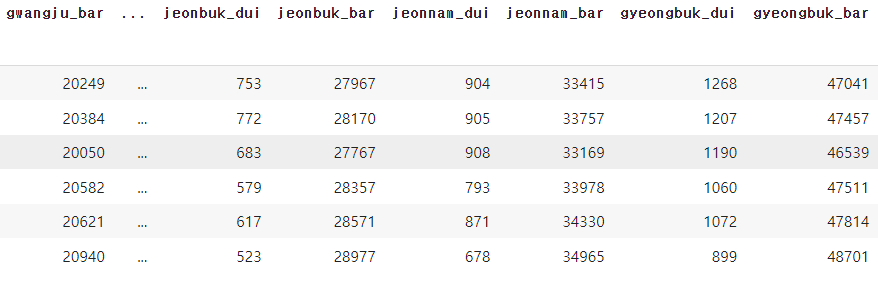
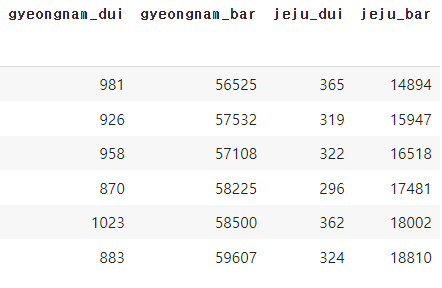
통계청과 경찰청에서 얻은 데이터를 데이터프레임화하였고 이를 통해 시각화를 진행.
plt.style.use("seaborn-v0_8-whitegrid")
fig, ax1 = plt.subplots(figsize = (12, 6))
ax1.plot(bd_city_df.index, bd_city_df['seoul_bar'], 'b-', label='Bar count')
ax1.set_xlabel('Date')
ax1.set_ylabel('Bar', color='b')
ax1.tick_params(axis='y', labelcolor='b')
ax1.grid(False)
_ = plt.xticks(size = 8, rotation=45, ha='right')
ax2 = ax1.twinx()
ax2.bar(bd_city_df.index, bd_city_df['seoul_dui'], width = 0.3, alpha = 0.5, color = "orange", label='DUI count')
ax2.set_ylabel('DUI', color='r')
ax2.tick_params(axis='y', labelcolor='r')
ax2.grid(False)
fig.suptitle('DUIs and bars by Seoul', fontsize = 16)
fig.legend(loc='upper left', bbox_to_anchor=(0.8, 0.8))이 코드를 계속 반복하여 각 지역별로 시각화를 진행.
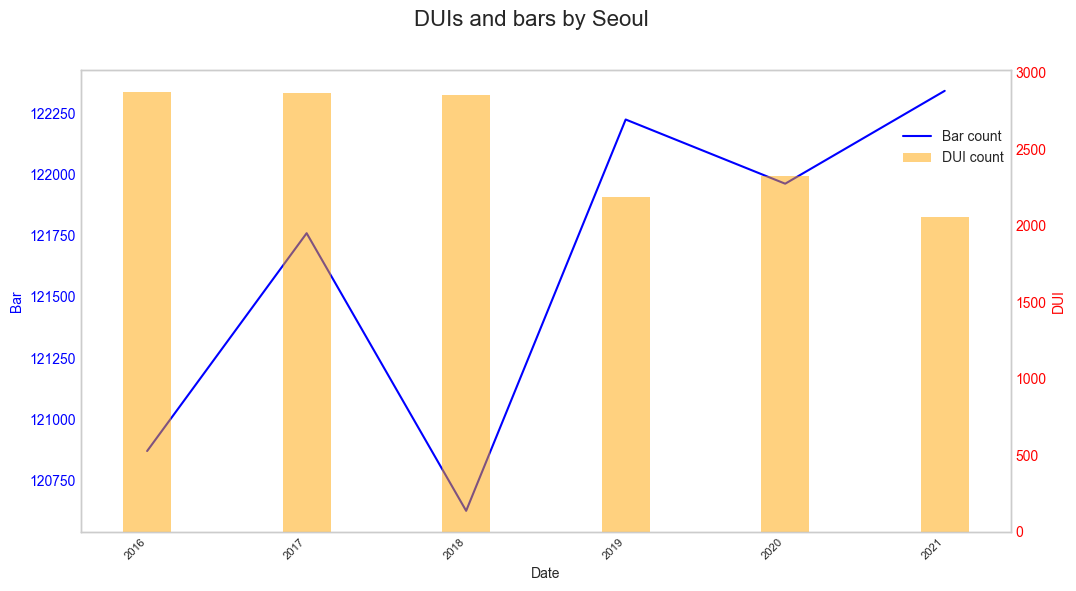
서울
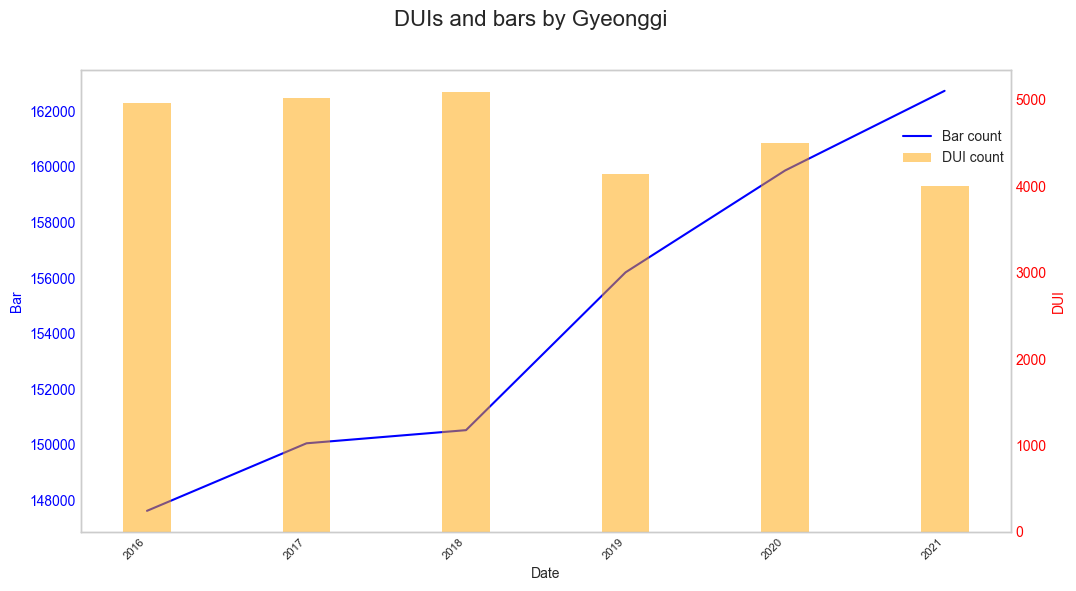
경기
강원
충북
충남
광주
울산
부산
제주
뭔가 패턴이 나올 것 같은 데이터들이어서 한껏 기대를 했었지만 시각화를 진행하였을 때 뚜렷이 보이는 패턴이 없어 상관관계가 적다고 판단하여 넘어갔다.
- 대중교통이 잘 갖춰지지 않았기에 음주운전을 하는게 아닐까?
각 연도별로 모아놓은 데이터를 평균을 내어 시각화를 진행했다.
plt.style.use('ggplot')
pp_df.plot(kind = "bar")
plt.title("< 지역별 인구수 대비 대중교통 이용 비율 >")
_ = plt.xticks(rotation=45)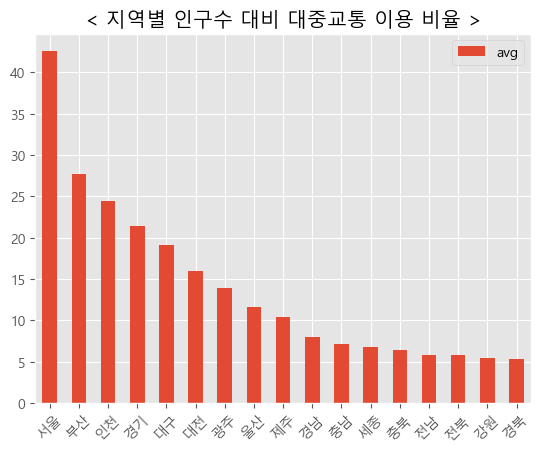
인구수 대비 음주운전 그래프와 이 그래프가 뭔가 패턴이 있을 것 같아서 그래프를 꺾은 선 그래프로 합쳐보았다.
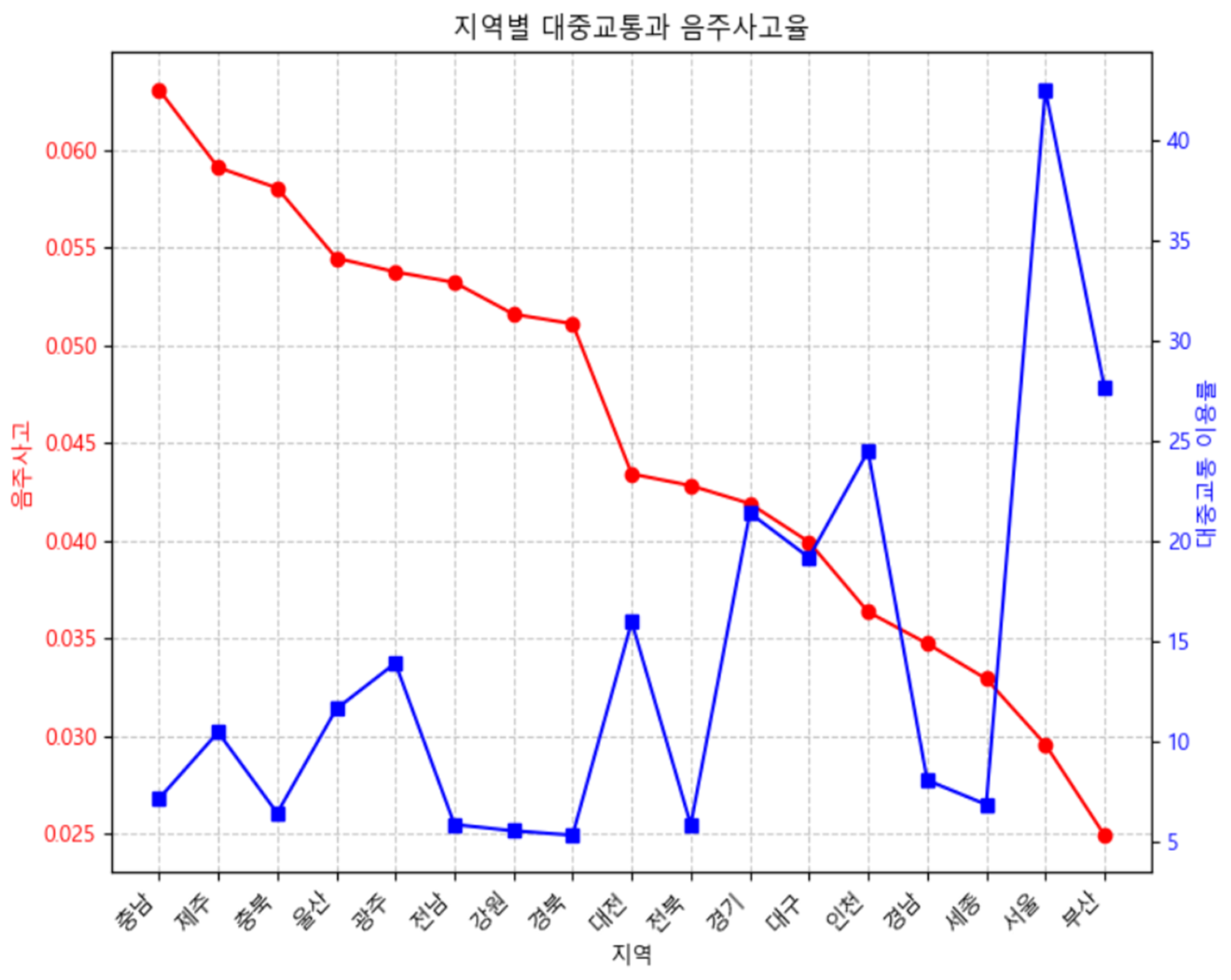
대중교통 이용률이 낮은 지방일수록 음주운전 사고율이 높은 것을 확인할 수 있었다.
또 다른 원인은 뭐가 있을까??
- 음주운전과 관련된 뉴스에 노출되어 위험도를 알게될수록 음주운전이 줄어들지 않을까?
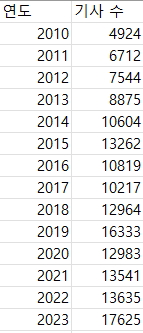
먼저 각 연도별 음주운전 관련 기사들을 웹에서 전부 크롤링한 후 카운트하여 데이터프레임으로 만들었다.
이를 위의 연도별 음주운전 발생 추이와 합쳐 그래프를 그려봤다.
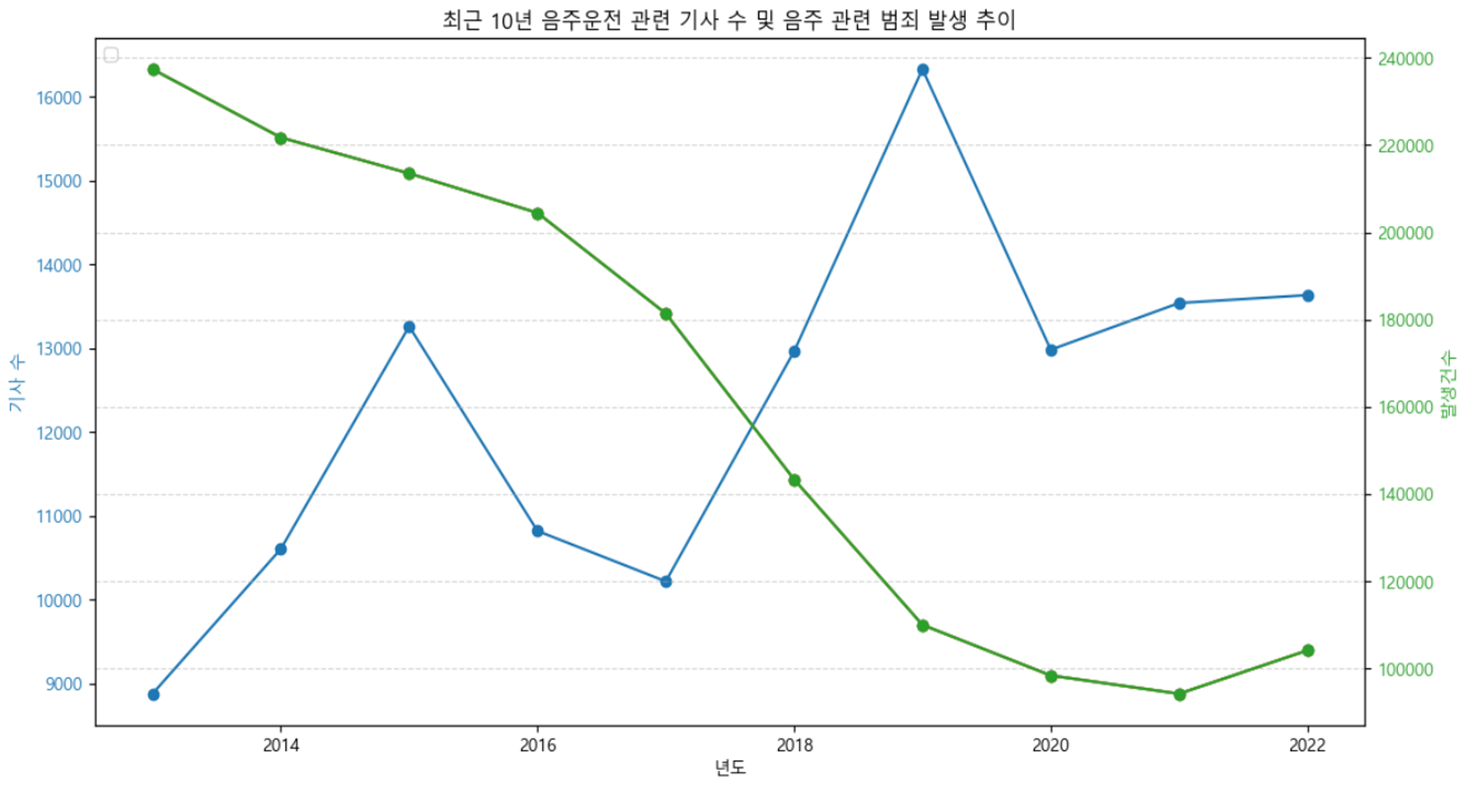
기사 수가 늘어날수록 음주운전 발생율 자체는 줄었다고 볼 수 있겠지만, 2020년도에 기사 수가 줄었는데 음주운전이 늘지 않은 걸로 봐서는 뚜렷한 결과라고는 할 수 없겠지만, '어느 정도의 영향은 있지 않았나' 하는 생각이 들었다.
정리
- 음주운전의 발생 건수는 줄어들고 있으나, 교통사고 중 음주운전이 차지하는 비율은 여전히 높은 편에 속한다.
- 음주운전 발생 및 재범자의 대부분은 경제활동인구가 주체이다.
- 음주사고는 주로 대중교통 이용률이 낮은 지역에서 잦게 일어나는 것 같다.
앞으로 나아가야할 방향
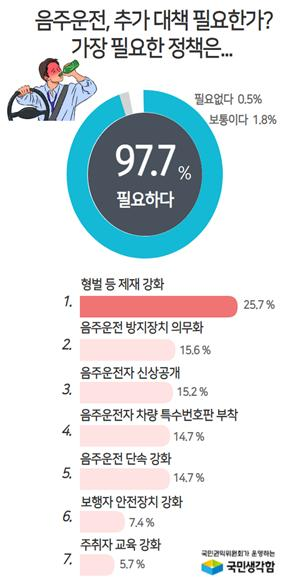
2023년 국민권익위원회가 국민들을 대상으로 설문조사를 진행하여 발표한 내용이다.
97.7% 대략 98%의 사람들이 음주운전의 추가 대책이 필요하다고 말하고 있다.
더불어 원하는 방향은 형벌 및 제재 강화와 같은 징벌적 수단의 강화가 필요하다고 말하고 있다.
그래서 다른 여러 나라들은 음주운전에 대한 처벌이 어떻게 이루어지는지 찾아보았다.
- 일본 : 직장 내 규정 강화, 직장에서 술자리 후 대중교통 이용비 지원
- 뉴질랜드 : 혈중 알콜농도 기준 0%
- 미국 : 면허 정지 및 재교육, 알콜 잠금 장치 설치 의무화
- 호주 : Random Breath Test 실시, 일간지 1면에 대문짝만하게 성명, 차량, 혈중알코올농도 표시
- 스웨덴 : 국가 기관에서 주류 판매, 고세율
- 러시아 : 운전자 뿐만 아니라 동승자까지 면허 정지
- 핀란드 : 한달 월급 몰수
- 싱가폴 : 음주운전 3회 적발시 태형
- 대만 : 영안실에서 시체닦기
- 터키 : 집에서 30km 떨어진 곳에 걸어오게 하기
- 대한민국
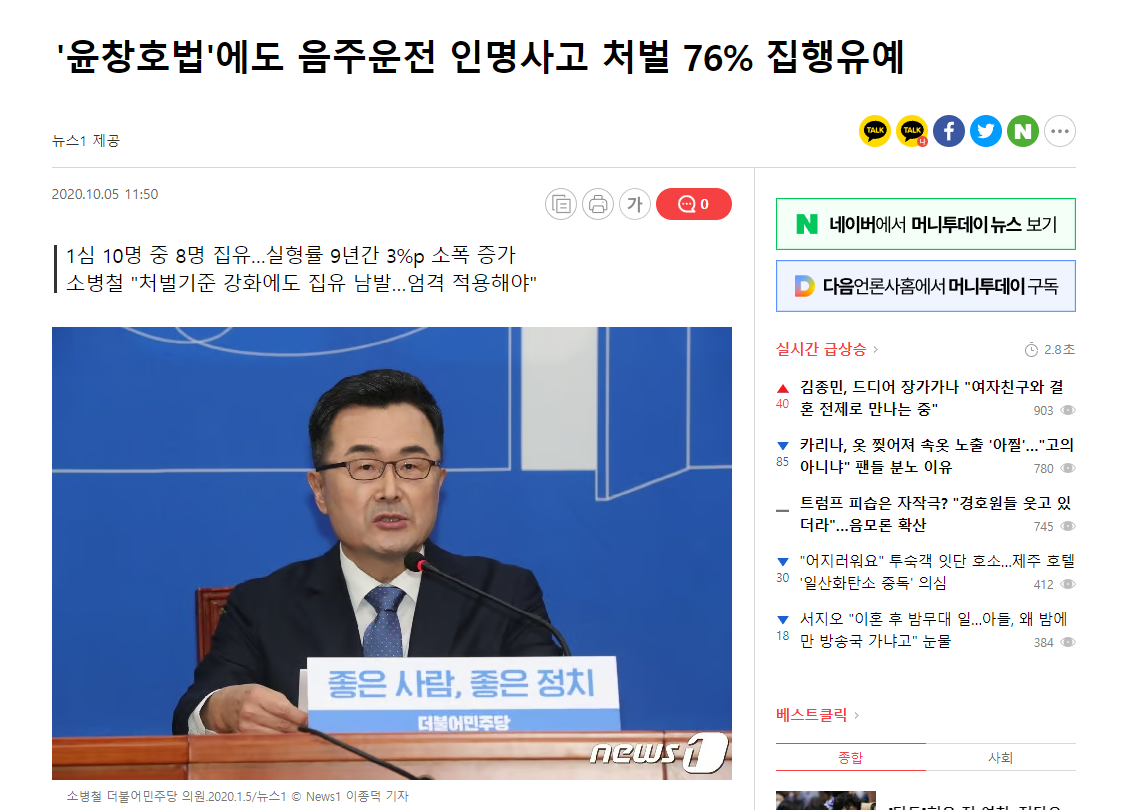
처벌 강화를 바라는 시민들의 이유를 정말 뼈저리게 느낄 수 있는 기사 사진 한장이었다.
따라서, 이렇제 제안하고 싶다.
1. 연령대별 음주운전 예방 캠페인 차별화 및 강화된 교육 추진
- 경제활동인구가 대부분의 음주운전을 발생시키므로 직장 내 의무적으로 교육을 추진하고 감사한다.
- 재발방지 전과자 치료 프로그램 강화 (현 : 적발 1회 12시간 교육 -> 3개월 부트캠프형식으로 강하게 진행)
2. 지역 맞춤형 해결책 제안 및 단속의 강화
- 각 지자체에서 대중교통 이용률을 명확히 분석하고 문제점을 파악하여 각 지역민들이 대중교통의 이용을 좀 더 편리하고 편안하게 경험할 수 있도록 해야한다.
- 평균적으로 음주운전사고가 많이 일어나는 월 / 일 / 시 별로 효율적으로 인원을 배치하고 많이 일어나는 지역은 더욱 더 집중 단속 및 특별단속기간을 늘려야한다.
3. 징벌적 제도의 강화
- 음주운전을 교통범죄가 아닌 강력범죄 및 살인으로 간주하고, 범죄자의 신상 공개
- '차량 위치 추적 번호판' 같은 음주운전 전과자 특수 번호판 의무화
- 음주운전 신고 포상금 인상
- 재발범죄자일 경우 주류 판매 제한 및 차량 압류 등의 강력한 재발 방지 대책 강구.
한계점 및 느낀점
음주운전의 원인에 대해서는 사실 사람이 발생시키는 사건이라 너무나도 많은 변수와 요인을 가지고 있었기 때문에 무엇 하나 정해서 '이게 원인일 것이다' 라고 판단하기가 너무 어려웠다. 그렇기에 분석해보고 싶었던 모든 데이터를 구할 수 없었고 제공되지도 않아서 한정된 데이터 속에서 최고의 인사이트들을 뽑아보려고 했지만 많이 어려웠다.
또한, 처음으로 진행된 팀프로젝트이자, 조금 큰 프로젝트여서 대화를 하면서 길을 잃은 적도 많았고, '이 분석이 왜 필요하지?' 하면서 이해가 가지 않는 분석을 하고 있는 나도 경험했었다.
혼자하는 것보다 수월했지만 혼자하는 것보다 더 어렵게 느껴지는 부분도 있었고, 생각만큼 만족할만한 인사이트도 뽑지 못해 너무너무 아쉬움이 많았던 이번 프로젝트였다.
이를 통해 내게 부족한 부분에 대해 명확히 짚어볼 수 있었고, 내가 가진 능력 중 어떤 부분이 모자르고 강화해야하는지 정확히 알 수 있는 프로젝트였고, 많은 것을 배울 수 있었던 프로젝트였다.
