
데이터 확인 및 전처리
1. 데이터 탐색 및 파악 (EDA)
# 데이터 불러오기
spaceship_df = pd.read_csv("./data/train.csv")
test_df = pd.read_csv("./data/test.csv")
- PassengerId : 승객 ID, gggg_pp 형식으로 여기서 gggg는 승객이 함께 여행하는 그룹을 나타내고 pp는 그룹 내 번호입니다.
- HomePlanet : 승객의 출발 행성
- CryoSleep : 냉동수면상태
- Cabin : 객실 번호로 Deck / Number / Side의 형태로 저장되어 있다. Side는 P 혹은 S
- Destination : 목적지
- Age : 나이
- VIP : 특별 VIP 서비스를 이용하는지 안하는지
- RoomService, FoodCourt, ShoppingMall, Spa, VRDeck : 우주선 내부 각 편의시설을 이용 후 결제한 금액
- Name : 이름과 성
- Transported : 다른 차원으로 이송되었는지 안되었는지 여부
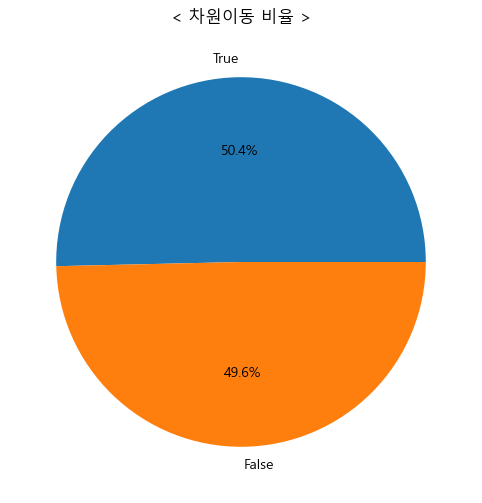
1. 차원이동 비율
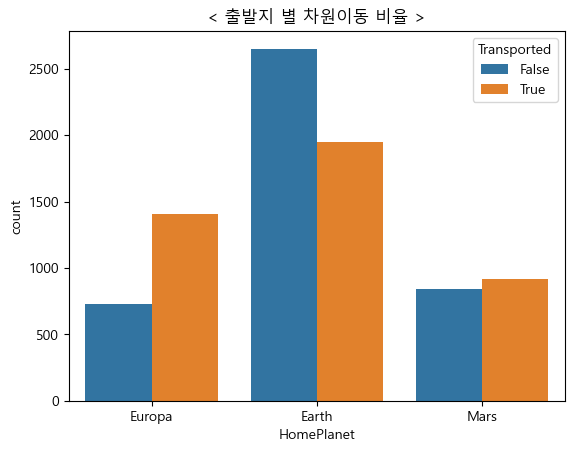
2. 출발 행성 별 차원이동 비율
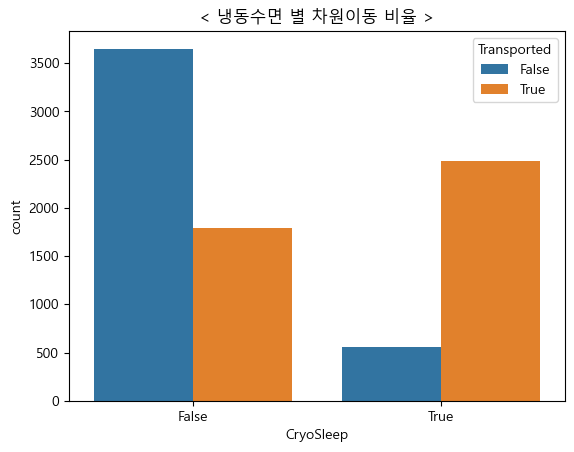
3. 냉동 수면 별 차원이동 비율
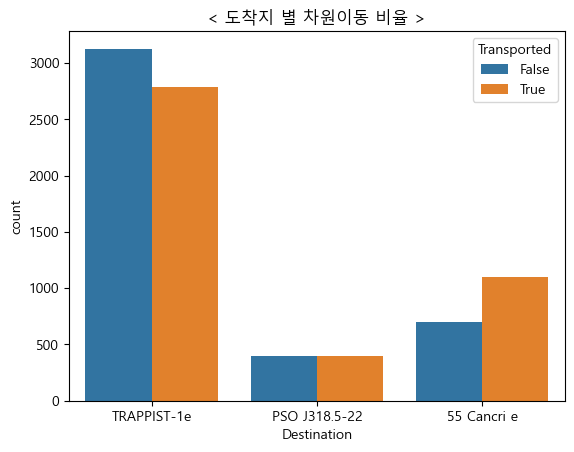
4. 도착지 별 차원이동 비율
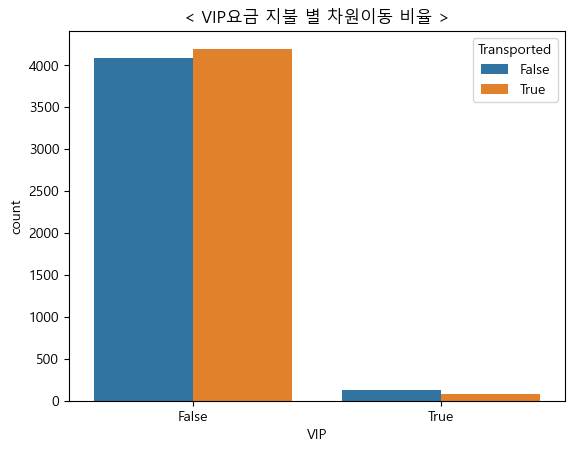
5. VIP 요금 지불 별 차원이동 비율
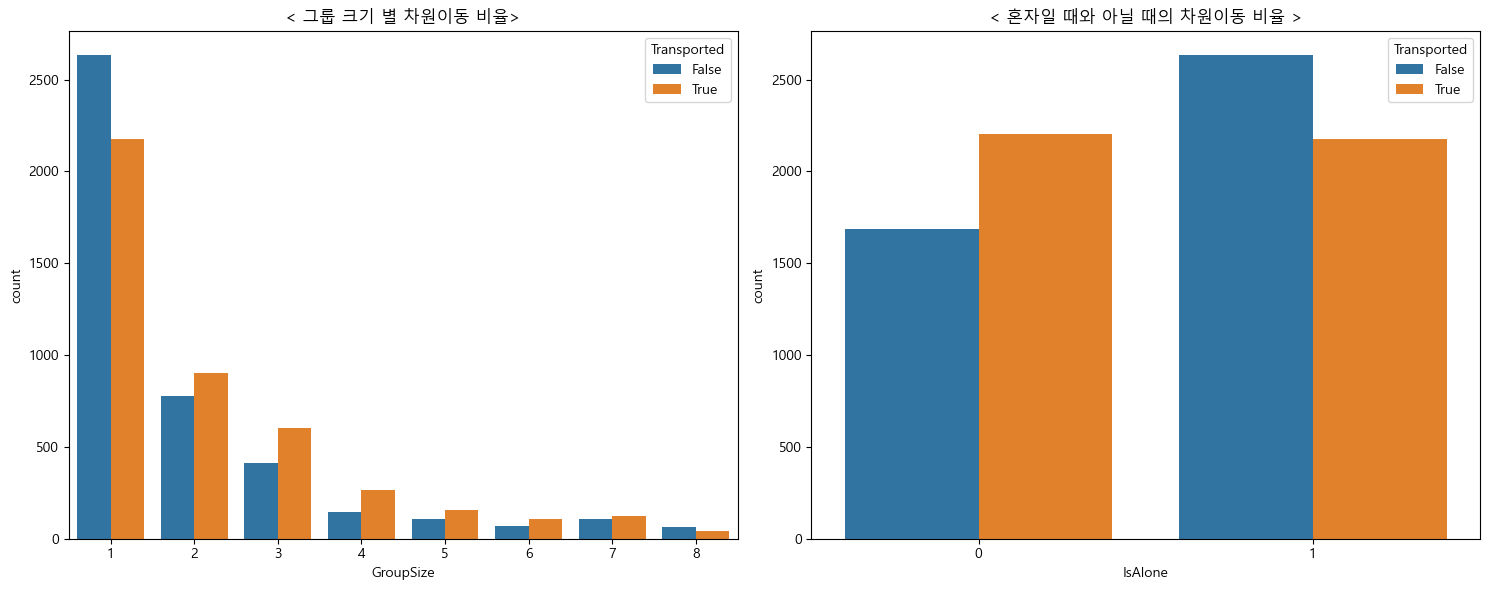
6. 그룹 크기 별, 혼자일 때 아닐 때 차원이동 비율
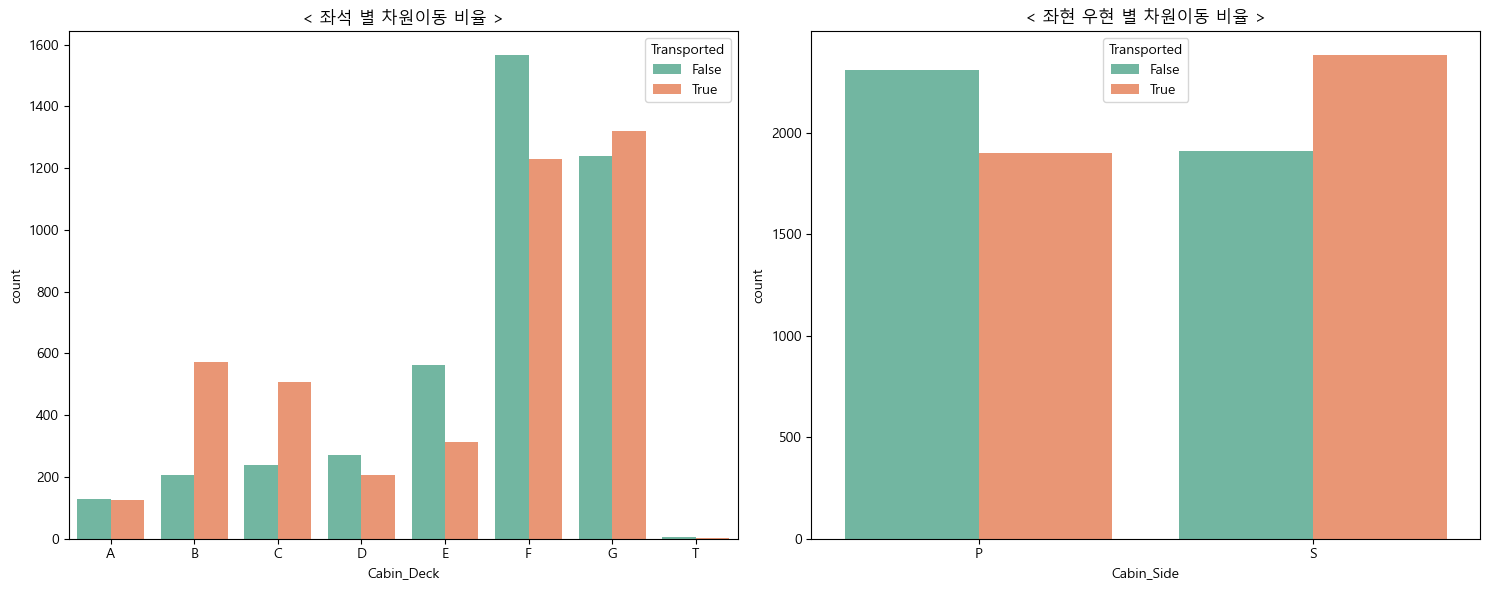
7. 자리 별 차원이동 탐색
2. 데이터 특성 확인
# 불러온 데이터 합치고 정리하기
df = pd.concat([spaceship_df, test_df])
df = df.reset_index(drop = True)
df = df.drop(["Name"], axis = 1)
# 데이터 특성 파악
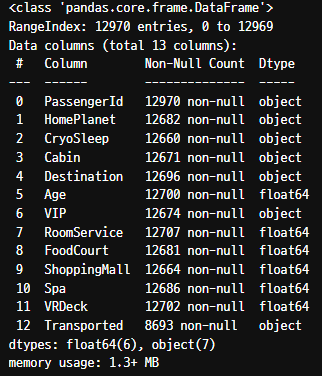
df.shape
df.info()
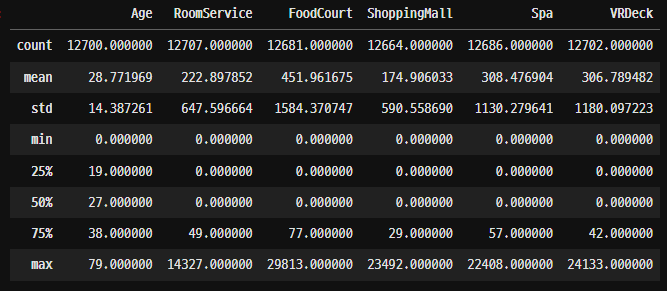
df.describe()- 12970행 / 13 열을 가진 데이터 프레임.
- 각 컬럼 별 데이터 타입
- 수치형 컬럼 통계량 확인
3. 파생변수 만들기
GroupSize & IsAlone 만들기
# 임시 데이터 프레임 생성
tmp_df = df.copy()
# gggg_pp 에서 뒤에 붙은 pp 떼고 그룹 넘버로만 만들어주기
new_passenger_id = []
for c in df["PassengerId"]:
tmp = ""
for d in c:
if d != "_":
tmp += d
else:
new_passenger_id.append(tmp)
break
tmp_df["PassengerId"] = new_passenger_id# 떼어버린 pp를 그룹사이즈로 표기하기 위해 전처리
cnt_p_id = Counter(new_passenger_id)
# 각 그룹 별 인원수 넣어주기
group_num = []
for c in tmp_df["PassengerId"]:
group_num.append(cnt_p_id[c])
tmp_df["group_num"] = group_num# group_num이 1보다 크면 혼자온게 아니므로 IsAlone값을 0 혼자 왔으면 1
tmp_df["IsAlone"] = 1
tmp_df.loc[tmp_df["group_num"] > 1, "IsAlone"] = 0
# 원래의 데이터 프레임에 넣어주기
df["GroupSize"] = tmp_df["group_num"]
df["IsAlone"] = tmp_df["IsAlone"]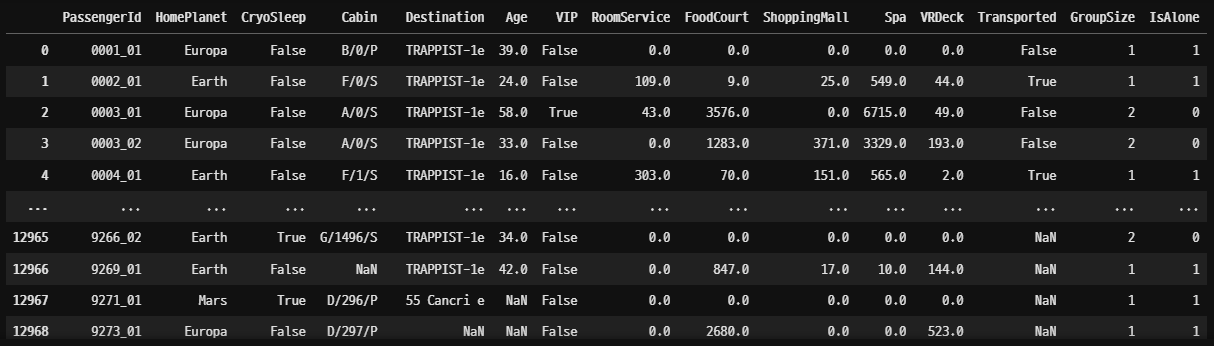
Cabin 나눠주기
deck = []
number = []
side = []
# cabin을 "/"을 기준으로 나누어서 넣어주기
for c in df["Cabin"]:
if type(c) == float:
deck.append(np.nan)
number.append(np.nan)
side.append(np.nan)
else:
a = c.split("/")
deck.append(a[0])
number.append(a[1])
side.append(a[2])
# 데이터 프레임에 추가
df["Cabin_Deck"] = deck
df["Cabin_Num"] = number
df["Cabin_Side"] = side
# 필요없는 Cabin 데이터 드랍
df = df.drop(["Cabin"], axis = 1)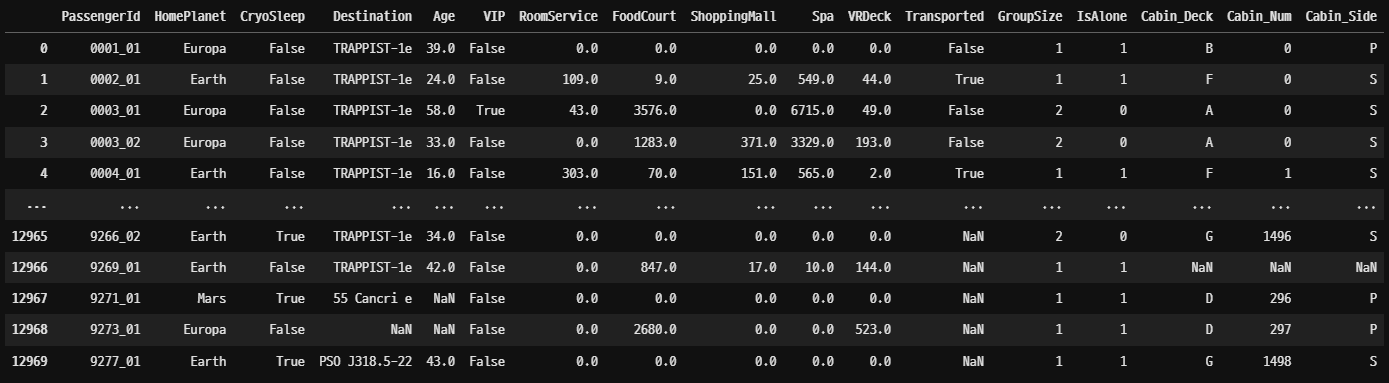
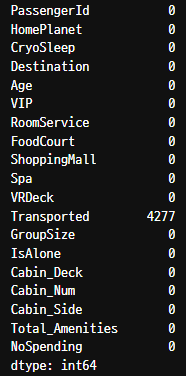
4. 결측치 처리
최빈값으로 채워주기
Destination, VIP, HomePlanet, CryoSleep 채워주기
df[["Destination",
"VIP",
"HomePlanet",
"CryoSleep"]] = df[["Destination",
"VIP",
"HomePlanet",
"CryoSleep"]].fillna(df[["Destination",
"VIP",
"HomePlanet",
"CryoSleep"]].mode().iloc[0])RoomService, FoodCourt, ShoppingMall, Spa, VRDeck 채워주기
df[["RoomService",
"FoodCourt",
"ShoppingMall",
"Spa",
"VRDeck"]] = df[["RoomService",
"FoodCourt",
"ShoppingMall",
"Spa",
"VRDeck"]].fillna(0)Total_Amenities, NoSpending 만들기
# Total_Amenities 만들기
df["Total_Amenities"] = df["RoomService"] + df["FoodCourt"] +
df["ShoppingMall"] + df["Spa"] + df["VRDeck"]
# NoSpending 돈을 썼는지에 관한 변수
df["NoSpending"] = 1
df.loc[df["Total_Amenities"] > 1, "NoSpending"] = 0각 조건 별로 채워주기
Cabin 채워주기
for col in ['Cabin_Deck', 'Cabin_Num', 'Cabin_Side']:
df[col] = df[col].where(df['IsAlone'] == 1, df[col].ffill())
df[['Cabin_Deck',
'Cabin_Num',
'Cabin_Side']] = df[['Cabin_Deck',
'Cabin_Num',
'Cabin_Side']].fillna(df[['Cabin_Deck',
'Cabin_Num',
'Cabin_Side']].mode().iloc[0])Age 채워주기
# 출발지와 도착지 별 평균 나이값으로 채워주기
df["Age"] = df["Age"].fillna(df.groupby(["HomePlanet",
"Destination"])["Age"].transform("mean"))결측치 확인
5. 각 종류 별 데이터 전처리
범주형 데이터 인코딩
- Label Encoding
CryoSleep, VIP, Cabin_Side, Cabin_Num 적용
# CryoSleep 인코딩
label_encoder.fit(df["CryoSleep"])
df["IsSleep"] = label_encoder.transform(df["CryoSleep"])
# VIP 인코딩
label_encoder.fit(df["VIP"])
df["IsVIP"] = label_encoder.transform(df["VIP"])
# Cabin_Side 인코딩
label_encoder.fit(df["Cabin_Side"])
df["Side"] = label_encoder.transform(df["Cabin_Side"])
# Cabin_Num 인코딩
df["Num"] = label_encoder.transform(df["Cabin_Num"])
df = df.drop(["Cabin_Num"], axis = 1)
# 인코딩 후 드랍
df = df.drop(["CryoSleep", "VIP", "Cabin_Side", "Cabin_Num"], axis = 1)- One-Hot Encoding
HomePlanet, Destination, Cabin_Deck 적용
# HomePlanet 인코딩
homeplanet_dummies = pd.get_dummies(df["HomePlanet"],
prefix = "HomePlanet", dtype = int)
df = pd.concat([df, homeplanet_dummies], axis = 1)
# Destination 인코딩
destination_dummies = pd.get_dummies(df["Destination"],
prefix = "Destination",
dtype = int)
df = pd.concat([df, destination_dummies], axis = 1)
# Cabin_Deck 인코딩
deck_dummies = pd.get_dummies(df["Cabin_Deck"],
prefix = "Deck", dtype = int)
df = pd.concat([df, deck_dummies], axis = 1)
# 인코딩 후 드랍
df = df.drop(["HomePlanet", "Destination", "Cabin_Deck"], axis = 1)연속형 확률 변수 전처리
Age, GroupSize, RoomService, FoodCourt, ShoppingMall, Spa, VRDeck, Total_Amenities 전처리
# Age와 GroupSize를 Standard Scaler를 사용해 전처리
df[["Age"]] = standard_scaler.fit_transform(df[["Age"]])
df[["GroupSize"]] = standard_scaler.fit_transform(df[["GroupSize"]])
# 각종 Amenities들은 log스케일을 취한 후 Standard Scaler로 전처리
df[["RoomService",
"FoodCourt",
"ShoppingMall",
"Spa",
"VRDeck"]] = np.log1p(df[["RoomService",
"FoodCourt",
"ShoppingMall",
"Spa",
"VRDeck"]])
df[["RoomService",
"FoodCourt",
"ShoppingMall",
"Spa",
"VRDeck"]] = standard_scaler.fit_transform(df[["RoomService",
"FoodCourt",
"ShoppingMall",
"Spa",
"VRDeck"]])
# Total_Amenities도 Standard Scaler를 사용해 전처리
df[["Total_Amenities"]] = standard_scaler.fit_transform(df[["Total_Amenities"]])
6. 전처리 후 데이터 셋 분리
# 전체 데이터를 분리
spaceship_df = df.iloc[:8693]
test_df = df.iloc[8693:]
# test 데이터 셋의 Trasported 컬럼 드랍
test_df = test_df.drop(["Transported"], axis = 1)
# 데이터 분리저장
spaceship_df.to_csv("./final_data/preprocessed_final_spaceship.csv",
index = False, encoding = "utf-8")
test_df.to_csv("./final_data/preprocessed_final_test.csv",
index = False, encoding = "utf-8")모델 적용 및 Test data 예측
1. 데이터 불러온 후 종속변수, 독립변수 지정
# 전처리 후 저장한 spaceship.csv / test.csv 파일 불러오기
spaceship_df = pd.read_csv("./data/preprocessed_final_spaceship.csv")
test_df = pd.read_csv("./data/preprocessed_final_test.csv")
# y_spaceship : 종속변수 / x_spaceship : 독립변수
y_spaceship = spaceship_df["Transported"]
x_spaceship = spaceship_df.drop(["PassengerId", "Transported"], axis = 1)2. Random Forest, LightGBM, CatBoost 모델 적용 후 교차 검증
- 각 모델에 적용
# Random Forest 모델
model_RF = RandomForestClassifier(
criterion = "entropy",
random_state = 1234
)
model_RF.fit(x_spaceship, y_spaceship)
# LightGBM 모델
model_LGBM = lgb.LGBMClassifier(verbose = -1)
model_LGBM.fit(x_spaceship, y_spaceship)
# CatBoost 모델
model_CB = CatBoostClassifier(verbose = 0)
model_CB.fit(x_spaceship, y_spaceship)- 교차 검증
# stratified_kf 를 사용해 교차검증 실시
stratified_kf = StratifiedKFold(n_splits = 5,
shuffle = True,
random_state = 1234)
# 각 모델에 교차검증 후 평균 점수 확인
score_RF = cross_val_score(model_RF, x_spaceship, y_spaceship, cv = stratified_kf)
score_LGBM = cross_val_score(model_LGBM, x_spaceship, y_spaceship, cv = stratified_kf)
score_CB = cross_val_score(model_CB, x_spaceship, y_spaceship, cv = stratified_kf)
print(score_RF.mean())
print(score_LGBM.mean())
print(score_CB.mean())Random Forest : 0.793511
LightGBM : 0.809731
CatBoost : 0.811455
CatBoost 가 가장 높은 평균점수를 획득한 것을 확인하여 최종 테스트 데이터에 CatBoost 적용
3. 모델에 적용
# CatBoost 모델에 적용
model = CatBoostClassifier(verbose = 0)
model.fit(x_spaceship, y_spaceship)
# CatBoost 모델로 test 데이터 예측
y_test = model.predict(x_test)
# 예측한 값을 test 데이터에 적용
test_df["Transported"] = y_test
# 제출양식에 맞추어 csv파일로 저장
test_df[["PassengerId", "Transported"]].to_csv("./final_data/sample_submission_final.csv",
index = False)제출


느낀 점
'데이터 전처리의 정답은 없다'를 정말 쉴 새 없이 느낄 수 있었던 프로젝트였다.
정말 설명서 없는 레고를 조립하는 느낌이어서 이게 맞는지 저게 맞는지 알 수가 없어서 결국 머리 속에서 떠오르는 모든 방법들을 하나씩 하나씩 직접 해보면서 정확도가 떨어졌다 올라갔다를 반복했다.
또한, 데이터 전처리 과정 (파생변수 만들기, 결측치를 채우기 등)을 완벽하게 하려고 하면 할수록 정확도는 오히려 떨어지는 경험을 했다.
거의 40번 정도 제출을 했는데 생각보다 러프하게 전처리를 한 파일들이 오히려 더 높은 점수를 받았다.
무엇 때문인지 각 feature의 중요도를 보고 했는데도 감이 오지 않아 정말 답답한 순간들이 너무 많았다.
후에 지금보다 더 지식을 쌓고 경험을 쌓으면서 머신러닝 모델의 학습이 어떻게 이루어지고, 어떤 방식으로 이루어지는지 직접적으로 책을 보거나 논문을 살펴보면서 공부해야겠다는 생각이 무척 강하게 들었다.
여전히 공부해야할 건 많고 터득해야할 지식은 수없이 많다는 걸 깨닫게해준 귀중한 프로젝트 경험이었다.
