
"Why should I trust you?" Explaining the predictions of any classifier
해당 논문은 머신러닝, 특히 XAI 분야에 관심이 있으신 분들은 들어보셨을 LIME이란 "머신러닝 모델을 설명하는 기법"을 제시한 2016년 논문입니다.
Abstract :
머신러닝 모델의 상용화에도 불구하고, 많은 머신러닝 모델들은 여전히 black box(정확한 판단 과정을 확인할 수 없음) 형태이다.
하지만 예측의 근거를 알아야 모델의 신뢰도를 평가할 수 있고, 모델에 대한 인사이트를 통해 모델을 개선할 수 있다.
본 연구에서는
- 예측에 대해 해석 가능한 모델을 국소적으로(locally) 학습하는 것으로, 어떤 분류기의 예측에도 적용 가능한 LIME 기법을 제시한다.
- 전체 모델을 효율적으로 설명하기 위해 필요한 개별 예측들에 대한 설명을 중복 없이 선택하는 과정을 submodular optimization problem으로 정의한다.
- 여러 모델에 대해 본 연구에서 제시한 방법론의 효과를 검증한다.
1. Introduction
최근에 과학 / 기술 분야에서 이루어진 많은 발전이 기계학습을 토대로 하고 있습니다. 하지만 안타깝게도, 기계학습 분야에서는 종종 "사람"의 역할이 간과되고는 합니다.
Trust
사용자가 모델이나 예측 결과를 신뢰하지 않으면, 사용하지도 않을 것이다.
원문에서는 trust로 언급된 신뢰에는 두가지 종류가 있습니다.
1. 예측에 대한 신뢰 : 개별 예측 결과를 믿고 그에 따라 행동하는 것 = 예측을 믿어도 되는가?
2. 모델에 대한 신뢰 : 모델이 충분히 합리적이라고 판단하여 실제로 사용하는 것 = 모델을 사용해도 되는가?
다르게 이야기하자면, 예측에 대한 신뢰는 "의사결정"에 영향을 끼치는 것이고 모델에 대한 신뢰는 실제 세계에 모델을 적용할 지 여부를 판단하는 것입니다.
예시를 들어볼까요?
Trusting a prediction
병원에서 환자의 상태를 판단하는 모델이 있다고 생각해 봅시다. 모델이 환자 A가 위험하다, 또는 위험하지 않다고 판단했을 때 예측 결과를 그대로 믿을 수 있을까요? 단순히 "모델이 그렇다는데?"라는 근거만을 가지고 의사가 의사결정을 함에 있어서 환자의 목숨을 건 도박을 하지는 않을 겁니다.
Trusting a model
어찌저찌 모델을 데이터로 학습시켰다고 해도, 대부분의 경우 모델을 바로 실제 문제 상황에 투입하지는 않습니다. 모델이 제대로 돌아갈지 모르니까요. 그래서 많은 경우 학습에 사용되지 않은 검증용 데이터로 정확도와 연관된 여러 평가 지표를 확인합니다. 그런데 정확도만으로는 모델에 대해 제대로 판단할 수 없는 경우가 존재합니다.

호날두와 메시를 구별하는 이미지 모델이 있다고 생각해 봅시다. 그런데 훈련용 데이터와 검증용 데이터에 있는 사진은 각각 레알 마드리드 시절과 바르셀로나 시절의 사진 뿐이어서, 모델이 실제로는 얼굴을 보고 구별하는 것이 아니라 흰색 옷이면 호날두, 빨강 / 파랑의 줄무늬면 메시로 구별을 하게 학습이 되어버렸습니다.

그렇다면 실제 상황에 적용했을 때 국가대표 유니폼이나 다른 팀의 유니폼, 혹은 정장을 입은 모습의 메시와 호날두를 제대로 구분하지 못할 것입니다. 정확도와 같은 평가 지표가 뛰어남에도 불구하고 말이죠. 하지만 정확도 뿐 아니라 개별 예측과 그에 대한 설명을 확인한다면, 모델이 판단 근거를 얼굴이 아닌 유니폼으로 본다는 것을 확인할 수 있을 것입니다.
그렇다고 개별 예측에 대한 정보를 수만, 수십만의 데이터를 일일이 까보면서 확인해 볼 수는 없으니, 어떤 데이터를 확인해야 할지 효율적으로 제안해주는 것이 곧 모델에 대한 신뢰와 직결된다고 볼 수 있겠습니다.
Main contribution
연구의 주요 내용은 다음과 같습니다.
- LIME : 어떤 회귀 / 분류 모델의 예측을, 해석 가능한 모델로 locally 근사하여 설명하는 알고리즘. 예측에 대한 신뢰를 제공
- SP-LIME : submodular optimization을 통해 데이터 내에서 대표성을 가지는 instance의 집합을 선택하여, 이들에 대한 LIME 설명 결과로 모델을 설명. 모델에 대한 신뢰를 제공.
- Simulated user와 실제 인간 피실험자를 통한 효과 검증
이번 글에서는 LIME과 SP-LIME에 대한 설명까지 다뤄볼 예정입니다.
2. The case for explanations
논문에서는 예측을 설명한다는 것을, "해당 instance의 요소들과 모델의 예측 사이의 관계에 대해 질적인 이해를 돕는 텍스트나 시각화 자료를 제시하는 것" 이라고 정의합니다. instance가 텍스트인 경우에는 각 단어들을 요소로 볼 수 있습니다. 논문의 예시를 볼까요?
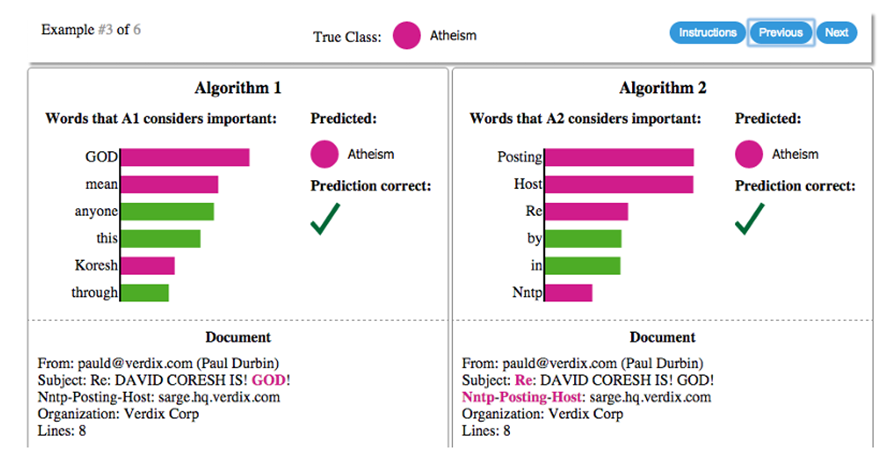
해당 텍스트가 "무신론"과 "기독교" 중 어디에 더 가까운지 분류하는 모델에 대한 설명입니다. 각각 어떤 단어가 예측에 영향을 줬는지 확인할 수 있습니다.
한편 질적인 이해를 돕는다는 건, 사람이 가지고 있는 도메인 영역의 지식과 비교하는 것으로 예측의 신뢰도를 판단할 수 있다는 이야기입니다. 그림의 알고리즘 2에서 중요하다고 판단한 단어들은 답장을 의미하는 "Re", 이메일을 호스팅하는 사이트를 의미하는 "Posting", "Host" 등입니다. 결국 알고리즘 2의 예측은 신뢰할 수 없는 것이죠. 나아가 다른 예측들에 대해서도 신뢰할 수 없다는 결과가 나오면, 알고리즘 2 자체가 신뢰할 수 없는 모델이라고 해석할 수 있습니다.
이 뒤의 내용은 앞서 언급했던 예측 / 모델에 대한 신뢰에 관한 부분이니, 다음으로 넘어가도록 하겠습니다. 시간 나시면 직접 읽어보시는 것도 좋아보입니다.
Desired characteristics for Explainers
그래서 모델과 예측을 설명하는게 중요하다는 건 알겠습니다. 그렇다면 좋은 설명은 뭘까요? 논문에서는 크게 4가지의 주요 특성들을 제시합니다.
Interpretability - 해석 가능성
- 독립 변수와 종속 변수간의 관계에 대해 질적인(qualitatve) 이해를 제공해야 함
설명 모델이면 당연히 설명을 할 수 있어야 합니다. 앞서 언급했듯 입력값과 출력값의 관계에 대해서 질적인 이해, 설명을 제공해야 하는데 여기서 중요한 것은 이 "해석 가능성"은 사용자를 고려해야 한다는 점입니다.
예를 들어, 선형회귀 모델은 기본적으로 회귀계수를 통해 해석이 가능하다고 생각되지만 항상 그렇지는 않습니다. 변수가 수백, 수천개가 있는 경우 사용자의 입장에서 수백 수천개의 회귀계수를 모두 고려해서 어떤 예측이 왜 그런 결과로 나왔는지 "이해"하기는 쉽지 않습니다. 그리고 이해할 수 없다, 혹은 어렵다는 것은 좋은 설명이 아니라는 것과 같은 말입니다.
해석 가능성이 뛰어난 모델은 사용자가 이해하기 쉬운 설명을 하는 모델입니다. 그런데 모델이 사용하는 변수부터 이해하기 쉽지 않은 경우가 존재합니다. 이런 경우 설명 모델의 입력값을 설명하고자 하는 원본 모델의 입력값과는 다르게 설정해야 합니다. 이 내용은 LIME 모델을 정의하는 부분에서 다시 다뤄보도록 하겠습니다.
Local fidelity - 국소적 충실함
- 모델 전역은 아니더라도 국소적으로(locally) 보았을 때 원 모델과 비슷해야 함
Fidelity는 충실함, 정도로 번역되는 단어입니다. 여기서 충실하다는 이야기는 '잘 모사한다' 정도로 이해하시면 될 것 같습니다. 당연하게도 "상대적으로 쉬운 모델"이 복잡한 원본 모델을 그대로 따라하는 것은 쉽지 않습니다. 그럴 수 있다면 애초에 복잡한 모델을 사용할 필요가 없겠죠. 다만, 설명 모델로 유의미하기 위해서는 모델의 전체는 아니더라도 일정 부분을 떼어놓고 보았을 때 원 모델에 충실해야 합니다.
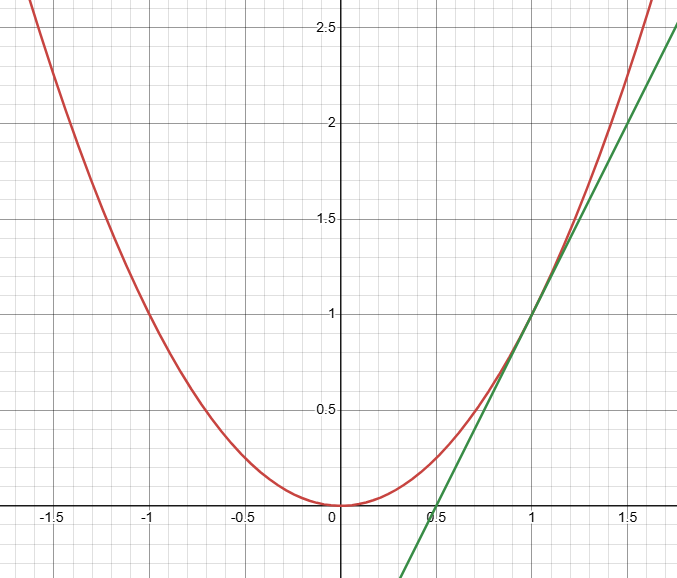
간단히 말하면 이차함수의 전체를 일차함수로 따라할 순 없지만, 이차함수의 아주 일부는 일차함수로 근사할 수 있듯이 쉬운 설명 모델로 복잡한 원본 모델을 일부만이라도 유사하게 나타내야 원 모델에 대해 의미있는 설명이 가능하다는 이야기입니다. 좀 더 멋있게 표현하자면 local fidelity != global fidelity라고도 말할 수 있습니다. 바꿔 생각해보면, 국소적으로도 비슷하지 않은 설명 모델을 사용해서는 유의미한 설명을 할 수 없겠죠?
Model-agnostic - 모델 불가지론
- 어떤 모델이든 설명할 수 있어야 함
Agnosticism은 불가지론, 그러니까 신이 있는지 없는지 알 수 없다! 할 때 나오는 그 불가지론입니다. 따라서 model-agnostic은 원 모델이 무엇이든지 관계 없이 설명 가능해야 한다는 의미입니다. 의사결정나무 기반의 모델만 설명 가능한 것이 아니고, 신경망 기반의 모델만 설명 가능한 것이 아니라, 어떤 모델이든 설명할 수 있어야 '좋은' 설명입니다. 원 모델을 Black-box로, 즉 내부에서 무슨 일이 일어나는지 모르는 모델로 취급하고 예측의 입력과 결과만을 가지고 설명할 수 있어야 합니다. 많은 모델들이 애초에 구조적으로 해석하기가 어렵고, (논문이 쓰여지던 당시 기준으로) 최신의 모델들 역시 대부분 자체적으로 해석이 불가능하다는 점을 지적합니다. 하지만 Model agnostic한 설명 모델은 이런 모델들을 설명할 수 있을 뿐 아니라 미래에 개발될 새로운 구조의 모델들도, 설명 모델에 원 모델의 구조에 대한 가정이 들어가지 않기에, 해석할 수 있습니다.
Global perspective - 전역적인 관점
- 모델 전반에 대한 설명도 가능해야 함
앞서 간단히 개별 예측에 대해 설명이 가능해야 한다는 이야기를 했습니다. 또한 Local fidelity도 비슷하게, 국소적으로는 설명 모델이 원 모델과 비슷해야 한다는 이야기였고요. 그런데 전체적인 관점도 제공해야 한다니, 이게 무슨 소리일까요? 아까 원본 모델의 전체를 따라하는 설명 모델은 현실적으로 어렵다는 이야기를 하지 않았나요?
맞습니다. 원본 모델 전체를 모사하는 설명 모델은 구축하기 쉽지 않습니다. 하지만 설명 모델이 국소적으로 원본 모델에 충실하다면, 대표성을 가지는 개별 예측에 대한 설명을 합쳐서 모델 전반에 대한 설명을 해낼 수 있습니다. 1번 예시에 대해서 왜 이렇게 예측했는지, 2번 예시에 대해서는 왜, 3번 예시에 대해서는 왜 ... 식으로 가다보면 모델 전반에 대한 이해가 가능해진다는 이야기입니다. 그렇다면 충분히 대표성을 가지는 예시를 선정하는 것이 관건이겠죠? 앞서 말한 호날두와 메시 문제에서, 호날두의 예시만 선정해서 분석한다면 모델 전체(호날두와 메시를 구분하는 모델)에 대한 충분한 설명이 되지 않을 테니까요.
3. Local Interpretable Model-agnostic Explanations
그래서! 논문에서 드디어 앞서 언급한 성질들을 가지는 설명 모델을 제시합니다. 첫 글자를 따서 LIME이라고도 하는 이 모델의 목표는 다음과 같습니다.
- 분류기의 interpretable representation에 대해, interpretable하며 locally faithful한 모델을 제시
3.1 Interpretable Data Representations
앞서 Interpretability에 대해 이야기하며 모델의 입력값과 설명 모델의 입력값은 다를 수 있다는 이야기를 했습니다. 모델이 실제로 분류에 사용하는 변수랑, 사람이 이해할 수 있는 변수가 다른 경우가 종종 발생하기 때문이죠. 이미지나 텍스트 분류가 대표적인 경우입니다.
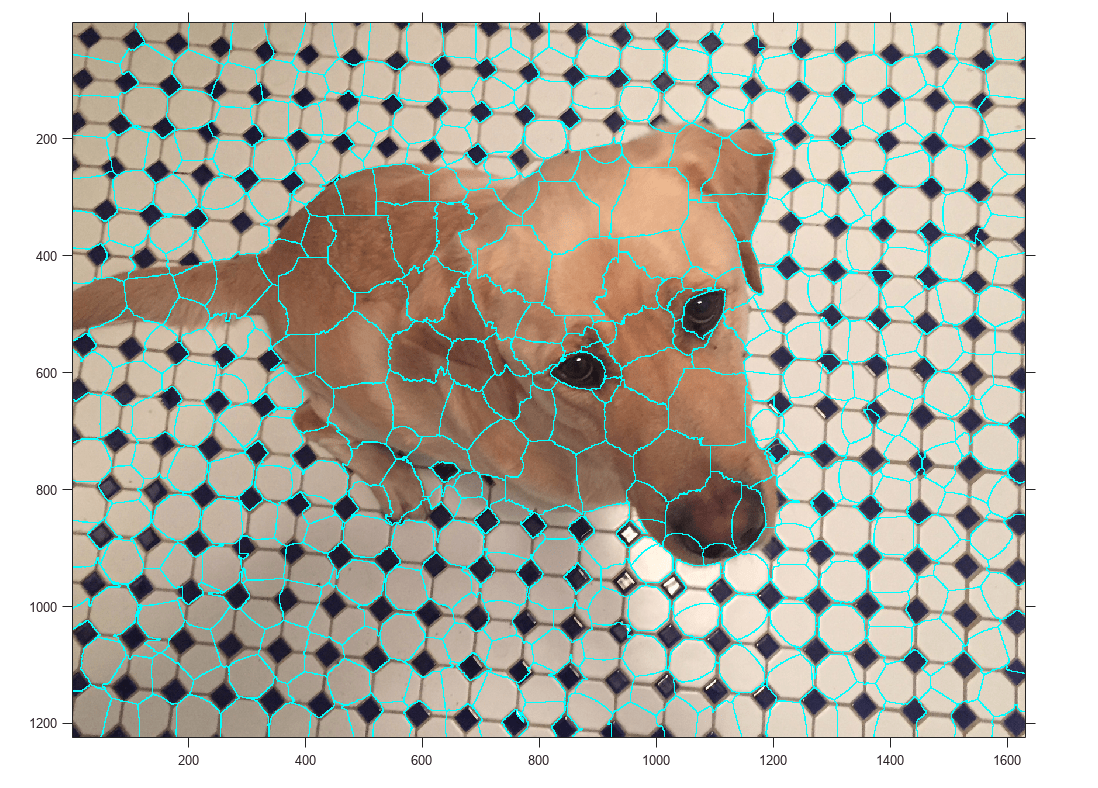
모델 vs 사람
- 이미지 분류 : 색 채널에 따른 3차원 텐서 vs 비슷한 픽셀들의 모임 (superpixel)
- 텍스트 분류 : 단어 임베딩 벡터 vs 특정 단어의 존재 여부
위의 내용이 무슨 소린지 잘 모르셔도 됩니다. Superpixel은 위 그림의 각 칸처럼, 비슷한 픽셀들이 모여있는 부분입니다. 저 조각난 칸들을 기준으로, "특정 칸(ex. 개의 코) 때문에 개라고 분류했다"고 설명하면 이해하기 수월할 것입니다. 반대로 각 픽셀 별 색 채널에 따른 3차원 텐서가 어쩌고 저째서 개로 분류했다고 하면 이해하기 쉽지 않습니다. 그 이야기입니다.
텍스트도 비슷합니다. 문장에 존재하는 단어의 임베딩 벡터 사이의 관계가 어쩌고 저쩌고... 보다는 "기분이 좋다"라는 단어 때문에 '긍정'으로 분류했다는 설명이 훨씬 'interpretable' 하니까요.
어쨌든, 논문에서는 원 모델과 설명 모델의 변수를 수식으로 다음과 같이 정의합니다. 설명 모델의 변수는 binary하게 존재 여부만을 나타낸다는 점에 유의해주세요. 특정 단어가 있어서, 특정 픽셀이 있어서 이러이러하게 판단하였다!기 때문에 이진 변수입니다. 설명 모델과 원 모델의 차원이 다르다는 점에 주의해주세요!
- Original representation of instance :
- Interpretable representation of instance :
3.2 Fidelity-Interpretability Trade-off
직관적으로 생각해보면, 복잡한 원 모델을 잘 모사할수록 (high fidelity) 해석이 어려운 모델 (low interpretability)일 것이라는 결론을 내릴 수 있습니다. 그렇다면 fidelity와 interpretability를 적절히 조절한 최적의 모델을 찾아야 할텐데, 이 단락은 그 내용을 수식화한 부분이라고 생각하시면 됩니다.
해석 가능한, 즉 "Interpretable" 한 설명 모델의 집합을 라고 정의해 봅시다. 모델 는 사용자에게 'visual' 혹은 'textual'한 'artifact'(인공물, 결점 정도의 의미)를 제시해주는 모델입니다. '설명' 모델이니까요. 는 의사결정나무나, 선형 모델이나, 혹은 또 다른 무언가일 것입니다.
그렇다면 바로 위에서 정의한 이 설명 모델의 변수라고 했던 것 기억나시죠? 다시 말해 이게 곧 의 정의역입니다. 풀어서 말하면 함수(혹은 모델) 는 interpretable representation의 존재 여부를 변수로 받아 판단을 한다고 볼 수 있습니다. 추가로 의 복잡도를 로 정의합니다. 가 의사결정나무라면 는 나무의 깊이가 될 수 있겠고, 가 선형 모델이라면 는 0이 아닌 회귀계수의 수가 될 수 있겠죠?
설명하고자 하는 원 모델을 이라 정의합시다. 그렇다면 우리가 알다시피 분류 모델에서 는 변수 가 특정 class에 속할 확률입니다. 추가적으로, 를 와 별개의 instance 사이의 가까운 정도로 정의합시다.
여기까지 읽으셨으면, 갑자기 이런걸 왜 (그것도 이렇게나 많이) 정의하지? 싶으실 수도 있습니다. 이 글을 읽으시는 분들이라면 기본적인 머신러닝 모델을 돌려본 경험이 있으실텐데, 보통 손실함수를 최소화해서 모델을 학습하셨을 것입니다. 지금 여러 변수들을 정의한 것이 바로 fidelity와 interpretability를 나타내는 손실함수를 정의하고, 손실함수를 최소화하는 설명 모델을 고르기 위함입니다.
손실함수 은, 가 를 얼마나 못 설명하고 있는지 나타내는 지표입니다. 손실함수니까, 낮을수록 좋습니다.
따라서 LIME의 설명모델은 다음 식을 통해서 얻어집니다. Loss를 낮추는 것은 local fidelity를 확보하는 것이고, 를 낮추는 것은 interpretability를 확보하는 것입니다.
여기서 를 적절히 수정하여 조건에 맞는 설명 모델을 선택할 수 있음을 볼 수 있습니다. 참고로, 이 연구에서는 sparse linear model을 설명 모델로 사용합니다.
간단하게 요약하면 아래와 같습니다. 참고로, 이 기호와 표현들은 논문에서 계속 언급되니 주의 깊게 봐두시면 좋습니다.
그런데 는 대체 뭘까요?
- Explanation model where is a class of potentially interpretable models
- Domain of is , acts over presence of interpretable components
- Complexity of is
- Original model is
- Proximity measure of to is
- Loss function (measure of unfaithfulness) is
- LIME is obtained by
3.3 Sampling for Local Exploration
앞서 정의한 Loss function 를 최소화하는 과정에서, 원 모델 에 대한 가정 없이 최적화를 하고자 합니다. 그래야 model-agnostic할 테니까요. 그 말은 결국 모델의 입력과 출력만 가지고 설명을 해야한다는 이야기입니다. 그 사이에 모델이 무슨 생각을 하는지는 알 수 없으니까요. 그런데 입력 하나, 를 가지고 설명을 만들수는, 즉 손실 함수를 최적화할 방법은 없지 않나요?
따라서 를 근사하기 위해 설명 모델의 해석하고자 하는 입력 근처에 있는 '비스무리한' 입력값 을, 에서 0이 아닌 element를 무작위로 골라 만듭니다. 가 원 모델의 입력 에서 왔던 것처럼, 으로 원 모델의 입력과 같은 꼴의 를 만들 수 있을 것이고, 그러면 다시 로 해당 입력에 대한 모델의 예측 결과를 구할 수 있겠죠? 를 위에서 정의했던 것이 '비스무리'한 를 제대로 표현하기 위함이었습니다.
참고로 이 '비스무리한' 입력은 perturbed sample이라고도 합니다. 어쨌든 위의 과정을 통해 설명 모델을 학습할 때 필요한 입력과 출력을 구할 수 있습니다. 이제 와 를 통해 "Locally" 근사하는, 해석 가능한 설명 모델을 만들면 됩니다. 바로 위의 Loss function을 최소화해서 말이죠.
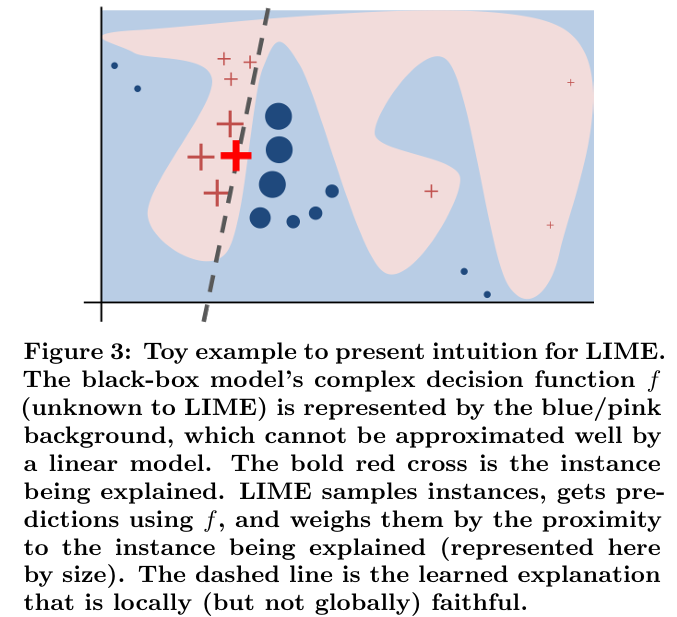
논문의 그림을 보시면 이해에 도움이 되실 겁니다. 원 모델의 경계면, 그러니까 분류 기준은 굉장히 복잡합니다. 하지만 국소적으로는, 개별 입력 의 주위에 추가로 입력 를 만들어서 손실함수를 최소화 하는 것으로 "Locally" 설명할 수 있다는 것이 LIME의 주 논지입니다.
자, 정리해볼까요? 3.2에서는 어떻게 설명 모델을 정의할 것인가?에 대해 다뤘습니다. 여러 수식과 기호를 정의하고, 적절한 손실함수를 정의하였습니다. 3.3에서는 조금 더 구체적으로 어떻게 설명 모델을 학습할 것인가?에 대해 다뤘습니다. 에 대해 '비스무리'한 perturbed sample 를 통해서 학습할 수 있음을 확인했습니다. 다음 3.4에서는 그래서 구체적으로 어떻게 설명 모델을 구현할 것인지 다룰 예정입니다.
3.4 Sparse Linear Explanations
논문에서는 , 즉 설명 모델을 인 선형 모델로 정의합니다. 또 손실 함수 정의에 필요한 로, 거리를 의미하는 와 width 에 대한 exponential kernel로 정의합니다. 무슨 말인지 모르시겠다면 그냥 는 가까움의 정도 비슷한거구나, 생각하셔도 무방합니다. 손실 함수는 여기서 measure of unfaithfulness, 즉 얼마나 못 설명하고 있는지의 정도라 했던 걸 기억합시다. 다음과 같이 정의하면 조건에 들어맞겠죠?
그런데 잘 기억해보면 "LIME is obtained by "라고 했었습니다. 복잡도 가 지금 없는 상태이기에, 복잡도도 정의해야 합니다.
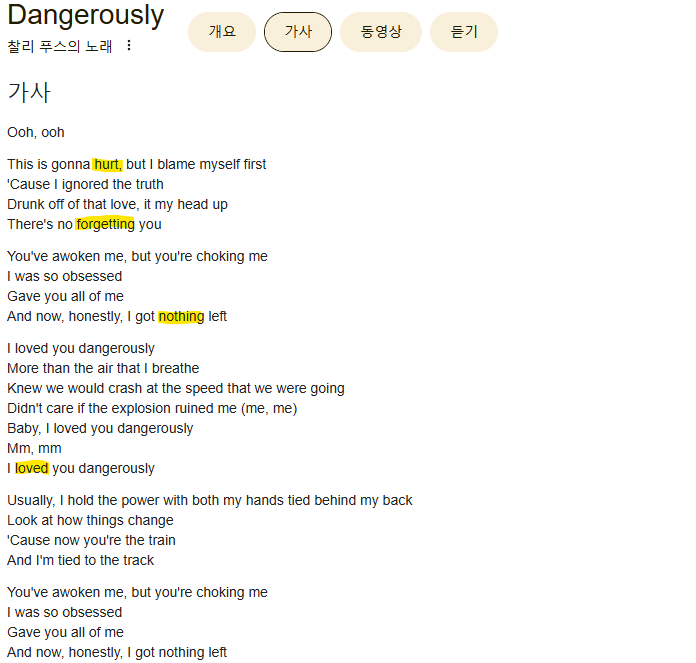
잠깐 다른 소리를 하자면, 지금 중요한 건 설명 모델이 제공해주는 설명이 "interpretable"해야 한다는 점입니다. 그래서 논문에서는 텍스트 분류를 예시로 들어 최대 K개의 단어까지를 "interpretable representation"으로 정의합니다. 예를 들어, 노래 가사를 "이별"으로 분류한 이유를 알고 싶은데 가사 전체가 그 이유다! 라고 정의하면 그건 별로 도움이 안되잖아요? 당연히 모든 단어가 어느정도 "이별"이라 판단하는데 기여를 했겠지만, K개의 가장 중요한 단어들만 설명으로 제공한다는 것이 주 골자입니다. 위의 그림에서 노란색으로 표시된, 이 경우엔 최대 4개까지 단어를 제공하는 것이죠.
이 복잡도를 수학적으로 어떻게 표현할 수 있을까요? 논문에서는 다음과 같이 정의합니다. 참고로 는 아까 가정한 선형 모델 의 계수로, 설명 모델이 도출한 설명(종속 변수와의 관계)을 의미합니다.
뭔가 되게 이상해보이지만 정말 간단합니다. 차근차근 이해해 봅시다. 는 L0 norm을 의미하는데, L0 norm은 0이 아닌 element의 수를 의미합니다. 그러니까 저 부등식의 의미는 "설명에서 의미가 있다고 선택한 단어의 개수가 K개 이상이면" 입니다. 앞의 1은 Indicator function으로, 참이면 1, 거짓이면 0을 반환하는 함수입니다. 마지막으로 반환값에 무한대를 곱하게 됩니다. 따라서, 저 이상해보이는 식의 의미는 K개 이상의 단어를 쓰면 엄청나게 큰 페널티(무한대)를 주고, 아닌 경우엔 별도의 페널티를 주지 않는다는 이야기입니다. 결국 위에서 얘기한 것처럼, 최대 K개의 단어만 설명으로 제공한다!는 것을 수학적으로 표현한 모습입니다.
그런데 저 식을 어떻게 풀 수 있을까요? 풀지 않습니다.
This particular choice of makes directly solving Eq.(1) intractable ...
논문에서도 직접 풀 수 없다고 이야기합니다. 대신에, Lasso regression이라는 방법을 통해 K개의 변수를 선택하는 방식으로 구현합니다. Lasso regression에 대해 궁금하신 분들은 직접 찾아보시면 많은 자료가 있으니 참고하시면 좋을 것 같네요. 참고로 이 방법을 논문에서는 K-Lasso라고 합니다.
과정을 정리하면 다음과 같습니다.

1. 원 입력 를 설명 모델에 맞는 형태로 변환한 근처의 를 선택
2. 원 모델의 입력 공간에 있는 를 구하고, 를 label로 설정, 인접도 계산
3. K-Lasso 과정을 통해 계산
마지막으로, 실제 적용 시에는 당연하게도 와 representation 설정이 중요합니다.
Interpretable Representation

적절한 interpretable representation을 설정해야 합니다. 위 사진처럼 '세피아' 톤의 사진을 보고 이 사진은 'retro'하다고 예측하는 모델에서는 특정 superpixel의 유무가 유의미한 설명을 제공할 수 없겠죠?
Explainer
결국 선형 설명 모델을 쓰면, 원 모델이 엄청나게 (국소적으로도) 비선형적인 경우 제대로 설명하기 어려울 것입니다( = not faithful ). 다만 논문에서는 그럼에도 선형 모델이 많은 경우 괜찮은 성능을 보였고, 필요한 경우 원 모델에 대한 충실도를 측정하여 사용자에게 제공하여 해석을 맡길 수 있다는 점을 언급하며 넘어갑니다.
4. Submodular pick for explaining models
앞서 정의한 내용은 개별 예측을 설명하는 방법 및 모델, 그러니까 처음에 언급한 "예측에 대한 신뢰"에 대한 것이었습니다. 이제 이야기할 부분은 모델 전반에 대한 검증과 설명입니다. 앞서 말했던 "모델에 대한 신뢰", 혹은 설명을 어떻게 할 것이냐의 문제이죠. 단순하게 생각하면 모든 예측에 대한 설명을 다 확인하면 되겠지만, 당연히 현실은 녹록치 않을 것입니다. 그렇다면 중요한 몇 개의 예측, 그러니까 최소한으로 겹치면서 전체 범위를 다룰 수 있는 예측들을 선택한다면 효율적으로 모델에 대한 이해를 할 수 있을 것이라는 것이 이 부분의 주요 논지입니다.
앞서 했던 것처럼 몇가지 기호를 정의하면서, 예측을 선택하는 과정을 구상해봅시다. 모델을 확인하는 사람이 가지는 시간 / 인내심 내에 확인할 수 있는 데이터를 예산(budget) 라고 합시다. 전체 instance의 집합은 입니다(). 앞서 interpretable representation의 차원을 이라 했던 것 기억하시나요? 하나의 예측에 대한 개별 설명도 당연히 의 차원을 가집니다.
그렇다면 모든 예측에 대한 설명은 행렬 로 나타낼 수 있습니다. 선형 모델을 설명 모델로 쓰는 (논문에서 제시한 방법대로의) 경우에는 instance 와 explanation 에 대해 로 설명을 정의합니다. 중요도를 측정하니까 부호에 관계없이 크기만 고려하기 위해 개별 설명에서 해당 변수가 가지는 계수(선형 모델이니, 곧 중요도)의 절댓값을 사용합니다.
마지막으로 Explanation matrix의 각 열 마다(즉, 각 interpretable representation 마다) 를 전역 중요도, 그러니까 모델 전체에서 해당 변수가 가지는 중요도로 정의합시다.
일단 기호를 정리해볼까요?
- Budget :
- Explanation matrix :
- For a linear model, instance and explanation ,
- For every column (feature) in the explanation matrix, is the importance
많은 instance를 설명하는 변수가 높은 중요도를 가지는 것으로 나타나야겠죠?
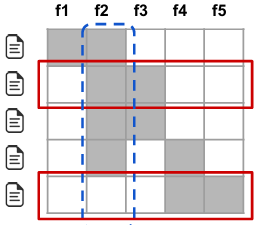
그림으로 예를 들면 가 보다 높아야 한다는 의미입니다. 더 많은 instance에서 가 보다 유의미한 변수로 나타났으니까요.
그렇다면 어떤 instance를 골라야 할까요? 가장 중요한 component (feature, column)를 사용하는 instance를 골라야하지만, 동시에 중복되지 않는(non-redundant) 조합으로 골라야 합니다. 위 그림에서 2번 instance를 고른 뒤 3번 instance를 고르면 추가되는 정보가 없습니다. 이런 non-redundant coverage intuition을 수식으로 구현해볼까요?
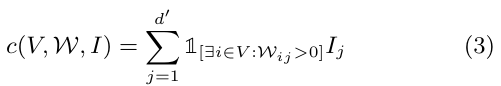
아까 봤던 indicator function이 다시 나옵니다. 이번에는 집합 내의 모든 원소에 대해 , 즉 계수(중요도)가 0 이상인 feature들의 importance를 더한다는 뜻이네요.
이를 다시 반영해서 pick problem을 정의하면 다음과 같습니다.
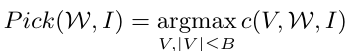
coverage를 최대화하도록 와 를 고른다는 의미입니다. 그런데 이 pick 문제는 NP-hard 문제입니다. (대략 풀기 어렵다, 정도로 이해하시면 됩니다.) 다만 submodularity 덕분에 greedy algorithm으로 해결할 수 있다고 하는데, 구체적인 알고리즘은 다음과 같습니다.

복잡한 내용은 차치하고, 최대한 많은 coverage를 예산 내의 instance로 구현한다는 것이 주 요지입니다.
결론
오늘은 LIME 논문에 대해 리뷰해봤습니다.
개별 예측에 대한 설명과 모델 전체에 대한 설명의 두 부분을 3. 각각 선형 모델을 어떻게 사용하는지, 그리고 효과적으로 4. 모델 전체에 대한 설명을 위해 어떻게 instance들을 선택하는지 정도로 요약할 수 있겠네요.
워낙 유명한 논문이기도 하고, 이후 SHAP 논문에서도 주요하게 다뤄지는지라 한번 정리해봤습니다.
긴 글 읽어주셔서 감사합니다.
