📖 CNN은 이미지를 분석하기 위한 패턴을 찾는데 유용한 알고리즘으로 널리 알려진 이미지 처리 기법입니다.
이번 포스팅에선 CNN(합성공 신경망)에 대해 기초부터 쉽게 정리해 보겠습니다.
Notion
- Convolution Neural Network의 약자로 일반 Deep Neural Network에서 이미지나 영상과 같은 데이터를 처리할 때 발생하는 문제점들을 보완한 방법입니다.
Motivation
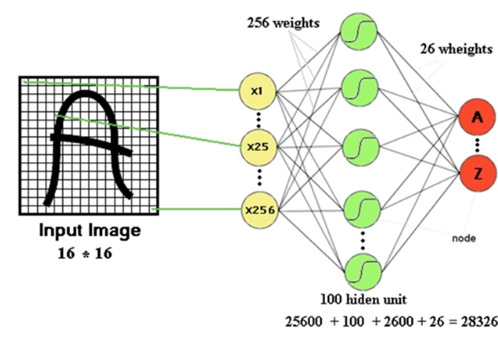
- 기존에 이미지 인식에 사용하던 FCNN(Fully Connected Neural Network)이 가지고 있는 한계를 개선하기 위해 개발되었습니다.
-
FCNN은 input image를 픽셀의 행으로 직렬화 시킨 후, 입력 신호로 주는 방식으로 동작을 합니다.
-
이러한 방식은 직렬화를 수행하는 과정에서 데이터의 형상이 무시된다는 문제점이 존재합니다.
-
즉, 픽셀은 주변 픽셀과 관련이 있는데 Fully conneted layer에 집어넣기 위해 직렬화를 수행하면서 상관관계들을 잃게 됩니다. 때문에 데이터의 전체 관계를 고려하지 못하게 된다는 문제점이 존재하여 이를 보완하기 위해 개발되었습니다.
-
CNN은 이미지의 한 픽셀과 주변 픽셀들과의 연관성을 유지시키며 학습시키는 것을 목표로 합니다.
CNN의 구성요소
1. convolutional layer (합성곱 층)
-
모든 부분과 연결(fully-connected)되는 것이 아닌, 작은 국소적인 일부 영역에 연결(local connected)합니다.
-
근접한 영역의 픽셀(피쳐)들에 집중하여, 특징을 더 잘 관찰하는 효과를 얻을 수 있습니다.
-
메모리 & 컴퓨팅 코스트를 줄이는 효과를 얻을 수 있습니다.
-
파라미터 공유(weight tying)가 가능합니다.
-
만약, 미리 학습과정에서 2번 이상 weight를 사용해 표현을 변환하는데, 그 변환 과정이 서로 거의 같아야 한다는 사전 지식이 있다면 이를 이용하는 것입니다.
-
학습하여야 하는 파라미터를 줄일 수 있습니다.
-
때문에 이미지 객체가 어떤 곳에 있든 그 객체의 특징을 일관되게 관찰할 수 있는 것입니다.
-
1-1. filter (필터)
-
이미지의 특징을 찾아내기 위한 공용 파라미터(shared parameter)입니다.
-
CNN에서는 동의어로 커널(kernel)이라고도 합니다.
1-2. convolution (컨볼루션)
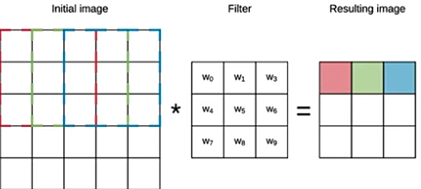
- 전체 인풋에 필터를 순차적으로 감아(convolve) 결과를 내는 과정을 말합니다.
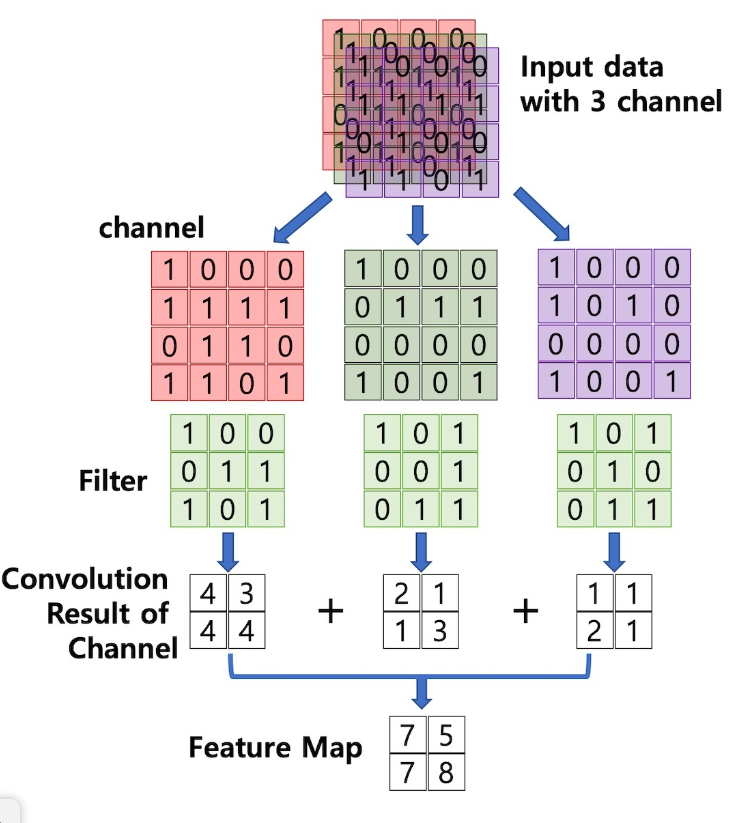
1-3. chnnel (채널)
-
이미지 픽셀 하나하나는 실수입니다.
-
컬러는 각 픽셀을 RGB 3개의 실수로 표현한 3차원 데이터인데, 여기서 각 차원을 chnnel이라 합니다.
-
만약 필터(kernel, shared weight)로 작용하는 것이 n개 라면, n개의 채널을 갖습니다.
1-4. stride (걸음)
- 몇 걸음 단위로 convolution을 진행할지를 의미합니다.
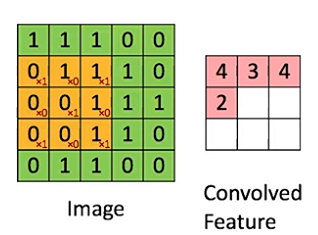
1-5. filter size (필터 사이즈)
-
필터 크기의 사이즈를 말합니다.
-
kernel size라고도 합니다.
-
위 예시는 stride = 1, filter size(노란 부분) = 3X3입니다. 결과적으로, convolved feature는 3X3형태의 결과를 도출합니다.
-
만약 stride = 2라면, convolved feature는 2X2형태의 결과를 도출하게 됩니다.
1-6. dilation rate (확장 간격)
-
필터 사이의 간격을 의미합니다.
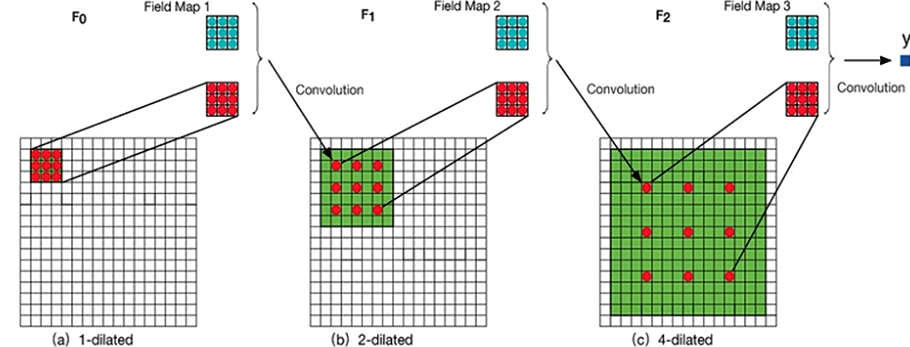
-
3X3으로 filter size가 같을 때, 1, 2, 4 dilation rate일 때는 위와 같습니다.
1-7. padding (패딩)
-
합성곱 계층을 거치면서 이미지의 크기는 점점 작아지게 되고 이미지의 가장자리에 위치한 픽셀들의 정보는 점점 사라지게 됩니다.
이러한 문제점을 해결하기 위해 이용되는 것이 padding입니다. -
입력 이미지 가장자리에 특정값으로 설정된 픽셀을 추가함으로써 입력 이미지와 출력 이미지 크기를 같거나 비슷하게 만드는 역할을 하며,
edge나 모서리 부분의 픽셀 정보도 충분히 활용할 수 있게 하는 역할도 해줍니다. -
만약 padding 값이 모두 0이라면, zero-padding이라고 합니다.
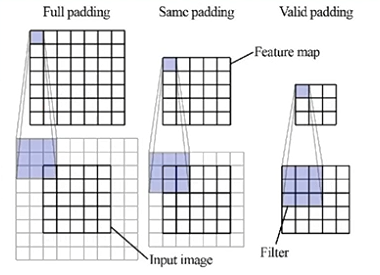
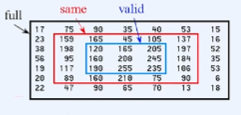
- 위와 같이 목적에 따라 크게 full padding, same padding, vaild padding을 가장 많이 사용합니다.
2. Pooling layer (통합 층)
-
convolution layer를 거쳐 나온 feature map에서 모든 데이터가 필요하지는 않습니다.
- 고해상도 사진을 보고 물체를 판별할 수 있지만 저해상도 사진으로도 어떤 사진인지 판별할 수 있는 것과 같은 원리입니다.
-
pooling layer를 거치면서 적당한 이미지 크기도 줄이고 특정 feature만 강조하게 됩니다.
-
일반적으로 pooling과 stride를 동일한 크기로 설정하여 모든 원소가 한 번씩 처리되도록 합니다.
2-1. pooling
- sub-sampling이라고도 불립니다.
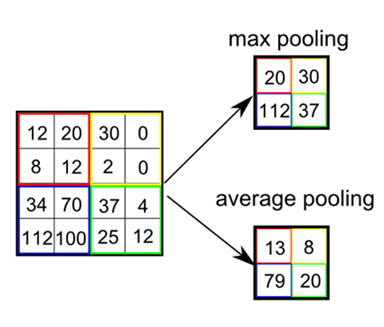
- pooling에는 여러가지 방법이 존재하는데, 어떠한 값을 대표값으로 두는지에 따라 average, max, min pooling이 존재합니다.
- 그 중 max pooling 기법이 많이 사용되는데 통상적으로 강한 신호만 전달되고 나머지는 무시하는 신경세포와 유사한 방식을 취하기 때문입니다.
3. Fully connected layer (완전 연결 계층)
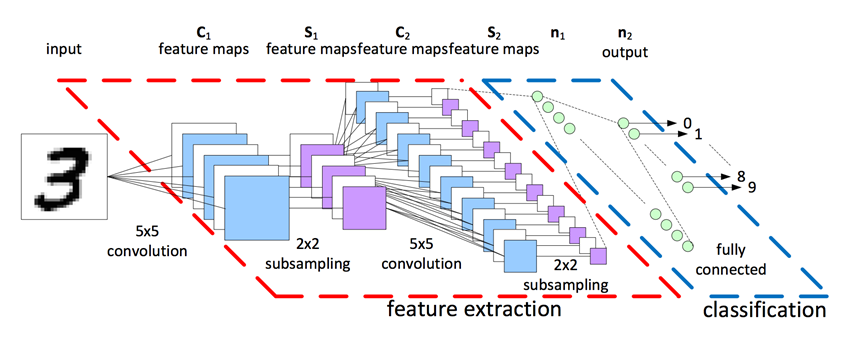
-
1차원 배열의 형태로 평탄화된 행렬을 통해 이미지를 분류하는데 사용되는 계층입니다.
-
구체적인 예를 들어 목적이 multi-class 분류라면, 앞에서 convolution layer와 pooling layer를 통해 얻은 2차원 벡터의 행렬을 1차원 배열로 평탄화한 뒤, ReLU 활성화함수로 뉴런을 활성화하고, softmax함수로 이미지를 분류하는 것까지 Fully connected layer라고 할 수 있습니다.
-
Dense layer라고도 합니다.
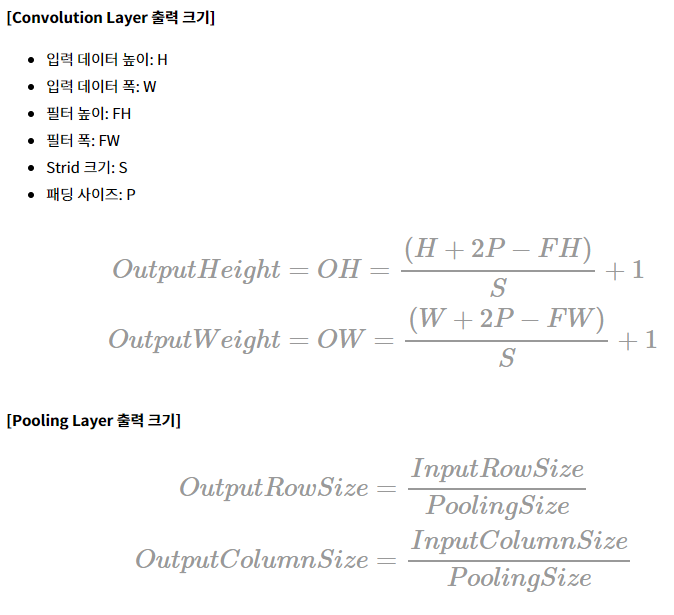
출력 크기 공식
다른 기법들과 합치기
1. Dropout
- activation function 뒤에 적용하는 것이 좋습니다.
2. Batch normalization
- convolution layer 또는 fully-connected layer 뒤에 적용하는 것이 좋다고 합니다.
- 또한, ReLU와 같은 activation function을 적용하기 전에 적용하는 것을 추천하고 있습니다.
- 배치 정규화의 목적은 네트워크 연산 결과가 원하는 방향의 분포대로 나오는 것입니다.
- 때문에, 핵심 연산인 convolution 연산 뒤에 바로 적용하여 정규화 하는 것이 좋습니다.
- 즉, activation function이 적용되어 분포가 달라지기 전에 적용하는 것이 좋습니다.
정리하면, Convolution layer > Batch normalization > activation > dropout 순서가 되겠습니다.
