7일차: 크롤링 실습, 워드 클라우드 시각화
오전: txt 파일 전처리 후 워드클라우드 시각화
오후: 뉴스, 관심사 크롤링 -> 데이터 전처리 -> 워드클라우드
txt 파일 시각화
1. 파일 열기
from wordcloud import WordCloud
text =open('/content/drive/MyDrive/fly_ai/2주차/alice.txt').read()
textProject Gutenberg\'s Alice\'s Adventures in Wonderland, by Lewis Carroll\n\nThis eBook is for the use of anyone anywhere ...~2. 빈도 계산
wordcloud = WordCloud().generate(text)
wordcloud
wordcloud.words_{'said': 1.0,
'Alice': 0.7225433526011561,
'said Alice': 0.3352601156069364,
'little': 0.31213872832369943,
...
}
3. 불용어 처리
from wordcloud import STOPWORDS
STOPWORDS
STOPWORDS.add('said') # said 라는 불용어 추가
print(STOPWORDS)
{'her', 'should', 'through', 'same', 'having', 'however', 'http', "i'd", 'our', 'it' ... }한글의 경우
Okt 라이브러리 이용하거나 직접 리스트 추가하여 제거해야함
4. 워드클라우드 생성
import matplotlib.pyplot as plt
plt.figure(figsize=(15, 10))
plt.imshow(wordcloud)
plt.axis('off')
plt.show()
불용어 적용 전이라 'said'단어가 표시됨
처리 후
wordcloud = WordCloud(max_words=100,font_path='/usr/share/fonts/truetype/nanum/NanumGothicBold.ttf',stopwords=STOPWORDS).generate(text)
plt.figure(figsize=(15,10))
plt.imshow(wordcloud)
plt.axis('off')
plt.show()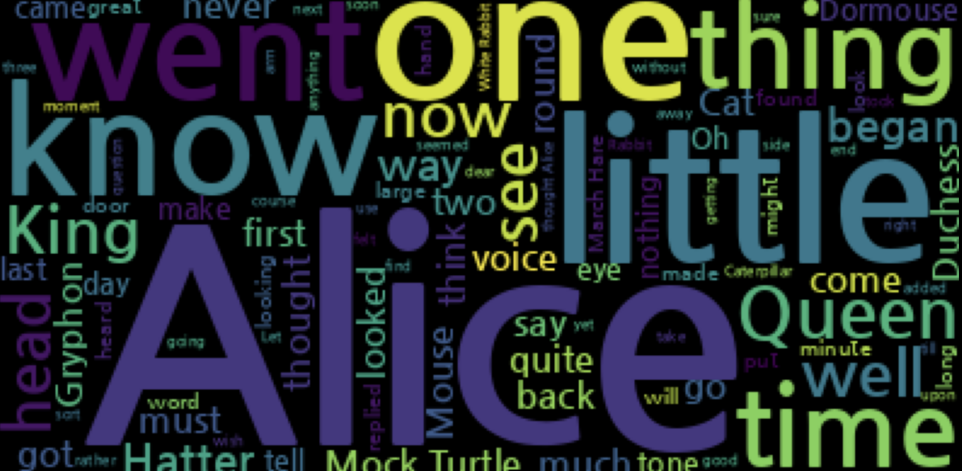
맛집리스트 크롤링 후 워드클라우드 생성
1. 맛집 이름 크롤링
import requests
from bs4 import BeautifulSoup as bs
url_path = 'http://www.soonwidot.co.kr/rank/search.php?si=458&stx=%EB%B3%B4%EB%9D%BC%EB%A7%A4%EC%97%AD%20%EB%A7%9B%EC%A7%91'
res = requests.get(url_path)
soup = bs(res.content, "html.parser")
content = soup.select(".ellipsis > strong:nth-child(2)")
result = []
for data in content:
result.append(data.text)
result['해물포차꼴통 2호점',
'응급실국물떡볶이 서울보라매역점',
'무한장어 신대방점',
'대성관',
...
]
하나의 문장으로 연결
join_result = ' '.join(result)
join_result'해물포차꼴통 2호점 응급실국물떡볶이 서울보라매역점 무한장어 ... '
2. 단어 빈도 계산 후 불용어 처리
wordcloud = WordCloud().generate(join_result)
wordcloud
wordcloud.words_{'보라매역점': 1.0,
'신대방점': 0.6428571428571429,
'보라매점': 0.6428571428571429,
'신풍역점': 0.5,
'대방점': 0.42857142857142855,
...
}
맛집 이름이 중요하므로 빈도 수 높은 지점 정보 불용어 처리
stopwords = ['길뉴타운점', '길', '신대방삼거리역점', '대방점', '신대방점', '영등포점',
'신길점', '보라매점', '신풍역점', '신대방삼거리점', '보라매공원점', '본점',
'2호점', '신', '보라매역점', '서울', '더뉴타운점', '영등포', '대방', '풍점', '풍래미안점',
'점', '삼거리역']
stop_result = join_result
for word in stopwords:
stop_result = stop_result.replace(word, '')
3. 워드클라우드 생성
import matplotlib.pyplot as plt
wordcloud = WordCloud(
font_path = '/usr/share/fonts/truetype/nanum/NanumBarunGothicBold.ttf',
height = 1000,
width=1000,
background_color ='ivory'
).generate(join_result)
plt.axis('off')
plt.imshow(wordcloud)불용어 처리 전과 후 비교
처리 전

처리 후

4. 마스킹
원하는 이미지에 맞게 워드클라우드 입히기
필자는 백종원 이미지에 입힘
import numpy as np
word_mask = np.array(Image.open('/content/백종원.png'))
wordcloud2 = WordCloud(
font_path = '/usr/share/fonts/truetype/nanum/NanumBarunGothicBold.ttf',
height = 1000,
width=1000,
max_words = 50,
background_color ='ivory',
mask = word_mask
).generate(stop_result)
plt.axis('off')
plt.imshow(wordcloud2)

개발자