8일차: 머신러닝 실습
오전: 유방암 데이터 실습
오후: spam 데이터 실습
유방암 데이터 실습
1. 라이브러리 선언, 유방암 데이터 가져오기
import sklearn
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_breast_cancer
cancer=load_breast_cancer()
cancer_df = pd.DataFrame(data=cancer.data, columns=cancer.feature_names)
cancer_df['target'] = cancer.target
cancer_df.head()
2. 데이터 스케일링
- StandardScaler() : 평균 0, 분산 1인 정규분포로 만듦
- MinMaxScaler() : 최대값 1, 최솟값 0, 이상치에 취약
- RobustScaler() : 중앙값 0 / IQR(1분위(25%) ~ 3분위(75%)) = 1, 이상치 영향 적음
- Normalizer() : 열을 대상으로 함, 행의 모든 피처들 사이의 유클리드 거리가 1이 되도록 생성, 학습속또 빠르고 과적합 확률 낮춤
standard 예시
std = StandardScaler()
X_train_scaled = std.transform(X_train)
X_test_scaled = std.transform(X_test)3. train, test 분리
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, test_size=0.2, random_state=3)4. 시각화
X_train_scaled_ss = X_train_scaled.reshape(13650,1)
X_train_data = X_train.reshape(13650,1)
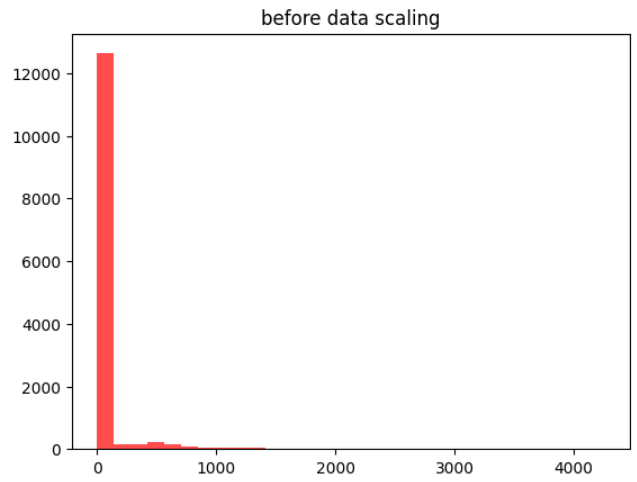
plt.hist(X_train_data, bins=30, color= 'red', alpha = 0.7)
plt.title('before data scaling')
plt.show()
스케일 전
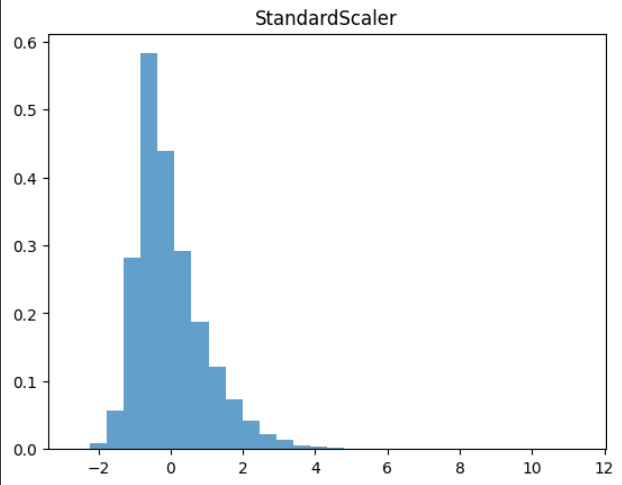
plt.hist(X_train_scaled_ss, bins=30, alpha = 0.7, density = True)
plt.title('StandardScaler')
plt.show()스케일 후

5. 학습
dtc = DecisionTreeClassifier()
dtc.fit(X_train, y_train)
print('모델의 정확도 :', round(dtc.score(X_test, y_test), 4))
모델의 정확도 : 0.9123SPAM 데이터 실습
1. 데이터 전처리
df = pd.read_csv('/content/drive/MyDrive/fly_ai/2주차/2주차학습데이터/spam.csv', encoding='latin1')
df v1 v2 Unnamed: 2 Unnamed: 3 Unnamed: 4
0 ham Go until jurong point, crazy.. Available only ... NaN NaN NaN
1 ham Ok lar... Joking wif u oni... NaN NaN NaN
2 spam Free entry in 2 a wkly comp to win FA Cup fina... NaN NaN NaN
3 ham U dun say so early hor... U c already then say... NaN NaN NaN
4 ham Nah I don't think he goes to usf, he lives aro... NaN NaN NaN불필요 값 제거
df = df.drop(['Unnamed: 2', 'Unnamed: 3', 'Unnamed: 4'], axis=1)결측치 처리
duplicates = df[df.duplicated()]
df = df.drop_duplicates()
df v1 v2
0 ham Go until jurong point, crazy.. Available only ...
1 ham Ok lar... Joking wif u oni...
2 spam Free entry in 2 a wkly comp to win FA Cup fina...2. train test 토큰화, 학습
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
X = df['v2']
y = df['v1']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
vectorizer = CountVectorizer()
X_train_vectorized = vectorizer.fit_transform(X_train)
X_test_vectorized = vectorizer.transform(X_test)
model = MultinomialNB()
model.fit(X_train_vectorized, y_train)
y_pred = model.predict(X_test_vectorized)
accuracy = accuracy_score(y_test, y_pred)
conf_matrix = confusion_matrix(y_test, y_pred)
classification_rep = classification_report(y_test, y_pred)
print(f"Accuracy: {accuracy}")
print(f"Classification Report:\n{classification_rep}")
Accuracy: 0.9854932301740812
Classification Report:
precision recall f1-score support
ham 0.99 1.00 0.99 889
spam 0.99 0.91 0.95 145
accuracy 0.99 1034
macro avg 0.99 0.95 0.97 1034
weighted avg 0.99 0.99 0.99 1034
개발자