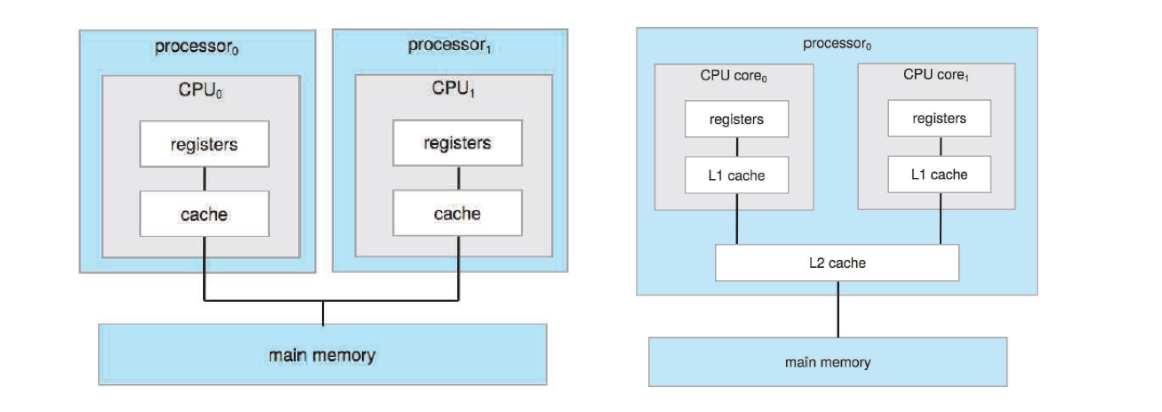
멀티 프로세싱의 필요성
그리닷 프로젝트를 진행하면서 아이가 그린 그림이 입력으로 들어왔을 때 내가 설계한 백엔드 로직은 다음과 같다.
-
non-deeplearning-segmentation 으로 그림의 텍스쳐를 추출하여 Azure storage에 저장하는 endpoint
-
사용자가 관절값을 리깅한 좌표를 yaml파일로 저장하여 Azure storage에 저장하는 endpoint
-
두 파일과 원본 그림을 이용하여 애니매이션을 랜더링하는 endpoint
이렇게 총 3개의 endpoint가 있어야 그림이 움직이는 gif가 생성이 된다.
하지만 이렇게 했을 경우 문제가 생겼다.
그리닷 프로젝트의 경우 기본적인 gif 모션은 [걷기, 인사하기, 춤추기, 점프하기, 울기, 화내기, 놀라기] 총 7개의 모션이 있는데, 하나의 gif를 만들 때 약 1분정도 소요되는 것이다.
그렇다면 사용자가 그림 이미지를 넣고 관절을 맞춘 다음 총 7분의 시간을 기다려야하는 것인데 내가 사용자였으면 기다리다가 지쳤을 것 같다.
멀티 프로세싱 적용
그래서 나는 운영체제 수업에서 배운 기억을 토대로 멀티 스레드 기술을 한 번 적용해보자라는 생각에 구글링을 하다가
멀티 스레드는 실제로 각 스레드가 하나의 프로세스 내에서 실행되기 때문에, 스레드 간에는 메모리 공간이나 자원을 공유한다는 것을 배웠다.
이는 데이터 처리나 간단한 연산에는 유리할 수 있지만, 우리 프로젝트와 같이 각 작업이 많은 CPU 자원을 소모하는 무거운 그래픽 렌더링의 경우에는 한계가 있다.
한 프로세스 안에서 많은 스레드가 활동하면 메모리 공간이 충분하지 않거나, 하나의 스레드에서 문제가 발생하면 전체 프로세스에 영향을 미칠 수 있다.
따라서, 이런 복잡하고 자원 집약적인 작업에는 멀티 프로세싱이 더 적합하다고 판단했다.
멀티 프로세싱은 각 프로세스가 독립적인 메모리 영역을 가지며, 하나의 프로세스에서 발생하는 문제가 다른 프로세스에 영향을 미치지 않는다.
또한, 현대의 많은 컴퓨터는 멀티 코어 프로세서를 탑재하고 있어, 동시에 여러 프로세스를 실행할 수 있어 처리 속도를 대폭 향상시킬 수 있다.
적용하기 전 코드
def create_gif(option):
render.start(f'AnimatedDrawings/examples/config/mvc/gree_{option}.yaml')
return f'./temp/{option}.gif'적용 후 코드
from concurrent.futures import ProcessPoolExecutor
def create_gif(option):
render.start(f'AnimatedDrawings/examples/config/mvc/gree_{option}.yaml')
return f'./temp/{option}.gif'
#멀티 프로세싱 적용
async def run_create_gif(options):
loop = asyncio.get_running_loop()
with ProcessPoolExecutor() as executor:
futures = [loop.run_in_executor(executor, create_gif, option) for option in options]
results = await asyncio.gather(*futures)
return results1. ProcessPoolExecutor
여러 프로세스 풀을 생성하고 관리할 수 있게 해줌
2. loop.run_in_executor
create_gif 함수를 각각의 프로세스에서 비동기적으로 실행
3. asyncio.gather
모든 비동기 작업의 결과를 수집하고 반환한다. 이는 모든 작업이 완료될 때까지 기다리고, 각 작업의 결과를 하나의 리스트로 모으는 역할
시행착오
멀티 프로세싱을 적용함으로써 7분 걸리던 gif 생성 작업이 4분으로 단축이 되었다.
그런데 Azure VM에서 vCPU 4코어짜리를 사용하고있는 상황에서 cpu 사용률이 100% 인걸 확인했을때 cpu 성능이 더 좋다면 더 줄지 않을까라는 생각이 들었다.
그래서 vCPU 8코어로 가상머신을 다시 생성해 실험한 결과 1분 30초까지 단축이 됐다. 하지만 해당 cpu도 사용률이 100% 였다.
cpu가 부족해서 더 안 주는건가 라는 생각에 vCPU 16코어짜리로 생성하며 1분을 기대하며 실행을 하였는데 똑같이 1분 30초의 시간이 소요가 되었고 의문이 들었다. 더 깊은 원인을 파악하기 위해 추가 조사를 해보았다.
배운점
구글링과 여러 테스트를 통해 알아본 결과, 멀티 프로세싱에서는 단순히 CPU 코어의 수를 늘리는 것만으로는 계속해서 성능이 선형적으로 향상되지 않는다는 것을 확인할 수 있었다. 이는 프로세스 간의 커뮤니케이션 오버헤드, 메모리 접근 패턴, 그리고 I/O 대역폭 등 여러 요소에 의해 제한될 수 있다.
이러한 이유로, vCPU 16코어에서의 성능 향상이 기대만큼 나타나지 않은 것이다. 이를 해결하기 위해 더 효율적인 멀티 프로세싱 설계, 메모리 접근 최적화, 그리고 필요한 경우 작업을 더 잘 분할하여 각 코어의 로드를 균일하게 만드는 것이 중요하다는 점을 이해할 수 있었다.
결국, 하드웨어를 업그레이드하는 것만으로는 한계가 있으며, 소프트웨어와 알고리즘의 최적화가 병행되어야 진정한 성능 향상을 이룰 수 있음을 깨닫게 되었다.
