학습내용
pandas indexing
df[] #인덱싱 불가
df.iloc #위치 기반 indexing
df.loc #실제값 기반 indexing, 따라서 df.iloc[-1] 안됨, 인덱스에 -1은 존재하지않기 때문유용한 Pandas 문법
#1. 파이썬, 라이브러리 등 버전확인
pd.show_versions()
#2. 데이터프레임 생성
pd.DataFrame()
#3. column명 조작
df = df.rename({'a:b'}, axis = 'columns')
df.columns = ['a', 'b']
df.columns = df.columns.str.replace(" ", "_")
df.add_prefix("X_")
df.add_suffix("_Y")
#4. reverse row
df.loc[::-1]
df.loc[::-1].reset_index(drop=True)
#5. reverse column
df.loc[: , ::-1]
#6. 특정 dtype 선택
df.select_dtype(exclude=' ' )
#7. 숫자로 형변환
df.astype({'col_one' : 'float', ' ' : ' '})
pd.to_numeric(df, errors='coerce') #error 무시, NaN으로 자동변환
df.apply(pd.to_numeric)
#8. 데이터프레임 줄이기
cols = ['beer_servings', 'continent']
small_drinks = pd.read_csv('http://bit.ly/drinksbycountry', usecols=cols)
small_drinks.info(memory_usage='deep') #용량 확인
dtypes = {'continent':'category'}
smaller_drinks = pd.read_csv('http://bit.ly/drinksbycountry', usecols=cols, dtype=dtypes)
smaller_drinks.info(memory_usage='deep') #용량 확인
#9. multiple files
from glob import glob
stock_files = sorted(glob('data/stocks*.csv'))
stock_files
pd.concat((pd.read_csv(file) for file in stock_files), ignore_index=True)
pd.concat((pd.read_csv(file) for file in drink_files), axis='columns').head() # -> 방향(칼럼 방향)으로 붙이기
#10. 클립보드에서 데이터프레임 생성
df = pd.read_clipboard()
#11. 데이터프레임 샘플링
movies_1 = movies.sample(frac=0.75, random_state=1234)
#12. 특정 값을 가지는 row뽑기
movies[movies.genre.isin(['Action', 'Drama', 'Western'])]
#13. Filter a DataFrame by largest categories
counts = movies.genre.value_counts()
counts.nlargest(3).index
movies[movies.genre.isin(counts.nlargest(3).index)]
#14. Handle missing values
ufo.dropna(thresh=len(ufo)*0.9, axis='columns') #column에 90%이상 NaN가 있을 시 column drop
#15. Split a string into multiple columns
df[['first', 'middle', 'last']] = df.name.str.split(' ', expand=True)
#16. Aggregate by multiple functions
orders.groupby('order_id').item_price.agg(['sum', 'count']).head()
#17. 원래 열에 맞추기
orders.groupby('order_id').item_price.transform('sum')
orders['percent_of_total'] = orders.item_price / orders.total_price
#18. Select a slice of rows and columns
titanic.describe().loc['min':'max', 'Pclass':'Parch']
#19. pivot table
titanic.pivot_table(index='Sex', columns='Pclass', values='Survived', aggfunc='mean', margins = True)
#20. 범위 지정하여 categorical 데이터로 표현
pd.cut(titanic.Age, bins=[0, 18, 25, 99], labels=['child', 'young adult', 'adult']).head(10)
#21. Change display options
pd.set_option('display.float_format', '{:.2f}'.format)
#22. Style a DataFrame
format_dict = {'Date':'{:%m/%d/%y}', 'Close':'${:.2f}', 'Volume':'{:,}'}
stocks.style.format(format_dict) #Volume column에 , 추가
(stocks.style.format(format_dict)
.hide_index()
.highlight_min('Close', color='red')
.highlight_max('Close', color='lightgreen')
)
(stocks.style.format(format_dict)
.hide_index()
.background_gradient(subset='Volume', cmap='Blues')
)
(stocks.style.format(format_dict)
.hide_index()
.bar('Volume', color='lightblue', align='zero')
.set_caption('Stock Prices from October 2016')
)
#23. Bonus: Profile a DataFrame(개인적으로 가장 신기하고 자주 사용해보고자하는 tric)
import pandas_profiling
pandas_profiling.ProfileReport(titanic)merge
#기준 열 이름이 같은 경우에는 on으로 한꺼번에 표시 가능.
#다르다면 left_on, right_on 따로 지정해주어야 함.
#how = inner, outer, left, right
df2 = pd.merge(left, right, on = ['key1','key2'], how = 'left')tidy data
tidy : 한 행에, 한 observation
df_tidy = df.reset_index()
df_tidy = df_tidy.melt(id_vars = '종목명', value_vars = ['매출액', '자산총계', '자본총계', 'EPS(원)'])
df_tidy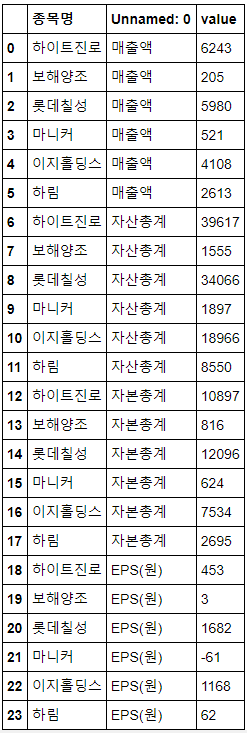
- 추후 공부 계획 : seaborn
wide data
wide = tidy1.pivot_table(index = 'row', columns = 'column', values = 'value')