학습내용
이전까지 학습했던 Word2Vec, fastText같은 경우는 단어 및 문장을 임베딩했다면 이제 임베딩한 text들을 여러가지 모델들을 통해 사용해보자.
언어 모델(Language Model)
언어 모델 : 문장과 같은 단어 시퀀스에서 각 단어의 확률을 계산하는 모델, Word2Vec도 여기에 해당함
1. 통계적 언어모델
Word2Vec이 나오기 전까진 t 번째 단어를 예측하기 위해 t 번째 단어 왼쪽의 단어만을 고려하여 확률을 계산
예를들어
"I am a student"라는 문장이 만들어질 확률은
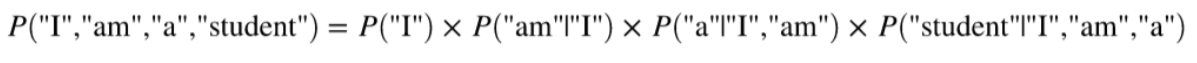
확률의 계산은 단어의 등장 횟수를 바탕으로 조건부 확률을 계산
위와 같은 모델들을 통계적 언어모델이라고 한다.
- 통계적 언어 모델의 한계점
횟수 기반으로 확률을 계산하기 때문에 희소성 문제를 가지고있다.
예를 들어 코퍼스에 1 times, 2 times 라는 표현은 있지만 7 times라는 표현이 없다면
I studied this section 7 times
라는 문장은 만들어낼 수가 없다. 이는 7이 오는순간 times가 올 확률이 0이 되어버리기 때문.
- 희소성 문제 해결 방안
- N-gram
- Back-off, Smoothing
- 신경망 언어 모델(Neural Language Model) : Word2Vec, fastText
Vanila RNN(Recurrent Neural Network)
순환신경망으로 이전 시점에서 출력되었던 벡터가 다시 입력되는 특징을 가진다.
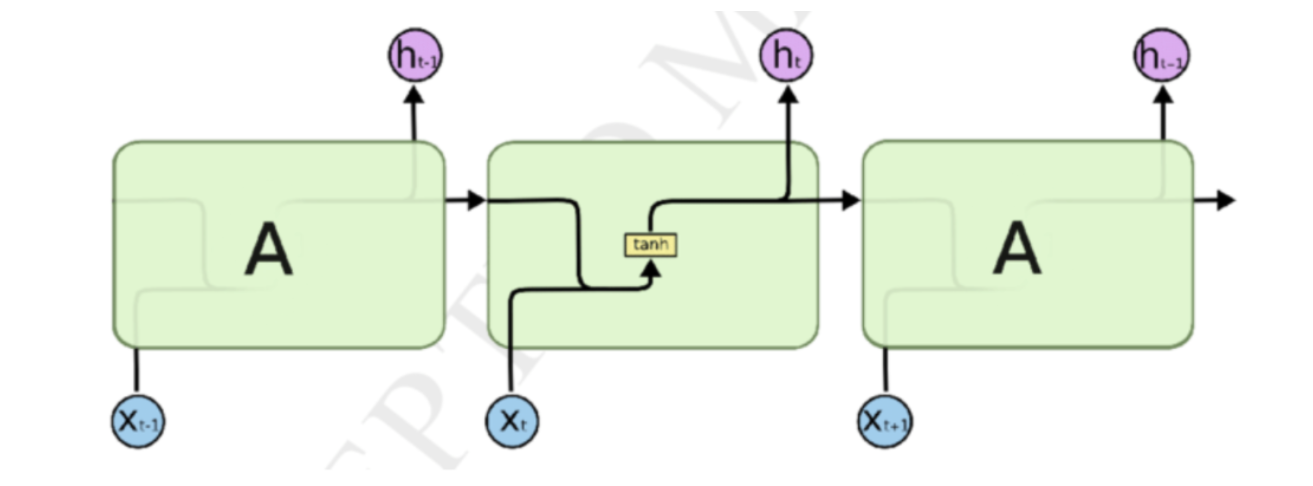
relu를 해버리면 층이 하나기 때문에 비선형으로 변환이 잘 안된다는 문제가 있어서 tanh를 사용
sigmoid는 gradient vaninshing 문제가 더 심각해지는 등의 이유에서 activation function으로 tanh를 사용
- 장점
- RNN은 간단하고 어떤 길이의 sequential 데이터도 처리할 수 있다는 장점이 있다.
- 단점
- 병렬화 불가능 : 입력이 순차적으로 일어나 GPU연산의 이점이 거의 없다. 따라서 학습 시간이 길게 걸린다.
- gradient vanishing : 기울기가 1 미만라고 본다면 역전파 과정에서 recurrent가 길수록 정보가 매우 많이 소실되는 문제가 생김
- gradient exploding : 기울기가 1 초과라고 본다면 역전파 과정에서 recurrne가 길수록 정보가 과하게 전될되는 문제가 생김
gradient 문제를 해결하기 위해 고안된 것이 LSTM & GRU
- 실습
import numpy as np
class RNN:
def __init__(self, Wx, Wh, b):
self.params = [Wx, Wh, b]
self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)]
self.cache = None
def forward(self, x, h_prev):
Wx, Wh, b = self.params
t = np.matmul(h_prev, Wh) + np.matmul(x, Wx) + b
h_next = np.tanh(t)
self.cache = (x, h_prev, h_next)
return h_nextLSTM&GRU
RNN의 Gradient 문제를 해결하고자 만들어진 모델
RNN구조에 이전 내용들을 기억하고, 잊어버리는 Gate를 추가한 형태
1. LSTM
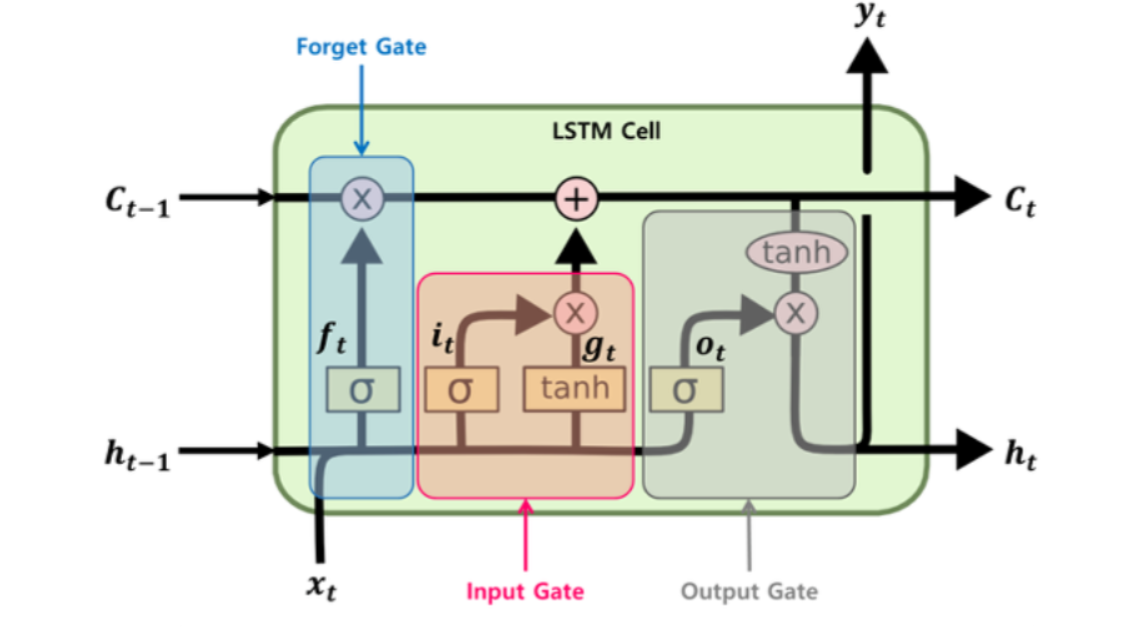
모든 activation function 앞에는 가중치가 존재. Cell state에는 activation function이 없으니 gradient vanishing문제가 일어나지않음.
- Forget gate : 새로운 입력과 sigmoid를 통해서 기존의 정보인 C를 얼마나 유지할 것인지를 결정
- Input gate : forget gate를 통해 기존의 정보를 어느정도 삭제했으니, 새로운 정보를 어느정도 추가함
- output gate : 새로 만들어진 정보 C(기존의 정보C + 새로운 정보)를 얼만큼 넘겨줄지 결정
cell-state는 역전파 과정에서 정보 손실이 없기 때문에 최근(short) 이벤트에 비중을 결정할 수 있으면서 동시에 오래된(long) 정보를 완전히 잃지 않을 수 있다는 LSTM의 장점을 살릴 수 있는 필수적 요소가 됨.
- 실습
RNN/LSTM 감정 분류(Sentiment classification)
from __future__ import print_function
from tensorflow.keras.preprocessing import sequence
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Embedding
from tensorflow.keras.layers import LSTM
from tensorflow.keras.datasets import imdb
# 이 단어 랭크 수 뒤에 텍스트는 사용하지 않도록 잘라냅니다(단어 등장 순위 : max_feature)
# 참조링크 : https://www.tensorflow.org/api_docs/python/tf/keras/datasets/imdb/load_data
max_features = 20000
# 최대 단어 길이
maxlen = 80
batch_size = 32
print('Loading data...')
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_features) #단어개수, 문서개수 아님. 근데 20000개 보다 좀 작아지는데 왜 그렇지??
print(len(x_train), 'train sequences')
print(len(x_test), 'test sequences')import tensorflow as tf
model = tf.keras.models.Sequential([
tf.keras.layers.Embedding(max_features, 128),
tf.keras.layers.LSTM(128, dropout=0.2, recurrent_dropout=0.2),
tf.keras.layers.Dense(1, activation='sigmoid')
])
# Embedding(7, 2, input_length=5)
#weights 파라미터를 입력해주면 내가 기존에 embedding 해놨던걸로 사용가능??
# 정수로 인코딩된 text들을 밀집벡터로 바꿔줌
# 밀집벡터 : 희소 행렬을 차원 감소를 통해(예를 들어 SVD와 같은 특이값 분해) 중요한 축을 찾아내어 더 적은 차원으로 다시 표현하는 것(=밀집 벡터)입니다.
# 7은 단어의 개수. 즉, 단어 집합(vocabulary)의 크기이다.
# 2는 임베딩한 후의 벡터의 크기이다.
# 5는 각 입력 시퀀스의 길이. 즉, input_length이다.
#tf.keras.layers.LSTM()
#dropout: 0과 1사이 부동소수점. 인풋의 선형적 변형을 실행하는데 드롭시킬(고려하지 않을) 유닛의 비율.
#recurrent_dropout: 0과 1사이 부동소수점. 순환 상태의 선형적 변형을 실행하는데 드롭시킬(고려하지 않을) 유닛의 비율.
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.summary()unicorns = model.fit(x_train, y_train,
batch_size=batch_size,
epochs=3,
validation_data=(x_test,y_test))LSTM 텍스트 생성기
# 라이브러리, 데이터 불러오기
from __future__ import print_function
from keras.callbacks import LambdaCallback
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from keras.optimizers import RMSprop
from keras.utils.data_utils import get_file
import numpy as np
import random
import sys
import io
path = get_file(
'nietzsche.txt',
origin='https://s3.amazonaws.com/text-datasets/nietzsche.txt')
with io.open(path, encoding='utf-8') as f:
text = f.read().lower()
print('corpus length:', len(text))
chars = sorted(list(set(text)))
print('total chars:', len(chars))
char_indices = dict((c, i) for i, c in enumerate(chars))
indices_char = dict((i, c) for i, c in enumerate(chars))# max length를 이용하여 문자열의 크기 정렬
maxlen = 40
step = 3
sentences = []
next_chars = []
for i in range(0, len(text) - maxlen, step):
sentences.append(text[i: i + maxlen])
next_chars.append(text[i + maxlen])
print('nb sequences:', len(sentences))
print('Vectorization...')
x = np.zeros((len(sentences), maxlen, len(chars)), dtype=np.bool)
y = np.zeros((len(sentences), len(chars)), dtype=np.bool)
for i, sentence in enumerate(sentences):
for t, char in enumerate(sentence):
x[i, t, char_indices[char]] = 1
#문장당 2차원 데이터가 생성. row는 문장길이 column은 모든 글자. 모든 글자를 feature로 놓고 해당 글자에 1
y[i, char_indices[next_chars[i]]] = 1
#문장당 다음 글자에 1. feature는 모든 글자# LSTM 모델 제작
print('Build model...')
model = Sequential()
model.add(LSTM(128, input_shape=(maxlen, len(chars)))) #input shape : 한글자 당 임베딩된 값이 문장길이만큼 입력됨
model.add(Dense(len(chars), activation='softmax'))
optimizer = RMSprop(lr=0.01)
model.compile(loss='categorical_crossentropy', optimizer=optimizer)model.fit(x, y,
batch_size=128,
epochs=60)2. GRU
LSTM의 간소버전
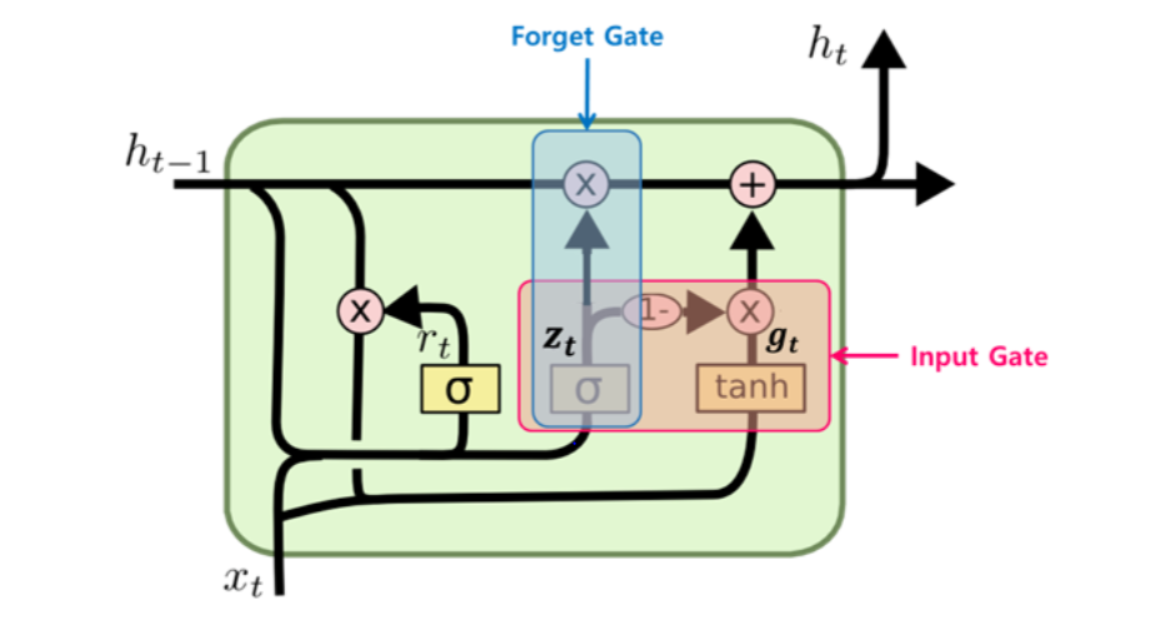
- 이전 정보와 새로운 정보를 통합하고 sigmoid를 통해 Z값을 얻어냄
- Z값에 따라 정보가 사라지고 입력되는 정도가 결정됨. 다시말해 Foreget gate로 전달되는 값과 Input gate로 전달되는 값이 계산됨.
- 이전 정보(h)가 Z에 따라 forget gate에서 정보를 잊어버리고, Input gate에서 새로운 정보를 받아들임.
- 새로운 정보는 r에서 제어된 이전 정보의 특정 부분과 함께 Input gate로 넘어감.
- 이전 정보가 forget gate, input gate를 통해 업데이트 되어 다음 셀로 출력
3. 단점
위 두 모델의 단점은 고정 길이의 hidden-state 벡터에 모든 단어의 의미를 담아야 한다는 점이다.
문장이 매우 길어지면 모든 단어 정보를 고정 길이의 hidden state 벡터에 담기는 어렵다.
이를 해결하고자 하는 모델이 Attention이다.
Attention(dot product)
Attention은 각 인코더의 Time-step 마다 생성되는 hidden-state 벡터를 간직
입력 단어가 N개라면 N개의 hidden-state 벡터를 모두 간직
모든 단어가 입력되면 생성된 hidden-state 벡터를 모두 디코더에 넘겨준다.
- 디코더에서 단어를 생성하는 과정
디코더의 각 time-step 마다의 hidden-state 벡터는 쿼리(query)로 작용
인코더에서 넘어온 N개의 hidden-state 벡터를 키(key)로 여기고 이들과의 연관성을 계산
이 때 계산은 내적(dot-product)을 사용하고 내적의 결과를 Attention 가중치로 사용
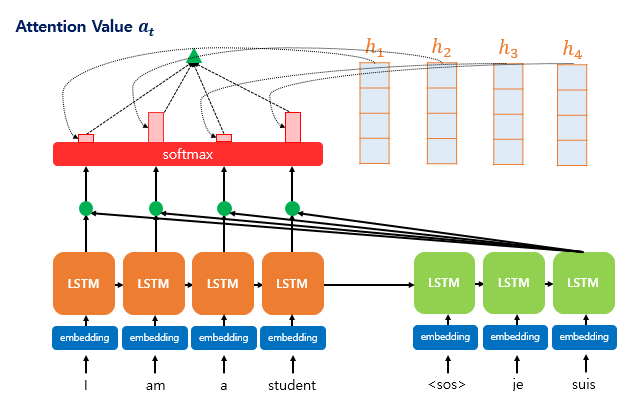
그림 출처 : https://wikidocs.net/22893
-
쿼리(Query)인 디코더의 hidden-state 벡터, 키(Key)인 인코더에서 넘어온 hidden-state 벡터를 준비한다.
-
각각의 벡터를 내적한 값을 구한다.(attention score)
-
이 값에 소프트맥스(softmax) 함수를 취해준다.(attention distribution)
-
소프트맥스를 취하여 나온 값에 밸류(Value)에 해당하는 인코더에서 넘어온 hidden-state 벡터를 곱해준다.
-
이 벡터를 모두 더해줍니다(attention value). 이 벡터의 성분 중에는 쿼리-키 연관성이 높은 밸류 벡터의 성분이 더 많이 들어있게 된다.
-
최종적으로 5에서 생성된 벡터와 디코더의 hidden-state 벡터를 사용하여 출력 단어를 결정하게 된다.
- 수식
attention score : 디코더의 hidden state(query)와 인코더 각각의 hidden state(key)를 내적해준 값이다. 유사도를 찾는 과정이다.
attention distribution : attention score에 softmax함수를 적용시킨 값으로 합이 1인 확률분포를 형성한다.
attention value = attention distribution에 인코더 각각의 hidden state를 곱하고 생성된 벡터들을 모두 더한 값이다.
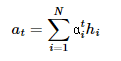
attention value와 디코더 t 시점(St)의 은닉 상태를 concat하고 가중치 및 tanh를 적용하여 새로운 St를 생성한다.
새로운 St를 입력으로 하여 다음 text 예측 벡터를 얻는다.
