학습내용
Transformer
attention 메커니즘을 극대화하여 기존의 RNN구조를 사용하지않고 attention만으로 인코더 디코더를 형성하여 기계번역을 시행한다.
-
장점 : RNN 기반 모델이 가진 구조적 단점은 단어가 순서대로 들어온다는 점이다. 트랜스포머는 이런 문제를 해결하여 많은 양의 데이터를 병렬적으로 처리가능하다.
-
논문에서의 파라미터
-
d_model(인코더, 디코더의 입력과 출력) : 512
임베딩 벡터의 차원 또한 512 /각 인코더와 디코더가 다음 층의 인코더와 디코더로 값을 보낼 때에도 유지
-
num_layer : 6
인코더와 디코더가 총 6층
-
num_heads : 8
어텐션을 사용할때 앙상블마냥 병렬로 어텐션을 수행하고 결과값을 다시 하나로 합침. 병렬의 개수
-
dff : 2048
트랜스포머 내부에는 피드 포워드 신경망이 존재한다. 이때 은닉층의 크기를 의미
-
- 인코더 구조
RNN이 자연어 처리에서 유용했던 이유는 단어의 위치에 따라 단어를 순차적으로 입력받아서 처리하는 RNN의 특성으로 인해 각 단어의 위치 정보를 가질 수 있다는 점에 있었다.
-
positional encoding : 트랜스포머는 단어의 위치 정보를 얻기 위해서 각 단어의 임베딩 벡터에 위치 정보를 더하여 입력으로 사용
-
트랜스포머는 위치 정보를 가진 값을 만들기 위해서 아래의 두 개의 함수를 사용
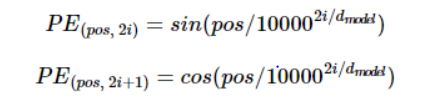
pos는 입력 문장에서의 임베딩 벡터의 위치를 나타내며, i는 임베딩 벡터 내의 인덱스를 의미
같은 단어라도 문장 내의 위치에 따라 트랜스포머의 입력으로 들어가는 임베딩 벡터의 값이 달라짐.
-
-
트랜스포머의 attention :
- 인코더의 셀프 어텐션 : Query = Key = Value
- 디코더의 마스크드 셀프 어텐션 : Query = Key = Value
- 디코더의 인코더-디코더 어텐션 : Query : 디코더 벡터 / Key = Value : 인코더 벡터
self attention의 효과
대명사 it을 예로 들자면, it 이 인코더에 입력되게 된다면 it이 무엇을 가리키는지, 어느 단어와 큰 유사도를 갖는지 알 수 있다.
self attention의 Q, K, V 벡터 얻기
- d_model / num_heads의 차원을 가지는 서로다른 3개의 가중치를 이용하여 Q, K, V를 얻어냄
- 다음으로 attention value를 얻어내는데 이 과정은 본래 attention에서의 과정과 다르지않음. Q, K의 유사도를 통해 가중치를 구하고 이를 V에 적용 후 합하기
- attention value 행렬의 크기는(seq_len, dv) = (문장길이, d_model / num_heads)
- attention value는 총 8개로 설정, 이 attention value들을 multi head attention이라함
- multi head attention 행렬의 크기는(seq_len, d_model)
- 위의 것이 바로 multi head attention의 출력값인데 행렬의 크기가 계속 유지되고 있음을 알 수 있다. 인코더가 여러개라 형태 유지 해야함.
- 출력값은 Position-wise FFNN이라는 일반적인 뉴럴넷에 입력으로 사용된다.
-
Position-wise FFNN
2개의 층으로 형성되어있음
- 1번째 W : (d_model, dff)의 크기를 가짐
- 2번째 W : (dff, d_model)의 크기를 가짐
결과값은 여전히 (seq_len, d_model)의 크기를 가짐1
-
Residual connection과 층 Layer Normalization
multi head attention과 포지션 와이즈 피드 포워드는 결과값을 바로 다음 순서로 넘겨주지않고 Residual connection과 layer normalization 과정을 거침
-
residual connection : 입력과 출력을 더한것을 다음 층으로 넘겨줌
-
layer normalization : 각 단어의 임베딩 벡터의 평균과 분산을 구한다. 이것을 이용하여 정규화
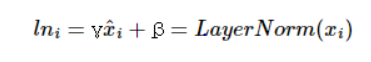
위에 해당하는 변수들은 아래와 같은 수식 및 초기값을 가진다.
-
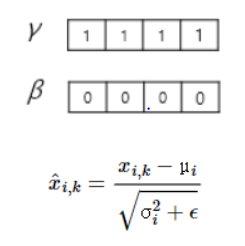
- 디코더 구조
-
masked multi-head self-attention : 다음 문장을 예측할때는 이전 문장의 정보만으로 예측을 해야한다. 이를 구현해주기 위해 masking이라는 개념을 도입했다.
먼저 인코더에서와 같이 디코더의 타겟 문장(번역된 문장)들에 대해서 self attention을 적용한다.
예측되지않은 text(예측하고자하는 text의 우측)에 대해서는 아주 작은 음수값으로 attention값을 바꿔준다. 이를 masking이라 하는데 masking은 유사도를 계산하는데 masking된 값들이 반영되지않도록 해준다.
-
encoder-decoder attention : decoder의 행렬을 query로 / key, value를 인코더에서 넘어온 행렬로 하여 attention 구하기
이를 통해 다음에 위치할 text를 찾아낸다.
GPT, BERT
GPT, BERT는 트랜스포머 구조를 변형하여 만들어진 언어 모델이다.
- 특징
pre-trained language model : 대량의 데이터를 사용하여 미리 학습하는 과정
fine tuning : 실제로 사용할때 태스크에 특화된 데이터를 학습하는 과정, 학습시 레이블링 된 데이터(감성분석, 자연어 추론, 질의 응답) 등을 사용
-
GPT : 트랜스포머의 12개 디코더만을 사용하여 학습
- NLI(자연어 추론), QA(질의 응답), classification(분류) 등 자연어 생성과 관련된 태스크에서 높은 성능을 보임
- Auto- Regressive
-
BERT : 트랜스포머의 12개 인코더만을 사용하여 문맥을 양방향으로 읽어냄.
- BERT에는 [CLS], [SEP] 라는 새로운 token이 등장한다. [CLS]는 문장의 시작, [SEP]는 문장사이
- BERT의 사전 학습방법은 MLM, NSP가 있다.
- MLM : 양방향 빈칸 채우기
- NSP : [SEP] 토큰의 왼쪽 문장과 오른쪽 문장이 바로 이어지는 문장인지 확인
- BERT는 자연어 이해와 관련된 태스크에 좋은 성능을 보임
- Auto- Encoder
