학습내용
CNN
고양이의 시각 피질의 수용영역에서 영감을 받음
convolution layer와 pooling layer의 조합으로 이루어져있다.
-
convolution : 주어진 데이터에 filter를 통해 곱과 덧셈의 연산을 계산하여 데이터의 feature를 추출해내는 방식
-
filter : 가중치의 집합으로 이루어져 가장 작은 특징을 잡아내는 창
-
padding : convolution 이후에 데이터는 filter의 shape에 따라 크기가 줄어드는데 이를 방지하기 위해 데이터 가장자리에 0을 붙여준후 convolution하는 방식을 zero padding이라 한다.
-
stride : convolution은 filter를 순차적으로 이동시켜가며 계산하는데 한번에 이동하는 거리를 stride로 지정해줄 수 있음.
import numpy as np #import scipy.ndimage as nd 를 통해서도 convolve계산 가능 input = [0, 0, 26, 51, 58, 59, 53, 29, 0, 0, 0] patch = [-1, 2, -1] output = np.convolve(input, patch) print(output) -
-
pooling : 마찬가지로 특징을 뽑아내는 과정이라고 할 수 있다. 더 자세히는 convolution에서 뽑아져나온 feature의 특징을 찾아준다고 할 수 있다.
- 효과
- overfitting을 줄임
- input size를 줄여 효율적으로 학습
- pooling을 했을 때, 특정한 모양을 더 잘 인식할 수 있음
from skimage.measure import block_reduce reduced = block_reduce(combined, (2,2), np.max) plt.imshow(reduced, cmap="gray"); - 효과
-
CNN의 장점
- 전처리 (자르기 / 센터링, 정규화 등)가 상대적으로 거의 필요하지 않다.
- 이미지의 모든 종류의 일반적인 문제 (이동, 조명 등)에 대해 견고하다.
-
실습
#이미지는 32X32X3 형태로 입력됨.
model = Sequential()
model.add(Conv2D(32, (3,3), activation='relu', input_shape=(32,32,3)))
#3X3 filter로 32개의 feature를 뽑겠다.
#파라미터 개수 : (3X3X32) X 3(입력채널) + 32(출력채널 편향)
model.add(MaxPooling2D((2,2)))
model.add(Conv2D(64, (3,3), activation='relu'))
model.add(MaxPooling2D((2,2)))
model.add(Conv2D(64, (3,3), activation='relu'))
model.add(Flatten())
model.add(Dense(64, activation='relu'))
model.add(Dense(10, activation='softmax'))
model.summary()
# 모델학습방식을 정의함
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 모델 학습시키기
model.fit(train_images, train_labels, epochs=10, validation_data=(test_images, test_labels))
model.evaluate(test_images, test_labels)Transfer Learning(전이학습)
기존 데이터로 학습된 네트위크를 재사용 가능하도록하는 라이브러리
-
사용방법
- 이전에 학습한 모델에서 파라미터를 포함한 레이어를 가져오기
- 학습과정에서 정보가 손상되지 않도록 해당 정보를 동결시킴
- 동결된 층 위에 새로운 층을 더함(이용자가 원하는 방향으로, 분류 회귀 등)
- 새로운 층만을 학습
-
장점
- 학습 데이터를 적게 사용
- 학습 속도가 빠름
- 일반화가 잘됨
-
ResNet
기존의 sequential 모델과 달리 skipped connection이 있는 모델.
기존모델들은 층이 깊어질수록 gradient vanishing/exploding과 같은 문제가 발생하는데, ResNet은 더 깊은 층을 만들더라도 학습이 가능해짐.
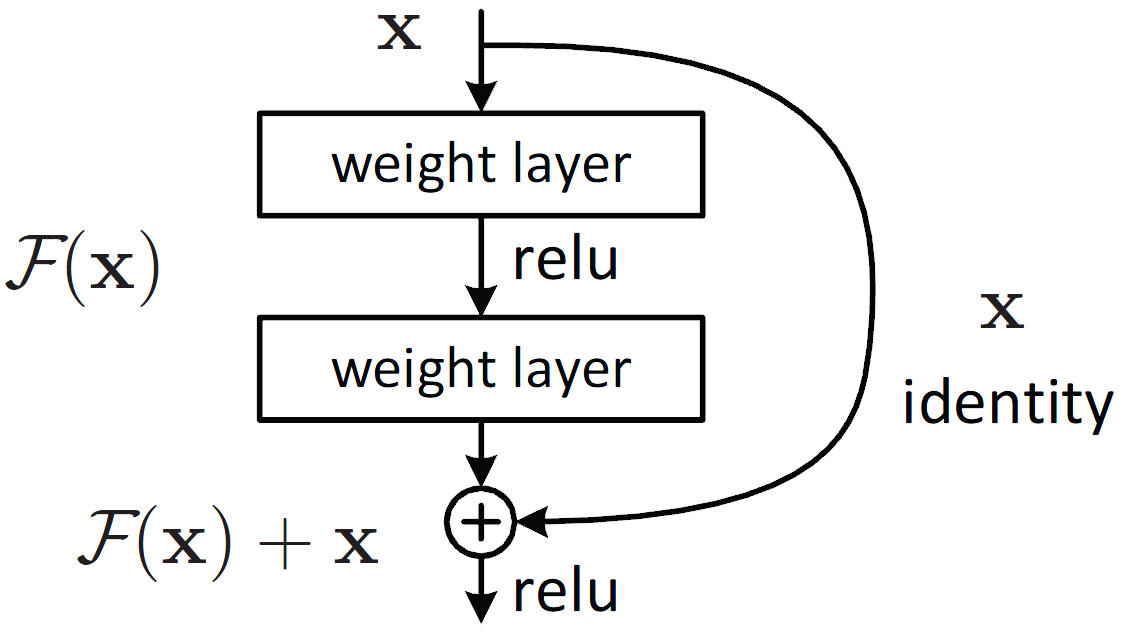
-
실습
from keras.applications.resnet50 import ResNet50
from tensorflow.python.keras.models import Sequential
from tensorflow.python.keras.layers import Dense
from tensorflow.keras import optimizers
# 클래스의 개수 정의 : Cats & Dogs
NUM_CLASSES = 2
# 입력 이미지의 차원 수 : RGB
CHANNELS = 3
# 학습된 네트워크 특징
IMAGE_RESIZE = 224
RESNET50_POOLING_AVERAGE = 'avg'
DENSE_LAYER_ACTIVATION = 'softmax'
OBJECTIVE_FUNCTION = 'categorical_crossentropy'
# 출력 Metric
LOSS_METRICS = ['accuracy']
# EARLY_STOP_PATIENCE < NUM_EPOCHS
NUM_EPOCHS = 10
EARLY_STOP_PATIENCE = 3
train-images / STEPS_PER_EPOCH_TRAINING
STEPS_PER_EPOCH_TRAINING = 10
STEPS_PER_EPOCH_VALIDATION = 10
batching to fill epoch step input
BATCH_SIZE_TRAINING = 100
BATCH_SIZE_VALIDATION = 100
# 테스트 배치의 개수
BATCH_SIZE_TESTING = 1# 모델 제작
model = Sequential()
# weights = resnet_weights_path 학습해둔 모델이 있으면 이렇게 불러올 수 있음
# include_top=False 기존의 FC를 버리겠다는 뜻
model.add(ResNet50(include_top = False, pooling = RESNET50_POOLING_AVERAGE))
model.add(Dense(NUM_CLASSES, activation = DENSE_LAYER_ACTIVATION))
# 이미 학습된 영역은 학습하지 않겠다고 설정하는 옵션
model.layers[0].trainable = False
# optimizer, compile
sgd = optimizers.SGD(lr = 0.01, decay = 1e-6, momentum = 0.9, nesterov = True)
model.compile(optimizer = sgd, loss = OBJECTIVE_FUNCTION, metrics = LOSS_METRICS)from keras.applications.resnet50 import preprocess_input
from keras.preprocessing.image import ImageDataGenerator
# 입력 이미지 사이즈 정의
image_size = IMAGE_RESIZE
# 입력 이미지, 데이터 증량(Augmentation)
datagen = ImageDataGenerator(
preprocessing_function=preprocess_input,
featurewise_center=True, # 데이터셋의 평균을 0으로
featurewise_std_normalization=True, # 데이터셋의 std로 나누기
rotation_range=20,
width_shift_range=0.2, #width 결정
height_shift_range=0.2, #height 결정
horizontal_flip=True)
# compute quantities required for featurewise normalization
# (std, mean, and principal components if ZCA whitening is applied)
datagen.fit(train_images)
#(train_images, train_labels), (test_images, test_labels) = datasets.cifar10.load_data()
# 모델 학습 (전이 학습)
model.fit(datagen.flow(train_images, train_labels, batch_size=32),
steps_per_epoch=len(train_images) / 32, epochs=NUM_EPOCHS)