■ Python 강의
01. 리스트 고급사용
# 리스트 고급사용
# 1. 1~1000까지 사이의 3의 배수값 리스트
list_3rd = []
for n in range(1,1000+1):
if n % 3 == 0: #3의 배수이면
list_3rd.append(n)
# print(list_3rd)
# 2. 1~1000까지 사이의
list_3rd_2 = [n for n in range(3, 1000+1, 3)]
# print(list_3rd_2)
list_3rd.clear()
for n in range(3, 1000+1, 3):
list_3rd.append(n)
# print(list_3rd)
##
# print([2 * x for x in range(1, 10+1)]) # 1붙터 10까지 2배수한다
# 3. 3의 배수 구하기
# print([3 * x for x in range(1, 333+1)])
# 4. 1~1000까지 사이의 3의 배수값 리스트
list_3rd = []
for n in range(1,1000+1):
if n % 3 == 0: #3의 배수이면
list_3rd.append(n)
print([x for x in range(1, 101) if x % 3 == 0]) # for문 if문 전부처리
# zip하고 유사
print([(x, y) for x in ['광어', '고등어', '참치'] for y in ['한돈','한우','한계']])
l1 = []
for x in ['광어', '고등어', '참치']:
for y in ['한돈','한우','한계']:
l1.append((x, y))
print(l1)
l1.clear()
print([x for x in range(10) if x < 5 if x % 2 == 0])
for x in range(10+1):
if x < 5:
if x % 2 == 0:
l1.append(x)
print(l1)
print((x*2 for x in range(1, 6)))- 결과값

02. 표준라이브러리, 웹클로닝
# 표준라이브러리
import datetime as dt
from datetime import date, datetime
first_date = date(2022, 12, 25)
cur_date = date.today() # date type
print(cur_date - first_date)
cur_dt = datetime.now() # 많이 씀
print(cur_dt)
print(cur_dt.strftime('%Y-%m-%d')) # date.today() 와 동일하지만 str
print(cur_dt.weekday()) # 0부터 월요일까지ㅏ
print(cur_dt.isoweekday()) # 1부터 월요일
import time
for x in range (10):
print(x)
time.sleep(1)# second(초)
import math
print(math.pi)
import os
#print(os.environ)
#print(os.environ['PATH'])
# print(os.getcwd())
# print(os.system('git --version')) # 콘솔 명령어 실행
import json
data = ''
with open('./Day04/data.json', mode='r', encoding='utf-8') as f:
data = json.load(f) # load -> str /loads -> byteArray
print(data)
# urllib
from urllib.request import urlopen
res = urlopen('https://www.naver.com')
print(res.status) # 200
print(res.read().decode('utf-8')) # index.html 가져옴 --> 웹 크롤링- 결과 : 웹클로닝을 통해 vscode을 실행을 하면 urlopen에 있는 주소창이 열린다.
03. Faker
from faker import Faker
import pandas as pd
dummy = Faker('ko-KR')
print(dummy.name())
print(dummy.address())
print(dummy.company())
dummy_date = [(dummy.name(), dummy.postcode(), dummy.address(),
dummy.phone_number(), dummy.email()) for i in range(100)]
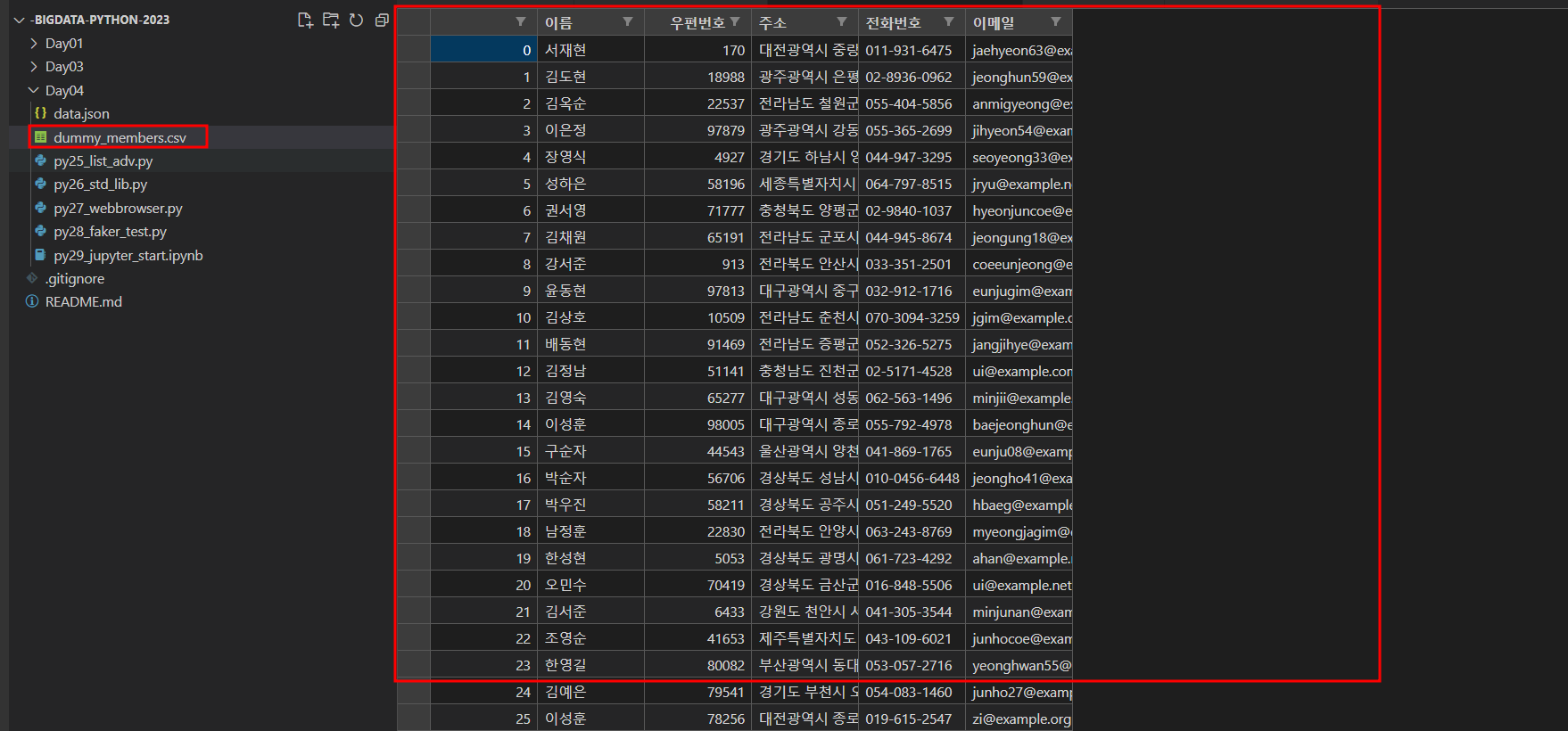
df = pd.DataFrame(data=dummy_date, columns=['이름', '우편번호', '주소', '전화번호', '이메일'])
# print(dummy_data)
df.to_csv('./Day04/dummy_members.csv', index=True, encoding='utf-8')
print('CSV 생성완료!')- 결과값
04. Jupyter