인덱스
인덱스란?
인덱스(Index)는 추가적인 쓰기 작업과 저장 공간을 활용하여 DB 테이블의 검색 속도를 향상시키기 위한 기술이다.
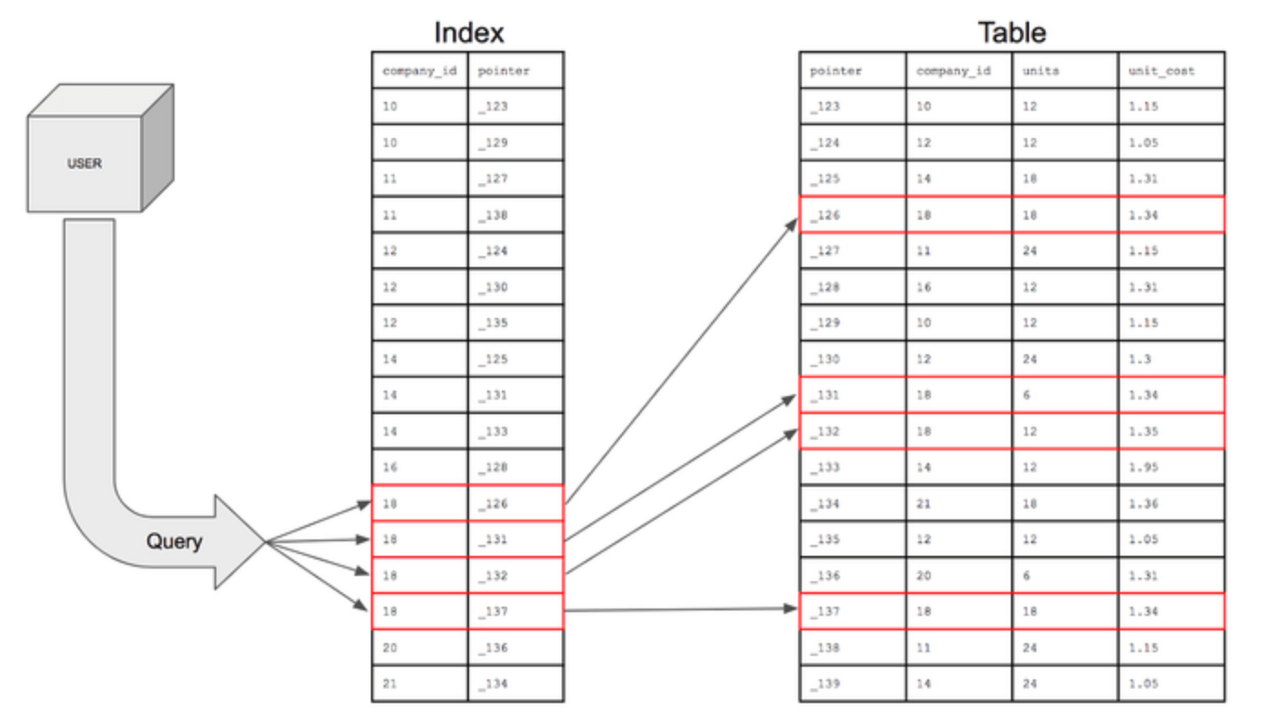
Table의 Column을 색인화(따로 파일로 저장)
➡ 해당 Table의 Row를 Full Scan하지 않음
➡ 색인화 된(B+ Tree 구조로) Index파일 검색으로 검색 속도 향상
이때 Index의 자료구조는 B-Tree/B+Tree 둘 중 하나로 되어있다.
이 둘의 차이는 다른 포스팅으로 다룰 예정이다.
Table 생성
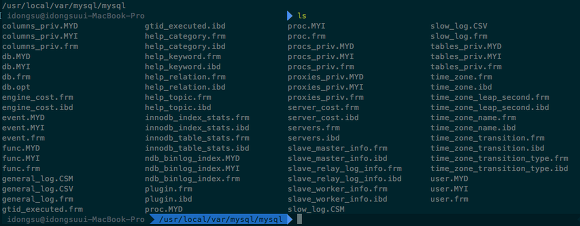
Table을 생성하면 .myd, .myi, .frm 총 3종류의 파일이 생성된다.
.myd: 실제 데이터가 저장되어 있는 파일.myi: index 정보가 들어가 있는 파일.frm: 파일의 경우 테이블 구조가 저장되어있음
Index를 사용하지 않은 경우, .myi파일은 비어져 있다. 그러나 인덱싱하는 경우 .myi파일이 생성된다.
이후 사용자가 index를 이용하여 Select하는 경우 .myi파일의 내용을 검색한다
Index의 단점
- 많은 수의 Index를 생성할 경우 디스크의 용량이 줄어듬(.mdb 파일의 용량이 커지기 때문)
- 테이블에서 CUD(create, update, delete)작업이 빈번하다면 성능이 떨어짐
- (CUD 작업에 대해서는 Index를 재작성 해야 하기 때문에 성능저하를 초래함)
- Index를 생성하는 시간이 길어짐
CUD요청 시 Index에서 일어나는 작업들
DML(Data Manipulation Language)
- 데이터를 조작하는 명령어 ex) INSERT, DELETE, UPDATE
1. Insert - Index Split
Index 테이블에 더 이상 공간이 없을 때, Insert가 들어오면 Index Split가 발생한다.
새로운 Table을 할당 받은 후, 기존의 Table에서 Key를 새로 할당한 곳으로 이동시키는 과정에서 많은 양의 Redo가 발생된다.
그리고 위 과정이 이루어지는 동안 추가적인 CUD가 발생하면 안되기 때문에, DML 블로킹이 발생한다.
2. Delete
보통의 사람이라면 Delete가 발생했을 경우, 정렬된 Index 에서 삭제된 레코드를 찾아 지울 것이라고 생각할 것이다. 하지만 아니다!!
실제 Index파일에서는 "삭제"가 아닌, "사용중지"명령을 내린다.
즉, 데이터는 파일에 존재하고 용량을 계속 차지한다는 것이다. (Table 데이터 수와 Index 데이터 수 다를 수 있음)
빈번한 Delete가 발생하게 되면, Index에 저장된 파일의 크기는 계속 증가할 것이므로, 성능 향상의 기대 또한 어렵다.
3. Update
Table에서 update가 일어나면, Index도 마찬가지로 update하는 것이 아니다!
대신 Delete가 발생한 후, 새로운 작업의 Insert가 일어난다. 즉, Delete + Insert 2배의 작업이 소요되어 성능 상 부담이 크다.
