정규화(Normalization)
정규화의 가장 큰 목표는 중복된 데이터를 허용하지 않는 것이다.
중복된 데이터를 만들지 않으면, 무결성을 향상시킬 수 있고, DB를 효율적으로 관리할 수 있다.
목적
- 삽입/삭제/갱신 이상 등을 방지할 수 있다.
- 데이터 중복을 최소화하고, 불필요한 데이터를 없앤다.
- 데이터베이스 구조의 확장성에 용이하다.
- 테이블 구성을 논리적이고 직관적으로 할 수 있다.
이 포스터에는 1-3단계 정규화까지만 다루겠다.
1. 제1 정규화(1NF)
제1 정규화란 테이블의 컬럼이 원자값(Atomic Value,하나의 값)을 갖도록 테이블을 분리시키는 것을 말한다.
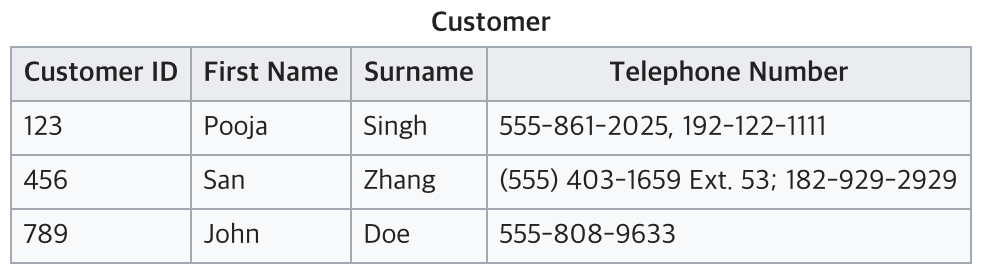
위 테이블은 전화번호를 여러 개 가지고 있어 원자값이 아니다. 따라서 제1 정규화에 위배된다. 또한 CustomerID가 123인 고객의 555-861-2025 번호를 삭제한다면, 192-122-1111까지 모두 삭제 되므로 삭제 이상이 발생하게 된다.
따라서, 제1 정규화를 적용하면 아래와 같은 테이블이 나온다.
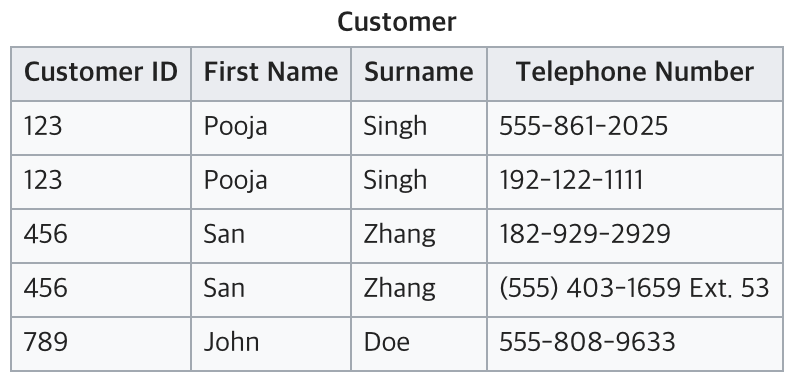
이 테이블에는 원자값만 존재하며, 삭제 이상이 발생하지 않는다.
2. 제2 정규화(2NF)
제2 정규화는 테이블의 모든 컬럼이 완전함수적 종속을 만족해야 한다.
이게 무슨말이냐면, 기본키가 복합키(키1,키2)로 묶여있을 때, 키1 키2 중 하나만으로 다른 컬럼을 결정지을 수 있으면 안된다는 것이다.
조금 더 확실한 이해를 위해, 예시를 보자.
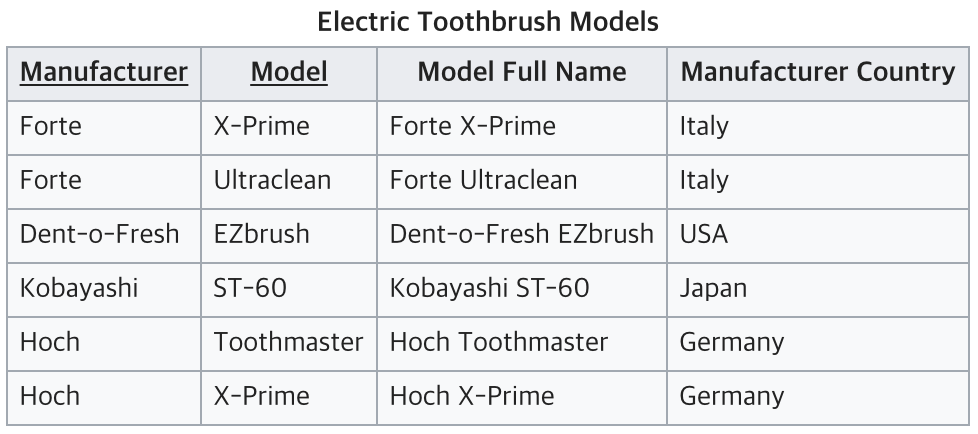
위 테이블에서는 (Manufacturer, Model) 이 키가 된다.
하지만 복합키 중 하나인 Manufacturer 만으로 Manufacturer Country 컬럼을 결정할 수 있기 때문에, 이는 제2 정규화에 위배되는 것이다.
또한 Fort의 Manufacturer Country를 Italy로 변경하면, 갱신 이상의 문제가 발생한다.
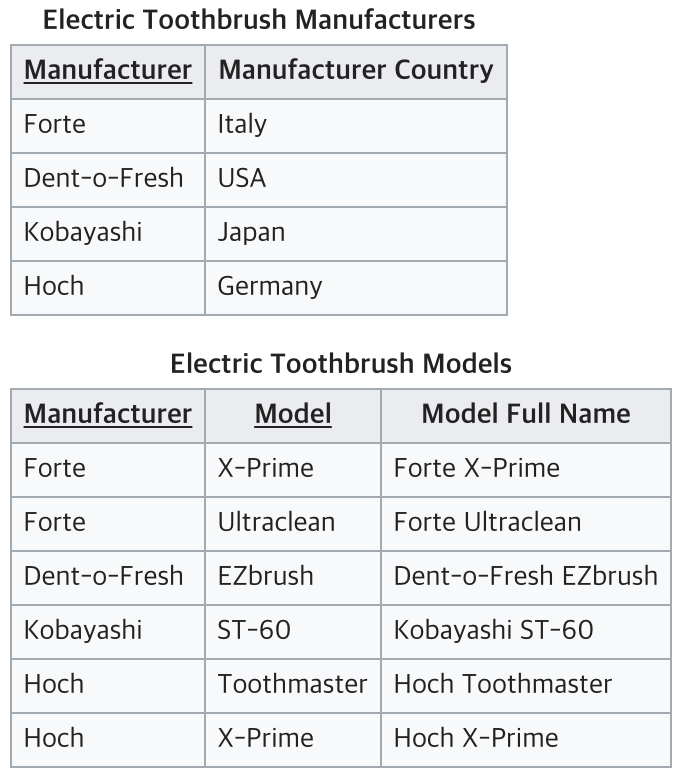
다음과 같이 2개의 테이블로 분리시키면 제2 정규화를 만족하게 된다.
3. 제3 정규화(3NF)
제3 정규화는 2NF가 진행된 테이블에서 이행적 종속을 없애기 위해 테이블을 분리하는 것이다.
🔍이행적 종속 : A ➡ B 이고, B ➡ C 를 만족할 때, A ➡ C 가 되는 상태
아직까지 무슨말인지 확실히 와닿지 않을 수 있다.
예시를 들어보면,
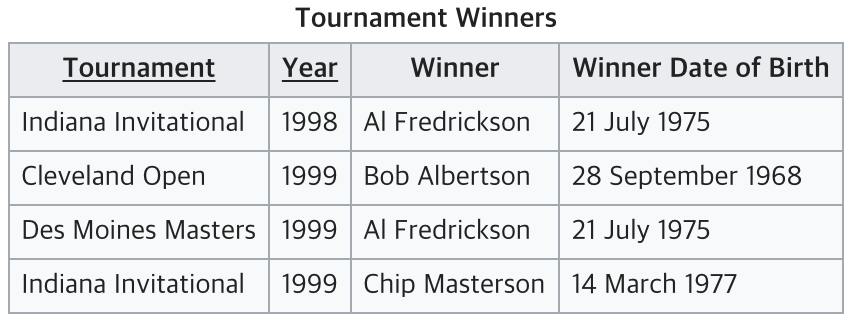
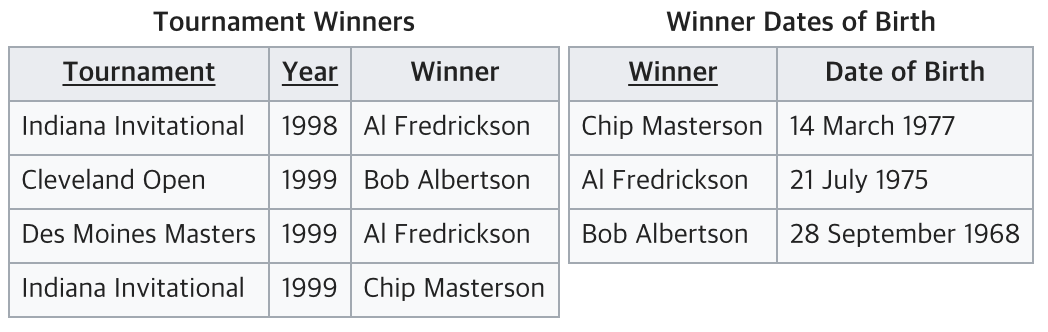
다음과 같은 테이블이 있다고 하자.
기본키인 (Tournament, Year)에 의해 Winner가 결정된다.
👉 (Tournament, Year) ➡ Winner
하지만 기본키가 아닌 Winner에 의해 Winner Date of Birth가 결정된다.
👉 Winner ➡ Winner Date of Birth
따라서 3NF에 위반되므로, 이를 만족시키기 위해 아래 테이블 처럼 분리시키면 된다.
이행적 종속을 제거하는 이유는 예를 들어,
첫번째 row의Winner를 Al Frendricson -> Mike라고 바꾼다면Date of Birth까지 바꾸어야 한다는 번거로움이 있다. 이러한 번거러움을 해결하기 위해 제3 정규화가 필요하다.