
일반적인 프로그래밍 기반 방법은 한 입력이 주어졌을 때 이를 결과로 만드는 알고리즘을 통해 출력을 만들어냅니다. 그러나 머신러닝 기반 방법에서는 어떤 입력이 주어졌을 때 이에 해당하는 결과를 정확하게 예측하는 모델을 만들고, 입력과 출력 데이터를 기반으로 모델을 학습하는 과정을 거칩니다. 이렇게 머신러닝 기반 방법은 일반적인 프로그래밍 기법와 다르게 몇 단계로 나눌 수 있는데, 크게 나누어보면 전처리 단계, 학습 단계, 테스트 단계로 볼 수 있습니다. 이 포스트에서는 딥러닝에서의 동작 과정(특히 학습 단계)에 조금 더 집중해서 설명드리겠습니다.
전처리 단계

전처리 단계는 취득된 데이터에 대해 정의된 모델에 대한 입력과 타겟(출력하고자 하는) 데이터로 가공하는 단계입니다. 이미 체계가 맞추어진 공개 데이터셋을 활용할 때 전처리 과정이 이미 수행되어 바로 모델에 입력으로 들어갈 수 있는 상태이면 이 단계를 생략할 수도 있습니다. 그러나, 그렇지 않은 데이터도 존재하기 때문에(특히 타겟 데이터에 대해서) 모델을 활용하기 위해 이 과정을 수행해야 합니다.
학습 단계
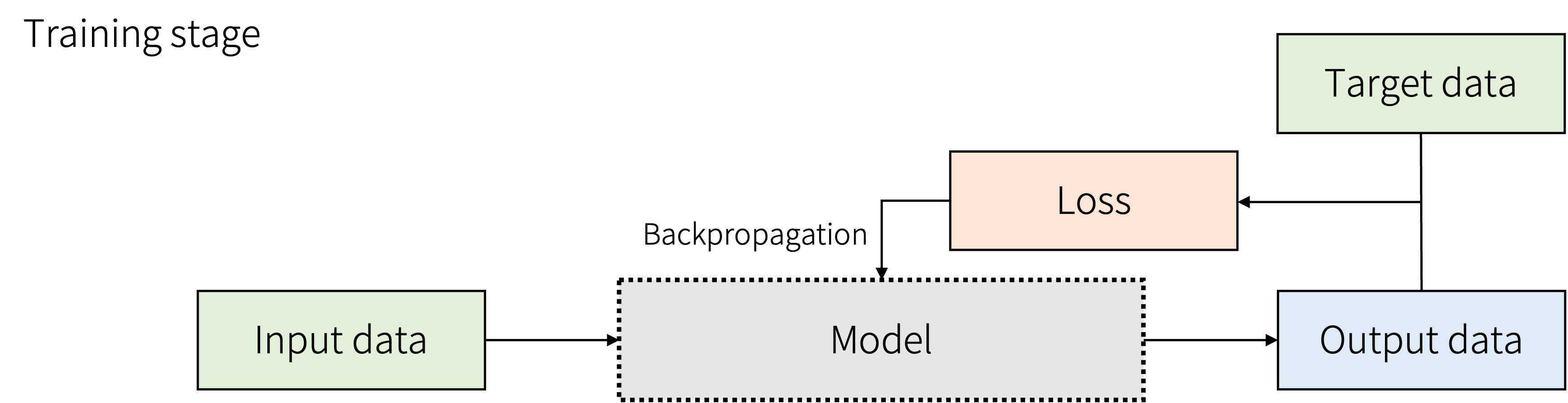
학습 단계는 전처리된 입력과 타겟 데이터를 활용해서 모델을 학습시키는 단계입니다. 학습을 수행할 입력 데이터는 모델을 통해 출력 데이터로 만들어집니다. 이는 타겟 데이터와 손실 함수를 통해 손실값을 계산합니다. 물론 초기에는 손실 함수의 값이 클 것으로 예상할 수 있습니다. 이 손실값을 편미분을 이용한 역전파 알고리즘을 통해 모델의 가중치들을 조절하는 과정을 수행하게 됩니다. 학습 데이터에 대해 몇 번의 에포크(epoch)를 통해 반복을 수행하게 되면 모델의 가중치들이 수렴하게 되고, 이를 결과 측면으로 보면 입력 데이터에 대해 타겟 데이터에 근사하는 모델로 학습될 수 있게 되는 것입니다.
테스트 단계

테스트 단계는 학습한 모델을 검증 및 평가하면서 실질적으로 활용하는 단계입니다. 이 단계에서는 이미 학습된 모델을 불러와, 전처리된 데이터가 모델을 통해 결과값을 출력하게 됩니다. 출력된 데이터는 여러 가지 방식으로 활용될 수 있습니다. 예를 들어, 분류 문제에서는 이 이미지 등이 어떤 클래스로 판정이 되었는지 터미널로 사용자에게 알려주거나 데이터 자체를 파일로 저장될 수도 있습니다. 실질적으로 서버에서 응답을 보내야 하는 경우 결과를 보내는 과정도 포함됩니다. 이렇게 출력된 데이터를 활용해서 실질적으로 사용자에게 도움이 되는 정보를 만드는 과정을 후처리(postprocessing) 과정이라고 할 수 있습니다.
