[Chaper14. Deep computer vision with cnns]
🔸 computer vision: 영상 이미지에서 영상 처리를 하고 인식하는 모든 영상 처리와 관련된 작업
🔸 Deep computer vison: cnn과 같은 neural network를 사용하는 computer vision
📌 The Architecture of the Visual Cortex
🔸 visual cortex: 시각 부분을 처리하는 뇌의 부분, 시신경(=시각신경)
1. Neurons in visual cortex:
1) Local receptive field: react only to visual stimuli located in a limited region of the visual field
🔅 수용하는 영역(receptive field)이 local함. visual field의 제한된 영역에 위치한 시각적인 정보에만 반응하도록 되어있음
🔅 하나의 신경 세포는 local receptive field만을 봄
🔸 visual field: 눈으로 볼 수 있는 영역
🔸 receptive field: 하나의 신경 세포가 받아들이는 영역
2) May overlap, and together they tile the whole visual field
🔅 receptive field는 중첩될 수 있고 receptive field가 타일처럼 모여 visual field(시각으로 볼 수 있는 전체 영역) 생성
3) Two neurons with the same receptive field; but react to different line orientations
🔅 두 neuron은 같은 receptive field를 가질 수 있지만 선의 방향이 다르게 반응
4) Some neurons with larger receptive fields: react to more complex patterns (combinations of the lower-level patterns) => based on the outputs of neighboring lower-level neurons
🔅 몇몇 neuron은 더 큰 receptive field를 가지고 이 경우 복잡한 패턴(lower-level pattern의 조합) 인식 => 이웃한 lower-level neuron의 출력에 기반해 패턴 인식
🔅 lower level에 있는 신경 세포는 단순한 패턴을 인식하고 higher level에 있는 신경 세포는 lower level의 신경세포가 인식한 패턴을 조합해 복잡한 패턴 인식
🔸 higher level로 갈수록 receptive field가 커지기 때문에 higher level로 갈 수록 더 복잡한 패턴 인식 : hierarchy 존재
5) => to detect all sorts of complex patterns in any area of the visual field
🔅 위와 같은 방식으로 hierarchy를 이루면 visual field 영역의 어떤 복잡한 패턴도 인식 가능
6) Inspired Neocognition (NN model) => CNN (LeNet-5, LeCun, 1988)
🔅 Neocognition이라는 neural network model에 영향을 미치고 이후 LeCun 교수가 LeNet-5를 통해 CNN 구조 발표 => 영상 컴퓨터 vision에 자주 사용됨
📌 Convolutional Layers
1. The most important building block of a CNN
🔅 CNN은 가장 중요한 빌딩 블럭. CNN은 convolutional layer를 쌓아 만듬
2. Neurons connected to pixels in their receptive fields
🔅 receptive field의 neuron이 pixel과 연결. 즉 하나의 pixel이 하나의 neuron
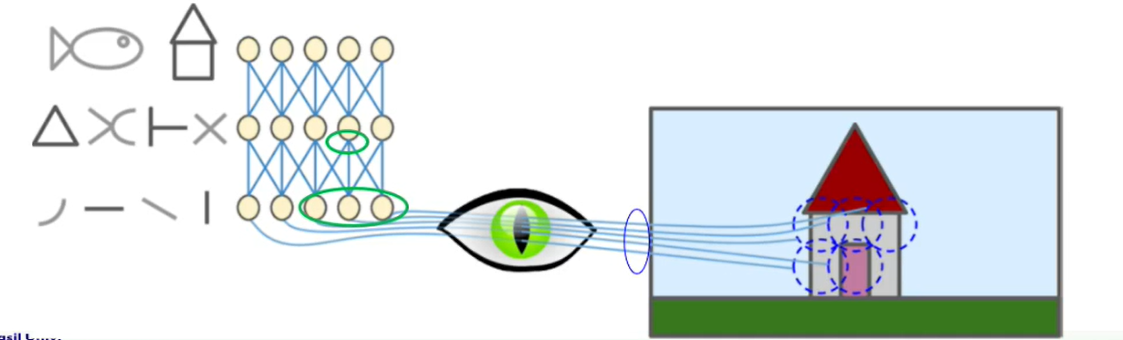
1) concentrate on low-level features in the first hidden layer
🔅 첫번째 convolutional layer에는 low-level feature를 담당하는 neuron이 모여있음
2) assemble the into higher-level features in the next hidden layer
🔅 다음 convolutional layer에는 이전 layer을 조합해 높은 high-level feature이 존재
3) hierarchical structure: common in real-world images => CNNs work so well for image recognition
🔅 실제 이미지에 볼 수 있는 것과 비슷(간단한 패턴이 복잡한 패턴 형성) => CNN은 이미지 인식에 잘 동작
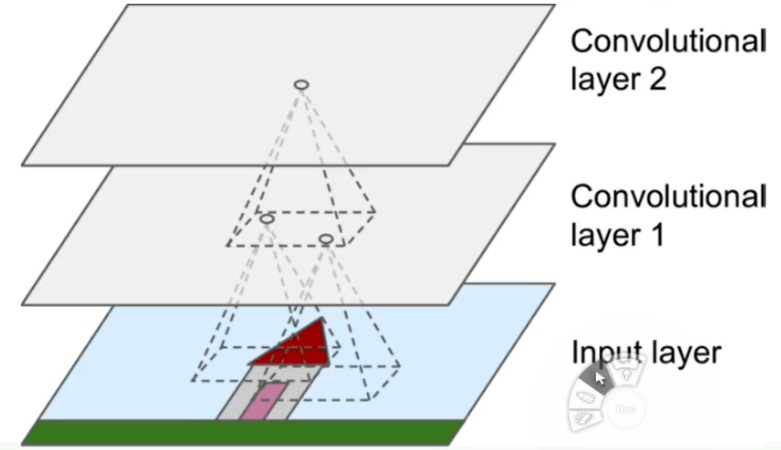
🔅 input layer에서의 가장 작은 receptive field가 convolutional layer 1에서는 하나의 pixel, 즉 neuron에 대응되고 convolutional layer 1에서의 여러 neuron이 convolutional layer 2에서 하나의 neuron에 대응됨 => higher layer로 갈수록 복잡한 패턴 인식 가능
🔸 ex. convolutional layer 1에서의 하나의 neuron은 선으로 인식 -> convolutional layer 2에서는 하나의 neuron이 삼각형으로 인식
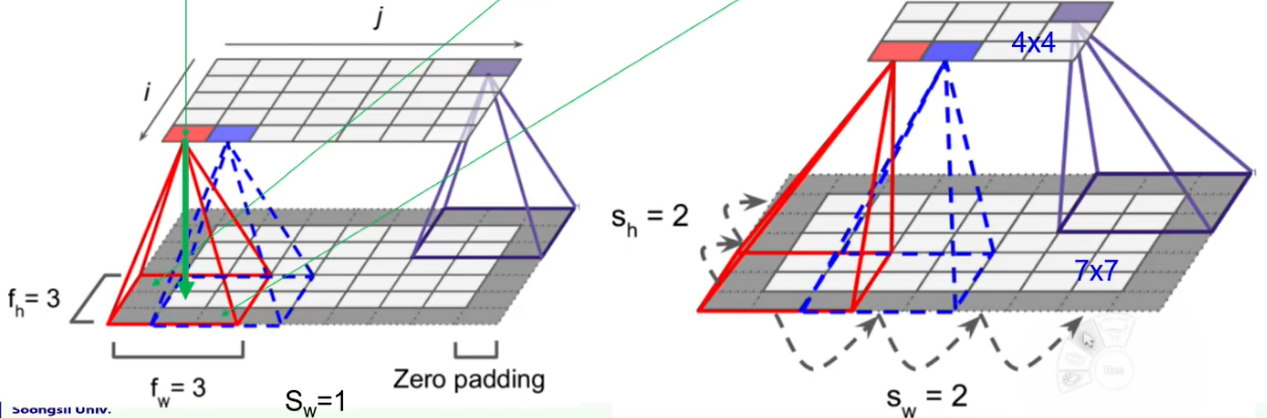
3. A neuron in (i,j) connected to the neurons in (i-()/2, j-()/2) to (i+(-1)/2, j+()/2) in the previous layer
🔸 아래 그림에서 lower layer의 각 사각형은 하나의 pixel, 즉 하나의 neuron 의미
🔸 neuron 좌표는 왼쪽 위가 (0,0)이고 각각 아래, 오른쪽으로 갈수록 좌표값 증가
🔅 high-layer의 (i,j) neuron이 low-layer의 하나의 receptive field에 대응
🔅 high-layer의 (i,j)는 low-layer의 (i-(-1)/2, j-(-1)/2)에서 (i+(-1)/2, j+(-1)/2)까지의 범위에 해당하는 neuron과 연결
and : the height and width of the receptive field
🔅 receptive field의 크기에 따라 receptive field 안에 포함된 neuron의 개수가 달라짐
Ex. =3, =3일 경우 (i,j)는 (i-1,j-1)에서 (i+1,j+1)까지의 neuron과 연결
4. Zero padding: add zeros (or other values) for boundary neurons
🔅 가장자리에 존재하는 pixel의 경우 receptive field 만들어주기위해 값이 0인 zero padding. high layer에서 가장자리의 pixel과 인접한 pixel까지 대응시킬 수 있도록 함
🔸 위에서 한 예시는 high layer의 pixel 개수와 low layer의 pixel 개수가 같은 경우이지만, CNN의 경우 high layer의 pixel 개수와 low layer의 pixel 개수가 다른 경우가 많음. 상위 layer로 갈수록 복잡한 패턴을 담당해야하기 때문에 하나의 neuron이 여러 pixel의 정보를 담고 있어야 함 => 상위 layer로 갈수록 pixel 수가 점점 줄어듬
🔸 low layer보다 high layer의 pixel 수가 더 작으면 stride가 더 커짐
5. Stride: distance between two consecutive receptive fields
🔅 stride: 연속된 receptive field의 거리
🔸 =2일 경우 high layer는 low layer의 pixel 수보다 가로, 세로가 각각 1/2 배 됨 => 이 때, zero padding도 포함해서 계산
Ex. low layer로 7x7 pixel이 있을 경우 zero padding을 포함하면 9x9, 가 2이므로 high layer는 4x4(9/2=4.5, pixel은 정수만 가능하므로 4.5는 4로 간주) pixel 존재
a large input layer => a much smaller layer
📌 Convolutional Layers: filters and training
🔸 convolutional layer도 neural network의 일부
1. Filters (convolutional kernels): neuron's weights with the size of the receptive field
🔅 filter(=convolutional kernels)란 receptive field 크기의 neuron의 weight(parameter)를 모아둔 것
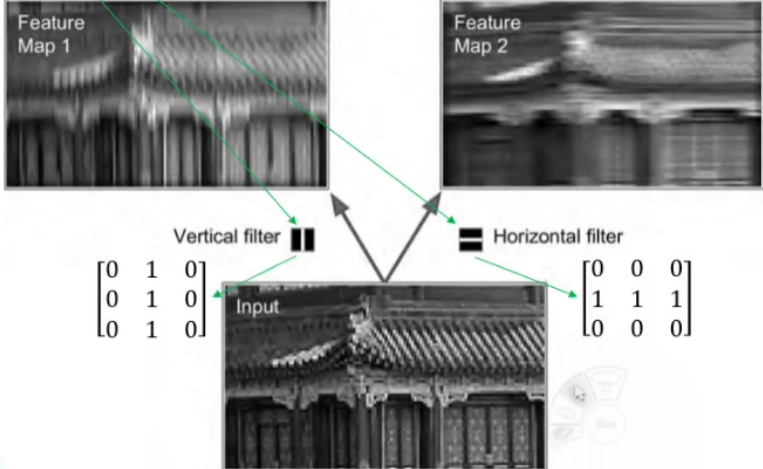
💡 kernel이란 작은 크기의 행렬로, 입력 데이터의 작은 부분(receptive field)을 처리하는데 사용
💡 filter란 하나 이상의 kernel로 이루어진 행렬로, 입력 데이터에 대한 합성곱 연산을 수행하여 출력 데이터의 feature map 생성
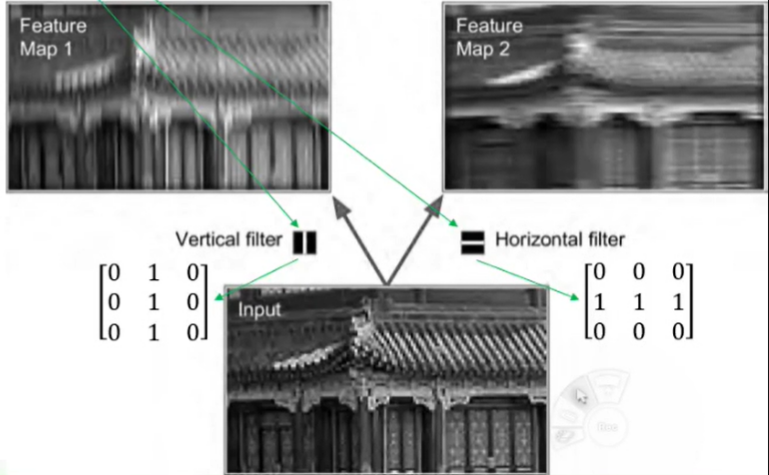
1) can be represented as a small image
2) Ex. Vertical filter: ignore everything except for vertical lines (can be 3x3, 5x5,7x7, and so on: 주로 홀수로 구성)
🔅 vertical filter는 vertical line을 제외한 모든 pixel 무시. vertical line만이 vertical filter의 1과 연산되어 존재하고, 나머지 line은 0과 연산되어 0이 되기 때문
🔸 vertical white lines get enhanced while the rest gets blurred
🔅 vertical line은 강조되고 나머지는 blur 처리된 것처럼 나타남
3) Filtering gives a feature map: highlights the areas similar to the filter
🔅 feature map: 입력 이미지에 대해 filter를 적용한 결과 => filter와 비슷한 형태로 이미지 변형해 강조
2. CNN training
🔸 학습이란 parameter를 얻는 것
1) finds the most useful filters for its task
🔅 CNN training이란 하고자하는 task에 맞는 적절한 filter를 찾는 것. filter가 weight 값을 receptive field 크기로 모아둔 것이기 때문
2) learns to combine them into more complex patterns
🔅 low layer의 filter는 단순한 패턴 인식. filter를 통해 얻은 단순한 패턴을 모아 복잡한 패턴 인식할 수 있도록 하는 것이 목적
🔸 E.g. cross=vertical line + horizontal line => vertical line과 horizontal line을 모으면 십자가 모양의 패턴 인식 가능
📌 Convolutional Neural Network
1. CNN
1) Pixel as Neuron
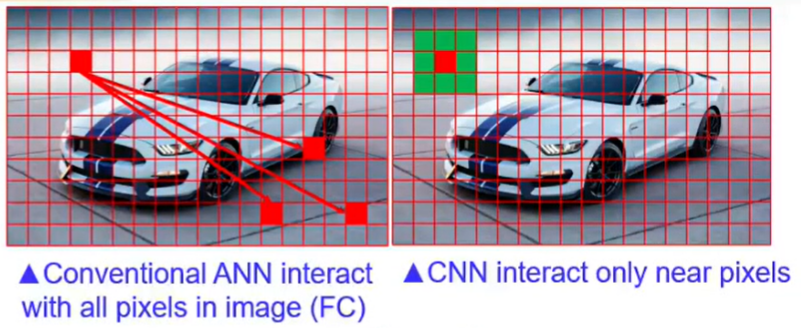
🔅 CNN과 Dense network(= fully connected network)는 하나의 neuron이 하나의 pixel에 대응된다는 공통점이 있지만 아래와 같은 차이점이 존재
🔸 Interact with nearby pixels only
🔅 이웃에 있는 pixel과만 상호작용
🔅 Dense network는 하나의 pixel이 이미지에 있는 모든 pixel과 관련성이 있는지를 찾아야하기 때문에 하나의 neuron은 이전 layer의 모든 neuron과의 관계(weight, bias)를 따지며 학습 진행
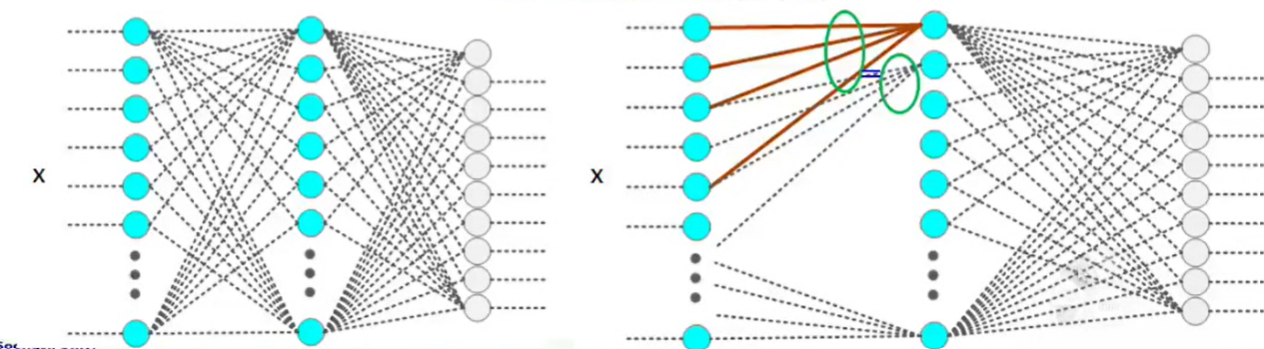
🔅 CNN은 kernel(=filter) size 범위 내에서만 관계성 찾음 => 이웃한 pixel이 특정 pattern을 나타내고 인식됨. (1) 하나의 neuron이 이전 layer에서 kernel에 포함되는 일정한 개수의 neuron으로부터만 입력받고 나머지는 connection 자체가 없음(weight=0으로 간주). (2) 각 neuron에 연결된 connection의 개수가 동일 (kernel size만큼의 connection 존재해 연산량 DNN보다 작음)
🔅 (3) 하나의 layer에 존재하는 neuron은 동일한 kernel 사용하므로 각 neuron에 첫번째로 들어가는 neuron의 weight는, 두번째로 들어가는 neuron의 weight는 서로 동일 => layer와 연결되는 connect weight값은 서로 같음
🔅 weight 값이 같다는 조건 안에서 w 값을 변화시켜 학습 진행
🔸 Computation reduction
🔅 fully connected network의 경우 모든 이전 layer의 neuron과 connection을 가지므로 parameter가 많아 연산량이 많은 반면, CNN은 한 neuron 당 kernel size의 connection만 가지므로 연산량이 작음. 입력 neuron의 크기가 클수록 연산량 차이가 커짐
🔸 Better performance
🔅 fully connected network의 경우 관련없는 pixel과의 weight 조절하므로 local feature에 집중하지 못함