JPA 영속성관리 공부의 기록
공부의 기록 시리즈는 공유하고자 적는 글이 아닙니다. 공부할때 필기 하는 습관이 있고, 모르는 내용을 메모할 공간이 필요하기 때문에 적는 글입니다. 나중에 이 글을 잘 정제하고 편집해서 공유를 위한 글을 따로 포스팅합니다.
JPA가 제공하는 기능은 크게 두 부분으로 나눌 수 있다.
(1) 엔티티와 테이블을 매핑하는 설계 부분
(2) 매핑한 엔티티를 실제 사용하는 부분
이번 공부에서는 매핑한 엔티티를 엔티티 매니저(EntityManager)를 통해 어떻게 사용하는지 알아보자.
엔티티 매니저는 엔티티를 저장하고, 수정하고, 삭제하고, 조회하는 등 엔티티 와 관련된 모든 일을 처리한다. 이름 그대로 엔티티를 관리하는 관리자다.
엔티티 매니저 팩토리와 엔티티 매니저
생성 비용
엔티니 매니저 팩토리는 이름 그대로 엔티티 매니저를 생성하는 역할을 맡는다. 엔티티 매니저 팩토리를 생성하는 비용은 굉장히 크기 때문에 한 개만 만들어서 애플리케이션 전체에서 공유하도록 설계되어 있다. 반면 엔티티 매니저는 생성 비용이 크지 않다.
동시성 문제
엔티티 매니저 팩토리는 여러 스레드가 동시에 접근해도 안 전하므로 서로 다른 스레드 간에 공유해도 되지만, 엔티티 매니저는 여러 스레드가 동 시에 접근하면 동시성 문제가 발생하므로 스레드 간에 절대 공유하면 안 된다.(무슨 말일까)
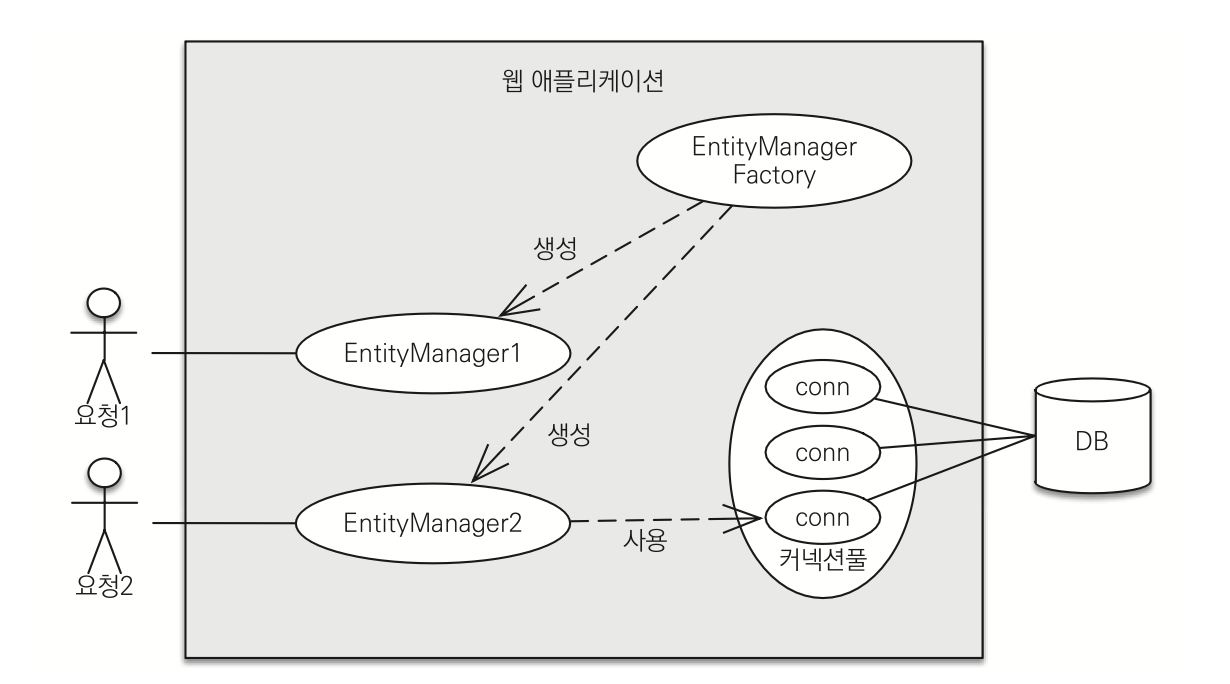
위 그림에서 엔티티매니저와 팩토리간의 관계가 명확하다. 그리고 특이한 점은 엔티티 매니저는 생성된 시점에 DB 커넥션을 얻는것이 아니라, 사용되는 시점에 DB 커넥션을 얻게 된다는 것이다.
하이버네이트를 포함한 JPA 구현체들은 EntityManagerFactory를 생성할 때 커넥션풀도 만드는데(persistence.xml에 보면 데이터베이스 접속 정보가 있다) 이것은 J2SE 환경에서 사용하는 방법이다. JPA를 J2EE 환경(스프링 프레임워크 포함)에서 사용하면 해당 컨테이너가 제공하는 데이터소스를 사용한다.
영속성 콘텍스트
JPA를 이해하는 데 가장 중요한 용어는 영속성 컨텍스트(persistence context)다. 우리말로 번역하기가 어렵지만 해석하자면 ‘엔티티를 영구 저장하는 환경’이라는 뜻이다.
엔티티 매니저로 엔티티를 저장하거나 조회하면 엔티티 매니저는 영속성 컨텍스트에 엔티티를 보관하고 관리한다.
em.persist(member);
지금까지는 이 코드를 단순히 회원 엔티티를 저장한다고 표현했다. 정확히 이야기하면 persist() 메소드는 엔티티 매니저를 사용해서 회원 엔티티를 영속성 컨텍스트에 저장하는 것이다.
영속성 컨텍스트는 논리적인 개념에 가깝고 눈에 보이지도 않는다. 영속성 컨텍스트는 엔티티 매니저를 생성할 때 하나 만들어진다. 그리고 엔티티 매니저를 통해서 영속성 컨텍스트에 접근할 수 있고, 영속성 컨텍스트를 관리할 수 있다.
엔티티 생명주기
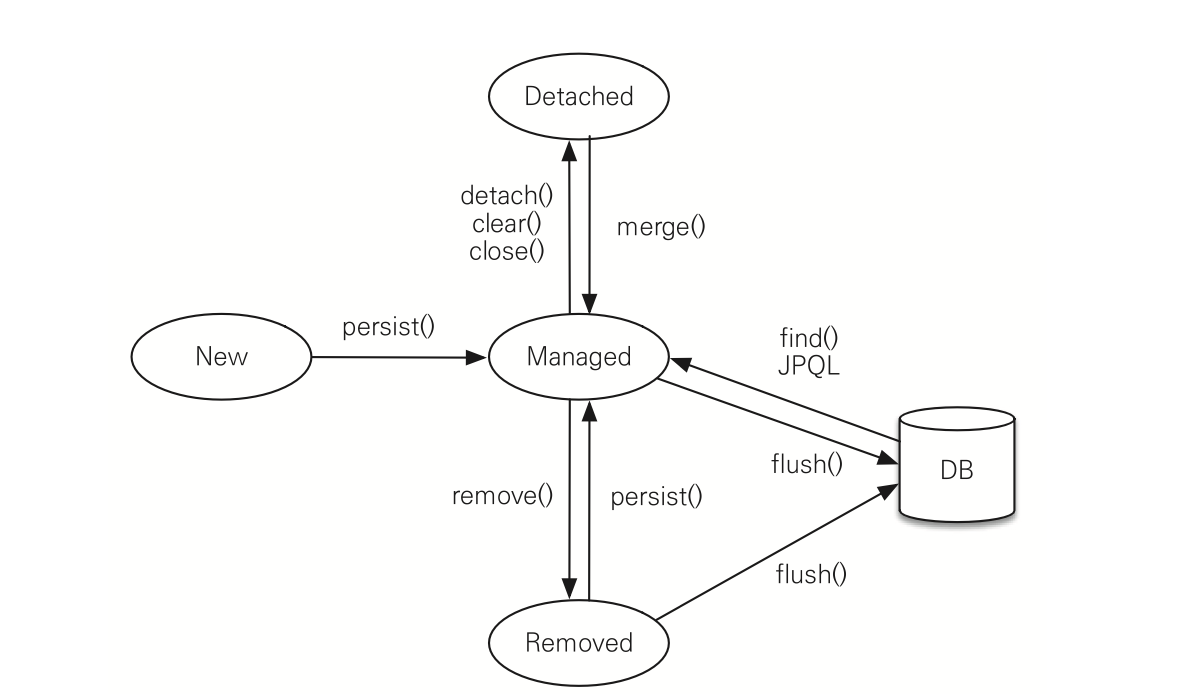
엔티티의 상태에는 4가지가 있다.
■ 비영속(new/transient): 영속성 컨텍스트와 전혀 관계가 없는 상태
■ 영속(managed): 영속성 컨텍스트에 저장된 상태
■ 준영속(detached): 영속성 컨텍스트에 저장되었다가 분리된 상태
■ 삭제(removed): 삭제된 상태
비영속(new) 상태
아래의 코드처럼 member(엔티티 객체) 인스턴스가 생성되었을 뿐, 영속성 컨텍스트와는 어떠한 상호작용도 없는 상태 이다.
Member member = new Member();
member.setId("member1");
member.setUsername("회원1");영속(managed) 상태
엔티티 매니저를 통해서 엔티티를 영속성 컨텍스트에 저장된(관리되는) 상태를 의미한다. persist메소드에 사용된 엔티티 객체 혹은 find 메소드나 JPQL을 통해 나타난 엔티티 객체를 영속 상태라고 한다.
em.persist(member); // 영속성 컨텍스트에 등록
Member member2 = em.find(Member.class, id); // DB나 영속성 컨텍스트에서 식별자 필드를 이용해 조회
List<Member> members =
em.createQuery("select m from jpastart.Member m",
Member.class).getResultList(); // JPQL을 이용해 조회준영속(detached) 상태
영속성 컨텍스트가 관리하던 영속 상태의 엔티티를 영속성 컨텍스트가 관리하지 않으면 준영속 상태가 된다. 다음의 세가지 경우에 엔티티가 준영속 상태가 된다.
em.detach(member); // 엔티티 매니저가 관리하는 영속성 컨텍스트에서 특정 엔티티를 제외시킴
em.close(); // 엔티티 매니저 자체를 닫아버림
em.clear(); // 엔티티 매니저가 관리하는 영속성 컨텍스트를 비워버림준영속 상태와 비영속 상태를 구분하는 이유가 있을텐데, 뭘까?
삭제(removed) 상태
엔티티를 영속성 컨텍스트와 데이터베이스에서 삭제한다.
em.remove(member);이러한 엔티티의 생명주기를 그림으로 나타내면 다음과 같다.
영속성 컨텍스트의 특징
1.영속성컨텍스트와 식별자값
영속성 컨텍스트는 엔티티를 식별자 값(@Id로 테이블의 기본 키와 매핑한 값)으로 구분한다. 따라서 영속 상태는 식별자 값이 반드시 있어야 한다. 식별자 값이 없으면 예외가 발생한다.
2. 영속성컨텍스트와 데이터베이스저장
영속성 컨텍스트에 엔티티를 저장하면 이 엔티티는 트랜잭션을 커밋하는 순간 영속성 컨텍스트에 새로 저장된 엔티티를 데이터베이스에 반영한다. 이것을 플러시(flush)라 한다.
3. 영속성컨텍스트의 엔티티 관리 장점
■ 1차 캐시
■ 동일성 보장
■ 트랜잭션을 지원하는 쓰기 지연
■ 변경감지
■ 지연로딩 (객체 그래프 탐색시 이점이 생기는데, 이 포스팅에서는 다루지 않는다.)
영속성 컨텍스트가 왜 필요하고 어떤 이점이 있는지 엔티티를 CRUD 하면서 그 이유를 하나씩 알아보자.
(1) 엔티티 조회 (1차 캐시, 동일성 보장)
영속성 컨텍스트는 내부에 캐시를 가지고 있는데 이것을 1차 캐시라 한다. 영속 상태의 엔티티는 모두 이곳에 저장된다.
1차 캐시의 키는 식별자 값이다. 그리고 식별자 값은 데이터베이스 기본 키와 매핑되어 있다. 따라서 영속성 컨텍스트에 데이터를 저장하고 조회하는 모든 기준 은 데이터베이스 기본 키 값이다.
1차 캐시의 성능상 이점
em.find(Member.class, id)로 엔티티를 조회하면 1차 캐시에서 먼저 조회를 하고 없으면 DB에서 조회를 한다. 바로 DB에서 조회하는것이 아니기 때문에 DB 커넥팅에 따른 비용이 발생하지 않을 수 있다.
1차 캐시에 없어서 DB에서 조회할 경우 DB에서 조회된 내용이 영속성 컨텍스트의 1차 캐시에 저장된뒤 엔티티가 반환된다. 다음에 똑같은 엔티티를 호출할 경우 성능상 이점을 누릴 수 있도록 하기 위함이다.
1차 캐시의 동일성 보장
Jdbc API로 직접 Member 테이블에서 ID 1인 row를 객체화하는 경우를 생각해보자. 총 두번 조회하고 각각을 a, b 라는 참조변수가 참조하도록 하였다. 이때 a == b(동등성 비교) 의 결과값은 어떻게 될까? Jdbc API를 통해 생성되는 인스턴스는 그때마다 서로 다른 주소값을 가진 인스턴스를 반환하기 때문에 false가 반환된다.
반면에 EntityManager를 통해 반환하는 객체는 영속성 컨텍스트 내부의 1차 캐시에 저장된 객체를 반환하기 때문에 항상 참조값이 동일한 객체를 반환한다.
Member a = em.find(Member.class, "Id1");
Member b = em.find(Member.class, "Id1");
a == b // 결과값 : true동일성과 동등성(identity & equality)
- 동일성(identity)
실제 인스턴스가 같다. 따라서 참조 값을 비교하는 == 비교의 값이 같다.- 동등성(equality)
실제 인스턴스는 다를 수 있지만 인스턴스가 가지고 있는 값이 같다. 자바에서 동등성 비교는 equals() 메소드를 구현해야 한다.
이러한 동일성 보장 때문에 서비스 로직에서 주의를 요하는데, 동일한 엔티티를 서로 다른 서비스 로직에서 참조할 경우 한쪽에서 바꾼 값이 다른 쪽 로직에 영향을 줄 수 있다. 될 수 있으면 한번에 하나의 엔티티만 참조하도록 로직을 설계해야 할 것이다.
private static void logic(EntityManager em) {
Member member1 = new Member();
member1.setId("1");
member1.setUsername("지환");
member1.setAge(20);
em.persist(member1);
Member member1re = em.find(Member.class, "1");
member1.setAge(15);
System.out.println(member1.getAge() == member1re.getAge());
// 반환값 : true
em.remove(member1);
}member1의 age를 20으로 설정하고 1차 캐시에 등록하였다. 그리고 동일한 엔티티를 member1re라는 참조변수가 참조하게끔 하였다. 그 뒤 member1 인스턴스의 age를 15로 변경하고 member1 과 member1re으 age의 동일성 검사를 하였다. 그 결과 둘은 동일하다는 결과를 얻을 수 있었는데, 너무나도 당연하게 두 변수가 참조하는 값이 동일하기 때문이다.
(2) 엔티티 등록 (쓰기 지연)
엔티티 매니저는 트랜잭션을 커밋하기 직전까지 데이터베이스에 엔티티를 저장하지 않고 내부 쿼리 저장소에 INSERT SQL을 차곡차곡 모아둔다. 그리고 트랜 잭션을 커밋할 때 모아둔 쿼리를 데이터베이스에 보내는데 이것을 트랜잭션을 지원하는 쓰기 지연(transactional write-behind)이라 한다.
EntityManager em = emf.createEntityManager();
EntityTransaction transaction = em.getTransaction();
//엔티티 매니저는 데이터 변경 시 트랜잭션을 시작해야 한다.
transaction.begin(); //[트랜잭션]시작
em.persist(memberA);
em.persist(memberB);
//여기까지 INSERT SQL을 데이터베이스에 보내지 않는다.
//커밋하는 순간 데이터베이스에 INSERT SQL을 보낸다.
transaction.commit(); //[트랜잭션] 커밋em.persist(memberA)를 하는 순간 memberA를 영속화 한다. 그리고 동시에 쓰기 지연 SQL 저장소에 INSERT SQL문을 생성하여 저장한다.
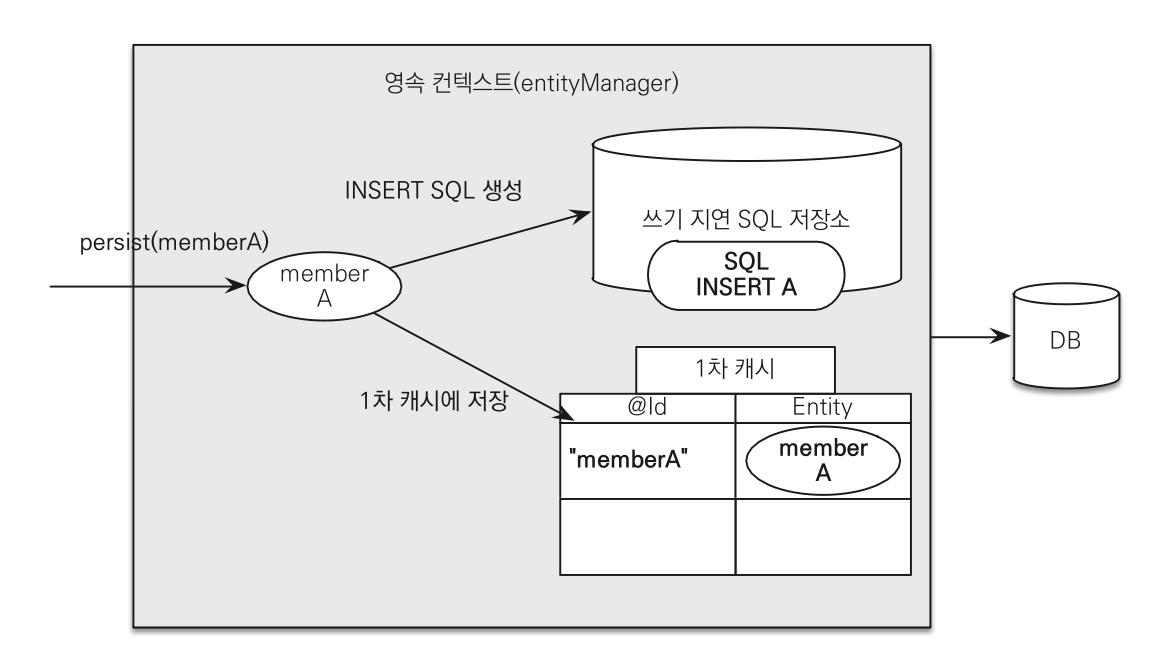
그리고 transaction.commit() 을 한다. 트랜잭션을 커밋하면 엔티티 매니저는 우선 영속성 컨텍스트를 플러시한다. 플러시는 영속성 컨텍스트의 변 경 내용을 데이터베이스에 동기화하는 작업인데 이때 등록, 수정, 삭제한 엔티티를 데이터베이스에 반영한다. 좀 더 구체적으로 이야기하면 쓰기 지연 SQL 저장소에 모인 쿼리를 데이터베이스에 보낸다. 이렇게 영속성 컨텍스트의 변경 내용을 데이터베이스에 동기화한 후에 실제 데이터베이스 트랜잭션을 커밋한다.
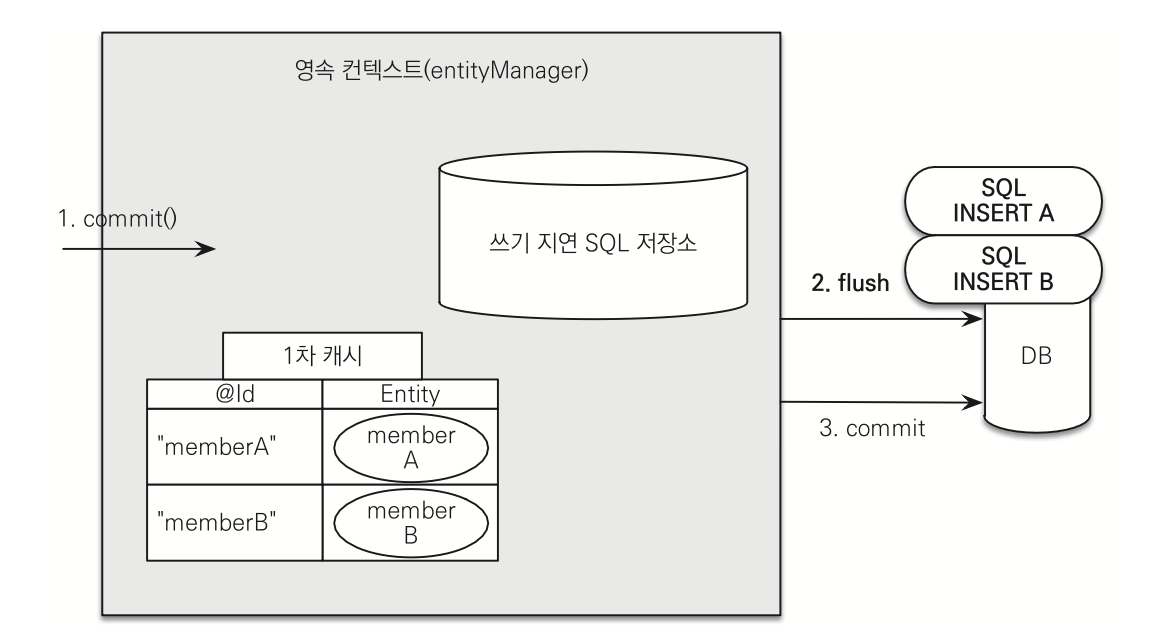
왜 쓰기 지연을 쓰는 걸까? persist 할 때마다 DB 커넥팅을 하면 비용이 많이 발생해서 커넥팅은 한번만 하고 SQL을 쌓아뒀다가 한번에 처리하기 위해서일까?
(3) 엔티티 수정 (변경 감지)
만약 SQL문을 직접 다룬다면 수정이 필요할 때마다 SQL문을 추가로 작성해줘야하는 번거로움이 있고, 어플리케이션의 복잡성을 증가시키는 요소가 된다. 하지만 JPA로 엔티티를 수정할 때는 단순히 엔티티를 조회해서 데이터만 변경하면 된다.
EntityManagerFactory emf = Persistence.
createEntityManagerFactory("jpabook");
EntityManager em = emf.createEntityManager();
EntityTransaction tx = em.getTransaction();
Member memberC = new Member();
memberC.setId("10");
memberC.setName("훈이");
memberC.setAge(20);
tx.begin();
em.persist(memberA);
memberA.setAge(10); // 엔티티 변경
tx.commit(); // 트랜잭션 commit시 변경감지(dirty checking) 시행위와 같이 코드를 실행하고 DB를 조회하면 MEMBER 테이블의 ID 10인 row의 age는 10으로 되어있는것을 알 수 있다.
update 메소드 없이 엔티티의 내용만 바꾸면 된다니, 어떻게 가능한 걸까? 엔티티의 변경사항을 데이터베이스에 자동으로 반영하는 기능을 변경 감지(dirty checking)라 한다. 변경 감지가 작동하는 매커니즘은 다음과 같다.
em.persist(member)를 호출하면 영속성 컨텍스트 1차 캐시에 저장이 되는데, 이때 최초 상태를 복사해서 저장해두는 스냅샷을 함께 저장한다.- 트랙잭션을 커밋
transaction.commit()하는 시점에 내부 스냅샷과 엔티티를 비교하는 플러시 작업을 한다. - 플러시 작업 : 스냅샷과 엔티티를 비교해서 변경된 내용을 찾는다.
- 변경된 내용에 대한 수정 쿼리(UPDATE SQL)문을 쓰기 지연 SQL 저장소에 저장한다.
- 쓰기 지연 SQL 저장소와 DB를 플러쉬하여 비교한다.
- DB에 트랜잭션을 커밋한다.
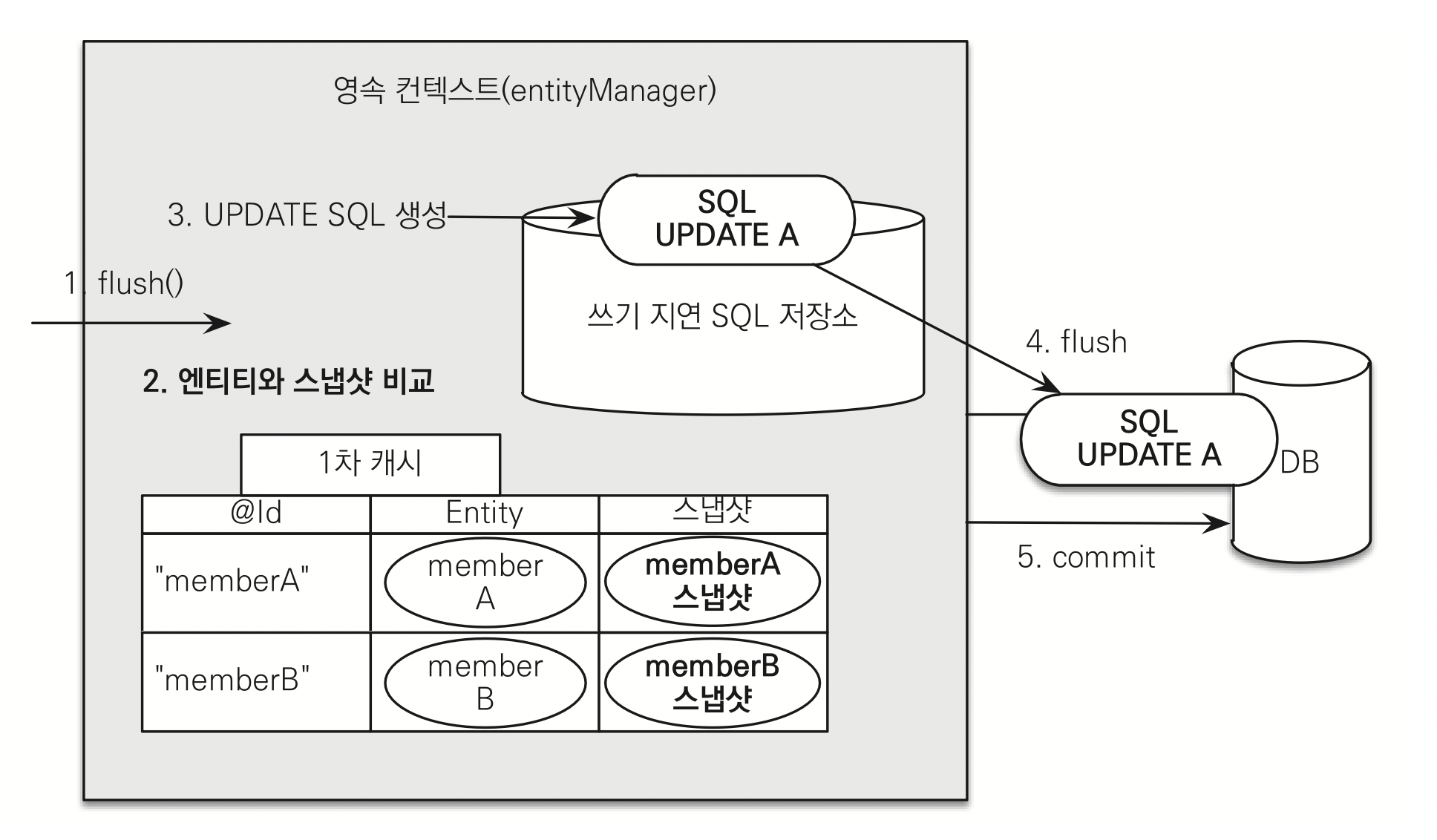
이러한 변경감지는 영속성 컨텍스트가 관리하는 영속 상태인 엔티티에만 적용된다.
이러한 변경감지가 엔티티를 변경할 때마다 일어난다고 착각하기 쉽지만, 다시 한번 강조하자면 트랜잭션을 커밋하는 순간에 변경감지가 일어나 내부적으로 플러시 작업이 일어나는 것이다.
UPDATE SQL
이때 쓰기 지연 SQL 지정소에 생성되는 UPDATE SQL 문이 변경된 내용만 반영하는 SQL문일거라고 생각할 수 있지만 모든 칼럽을 업데이트하는 SQL문이 생성되고, value에 들어가는 인자만이 바뀐 내용을 반영하게끔 되어있다. 이러한 방법을 정적 수정 쿼리라고 한다.
정적 수정 쿼리를 사용하는 이유는 다음과 같다.
-
모든 필드를 사용하면 수정 쿼리가 항상 같기 때문에 애플리케이션 로딩 시점에 수정 쿼리를 미리 생성해두고 재사용할 수 있다. 동적으로 매번 SQL문을 생성하는 것보다 성능상 이점을 얻을 수 있다.
-
데이터베이스에 동일한 쿼리를 보내면 데이터베이스는 이전에 한 번 파싱된 쿼 리를 재사용할 수 있다. DB 단에서도 성능상 이점을 얻을 수 있다.
하지만 매핑된 칼럼이 많은 엔티티라면 모든 칼럼을 업데이트하는 방법은 오히려 성능을 악화시키는 방법일 것이다. 이럴때는 수정된 데이터만 사용해서 동적으로 UPDATE SQL을 생성하는 전략을 선택하면 된다.
// 하이버네이트 확장 기능을 사용해야 한다.
@Entity
@org.hibernate.annotations.DynamicUpdate
@Table(name = "Member") public class Member {...}이렇게 @org.hibernate.annotations.DynamicUpdate 어노테이션을 사용하면 수정된 데이터만 사용해서 동적으로 UPDATE SQL을 생성한다. 참고로 데이터를 저장할 때 데이터가 존재하는(null이 아닌) 필드만으로 INSERT SQL을 동적으로 생성하는 @DynamicInsert도 있다.
(4) 엔티티 삭제
엔티티를 삭제하려면 먼저 삭제 대상 엔티티를 조회해야 한다.
//삭제 대상 엔티티 조회
Member memberA = em.find(Member.class, "memberA");
em.remove(memberA); //엔티티 삭제em.remove()에 삭제 대상 엔티티를 넘겨주면 즉시 엔티티를 삭제하는 것이 아니라 엔티티 등록과 비슷하게 삭제 쿼리를 쓰기 지연 SQL 저장소에 등록한다.이후 트랜잭션을 커밋해서 플러시를 호출하면 실제 데이터베이스에 삭제 쿼리를 전달한다.
반면에 em.remove(memberA)를 호출하는 순간 memberA는 영속성 컨텍스트에서 제거된다. 이렇게 삭제된 엔티티는 재사용하지 말고 자연스럽게 가비지 컬렉션의 대상이 되도록 두는 것이 좋다.
(5) 플러시 (flush)
영속성 컨텍스트의 내용와 DB의 내용을 비교하여 변경 사항을 적용하는 역할을 한다.
플러시의 동작
플러시는 구체적으로 다음과 같이 동작한다.
- 변경 감지가 동작해서 영속성 컨텍스트에 있는 모든 엔티티를 스냅샷과 비교해서 수정된 엔티티를 찾는다. 수정된 엔티티는 수정 쿼리를 만들어 쓰기 지연 SQL 저장소에 등록한다.
- 쓰기지연SQL저장소의쿼리를데이터베이스에전송한다(등록,수정,삭제쿼리).
플러시 시행 방법
영속성 컨텍스트를 플러시하는 방법은 3가지다.
- em.flush()를 직접 호출한다.
- 트랜잭션 커밋 시 플러시가 자동 호출된다.
- JPQL 쿼리 실행 시 플러시가 자동 호출된다.
-
em.flush()
직접 엔티티 매니저를 플러시하는 방법은 트랜잭션을 이용하는 의미를 퇴색히키기 때문에 잘 사용하지 않는다. 테스트나 다른 프레임워크와 JPA를 함께 사용할 때나 사용한다. -
트랜잭션 커밋
가장 일반적인 경우다. 영속성 컨텍스트를 플러시 하지 않고 커밋하게 되면 DB에 어떤 변화도 발생하지 않는다. 이러한 일을 방지하고자 자동으로 트랜잭션 커밋시 플러시가 실행 되도록 하였다. -
JPQL 시행
JPQL이나 Criteria같은 객체지향 쿼리를 호출할 때도 플러시가 실행된다.
왜 플러시가 실행되는 걸까? 이는 JPQL이 DB에 SQL문을 실행시키는 것이기 때문이다. 다음의 예제를 보자.
em.persist(memberA);
em.persist(memberB);
em.persist(memberC);
query = em.createQuery("select m from Member m", Member.class);
List<Member> members= query.getResultList();memberA, memberB, memberC는 영속성 컨텍스트에 있지만 아직 플러시가 되지 않았기 때문에 DB에는 없는 상태이다. 이때 만약 JPQL로 Member 객체를 모두 조회한다면 플러시가 되지 않은 상태이므로 어떠한 반환값도 얻을 수 없을 것이다. 이러한 일을 방지하기 위해 JPQL을 시행하는 순간에 플러시가 되고, 덕분에 JPQL은 의도한 결과값을 얻을 수 있게 된다.
플러시 모드 옵션
어떤 경우에 플러시를 할지 설정할 수 있도록 도와주는 옵션이 있다.
javax.persistence.FlushModeType를 이용하는데, 옵션은 다음의 두 가지이다.
■ FlushModeType.AUTO: 커밋이나 쿼리를 실행할 때 플러시(기본값)
■ FlushModeType.COMMIT: 커밋할 때만 플러시
자바 코드에서 설정한다.
em.setFlushMode(FlushModeType.COMMIT) //플러시 모드 직접 설정플러시 모드를 별도로 설정하지 않으면 AUTO로 동작한다. 따라서 트랜잭션 커 밋이나 쿼리 실행 시에 플러시를 자동으로 호출한다.
(6) 준영속
영속성 컨텍스트가 관리하는 영속 상태의 엔티티가 영속성 컨텍스트에서 분리 된(detached) 것을 준영속 상태라 한다. 따라서 준영속 상태의 엔티티는 영속성 컨텍스트가 제공하는 기능을 사용할 수 없다.
영속된 엔티티를 준영속 상태로 만드는 방법은 세가지이다.
- em.detach(entity): 특정 엔티티만 준영속 상태로 전환한다.
- em.clear(): 영속성 컨텍스트를 완전히 초기화한다.
- em.close(): 영속성 컨텍스트를 종료한다.
엔티티 삭제와의 차이
엔티티 삭제(em.remove()) 와는 차이가 명확하다. 엔티티 삭제는 DELETE SQL문을 지연 쓰기 SQL 저장소에 등록하고 영속성 컨텍스트에서 엔티티를 삭제하는 것이다.
반면 엔티티 비영속화는 해당 엔티티 관련 INSERT, UPDATE SQL문을 지연 쓰기 SQL 저장소에서 삭제하고, 영속성 컨텍스트에서 엔티티를 삭제하는 것이다.
detach()
public void testDetached() {
...
//회원 엔티티 생성, 비영속 상태
Member member = new Member();
member.setId("memberA");
member.setUsername("회원A");
//회원 엔티티 영속 상태
em.persist(member);
//회원 엔티티를 영속성 컨텍스트에서 분리, 준영속 상태
em.detach(member);
transaction.commit(); //트랜잭션 커밋
}엔티티 memberA를 생성한 뒤 영속성하고, 그 다음 준영속 상태로 만들었다.
준영속 상태로 만든 순간 영속성 컨텍스트의 1차 캐시와 지연 쓰기 SQL 저장소에서 엔티티 관련 정보가 삭제된다. 이 경우에는 memberA 관련 INSERT SQL문이 삭제되었을 것이다. 그리고 트랜잭션을 커밋했기 때문에 당연히 DB에는 memberA 엔티티 관련 정보가 입력되지 않는다.
em.clear()
영속성 컨텍스트를 초기화해서 해당 영속성 컨텍스트의 모든 엔티티를 준영속 상태로 만든다. 이것은 영속성 컨텍스트를 제거하고 새로 만든 것과 같다.
em.close()
영속성 컨텍스트 자체를 없애버린다. 관리하고 있던 모든 엔티티를 준영속 상태로 만든다. 이것은 말 그대로 영속성 컨텍스트를 제거하는 것이다.
엔티티가 준영속화 되는 것은 보통 영속성 컨텍스트가 종료됐을 때이다. 개발자가 엔티티 개별로 준영속화하는 일은 드물다.
준영속 상태의 특징
-
거의비영속상태에가깝다
영속성 컨텍스트가 관리하지 않으므로 1차 캐시, 쓰기 지연, 변경 감지, 지연 로 딩을 포함한 영속성 컨텍스트가 제공하는 어떠한 기능도 동작하지 않는다. -
식별자값을가지고있다
비영속 상태는 식별자 값이 없을 수도 있지만 준영속 상태는 이미 한 번 영속 상태였으므로 반드시 식별자 값을 가지고 있다. -
지연로딩을할수없다
지연 로딩은 실제 객체 대신 프록시 객체를 로딩해두고 해당 객 체를 실제 사용할 때 영속성 컨텍스트를 통해 데이터를 불러오는 방법이다. (이 지연로딩 덕분에 JPA로 조회한 엔티티는 객체 탐색 그래프에 단절이 없었다.)
준영속 병합
준영속 상태의 엔티티를 다시 영속 상태로 변경하려면 병합을 사용하면 된다. merge() 메소드는 준영속 상태의 엔티티를 받아서 그 정보로 새로운 영속 상태의 엔티티를 반환한다.
public class ExamMergeMain {
static EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpabook");
public static void main(String args[]) {
Member member = createMember("memberA", "회원1");
member.setUsername("회원명변경");
mergeMember(member);
}
static Member createMember(String id, String username) {
EntityManager em1 = emf.createEntityManager();
EntityTransaction tx1 = em1.getTransaction();
tx1.begin();
Member member = new Member();
member.setId(id);
member.setUsername(username);
em1.persist(member);
tx1.commit();
em1.close(); //영속성 컨텍스트1 종료,
return member;
}
static void mergeMember(Member member) {
EntityManager em2 = emf.createEntityManager();
EntityTransaction tx2 = em2.getTransaction();
tx2.begin();
Member mergeMember = em2.merge(member);
tx2.commit();
System.out.println("member = " + member.getUsername());
System.out.println("mergeMember = " + mergeMember.getUsername());
System.out.println("em2 contains member = " + em2.contains(member));
System.out.println("em2 contains mergeMember = " + em2.contains(mergeMember));
System.out.println("mergeMember.equals(member) = " + mergeMember.equals(member));
em2.close();
}
}위의 예제 코드를 mian문 위주로 살펴보자.
-
Member member = createMember("memberA", "회원1")
하단에 정의된 createMember 함수에 의해 member 참조 변수는 준영속 상태가 된 엔티티 객체를 참조하게 된다. 이때 준영속 상태가 된 엔티티의 내용은 DB에 이미 저장한 상태이다. -
member.setUsername("회원명변경")
member 변수의 Username을 '회원1'에서 '회원명변경'으로 변경한다. member 변수는 준영속 상태이므로 DB에 어떠한 영향고 끼치지 못한다. -
mergeMember(member)
en.merge(member) 로 mergeMember 변수를 만든다. 이때 진행되는 매커니즘은 아래와 같다. 그 결과 mergeMember 엔티티가 갖는 정보는 member 엔티티와 동일해진다. 하지만 엔티티 매니저는 member 변수를 알지 못한다고 하기 때문에, merge에 사용된 엔티티와 반환된 엔티티는 서로 다른 인스턴스가 된다.
merge 매커니즘
(1) merge(member)가 실행된다.
(2) merge에 사용된 엔티티가 1차 캐시에 있는지 조회한다.
(3) 우리는 member 변수를 준영속 상태로 만들었기 때문에 1차 캐시에 member 엔티티는 존재하지 않는다. 따라서 DB에서 조회한다.
(4) DB에서 조회된 엔티티 정보를 mergeMember 라는 이름으로 1차 캐시에 저장한다.
(5) 인자로 들어온 member의 정보로 mergeMember 엔티티의 정보를 변경한다.
(6) mergeMember 변수는 mergeMember 엔티티를 참조하게 된다.
비영속 병합
tx.begin();
Member memberI = new Member(); // 비영속 엔티티 member
Member newMember = em.merge(memberI); // 비영속 병합
tx.commit();병합은 비영속 엔티티도 할 수 있는데, 병합을 하기 위해서는 엔티티의 식별자값을 기준으로 1차 캐시에서 조회, 없으면 DB에서 조회, DB에서도 없으면 새로운 엔티티를 생성해서 병합하기 때문이다.
정확히 모르는 개념
J2SE 와 J2EE
J2SE
자바 스탠다드 에디션은 가장 보편적으로 쓰이는 자바 API집합체다. 예전에는 J2SE로 불렸으나 버전 6.0이후에 Java SE로 변경되었다. 이전에는 썬마이크로시스템즈에서 관리했으나 지금은 JCP주도하에 개발되고 있다. 일반 자바 프로그램 개발을 위한 용도로 사용되며 스윙이나 AWT와 같은 GUI방식의 기본 기능이 포함된다.
J2EE
자바 엔터프라이즈 에디션은 자바를 이용한 서버측 개발을 위한 플랫폼이다. Java EE는 표준 플랫폼인 Java SE를 사용하는 서버를 위한 플랫폼이다. 전사적 차원(대규모의 동시 접속과 유지가 가능한 다양한 시스템의 연동 네트워크 기반 총칭)에서 필요로 하는 도구로 EJB, JSP, Servlet, JNDI 같은 기능을 지원하며 WAS(Web Application Server)를 이용한 프로그램 개발 시 사용된다.
출처
티끌모아 로키산맥 🏔
데이터베이스 트랜잭션
트랜잭션(Transaction)은 데이터베이스의 상태를 변환시키는 하나의 논리적 기능을 수행하기 위한 작업의 단위 또는 한꺼번에 모두 수행되어야 할 일련의 연산들을 의미한다.
트랜잭션의 특징
- 트랜잭션은 데이터베이스 시스템에서 병행 제어 및 회복 작업 시 처리되는 작업의 논리적 단위이다.
- 사용자가 시스템에 대한 서비스 요구 시 시스템이 응답하기 위한 상태 변환 과정의 작업단위이다.
- 하나의 트랜잭션은 Commit되거나 Rollback된다.
트랜잭션의 성질
-
Atomicity(원자성)
트랜잭션의 연산은 데이터베이스에 모두 반영되든지 아니면 전혀 반영되지 않아야 한다.
트랜잭션 내의 모든 명령은 반드시 완벽히 수행되어야 하며, 모두가 완벽히 수행되지 않고 어느하나라도 오류가 발생하면 트랜잭션 전부가 취소되어야 한다. -
Consistency(일관성)
트랜잭션이 그 실행을 성공적으로 완료하면 언제나 일관성 있는 데이터베이스 상태로 변환한다.
시스템이 가지고 있는 고정요소는 트랜잭션 수행 전과 트랜잭션 수행 완료 후의 상태가 같아야 한다. -
Isolation(독립성,격리성)
둘 이상의 트랜잭션이 동시에 병행 실행되는 경우 어느 하나의 트랜잭션 실행중에 다른 트랜잭션의 연산이 끼어들 수 없다.
수행중인 트랜잭션은 완전히 완료될 때까지 다른 트랜잭션에서 수행 결과를 참조할 수 없다. -
Durablility(영속성,지속성)
성공적으로 완료된 트랜잭션의 결과는 시스템이 고장나더라도 영구적으로 반영되어야 한다.
트랜잭션 연산
-
Commit연산
Commit 연산은 한개의 논리적 단위(트랜잭션)에 대한 작업이 성공적으로 끝났고 데이터베이스가 다시 일관된 상태에 있을 때, 이 트랜잭션이 행한 갱신 연산이 완료된 것을 트랜잭션 관리자에게 알려주는 연산이다. -
Rollback연산
Rollback 연산은 하나의 트랜잭션 처리가 비정상적으로 종료되어 데이터베이스의 일관성을 깨뜨렸을 때, 이 트랜잭션의 일부가 정상적으로 처리되었더라도 트랜잭션의 원자성을 구현하기 위해 이 트랜잭션이 행한 모든 연산을 취소(Undo)하는 연산이다. Rollback시에는 해당 트랜잭션을 재시작하거나 폐기한다.
