정렬 알고리즘을 선택할 때 고려할 사항
- 정렬할 데이터의 양
- 데이터와 메모리
- 이미 정렬된 정도
- 필요한 추가 메모리의 양
- 상대위치 보존여부(안정성) 등
⚙️ 내부 정렬 (Internal Sort)
- 정렬하고자 하는 자료를 주 메모리(주기억 장치)에 모두 가져다 놓고 정렬하는 방식
- 자료의 양이 적을 때 사용
- 속도가 빠름
- PASS 1 = 첫 정렬이 끝난 상태
1. 삽입정렬 (Insertion Sort)
평균 수행 시간복잡도 : O(N^2) == n(n-1)/2
최상 수행 시간 : O(N)
- 삽입 정렬은 가장 간단한 정렬 방식으로 이미 순서화된 파일에 새로운 하나의 레코드를 순서에 맞게 삽입시켜 정렬한다.
- 데이터 집합을 순회하면서 정렬이 필요한 요소를 뽑아내어 이를 다시 적당한 곳에 삽입하는 알고리즘
- 성능은 버블 정렬보다 좋다.
정렬 진행 과정
-
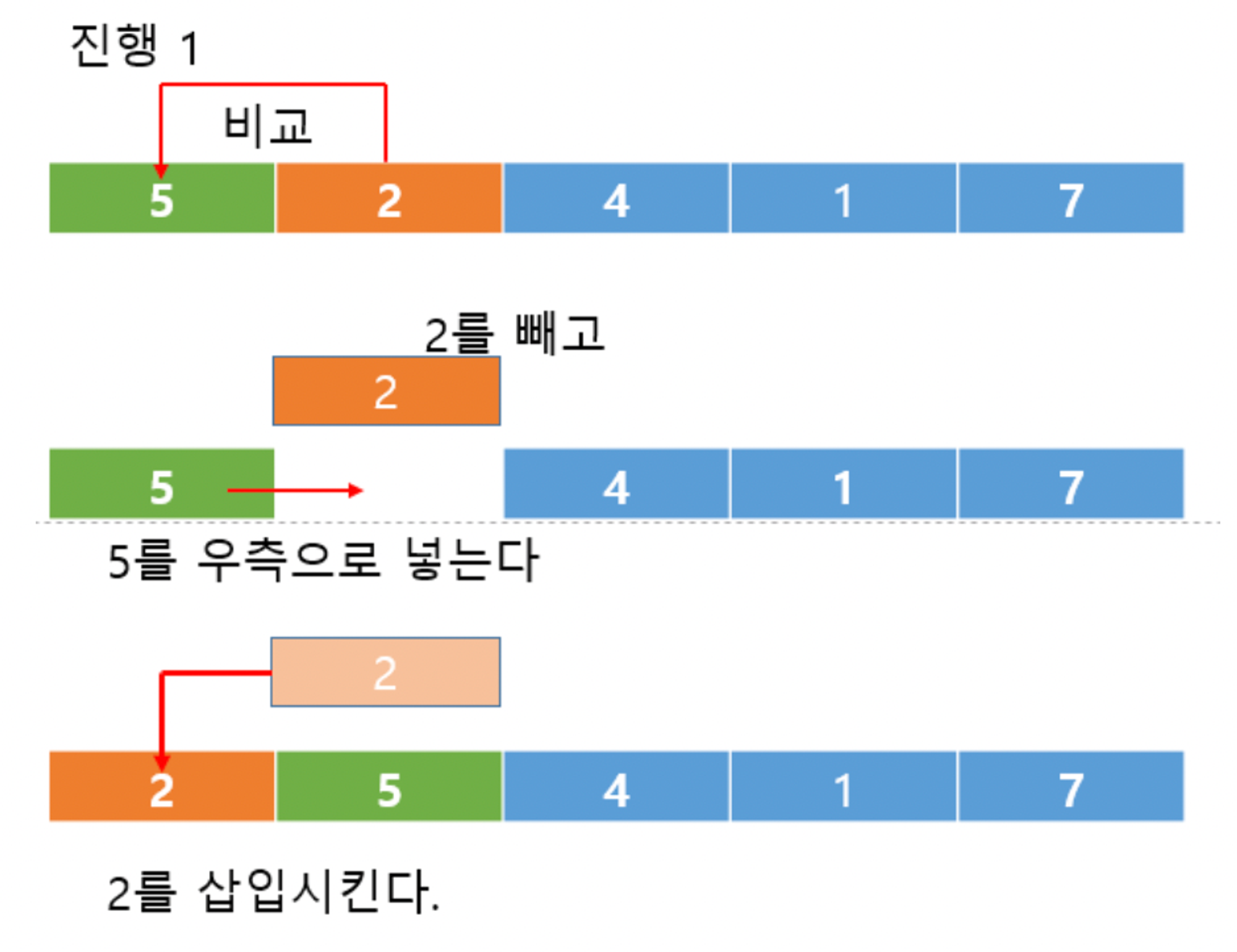
pass 1 : 두 번째 값(2)을 첫 번째 값(5)과 비교해서 더 작으면 첫번째 자리에 삽입하고, 첫 번째 값을 뒤로 한 칸 이동시킨다.
-
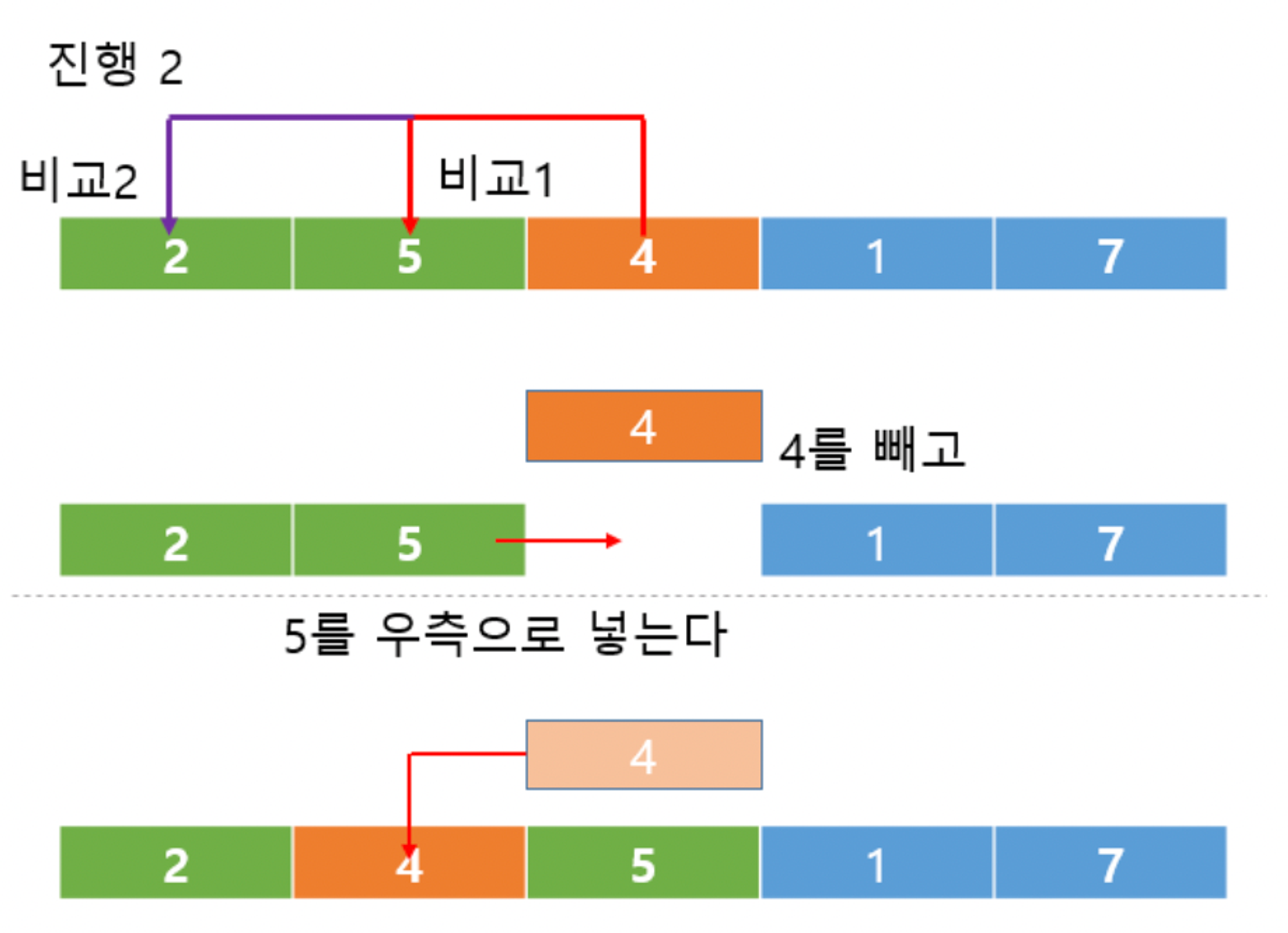
pass 2 : 세 번째 값(4)을 5와과 비교해서 더 작으면 두 번째 자리에 삽입하고, 5를 뒤로 한 칸 이동시킨다. 2와 비교해서 더 크기 때문에 두 번째 자리에 둔다.
-
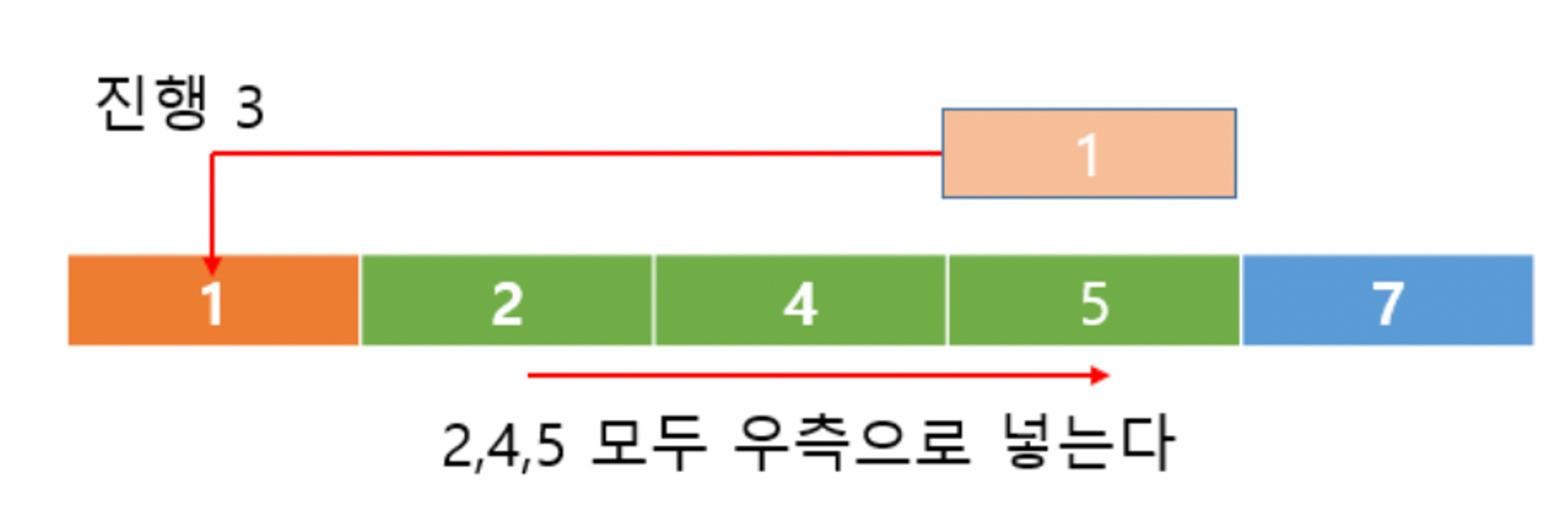
pass 3 : 네 번째 값(1)을 2, 4, 5와 비교한다. 1이 제일 작기 때문에 첫 번째로 이동한다.
-
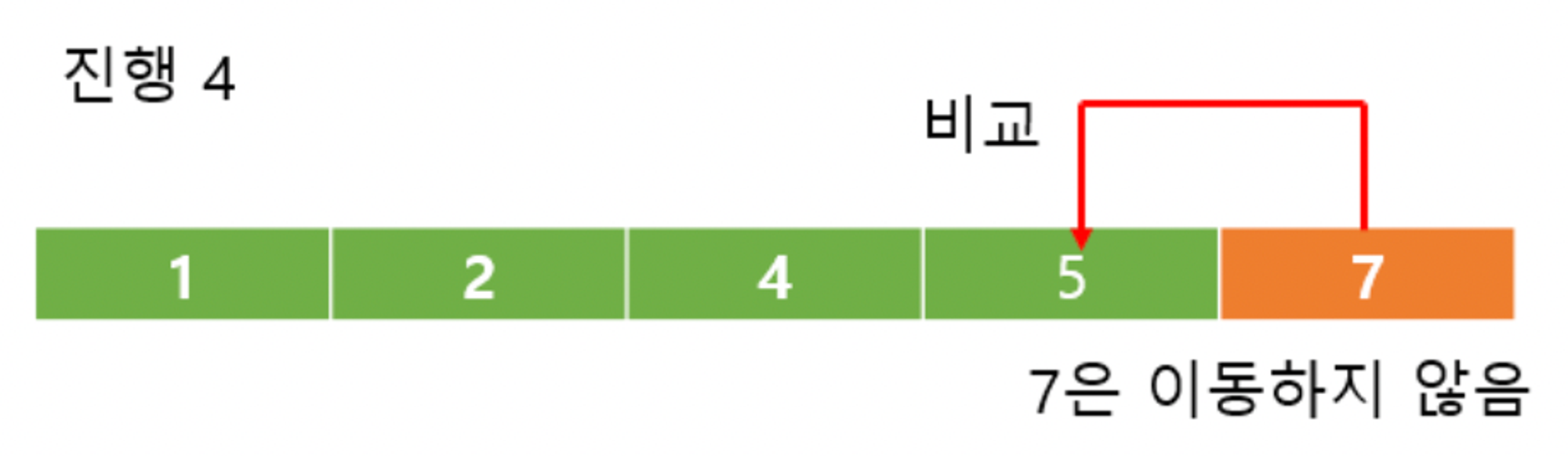
pass 4 : 마지막 값(7)이 5보다 크기 때문에 앞 인덱스가 모두 정렬 되었다고 가정하고 더 이상 비교를 진행하지 않는다.
-
예시 코드 :

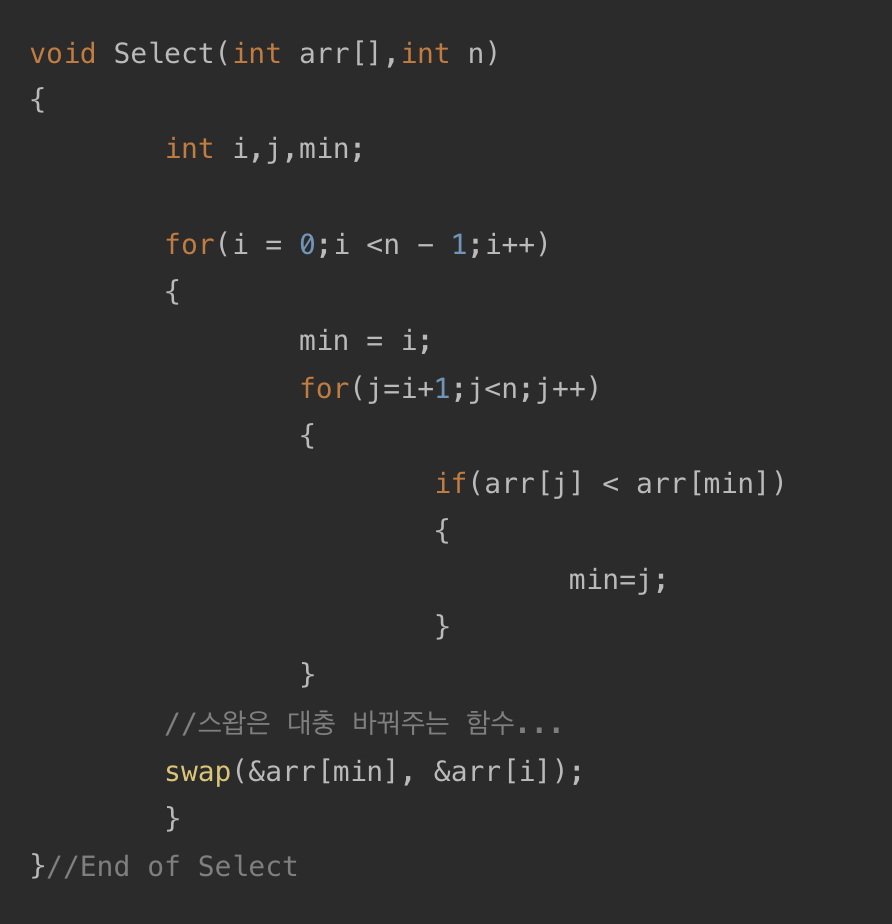
2. 선택 정렬 (Selection Sort)
평균 수행 시간복잡도 : O(N^2)
- 선택 정렬은 n개의 레코드 중에서 최소값을 찾아 첫 번째 레코드 위치에 놓고, 나머지 (n-1)개 중에서 다시 최소값을 찾아 두 번째 레코드 위치에 놓는 방식을 반복하여 정렬하는 방식이다.
정렬 진행 과정
-
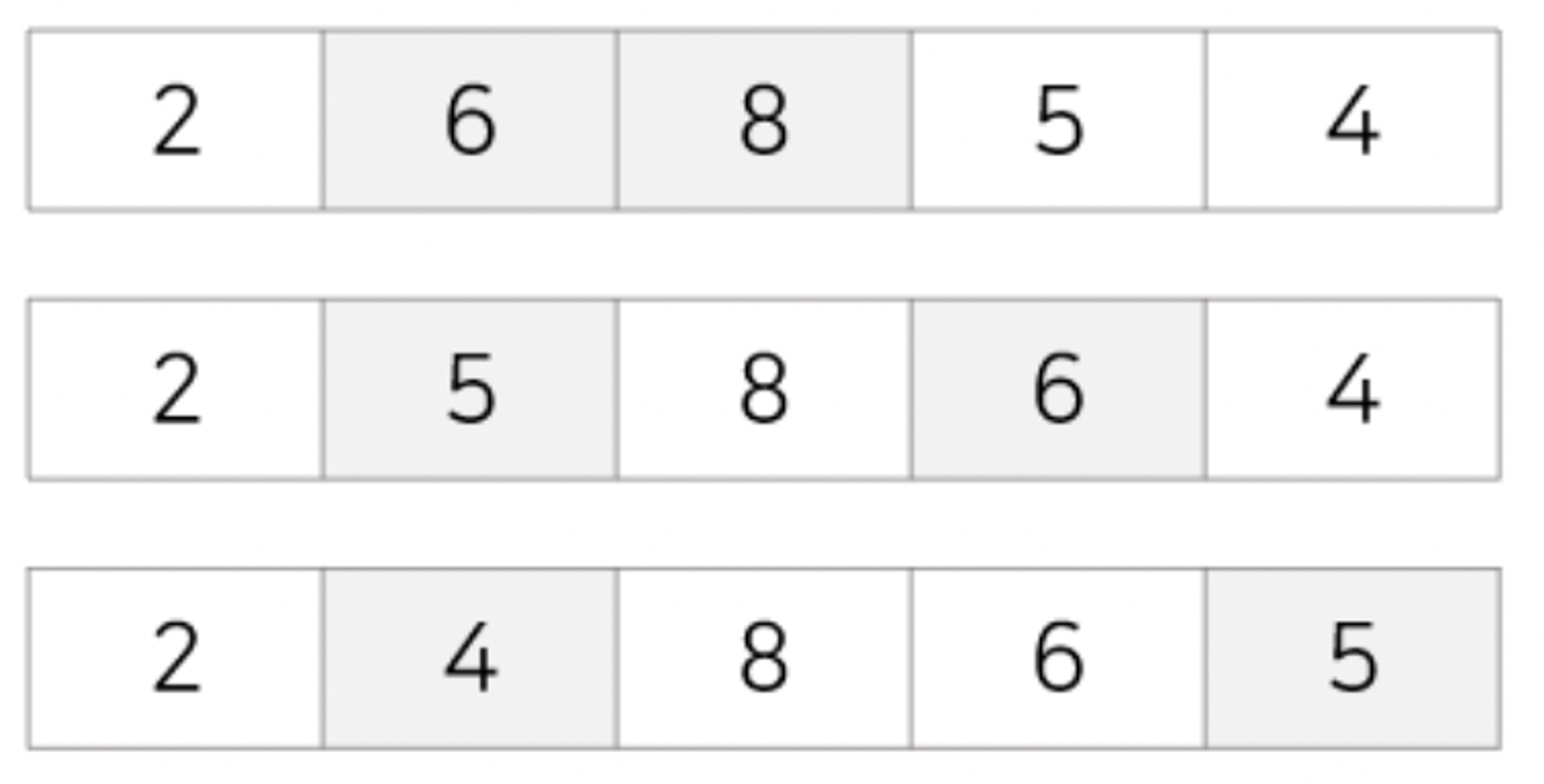
pass 1 (1회전) : 첫번째 값 8을 두번째 값 5과 비교해 교환, 첫번째 값 5를 세번째 값 6과 비교해 교환X, 첫번째 값 5를 네번째 값 2와 비교해 교환, 첫번째 값 2를 다섯번째 값 4와 비교해 교환X
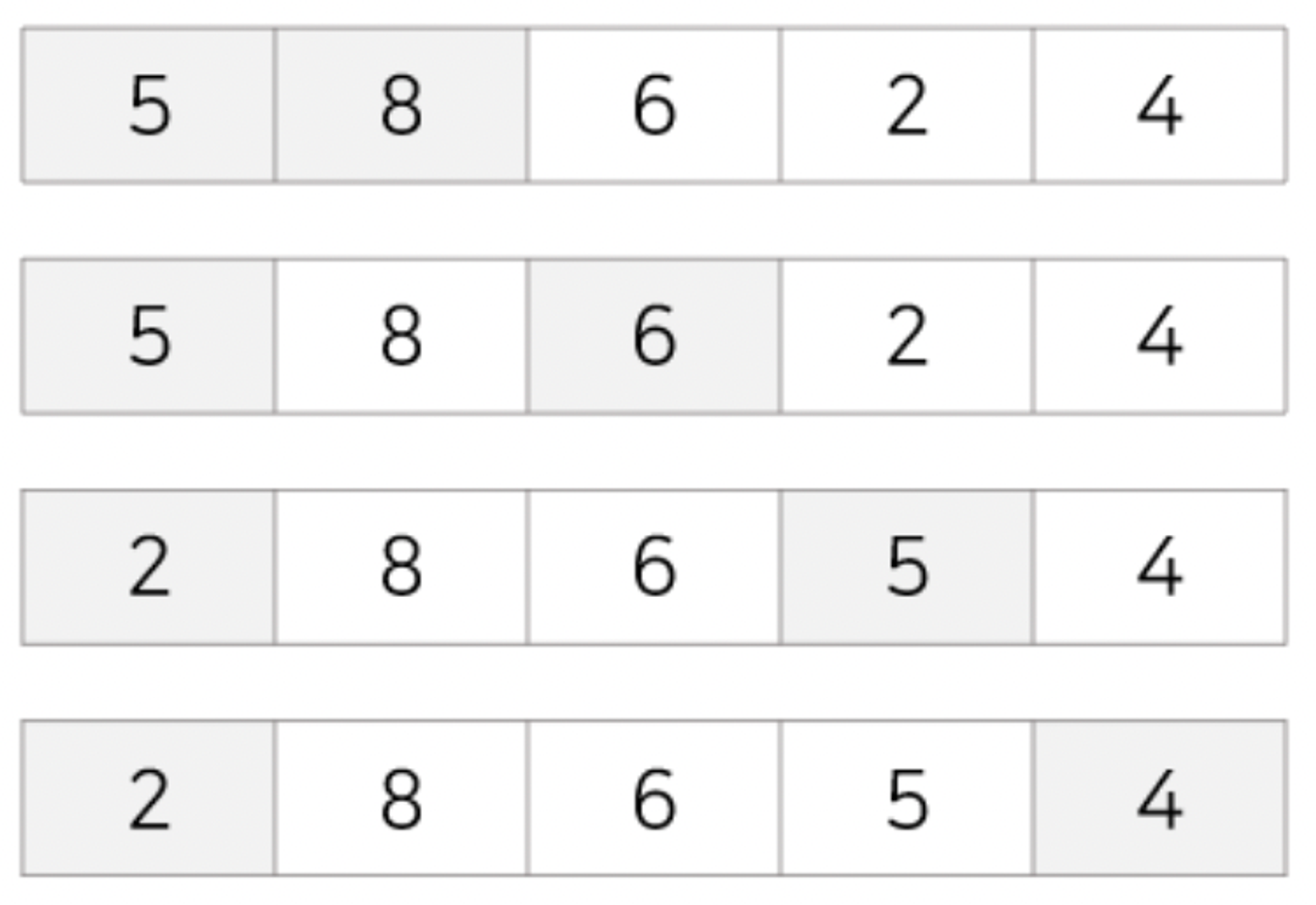
-
pass 2 : 두번째 값 8을 세번째 값 6과 비교해 교환, 두번째 값 6을 네번째 값 5와 비교해 교환, 두번째 값 5를 다섯번째 값 4와 비교해 교환
-
pass 3 : 세번째 값 8을 네번째 값 6과 비교해 교환, 세번째 값 6을 다섯번째 값 5와 비교해 교환
-
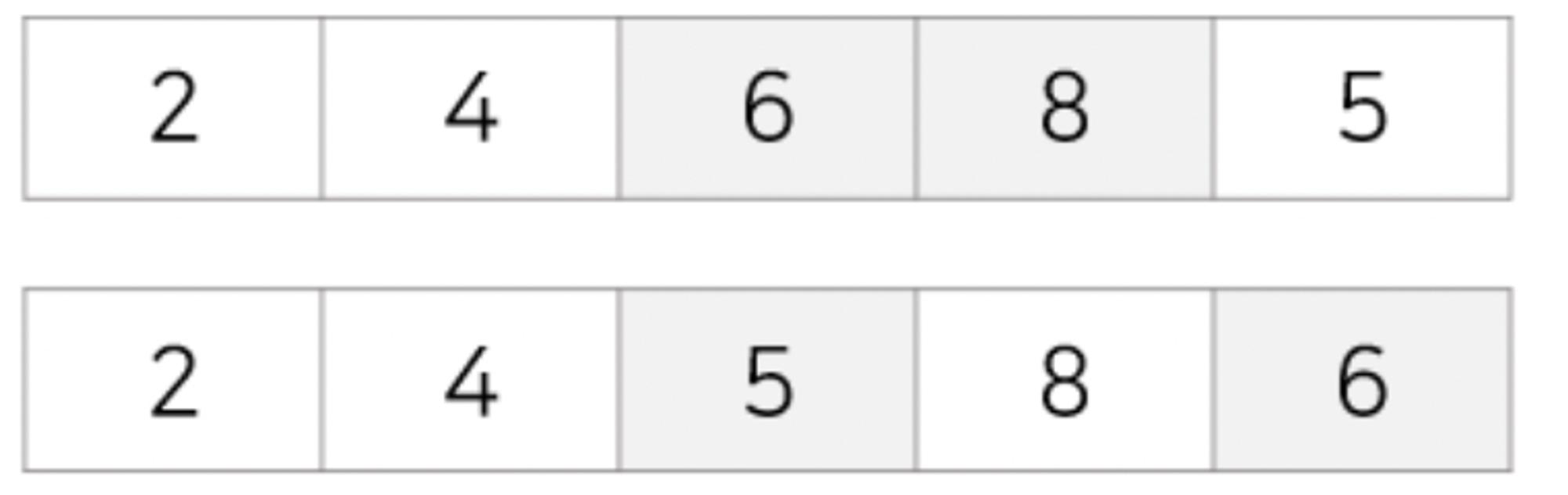
pass 4 : 네번째 값 8을 다섯번째 값 6과 비교해 교환

-
예시 코드 :
3. 버블 정렬 (Bubble Sort)
평균 수행 시간복잡도 : O(N^2)
- 첫 위치부터 시작해서 오른쪽 값과 비교한다.
- 인접한 두 수를 비교하여 오름차순 or 내림차순 정렬
- 안정성은 보장된다.
정렬 진행 과정
9, 6, 7, 3, 5를 오름차순으로 정렬할 경우
-
PASS 1 :
9, 6 비교하고 정렬 6, 9, 7, 3, 5
→ 9, 7 비교하고 정렬 6, 7, 9, 3, 5 ….
→ 마지막 정렬하면 6, 7, 3, 5, 9 -
예시 코드 :

4. 힙 정렬 (Heap Sort)
평균, 최악 수행 시간복잡도 : O(nlog2n)
- 정렬할 입력 레코드들로 힙을 구성하고 가장 큰 키 값을 갖는 루트 노드를 제거하는 과정을 반복하여 정렬하는 기법
- 완전이진트리(complete binary tree)여야 한다.
- 트리 기반으로 최소 힙 트리 또는 최대 힙 트리를 구성해 정렬하는 방법
- 최소 힙 : 부모 노드의 키값이 자식 노드의 키값보다 항상 작은 힙 (오름차순 정렬을 위함)
- 최대 힙 : 부모 노드의 키값이 자식 노드의 키값보다 항상 큰 힙 (내림차순 정렬을 위함)
- 안정성이 보장되지 않는다.
5. 2-WAY 합병 정렬(Merge Sort)
평균, 최악 수행 시간복잡도 : O(nlog2n)
- 이미 정렬되어 있는 두 개의 파일을 한 개의 파일로 합병하는 정렬 방식
- 둘 이상의 부분집합으로 가르고, 각 부분집합을 정렬한 다음 부분집합들을 다시 정렬된 형태로 합치는 방식
- 안정성은 보장된다.
- 다른 정렬 알고리즘과 달리 데이터 집합이 메모리에 한 번에 올리기 너무 클 때 사용하기 좋은 방법이다. 따라서 O(n) 수준의 메모리가 추가로 필요하다는 단점이 있다.
6. 퀵 정렬 (Quick Sort)
평균 수행 시간복잡도 : O(nlog2n)
최악 수행 시간 : O(n^2)
- 데이터 집합 내에 임의의 기준(pivot)값을 정하고 해당 피벗과 집합을 기준으로 두 개의 부분 집한으로 나눈다.
- 한 쪽 부분에는 피버값보다 작은 값만, 다른 한 쪽에는 큰 값들만 넣는다.
- 더 이상 쪼갤 부분집합이 없을 때까지 각각의 부분 집합에 대해 피벗/쪼개기를 재귀적으로 적용한다.
- 안정성이 보장되지 않는다.
7. 쉘 정렬 (Shell Sort)
⚙️ 외부 정렬 (External Sort)
- 정렬하고자 하는 자료를 보조 기억 장치에 두고 일부분만 주기억 장치로 가져가 병합하여 정렬하는 방식
- 자료의 양이 많을 때 사용
