<논문 리뷰> Unbiased Recommender Learning from Missing-Not-At-Random Implicit Feedback (WSDM 2020)
논문 리뷰
Positive-Unlabeled 문제와 기존 연구의 한계
Positive-Unlabeled 문제는 클릭되지 않은 데이터가 "Negative"인지 "Unlabeled"인지 명확히 구분할 수 없는 문제를 말합니다.
이전 연구들은 이 문제를 해결하기 위해 다음과 같은 방법을 사용하였습니다:
- 클릭된 데이터(Positive)에 더 큰 가중치를 부여함으로써 클릭되지 않은 데이터(Unlabeled)로 인해 발생하는 왜곡을 줄입니다.
- EM 알고리즘을 사용하여 데이터가 클릭될 확률을 추정하고, 긍정적 피드백의 신뢰도를 높이는 방법을 적용합니다.
하지만:
- 클릭 데이터를 균일하게 강조하더라도, 클릭 여부는 노출 확률과 연관되기 때문에 인기 아이템이 과대평가되는 경향이 지속됩니다.
- EM 알고리즘은 노출 확률에 관계 없이 데이터를 모두 균일하게 처리하는 경향으로 인해 MNAR 문제를 완전히 해결하지 못합니다.
결론적으로, 노출 확률과 관련성(Relevance)을 독립적으로 추정할 수 있는 새로운 방식이 필요합니다.
ABSTRACT
이 논문은 추천 시스템에서 발생하는 Missing-Not-At-Random(MNAR) 문제를 해결하기 위해 편향 없는 추정기(unbiased estimator)를 제안합니다.
기존 방법들이 인기 아이템에 치우쳐 드문 아이템을 과소 평가하는 한계를 극복하기 위해, 이상적 손실 함수(ideal loss function)를 정의하고 이를 최적화하는 새로운 추정기를 설계했습니다.
특히, Inverse Propensity Score (IPS) 기법을 확장해 높은 분산 문제를 해결하는 클리핑(clipping) 기법을 추가로 도입하였습니다.
실험 결과:
- 제안된 모델은 드문 아이템에서의 성능을 크게 개선하였으며, 기존 모델(WMF, ExpoMF)을 전반적으로 능가하는 성능을 보였습니다.
- 이 논문은 추천 시스템의 공정성과 정확성을 동시에 개선할 수 있는 가능성을 제시합니다.
Keywords
-
Implicit Feedback
사용자의 명시적 평가 대신 행동 데이터(예: 클릭, 조회)를 기반으로 학습하는 피드백 유형 -
Missing-Not-At-Random (MNAR)
데이터가 무작위로 누락되지 않았음을 나타내며, 인기 아이템이 과대평가되고 드문 아이템이 과소평가되는 문제 -
Inverse Propensity Weighting (IPS)
데이터의 노출 확률(Propensity)을 역으로 가중하여 편향을 제거하는 방법 -
Positive-Unlabeled Learning
긍정적 피드백과 비라벨 데이터를 기반으로 학습하는 방법론 -
Matrix Factorization
협업 필터링에서 자주 사용되는 기법으로, 사용자와 아이템 간의 잠재 요인을 학습하는 데 사용
1. Introduction
사용자가 관심을 가질만한 아이템을 예측하여 사용자 경험을 개선하기 위해 추천 시스템을 활용합니다.
사용자가 진정으로 관심을 가지는 아이템을 추천할 수 있기 위해서는, 아이템과의 관련성(Relevance)을 잘 판단해야 합니다.
관련성을 예측하기 위한 기존 방법:
-
가중치 행렬 분해(Weighted Matrix Factorization, WMF):
클릭되지 않은 아이템에 더 낮은 가중치를 부여하여, 클릭되지 않은 아이템이 클릭된 아이템에 비해 예측의 신뢰도가 낮음을 반영. -
노출 행렬 분해(Exposure Matrix Factorization, ExpoMF):
클릭의 확률을 노출 확률과 관련성 수준의 확률의 곱으로 나타내어, 노출 확률이 높은 데이터의 손실에 더 높은 가중치를 부여.
그러나, 이러한 방법들은 MNAR(Missing-Not-At-Random) 문제를 해결하지 못합니다.
본 연구의 목표와 접근 방법:
-
이상적 손실 함수(ideal loss function)의 정의:
- 관련성을 극대화하기 위해 최적화할 수 있는 손실 함수를 설계.
- 기존 방법(WMF, ExpoMF)이 이상적 손실 함수에 대해 편향을 가지고 있음을 이론적으로 증명.
-
편향 없는 추정기(unbiased estimator)의 제안:
- 인과 추론(causal inference) 기법에서 영감을 받아 Positive-Unlabeled 문제와 MNAR 문제를 동시에 해결.
- 관찰 가능한 피드백만으로 이상적 손실을 추정.
-
분산 감소와 클리핑(clipping):
- 편향 없는 추정기의 분산(variance)을 분석하고, 편향-분산 균형(bias-variance trade-off)을 개선.
- 클리핑 기법을 추가로 도입하여 이론적 특성을 조사.
-
실험적 검증:
- 반합성 데이터(semi-synthetic data)와 실제 데이터(real-world data)를 사용한 실험을 통해 제안된 방법의 효과를 검증.
연구의 기여점:
- 관련성을 극대화하기 위한 최적화된 이상적 손실 함수를 정의하고, 이에 대한 편향 없는 추정기를 제안.
- 추천 환경에서 추정기의 분산이 클 수 있음을 지적하고, 이를 해결하기 위해 분산 감소 추정기(variance reduction estimator)를 사용.
- 반합성 데이터와 실제 데이터를 사용하여 실험을 수행:
- 순위 측정(ranking metrics)을 크게 향상.
- 드문 아이템의 성능을 개선.
2. NOTATION AND PROBLEM FORMULATION
2.1 Notation
Notation
- : 사용자
- : 사용자 수
- : 아이템
- : 아이템 수
- : 사용자-아이템 쌍의 집합
- : 클릭 행렬(click matrix), 각 항목 는 클릭 여부
- : 클릭된 경우
- : 클릭되지 않은 경우 (부정적 피드백 or 라벨이 없는 긍정적 피드백)
추가 행렬 정의
-
관련성 행렬 (Relevance Matrix):
- : 각 항목 는 사용자 와 아이템 간의 관련성(relevance)을 나타내는 베르누이 확률 변수
- : 와 가 관련이 있음을 의미
- : 와 가 관련이 없음을 의미
- : 각 항목 는 사용자 와 아이템 간의 관련성(relevance)을 나타내는 베르누이 확률 변수
-
노출 행렬 (Exposure Matrix):
- : 각 항목 는 사용자 가 아이템 에 노출되었는지를 나타내는 확률 변수
- : 가 에게 노출됨을 의미
- : 가 에게 노출되지 않음을 의미
- : 각 항목 는 사용자 가 아이템 에 노출되었는지를 나타내는 확률 변수
확률 모델 정의
- : 노출 확률 (Exposure Parameter)
- : 관련성 확률 (Relevance Parameter)
식 (1) : 클릭 조건
- 식 (1)은 아이템 가 사용자 에 의해 클릭되려면, 가 에게 노출되었고 , 동시에 관련성이 있어야 함을 나타냅니다.
- 이 식은 암묵적 피드백에서 클릭이 반드시 관련성을 의미하지는 않는다는 점을 명확히 나타냅니다.
- Unbiased Learning-to-Rank의 위치 기반 모델과 동일한 가정(클릭 데이터가 단순히 아이템과 사용자의 관련성만을 반영하는 것이 아니라 노출 위치의 영향을 받는다)을 따릅니다.
식 (2) : 클릭 확률
- 식 (2)는 클릭 확률을 노출 확률 와 관련성 수준 로 분해하는 가정을 나타냅니다.
- 이 가정을 통해:
- 사용자-아이템 쌍마다 다른 노출 확률 값을 가질 수 있음을 반영합니다.
- 클릭 확률과 관련성 수준이 비례하지 않을 수 있는 MNAR (Missing-Not-At-Random) 환경을 모델링할 수 있습니다.
2.2 True Performance Metric
기존 메트릭의 한계
클릭 기반 메트릭의 정의:
-
: 순위 기반 가중치 (예: DCG, NDCG 등에서 사용되는 가중치)
-
: 추천 시스템이 예측한 순위
문제점:
- MNAR 문제
- 노출 빈도에 의한 편향 : 인기 아이템이 과대평가되고, 드문 아이템은 과소평가되는 문제가 발생합니다.
True Performance Metric 의 정의
관련성 기반 메트릭:
-
클릭 확률에서 노출 확률의 영향을 제거하고 오직 사용자와 아이템 간의 관련성 확률만 사용
-
기존의 클릭 데이터를 사용하는 메트릭이 노출 편향(MNAR 문제)에 영향을 받는 것과는 대조적으로, 더 공정하고 이상적인 성능 평가를 가능하게 합니다.
장점:
- 클릭 데이터의 편향 제거: 노출 확률 의 영향을 배제하고, 사용자와 아이템 간의 실제 관련성만으로 평가합니다.
이상적 손실 함수 (Ideal Loss Function)
True Performance Metric을 최적화하기 위해, 이상적 손실 함수가 정의됩니다 :
- : 관련성이 있는 경우의 손실(예: 로지스틱 손실)
- : 관련성이 없는 경우의 손실
의미:
- 관련성 확률 를 기반으로 한 최적화로, 사용자 경험을 더 잘 반영하는 모델 설계가 가능
- 모델이 관련성이 잘 예측하면 가 작아지고, 손실이 감소
- 모델이 비관련성을 잘 예측하면 가 작아지고, 손실이 감소
- 기존의 WMF, ExpoMF와 같은 메트릭이 이상적 손실에 대해 편향되어 있음을 이론적으로 증명
결론
이상적 손실을 최소화하는 예측 행렬 은 Top_N 추천 메트릭에서 원하는 값을 도출할 것으로 기대된다.
3. ANALYSIS ON EXISTING BASELINES
이 섹션에서는 기존의 기준선 모델들을 설명하고, 이 모델들에서 사용된 손실 함수에 대해 이론적으로 분석합니다. 특히, 이 손실 함수들이 이상적 손실(ideal loss)에 대해 편향(bias)을 가지고 있음을 증명합니다.
3.1 Weighted Matrix Factorization
WMF 모델의 손실 함수
- : 클릭된 데이터(positive feedback)에 더 높은 가중치를 부여하는 하이퍼파라미터.
WMF 모델의 편향
이상적 손실 함수 와 WMF 손실 함수의 차이를 편향으로 정의:
이를 계산하면 WMF의 편향이 다음과 같이 나타납니다:
(증명과정 생략)
편향 분석
WMF가 이상적 손실과 편향을 가지는 이유는 다음과 같습니다.
-
노출 확률()에 의존:
- 클릭 확률 에서 노출 확률 의 영향을 제거하지 못해, 인기 있는 아이템이 과대평가됩니다.
-
가중치 의 영향:
- 와 같은 항이 포함되어 있어, 인 경우 편향이 발생합니다.
-
MNAR 문제
한계
따라서, 이상적 손실을 정확히 최적화하려면 WMF 모델의 한계를 극복할 수 있는 편향 없는 추정기(Unbiased Estimator)가 필요합니다.
3.2 Exposure Matrix Factorization
모델 구조
1. 잠재 요인(Latent Factors)
- 사용자 잠재 벡터:
- 아이템 잠재 벡터:
- 사용자 와 아이템 는 각각 와 라는 잠재 벡터로 표현됩니다.
2. 확률적 모델링
노출 확률 모델:
- 여기서 는 시그모이드 함수입니다.
- 는 사용자 가 아이템 를 본 여부를 나타내는 베르누이 변수.
클릭 확률 모델:
- 는 노출된 경우에만 클릭 확률을 계산합니다.
3. The log-likelihood to derive the parameters
- 첫 번째 항: 노출 데이터 를 설명하는 로그 우도
- 두 번째 항: 클릭 데이터 를 설명하는 로그 우도
ExpoMF 모델의 손실 함수
- 로그 가능도 함수에서 와 의 상태에 따라 손실이 계산됩니다.
- 이를 구체적으로 나타내기 위해 (a)를 정의하여 상황별 가중치를 설정합니다.
따라서, 손실함수는 다음과 같이 정의됩니다.
- : Posterior Exposure Probability, 즉 클릭 데이터 가 주어졌을 때의 노출 확률.
ExpoMF 모델의 편향
이상적 손실 함수 와 ExpoMF 손실 함수의 차이를 편향으로 정의:
편향 분석
ExpoMF가 이상적 손실 함수와 편향을 가지는 주요 원인은 다음과 같습니다:
-
노출 확률의 추정치() 오차:
- 는 노출 확률을 클릭 데이터 를 기반으로 추정하지만, 모든 사용자-아이템 쌍에 대해 동일한 값이 아니므로 편향이 발생합니다.
-
로컬 손실 강조:
- ExpoMF는 노출 확률이 높은 데이터에 더 큰 가중치를 부여하기 때문에, 노출 확률이 낮은 드문 아이템(Tail Items)의 예측 성능이 저하됩니다.
3. ExpoMF와 이상적 손실 함수의 차이
ExpoMF의 손실 함수는 로그 우도 기반으로 모델을 학습하지만, 이상적 손실 함수는 사용자와 아이템 간의 실제 관련성을 최대화하려는 목표를 가지고 있습니다. 이러한 차이는 다음과 같은 문제를 초래합니다:
- 노출 확률 기반의 편향: 클릭 데이터가 노출 확률에 의존하기 때문에, 관련성 수준이 아닌 노출 확률이 높은 아이템이 과대평가됩니다.
- 드문 아이템(Tail Items)에서의 성능 저하: 노출 확률이 낮은 드문 아이템은 충분히 고려되지 않기 때문에 추천 품질이 저하됩니다.
한계
- 이론적 편향 문제: ExpoMF는 노출 확률을 가중치로 사용하는 접근 방식을 통해 WMF의 한계를 일부 극복했으나, 여전히 이상적 손실 함수와의 편향이 존재합니다.
- 성능 저하: 특히 노출 확률이 낮은 경우, 관련성이 있는 아이템이 충분히 평가되지 못합니다.
4. Proposed Method
본 섹션에서는 이전 섹션에서 설명한 한계를 극복하기 위해 이상적 손실(Ideal Loss)을 위한 편향 없는 추정기(Unbiased Estimator)를 제안합니다.
제안된 편향 없는 추정기는 인과 추론(Causal Inference)의 Inverse Propensity Score (IPS)와 Positive-Unlabeled Learning에서 사용되는 추정기를 확장한 것입니다.
-
IPS 기반 노출 확률 보정
: 관찰된 노출 데이터를 통해 노출 확률 를 추정하고, 이를 통해 클릭 데이터의 편향을 제거. -
Positive-Unlabeled Learning
: 클릭 데이터의 관련성을 추정하여, 클릭되지 않은 데이터도 학습에 활용.
4.1 Unbiased Estimator
편향 없는 추정기(Unbiased Estimator)의 정의
기존의 WMF와 ExpoMF 모델이 노출 확률에 의존하여 이상적 손실 함수와 편향을 가지는 문제를 해결하기 위해 편향 없는 추정기를 제안합니다.
손실 함수 정의 :
- : 클릭 데이터 (1이면 클릭, 0이면 클릭되지 않음).
- : 노출 확률 (Exposure Probability).
- 와 : 각각 클릭 및 비클릭 데이터에 대한 손실.
편향 제거의 이론적 보장
이상적 손실 함수와의 관계 :
증명 :
- 를 이용하여, 의 기대값이 와 동일함을 확인할 수 있습니다.
- 따라서, 의 기대값은 와 동일하며, 이는 편향이 없음을 보장합니다.
장점
-
노출 확률 보정:
- 클릭 데이터의 노출 확률 로 보정되므로, 노출 확률에 따른 편향이 제거됩니다.
-
MNAR 문제 해결:
- 클릭 데이터가 Missing-Not-At-Random(MNAR)으로 인해 발생하는 문제를 완화합니다.
-
이상적 손실 함수와의 일치:
- 기대값 차원에서 이상적 손실 함수와 동일하므로, 관련성(Relevance) 기반 최적화가 가능합니다.
편향 없는 추정기의 분산 분석
Proposition 4.3
- 노출 확률 가중치(propensity reweighting)를 사용하여 편향을 줄이는 방식은 MNAR 문제를 해결할 수 있음.
- 하지만, 높은 분산(variance)을 가질 가능성이 있음.
Theorem 4.4 (Variance of the unbiased estimator)
-
편향 없는 추정기의 분산은 아래와 같이 정의됨:
-
분산은 노출 확률 의 역수에 의존.
-
노출 확률이 낮은 드문 아이템(Tail Items)에서 분산이 크게 증가할 수 있음.
-
편향 없는 추정기를 설계할 때 분산 감소 기법이 필요함.
4.2 Variance Reduction Technique
문제점 : 높은 분산
- Unbiased Estimator는 이상적 손실 함수와의 편향은 제거했지만, 노출 확률 가 매우 작은 경우 분산이 매우 커지는 문제가 발생합니다.
- 특히 드문 아이템(Tail Items)의 경우 가 작아 역수 가 커져 안정적인 학습이 어렵습니다.
해결책 : 클리핑(Clipping) 기법
클리핑 적용:
- 를 적용하여, 노출 확률 가 매우 작을 경우 하한선을 설정합니다.
- 여기서 은 하이퍼파라미터로, 가 보다 작을 경우 를 으로 대체합니다.
수정된 손실 함수 :
- : 클리핑된 노출 확률.
장점
-
분산 감소 :
- 를 도입하여 가 과도하게 커지는 문제를 방지하고, 안정적인 학습을 보장합니다.
-
효율적인 학습 :
- 드문 아이템(Tail Items)에서도 안정적인 학습이 가능해지고, 추천 품질이 향상됩니다.
이론적 보장
- 클리핑을 적용한 추정기는 이상적 손실 함수와의 편향을 여전히 최소화하며, 높은 분산 문제를 완화하는 효과를 보입니다. 또한 안정적인 학습과 추천 품질 개선을 동시에 달성합니다.
5. Semi-Synthetic Experiment
이 섹션에서는 반합성 데이터셋을 사용하여 아래의 연구 질문(RQ)을 조사합니다:
- RQ1. 노출 편향의 수준이 MF-Naive와 MF-Unbiased 모델의 성능에 어떤 영향을 미치는가?
- RQ2. 이상적인 손실 함수를 최적화하는 것이 True Performance Metric을 개선하는 데 효과적인가?
5.1 Experimental Setup
1. Dataset
-
Semi-Synthetic Data:
- MovieLens 100K 데이터셋을 사용하여 반합성 데이터를 생성
-
Generation Process:
- 로 추정된 관련성 점수 기반으로 생성
- 는 로 계산하여 노출 확률 분포를 제어(: 노출 편향 조절 파라미터)
2. Baselines
- MF-Oracle:
- 실제 관련성 정보를 사용해 학습한 모델. 이상적 성능을 제공
- MF-Naive:
- 클릭 데이터만을 기반으로 학습하는 모델
- Proposition 3.1에 의해 편향을 가짐
- MF-Unbiased:
- 편향 없는 손실 함수를 사용하여 학습한 모델
- Proposition 4.4에 따라 높은 분산 문제를 가질 수 있음
3. Evaluation Metrics
- Log-Loss:
- 테스트 셋에서 예측의 적합성을 평가.
- Discounted Cumulative Gain (DCG@K):
- 상위 개의 순위 추천 정확도를 평가.
5.2 Results & Discussions
그래프 분석
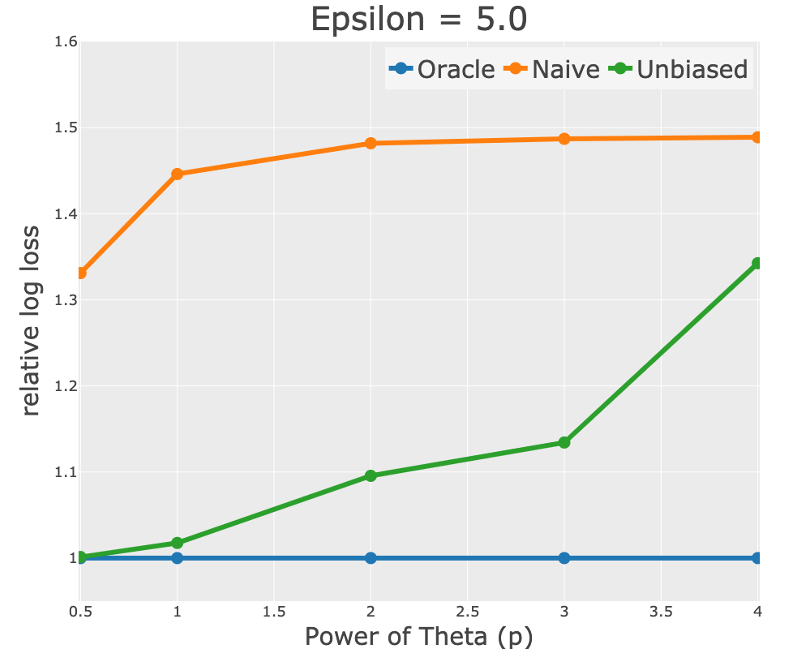
본 이미지는 'Unbiased Recommender Learning from Missing-Not-At-Random Implicit Feedback' 의 내용을 참조하여 사용되었습니다.
(1) Log-Loss 그래프
- X축: 의 power 값(), 즉 노출 편향의 강도를 나타냄.
- Y축: Relative Log-Loss (MF-Naive, MF-Unbiased 모델이 MF-Oracle 대비 얼마나 더 높은 손실을 보이는지 비교).
Naive (주황색 선)
-
Naive 모델:
-
노출 확률을 고려하지 않아 높은 편향 문제를 가짐.
-
노출 편향에 매우 취약하며, 성능 저하가 두드러짐.
-
Unbiased (녹색 선)
-
Unbiased 모델:
-
p 값 증가 시 로그 손실이 다소 증가하지만, Naive 모델보다 훨씬 안정적.
-
노출 확률 보정을 통해 편향 문제를 완화하며, Naive 대비 성능이 우수함.
-
- 결론:
- Unbiased 모델은 Naive보다 훨씬 낮은 로그 손실을 기록하며, 특히 높은 노출 편향 환경에서도 보다 안정적인 성능을 보여줍니다.
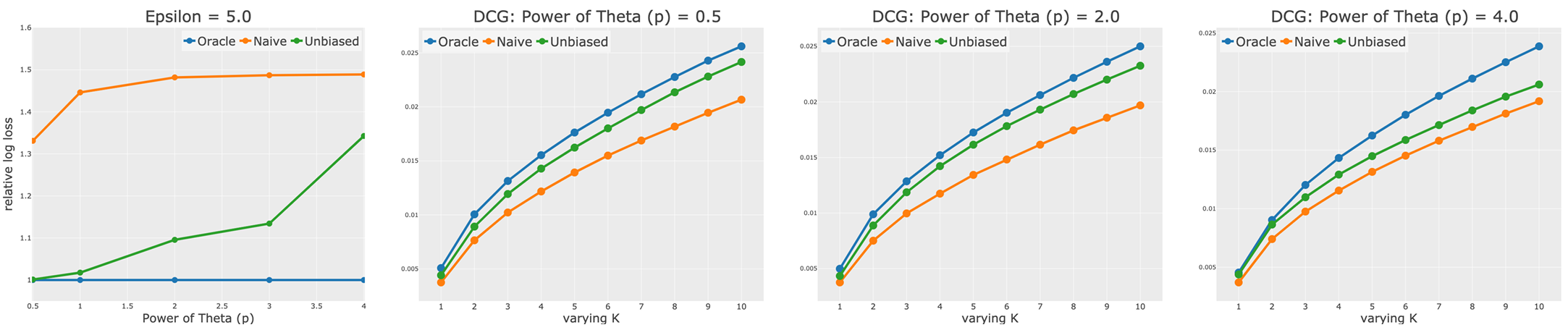
(2) DCG@K 그래프
- X축: 값 (추천 순위의 상위 항목).
- Y축: DCG@K (추천 품질 측정 지표).
-
결과 :
(1) :- MF-Unbiased는 MF-Naive보다 높은 성능을 보이며, MF-Oracle에 매우 근접
- 낮은 노출 편향에서 이상적 손실 함수 최적화가 효과적임을 보여줌
(2) , :
- MF-Unbiased는 여전히 MF-Naive의 성능을 능가함
- 하지만 노출 편향이 증가할수록 MF-Oracle에서 멀어짐
- 이는 높은 노출 편향 환경에서 분산 문제가 성능에 영향을 미쳤음을 나타냄
- 결론:
- MF-Unbiased는 MF-Naive보다 모든 값에서 일관되게 우수한 성능을 보임
- 높은 환경에서는 성능 향상이 제한적일 수 있지만, 여전히 MF-Naive보다 추천 품질이 높음
6. Real-World Experiment
목표
- 실제 데이터셋에서 Proposed Unbiased Estimator와 기존 모델들의 성능을 비교.
- Research Question:
- RQ3: 제안된 편향 없는 추정기가 기존 모델 대비 얼마나 효과적으로 동작하는가?
요약
- Proposed 모델 (Rel-MF with clipping)은 DCG, Recall, MAP 모두에서 WMF와 ExpoMF를 능가
- 제안된 모델은 Positive-Unlabeled 문제와 MNAR 문제를 효과적으로 해결하며, 특히 드문 아이템에서 높은 성능을 기록
- 클리핑 기법을 통해 분산 문제를 완화하면서도 높은 추천 품질을 유지
- 실제 데이터에서도 이상적 손실 함수 기반 접근 방식의 유효성을 입증
7. 결론 (Conclusion)
연구 요약
- 본 연구에서는 추천 시스템에서 발생하는 Missing-Not-At-Random(MNAR) 문제를 해결하기 위해 편향 없는 추정기(Unbiased Estimator)를 제안하였습니다.
- 이상적 손실 함수(Ideal Loss Function)를 정의하고, 기존 방법(WMF, ExpoMF)이 이상적 손실과의 편향을 가지는 이유를 이론적으로 분석하였습니다.
- 또한, 클리핑 기법(Clipping)을 도입하여 편향-분산 균형(Bias-Variance Trade-off)을 개선하였습니다.
주요 기여
-
이상적 손실 함수 정의 및 편향 분석:
- 이상적 손실 함수는 노출 확률과 관련성을 분리하여 관련성(Relevance)에 기반한 추천 품질을 최적화하도록 설계.
- 기존 모델(WMF, ExpoMF)의 손실 함수가 노출 확률에 의해 편향된다는 점을 이론적으로 증명.
-
편향 없는 추정기(Unbiased Estimator) 설계:
- 노출 확률과 관련성을 독립적으로 추정하여, MNAR 문제와 Positive-Unlabeled 문제를 동시에 해결.
- 클리핑 기법을 도입해 분산 문제를 완화하고 드문 아이템(Tail Items)에서의 성능을 개선.
-
실험적 검증:
- Coat 데이터셋 및 MovieLens 데이터셋에서 실험을 통해 제안된 추정기가 기존 모델보다 뛰어난 성능을 보임.
- 특히, True Relevance Metric과 NDCG@K에서 높은 성능을 기록하며, 드문 아이템에서도 안정적인 추천 품질을 제공.
한계 및 향후 연구
-
한계:
- 노출 확률 의 정확한 추정이 모델 성능에 중요한 영향을 미침.
- 대규모 데이터셋에서 계산 비용이 증가할 가능성이 있음.
-
향후 연구 방향:
- 노출 확률 추정 정확도를 높이기 위한 새로운 방법론 개발.
- 이상적 손실 함수의 최적화를 위한 더 효율적인 학습 알고리즘 설계.
- 다양한 추천 환경(예: 시간 기반 데이터, 온라인 학습 등)에 제안된 모델을 적용하여 실용성을 평가.
결론
- 제안된 편향 없는 추정기는 추천 시스템의 공정성(Fairness)과 정확성(Accuracy)을 동시에 개선할 수 있는 잠재력을 보여줍니다.
- 이는 기존의 WMF 및 ExpoMF 모델이 가진 한계를 극복하며, 추천 시스템 연구와 실무 적용 모두에 중요한 기여를 합니다.
- 본 연구는 추천 품질 향상을 위한 새로운 방향을 제시하며, 관련성 기반 추천 시스템 개발의 초석이 될 것입니다.
내가 생각한 향후 연구 방향
-
분산 문제 해결의 확장 연구 :
- 본 연구는 클리핑 기법을 통해 분산 문제를 완화했지만, 완전히 해결하지는 못했습니다. 특히, 노출 확률을 어느 수준에서 클리핑 값으로 제한할 것인지, 그리고 이 값을 어떻게 설정할 것인지는 중요한 연구 과제로 남아 있다고 생각합니다.
-
노출 확률(Exposure Probability) 추정의 개선 :
- 제안된 모델(Unbiased Estimator)은 노출 확률 를 정확히 추정하는 것이 중요한데, 이 과정에서 발생하는 오차가 성능 크게 영향을 미친다고 생각합니다.
- 더욱 정확한 노출 확률 추정 방법론에 대한 연구가 필요하다고 생각합니다.
-
사용자 행동 데이터를 활용한 모델 개선 :
- 클릭 데이터 외에도 체류 시간, 구매 이력 등 다양한 사용자 행동 데이터를 활용한 모델 확장이 가능할 것 같습니다.
- 이러한 데이터를 고려하면 추천 품질을 더욱 높일 수 있을 것으로 예상됩니다.
논문을 읽으며 든 생각들
-
편향이 없는 추정기를 정의할 뿐만 아니라, 높은 분산 문제를 클리핑 기법으로 완화시킨 점이 매우 흥미로웠습니다.
-
이와 관련하여 분산-편향 트레이드 오프에서 보통은 분산과 편향이 모두 작은 최적의 위치를 찾는 것이 목표인데, 추천 시스템에서는 왜 편향이 없는 것이 더 중요한지에 대해 추가로 공부해보고 싶다는 생각이 들었습니다.
-
MNAR 문제와 WMF와 ExpoMF에 대한 내용 또한 이번 논문을 통해 처음 알게 되었으며, 주요 내용 외에도 논문을 읽기 위해 필요한 많은 내용들(예: 인과추론, EM 알고리즘, 다양한 평가지표 등)을 이해하는데 시간이 많이 걸렸습니다. 관련 논문을 많이 읽다보면 이해하는 속도가 빨라질 것이라 생각합니다.
-
이론적으로 정의된 내용을 실제 데이터에 적용해보는 프로젝트도 좋은 학습이 될 것이라고 생각합니다.
-
혹시 설명이 잘못되었거나 잘못 이해한 부분이 있다면 피드백을 주면 감사하겠습니다.
논문 출처 : https://arxiv.org/abs/1909.03601
