Abstract
현재의 추천 시스템은 실제 인간의 추천 방식과 달리, 새로운 사용자(콜드스타트 문제)의 초기 선호도를 신속하게 파악하기 어렵습니다.
이 논문은 온라인 학습 기반 대화형 추천 시스템을 설계하여, 대화형 질문을 통해 사용자의 선호도를 빠르게 학습하고 더욱 개인화된 추천을 수행하는 방식을 제안합니다.
- 인간과 유사한 상호작용 방식을 구현
- 콜드스타트 문제를 해결하기 위해 사용자의 초기 선호도를 빠르게 파악
- 온라인 학습을 통해 실시간으로 모델을 업데이트
Chapter 1. Introduction
추천 시스템 연구 배경
- 대부분의 기존 추천 시스템은 주로 협업 필터링과 콘텐츠 기반 필터링으로 나눌 수 있음
- 콜드스타트 상황에서는 사용자 선호도가 불명확하기 때문에 실제 인간의 대화형 추천 방식과 차이가 큼
예시 상황
- 저녁 식사 장소를 물어볼 때 “해산물을 좋아하는지?”, “차가 있는지?” 등을 묻고, 맥락(Context)에 따라 적절한 후보를 빠르게 좁힘
논문의 주장
- 온라인 학습을 적용한 대화형 추천 시스템
1) 사용자 선호도를 빠르게 학습
2) 어떤 질문이 효과적인지 학습하여 더욱 정교한 추천 제공
논문에서 밴딧 접근(탐색과 활용) + 톰슨 샘플링을 활용해 콜드스타트 상황에서도 효율적으로 사용자 선호를 파악하는 모델을 제안함.
Chapter 2. Related Work
기존의 오프라인 추천 시스템
- 모델 재훈련 비용이 큼
- 오프라인 최적화가 실제 사용자 행동을 반영하지 못함
- 사용자 선호도의 변화(preference drift)를 포착하기 어려움
이러한 한계를 극복하기 위해 온라인 추천 시스템이 등장.
온라인 추천 시스템
-
문맥적 밴딧 (Contextual Bandit)
- 아이템을 팔(arms), 사용자를 문맥(context)으로 간주
- 문맥에 따라 최적의 팔을 탐색·활용
- Gaussian 프로세스를 적용해 유사한 문맥과 아이템 간 피드백을 공유하는 방법도 존재
-
잠재 요인 기반 온라인 추천
- 확률적 행렬 분해(PMF)와 밴딧 전략을 결합해 완전 온라인 학습 수행
- 사용자·아이템 잠재 벡터 곱을 평균으로 하는 정규분포 가정
- 유저와 아이템 잠재 요인은 각각 평균 0, 분산이 일정한 정규분포로 설정
본 논문의 방법
- 모든 사용자와 아이템 매개변수를 온라인 학습
- 절대적 피드백과 상대적 피드백을 모두 통합
- 탐색-활용 균형에 초점을 맞춘 접근 방식 제안
Chapter 3. Understanding Real Users
사용자들이 레스토랑을 검색할 때 어떤 요소를 고려하는지, 실제 웹 검색 엔진 로그를 분석해 통찰을 얻음.
연구 목표
- 도메인 인사이트 획득: 레스토랑 선택 시 고려되는 기준 파악
- 질문 식별: 시스템 평가를 위한 실제 질문 후보 도출
데이터 수집 과정
- 2014.07 ~ 2015.07 기간의 검색 쿼리 중, “restaurant” 또는 “dining”이 포함되고 “for”, “near”, “with” 등의 단어가 들어간 쿼리를 필터링
- 가장 빈도가 높은 10,000개의 쿼리(Q) 선정
3.1 Query Annotation with Entities
- 상위 수백 개 쿼리를 추가로 분석해, 위치(location), 이름(name), 요리(cuisine), 음식 유형(food type), 최상급 표현(superlative) 등을 태깅

분석 결과
- 39%: 위치(location)
- 19%: 레스토랑 이름(name)
- 9%: 요리(cuisine)
- 7%: 최상급 표현(“best”)
또한 위치와 이름이 함께 들어가는 경우(29%), 요리+위치(10%), best+위치(8%) 등의 조합도 발견됨.
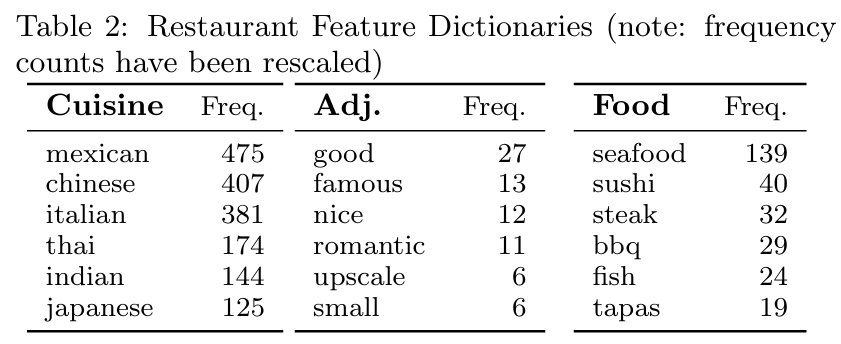
Table 1 & Table 2
- 사용자 쿼리에 자주 등장하는 전치사(in, near, for, with)
- 주요 요리, 형용사, 음식 관련 단어 등의 빈도 리스트를 통해 대화형 추천 시 고려할 핵심 질문 요소들을 식별
3.2 Understanding Common Phrases
- 위치(location)가 중요한 요소임을 확인
- 레스토랑 선택 시 사용자 상황(context)을 함께 고려해야 함
3.3 Restaurant Feature Dictionaries
- “형용사 & 요리 & 훌륭함 & 위치” 등 복합적 조건을 모두 고려하기 위해, 5,000개 쿼리 중 상위 1,013개 구문을 정리
- 음식(Food): 요리, 식단 제약, 품질(유기농 등)
- 평점(Rating): 미슐랭 스타 등
- 분위기(Atmosphere): 전망, 낭만적 분위기 등
- 시간·위치(Time/Location): 영업시간, 테마, 시간대 등
3.4 Outlook
- 검색 로그 분석을 통해 연구 동기를 명확히 하고, 사용자 연구(user study)에 대한 기반을 마련(섹션 7)
- “무엇을 물을지”뿐 아니라, “어떻게 물을지”를 결정하는 데 핵심 가이드 제공
Chapter 4. Model
4.1 Overview (모델 개요)
대화형 추천 시스템 전체 프로세스:
- 모델 및 선호도 유도 메커니즘 선택
- 절대적(Absolute) vs 상대적(Pairwise) 질문
- 예: 절대적 선호도(Abs), 긍정/부정(Abs Pos & Neg), 상대적 선호도(Pairwise)
- 오프라인 데이터로 초기화
- 기존 데이터를 활용해 새로운 사용자·아이템 초기값 설정
- 사용자와 반복 상호작용
- 시스템이 질문을 선택하고, 사용자는 응답
- 필요 없는 질문은 점차 제외
- 최종 추천 제공
- 업데이트된 모델로 맞춤형 리스트 생성
4.2 Latent Factor Recommendation (잠재 요인 추천)
- 사용자·아이템 모두 잠재 벡터를 갖고, 내적(Inner Product)으로 선호도를 계산
- 수식:
- 사용자 바이어스(), 아이템 바이어스()를 함께 고려
4.3 Continuous Learning Recommender (지속적 학습 추천 시스템)
4.3.1 Initialization from Offline Data
- 오프라인 데이터에서 학습된 아이템 특성(, )으로 아이템 초기화
- 새로운 사용자 특성()과 바이어스()는 기존 사용자 평균값으로 설정
4.3.2 Question Selection Strategies (질문 선택 전략)
- 목표: 적은 수의 질문으로 최대 정보 획득
- 주요 예시: Greedy, Random, MV, MaxT, MinT, UCB, Thompson Sampling
4.3.3 Online Updating (온라인 업데이트)
- 사용자가 응답(좋아함/싫어함)을 제공하면, 모델 파라미터를 실시간으로 갱신
- 노이즈를 고려하여 선호도 분포를 점진적으로 업데이트
4.3.4 Absolute Model: Absolute Questions
- 특정 아이템에 대해 “좋아하시나요?” 식의 절대적 질문
- Thompson Sampling을 기반으로 가장 높은 잠재 선호도를 가진 아이템부터 물어봄
4.4 Extension to Relative Preferences (상대적 선호도로 확장)
4.4.1 Absolute Model: Relative Questions
- 절대적 모델(Abs)에 상대적 질문 방식을 도입
- 아이템 A 선택 후, 가상의 부정 응답을 추가해 업데이트된 분포로 아이템 B를 선택
- Abs Pos: 긍정 피드백 중심
- Abs Pos & Neg: 긍정·부정 피드백 모두 반영
4.4.2 Pairwise Model: Relative Questions
- 두 아이템 중 어느 것을 선호하는지 직접 묻는 전용 모델
- Dueling Bandit을 적용해, A와 비교 시 가장 큰 차이를 보이는 B를 선택
- “둘 다 싫다” 옵션도 제공해, 사용자의 실제 선호를 왜곡 없이 반영
Chapter 5. Experimental Setup
Setting
- 대화형 추천 시스템을 평가하기 위해서는, 시스템 액션에 대한 사용자 반응을 전부 처리할 수 있어야 함.
- 이를 위해 생성적 사용자 모델(generative user models)을 사용:
1) 합성(synthetic) 모델 (섹션 6에서 검증용)
2) 실 사용자 선호 기반 모델 (섹션 7에서 사용자 연구 통해 수집)
실험 구성
-
모든 실험은 오프라인 단계(offline phase)와 온라인 단계(online phase)로 구성
- 오프라인 단계:
- 명의 사용자가 개의 아이템과 상호작용하여 모델에 데이터를 제공
- 온라인 단계:
- 모델이 콜드스타트 사용자와 상호작용
- 오프라인 단계에서 사용한 개 아이템을 바탕으로 질문을 제시
- 오프라인 단계:
-
질문 수를 0에서 15까지 다양하게 설정하고, 각 질문 후 모델 성능을 측정
-
실제 사용 시에는 더 적은 질문으로도 추천 가능하며, 초기 추천과 결합하거나 여러 차례 상호작용에 분산해 사용할 수도 있음
Research Questions
- RQ 1. 모델이 사용자의 선호도에 제대로 적응할 수 있는가?
- RQ 2. 절대적 피드백(Absolute)과 상대적 피드백(Relative) 중 어떤 방식이 효과적인가?
- RQ 3. 어떤 상대적 질문 방법이 더 우수한가?
- RQ 4. 절대적 vs 상대적 피드백 중 더 효과적인 것은 무엇인가?
- RQ 5. 오프라인 초기화(offline initialization) 과정은 도움이 되는가?
- RQ 6. 어떤 질문 선택 전략(question selection strategy)이 가장 효과적인가?
Evaluation Metric
- 추천 목록이 사용자 선호도에 얼마나 부합하는지를 평가하기 위해 Average Precision@k (AP@k)를 사용
- 으로 설정 (상위 10개 추천 정확도 측정)
AP@k 정의
1. 사용자 의 예측 추천 목록을, 모델이 추정한 선호도 (평균 추정치)에 따라 내림차순 정렬
2. 실제 사용자 반응(좋아함/싫어함)을 라 할 때, 상위 개 아이템 내에서 각 위치 마다 Precision@을 구하고 평균화
수식은 다음과 같이 정의됨:
- 여기서 이면 해당 위치 아이템을 사용자가 좋아함을 의미, 0이면 싫어함을 의미
- (Precision@)은 상위 개 중 좋아하는 아이템의 비율
- 값이 1에 가까울수록 상위 추천 성능이 좋음을 의미
추가적으로 순위 상관(rank correlation) 지표 등도 함께 분석하여 결과를 보완하며, AP@10의 평균값과 95% 신뢰구간을 제시해 모델 성능을 평가함.
Chapter 6. Learning Synthetic User Type Preferences
본 장에서는 의도적으로 단순화된 레스토랑 추천 시나리오를 통해, 모델이 어떻게 사전 정보(prior beliefs)를 수정(unlearn)하고 특정 유형의 사용자에게 맞춤형 추천을 제공할 수 있는지 실험적으로 보입니다. 이는 RQ1에 대한 긍정적인 답을 제시합니다.
실험 설정: 오프라인 임베딩
-
오프라인 데이터 학습
- 사용자의 오프라인 관찰 데이터를 통해 사용자와 아이템을 동일한 저차원 공간에 임베딩
- 레스토랑 유형과 사용자 유형을 각각 여러 가지로 설정하고, 사용자가 좋아하는 레스토랑 카테고리와 싫어하는 카테고리를 나눠 데이터 생성
-
레스토랑 및 사용자 유형 예시

- 파라미터 및 데이터 규모
- (레스토랑 수), (사용자 수)
- 각 오프라인 사용자는 자신의 좋아하는 카테고리에서 10개 아이템을 ‘좋아함’, 나머지 카테고리들에서 10개 아이템을 ‘싫어함’으로 샘플링
- 예시로, 등의 파라미터 사용
- 잠재 차원 로 제한하여, 하나의 축은 맵기(spiciness)로, 다른 축은 가격(price) 요인으로 해석
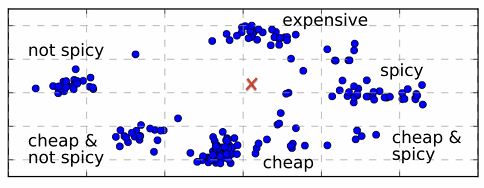
Cold-Start User Initialization
- 모든 사용자 평균 특성 벡터(빨간색 X 표시)를 cold-start 사용자에게 초기값으로 할당
- 아이템 바이어스, 평균 사용자 바이어스 등도 함께 고려하여 사용자의 잠재 선호도 분포를 추정
사용자와 아이템을 같은 잠재공간에 임베딩
- 레스토랑들이 spicy/not-spicy, cheap/expensive 축에 따라 분포
- 빨간색 X : 평균 사용자 벡터 (cold-start)
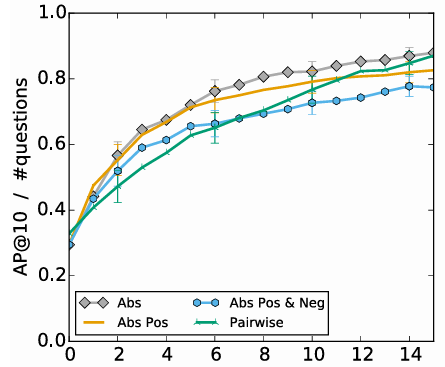
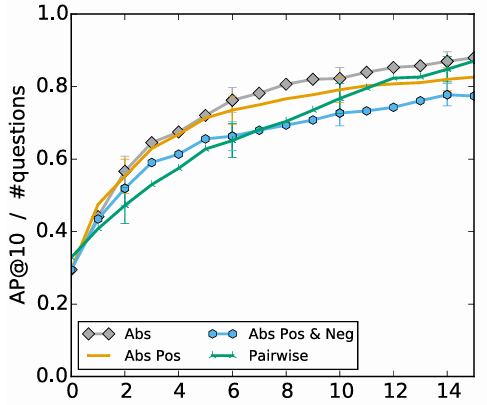
실험 결과
- 질문의 방식에 따른, 질문의 수 당 정확도 상승을 보여주는 그래프
- 드물게 관찰된 유형인 expensive 와 자주 관찰된 유형인 not spicy 의 정확도 비교
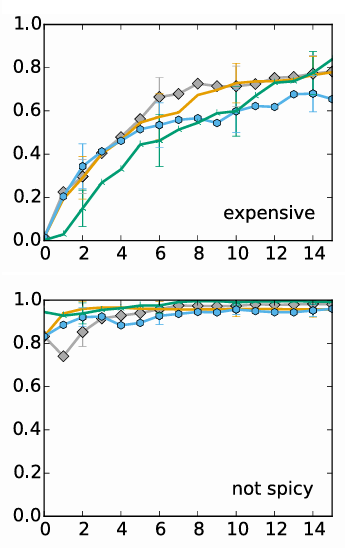
결과 해석
1. 전반적 추이
- 질문이 늘어날수록 추천 정확도(AP@10)가 상승
- x축(0~15)은 “질문(피드백)을 몇 번 받았는가?”, y축은 “AP@10(상위 10개 추천 정확도)”
- 질문 횟수가 증가할수록 모든 방식에서 정확도가 전반적으로 올라감
2. 방법별 성능 차이
- Abs(회색 다이아) 가 최종적으로 가장 높은 AP@10에 도달
- 그다음 Abs Pos(주황), Pairwise(초록), Abs Pos & Neg(파랑) 순
- 초기 몇 번의 질문 구간에서는 오차범위가 겹치지만, 전반적으로 Abs 곡선이 계속 높게 유지
3. 자주 관찰된 유형 vs. 드물게 관찰된 유형
- expensive 유형(위쪽)과 not spicy 유형(아래쪽)을 예시 비교
- not spicy: 오프라인 데이터에서 흔히 관찰된 취향 → 질문 0~2번만으로도 AP@10이 0.8 이상
- expensive: 오프라인에서 드물게 관찰된 취향 → 초기 AP@10이 낮지만 질문이 누적될수록 빠르게 개선
- 결론적으로, 오프라인 데이터와 가까운 취향은 초기 성능이 높고, 드문 취향은 질문을 통해 학습 필요
4. RQ2(절대 vs 상대 피드백) 관점
- RQ2: “절대적 피드백(좋다/싫다) vs 상대적 피드백(A vs B)? 어느 쪽이 더 효과적인가?”
- 그래프상 절대적 방식(특히 Abs)이 최종 AP@10을 가장 높게 달성
- 상대적 방식(Pairwise, Abs Pos & Neg)도 질문이 충분히 늘어나면 성능이 상당히 높아짐
- 이 실험에서는 Abs가 약간 앞서며, “절대적 피드백도 충분히 효과적”임을 시사
5. 결론 정리
- 질문(피드백)이 늘어날수록 오프라인 데이터의 편향(‘평균 사용자 취향’ 가정)이 해소되고, 콜드스타트 사용자 취향을 더 정확히 학습
- 자주 관찰된 취향은 질문이 적어도 이미 높은 정확도를 보이지만, 드물게 관찰된 취향은 질문을 통해 ‘잘못된 사전 가정’을 수정
- RQ2 관점으로 보면, 절대적(Abs)과 상대적(Pairwise) 피드백 모두 학습 효과가 뛰어나지만, 이 그래프에서는 Abs가 다소 앞서는 결과를 얻음
Chapter 7. Results on Real Data
본 장에서는 실제 데이터를 활용하여 대화형 추천 시스템의 성능을 평가합니다. 특히, RQ3 ~ RQ6에 답하기 위해 다양한 실험을 설계하고 수행했습니다. 이 장은 케임브리지(UK)에서의 레스토랑 추천을 사례로, 대화형 추천 시스템이 사용자 선호를 얼마나 효과적으로 학습할 수 있는지 확인합니다.
7.1 Search Data for Offline Initialization
실험 설정 : 오프라인 초기화 데이터
- 데이터 수집 :
- 주요 검색 엔진에서 케임브리지 레스토랑 관련 검색 기록을 기반으로 수집.
- 쿠키 데이터를 사용하여 익명의 사용자 활동 추적.
- 레스토랑 페이지 방문 기록을 "선호"로 간주.
데이터 요약
- 사용자 수: 3,549명
- 레스토랑 수: 289개
- 관찰 수: 9,330건
- 랜덤 샘플링으로 부정적 데이터(싫어요)를 추가하여 학습 데이터 균형화.
파라미터 설정
- 잠재 차원:
- 분산:
- 노이즈:
7.2 User Study as Basis for Online Evaluation
사용자 연구
-
실험 설계:
- 10개의 레스토랑에 대해 사용자 선호도를 "예/아니오"로 평가.
- 28명의 참가자를 모집하여 응답 데이터를 수집.
- 레스토랑에 익숙하지 않은 참가자를 위해 관련 링크를 제공.
-
실험 결과
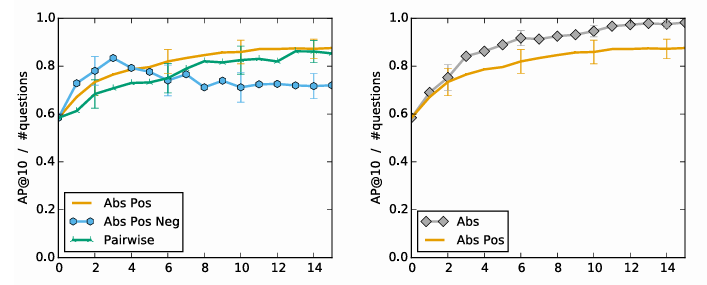
왼쪽 그래프 :
Abs Pos(긍정적 데이터만 반영)가 가장 높은 성능을 유지하며, 학습이 안정적입니다.
Abs Pos Neg는 비선호 데이터를 반영하면서 선호 항목에 대한 부정적 영향을 유발해 성능이 저하됩니다.
오른쪽 그래프 :
Abs가 Abs Pos보다 높은 성능을 보임. 이전의 6장 결과와 동일
실험 설계는 데이터 수집 단계이고, 그래프는 이 데이터를 사용한 학습 결과를 시각적으로 표현한 것
7.3 Obtaining Ground Truth
콜드스타트 문제 해결
- 부트스트래핑을 사용하여 ground truth 생성:
- 참가자 중 1명을 랜덤 샘플링.
- 이 참가자의 데이터를 기반으로 289개 레스토랑에 대한 완전한 평점을 예측.
결과
- 기존 사용자 데이터와 부트스트래핑으로 생성한 데이터 간 높은 일관성을 확인.
7.4 Results
실제 데이터를 이용하여 RQ 3~6에 대한 실험 결과를 보임.
RQ 3: 상대적 질문에서 어떤 방법이 더 좋은가?
- Abs Pos(선호만 반영) vs. Abs Pos & Neg(선호/비선호 반영) vs. Pairwise(쌍별 비교).
- 결과: Abs Pos가 가장 높은 성능을 보임.
RQ 4: 절대적 질문 vs. 상대적 질문
- 절대적 질문(Abs): 높은 성능 달성.
- 15개의 질문 이후 AP@10=0.975로 거의 완벽한 성능.
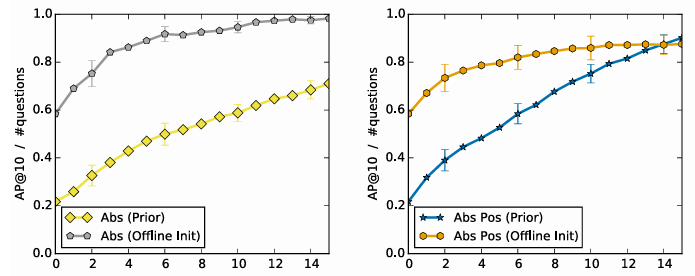
RQ 5: 오프라인 초기화의 효과
- 오프라인 임베딩으로 초기화 시, 질문 없이도 성능이 0.217 → 0.584로 향상.
Impact of offline initialization on performance for absolute (Abs, left) and relative feedback (Abs Pos, right)
RQ 6: 질문 선택 전략 비교
- Thompson Sampling과 UCB가 가장 높은 성능을 기록.
- Greedy, Random, MinT는 낮은 성능을 보임.
Performance of question selection strategies for absolute (Abs, top) and relative (Abs Pos, bottom) models.
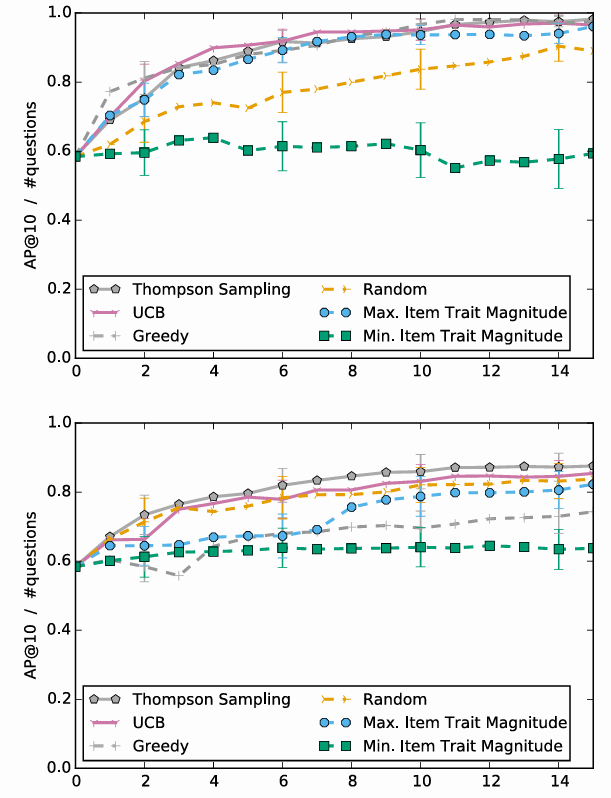
결론
- 오프라인 초기화와 적절한 질문 선택 전략은 대화형 추천 시스템의 학습 속도와 정확도를 크게 향상시킵니다.
- 밴딧 기반 전략(Thompson Sampling, UCB)은 특히 효과적이며, 사용자 선호를 빠르고 정확하게 학습할 수 있습니다.
Chapter 8. Conclusions
본 논문에서는 추천 시스템을 대화형 프로세스로 보는 새로운 관점을 제안했습니다. 실제 사람이 추천을 하는 것 처럼, 새로운 사용자와 대화를 통해 선호도를 학습할 수 있는 대화형 추천 시스템의 개념을 소개했습니다.
주요 내용 요약
-
연구 목표:
- 레스토랑 추천을 사례로 사용하여, 사용자의 선호를 학습하는 대화형 추천 시스템을 개발.
- 상업적 검색 엔진의 레스토랑 관련 쿼리를 분석하여 초기 통찰을 얻음.
- 사용자 연구를 통해 시스템 평가를 위한 진실 데이터(ground truth)를 수집.
-
제안된 모델:
- 확률적 행렬 분해(probabilistic matrix factorization)에 기반을 둔 대화형 추천 모델.
- 모델을 지속적인 학습(continuous learning)이 가능하도록 확장.
-
평가 방식:
- 사용자 연구를 통해 얻은 실제 선호 데이터를 기반으로 실험적 평가를 수행.
연구 결과 및 시사점
-
절대적 질문의 효과:
- 절대적 질문(Absolute Questions)이 가장 높은 성능을 제공.
- 그러나, 상대적 피드백(Relative Feedback)만 가능한 환경에서도 효과적인 학습이 가능함을 확인.
-
오프라인 초기화의 중요성:
- 오프라인 임베딩(Offline Embedding)을 사용한 초기화 접근법을 제안.
- 약하게 레이블링된 데이터(weakly supervised data)만으로도 성능이 크게 향상됨.
-
질문 선택 전략의 효과:
- 피드백을 효과적으로 이끌어낼 수 있는 질문 선택 전략을 식별.
- 이러한 전략은 학습 효율성을 크게 높임.
향후 연구 방향
-
강화 학습(Reinforcement Learning):
- 대화형 추천 시스템에 강화 학습을 적용하여 장기적 의존성을 학습할 가능성 탐구.
-
모듈형 구조:
- 제안된 프레임워크의 모듈형 구조를 활용하여 다양한 피드백 유형과 확률 모델을 조합.
- 다양한 설정에 적합한 대화형 추천 시스템을 구축할 수 있는 플러그 앤 플레이 방식 제공.
내가 생각한 향후 연구 방향
1. 강화 학습을 활용한 대화형 추천 시스템 확장
본 논문에서는 주로 확률적 행렬 분해와 사용자 응답 데이터를 활용해 대화형 추천 시스템을 구축했습니다. 그러나, 강화 학습(Reinforcement Learning)을 활용하면 장기적 사용자 선호를 더 잘 학습할 수 있을 것으로 보입니다.
특히, 사용자의 미래 행동을 예측하거나, 장기적으로 최적의 추천을 제공하기 위한 정책 학습(policy learning)에 대한 연구가 필요하다고 생각합니다.
2. 오프라인 임베딩과 실시간 데이터 융합
현재 논문에서는 오프라인 임베딩을 초기화 단계로만 사용했습니다. 하지만, 실시간 데이터와 오프라인 임베딩을 융합하는 연구가 진행된다면 더 나은 성능과 적응력을 기대할 수 있을 것 같습니다.
예를 들어, 사용자 행동 데이터가 실시간으로 반영되어 오프라인 임베딩을 지속적으로 업데이트할 수 있는 방법론을 탐구하면 좋을 것 같습니다.
3. 다양한 피드백 데이터 통합
현재 연구에서는 주로 "예/아니오" 방식의 절대적 피드백과 두 항목 간 비교를 활용했습니다. 하지만, 클릭 데이터, 체류 시간, 구매 이력 등 다양한 사용자 행동 데이터를 통합하면 추천의 품질을 더욱 높일 수 있을 것이라 생각합니다.
이러한 추가 데이터를 활용하면, 특히 콜드 스타트 문제를 해결하는 데 큰 도움이 될 것으로 예상됩니다.
4. 편향-분산 문제 해결
논문에서 사용된 오프라인 초기화나 질문 선택 전략은 편향-분산 문제를 어느 정도 해결합니다. 하지만, 질문 선택 전략에서의 편향과 데이터 부족으로 인한 분산 증가 문제가 여전히 존재합니다.
이를 개선하기 위한 새로운 질문 설계 전략이나 데이터 증강(Data Augmentation) 방식을 연구하는 것도 유의미한 확장이 될 수 있습니다.
논문을 읽으며 든 생각들
-
추천 시스템의 대화형 접근의 가능성
기존의 비대화형 추천 시스템과는 달리, 본 논문에서는 대화형 접근 방식을 통해 사용자의 선호를 학습하는 아이디어가 매우 흥미로웠습니다. 특히, 절대적 질문(Abs) 방식이 상대적 질문(Abs Pos)보다 높은 성능을 보여주는 점이 신선했으며, 사용자의 긍정/부정 피드백을 어떻게 활용할지에 대한 고찰이 필요한 것 같습니다. -
오프라인 초기화의 실제 적용
오프라인 임베딩을 통해 학습 초기의 성능을 크게 향상시킨 점이 인상적이었습니다. 하지만, 실제 응용에서 오프라인 데이터의 품질이 추천 시스템 성능에 얼마나 큰 영향을 미칠지에 대해 고민이 들었습니다. 예를 들어, 특정 도메인에서는 오프라인 데이터가 부족할 가능성이 높은데, 이를 보완할 방법이 필요할 것 같습니다. -
연구의 응용 가능성
논문에서 제안된 모델이 레스토랑 추천에만 국한되지 않고, 전자 상거래, 음악 추천, 영화 추천 등 다른 도메인에서도 활용될 가능성이 있다고 생각했습니다. 이를 실제 데이터에 적용해보는 프로젝트를 진행하면 좋은 학습 경험이 될 것 같습니다.
“Towards Conversational Recommender Systems” (KDD 2016) 논문의 핵심은
- 대화형 추천이라는 문제를 명확히 정의
- 사용자에게 질문-응답(속성 선호)을 통해 반복적(Iterative)으로 정보를 얻는 구조 제안
- 이를 뒷받침할 수 있는 데이터 수집/실험 환경과 모델을 구체적으로 보여준다는 점
이라고 생각하며, “사용자 피드백(응답)을 어떻게 수집하고 해석해 모델에 반영하는가?”와 “그 과정(질문 순서, 피드백 반영 방식)을 어떻게 설계해 추천 성능을 극대화하는가?” 에 집중하여 논문을 읽어야 한다고 생각합니다.
대화형 추천시스템을 처음 접한 논문이라서, "대화형 추천이란 이러한 단계와 과제를 가지고 있구나” 라는 맥락을 잡으며 공부하였습니다.
