ElasticSearch 이란
Elastic Search 는 Apache Lucene 기반의 Java 오픈 소스 분산 검색 시스템입니다.
ElasticSearch를 통해 Lucene 라이브러리를 단독으로 사용할 수 있게 되었으며, 많은 데이터를 신속하고, 실시간으로 저장, 검색 , 분석할 수 있습니다.
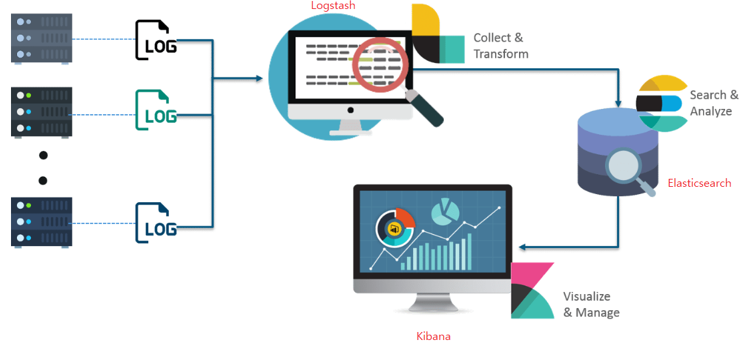
ElasticSearch는 검색을 위해 단독으로 사용되기도 하며, ELK ( Elasticsearch / Logstatsh / Kibana ) 스택으로 사용되기도 합니다.
- Logstash : 다양한 소스 ( DB, csv 파일 ) 의 로그 또는 트랜잭션 데이터를 수집, 집계, 파싱하여 Elasticsearch에게 전달
- Elasticsearch : Logstash로부터 받은 데이터를 검색 및 집계를 하여 필요한 관심 있는 정보를 획득
- Kibana : Elasticsearch의 빠른 검색을 통해 데이터를 시각화 및 모니터링
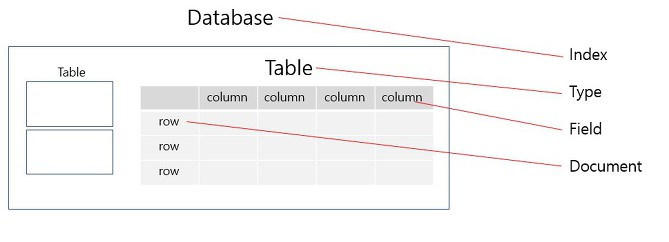
ElasticSearch 와 RDBS 비교
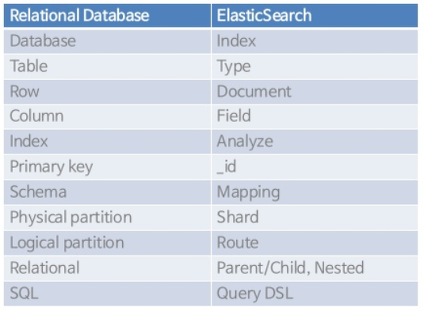
| RDBMS | ElasticSearch |
|---|---|
| Database | Index |
| Table | Type |
| Row | Document |
| Column | Field |
| Join 가능 | Join 불가능 |
| 검색속도 느림 | 검색속도 빠름 |
| 수정,삭제 빠름 | 수정,삭제 느림 |
RDBMS 데이터 저장형태
RDBMS 는 데이터를 저장할 때 테이블 형태로 저장합니다. 만약 데이터를 찾을 때 찾고자 하는 데이터를 전체 데이터에서 검색하기 때문에, 데이터가 많아질수록 검색 속도가 느려집니다.
| Doc | 내용 |
|---|---|
| 1 | "Dogs should always be taken for a walk." |
| 2 | "A Car is beautiful." |
| 3 | "It`s really nice house" |
ElasticSearch 저장 형태
ElasticSearch 는 역색인 구조로 데이터를 저장합니다. RDBMS와 반대이며 데이터의 모든 단어들을 분리하여 사전을 만들어 탐색을합니다.
ElasticSearch는 Text Analysis 과정을 통해서 규칙이 있습니다.
- 대문자 소문자 검색없이 진행되어야 하기 때문에 모든 영어는 소문자로 만들어져야합니다.
- Dogs 와 DOG 등은 dog로 통일시켜서 데이터 사전에 저장됩니다.
- 문장에서 불필요한 단어를 제거하고, Token으로 만들어줍니다.
| Token(Term) | Doc |
|---|---|
| car | 1,3 |
| dog | 1 |
| walk | 2 |
| house | 1,4 |
ElasticSearch 아키텍쳐 / 용어
ElasticSearch 에서 사용하는 대부분 개념은 RDBMS에서 존재하는 개념입니다.
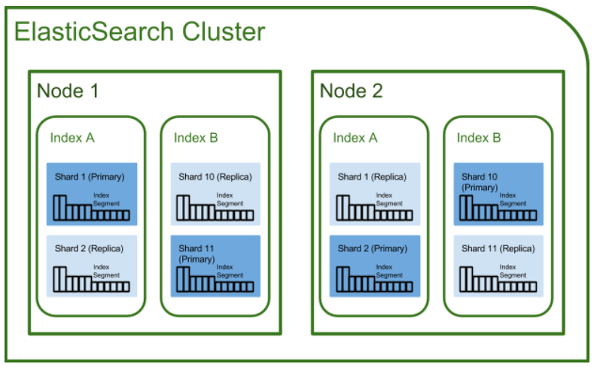
클러스터 ( Cluster )
클러스터는 ElasticSearch 에서 가장 큰 시스템 단위를 의미하며, 최소 하나 이상의 노드들로 이루어진 집합을 말합니다.
각각의 클러스터는 접근할 수 없으며, 여러 대의 서버가 하나의 클러스터를 구성할 수 있고, 한 서버에 여러개의 클러스터가 존재할 수 있습니다.
엘라스틱서치의 실행프로세스는 노드 ( Node ) 라고하며, 저장 데이터들은 샤드 ( Shared ) 라고 합니다.
하나의 노드에 있던 샤드는 다른 노드와 클러스터링 되면 샤드들이 재배치( relocation ) 됩니다.
또한 노드들간의 클러스터링을 통해 쉽게 스케일 아웃이 가능합니다.
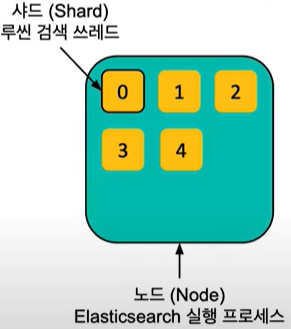
그림 1
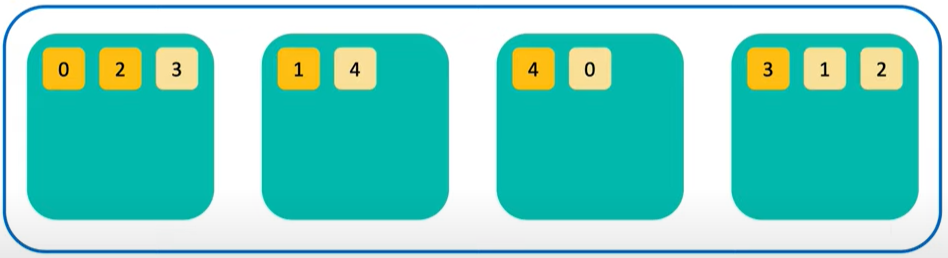
그림 2
위의 그림처럼 하나의 노드에는 5개의 샤드가 있습니다. 그림 2에서는 4개의 노드로 분리하여 저장할 수 있습니다. 이때 분산 저장된 데이터들은 복제본을 가지고있습니다.
그림 2에서 원본 ( 진한색 ) 과 복제본 ( 옅은 색 ) 이 존재하는 것을 볼 수 있습니다.
이것을 Primary Shard ( 원본 데이터 ) , Replica Shard ( 복제 데이터 ) 라고 부릅니다.
그림 1에서는 현재 노드가 종료되면 노드 안에있는 0~4번의 데이터가 모두 사라지는 문제가 발생합니다. 이러한 상황을 방지하기 위해 여러개의 데이터로 나누는 클러스터링 기법이 필요합니다.
노드 ( Node )
ElasticSearch를 구성하는 하나의 단위 프로세스를 말합니다.
그 역할에 따라 Master-eligible, Data, Ingest, Tribe 노드로 구분할 수 있습니다.
master-eligible node
클러스터를 제어하는 노드를 말합니다.
- 인덱스 생성, 삭제
- 클러스터 노드들의 추적, 관리
- 데이터 입력 시 어느 샤드에 할당할 것인지 정의
Data Node
데이터와 관련된 Crud 작업을 하는 노드입니다.
이 노드는 CPU, 메모리 등 자원을 많이 소모하기 때문에 모니터링이 필요하며 master노드와 분리해야 합니다.
Ingest Node
데이터를 변화하는 등 사전 처리 파이프라인을 실행하는 역할을 합니다.
Coordination only Node
Data Node와 Master-eligible node의 일을 대신하는 노드이며, 대규모 클러스터에서 사용됩니다. 즉 로드밸런서와 비슷한 역할을 합니다.
인덱스 ( Index ) / 샤드 ( Shared ) / 복제 ( Replica )
샤딩 ( Sharding ) 는 데이터를 분산해서 저장하는 방법을 의미합니다. ElasticSearch에서 Index를 여러 shared 로 쪼갠 것을 말합니다. 기본적으로 1개가 존재합니다.
복제 ( Replica ) 는 노드를 손실했을 경우 데이터의 신뢰성을 위해 샤드들을 복제한 것을 말합니다. 해당 Replica 는 서로 다른 노드에 존재하는 것을 권장하고있습니다.
그 이유는 Node가 손상되어 데이터 손실이 났을 경우 다른 Node에서 데이터를 불러오기 위함입니다.
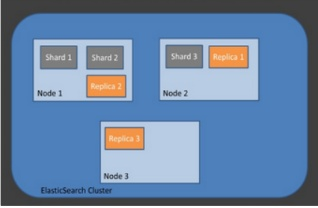
위의 사진처럼 각각의 Replica 는 서로 다른 노드에 저장됨을 볼 수 있습니다.
ElasticSearch 특징
- Scale Out : 샤드를 통해 규모를 수평적으로 늘릴 수 있습니다.
- 고 가용성 : Replica 를 통해 데이터의 안정성을 보장합니다.
- Schema Free : JSON 문서를 통해 데이터를 검색하므로 스키마 개념이 없습니다.
- RestFul : 데이터 CRUD 작업은 RestFul API 를 통해 수행합니다.
참고
참고 블로그 1 : https://velog.io/@junsu1222/Elasticsearch%EB%A5%BC-%EC%82%AC%EC%9A%A9%ED%95%9C-%EA%B2%80%EC%83%89%EC%97%94%EC%A7%84-%EA%B5%AC%EC%B6%95
참고 블로그 2 : https://victorydntmd.tistory.com/308
참고 블로그 3 : https://anygyuuuu.tistory.com/2
참고 블로그 4 : https://12bme.tistory.com/589
