
기존 검색 기능
where article.title like %param% and article.id > listindex
기존 검색 기능을 보면 where 절을 사용하여 쿼리를 작성하여 검색 기능을 만들었습니다.like 문을 활용하여 해당 텍스트가 포함되어있는 데이터를 가져오는 로직입니다.
문제점
like 쿼리는 like %query 로 사용했을 때 인덱스를 사용할 수 있습니다. 하지만 like %query% 와 같이 Full Text를 검색할 때는 인덱스를 하지 않고 풀스캔을 하게 됩니다.
그렇기 때문에 쿼리를 작성하면 1000만건이 넘을 경우 5초가 넘는 실행시간이 걸리게 됩니다.
Elastic Search를 선택한 이유
-
기능의 확장성
ElasticSearch를 사용하면 Mysql full text search 를 선택했을 때 보다 복잡한 검색이 가능합니다. ( 동의어와 유의어 ) -
분산
검색과 관련된 기능을 Elastic Search 에게 맡긴다면 Mysql이 부담해야 할 부하가 줄어들어 성능 개선을 기대할 수 있습니다. -
검색 속도
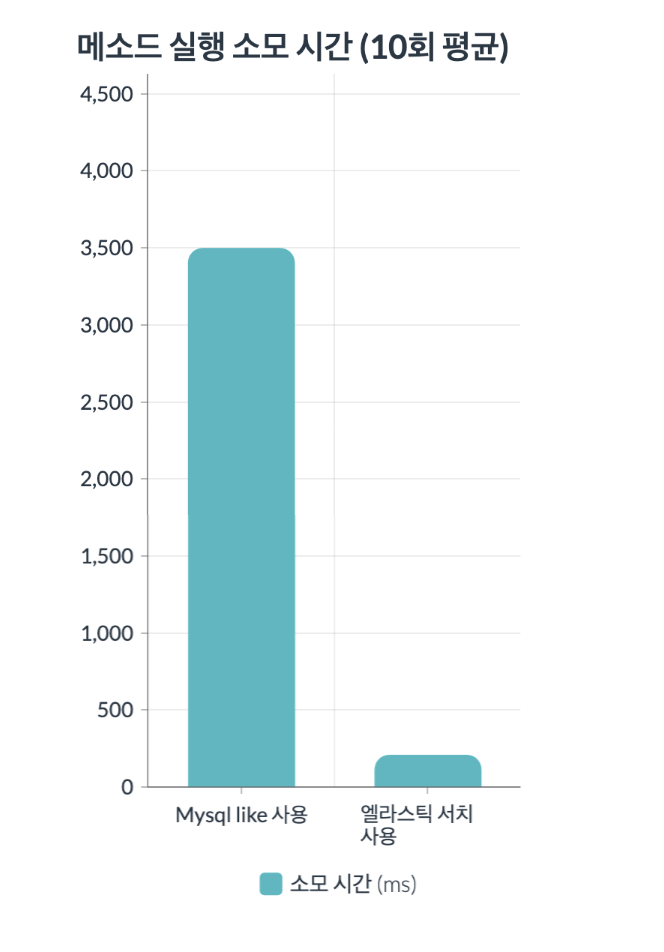
위 사진처럼 같은 데이터를 조회했을 때 Mysql 의 경우 3500ms가 걸린 경우 150ms 가 걸리는 것을 알 수 있습니다.
Tokenizer와 Filter
먼저 ES 에서 동의어 처리를 하기 위해서는 Tokenizer와 Synonym filter를 적용해주어야합니다. 보통 Tokenizer는 nori를 사용하게 됩니다.
동의어 사전은 analysis/synonym.txt 로 저장되어 있으며 규칙에 따라 동의어를 작성해주어야 합니다.
첫번쨰로 , 쉼표는 동의어로 등록하는 방법이고
두번째로 => 화살표는 다른 토큰을 치환하는 방법입니다.
자세한 방법은 밑에서 소개를 합니다.
Nori Tokenizer
Nori Tokenizer 는 한국어 형태소 분석기를 의미하며 "아버지가방에들어가십니다" 를 검색했을 때 "아버지" , "가방" , "들어" , "가신다." 처럼 한글을 나눠주는 역할을 합니다.
다른 예시로 "삼성전자" 는 "삼성" , "전자" 로 나뉘게됩니다. 아는 사전에 해당 단어가 없다면 더 작은 단위로 나누어 저장하는 방식입니다.
만약 "삼성" , "전자" 를 "삼성전자" 로 붙여서 사용하고 싶다면, 사용자 정의 사전에 추가를 해야합니다. user_dic.txt
사용자 정의 사전
사용자 정의 사전이란 색인 시 해당 단어로 검색할 수 있게 해주는 사전입니다.
보통 Tokenizer를 사용하면 사전에 검색할 수 있는 단어로 쪼개는데, 복합 명사와 같이 두가지 이상의 단어가 하나로 사용되는 것을 정의합니다.
사전을 정의할 때 단일어와 복합어를 구분하여 작성합니다
- 단일어의 경우 단일어 하나만 작성, 복합어의 경우 복합어를 작성 후 띄어쓰기 구분으로 단어 원형을 작성
ex ) 책가방 책 가방
ex ) 서울대학교 서울 대학교
ex ) 삼성전자 삼성 전자
사용자 정의 사전은 elasticsearch/config/user_dic.txt 로 저장됩니다.
사용자 정의 사전이 필요한 이유
만약 디 인퓨저 를 검색했을 때 디, 이, 퓨저 로 나뉘게 되어 정상적인 검색이 불가능합니다. 이를 위해 사용자 정의 사전을 활용하여 디 인퓨저가 비 정상적으로 나뉘는 경우를 막을 수 있습니다,.
동의어 ( 유의어 )
- 동의어 사전은 외래어 혹은 오타나 비슷한 뜻을 가진 단어, 약어 등을 정의하는 사전입니다. 이는
삼전, 삼성전자처럼 글자는 다르지만 같은 데이터를 검색하고 싶을 때 사용합니다.
해당 동의어 사전을 활용하면 삼전을 검색했을 때 삼성전자를 검색할 수 있습니다.
동의어 사전을 작성할 때에는 , 쉼표 단위로 나열하여 작성합니다.
또한 특정 단어를 다른 뜻으로 치환하여 색인할 수 있는데 이는 => 를 사용하면 가능합니다.
ex ) 치킨, 통닭, chiken
ex ) chiken => 치킨
보통 동의어 정의 사전은 elasticsearch/config/synonyms.txt 에 저장됩니다.
불용어
불용어는 색인시 포함이 되면 색인을 하지 않는 사전입니다. 불용어에는 조사, 접속사 등을 제외하고 줄개행 단위로 단어를 작성합니다.
ex ) 바보
ex ) 멍청이
ex ) 기타욕설
동의어 사전의 색인 or 검색 시점
동의어 사전은 색인 시점에 사용될수도, 검색 시점에 사용될 수도 있습니다.
색인 시점
색인 시점에 동의어 사전 필터를 사용하는 것은 색인된 용어들이 최종적으로 추가되거나 치환되어 역색인이 된다는 뜻입니다.
색인 시점에 동의어 사전 필터를 적용하면 다음과 같은 단점이 있습니다.
- 인덱스가 더 커질 수 있습니다. 모든 동의어가 색인되어야 하기 때문입니다.
- 단어의 통계 정보에 의존하는 검색 점수가 동의어 갯수도 계산에 포함되기 때문에 통계가 왜곡됩니다.
- 동의어 규칙이 변경된다 하더라도 기존의 색인이 변경되지 않습니다. 즌 기존의 색인을 모두 삭제하고 새로 생성해야합니다.
색인 시점에 동의어 사전 필터를 적용하면 성능이 가장 큰 장점이 됩니다. 확장 프로세스에 대한 대가를 미리 지불하여, 쿼리마다 매번 수행할 필요가 없기 때문입니다.
검색 시점
검색 시점에 동의어 사전 필터를 적용하는 것은 색인 시점에서 사용할 때 문제들 중 많은 부분이 발생하지 않습니다.
- 인덱스의 크기에 영향을 미치지 않습니다.
- 단어의 통계 정보가 동일하게 유지됩니다.
- 동의어 규칙이 수정되더라도 문서를 재색인할 필요가 없습니다.
일반적으로 검색 시점의 동의어 사용에 대한 장점은 색인 시점의 동의어를 사용할 때 보다 약간의 성능상 이점이 큽니다.
검색 시점의 동의어 사전은 사전이 변경됐을 경우 인덱스를 _Close 했다가 _Open 하여 Reload 를 해주어야 합니다. 노드가 다시 시작되거나 인덱스가 Reload 되었을 때 분석기가 인스턴트화 하기 때문에 이 작업이 필요합니다.
하지만 ElasticSearch 7.3 버전부터는 동의어 사전의 변경 사항을 적용하기 위해선 동의어 필터에 updateable 속성이 추가와 함께 _reload_search_analyzer API 를 활용하면 모든 분석기가 Reload 되도록 할 수 있습니다.
동의어 사전 업데이트
동의어 사전이 변경됐을 경우 이를 인식시키기 위해 index를 Reload를 해야합니다.
POST /test_index/_close
다음 요청을 통해 인덱스는 Close 상태가 되며 검색이 불가능해집니다.
POST /test_index/_open
인덱스를 다시 Open을 하면 인덱스가 Reload가 되며 업데이트된 동의어 사전을 작용할 수 있습니다.
참고
참고 블로그 1 : https://velog.io/@chs98412/%EC%97%98%EB%9D%BC%EC%8A%A4%ED%8B%B1-%EC%84%9C%EC%B9%98%EB%A5%BC-%EC%9D%B4%EC%9A%A9%ED%95%9C-%EA%B2%80%EC%83%89-%EA%B8%B0%EB%8A%A5-%EC%84%B1%EB%8A%A5-%EA%B0%9C%EC%84%A0
참고 블로그 2 : https://yeong-development-note.tistory.com/13
참고 블로그 3 : https://m.blog.naver.com/pjh08190819/222113052210
참고 블로그 4 : https://velog.io/@yeomyaloo/%EC%87%BC%ED%95%91%EB%AA%B0-%EB%A7%8C%EB%93%A4%EA%B8%B0-%ED%94%84%EB%A1%9C%EC%A0%9D%ED%8A%B8-%EC%97%98%EB%9D%BC%EC%8A%A4%ED%8B%B1-%EC%84%9C%EC%B9%98elasticsearch%EC%99%80-%EC%8A%A4%ED%94%84%EB%A7%81%EB%B6%80%ED%8A%B8-%EC%97%B0%EB%8F%99%ED%95%B4%EB%B3%B4%EC%9E%90
참고 블로그 5 : https://sooyeol86.blogspot.com/2019/12/elasticsearch-nori.html
참고 블로그 6 : https://medium.com/@qpark99/%EC%97%98%EB%9D%BC%EC%8A%A4%ED%8B%B1-%EC%84%9C%EC%B9%98-%EB%8F%99%EC%9D%98%EC%96%B4-%EB%B9%8C%EB%93%9C-%EC%8B%A4%ED%8C%A8-893216b7f1ec
참고 블로그 7 : https://mondayus.tistory.com/55
참고 블로그 8 : https://icarus8050.tistory.com/49
참고 블로그 9 : https://velog.io/@junsu1222/Elasticsearch-%EB%8F%99%EC%9D%98%EC%96%B4-%EC%82%AC%EC%A0%84%EC%9C%BC%EB%A1%9C-%EA%B2%80%EC%83%89-%ED%92%88%EC%A7%88-%ED%96%A5%EC%83%81#%EC%A0%95%EB%A6%AC
