
1. Introduction
1-1. Audio and Games
- 오디오는 거의 모든 게임에서 중요한 부분임. (오디오가 없으면 게임이 성립하지 않음) → 이 때문에 게임 개발에서 오디오 전문가가 있는 것
- 또한 이 오디오를 일관적이고 효율적으로 관리하기 위한 전문적인 기술이 필요함.
2. Windows Audio Architecture
2-1. Windows 10 Audio Stack Diagram [1]
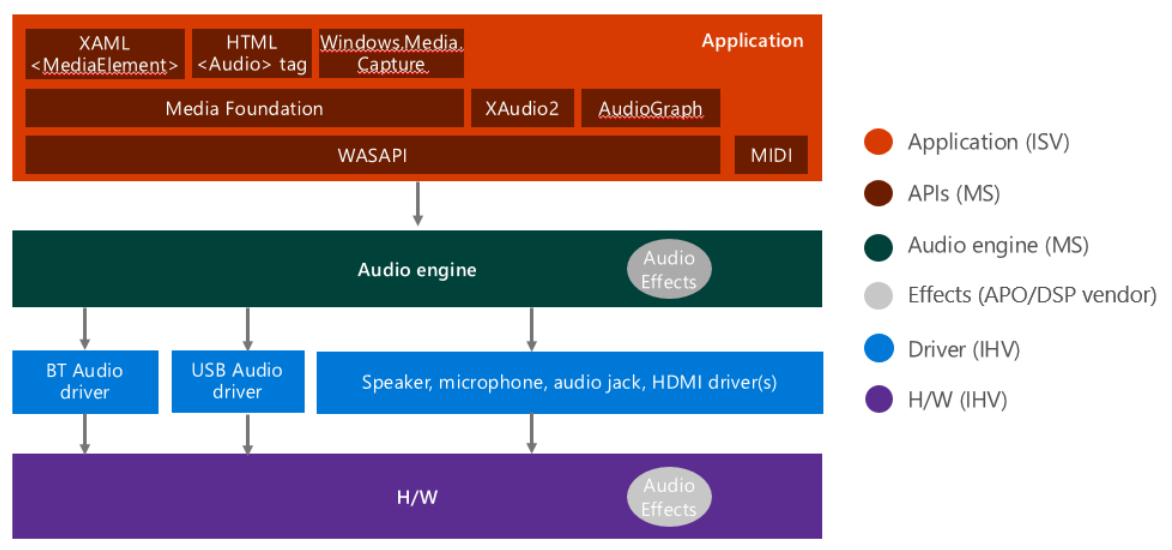
위 그림은 Windows 10 오디오 스택의 중요한 부분만을 모아놓은 것.
어플리케이션 레벨에서 MIDI 파일 등을 재생하는 등의 작업을 수행한 뒤 아래 레벨로 넘겨줌.
오디오 엔진에서는 규약에 따라 처리를 위한 준비를 함.
드라이버 레벨에서는 각 장치에 맞는 드라이버에 접근하여 출력 및 입력을 준비함.
하드웨어 레벨에서는 실제로 하드웨어를 통해 출력을 하거나 입력을 받음.
2-2. Top Level APIs [1]
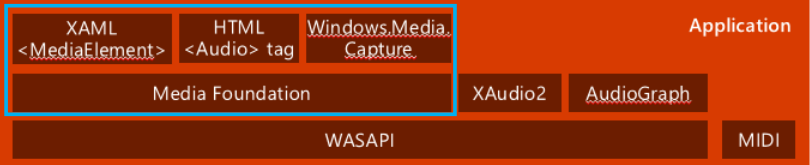
- 보통 어플리케이션 개발을 위해 사용하는 레벨.
- XAML : 디스플레이에서 비디오를 재생하거나 오디오를 출력할 때 사용하는 API
- Object를 통해 관리함. (상속 관계 : Object → DependencyObject → UIElement → FrameworkElement → MediaElement)
이 레벨의 API들은 주로 파일을 읽고, 재생하는 작업을 수행함.
- Media Foundation
-
보다 깊고 복잡한 handle을 제공함. (파일을 읽고 재생하는 API보다)
-
Windows Vista 이후로 Media Foundation이 디지털 미디어를 통한 어플리케이션 개발 등을 가능하게 하고 있음.
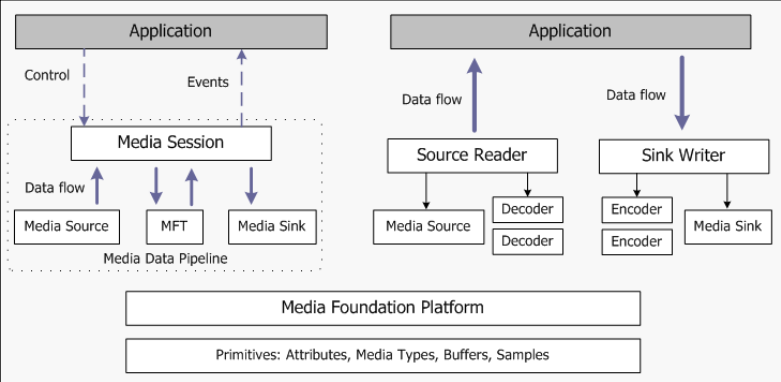
-
Media Foundation Architecture의 high-level view
-
왼쪽은 end-to-end pipeline for media data로, Media session이 외부에 있어 어플리케이션이 이를 control하고, 작업이 끝난 경우 event를 받는 식으로 진행됨. → media session 내부에서는 media source, MFT, media sink 등을 따로 관리함.
-
오른쪽은 직접적으로 데이터를 처리하는 부분으로, source를 직접 읽어서 그대로 writer에게 직접 전달해줌.
-
왼쪽은 오디오 재생 등은 잘 되지만 source streaming 자체에 대한 권한이 없어 source에 직접적으로 무언가 할 수는 없음. 다만 media session을 외부에 두기 때문에 추상적으로 사용할 수 있음. (세부 구조를 알 필요 없음)
-
오른쪽은 source 자체에 접근하여 수정하고 조작할 수 있다는 장점이 있지만, 이 모든 것들을 직접 구현해야 하기 때문에 다소 복잡함.
-
2-3. Low Level APIs
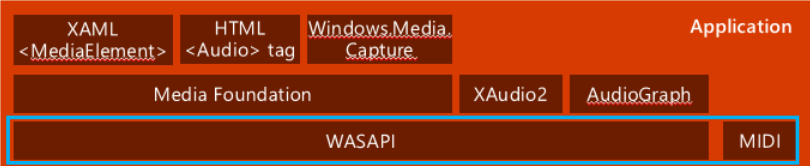
2-4. Low Level APIs (WASAPI)
- Windows Audio Session API (WASAPI)는 endpoint device와 어플리케이션 사이의 데이터 흐름을 관리함.
- Endpoint device [2]
- 스피커와 같이 어플리케이션 프로그램에서 시작하거나 끝나는 데이터 경로의 끝에 있는 디바이스를 말함.
- 어플리케이션과 endpoint device 사이에는 수많은 처리가 들어갈 수 있는데, 혼란을 막기 위해 시작 지점과 끝 지점을 명시하는 것
- ex) 스피커, 헤드폰, 마이크 등
- 오디오 데이터 재생을 위해 명령을 내리면, 이 데이터는 수많은 소프트웨어와 하드웨어 장치를 거쳐 endpoint device까지 이동하게 됨.
- 사실 사용자 입장에서는 중간에 무슨 동작이 일어나는지 관심이 없음. 따라서 endpoint device 차원에서 데이터 흐름을 관리하기 위해 endpoint device라는 개념을 만든 것.
- WASAPI에 접근하려면
IMMDevice::Activate를 호출하여 초기화를 진행해주어야 함.
- Endpoint device [2]
2-5. Low Level APIs (MIDI)
- Musical Instrument Digital Interface (MIDI)는 신디사이저와 같은 음향 기기와 컴퓨터 간의 연결을 위한 프로토콜 (.wav, .mp3와는 다른 파일 형식임)
- 장치 간 message-passing을 기본 아이디어로 함.
- MIDI 파일에는 액션 자체가 기록됨. ex) 키보드 버튼을 누름.
- 이 액션을 통해 규약에 맞게 신디사이저와 같은 음향 기기에서 소리를 재생함.
- 컴퓨터는 사운드 자체를 기록하지 않는다.
- Win32 API는 MIDI 데이터를 다루기 위해 다음과 같은 인터페이스를 제공함.
-
Media Control Interface (MCI)
- MCI는 MIDI 파일을 재생함.
- 어플리케이션은 MCI를 사용하여 쉽게 MIDI 파일을 재생할 수 있음.
- but, MCI는 MIDI output만을 지원함. (단점)
- 또한 MIDI event와 다른 real-time event 간의 동기화를 제공하지 않음.
- 따라서 MIDI synchronization을 위해서는 stream buffer나 MIDI service를 사용해야 함.
-
Stream Buffer
- time-stamped MIDI data를 관리함. (시간 간격마다 기록)
- MCI는 단순 재생 동작만을 수행한 반면, stream buffer를 사용하면 더욱 다양하고 정확한 처리를 수행할 수 있음.
- MIDI event의 timing information은 보통
dwDeltaTime에 저장됨. (MIDIEVENT구조체의 멤버) - 시간은 tick의 형태로 주어지며 (tick은 운영체제나 시스템마다 다름), Standard MIDI Files 1.0 specification에 정의되어 있음.
- 특정 시간 구간의 데이터를 읽을 때 stream buffer를 사용함.
-
MIDI Service
- MIDI data를 최대한 정교하게 다루기 위해 MIDI service를 사용함.
- MIDI를 진심으로 다루는 개발자들은 MIDI service를 사용하여 작업을 하고, MIDI authoring or sequencing tools 등이 있음.
-
2-6. Audio Engine
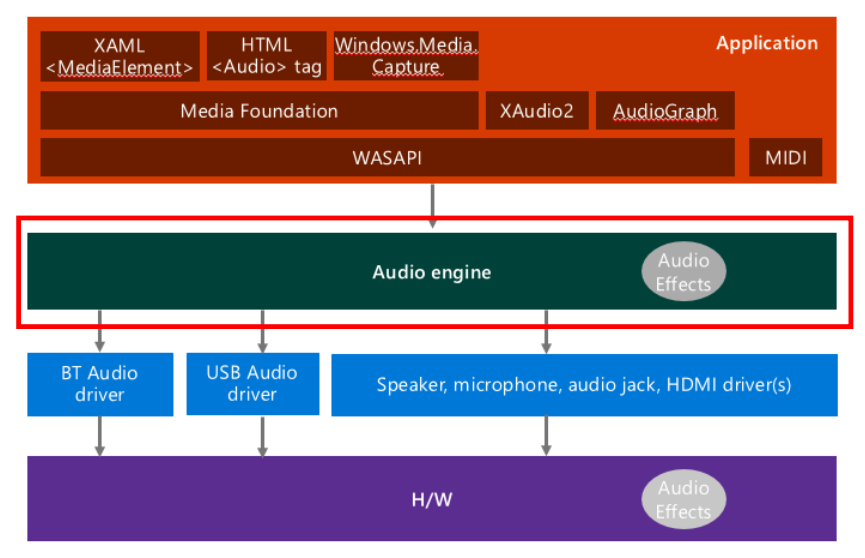
- 오디오 엔진에서는 audio stream을 처리함. (high level에서 내려온 데이터들)
- Audio Processing Objects (APOs)를 로드하는데, 이는 Hardware-specific plugin으로써 오디오 데이터를 특정 하드웨어에 맞는 형태로 처리함.
- WaveRT Port Driver, Windows Audio Processing Objects 등에 자세한 정보가 나와있음.
2-7. Audio Drivers
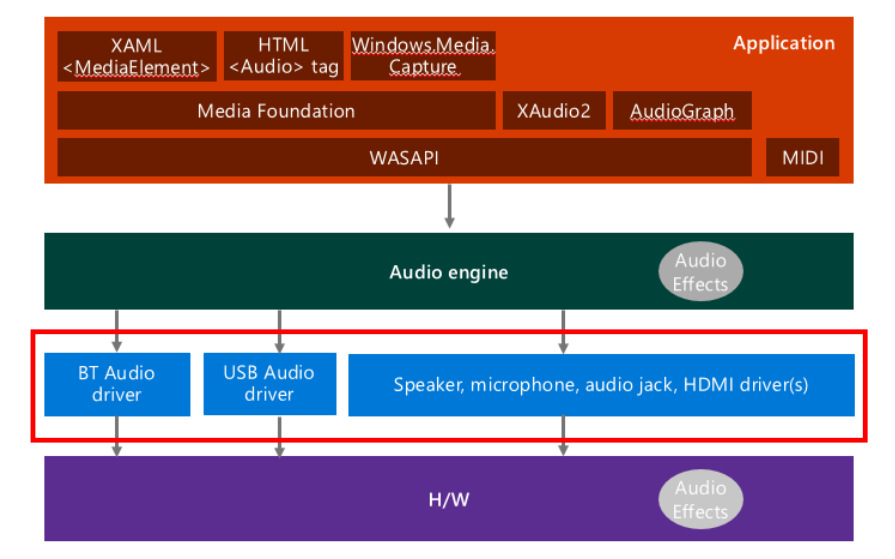
- 오디오 엔진에서 처리하는 Hardware-specific한 정보들을 실제로 처리하는 부분
- 특정 하드웨어의 audio stream에 맞는 드라이버를 통해 오디오 스택을 처리함.
- ex) 스피커, 마이크, 헤드셋/헤드폰, USB 장치, 블루투스 장치, HDMI 등
- 드라이버가 없으면 오디오 데이터가 특정 하드웨어에서 재생할 수 있는 형태로 가공되지 않음.
Hardware
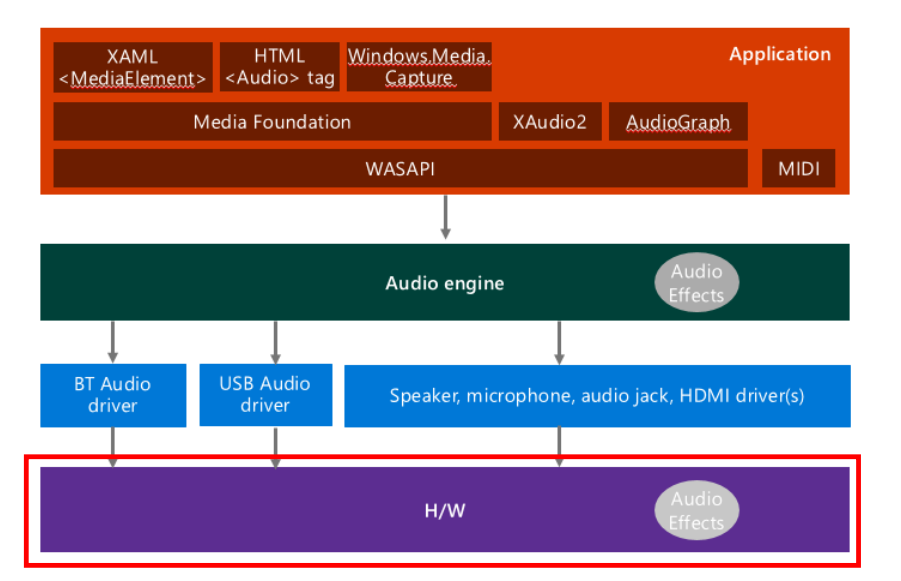
- 실제 하드웨어 (스피커, 마이크, external device 등)을 통해 오디오를 재생함.
3. Audio Development and Terminology
3-1. Digital Audio [3]
- 디지털 오디오란 “녹음되거나 만들어진 sound를 디지털의 형태로 표현한 것”임.
-
디지털 오디오에서 음향 신호의 sound wave는 일반적으로 numerical sample로 인코딩됨.
- 아날로그 데이터가 디지털로 변환되는 것을 A-D, 반대의 경우를 D-A라고 표현함.
아날로그 오디오 → 디지털 오디오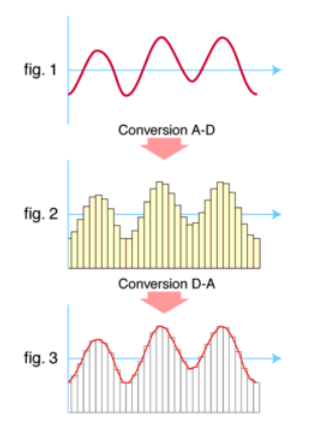
-
Analog-to-Digital Converter (ADC)를 통해 아날로그 신호를 디지털 신호로 바꿔줌.
-
전자학적으로 ADC는 아날로그 신호를 디지털 신호로 바꿔주는데, 이러한 conversion에 quantization of the input (양자화)가 들어가기 때문에 약간의 에러나 노이즈가 발생할 수 있음.
→ quantization : 아날로그를 디지털로 바꾸는 과정에서, 연속적인 데이터를 대략적인 데이터로 표현하는 것. 이를 통해 정교하지는 않지만 그럴듯한 소리로 바꿀 수 있지만, 데이터의 손실이 발생함.
(아날로그의 모든 데이터를 표현할 수 없기 때문에 대략적으로 표현함) -
sampling rate가 높을수록 더욱 정교하게 데이터를 가져올 수 있고, 낮을수록 대략적이고 큰 폭으로 데이터를 가져오게 되므로 손실이 발생할 가능성이 높아짐.
-
- 디지털 오디오 기술은 오디오가 사용되는 거의 모든 곳에 사용됨.
- 디지털 오디오가 생기기 전에는 카세트 테이프 등으로 음악을 물리적으로 copy했음. (레코드판의 홈)
- 아날로그 오디오가 나오면서 physical waveform을 전자 신호로 바꿀 수 있게 되었음.
- 아날로그 신호는 노이즈에 약함. 물리적인 파동을 전자적인 신호로 바꾸는 과정에서 노이즈의 방해를 받아 distortion (왜곡) 등이 발생할 수 있음.
- 반면 디지털 신호는 인코딩 기술이 좋기 때문에 노이즈에 강하도록 설계가 가능하며, 에러 없이 오디오가 재생되도록 할 수 있다는 장점이 있음.
3-2. Digital Audio Compression
- digital audio compression은 오디오 데이터를 압축하여 효율적으로 저장하고 transmission이 가능하게 함.
- 언제나 데이터의 크기를 줄이는 것은 hot issue
- 오디오 압축 방식에는 Lossy (손실)과 Lossless (무손실)이 있는데, 두 방식 모두 redundancy (중복)를 줄이는 것을 목표로 함. coding, quantization, discrete cosine transform, linear prediction 등의 method를 사용함. → 불필요한 데이터를 줄임
- lossy compression은 약간의 데이터 손실을 감수하면서도 극한의 압축 효율을 자랑하고, 이 때문에 많은 오디오 어플리케이션에서 이 방식을 사용하고 있음.
- psychoacoustics라는 이론에 기초하여 잘 들리지 않는 사운드를 줄임.
- 압축률 : 80 ~ 90%
- AC-3, MP3, AAC, MP4, Vorbis, WMA 등에서 사용하는 압축 방식
- lossless compression은 encoding, decoding 과정을 거치더라도 원본 데이터를 손실하지 않음.
- 압축률 : 50 ~ 60% (오디오 뿐만 아니라 다른데이터의 경우에도 비슷한 비율)
- curve fitting이나 linear prediction과 같은 알고리즘을 기반으로 함.
- FLAC, ALAC, APE, OFR, WV, TTA, MPEG-4 ALS 등에서 사용함.
- 주로 전문가들이 사용하는 압축 방식 (손실이 있으면 안되는)
3-3. Digital Audio Compression - Psychoacoustics
-
psychoacoustics는 오디오 자체의 특징과 이를 받아들이는 사람의 수용기 (귀)의 특징이나 감각 등을 결합한 학문 [5]
-
Loudness는 sound intensity에 대한 주관적인 평가임. 이 감각은 loud & soft sound를 구분하도록 만듬.
- 다만 loud & soft가 사람마다 느끼는 정도가 다르고, 또 상황마다 다르기 때문에 이를 학문적으로 표현하기 위해 몇 가지 기준점이 존재함.
- Absolute threshold of hearing
- 매우 조용한 환경에서 소리를 재생했을 때 소리가 났음을 인식하는 정도
- 당연하게도, 사람마다 다름. (너 들었어? 아니 난 못들었는데?)
- Discomfort level
- 소리를 재생했을 때, 그 소리가 불편하다고 느끼는 정도
- 역시 사람마다 다름. (아 불편해.. 읭? 난 괜찮은데?)
- Normal thresholds
- 여러 명의 사람들을 놓고 실험했을 때, 불편하다고 느끼는 discomfort level의 평균적인 정도
- 소수의 의견까지 고려하지는 않고, 대중적이고 일반적인 의견을 고려함.
-
absolute threshold of hearing과 discomfort threshold 사이의 영역을 통해 person’s auditory field (청각 범위)를 정의할 수 있음. (사람이 들을 수 있는 정도) 이 영역의 dynamic range는 두 threshold 사이의 거리에 의해 결정됨. [6]
- 인간의 auditory field는 0 db SPL ~ 120 db SPL임.
- 이는 귀가 가장 민감하게 반응하는 0.5 ~ 8 kHz의 주파수에 해당함.
- 낮은 영역과 높은 영역의 주파수의 경우 hearing threshold에 도달하기 위해서는 높은 SPL이 필요함. → 주파수가 너무 낮거나 너무 높은 경우 가청 영역이 좁음.
- conversation area → 사람들의 대화에 해당하는 영역
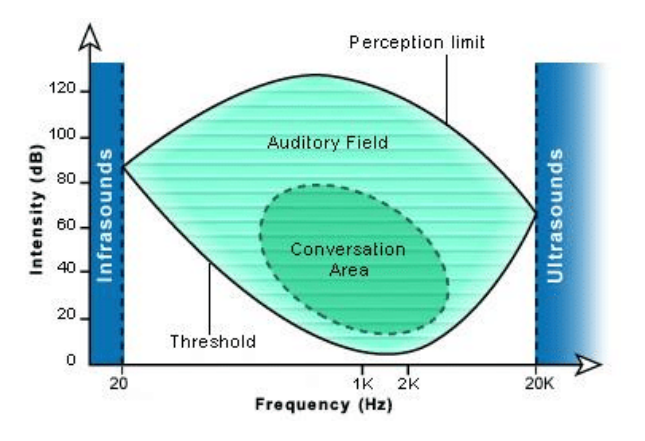
Sound Pressure Level (SPL)
sound level은 사람마다 다르게 인식되기 때문에 평균적이고 절대적인 기준을 통해 비교할 필요가 있음.
sound pressure란 소리가 발생했을 때 공기를 미는 압력을 말함.
이러한 개념을 통해 기준이 되는 값이 정의되어 있으며, SPL은 이 값을 기준으로 얼마나 차이가 있는지를 나타내게 됨.
0 dB SPL은 사람 귀에 들리지 않는 정도임.
- Phons [7]
- 같은 데시벨을 갖는 소리를 재생했다고 해서 모든 사람이 이를 같은 데시벨로 인식하지는 않을 것.
- 즉, 같은 intensity를 갖는 소리를 재생했다고 해도 사람들이 같은 loudness로 인식하지는 않는다는 의미.
- 사람의 청각 민감도가 주파수에 따라 다르기 때문에, 여러 사람들의 평균적인 값을 토대로 equal loudness curve를 만들었음. → 이 정도 데시벨에서는 어느 정도의 loudness를 느끼는구나!
- 1000 Hz를 표준 주파수로 설정한다면, 1000 Hz가 equal loudness curve의 기준값이 됨. (1000 Hz에서의 값을 기준으로 phon을 정의함)
- 주파수와 세기가 달라졌다고 해도 equal loudness curve에 있는 소리는 같은 phon을 가짐.
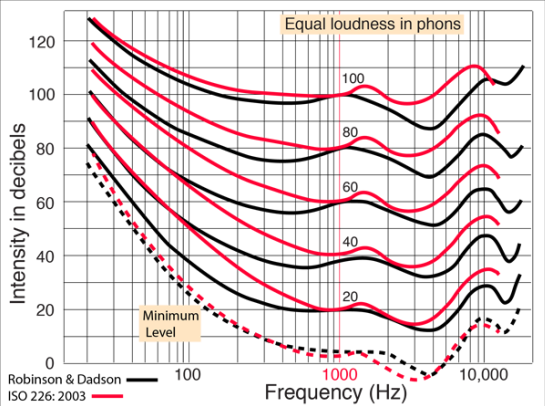
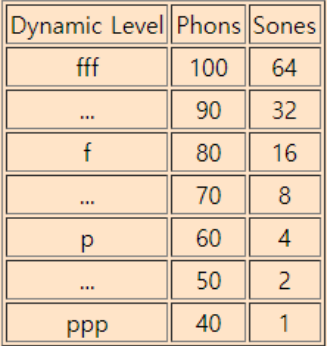
- Sones [7]
- phon은 loudness를 측정하기 위한 수단이었음. 하지만 직접적으로 loudness에 비례하지는 않음. (같은 주파수를 갖는데 phon이 다른 경우도 있고, 다른 주파수를 갖는데도 phon이 같은 경우도 있음)
- 따라서 loudness를 잘 표현하기 위해 loudness의 linear scale을 표현하는 것이 sone
- 오케스트라 음악이 일반적으로 40 ~ 100 phon이라고 가정하고, 가장 작은 phon을 갖는 것을 1 sone으로 정의한 다음 linear하게 증가하는 방식으로 sone을 정의함.
- equal loudness contour은 특정 주파수에서의 loudness를 정의하고, 주파수가 달라졌을 때 어느 정도의 세기를 가져야 같은 loudness로 인식할지에 대한 것
- 1930년대 Fletcher와 Munson의 연구로 equal loudness curve가 개발되었으며, 이를 통해 사람의 귀가 loudness에 어떻게 대응하는지 이해할 수 있었음.
- 따라서 equal loudness contours를 Flethcer-Munson curve라고도 함.
- ISO 226 국제표준임.
- 주파수가 작은 소리는 “낮은 소리”이고, 주파수가 큰 소리는 “높은 소리”임.
- 주파수가 작은 소리는 외부 노이즈에 강하고, 주파수가 큰 소리는 외부 노이즈에 약하며 잘 묻힘.
- 사람의 귀는 높은 주파수 소리에 민감함. (엄마의 목소리를 더 잘 듣는다 등)
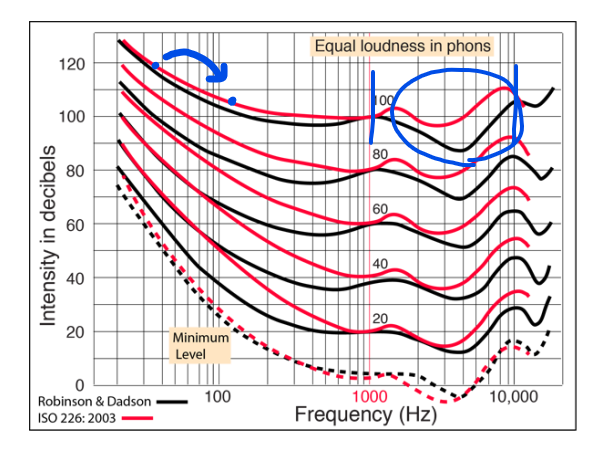
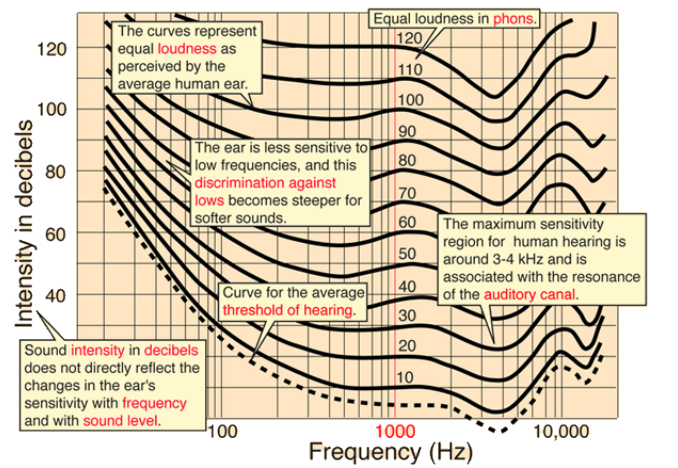
- 즉, 낮은 주파수에서 높은 주파수로 이동하면 소리의 크기가 줄어들더라도 같은 loudness로 인식함.
- 또한 2000 ~ 5000 Hz 정도의 범위에 그래프가 급격히 낮아지는 부분이 존재하는데, 이는 사람의 귓바퀴가 이 영역의 소리를 잘 증폭시키기 때문. → 따라서 소리를 더 크게 인식함. 기준점이 낮아짐.
- 저주파수 영역에 있는 소리들은 잘 인식하지 못하고 세기가 커야만 인식하는 모습을 보이고, 높은 주파수는 크기가 작아도 잘 인식되는 모습을 보여줌.
- equal loudness curve의 또다른 예시
-
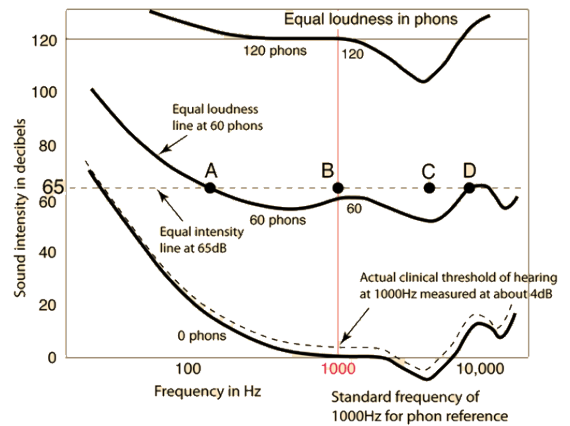
“very soft”, “midrange”, “very loud” sound에 대한 equal loudness curve가 제시되어 있음.
-
sound level에 따라, 주파수에 따라 소리를 다르게 인식하는 것이 그래프의 모양 등에서 나타남.
-
very loud sound의 경우 세기의 변화가 크지 않고 “flatter”한 모습을 보이는 반면, very soft sound는 매우 큰 변화가 일어나고 있음.
-
귓바퀴가 소리를 증폭시키는 영역인 2000 ~ 5000Hz 영역에서는 소리의 세기가 낮아진 모습을 볼 수 있음. → 이 영역에 대해서는 민감하게 반응함.
- 특히 높은 주파수를 갖는 소리를 증폭시킴 (성인의 경우 2000 ~ 4000 Hz 영역에 있는 소리)
- 증폭의 정도는 사람마다 다르고, 귀의 길이, 부피, 곡률 등에 따라 다름.
-
65 dB에서 A, B, C, D를 비교함.
- A와 D는 같은 loudness를 가짐. (60 phon)
- B, C는 60 phon보다 높은 loudness를 가짐. (B < C)
- 즉, 같은 데시벨의 소리일지라도 equal loudness curve에 따라 다른 loudness를 가질 수 있음.
-
Reference
[1] https://docs.microsoft.com/en-us/windows-hardware/drivers/audio/windows-audio-architecture
[2] https://docs.microsoft.com/en-us/windows/win32/coreaudio/audio-endpoint-devices
[3] https://en.wikipedia.org/wiki/Digital_audio
[4] https://mynewmicrophone.com/the-complete-guide-to-audio-compression-compressors/
[5] http://www.cochlea.eu/en/sound/psychoacoustics/
[6] https://www.researchgate.net/figure/Auditory-graphic-for-human-ear-1_fig2_312500129
[7] http://hyperphysics.phy-astr.gsu.edu/hbase/Sound/phon.html#c1
[8] https://support.ircam.fr/docs/AudioSculpt/3.0/co/Masking%20Effect%20Intro.html
