이 글은 T아카데미-아파치 카프카 입문영상을 참고하여 글을 정리하는 것이다. 본 실습 영상에서는 구성환경이 다르기 때문에 본 강의와 다르게 파이썬으로 연습하였다.
1.Kafka(카프카)란?
Apache Kafka는 실시간으로 기록 스트림을 게시, 구독, 저장 및 처리할 수 있는 분산 데이터 스트리밍 플랫폼이다.
예를 들어 링크드인의 데이터 처리 시스템 구조를 보겠다.
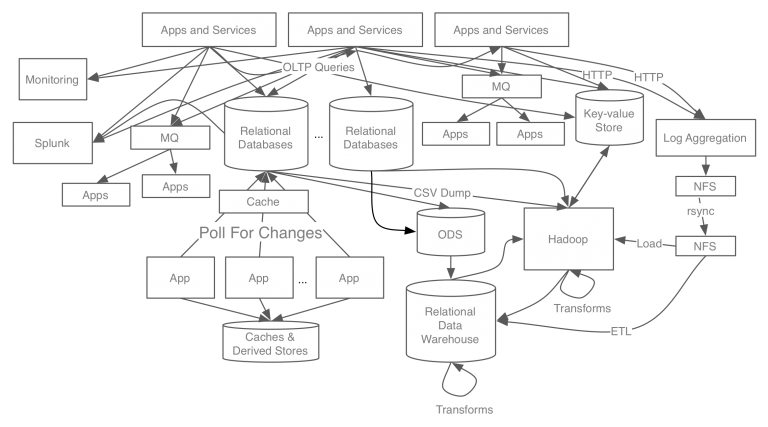
구조를 보면서 느끼는 가장 큰 것은 복잡하다는 것을 알 수 있다. 그리고 새로운 시스템을 확장하는데 있어 어렵다.
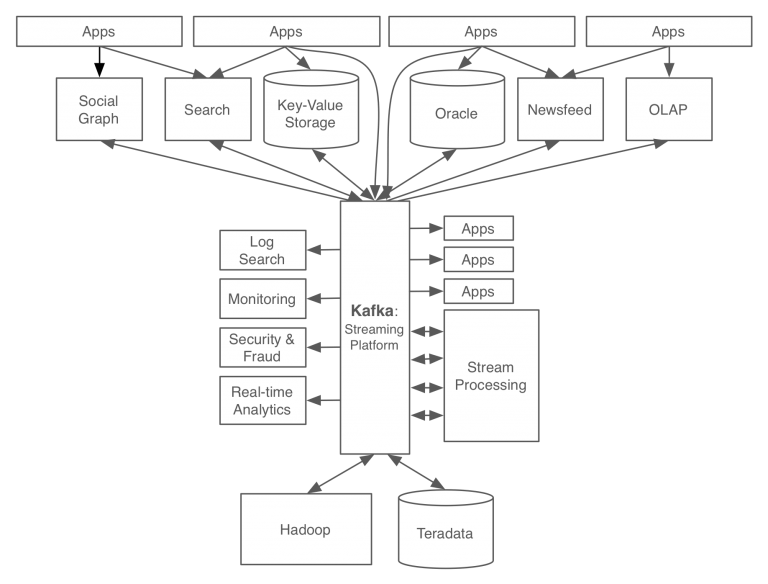
다음은 카프카 도입후 데이터 처리 시스템 구조이다. 카프카를 적용함으로써 모든 이벤트/데이터의 흐름을 중앙에서 관리할 수 있게 되었으며, 서비스 아키텍처가 기존에 비해 관리하기 심플해진 것을 알 수 있다.
2. 카프카 구성요소(명칭)와 작동방식
2-1. 카프카 구성요소
Kafka는 발행-구독(publish-subscribe) 방식으로 동작하며 다음과 같은 요소(producer, consumer, broker)로 구성된다.
아래의 그림은 단일 서버(broker) 기준 kafka의 동작방식을 나타낸다.
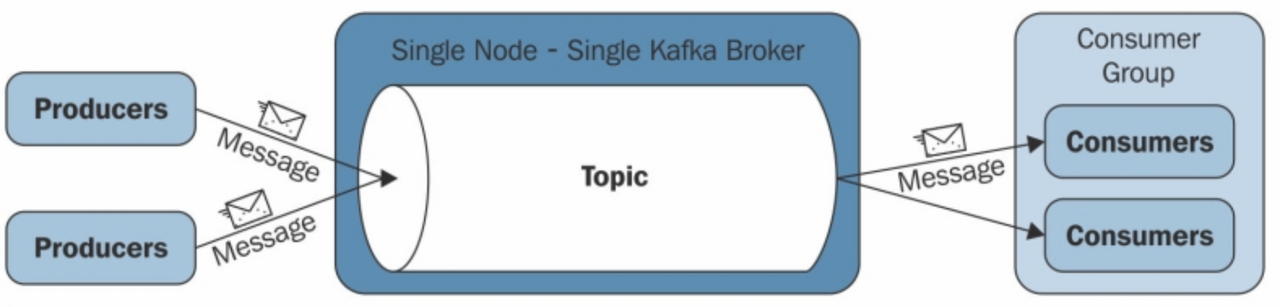
- Producer
Producer는 데이터를 생산하는 주채로 예를 들어 공공데이터 포탈의 데이터나 기계에 달려있는 센서 등 데이터를 생산하는 모든 개채를 말한다. Producer는 생산된 데이터를 Topic이라는 저장?공간에 집어 넣어 준다. - Broker
Kafka의 Node즉 클러스터 단위 1개를 Broker라고 칭한다 Producer와 Consumer의 중간 단계에서 두 사이의 데이터 중계 역할을 담당하기에 이름을 이렇게 부르는것 같다. - Topic
일종의 저장공간으로 Producer로 부터 데이터를 받아 저장하고 있다. 각각의 Topic은 이름이 부여되어 있으며 이 저 장된 데이터를 Consumer가 요청하면 그쪽으로 보내어 활용할 수 있다. (Topic의 내부는 조금있다 더 자세하게 다루어 보자) - Consumer
데이터를 소비하는 주체로서 Topic에게 데이터를 요청하여 "소비" 한다는 개념으로서 이름이 Consumer로 지어진 것 같다.
여기서 중요한점은 Producer와 Consumer는 직접적인 관계를 가지지 않으며 중계소인 Broker Topic을 통해서 데이터가 교환 되기 때문에 "비동기식"이라고 한다.
2-2. 작동방식
1.프로듀서는 새 메시지를 카프카에 전달
2.전달된 메시지는 브로커의 토픽이라는 메시지 구분자에 저장
3.컨슈머는 구독한 토픽에 접근하여 메시지를 가져옴 (pull 방식)
3. 구성요소 특징 및 상세
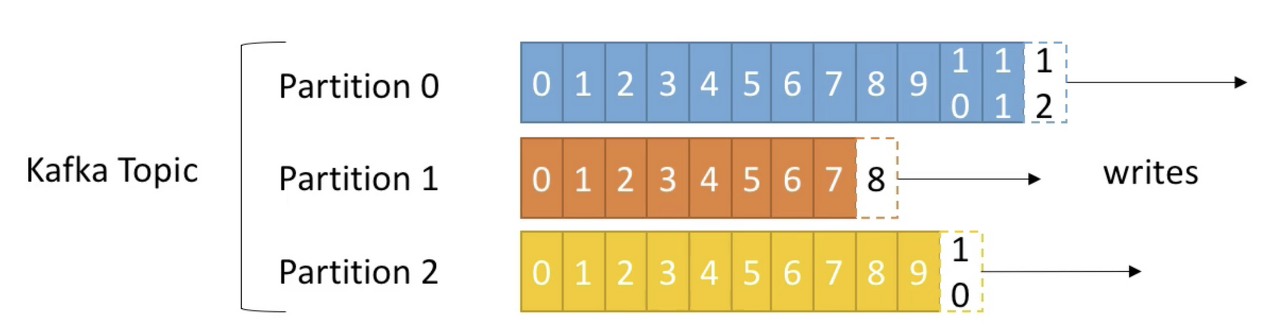
3-1. 토픽(Topic)
특정 스트림 데이터이며, 카프카 클러스터에 데이터를 관리할 시 기준이 된다.
특징
- Similar to a table in a database (without all the constraints)
- 원하는 수만큼 토픽은 가질 수 있다.
- 토픽은 토픽 이름(=name)으로 구분됨
- 토픽은 파티션으로 나눠서 처리되며 각 파티션은 순서가 있고 각각의 파티션 내 메시지는 offset이라는 단위로 고유 id가 증가한다. 스트리밍 처리를 할때 해당 파티션이 어디까지 데이터를 전송했는지가 이 offset번호로 기억된다.
- 파티션(Partition): 각 토픽 당 데이터를 분산 처리하는 단위. 카프카에서는 토픽 안에 파티션을 나누어 그 수대로 데이터를 분산처리 한다. 카프카 옵션에서 지정한 replica의 수만큼 파티션이 각 서버들에게 복제된다
(replica로 복제된 파티션은 Cluster 그룹내에 있는 다른 kafka에 동일하게 저장된다)
- offset은 특정 partition 에서만 의미가 있으며 순서 또한 속해있는 파티션 내에서만 보장된다. (즉, 'partion 0의 offset 3'은 'partion 1의 offset 3'에 있는 데이터와 다르다.) - 데이터의 보존 주기는 default 7일이고 변경 가능하다. (log.retention.hours/log.retention.check.interval.ms=300000 설정)
- 데이터가 특정 파티션에 쓰여지면 절대 변경되지 않는다. (새로운 데이터는 새로운 파티션-오프셋에 쓰여짐)
- 특정 키로 파티션을 지정하지 않으면, 데이터는 랜덤하게 파티션이 지정되어 쓰여진다.
- 파티션의 개수도 설정으로 지정이 가능하다(num.partitions=x) 설정후 생성되는 토픽의 파티션 초기 설정이 x값으로 지정된다.
- 데이터 처리량에 따라 Partition을 조정해야 한다.
- 파티션의 개수에 따라 연결할 수 있는 Consumer의 개수가 다르다 설정된 파티션의 개수보다 Consumer가 많은 경우 Consumer가 동작하지 않을 수 있다.
3-2. Brokers
- Kafka Cluster는 여러대의 broker(server)로 구성된다.
- 각 broker는 고유한 id 값으로 구분되며 특정 topic partition을 포함한다.
- bootstrap broker라 불리는 어떤 broker 에나 연결이 된다면, 전체 클러스터에 연결된 것이다.
- 통상 3개의 broker로 운영을 하는게 이상적이나 기업과 시스템의 규모에 따라서 100개 이상의 broker를 클러스터로 구성하여 운영하는 경우도 있다.
- Kafka topic 파티션의 Replication Factor(RF)는 broker 설정 중 offsets.topic.replication.factor에 의해 결정된다. 기본 값은 3으로, 하나의 파티션이 총 세 개로 분산 저장된다. (아래 사진은 replication factor가 2인 모습 -> leader 파티션 1 + ISR 파티션 1 / ISR = In-Sync Replica)
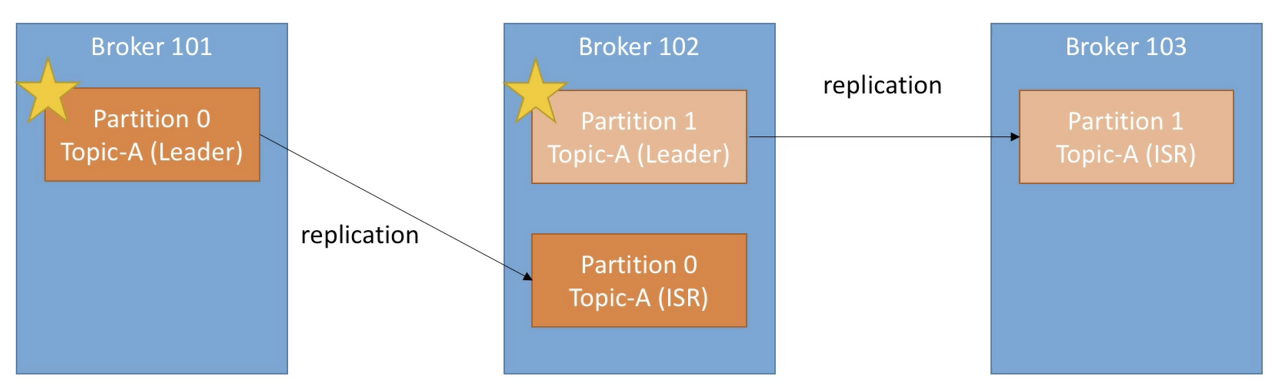
3-3. Producers
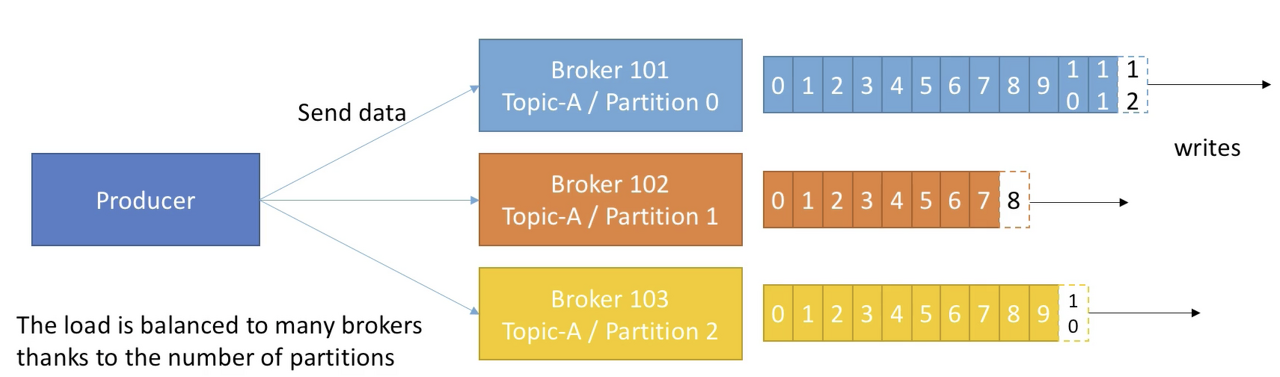
- Producer는 topic에 데이터를 write 한다.
- Producer는 데이터를 쓰는 때에 자동적으로 어떤 브로커와 파티션에 데이터를 write 할지 알고있다.
- Producer는 데이터를 write 할 때의 receive acknowledgment 를 선택할 수 있다.
acks=0 : Producer는 acknowledgment를 기다리지 않음(데이터 손실 가능성이 있다.)
acks=1 : producer는 leader acknowledgment를 기다렸다가 다음 액션을 함(제한된 데이터 손실 가능성)
acks=all: leader+ISR acknowledgment를 모두 기다림(no data loss)
3-4. Consumers
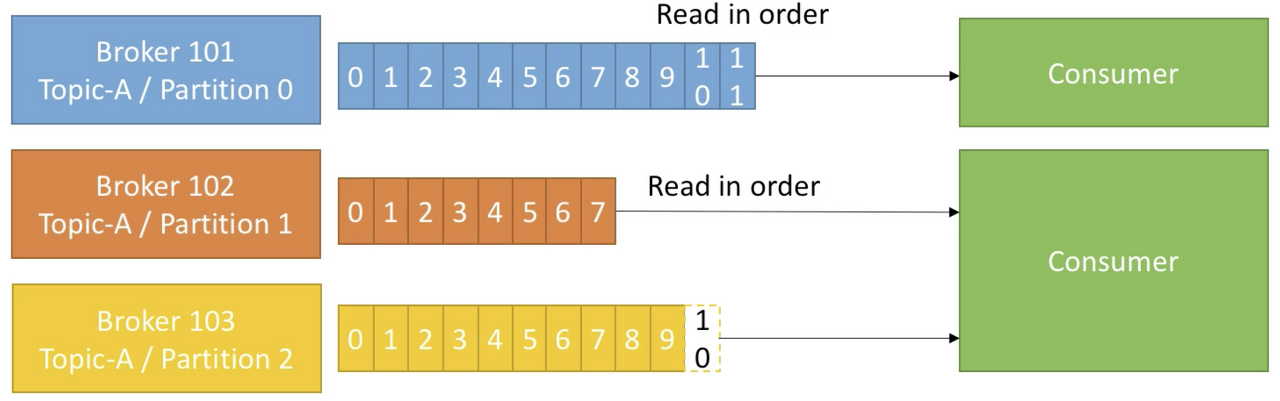
- Consumer는 topic에 있는 데이터를 read 한다.
- Consumer는 데이터를 읽을 때에 자동적으로 어떤 브로커와 파티션에서 데이터를 read 할지 알고있다.
- 데이터는 각 파티션 내에서 순서대로 읽어온다
4. Zookeeper
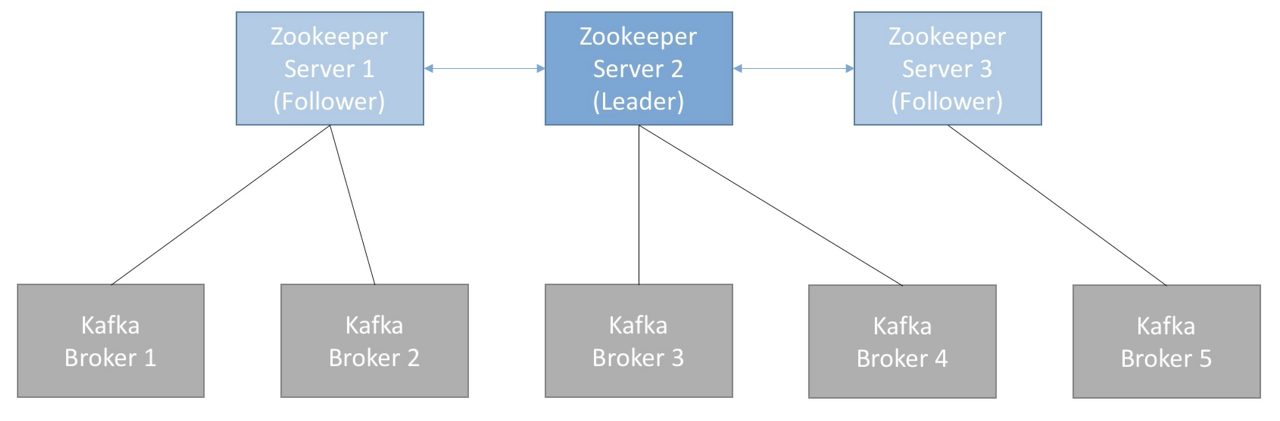
Zookeeper는 분산 코디네이션 시스템이다.
카프카 브로커를 하나의 클러스터로 코디네이팅하는 역할을 하며, 카프카 클러스터의 리더(Leader)를 발탁하는 방식을 제공한다.
새로운 토픽 생성, 브로커 서버 다운 등 모든 카프카 클러스터 내 변화들에 대하여 알림을 준다.
카프카는 주키퍼 없이는 작동할 수 없다.
보통 홀수 개의 서버 (3,5,7)수로 주키퍼는 운영됨
consumer offset은 zookeeper가 가지고 있지 않다. (-> kafka topic 내 저장함 after v0.10)
참고 사이트
- https://tacademy.skplanet.com/live/player/onlineLectureDetail.action?seq=183
- https://todaycodeplus.tistory.com/10?category=988491
- https://velog.io/@jaehyeong/Apache-Kafka%EC%95%84%ED%8C%8C%EC%B9%98-%EC%B9%B4%ED%94%84%EC%B9%B4%EB%9E%80-%EB%AC%B4%EC%97%87%EC%9D%B8%EA%B0%80#2-%EB%A9%94%EC%8B%9C%EC%A7%95-%EC%8B%9C%EC%8A%A4%ED%85%9C
