로지스틱 회귀란?
회귀를 사용하여 데이터가 어떤 범주에 속할 확률을 0에서 1사이의 값으로 예측하고 그 확률에 따라 가능성이 더 높은 범주에 속하는 것으로 분류해주는 알고리즘이다.
Classification 알고리즘들 중에서 굉장히 정확도가 높은 알고리즘으로 알려져 있다.
이번 시간에는 Classification 중에서 Binary Classification으로 둘 중에 무엇에 속하는지를 판별하는 알고리즘을 생각할 것이다. 예를 들면 스팸 감시가 될 수 있다. 특정 메일이 왔을 때 그 메일이 스팸인지 아닌지에 대한 판별이 필요하다. 다른 예시로 페이스북 피드가 있다. 페이스북의 타임라인에 모든 자료를 보여주는 것이 아니라 사용자에게 알맞은 정보를 보여주기 위해 특정 정보에 대해 보여줄 것인지 아닌지를 판별하는 방법이 필요하다. 사용자의 예전 흔적들을 통해 학습을 해서 새로운 정보에 대한 판별을 진행하는 것이다. 이 때 두 가지의 답을 encoding할 때 0과 1을 사용하게 된다. 보여주는 것을 1, 가리는 것을 0이라는 것처럼 나타나게 된다.
Classification에 대해 배우기 위해 공부한 시간에 따른 시험의 pass or fail에 대한 결과를 예측하는 알고리즘을 생각해보자. 2시간을 공부하면 fail이다. 3시간을 해도 4시간을 해도 fail이 나타난다. 하지만 5시간을 넘어서면 pass를 하게 된다. 이를 통해 학습을 한다.
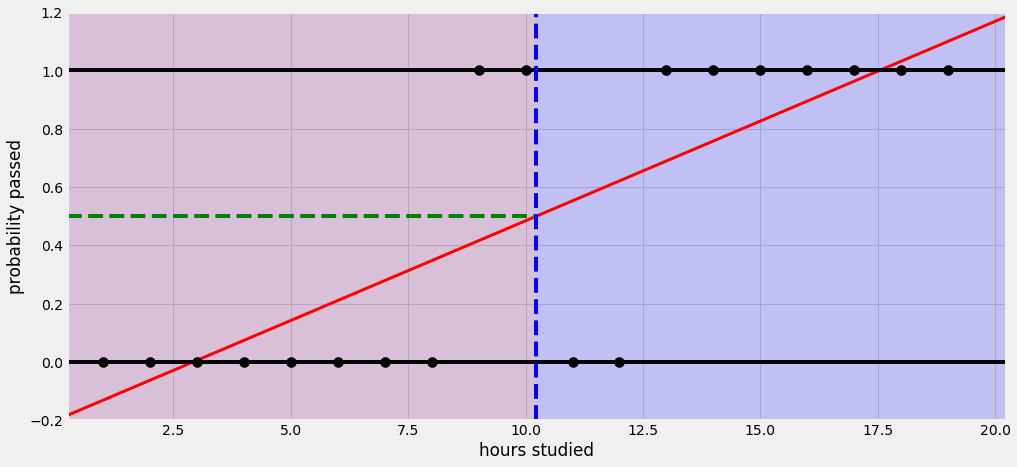
그런데 이 알고리즘을 사용하면 문제가 발생할 수 있다. 지금은 fail한 시간과 pass한 시간의 data가 같지만 만약 50시간을 공부했을 때를 생각해보자. Linear한 선형을 가지고 예측을 하겠지만 실제로 50시간 공부를 했을 때 가지는 값은 pass인 1의 값을 가지게 된다. 이러한 데이터를 다시 학습시키게 되면 앞에서 예측한 Linear 선형의 기울기가 낮아지게 된다. 그러면 앞의 기준인 0.5로 다시 판별하게 되면 합격인데도 불구하고 불합격으로 판별 받을 수 있게 된다.
또한 예측한 결과 값이 1과 0의 형태가 아니라 수많은 값을 가질 수 있게 된다. 5시간을 공부해도 50시간을 공부해도 실제로 결과 값은 1인데 Linear Regression을 사용하게 되면 예측 값은 다르게 나오기 때문이다.
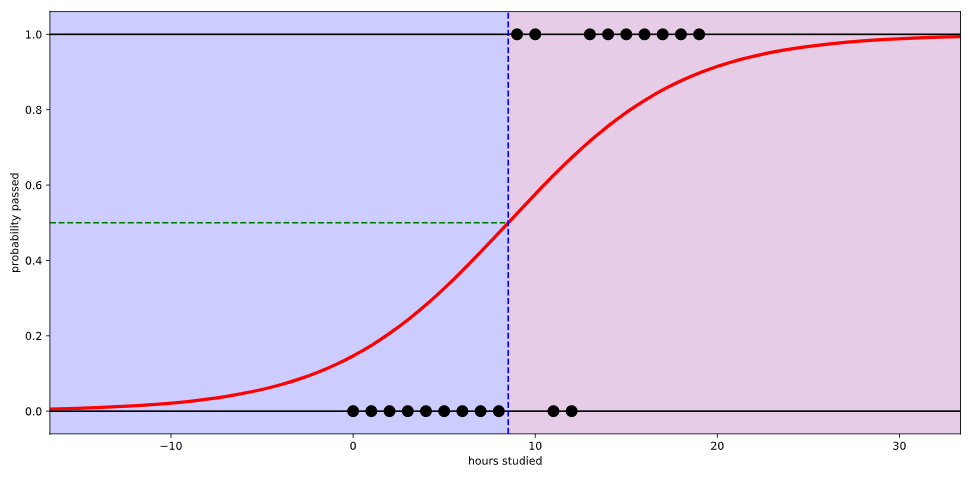
Linear Regression이 단순하고 편리해서 사용하긴 좋은데 위와 같은 문제로 인해 Classification하기 위해서 0과 1사이의 값을 가지는 수로 바꾸어주려고 한다. 이런 함수가 존재하는데 바로 sigmoid 함수이다. sigmoid 함수를 이용하게 되면 어떤 한 값을 대입시키더라도 0과 1사이의 값을 가지게 된다. sigmoid 함수에 데이터 값을 Linear Regression 값을 사용하여 나타내게 되면 Logistic Hypothesis가 탄생하게 된다.
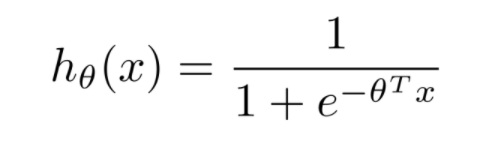
Cost Function
이번에는 Logistic Regression을 풀기위해 필요한 θ 를 구하는 방법에 대해서 알아보도록 하겠다. 우리가 직면한 문제는 아래의 그림과 같고 θ 를 고르는 것이 우리가 해야 할 일이다.

앞에서 우리가 배웠던 Linear Regression을 위한 공식은 J(θ)=12m∑mi=1(hθ(x(i))−y(i)) 와 같으며 우리는 이를 간단히 아래와 같이 적을 수 있다.
Cost(hθ(x),y)=12(hθ(x)−y)2
그리고 Logistic Regression 문제를 위해 hθ(x)=11+e−θTx 를 대입하면 비용함수가 구해질 것 같지만 우리는 이것을 사용할 수 없다. 그 이유는 위의 과정에 따라 대입한 비용함수 J(θ) 는 아래의 그림과 같은 Non-Convex 함수이기 때문이다. Linear Regression의 비용함수는 Convex = Single bow-shaped 구조로 Gradient Descent를 실행하면 Global Minimum으로 수렴함을 보장했었지만 Logistic Regression의 비용함수는 그것을 보장하지 못한다.

참고 사이트
