
unified agent는 여러 개의 개인 프로덕트를 하나의 관점에서 분석하고,
개선 우선순위를 판단한 뒤 실제 코드 수정과 PR 생성까지 이어지도록 설계한 자동화 에이전트입니다.
수익화를 목적으로 개인 프로젝트로 QR Generator와 Convert Image라는 두 개의 툴 서비스를 운영하면서, 아래와 같은 한계와 문제들이 있었습니다.
- 마케팅 경험의 부재: 유지보수와 개선 방향을 잡기 위해 GA4, GSC 데이터를 세팅했지만, 데이터를 통해 어떤 인사이트를 도출하고 다음 방향성을 정해야 하는지에 대한 경험이 부족했습니다.
- 관리 부담: 두 서비스의 GSC, GA4 데이터를 각각 확인하고 전략을 세우는 데 상당한 시간이 소요되었습니다.
- 의사결정의 모호함: 어떤 프로덕트에 리소스를 더 집중해야 할지 데이터 기반으로 우선순위를 정하기 어려웠습니다.
- 실행의 병목: 리포트에서 "메타 타이틀을 수정하세요"라는 인사이트를 얻더라도, 실제 파일 수정과 PR 생성까지 이어지는 과정이 번거로워 실행이 미뤄지는 문제가 있었습니다.
단순히 데이터를 보여주는 도구가 아니라, 스스로 판단하고 코드를 수정해 PR까지 올리는 에이전트가 필요했습니다.
아래에서는 에이전트를 구성하는 전체 구현 과정보다는, 실제로 설계하면서 중요하게 판단했던 의사결정 지점들을 중심으로 기록해두었습니다.
프로젝트 구조 결정하기: Monorepo vs Multi-Repo
에이전트를 설계할 때 가장 먼저 마주한 고민은 "에이전트가 두 프로젝트를 어떤 방식으로 바라보게 할 것인가?"였습니다. 모노레포를 고려하기도 했지만, 최종적으로는 Multi-Repo 구조를 유지하되 이를 상위 계층에서 통합 관리하는 방식을 선택했습니다.
- 코드의 독립성: 두 프로젝트가 공유하는 코드가 없어 결합도를 높일 이유가 없었고, 모노레포를 도입하려면 기존 프로젝트 구조를 변경해야 했습니다.
- 데이터 중심의 통합: 에이전트에게 필요한 것은 코드 전체가 아니라 각 프로덕트의 데이터와 PR 생성 권한이었습니다.
- 확장성: 이 구조 덕분에 기존 프로젝트 설정을 거의 건드리지 않고도 새로운 프로덕트를 언제든 관리 대상에 추가할 수 있었습니다.
Agent의 단계별 설계
핵심은 분석에서 실행까지 이어지는 파이프라인을 만드는 것이었습니다.
-
Analysis (분석)
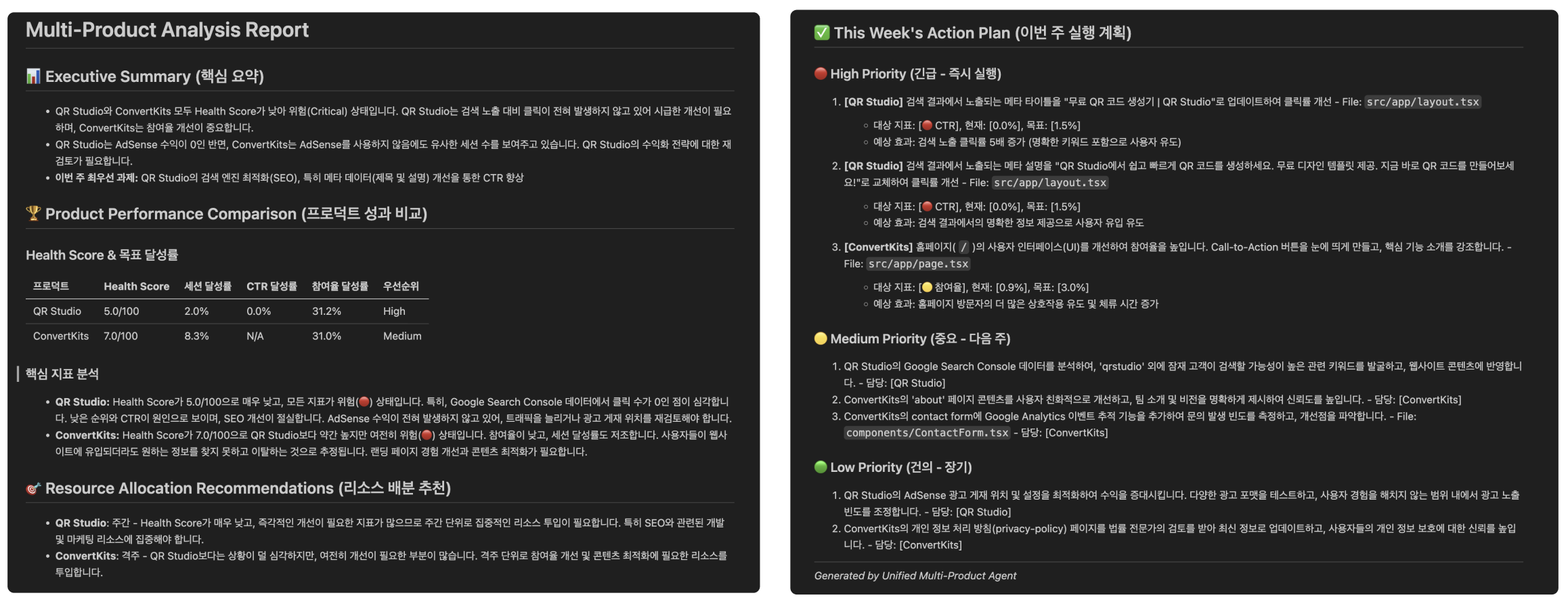
에이전트는 먼저 각 프로덕트의 GSC(Search Console), GA4(Analytics) 지표를 수집합니다. 수집된 로우 데이터는 통합 분석 모듈을 통해 가공됩니다. 이 모듈은 단순히 데이터를 나열하는 것이 아니라, 각 서비스의 트래픽, 사용자 참여도, SEO 순위, 수익 데이터를 사전에 정의한 목표 지표와 비교합니다.특히 서비스마다 중요도가 다르다는 점을 반영하기 위해 가중치 기반의 Health Score를 계산하도록 했습니다. 이를 통해 어떤 서비스의 성장이 정체되어 있는지, 어디에 리소스를 우선 투입해야 하는지를 보다 객관적으로 판단할 수 있게 했습니다.
Gemini AI는 이렇게 가공된 지표 분석 결과와 트렌드 데이터를 결합해 아래와 같은 구조화된 마크다운 리포트를 생성합니다.
- Executive Summary: 전체 프로덕트 상태 요약
- Health Score: 트래픽, SEO, 수익률을 가중 합산한 건강 지표
- Action Plan: 하이라이트된 개선 과제 (🔴 긴급, 🟡 중요, 🟢 건의)
그리고 이 리포트를 기반으로 아래 과정을 따라 실제 기능 개선을 수행합니다.
-
Action Extraction (추출)
마크다운 리포트에서 실행 가능한 액션을 구조화된 데이터로 변환합니다. 이 단계에서는 데이터 파싱 전략으로 성능을 확보하고, 복잡한 문맥만LLM Fallback으로 처리하는 하이브리드 방식을 채택했습니다.기존에는 전체 리포트를 LLM으로만 파싱했는데, 불필요한 토큰 소모가 컸고 특히 파일 경로를 잘못 짚는 환각(Hallucination)이 자주 발생했습니다.
Regex-First방식으로 전환한 뒤에는 약 90%의 전형적인 수정 액션을 거의 즉시 추출할 수 있었고, 비용도 거의 0에 가깝게 줄일 수 있었습니다. -
Action Validation (검증)
AI가 제안한 액션이 안전한지 검증합니다. 사전에 정의된 파일과 태그(Meta Title, Description 등)만 수정할 수 있도록 하는 화이트리스트 방식을 적용해 시스템 안정성을 확보했습니다.여기서 화이트리스트(Whitelist) 방식이란, "허용된 것 외에는 모두 금지"하는 보안 원칙입니다. 예를 들어
.env같은 민감 파일은 접근 자체를 차단하고,layout.tsx같은 특정 SEO 관련 파일과update_meta_title같은 특정 액션 타입만 통과시키도록 제한했습니다. 이 덕분에rm -rf같은 파괴적인 명령이나 예상하지 못한 파일 수정은 구조적으로 발생할 수 없도록 설계할 수 있었습니다. -
Repository Dispatch (실행)
초기 버전에서는 에이전트가 직접 모든 코드를 클론해 수정했지만, 서비스 수가 늘어나면서 속도 문제가 발생했습니다. 이를 해결하기 위해 GitHubRepository Dispatch이벤트를 활용해 각 프로덕트가 자신의 워크플로우 안에서 파일 수정과 PR 생성을 비동기적으로 처리하도록 구조를 바꿨습니다.
# 프로덕트(Receiver) 측의 GitHub Action 예시
on:
repository_dispatch:
types: [seo_update_event]
jobs:
update_meta:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Apply AI Actions
run: python update_script.py '${{ github.event.client_payload.actions }}'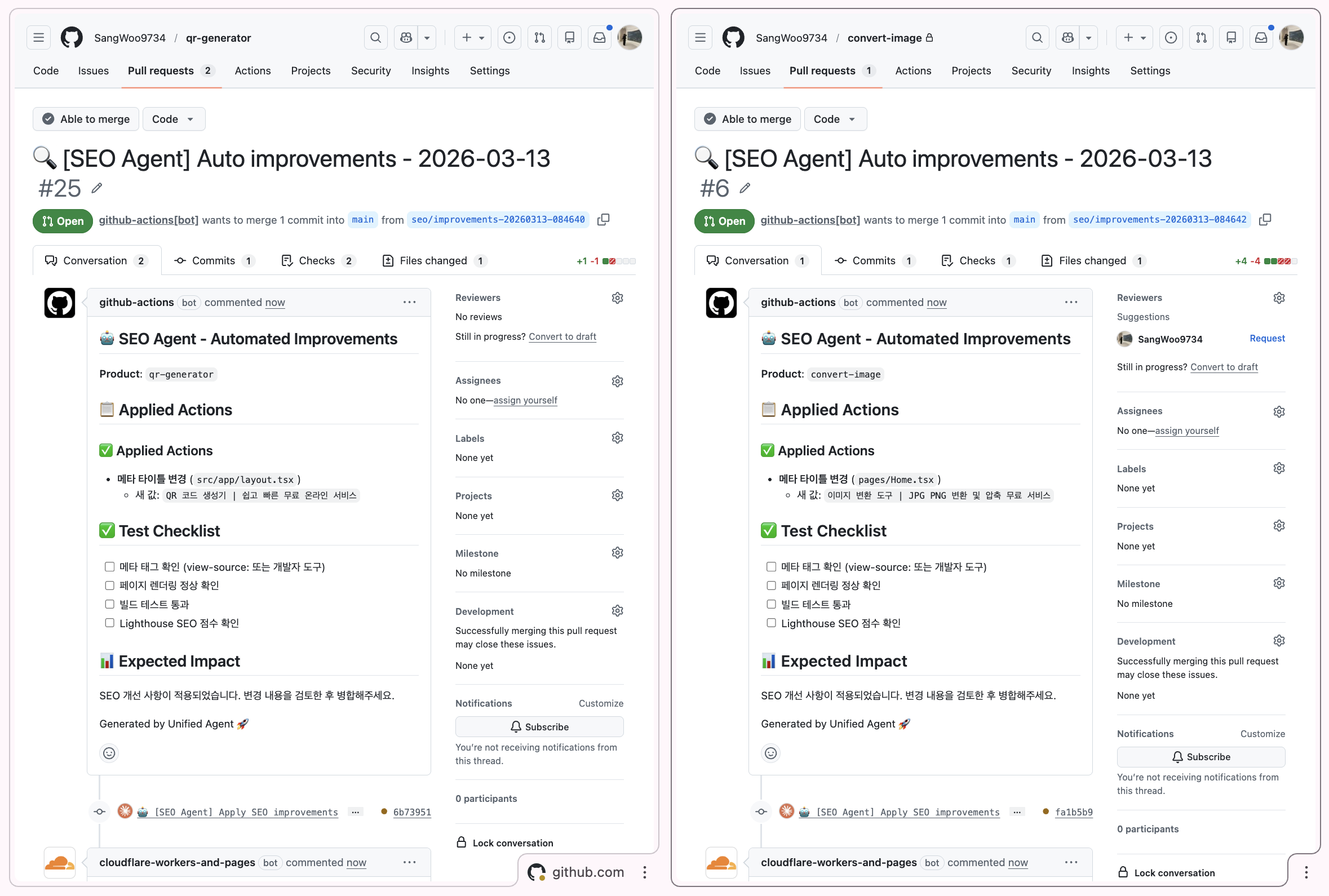
Spec 기반으로 코드를 수정하도록 하기
에이전트 개발 과정에서 또 하나 중요하게 본 점은, 코드 수정 과정이 항상 일정한 단계와 형식을 따르도록 만드는 것이었습니다. 그래야 두 프로젝트 간 코드 스타일을 유지할 수 있고, LLM도 더 안정적으로 동작한다고 판단했습니다.
spec.md → plan.mdㅁ → tasks.md 로 이어지는 문서화 과정을 통해 구현 전에 설계를 충분히 정리했습니다.
에이전트에게 내리는 각 단계의 지침(Prompt)은 다음과 같습니다.
- spec.md: "코드를 건드리지 말고, 우리가 해결하려는 도메인 문제와 비즈니스 로직의 정의(What & Why)만 서술하라."
- plan.md: "정의된 스펙을 달성하기 위해 어떤 파일을 어떻게 수정할지 기술적인 설계도(How)를 작성하라. 이때 안전장치를 반드시 포함하라."
- tasks.md: "설계도를 바탕으로 에이전트가 한 번에 하나씩 수행할 수 있는 원자 단위 작업 리스트를 체크리스트 형태로 생성하라."
이 과정을 도입하면서 얻은 효과는 명확했습니다.
- 설계 강제: 무작정 코딩에 들어가는 대신, 도메인 문제와 리스크(Risk & Mitigation)를 먼저 정의할 수 있었습니다.
- 안전장치 내재화: "어떻게 안전하게 수정할 것인가"를 설계 단계에서 LibCST 도입 등으로 미리 결정했기 때문에 실제 구현 과정의 시행착오를 크게 줄일 수 있었습니다.
- 작업의 원자성: 모든 태스크를
todos/아래 작은 단위로 나누어 에이전트와의 협업 정확도를 높였습니다.
코드 에이전트별 강점 살리기
이번 프로젝트에서는 Claude Code와 Antigravity 두 개의 코딩 에이전트를 함께 활용했습니다.
개인적으로는 Antigravity를 전반적인 기능 개발에, Claude Code를 세부 리팩토링과 코드 정리에 활용했습니다.
Antigravity는 기능 개발이나 디버깅 과정에서 기본적으로 plan 문서를 생성해주기 때문에 작업 흐름을 파악하기 쉬웠고, Chrome을 통해 실제 화면을 분석하면서 기능과 UI 설명을 잘 이해하는 편이었습니다.
반면 Claude Code는 기존에 활용하던 Skill을 기반으로 코드 리뷰, 컴포넌트 분리, 커밋 단위 정리에 강점이 있었고, 코드가 더 의도에 맞게 정리되는 느낌을 받았습니다.

마치며
현재 unified agent는 다음 역할을 수행할 수 있는 구조까지 구성되어 있습니다.
- 여러 프로젝트의 GSC / GA4 데이터를 통합 분석
- 서비스별 Health Score 기반 우선순위 제안
- 실행 가능한 액션 추출
- 안전 검증 후 repository dispatch 기반 PR 생성
즉 단순히 리포트를 생성하는 도구가 아니라, 어느 프로젝트에 먼저 개입해야 하는지 판단하고 실행까지 이어지는 흐름을 목표로 설계했습니다.
다만 실제 운영 단계에서는 트래픽 규모가 아직 충분하지 않아, 생성된 PR이 지속적으로 유효한 개선으로 이어지는 수준까지는 검증하지 못했습니다.
오히려 이 과정에서 데이터가 부족한 환경에서는 AI가 의미 있는 개선 방향을 제안하기 어렵고, 도메인 맥락과 우선순위를 함께 제공해야 한다는 점을 더 분명히 확인할 수 있었습니다.
특히 "기능을 수행하는 AI"와 "실제로 효과가 있는 AI Product" 사이에는 생각보다 많은 설계가 필요하다는 점을 직접 체감할 수 있었던 작업이었습니다. 🚀
