Python과 모듈 BeautifulSoup, requests, re, pymongo을 이용하여 웹 크롤링 기본을 연습해볼 것이다.
1. 웹 페이지 선정
- 먼저 크롤링을 진행할 적절한 웹 페이지를 선정해야한다. 이번 연습을 위해 OP.GG(롤 전적검색 사이트)의 랭킹 페이지를 선정하였다.
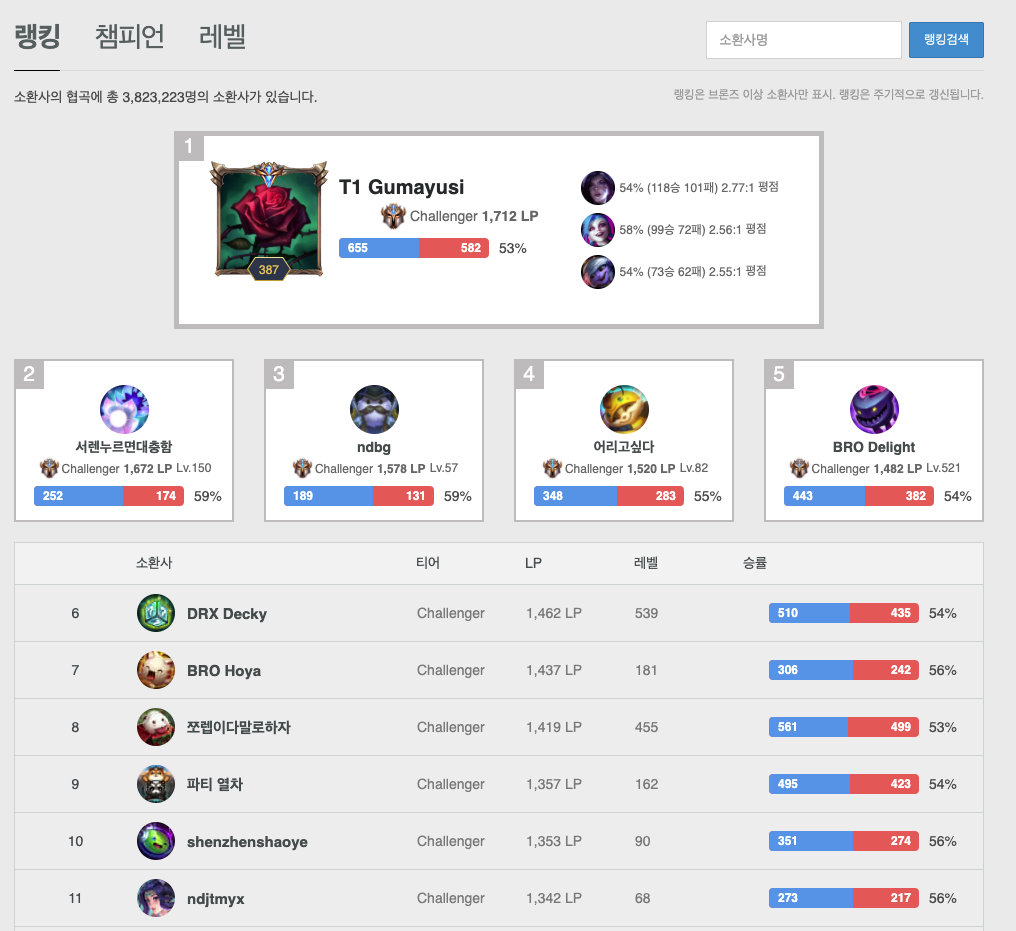
여기서 얻을 수 있는 정보는 각 유저의 순위, 닉네임, 점수(LP) 등등의 데이터이고 닉네임을 눌렀을 때 해당 유저의 개인 전적 페이지로 넘어가게 되는데
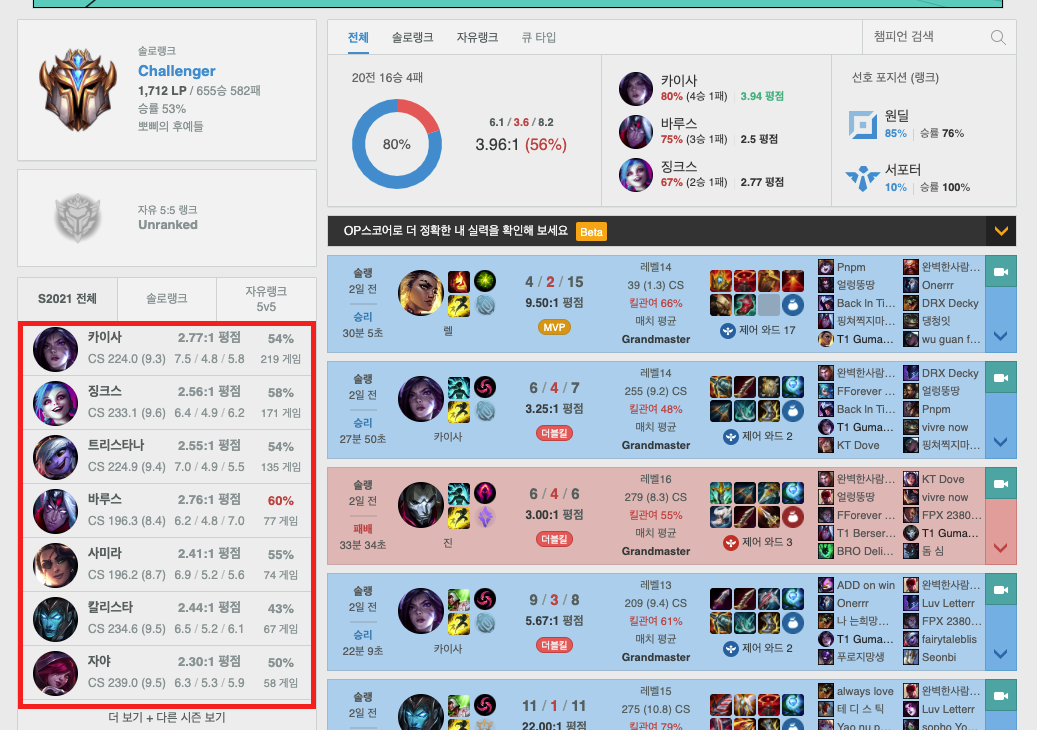
개인 전적 페이지에선 가장 선호하는 챔피언 세명과 챔피언의 세부 전적를 가져올 것이다.
결과를 예상했을 때
[
{"닉네임": nickname, "순위": 1, . . ., "모스트챔피언": [{"챔피언이름": name, . . .}, . . .]}
{"닉네임": nickname, "순위": 2, . . ., "모스트챔피언": [{"챔피언이름": name, . . .}, . . .]}
{"닉네임": nickname, "순위": 3, . . ., "모스트챔피언": [{"챔피언이름": name, . . .}, . . .]}
.
.
.
]위와 같이 나올 것이다.
2. API 요청 / 응답 분석
- 웹 페이지를 선정하였다면 API요청과 응답을 분석하여야한다. 크롬의 개발자 도구를 활용하여 분석을 해보자.
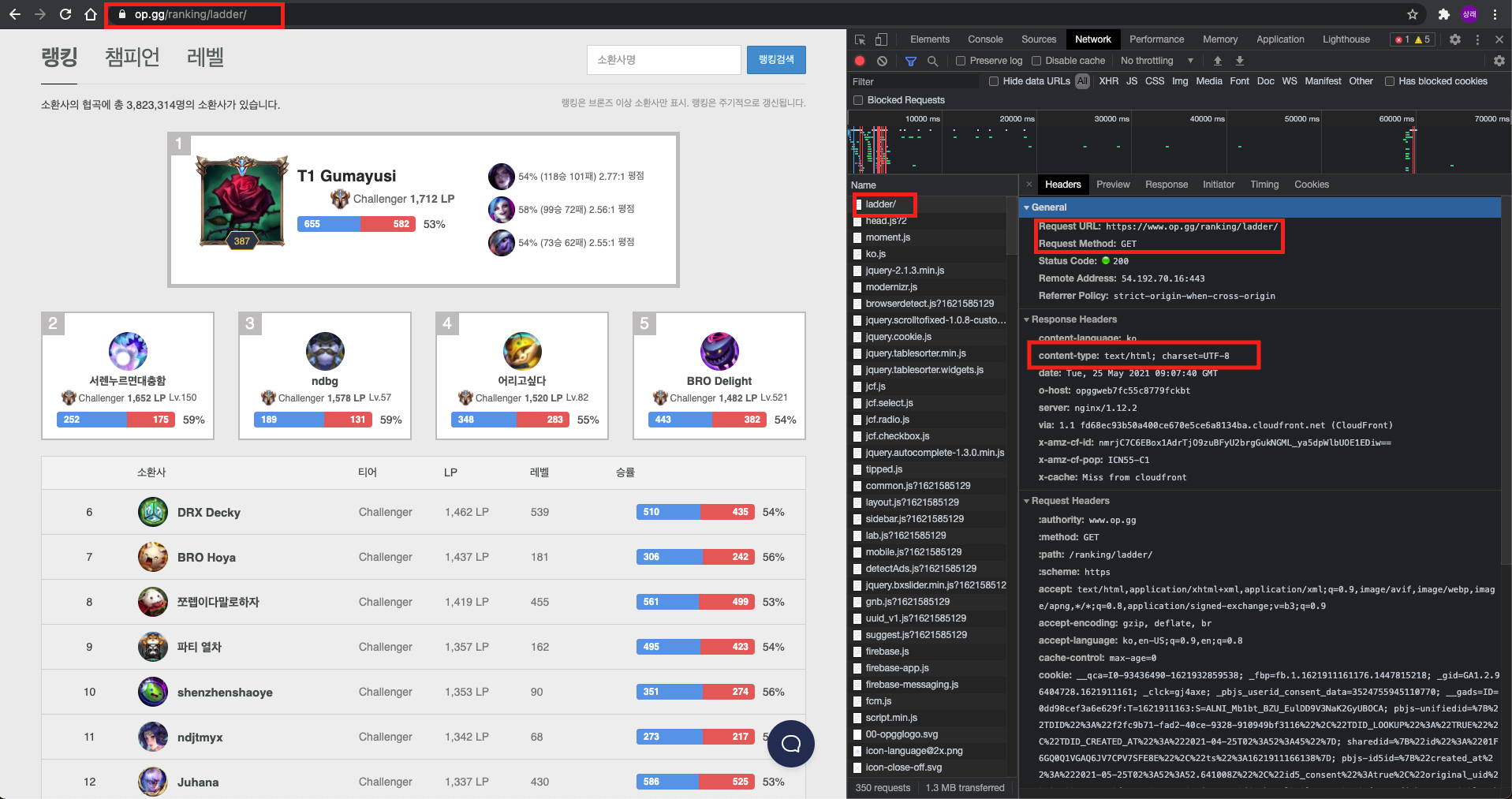
개발자 도구의 Network 탭에서 해당되는 요청을 찾아 HTTP Headers를 분석해보면 Method, 응답 데이터 타입을 알 수 있으며 Response탭을 보면 응답 데이터를 볼 수 있다.
OP.GG의 랭킹 페이지는 HTML 형식의 데이터를 응답 받아 렌더링을 하는 것을 알 수 있다.
즉, Elements 탭을 보면 요소에 맞는 태그들을 찾을 수 있다.
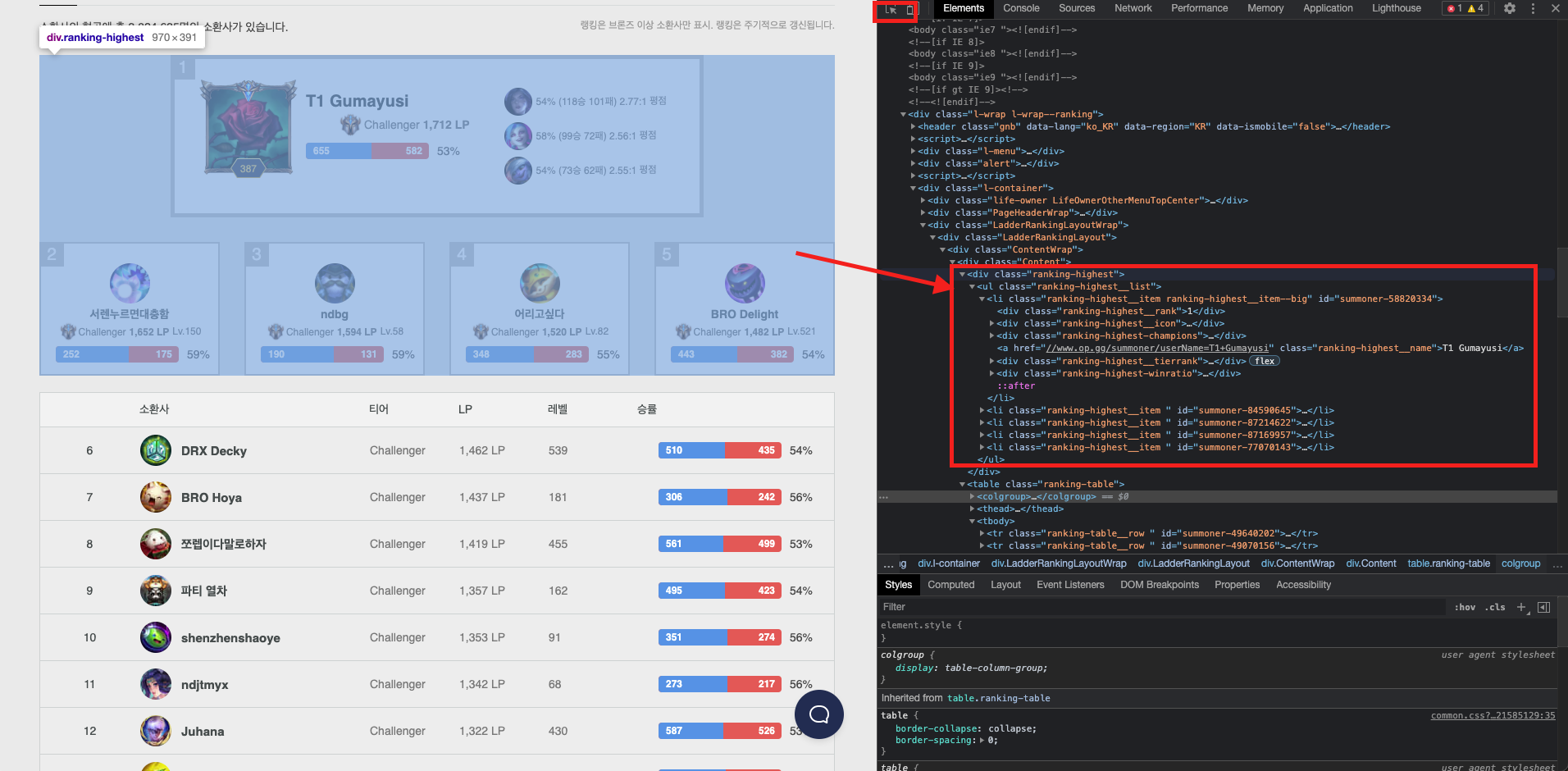
OP.GG는 랭킹 태그가 두개로 나뉘었다. 하나는 1~5위 까지 모여있는 div.ranking-highest와 다른 하나는 그 외의 유저가 모여있는 테이블로 tbody 태그이다. 이를 염두하고 코드를 작성해보자.
위의 작업으로 크롤링의 준비는 거의 70%는 끝났다. 분석이 크롤링의 많은 부분을 차지한다고 생각한다.
3. 크롤링 (Crawling)
1) 모듈 임포트 / DB 연결 / API요청
import requests
from bs4 import BeautifulSoup
import re
import pymongo
conn = pymongo.MongoClient()
db_opgg = conn.opgg
db_opgg_rank = db_opgg.rank
opgg_link = 'https://www.op.gg/ranking/ladder/' #API 요청 링크
data = requests.get(opgg_link).content
soup = BeautifulSoup(data, 'html.parser')- requests - API요청을 위한 모듈
- BeautifulSoup - 요청으로 받아온 데이터를 parse하는 모듈
- re - 정규표현식 모듈, 가끔식 필요없는 부분을 없애 줄 때 사용한다.
- pymongo - MongoDB를 Python으로 핸들링 할 수 있게 하는 모듈
로컬 MongoDB에 opgg라는 DB를 만들어 주었고 rank라는 Collection을 생성하였다. requests를 이용하여 데이터를 요청하고 받아온 데이터를 BeautifulSoup로 parse 해주었다.
변수 soup에는
위와 같이 개발자 도구에서 본 데이터들이 할당 되어있는 것을 볼 수 있다.
2) 1 ~ 5위 유저 데이터
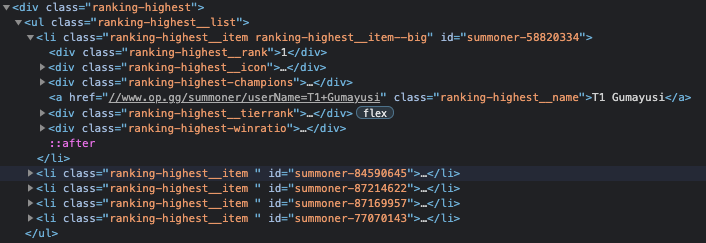
div.ranking-highest > ul.ranking-highest__list > li.ranking-highest__item 에 각 유저들의 데이터가 들어있는 것을 알 수 있다. 즉, 필요한 것은 li.ranking-highest__item이다.
import requests
from bs4 import BeautifulSoup
import re
import pymongo
conn = pymongo.MongoClient()
db_opgg = conn.opgg
db_opgg_rank = db_opgg.rank
opgg_link = 'https://www.op.gg/ranking/ladder/' #API 요청 링크
data = requests.get(opgg_link).content
soup = BeautifulSoup(data, 'html.parser')
# 1 ~ 5 ranking highest
ranking_highest = soup.select('li.ranking-highest__item')select를 이용하여 지정해준 태그와 클래스에 해당되는 모든 데이터를 리스트 형태로 가져온다.
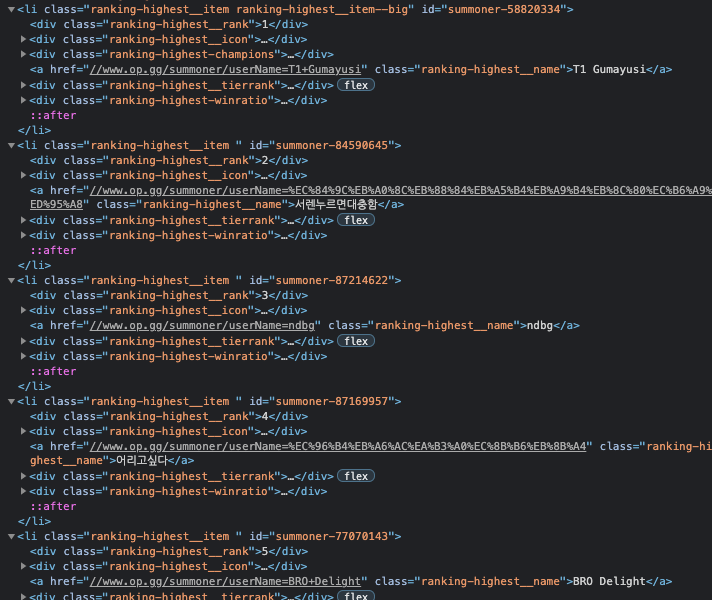
위 사진에 해당되는 데이터들이 들어 있을 것이고 랭킹, 닉네임 등등 각각의 태그안에 정보가 들어있을 것이다. 그리고 a태그의 href에 유저 개인 전적 페이지의 링크가 있는 것을 볼 수 있다.
이를 for 반복문을 이용하여 하나씩 가공해보자.
import requests
from bs4 import BeautifulSoup
import re
import pymongo
conn = pymongo.MongoClient()
db_opgg = conn.opgg
db_opgg_rank = db_opgg.rank
opgg_link = 'https://www.op.gg/ranking/ladder/'
data = requests.get(opgg_link).content
soup = BeautifulSoup(data, 'html.parser')
# 1 ~ 5 ranking highest
ranking_highest = soup.select('li.ranking-highest__item')
for highest_user in ranking_highest:
user_info = highest_user.select_one('a.ranking-highest__name')
user_link = user_info.attrs['href']
# 닉네임
name = user_info.text
# 순위
rank = highest_user.select_one('div.ranking-highest__rank').text
# 티어 레벨
tier_info = highest_user.select_one('div.ranking-highest__tierrank')
tier = tier_info.select_one('span').text
score = re.sub('( |,|LP)','',tier_info.select_one('b').text)
level = tier_info.select_one('div.ranking-highest__level').text.replace('Lv.', '')
# 승률
winratio_info = highest_user.select_one('div.winratio')
win_lose = winratio_info.select_one('div.winratio-graph')
win = win_lose.select_one('div.winratio-graph__text--left').text
lose = win_lose.select_one('div.winratio-graph__text--right').text
winratio = winratio_info.select_one('span').text원하는 모습으로 가공하였다.
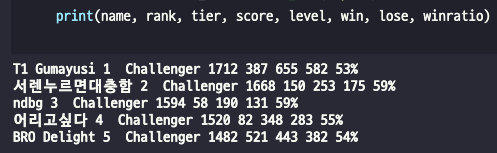
코드를 작성하는 와중에 수시로 print를 찍으면서 작성을 하면 도움이 될 것이다.
이제는 모스트 챔피언 3명을 가져오는 코드를 작성해보자.
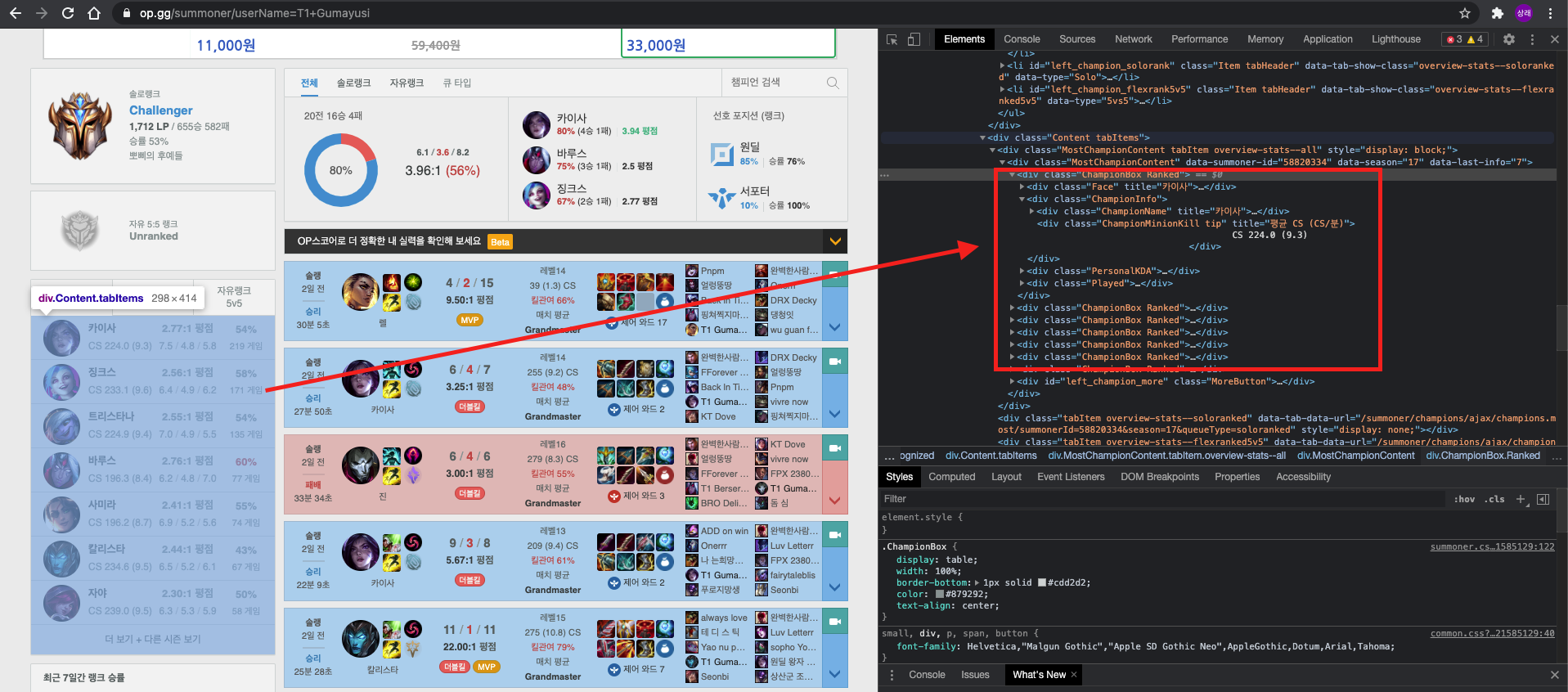
위 사진을 보면 모스트 챔피언이 담긴 테이블의 요소는 div.ChampionBox로 되어있는 것을 알 수 있다.
import requests
from bs4 import BeautifulSoup
import re
import pymongo
conn = pymongo.MongoClient()
db_opgg = conn.opgg
db_opgg_rank = db_opgg.rank
opgg_link = 'https://www.op.gg/ranking/ladder/'
data = requests.get(opgg_link).content
soup = BeautifulSoup(data, 'html.parser')
# 1 ~ 5 ranking highest
ranking_highest = soup.select('li.ranking-highest__item')
for highest_user in ranking_highest:
user_info = highest_user.select_one('a.ranking-highest__name')
user_link = user_info.attrs['href']
# 생략
# 모스트챔 피언
user_data = requests.get('https:' + user_link).content
user_data_soup = BeautifulSoup(user_data, 'html.parser')
most_champion = user_data_soup.select('div.MostChampionContent div.ChampionBox', limit = 3)
most_champion_list = []
for champ in most_champion:
champ_info = champ.select_one('div.ChampionInfo')
champ_name = champ_info.select_one('div.ChampionName').attrs['title']
champ_minon_kill = re.sub('(\n|\t)', '', champ_info.select_one('div.ChampionMinionKill').text).split(' ')
avr_CS = champ_minon_kill[1]
minute_CS = re.sub('(\(|\))', '', champ_minon_kill[2])
persnal_kda = champ.select_one('div.PersonalKDA')
kda = persnal_kda.select_one('div.KDA span.KDA').text
kill = persnal_kda.select_one('div.KDAEach span.Kill').text
death = persnal_kda.select_one('div.KDAEach span.Death').text
assist = persnal_kda.select_one('div.KDAEach span.Assist').text
champ_winratio = re.sub('(\n|\t)', '', champ.select_one('div.Played div.WinRatio').text)
champ_play_count = champ.select_one('div.Played div.Title').text.replace(' Played', '')
most_champ = {
"챔피언이름": champ_name,
"평균CS": float(avr_CS),
"분당CS": float(minute_CS),
"KDA": kda,
"Kill": float(kill),
"Death": float(death),
"Assist": float(assist),
"승률": champ_winratio,
"플레이횟수": int(champ_play_count)
}
most_champion_list.append(most_champ)
위와 같이 작성하여 하나의 리스트에 정리해준다.

모든 데이터를 합쳐보자.
import requests
from bs4 import BeautifulSoup
import re
import pymongo
conn = pymongo.MongoClient()
db_opgg = conn.opgg
db_opgg_rank = db_opgg.rank
opgg_link = 'https://www.op.gg/ranking/ladder/'
data = requests.get(opgg_link).content
soup = BeautifulSoup(data, 'html.parser')
# 1 ~ 5 ranking highest
ranking_highest = soup.select('li.ranking-highest__item')
highest_user_list = []
for highest_user in ranking_highest:
user_info = highest_user.select_one('a.ranking-highest__name')
user_link = user_info.attrs['href']
# 닉네임
name = user_info.text
# 순위
rank = highest_user.select_one('div.ranking-highest__rank').text
# 티어 레벨
tier_info = highest_user.select_one('div.ranking-highest__tierrank')
tier = tier_info.select_one('span').text
score = re.sub('( |,|LP)','',tier_info.select_one('b').text)
level = tier_info.select_one('div.ranking-highest__level').text.replace('Lv.', '')
# 승률
winratio_info = highest_user.select_one('div.winratio')
win_lose = winratio_info.select_one('div.winratio-graph')
win = win_lose.select_one('div.winratio-graph__text--left').text
lose = win_lose.select_one('div.winratio-graph__text--right').text
winratio = winratio_info.select_one('span').text
# 모스트 챔피언
user_data = requests.get('https:' + user_link).content
user_data_soup = BeautifulSoup(user_data, 'html.parser')
most_champion = user_data_soup.select('div.MostChampionContent div.ChampionBox', limit = 3)
most_champion_list = []
for champ in most_champion:
champ_info = champ.select_one('div.ChampionInfo')
champ_name = champ_info.select_one('div.ChampionName').attrs['title']
champ_minon_kill = re.sub('(\n|\t)', '', champ_info.select_one('div.ChampionMinionKill').text).split(' ')
avr_CS = champ_minon_kill[1]
minute_CS = re.sub('(\(|\))', '', champ_minon_kill[2])
persnal_kda = champ.select_one('div.PersonalKDA')
kda = persnal_kda.select_one('div.KDA span.KDA').text
kill = persnal_kda.select_one('div.KDAEach span.Kill').text
death = persnal_kda.select_one('div.KDAEach span.Death').text
assist = persnal_kda.select_one('div.KDAEach span.Assist').text
champ_winratio = re.sub('(\n|\t)', '', champ.select_one('div.Played div.WinRatio').text)
champ_play_count = champ.select_one('div.Played div.Title').text.replace(' Played', '')
most_champ = {
"챔피언이름": champ_name,
"평균CS": float(avr_CS),
"분당CS": float(minute_CS),
"KDA": kda,
"Kill": float(kill),
"Death": float(death),
"Assist": float(assist),
"승률": champ_winratio,
"플레이횟수": int(champ_play_count)
}
most_champion_list.append(most_champ)
user_dict = {
"닉네임": name,
"순위": int(rank),
"티어": tier,
"점수(LP)": int(score),
"레벨": int(level),
"승률": winratio,
"승": int(win),
"패": int(lose),
"모스트챔피언": most_champion_list
}
highest_user_list.append(user_dict)아웃풋을 확인해보자.
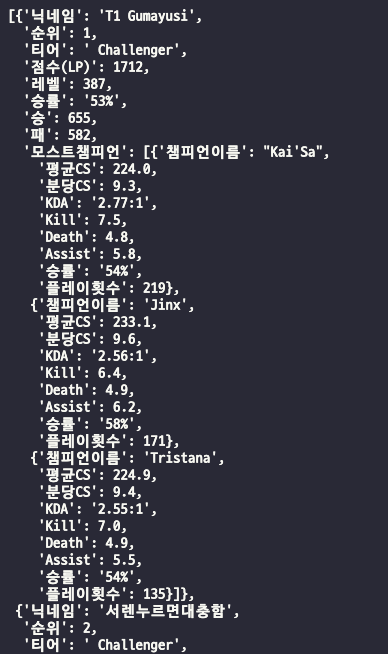
3) 그 외(6 ~ ) 유저 데이터
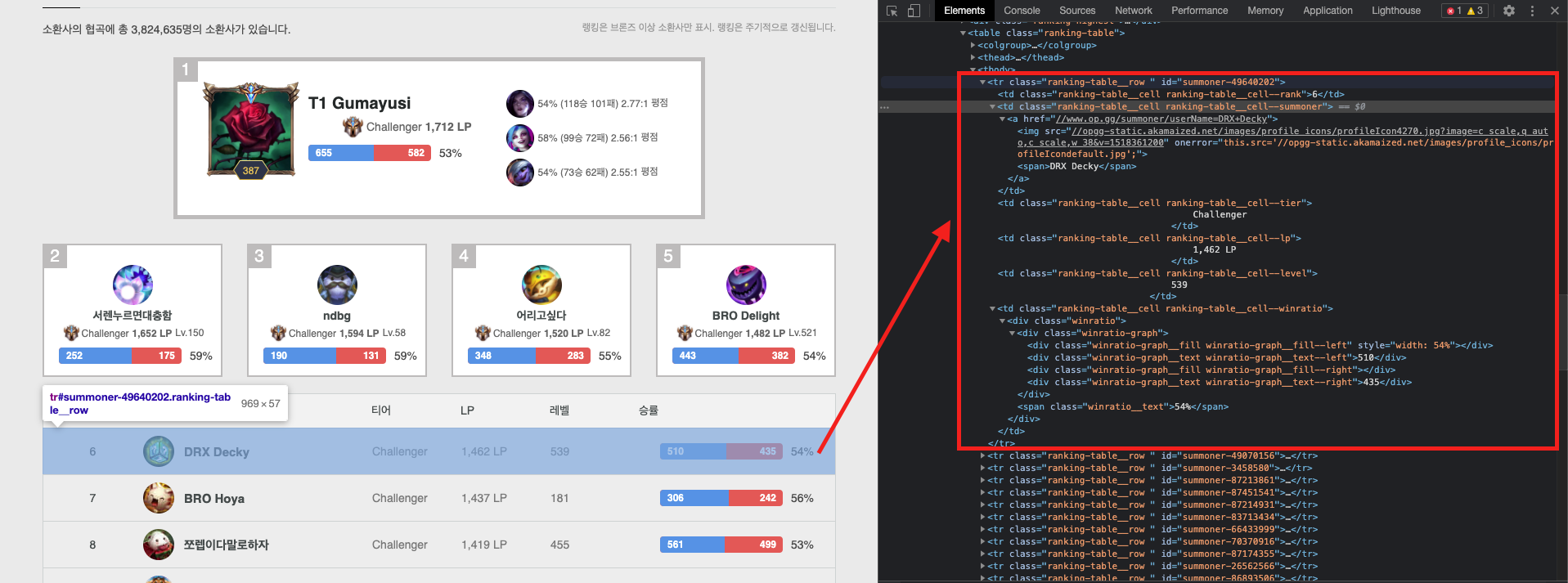
그 외의 유저 데이터는 td.ranking-table__row에 담겨있는 것을 확인했고 2)의 과정과 마찬가지로 데이터를 가공하면된다.
import requests
from bs4 import BeautifulSoup
import re
import pymongo
conn = pymongo.MongoClient()
db_opgg = conn.opgg
db_opgg_rank = db_opgg.rank
opgg_link = 'https://www.op.gg/ranking/ladder/'
data = requests.get(opgg_link).content
soup = BeautifulSoup(data, 'html.parser')
# 1 ~ 5위 코드 생략
ranking_table = soup.select('tr.ranking-table__row')
for user in ranking_table:
user_info_list = user.select('td.ranking-table__cell')
rank = user_info_list[0].text
user_info = user_info_list[1]
name = user_info.select_one('span').text
user_link = user_info.select_one('a').attrs['href']
tier = re.sub('(\n|\t)', '', user_info_list[2].text)
score = re.sub('(\n|\t|,| |LP)', '', user_info_list[3].text)
level = user_info_list[4].text
winratio = user_info_list[5].select_one('span').text
win = user_info_list[5].select_one('div.winratio-graph__text--left').text
lose = user_info_list[5].select_one('div.winratio-graph__text--right').text
user_data = requests.get('https:' + user_link).content
user_data_soup = BeautifulSoup(user_data, 'html.parser')
most_champion = user_data_soup.select('div.MostChampionContent div.ChampionBox', limit = 3)
most_champion_list = []
for champ in most_champion:
champ_info = champ.select_one('div.ChampionInfo')
champ_name = champ_info.select_one('div.ChampionName').attrs['title']
champ_minon_kill = re.sub('(\n|\t)', '', champ_info.select_one('div.ChampionMinionKill').text).split(' ')
avr_CS = champ_minon_kill[1]
minute_CS = re.sub('(\(|\))', '', champ_minon_kill[2])
persnal_kda = champ.select_one('div.PersonalKDA')
kda = persnal_kda.select_one('div.KDA span.KDA').text
kill = persnal_kda.select_one('div.KDAEach span.Kill').text
death = persnal_kda.select_one('div.KDAEach span.Death').text
assist = persnal_kda.select_one('div.KDAEach span.Assist').text
champ_winratio = re.sub('(\n|\t)', '', champ.select_one('div.Played div.WinRatio').text)
champ_play_count = champ.select_one('div.Played div.Title').text.replace(' Played', '')
most_champ = {
"챔피언이름": champ_name,
"평균CS": float(avr_CS),
"분당CS": float(minute_CS),
"KDA": kda,
"Kill": float(kill),
"Death": float(death),
"Assist": float(assist),
"승률": champ_winratio,
"플레이횟수": int(champ_play_count)
}
most_champion_list.append(most_champ)
user_dict = {
"닉네임": name,
"순위": int(rank),
"티어": tier,
"점수(LP)": int(score),
"레벨": int(level),
"승률": winratio,
"승": int(win),
"패": int(lose),
"모스트챔피언": most_champion_list
}
highest_user_list.append(user_dict)4) 중복 되는 코드 함수 / 모듈화
위의 코드에서 중복되는 부분이 있다. user_dict와 most_champ 두 부분이 중복이 된다. 이를 쉽게 모듈화 할 수 있다.
새로운 module.py 파일을 하나 만들고
from bs4 import BeautifulSoup
import requests
import re
def user_dict_func(name, rank, tier, score, level, winratio, win, lose, most_champs):
return {
"닉네임": name,
"순위": int(rank),
"티어": tier,
"점수(LP)": int(score),
"레벨": int(level),
"승률": winratio,
"승": int(win),
"패": int(lose),
"모스트챔피언": most_champs
}
def most_champs_func(user_link):
user_data = requests.get('https:' + user_link).content
user_data_soup = BeautifulSoup(user_data, 'html.parser')
most_champion = user_data_soup.select('div.MostChampionContent div.ChampionBox', limit = 3)
most_champion_list = []
for champ in most_champion:
champ_info = champ.select_one('div.ChampionInfo')
champ_name = champ_info.select_one('div.ChampionName').attrs['title']
champ_minon_kill = re.sub('(\n|\t)', '', champ_info.select_one('div.ChampionMinionKill').text).split(' ')
avr_CS = champ_minon_kill[1]
minute_CS = re.sub('(\(|\))', '', champ_minon_kill[2])
persnal_kda = champ.select_one('div.PersonalKDA')
kda = persnal_kda.select_one('div.KDA span.KDA').text
kill = persnal_kda.select_one('div.KDAEach span.Kill').text
death = persnal_kda.select_one('div.KDAEach span.Death').text
assist = persnal_kda.select_one('div.KDAEach span.Assist').text
champ_winratio = re.sub('(\n|\t)', '', champ.select_one('div.Played div.WinRatio').text)
champ_play_count = champ.select_one('div.Played div.Title').text.replace(' Played', '')
most_champ = {
"챔피언이름": champ_name,
"평균CS": float(avr_CS),
"분당CS": float(minute_CS),
"KDA": kda,
"Kill": float(kill),
"Death": float(death),
"Assist": float(assist),
"승률": champ_winratio,
"플레이횟수": int(champ_play_count)
}
most_champion_list.append(most_champ)
return most_champion_list위와 같이 모듈화 하면
import requests
from bs4 import BeautifulSoup
import re
import pymongo
from module import user_dict_func, most_champs_func # 모듈 import
conn = pymongo.MongoClient()
db_opgg = conn.opgg
db_opgg_rank = db_opgg.rank
opgg_link = 'https://www.op.gg/ranking/ladder/'
data = requests.get(opgg_link).content
soup = BeautifulSoup(data, 'html.parser')
# 1 ~ 5 ranking highest
ranking_highest = soup.select('li.ranking-highest__item')
highest_user_list = []
for highest_user in ranking_highest:
user_info = highest_user.select_one('a.ranking-highest__name')
user_link = user_info.attrs['href']
# 닉네임
name = user_info.text
# 순위
rank = highest_user.select_one('div.ranking-highest__rank').text
# 티어 레벨
tier_info = highest_user.select_one('div.ranking-highest__tierrank')
tier = tier_info.select_one('span').text
score = re.sub('( |,|LP)','',tier_info.select_one('b').text)
level = tier_info.select_one('div.ranking-highest__level').text.replace('Lv.', '')
# 승률
winratio_info = highest_user.select_one('div.winratio')
win_lose = winratio_info.select_one('div.winratio-graph')
win = win_lose.select_one('div.winratio-graph__text--left').text
lose = win_lose.select_one('div.winratio-graph__text--right').text
winratio = winratio_info.select_one('span').text
most_champs = most_champs_func(user_link)
user_dict = user_dict_func(name, rank, tier, score, level, winratio, win, lose, most_champs)
highest_user_list.append(user_dict)
ranking_table = soup.select('tr.ranking-table__row')
for user in ranking_table:
user_info_list = user.select('td.ranking-table__cell')
rank = user_info_list[0].text
user_info = user_info_list[1]
name = user_info.select_one('span').text
user_link = user_info.select_one('a').attrs['href']
tier = re.sub('(\n|\t)', '', user_info_list[2].text)
score = re.sub('(\n|\t|,| |LP)', '', user_info_list[3].text)
level = user_info_list[4].text
winratio = user_info_list[5].select_one('span').text
win = user_info_list[5].select_one('div.winratio-graph__text--left').text
lose = user_info_list[5].select_one('div.winratio-graph__text--right').text
most_champs = most_champs_func(user_link)
user_dict = user_dict_func(name, rank, tier, score, level, winratio, win, lose, most_champs)
highest_user_list.append(user_dict)코드의 길이를 현저히 줄일 수 있다.
5) 페이지에 따른 데이터 추출
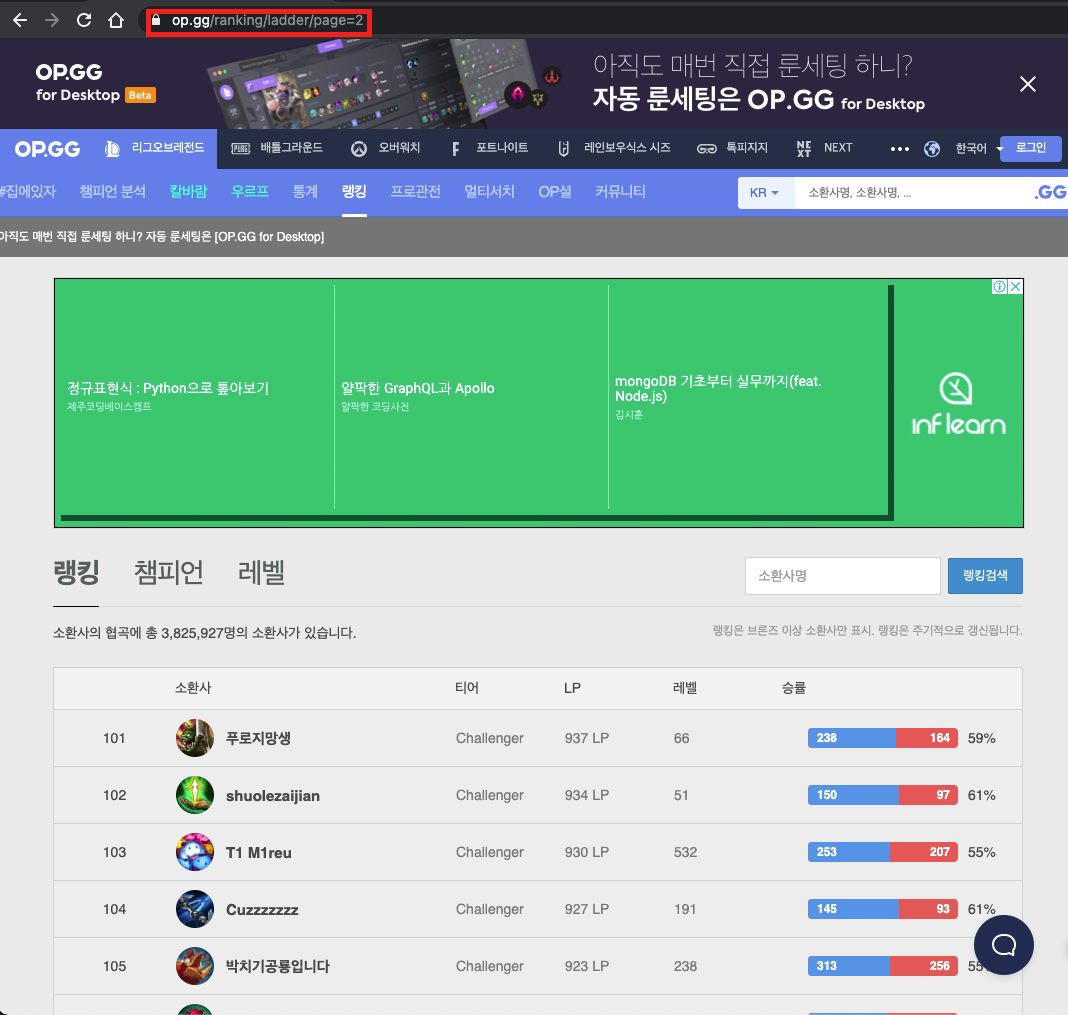
랭킹 페이지의 API는 GET 요청이므로 path에 page가 담겨있는 것을 볼 수 있다. 이를 활용하여 페이지를 이동시키면서 데이터를 추출할 수 있다.
import requests
from bs4 import BeautifulSoup
import re
import pymongo
from module import user_dict_func, most_champs_func
conn = pymongo.MongoClient()
db_opgg = conn.opgg
db_opgg_rank = db_opgg.rank
opgg_link = 'https://www.op.gg/ranking/ladder/'
page = 1
highest_user_list = []
while page < 3:
opgg_link = 'https://www.op.gg/ranking/ladder/page=' + str(page) if page > 1 else opgg_link
data = requests.get(opgg_link).content
soup = BeautifulSoup(data, 'html.parser')
if page == 1:
ranking_highest = soup.select('li.ranking-highest__item')
for highest_user in ranking_highest:
user_info = highest_user.select_one('a.ranking-highest__name')
user_link = user_info.attrs['href']
name = user_info.text
rank = highest_user.select_one('div.ranking-highest__rank').text
tier_info = highest_user.select_one('div.ranking-highest__tierrank')
tier = tier_info.select_one('span').text
score = re.sub('( |,|LP)','',tier_info.select_one('b').text)
level = tier_info.select_one('div.ranking-highest__level').text.replace('Lv.', '')
winratio_info = highest_user.select_one('div.winratio')
win_lose = winratio_info.select_one('div.winratio-graph')
win = win_lose.select_one('div.winratio-graph__text--left').text
lose = win_lose.select_one('div.winratio-graph__text--right').text
winratio = winratio_info.select_one('span').text
most_champs = most_champs_func(user_link)
user_dict = user_dict_func(name, rank, tier, score, level, winratio, win, lose, most_champs)
highest_user_list.append(user_dict)
ranking_table = soup.select('tr.ranking-table__row')
for user in ranking_table:
user_info_list = user.select('td.ranking-table__cell')
rank = user_info_list[0].text
user_info = user_info_list[1]
name = user_info.select_one('span').text
user_link = user_info.select_one('a').attrs['href']
tier = re.sub('(\n|\t)', '', user_info_list[2].text)
score = re.sub('(\n|\t|,| |LP)', '', user_info_list[3].text)
level = user_info_list[4].text
winratio = user_info_list[5].select_one('span').text
win = user_info_list[5].select_one('div.winratio-graph__text--left').text
lose = user_info_list[5].select_one('div.winratio-graph__text--right').text
most_champs = most_champs_func(user_link)
user_dict = user_dict_func(name, rank, tier, score, level, winratio, win, lose, most_champs)
highest_user_list.append(user_dict)
page += 1첫 페이지에서 1 ~ 5위 유저만 데이터 추출 방법이 다르기 때문에 조건문으로 한정해주고, 다음 페이지부터 한 페이지가 끝날 때 마다 page += 1을 해주면 된다. 위의 코드는 연습용으로 2페이지까지만 추출을 했다.
4. DB에 입력
import requests
from bs4 import BeautifulSoup
import re
import pymongo
from module import user_dict_func, most_champs_func
conn = pymongo.MongoClient()
db_opgg = conn.opgg
db_opgg_rank = db_opgg.rank
highest_user_list = []
# 3. 크롤링 코드 생략
db_opgg_rank.insert_many(highest_user_list).insert_many()를 이용해
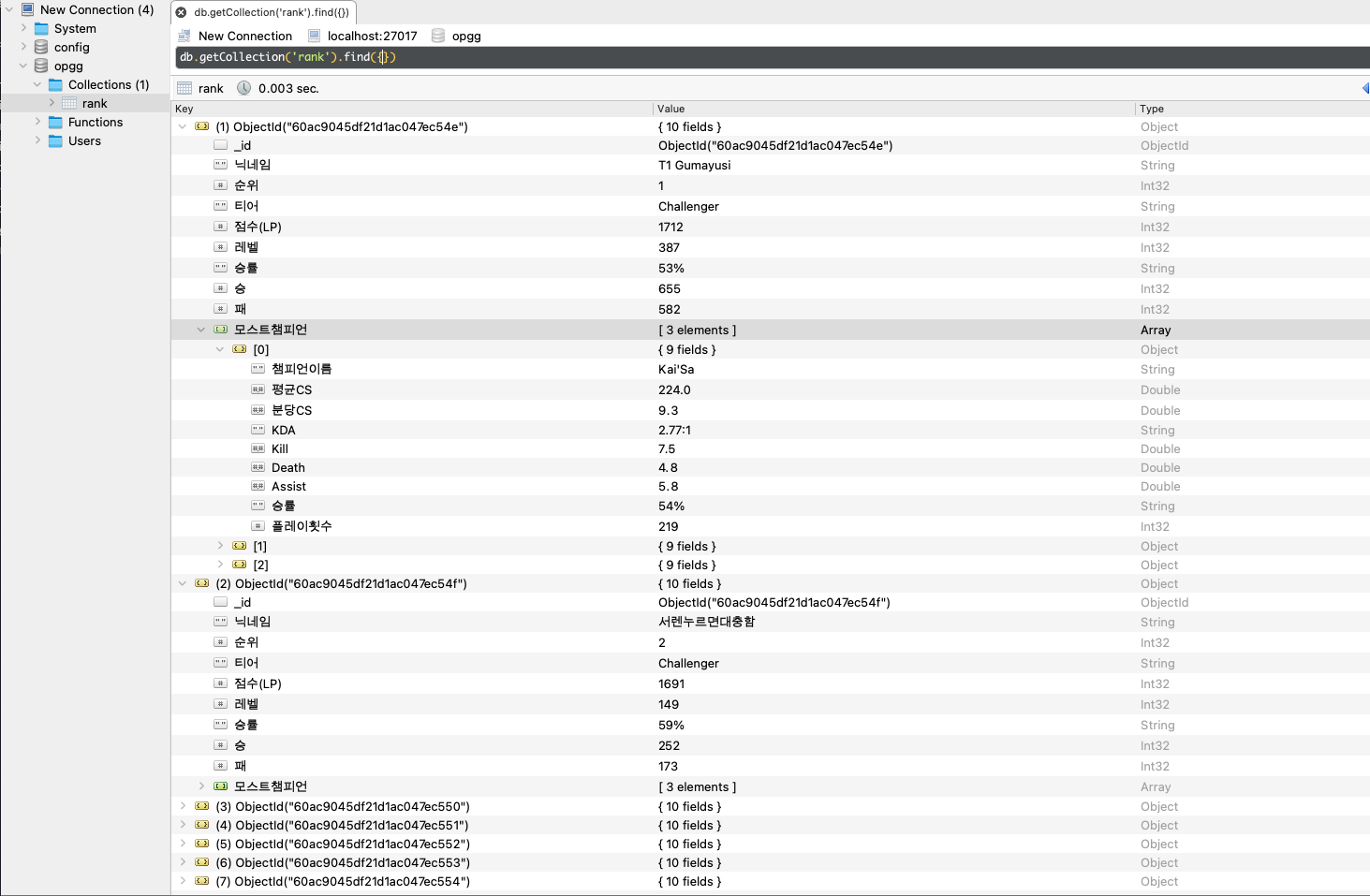
위의 사진과 같이 DB에 입력을 해주면 된다.
