프로그래머스 데브코스 풀스택 FrontEnd 🚀
뼈대가 튼튼해야한다고 강사님께서 강조하셨다. 이번 과정은 아마 기초부터 차근차근 쌓아나가고 그 원리를 파악하는 수업이 될 거 같다👍
코드의 문법과 방법론이 아닌 내부 동작원리를 알아야 문제에 봉착했을 때 해결할 수 있는 힘이 생긴다.
그러니 기능<<원리 를 좀 더 알아야한다.
즉, 코드 내부 동작 구조를 알아야한다.
-
알고리즘적인 사고 (원리를 이해하면 자연스럽게된다.)
-
공통적인 로직
-
포인터의 개념 (모든 현존하는 모든 프로그래밍 언어 내부에서 사용한다.)
-
함수 포인터
-
구조체, 공용체, 열거형
위 사항들을 자연스럽게 알게 될 것이다. 그리고 이러한 공부를 꾸준히 하면 객체지향에 대한 어느정도 감을 잡을 수 있을 것이다!
왜 컴파일 언어를 이해해야 하는가 🧐
cf) compile언어 -> 코드를 한번에 해석을 해서 실행할 수 있는 파일로 변환시켜줌
interpreter언어 -> 코드를 한 라인씩 해석하며 실행하는 언어
- 모든 프로그래밍 언어의 동작원리는 같다.
- 자바스크립트와 같은 스크립트언어는 사용이 비교적 간단한 만큼 그 내부 동작원리를 알기 힘들다.
- C언어는 이러한 기본적인 동작원리의 근간을 이루기 때문에 이를 아는 것이 프로그래밍 언어의 동작 원리를 아는 것이다.
- 타입스크립트가 자바스크립트로 한번의 컴파일이 이루어지는데 이를 통해 타입스크립트를 더 잘 이해할 수 있다. 보통의 C 언어는 타입이 붙어있기 때문에 타입스크립트를 이해하는 데에 유리하다.
프로그래밍의 개념 🧐
개발의 3단계
프로그래밍도 예술 작품을 만드는 과정과 비슷
구상 -> 설계 -> 구현
컴퓨터는 2진수만 이해한다. 010101010
이를 "기계어" 라고한다.
컴퓨터는 c언어, javascript, python 등을 이해하지 못한다.
결국 위 언어들은 사람들의 언어다.
이렇게 사람언어 -> 기계어 과정을 "컴파일"
프로그래밍 과정은
설계 -> 원시코드작성 -> 컴파일 -> 링크
이러한 과정을 거치는데 요즘 컴파일+링크 하는 과정을 Build라고한다.
이때 주의할점이있다.
컴파일하는 과정이 꼭 이진코드로 변환하는 과정이 아니라는 점이다!
컴파일은 반드시 이진코드로 변환하는 과정이 아니야 🎯
컴파일은 꼭 이진코드로 변환하는 과정인게 아니라 소스코드를 실행가능한형태로 변환하는 것을 말한다.
예를 들어서 Javascript 코드를 build 하면 컴파일이 이루어지는데
이는 브라우저의 Javascript engine이 해석가능하도록 번들링과 컴파일을 통해 최적화된 상태의 Javascript code의 형태로 컴파일 하는 것이다.
즉, React로 개발을 했을 때 build를 한다고해서 무조건 이진코드로 변환되는 것이 아니라, 실행가능한코드로 변경후 Javascript engine을 통해 이진코드로 변환된다. 이때도 역시 컴파일이 일어나는 것이다.
C언어 맛보기 😋
오늘은 먼저 프로그래밍의 근본인 C언어를 배울 수 있는 기회가 주어졌다.
위 사이트에서 실습을 진행했다.
#include <stdio.h>
int main(){
printf("Hello World")
return 0;
}
위를 보면 #include가 Javascript로 생각했을 때 Import와 같고
<stdio.h>는 외부 모듈로 생각하면된다.
y=f(x)
y=2x
int main(void){
}
f: main
x: void
y: int
c언어는 엄격하다 ㄷㄷ 🥶
-
문장의 끝에는 세미콜론을 찍어주어야한다.
-> 컴파일러는 세미콜론 단위로 문장을 해석하기 때문
(이는 후에 typescript에서도 이렇게함)
-> 그럼 Javacsript에서는 왜 ;(세미콜론)를 찍지 않아도 한줄씩 잘 해석할까?
Javascript는 인터프리터 방식이기 때문 -
리턴값
-> 함수의 수행이 끝났다.
-> 리턴값을 외부로 보내겠다.
변수와 자료형 🎯
변수는 그릇. 그럼 그릇의 크기는 누가 결정하지?
-> 선언된 타입 or 입력된 값의 타입
을보고 시스템이 결정을한다.
즉, 정적타입 Or 동적타입에 따라 시스템이 그 그릇의 크기(메모리)를 결정한다.
메모리의 기본 단위는 byte 🎯
정수-> 4byte
메모리의 주소는 너무나 방대하고 많기 때문에 사람이 기억 못함
그래서 해당 메모리의 주소를 변수로 저장하는 것이다.
즉, 친구의 집을 집주소로 기억하는게 아닌 철수네로 기억하는 것
메모리에는 코드영역, 스택영역, 힙 영역, 데이터 영역
그 중 스택, 힙 영역을 이해해보자
스택
지역변수 및 매개변수를 저장
주로 원시 타입 데이터(정수, 실수, 문자)에서 사용한다.
변수 식별자는 콜스택 상의 실행 컨텍스트의 렉시컬 환경에 저장된다.
힙
사용자가 필요한 만큼의 메모리를 동적으로 할당할 때 사용
주로 참조데이터(배열, 객체)에서 사용한다.
원시타입의 데이터가 재할당이 된다면 ? 🧐
int a = 10;
int a = 20;
기존의 20을 저장하고 있던 메모리가 있다면?
그 메모리의 주소값으로 변수 a의 주소값이 변경된다.
즉, 값이 변경되는게 아니라 메모리 주소값이 변경된다.
만약, 주소값이 없는 값으로 변경된다면?
새로운 메모리를 확보한다.
그렇게하면?? 참조되지 않는 메모리가 있겠지? 그럼 그 메모리는 적절한 시점에 가비지 컬렉터에 의해 메모리에서 해체한다.
자료형 🎯
선언한 변수가 얼만큼의 메모리 공간을 할당할 것인지 결정
(cf: 어떤그릇에 담을래)
효율적인 메모리 공간의 확보를 위해 알맞은 자료형을 사용하는 것이 중요하다.
문자형 => 아스키 코드라는 표준에 의거하여 문자를 10진수로 변경한다.
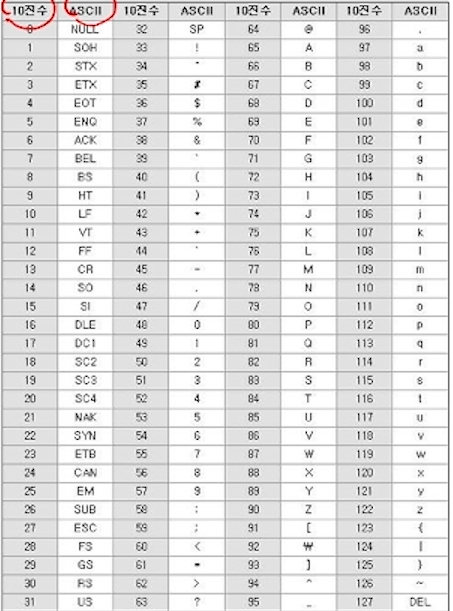
상수 🎯
메모리 공간에 값이 존재하지만 그 값을 변경할 수 없다.
c언어에서도 const를 붙이면 상수화가 가능하다. 아니 이게 근본
const int TEN = 10;
이런식으로 사용이 가능하다.
그런데 이건 안된다.
const int TEN;
TEN = 10;
왜냐면 이미 TEN의 메모리는 할당되었고 그 안에 가비지값이 들어있게된다.
마치 이젠 사용하지 않는 메모리처럼
여기서 초기화란! 변수의 선언과 동시게 값을 할당하는 것을 초기화라고한다.
