타이피스트의 딜레마
ChatGPT나 Claude에게 무언가를 물어본 사람이라면 누구나 경험했을 장면이 있다. 답변이 한 글자씩, 마치 누군가가 키보드를 천천히 두드리듯 흘러나오는 광경. 질문은 순식간에 전송되는데, 왜 대답은 저렇게 조금씩 나오는 걸까?
이유는 AI가 실제로 그렇게 일하기 때문이다. 현재의 대형 언어 모델은 단어를 하나 만들 때마다 지금까지 쓴 모든 내용을 다시 읽고, 다음 단어를 결정하고, 그걸 출력한 뒤, 또 처음부터 읽는다. 마치 편지를 쓰는 타이피스트가 한 글자를 칠 때마다 처음 줄부터 다시 읽어야 한다고 상상해 보라. 천 글자짜리 답변을 쓴다면 처음부터 다시 읽기를 천 번 반복하는 셈이다. 엄청난 낭비다. 그런데 현재의 AI는 정확히 그 방식으로 작동한다.
이 방식을 자기회귀 디코딩(autoregressive decoding)이라 부른다. 앞에 나온 내용이 다음 내용을 결정하는, 고리처럼 연결된 순서를 끊을 수 없기 때문에 태생적으로 느리다.
보조 작가와 편집장
이 병목을 뚫으려는 아이디어 중 가장 영리한 것 하나가 투기적 디코딩(speculative decoding)이다. 비유하자면 이렇다. 뛰어난 소설가(대형 AI)가 혼자 글을 쓰는 대신, 빠르지만 다소 거친 보조 작가(소형 초안 모델)에게 먼저 초안을 맡긴다. 보조 작가는 다음 열 문장을 후다닥 써낸다. 그러면 소설가가 한꺼번에 읽으며 "이건 OK, 이건 OK, 이건 내 스타일 아니야" 하고 검토한다. 틀린 부분이 나오면 그 지점부터 소설가가 직접 수정하고, 다음 라운드를 또 보조 작가에게 넘긴다.
핵심은 검토가 병렬로 이뤄진다는 점이다. 소설가는 열 문장을 순서대로 한 줄씩 읽는 게 아니라 한눈에 훑어본다. 덕분에 전체 속도가 크게 올라간다. 최종 결과물의 품질은 소설가(대형 모델)가 모두 검수했으니 보장된다. 이것이 투기적 디코딩의 원리다.
문제는 보조 작가, 즉 초안 모델도 여전히 자기회귀 방식으로 글을 쓴다는 점이다. 한 문장씩, 순서대로. EAGLE-3 같은 최신 방법도 이 한계를 벗어나지 못한다. 보조 작가가 아무리 빨라도, 순서대로 열 문장을 써야 한다면 속도는 제한된다.
빈칸을 한꺼번에 채우는 방법
여기서 논문의 주인공인 확산 모델(diffusion model)이 등장한다. 이미지 생성 AI인 미드저니나 DALL-E의 작동 방식이 바로 확산 모델이다. 이 모델은 처음에 노이즈로 가득한 흐릿한 화면에서 시작해, 조금씩 노이즈를 제거하며 선명한 이미지를 만들어낸다. 언어 모델에 적용하면 이렇게 된다. 우선 모든 자리를 "[빈칸]"으로 채운 문장을 만든다. 그리고 이 빈칸들을 한꺼번에 "노이즈를 제거하듯" 채워나간다. 순서가 없다. 1번 빈칸, 5번 빈칸, 3번 빈칸을 동시에 예측한다.
보조 작가가 왼쪽에서 오른쪽으로 한 글자씩 쓰는 대신, 빈칸 열 개를 동시에 채우는 방식이다. 훨씬 빠를 수 있다. 그러나 문제가 있었다. 지금까지 개발된 확산 기반 언어 모델들은 자기회귀 모델보다 품질이 낮았다. 빠른 대신 틀린 답을 많이 썼다. 보조 작가가 빠른 대신 엉터리 초안을 내놓으면, 소설가의 검수에서 번번이 거절당하고 결국 전체 속도는 나빠진다.
DFlash의 해법: 편집장의 메모를 건네주다
이 논문에서 제안하는 DFlash의 핵심 아이디어는 단순하지만 영리하다. 확산 모델 방식의 보조 작가에게 소설가(대형 모델)의 내부 생각을 건네주는 것이다.
비유를 확장해 보자. 지금까지의 보조 작가는 소설가의 글을 겉으로만 읽고 초안을 썼다. 그런데 DFlash의 보조 작가는 소설가가 각 문단을 읽으면서 속으로 무슨 생각을 했는지 담긴 메모를 받는다. "이 다음엔 등장인물 A가 나와야 해", "이 장면의 분위기는 긴장감이어야 해" 같은 내부 맥락이다.
기술적으로는 이렇다. 대형 목표 모델이 입력 문장을 처리할 때 내부적으로 생성하는 숨겨진 표현(hidden representation)을 추출한다. 이 숨겨진 표현은 단순히 "다음 단어가 뭘까"보다 훨씬 풍부한 정보를 담고 있다. 문맥의 의미, 장기적 의존 관계, 미래 토큰에 대한 암묵적인 예측까지 인코딩되어 있다. DFlash는 이 정보를 압축해 확산 초안 모델의 모든 레이어의 Key-Value 캐시에 직접 주입한다.
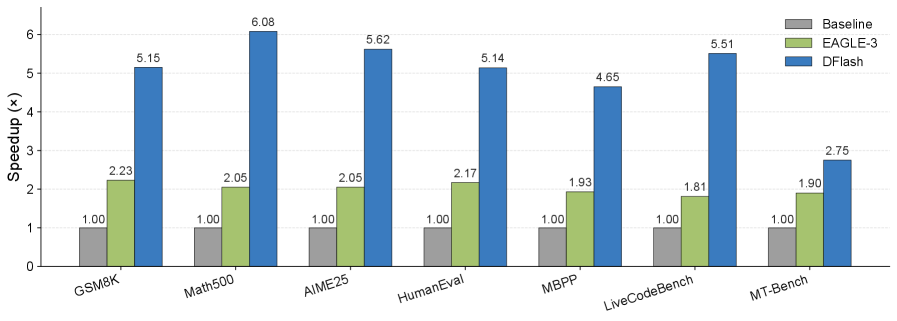
Figure 1: Speedup comparison between DFlash, EAGLE-3 against Autoregressive Decoding on Qwen3-8B with the Transformers backend. Overall, DFlash achieves more than 2.5× higher speedup than EAGLE-3.
여기서 "Key-Value 캐시에 주입한다"는 표현이 낯설게 느껴질 수 있다. 이렇게 상상하면 된다. 보조 작가의 모든 판단 과정에, 소설가의 메모가 항상 옆에 펼쳐져 있는 것이다. 첫 번째 판단을 내릴 때도, 다섯 번째 판단을 내릴 때도. 기존의 EAGLE-3 방식은 이 메모를 보조 작가의 첫 페이지에만 붙여줬다. 작가가 글을 깊이 쓸수록 첫 페이지를 참고하기 어려워지고, 점점 소설가의 의도에서 벗어난다. DFlash는 메모를 매 단계마다 참고할 수 있도록 구조를 바꿨다.
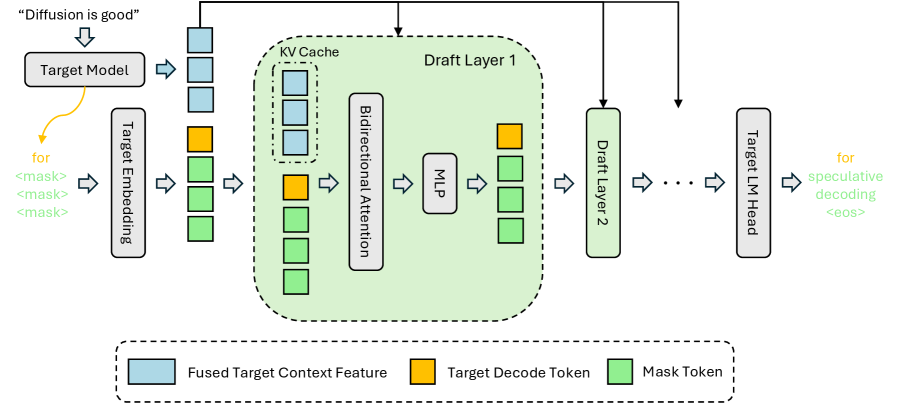
Figure 2: DFlash Inference Design. Hidden context features extracted from the target model are fused and injected into each draft layer's Key-Value cache to enable conditional speculation.
결과는 극적이었다. DFlash는 기존 자기회귀 방식 대비 6배 이상의 속도를 달성했고, 최신 투기적 디코딩 방법인 EAGLE-3보다 2.5배 더 빠른 성능을 보였다. 그것도 최종 결과물의 품질은 전혀 손상시키지 않으면서.
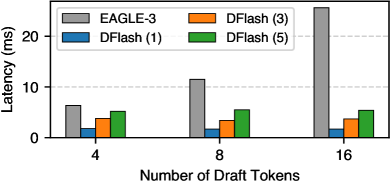
Figure 3: Draft cost of 1, 3, 5-layer DFlash and 1-layer EAGLE-3.
이게 실현되면 무엇이 달라지나
수학 문제를 AI에게 물어보면 한 줄씩 풀이가 나오던 경험을 떠올려 보라. 긴 추론 과정을 요구하는 Chain-of-Thought 방식은 AI가 "생각하는 시간"이 길어질수록 답변 속도가 더 나빠지는 구조적 문제를 안고 있었다. DFlash의 방식이 보편화된다면, AI가 복잡한 수학 문제나 코딩 문제를 풀 때 지금보다 몇 배 빠른 속도로 답을 내놓을 수 있다.
더 중요한 것은 비용이다. 같은 서버에서 더 많은 사람에게 더 빠른 응답을 줄 수 있다는 뜻이기도 하다. AI 서비스의 대중화에 직접적인 영향을 미친다.
남은 질문들
그럼에도 솔직히 물음표가 남는다. 확산 모델 기반 초안 모델은 대형 모델의 맥락을 받아 품질이 높아졌지만, 그 자체로는 여전히 자기회귀 모델보다 약하다. 지금은 "틀린 초안은 대형 모델이 걸러낸다"는 방어망 덕분에 최종 품질이 유지되지만, 초안 거절률이 높아지면 속도 이점이 줄어들 수 있다.
또한 이 연구는 텍스트에 집중되어 있다. 이미지, 음성, 동영상을 생성하는 다른 AI에 같은 방식이 얼마나 잘 적용될지는 아직 열린 질문이다.
연구자들은 논문 결론에서 흥미로운 시각 전환을 제안한다. 지금까지 확산 모델은 자기회귀 모델과 "누가 더 좋은 AI냐"를 겨루는 경쟁자로 여겨졌다. 그런데 DFlash는 이 관계를 완전히 다시 정의한다. 확산 모델은 경쟁자가 아니라, 더 빠른 AI를 만들기 위한 보조 엔진이 될 수 있다. 서로 다른 특기를 가진 두 AI가 협력할 때, 결과가 더 좋아진다는 이야기다. 어쩌면 AI의 발전도 결국 협력의 문제인지 모른다.
태그: AI가속, 언어모델, 확산모델, 추론속도
📄 원문: https://arxiv.org/abs/2602.06036
🌐 English version on Dev.to: https://dev.to/xoqhdgh1002/the-sous-chef-who-guesses-in-batches-33ph
