새벽 두 시, 막힌 코드 앞에서
새벽 두 시. 모니터 앞에 앉아 있다. 화면에는 빨간 줄로 가득한 에러 메시지. 어디서부터 손대야 할지 모르겠다. 옆에는 식어버린 커피, 책상 위에는 어제부터 쌓인 영수증과 접시들. 한숨을 쉬며 챗봇 창을 연다. "이거 좀 고쳐줘." 그러면 AI가 코드 한 조각을 던져준다. 복사해서 붙여넣는다. 또 에러가 난다. 다시 묻는다. 또 코드를 받는다. 다시 붙여넣는다. 이 반복을 사람들은 한동안 "바이브 코딩(vibe coding)"이라고 불렀다. 코드의 원리를 깊이 이해하지 않고 분위기로, 감으로, 챗봇이 던져주는 조각을 이어 붙여 그럭저럭 굴러가게 만드는 것.
문제는 이 방식이 아주 작은 장난감 프로그램에서나 통한다는 점이다. 진짜 소프트웨어는 수십 개의 파일이 얽혀 있고, 한 줄을 고치면 다른 곳에서 무너지고, 사람의 의도를 처음부터 끝까지 추적해야 한다. 챗봇에게 한 조각씩 시켜서는 결코 완성되지 않는다. 누군가는 그 모든 흐름을 머리에 담고 있어야 한다. 지금까지 그 누군가는 사람이었다.
GLM-5라는 새 모델은, 그 누군가의 자리를 AI가 대신할 수 있다고 주장한다. 분위기로 코드 조각을 던져주던 조수가, 이제 머리에 전체 설계도를 그리고 직접 망치를 드는 엔지니어가 되었다는 것이다. 연구팀은 이를 "바이브 코딩에서 에이전트 엔지니어링으로의 전환"이라고 부른다.
모델이 똑똑해지는 두 가지 길
AI를 더 똑똑하게 만드는 방법을 비유하자면 두 가지다. 첫째는 책을 더 많이 읽히는 것. 둘째는 직접 문제를 풀게 하고, 틀리면 가르치는 것. 지금까지 거대 언어 모델은 첫 번째 길을 주로 걸어왔다. 인터넷에 있는 거의 모든 글을 모델에 쏟아붓고, 단어들 사이의 관계를 외우게 한다. 이 방식은 모델을 박학다식한 도서관 사서로 만든다. 무엇이든 물어보면 어디선가 본 듯한 답을 돌려준다.
하지만 박학다식한 사서가 곧바로 유능한 엔지니어가 되지는 않는다. 엔지니어는 모르는 문제를 만났을 때 시도하고, 실패하고, 고쳐가며 답에 도달한다. AI에게 이 두 번째 능력을 키우려면 강화학습이라는 훈련 방식이 필요하다. 모델이 어떤 일을 시도하면, 잘했을 때는 칭찬 신호를, 못했을 때는 꾸중 신호를 보내준다. 이 신호를 수만 번, 수백만 번 받으며 모델의 내부 회로가 조금씩 바뀐다. 시험을 망친 학생이 답안을 받아 들고 어디서 틀렸는지 짚어가며 다음 시험을 준비하는 것과 같다.
GLM-5의 핵심 자랑거리는 바로 이 강화학습 단계를 새롭게 설계했다는 점이다. 그리고 그 새로움은 "비동기"라는 한 단어로 요약된다.
비동기 강화학습, 콜센터의 이중 라인
비동기(asynchronous)란 무엇인가. 회사에서 흔한 회의 풍경을 떠올려보자. 한 사람이 발표를 하고, 모두가 그 사람만 바라보며 끝나기를 기다린다. 한 명이 끝나면 다음 사람이 발표한다. 이게 동기식이다. 한 명이 5분 동안 막히면, 나머지 열 명이 5분 동안 함께 멈춰 있다.
비동기는 이런 식이다. 카페에서 사람들이 각자 노트북으로 일하고 있다. 누군가 막히면 옆 사람에게 메시지를 보내고, 답이 올 때까지 자기는 다른 일을 한다. 모두가 모두를 기다리지 않는다. 전체 처리량이 폭발적으로 늘어난다.
기존의 강화학습은 동기식 회의에 가까웠다. 모델이 답을 만드는 단계(생성)와, 그 답을 평가해서 모델을 업데이트하는 단계(훈련)가 한 줄에 매달려 돌아갔다. 모델이 긴 답을 만드는 동안 훈련용 컴퓨터는 멍하니 놀고 있었다. 모델이 잠깐 학습되는 동안에는 거꾸로 답을 만드는 쪽이 멈춰 있었다. 비싼 GPU 수천 대가 절반의 시간을 낭비하고 있었던 셈이다.
GLM-5 팀은 이 두 단계를 떼어놓았다. 답을 만드는 라인은 계속 답을 만들고, 훈련 라인은 들어오는 답을 받는 대로 모델을 다듬는다. 콜센터에 비유하면, 전화를 받는 상담원과 결과를 정리하는 후처리팀을 분리한 것이다. 상담원은 끊임없이 다음 전화를 받고, 후처리팀은 들어오는 통화 기록을 차례로 처리한다. 둘 사이의 약간의 시차는 감수하지만, 전체 처리량은 비교할 수 없이 늘어난다. 연구팀이 "post-training 효율을 극적으로 개선했다"고 말하는 게 이 의미다.
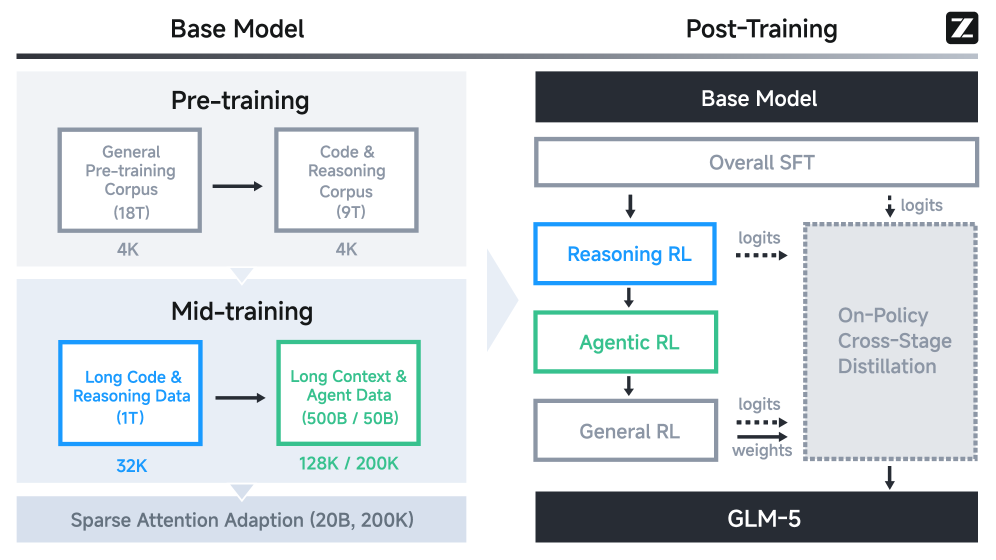
Figure 5: Overall training pipeline of GLM-5.
긴 호흡으로 일을 끝까지 해내는 능력
여기까지가 인프라 이야기였다면, 진짜 어려운 문제는 따로 있다. 강화학습으로 짧은 문제는 잘 풀게 만들 수 있다. "두 수를 더해라" 같은 일은 한 번 시도하고 한 번 채점하면 된다. 하지만 "이 웹사이트 전체를 만들어라" 같은 일은 어떻게 가르치는가. 한 번의 작업이 수십 단계로 이어지고, 각 단계마다 또 분기가 생긴다. 어느 시점의 어느 결정이 마지막 결과의 성패를 갈랐는지 따지기가 거의 불가능하다.
이걸 비유하자면, 골프 한 라운드를 마친 뒤 점수만 보고 "어느 스윙이 잘못이었는지" 가르치는 것과 같다. 18홀 동안 수백 번의 스윙이 있었고, 그중 몇 개의 작은 실수가 누적돼 점수를 망쳤다. 코치가 "이 라운드는 망했어"라는 한 마디만 한다면 선수는 아무것도 배우지 못한다. 매 스윙마다 어떤 부분이 좋았고 어떤 부분이 나빴는지 짚어줘야 다음 라운드가 달라진다.
GLM-5 팀이 새로 제안한 비동기 에이전트 강화학습 알고리즘이 하려는 일이 정확히 이거다. 길고 복잡한 작업을 모델이 끝까지 수행하게 두고, 그 과정 곳곳의 결정에 적절한 칭찬과 꾸중 신호를 흘려보내 모델이 긴 호흡의 일에서도 점차 나아지게 만든다. 코드를 짜다 막혔을 때 우회 경로를 찾고, 테스트가 실패하면 원인을 짚어 고치고, 그 고침이 다른 곳을 망가뜨리지 않는지 확인하는, 진짜 엔지니어가 하는 일을 모델이 스스로 익히게 한다.
Figure 4: Results on several long-horizon tasks. Left: Vending-Bench 2; Right: CC-Bench-V2.
길게 기억하면서도 가볍게 — DSA라는 다이어트
또 하나의 기술적 도전은 비용이다. 모델이 긴 작업을 하려면 긴 문맥을 한꺼번에 머리에 담고 있어야 한다. 코드 1만 줄을 짜려면 1만 줄을 모두 기억하면서 다음 한 줄을 결정해야 한다. 그런데 기존의 어텐션이라는 방식은 문맥이 길어질수록 비용이 기하급수적으로 늘어난다. 책을 읽을 때 한 페이지가 늘어날 때마다 모든 페이지를 다시 한 번씩 훑어보는 사람을 상상해보라. 200페이지짜리 책을 읽고 나면 그가 훑어본 횟수는 페이지 수의 제곱에 가까워진다.
GLM-5는 DSA라는 새로운 어텐션 구조를 채택했다. 자세한 수식은 논문 본문에 있지만, 비유하자면 책을 읽을 때 모든 페이지를 다 훑지 않고, 색인과 책갈피를 영리하게 활용해 정말 필요한 몇 페이지만 들춰보는 독자에 가깝다. 긴 문맥을 잃지 않으면서도, 매 단계의 비용을 극적으로 줄였다. 학습할 때도, 실제로 답을 만들 때도 둘 다 빨라졌다. 더 무거운 사고를 하면서 더 가벼운 몸으로 움직이는, 일종의 다이어트에 성공한 셈이다.
결과는 어디까지 왔나
이렇게 비동기 인프라, 비동기 에이전트 강화학습, DSA라는 세 축으로 다듬어진 GLM-5는 어디쯤 와 있는가. 연구팀은 8개의 주요 벤치마크에서 GLM-5를 자사의 이전 모델 GLM-4.7, 그리고 클로드 오퍼스 4.5, 제미나이 3 프로, GPT-5.2와 비교했다. 평균적으로 GLM-4.7 대비 약 20% 향상되었고, 클로드 오퍼스 4.5 및 GPT-5.2와 비등하며, 제미나이 3 프로보다는 앞선다고 보고한다.
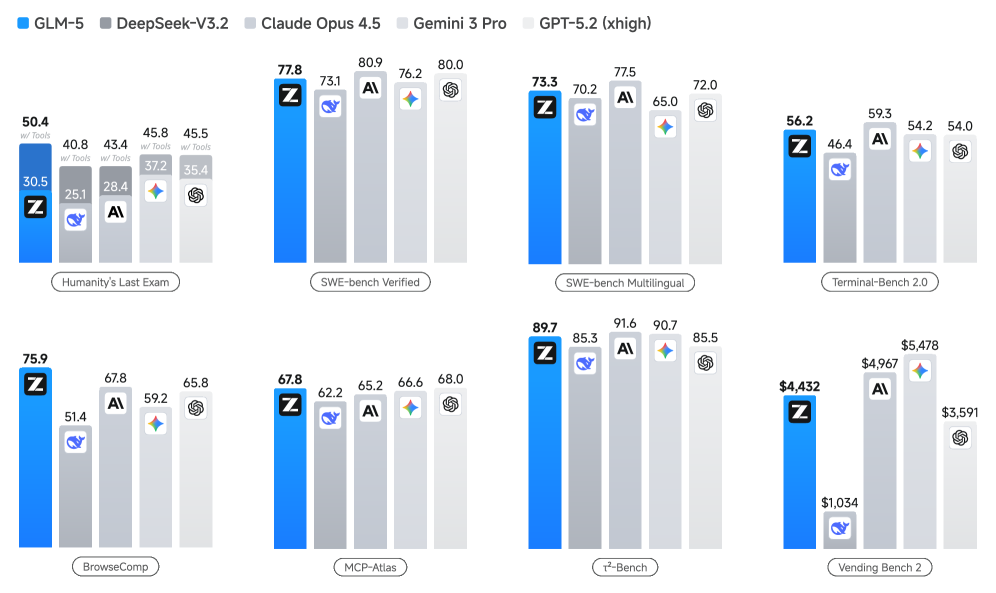
Figure 1: Results of GLM-5, DeepSeek-V3.2, Claude Opus 4.5, Gemini 3 Pro, and GPT-5.2 (xhigh) on 8 agentic, reasoning, and coding benchmarks.
특히 의미 있는 숫자가 하나 있다. Artificial Analysis Intelligence Index v4.0이라는 종합 지능 지표에서 GLM-5는 50점을 기록했다. 이전 버전이 42점이었으니 8점이 한 번에 뛴 것이고, 무엇보다 가중치가 공개된 오픈 모델 중에서 50점을 받은 것은 처음이다. 이 점수는 단순한 시험 점수가 아니라, 환각이 얼마나 적은지, 에이전트로서 얼마나 자율적으로 일하는지를 모두 합산한 종합 평가다.
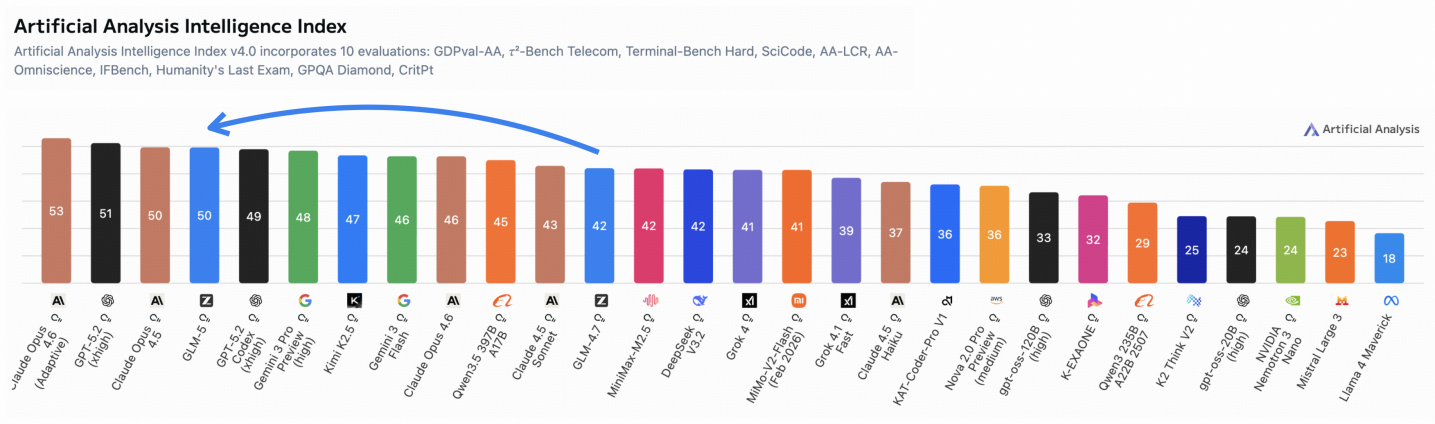
Figure 2: Artificial Analysis Intelligence Index v4.0 incorporates 10 evaluations.
LMArena라는 또 다른 평가도 흥미롭다. 이 평가는 정해진 시험지 대신, 실제 사람들이 두 모델의 답을 보고 어느 쪽이 더 좋은지 직접 투표하는 방식이다. 정적인 벤치마크와 달리 실제 사용 맥락에서의 유용성을 본다. GLM-5는 이 무대에서 텍스트와 코드 두 부문 모두 오픈 모델 1위를 차지했다.
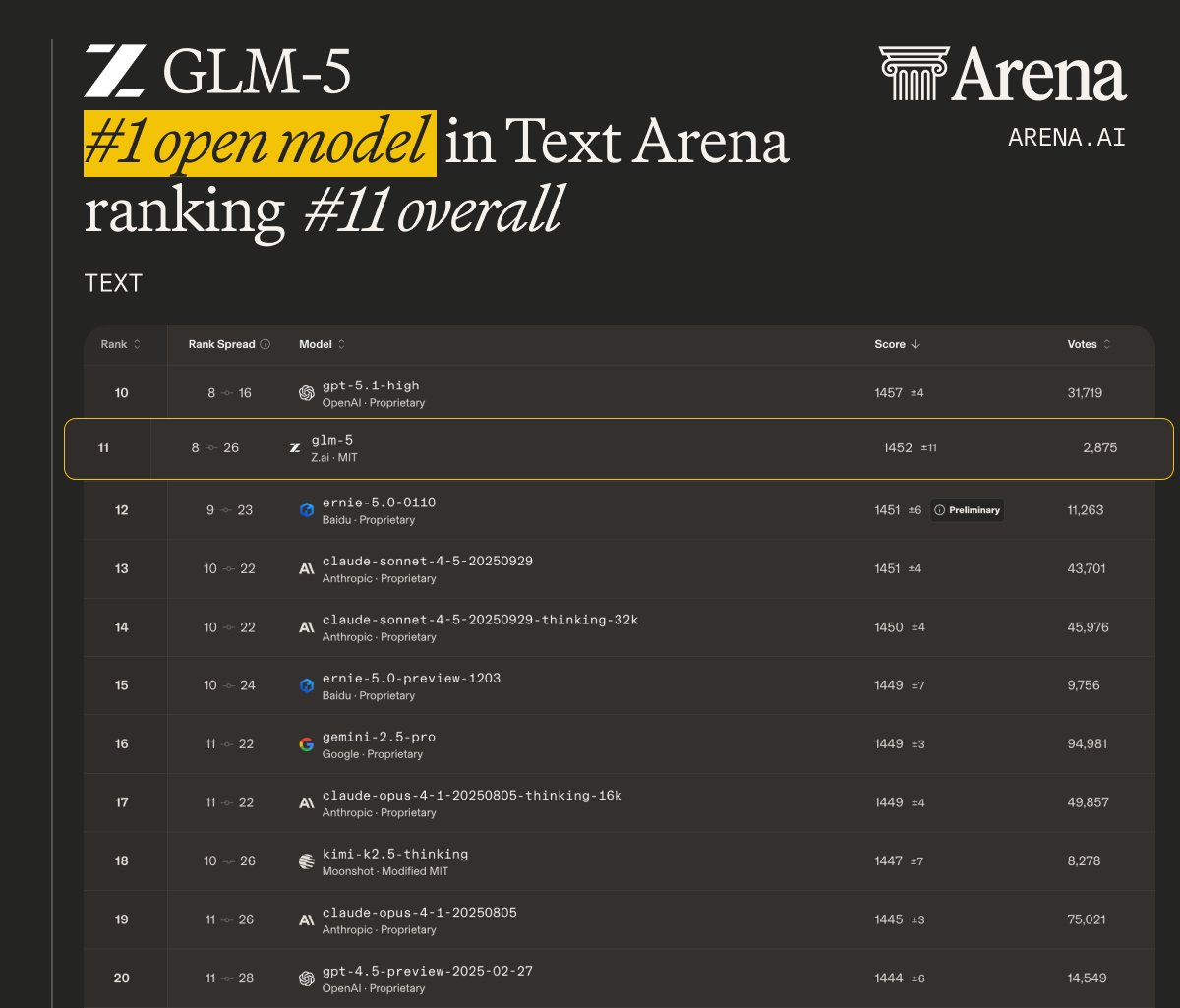
Figure 3: On LMArena, GLM-5 is the #1 open model in both Text Arena and Code Arena.
우리 일상에는 무엇이 달라지나
이 모든 것이 실현되면, 새벽 두 시의 풍경이 달라진다. 막힌 코드를 한 조각씩 던져주는 챗봇이 아니라, 옆자리에 앉아 전체 프로젝트의 구조를 함께 들여다보고, 새로 추가할 기능을 듣고, 관련 파일을 찾아 고치고, 테스트를 돌려보고, 깨진 부분을 다시 고치고, 마침내 "다 됐어요"라고 말해주는 동료가 생긴다. 코딩에만 한정된 이야기가 아니다. 며칠치 일정을 함께 짜고, 자료를 모으고, 보고서를 쓰고, 누락된 부분을 챙겨주는 비서도 같은 원리에서 나온다.
오픈 모델이라는 점도 중요하다. 누구나 이 모델의 가중치를 내려받아 자기 컴퓨터에서 돌릴 수 있고, 자신의 데이터로 다듬을 수 있다. 빅테크 기업의 서버에 의존하지 않아도 된다는 뜻이다. 한국의 작은 회사도, 학교의 연구실도, 한 명의 개인 개발자도 같은 출발선에 설 수 있다.
남는 의문들
물론 의문도 남는다. 벤치마크 점수가 높다는 것이 곧 우리 일상의 모든 일을 잘한다는 뜻은 아니다. 시험 잘 보는 학생이 반드시 좋은 동료는 아닌 것과 같다. 비동기 강화학습은 효율을 높였지만, 답을 만드는 모델과 학습되는 모델 사이의 작은 시차가 어떤 미묘한 편향을 만들어낼지는 더 두고 봐야 한다. 또 모델이 긴 호흡의 일을 자율적으로 해낸다는 것은, 그 자율의 끝에 사람이 의도하지 않은 결정이 끼어들 가능성도 함께 키운다. 누가 어디까지 책임질 것인가는 기술이 답해주지 않는다.
그래도 한 가지는 분명해 보인다. 분위기로 코드를 던져주던 시대는 지나가고 있다. 옆자리에 앉아 함께 일을 끝까지 해내는 동료로서의 AI라는 새로운 풍경이, 이제 막 윤곽을 드러내고 있다.
태그: GLM-5, 강화학습, 에이전트, 오픈모델
📄 원문: https://arxiv.org/abs/2602.15763
🌐 English version on Dev.to: https://dev.to/xoqhdgh1002/when-code-stopped-being-a-vibe-and-started-being-a-job-b1l
