Trie란?
-
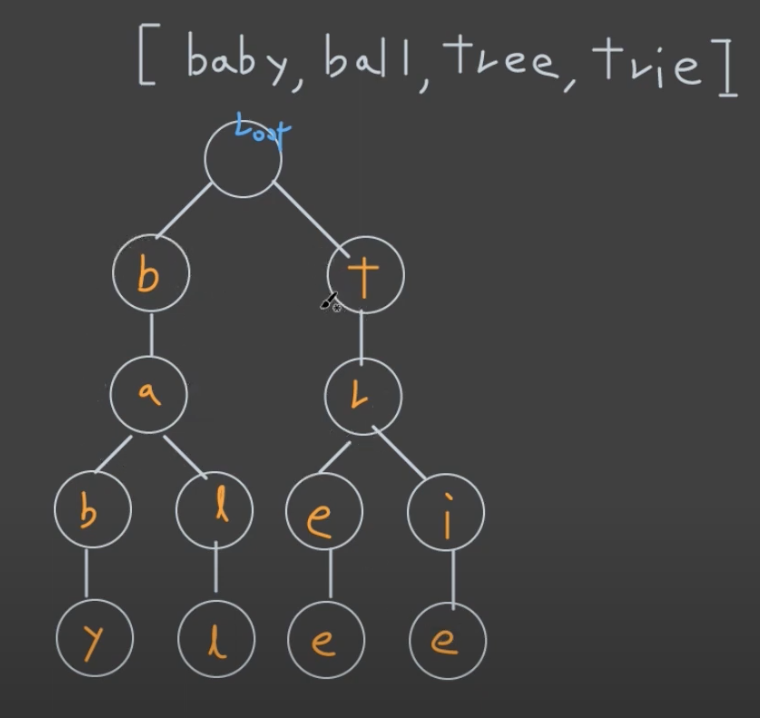
트라이(Trie)는 문자열을 저장하고 효율적으로 탐색하기 위한 트리 형태의 자료구조이다.
-
우리가 검색할 때 볼 수 있는 자동완성 기능, 사전 검색 등 문자열을 탐색하는데 특화되어있는 자료구조라고 한다.
문자열 자동완성기능 로직구현방법
- 스펠링 체크도 가능
-
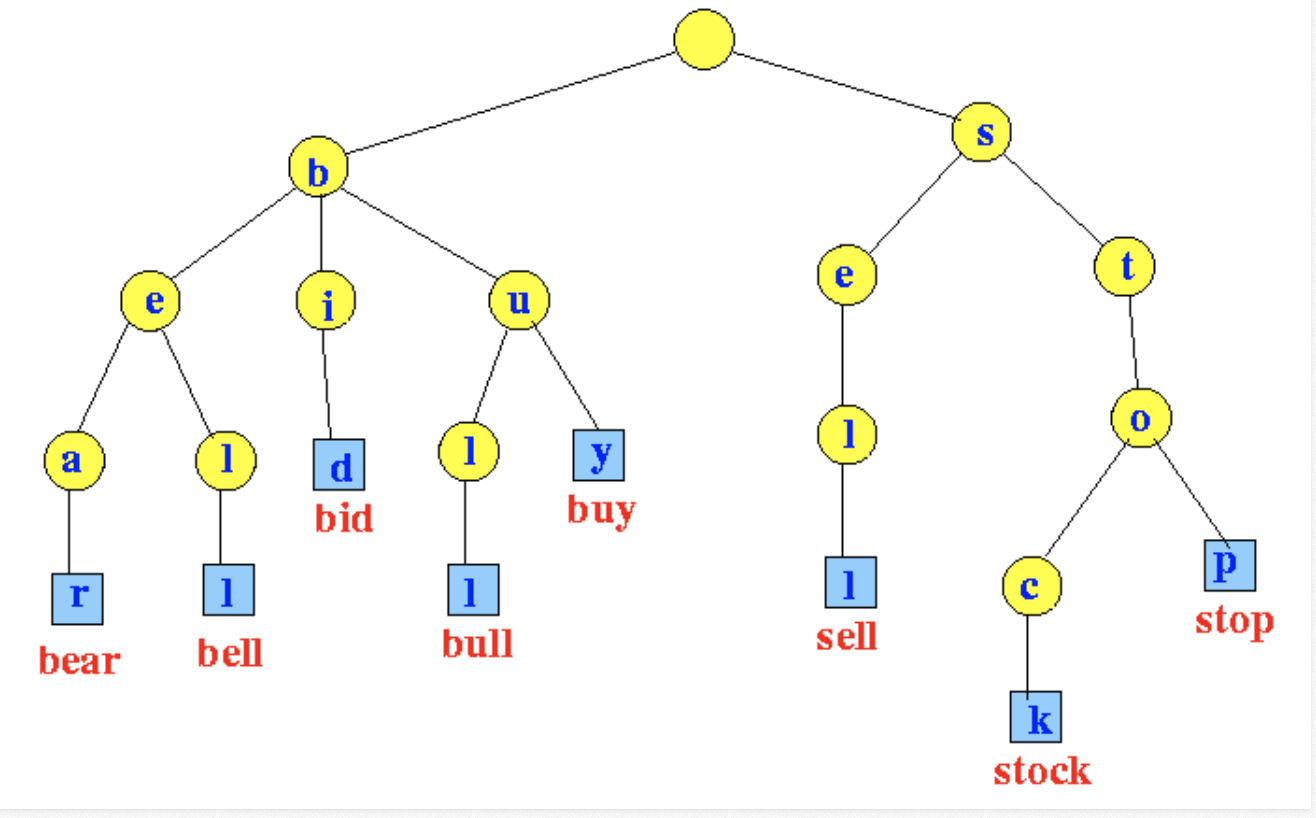
래딕스 트리(radix tree) or 접두사 트리(prefix tree) or 탐색 트리(retrieval tree)라고도 한다. 트라이는 retrieval tree에서 나온 단어이다.
예를 들어 'Datastructure'라는 단어를 검색하기 위해서는 제일 먼저 'D'를 찾고, 다음에 'a', 't', ... 의 순서로 찾으면 된다. 이러한 개념을 적용한 것이 트라이(Trie)이다.
시간복잡도
어떤 단어를 찾고자할때 시간복잡도는 얼마나 나올까?
-> O(M)
이때 M은 그 단어의 길이이다.
트라이(Trie) 장단점
-
트라이(Trie)는 문자열 검색을 빠르게 한다.
-
문자열을 탐색할 때, 하나하나씩 전부 비교하면서 탐색을 하는 것보다 시간 복잡도 측면에서 훨씬 더 효율적이다.
-
각 노드에서 자식들에 대한 포인터들을 배열로 모두 저장하고 있다는 점에서 저장 공간의 크기가 크다는 단점도 있다. (메모리 측면에서 비효율적일 수 있음!)
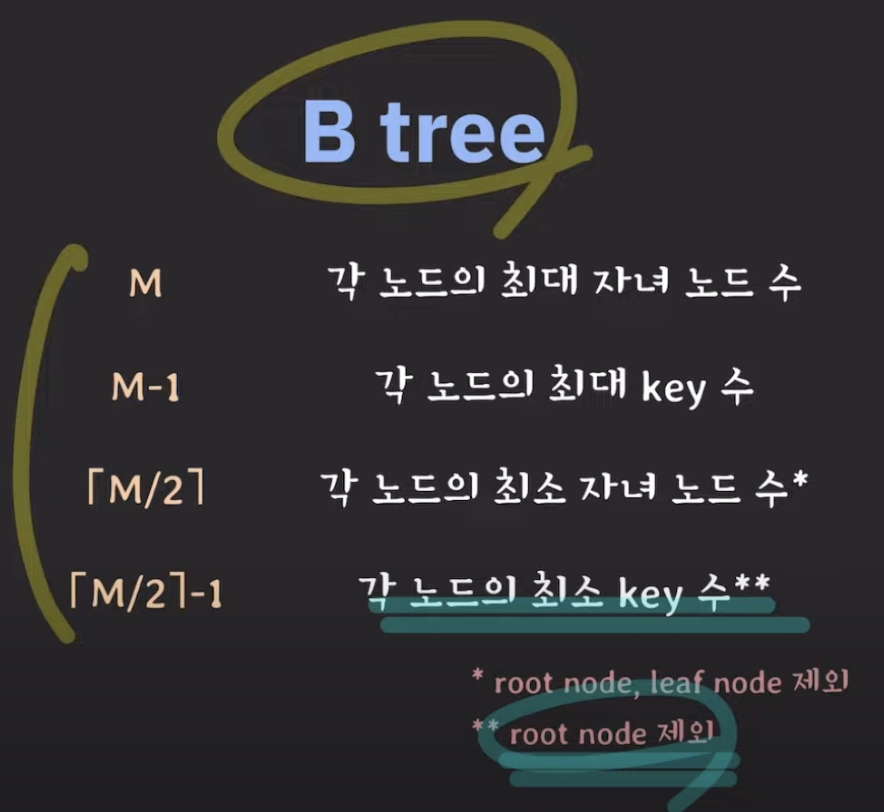
B-Tree란?
B-Tree는 탐색 성능을 높이기 위해 균형 있게 높이를 유지하는 Balanced Tree의 일종이다.
모든 leaf node가 같은 level로 유지되도록 자동으로 밸런스를 맞춰준다. 자식 node의 개수가 2개 이상이며, node 내의 key가 1개 이상일 수 있다.
node의 자식 수 중 최댓값을 K라고 하면, 해당 B-Tree를 K차 B-Tree라고도 한다.
자식 node의 갯수를 정할 수 있다.
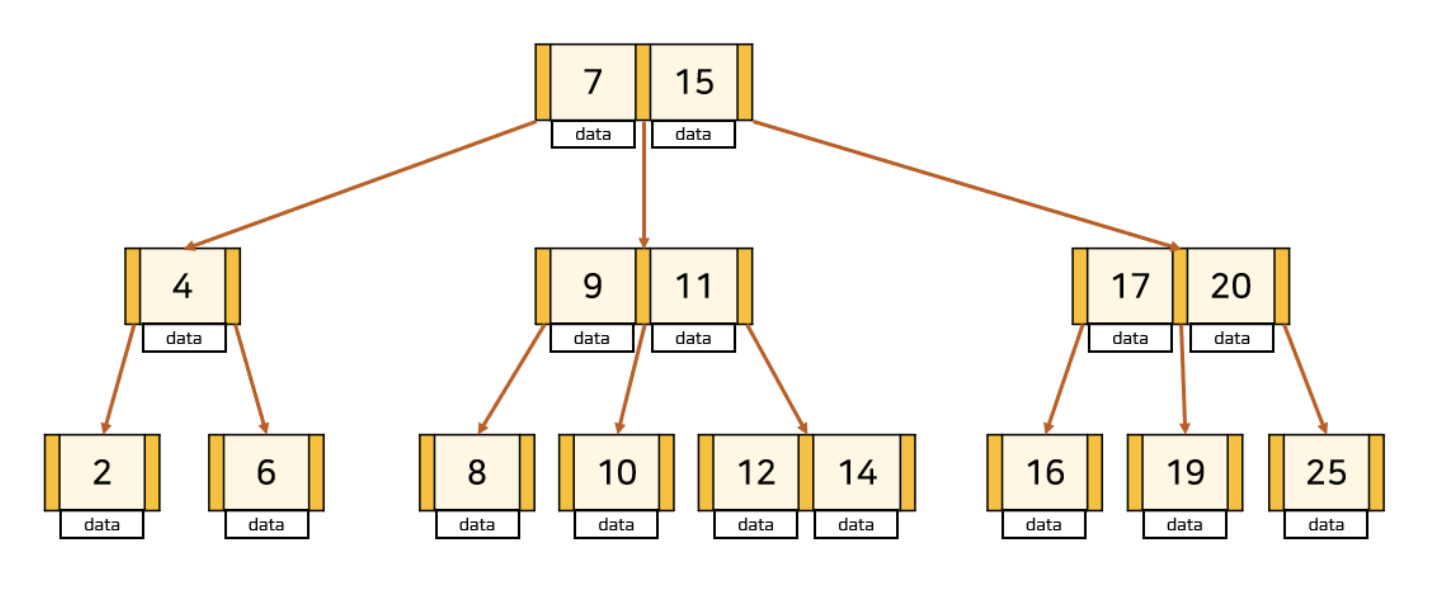
위 사진의 트리는 3차 B-Tree이다.
조건
-
node의 key의 수가 k개라면, 자식 node의 수는 k+1개이다.
-
node의 key는 반드시 정렬된 상태여야 한다.
-
자식 node들의 key는 현재 node의 key를 기준으로 크기 순으로 나뉘게 된다.
-
root node는 항상 2개 이상의 자식 node를 갖는다. (root node가 leaf node인 경우 제외)
-
M차 트리일 때, root node와 leaf node를 제외한 모든 node는 최소
[M/2]<-올림표시, 최대 M개의 서브 트리를 갖는다. -
모든 leaf node들은 같은 level에 있어야 한다.
Balanced tree
일반적인 트리인 경우 탐색하는데 평균적인 시간 복잡도로 O(logN)을 갖지만, 트리가 편향된 경우 최악의 시간복잡도로 O(N)을 갖게 된다.
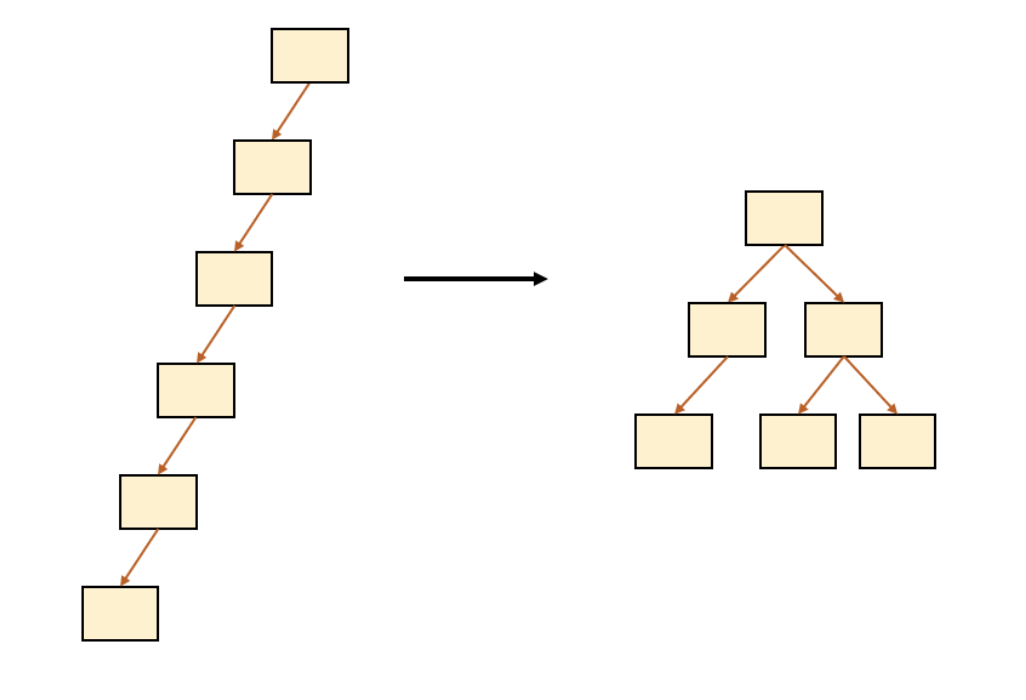
이진트리와 다르게 B-Tree는 최악의 경우에도 O(logN)의 시간이 보장된다.
그래서 DB의 인덱스로 활용함.
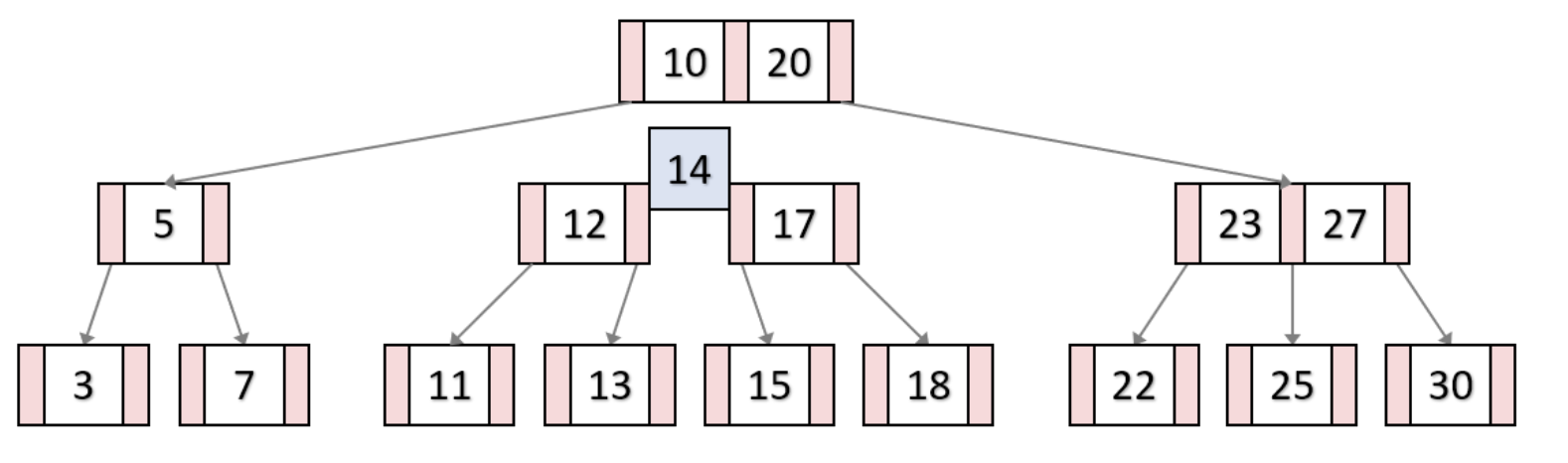
B-Tree의 key 검색
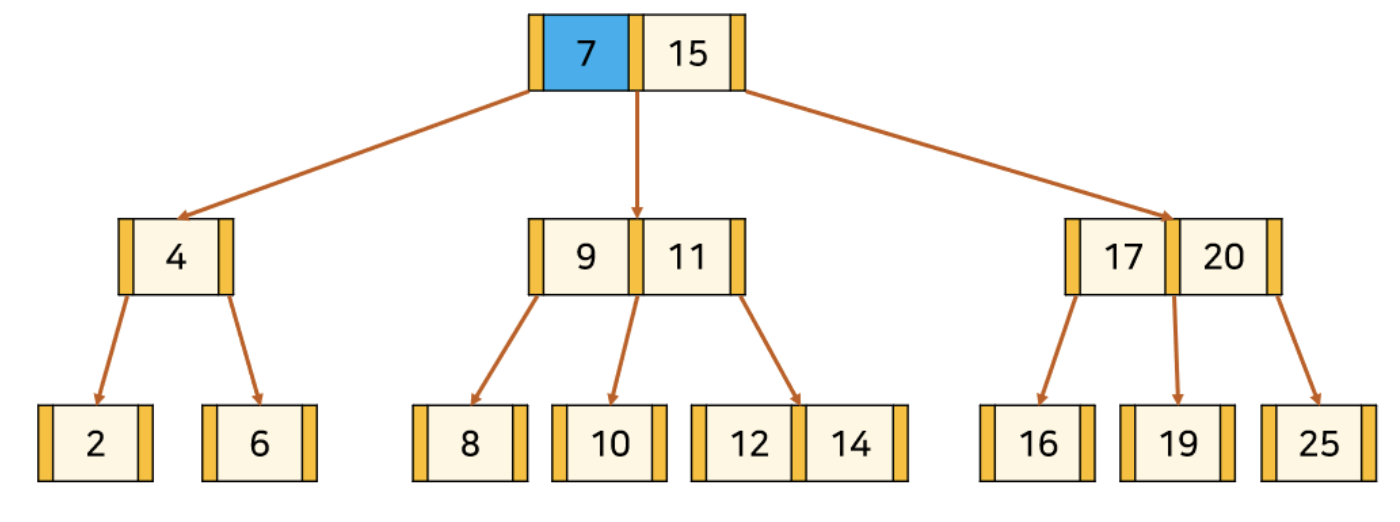
14라는 key를 검색해보자
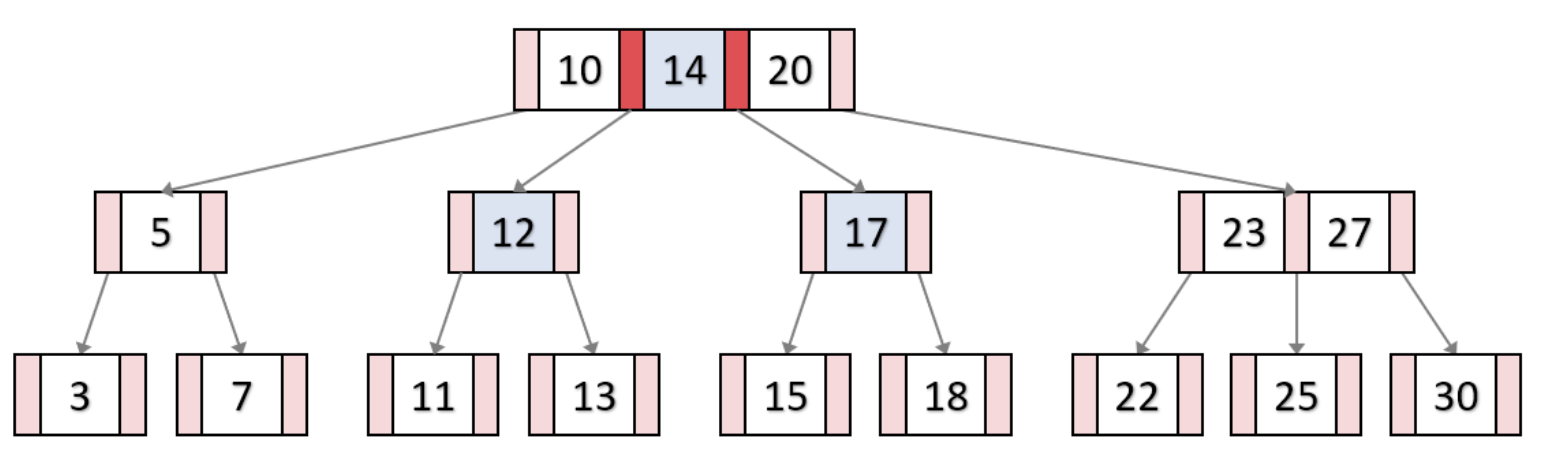
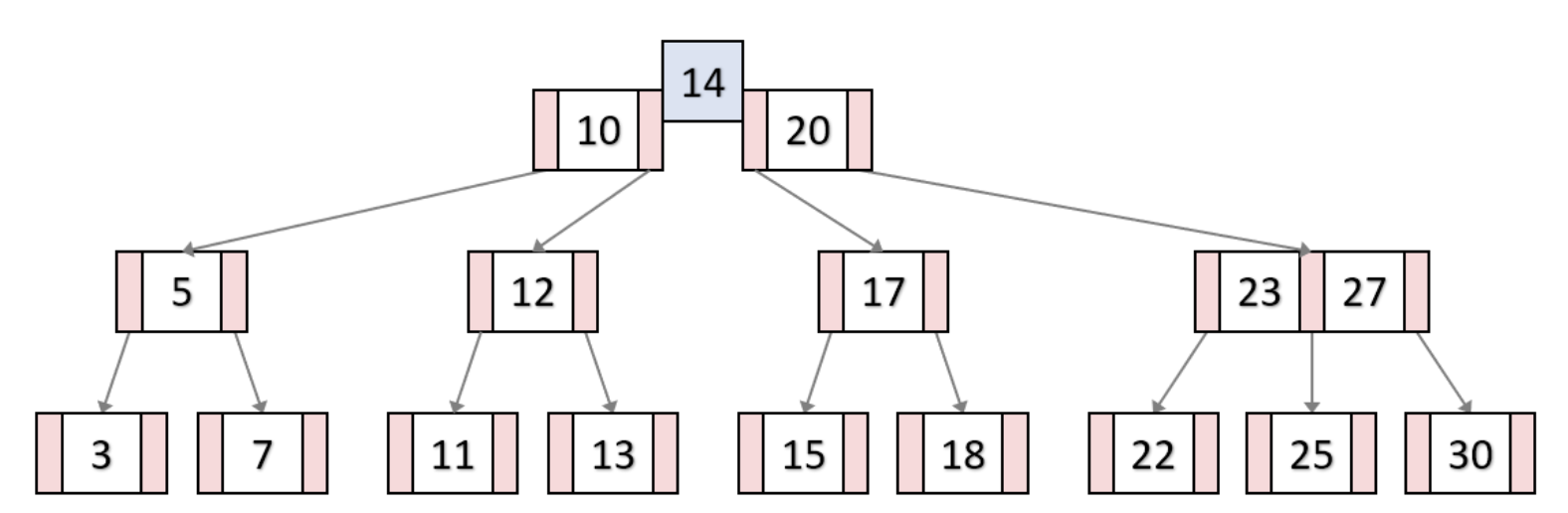
B-Tree의 key 삽입

13 삽입
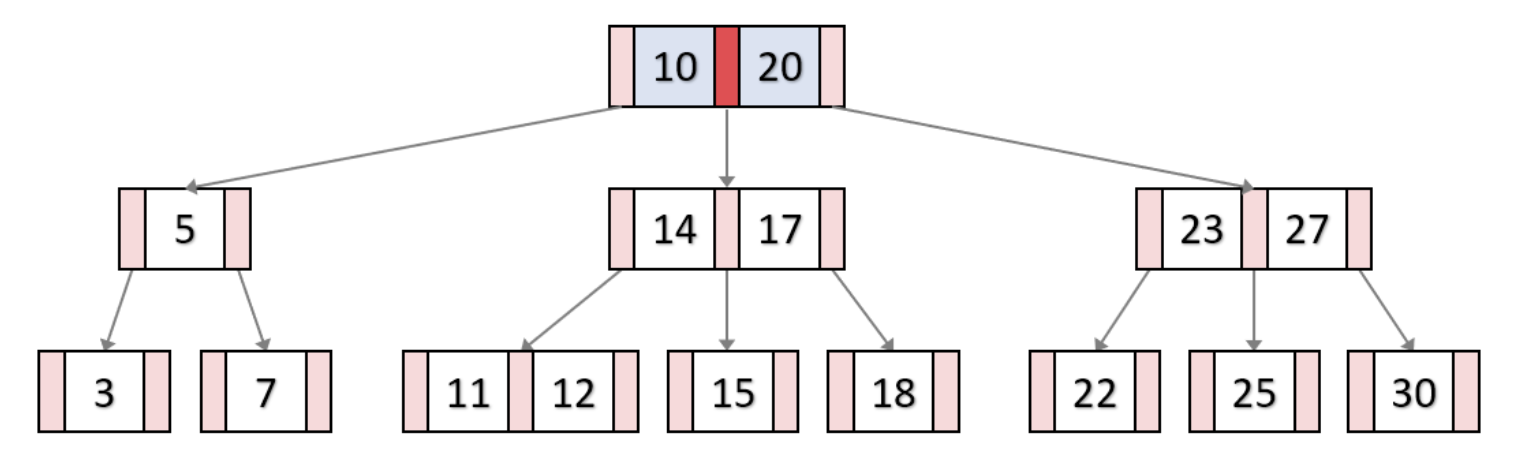
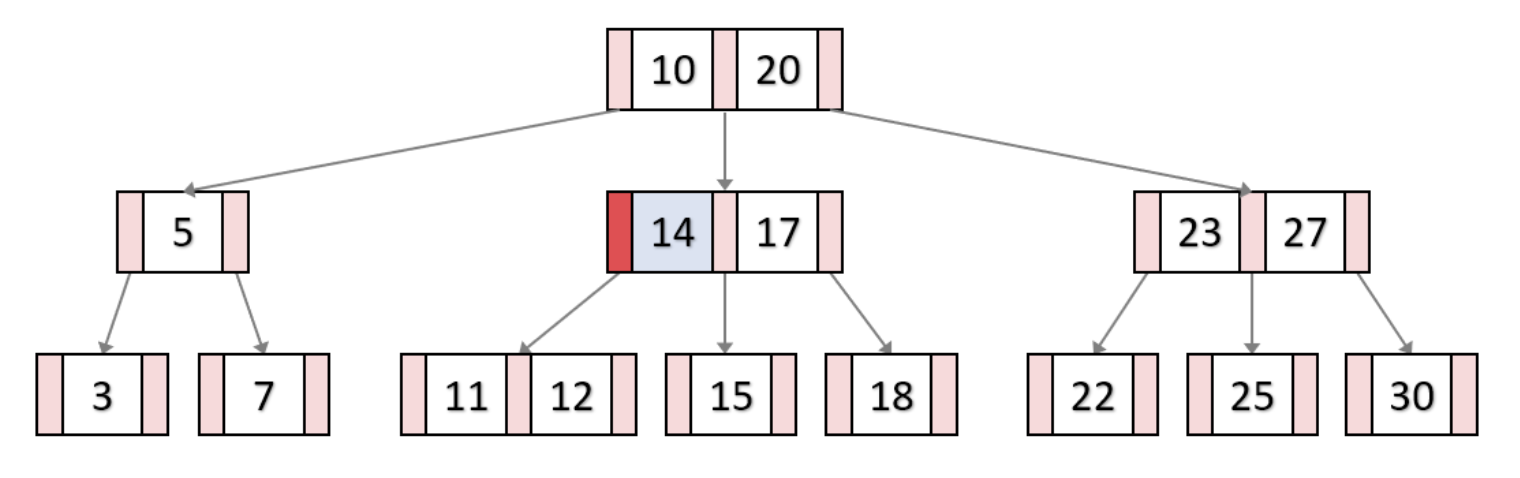
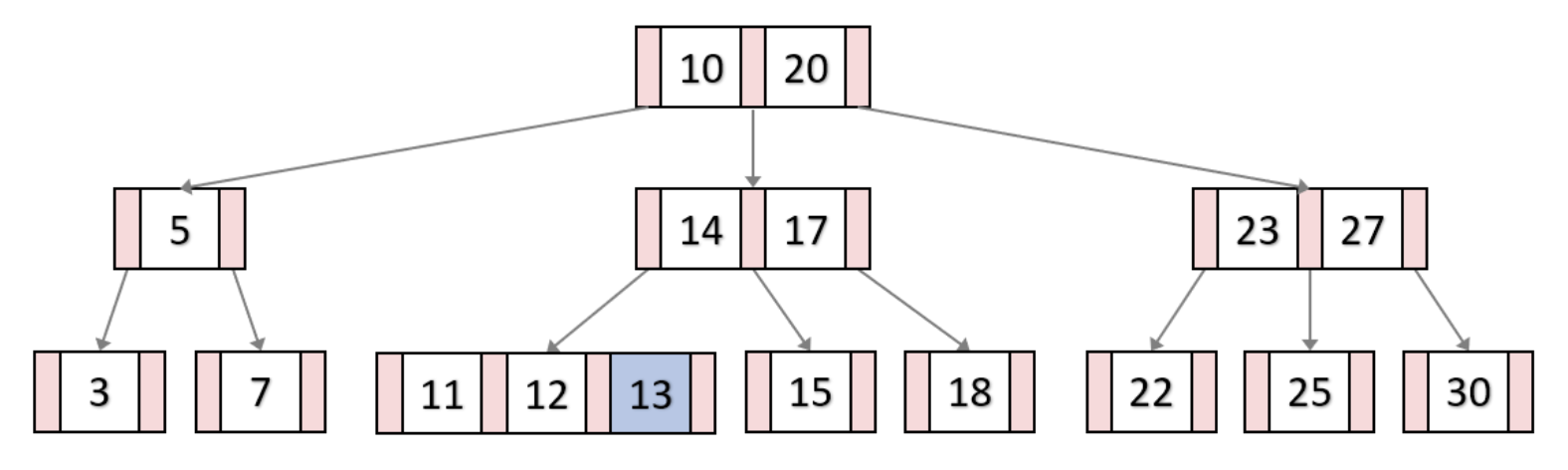
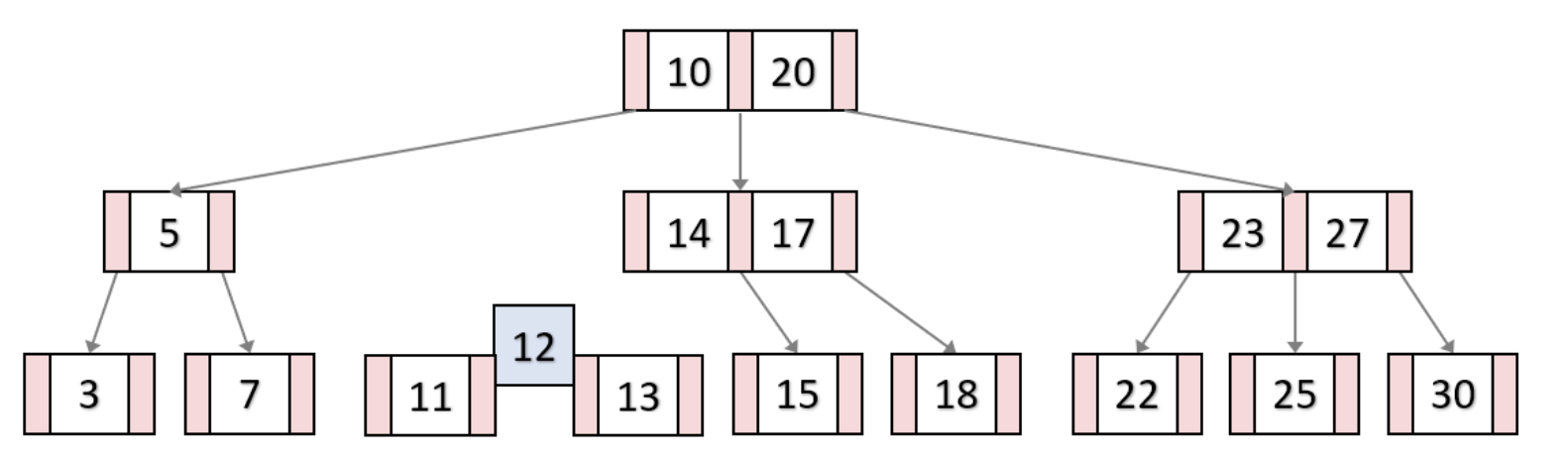
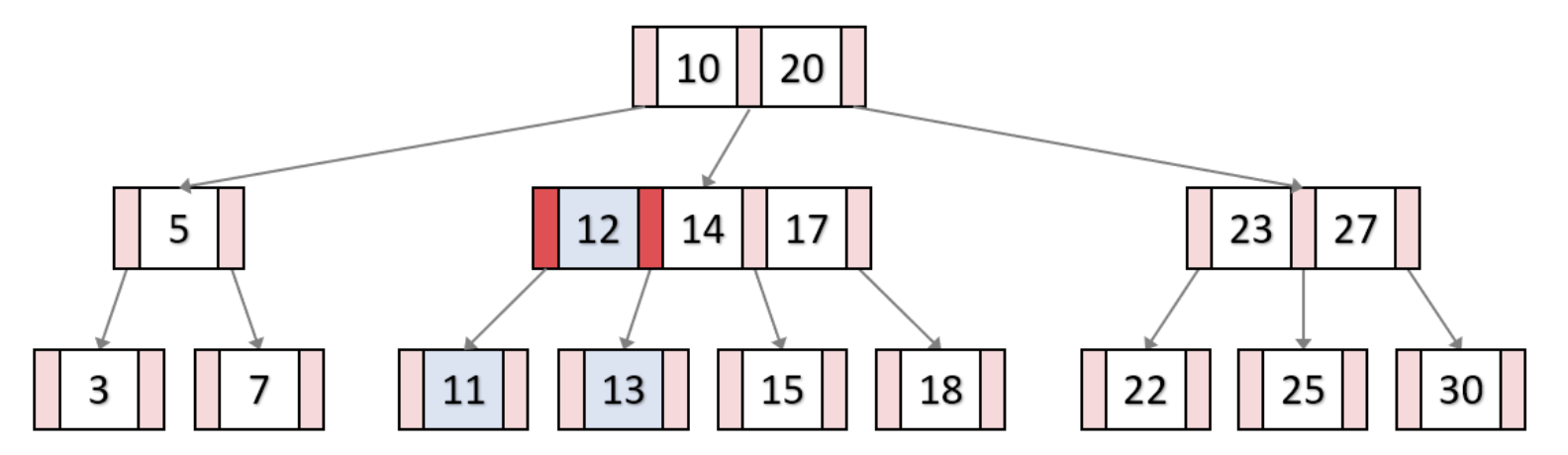
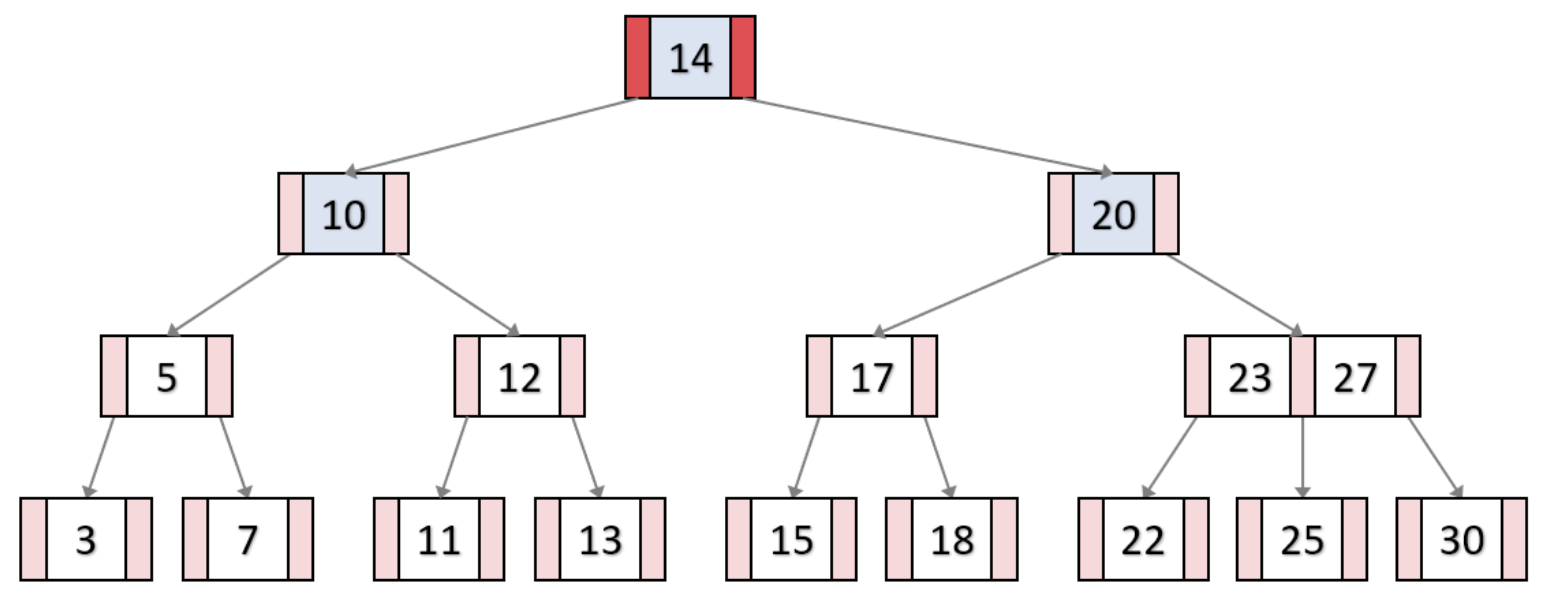
B-Tree의 key 삭제과정



B+Tree란?
실제 DB의 인덱싱은 B+트리로 이루어져있다고 합니다. 다음 그림은 인덱싱을 나타낸 것입니다. 인덱싱은 어떠한 자료를 찾는데 key값을 이용해 효과적으로 찾을 수 있는 기능입니다.
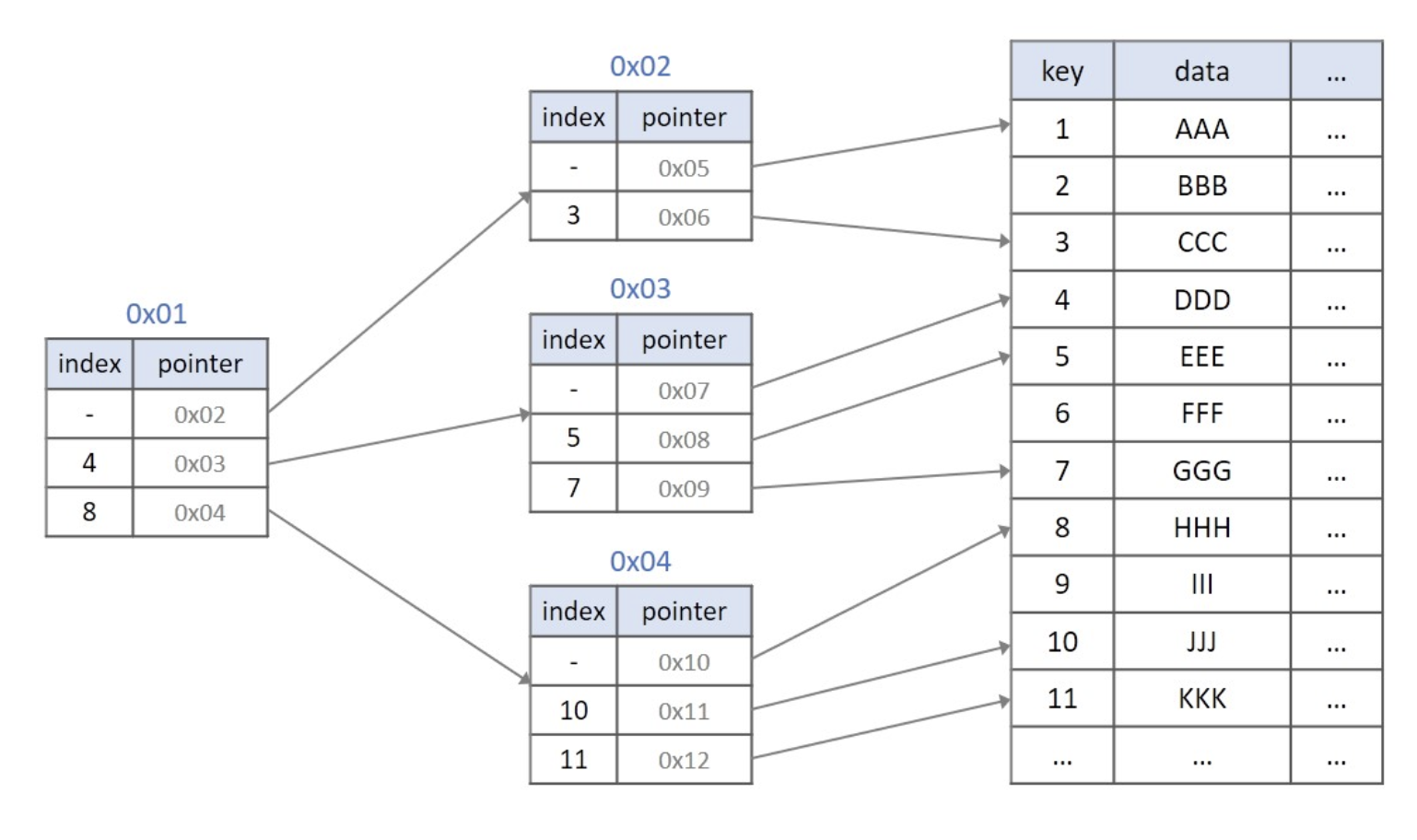
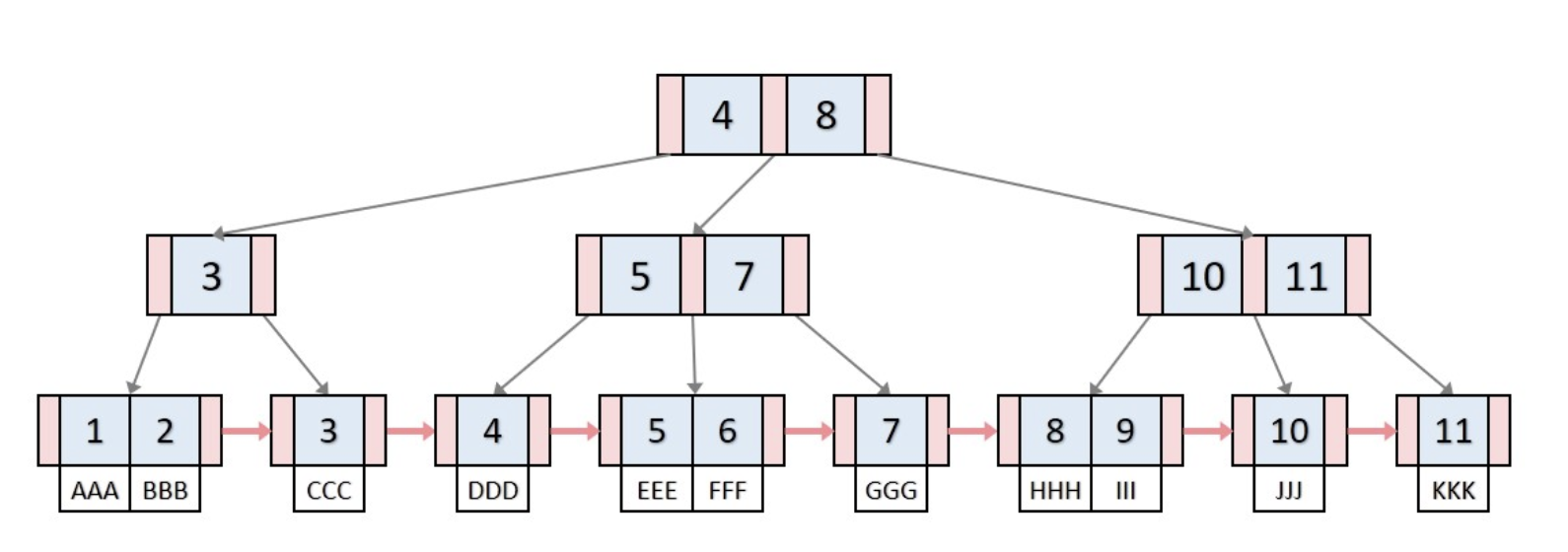
B트리와 B+트리 차이점
-
모든 key, data가 리프노드에 모여있습니다. B트리는 리프노드가 아닌 각자 key마다 data를 가진다면, B+트리는 리프 노드에 모든 data를 가집니다.
-
모든 리프노드가 연결리스트의 형태를 띄고 있습니다. B트리는 옆에있는 리프노드를 검사할 때, 다시 루트노드부터 검사해야 한다면, B+트리는 리프노드에서 선형검사를 수행할 수 있어 시간복잡도가 굉장히 줄어듭니다.
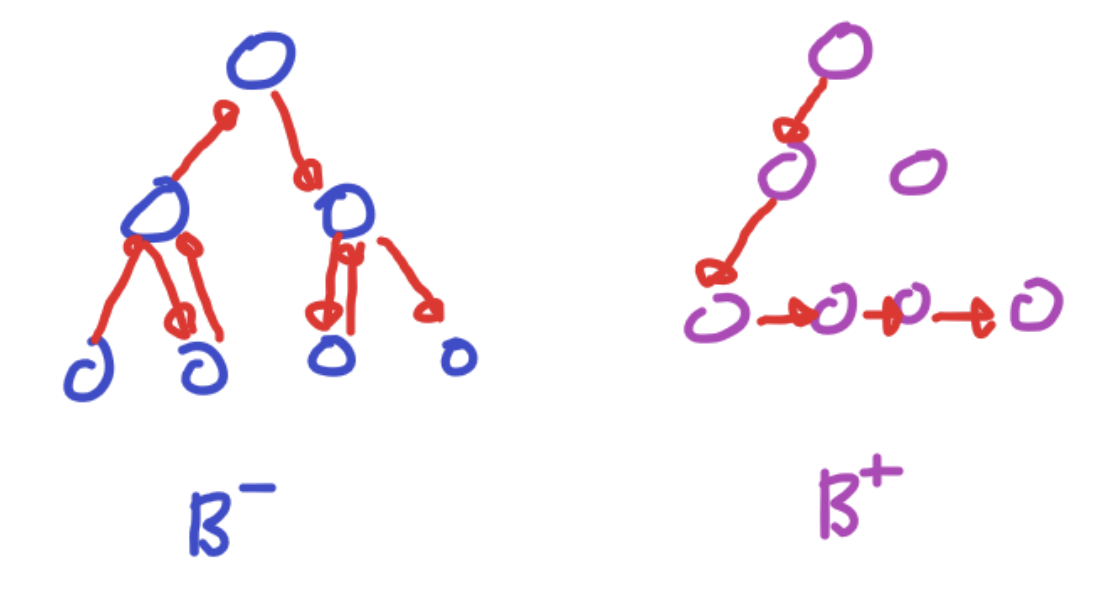
- 리프노드의 부모 key는 리프노드의 첫번째 key보다 작거나 같습니다. 그림의 B+트리는 리프노드의 key들을 트리가 가지고 있는 경우여서, data 삽입 또는 삭제가 일어날 때 트리의 key에 변경이 일어납니다. 해당 경우뿐만 아니라 data의 삽입과 삭제가 일어날 때 트리의 key에 변경이 일어나지 않게 하여 더욱 편하게 B+트리를 구현하는 방법도 존재하기 때문에 작거나 같다라는 표현을 사용하였습니다.
조건

key 삽입, 삭제
B+Tree 구현해보기
https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html
예상질문
- Trie 장점을 말해보세요
- 댕냥 프로젝트에 필요한지 여부와 사용한다면 어떻게 활용하겠습니까?
- B-Tree와 B+Tree의 차이점 한가지 이상 얘기해보세요.
- Balanced tree를 DB 인덱스로 사용하기 좋은 이유를 설명해보세요
참고
https://rebro.kr/169
https://www.youtube.com/watch?v=bqkcoSm_rCs
https://www.youtube.com/watch?v=H_u28u0usjA
