
문득 Redis의 복제 과정을 공부하던 중 "MySQL에서는 어떻게 복제를 진행할까?"라는 의문증이 생겼습니다. 그래서! MySQL에서 어떻게 복제를 진행하는지 가져왔습니다.
복제란?(Replication)
복제(replication)는 소스 서버에서 하나 이상의 레플리카(replica)서버로 데이터를 복사하는 것을 말합니다. 흔히 master-slave replication이라고 알려져 있습니다.
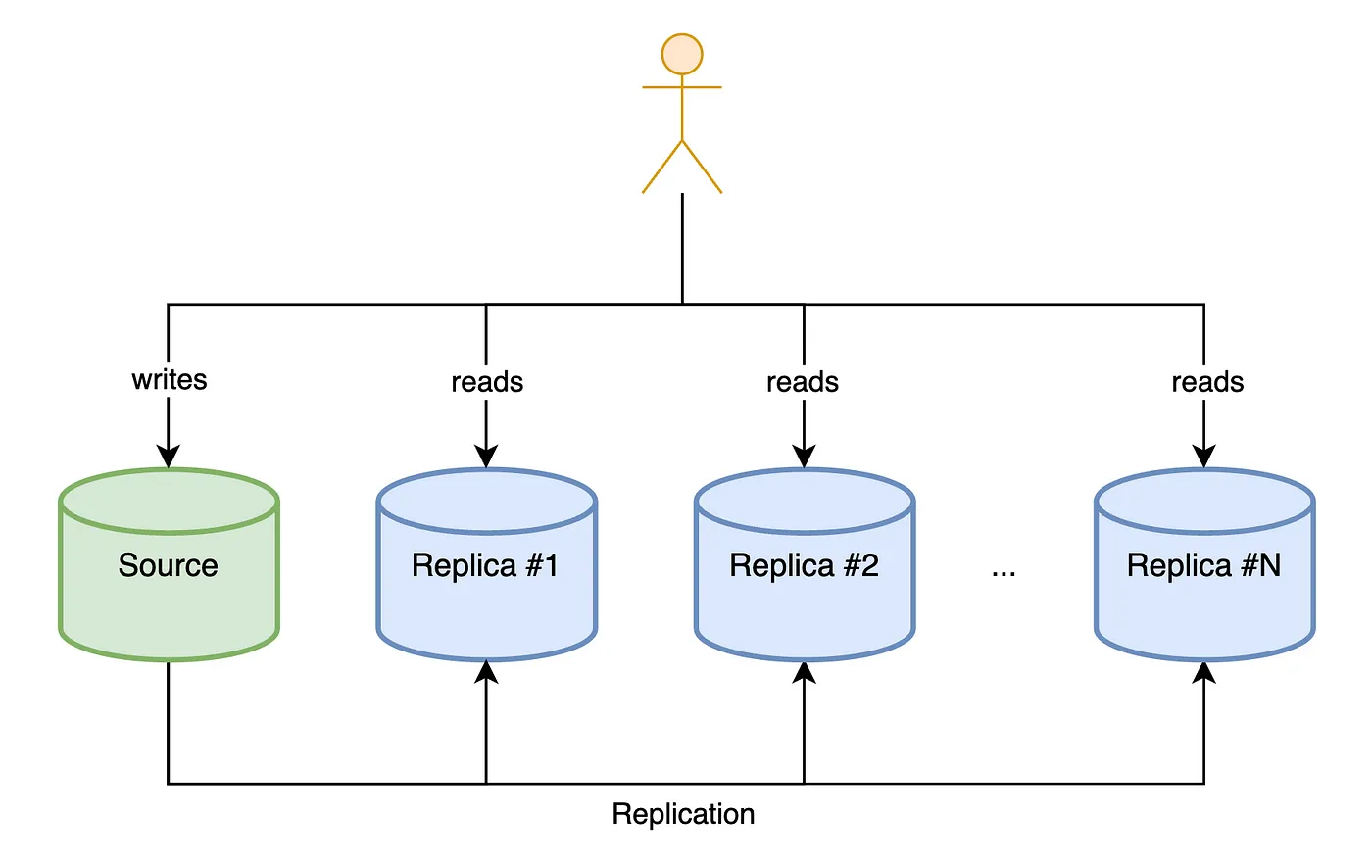
복제 환경에서 쓰기(CUD)는 소스 서버에서만 가능하고 나머지 레플리카 서버에서는 읽기 요청을 처리할 수 있습니다. 물론 소스 서버에서도 읽기 요청이 가능하지만 일반적으로 부하를 줄이기 위해 레플리카 서버로 조회 요청을 보냅니다.
그러면 레플리카 서버들은 읽기 요청을 분산 처리하기 위해서 도입하는 걸까요?
물론 그렇게도 사용할 수 있습니다. 하지만 주로 소스 서버에 장애가 발생할 경우 이를 대체하기(failover) 위해 사용합니다.
그러면 MySQL에서는 어떤 방식을 통해서 복제를 진행할까요?
바이너리 로그 방식(Binary Log)
바이너리 로그 방식 복제
혹시 MySQL에서 수정 쿼리(DDL, DML)가 요청으로 들어오면 해당 요청을 바이너리 로그에 저장한다고 들어보셨나요? MySQL 복제는 이 바이너리 로그를 통해 진행합니다.
소스 서버는 insert, update, delete와 데이터베이스 구조 수정에 대한 이력들을 바이너리 로그라는 파일에 저장해둡니다.
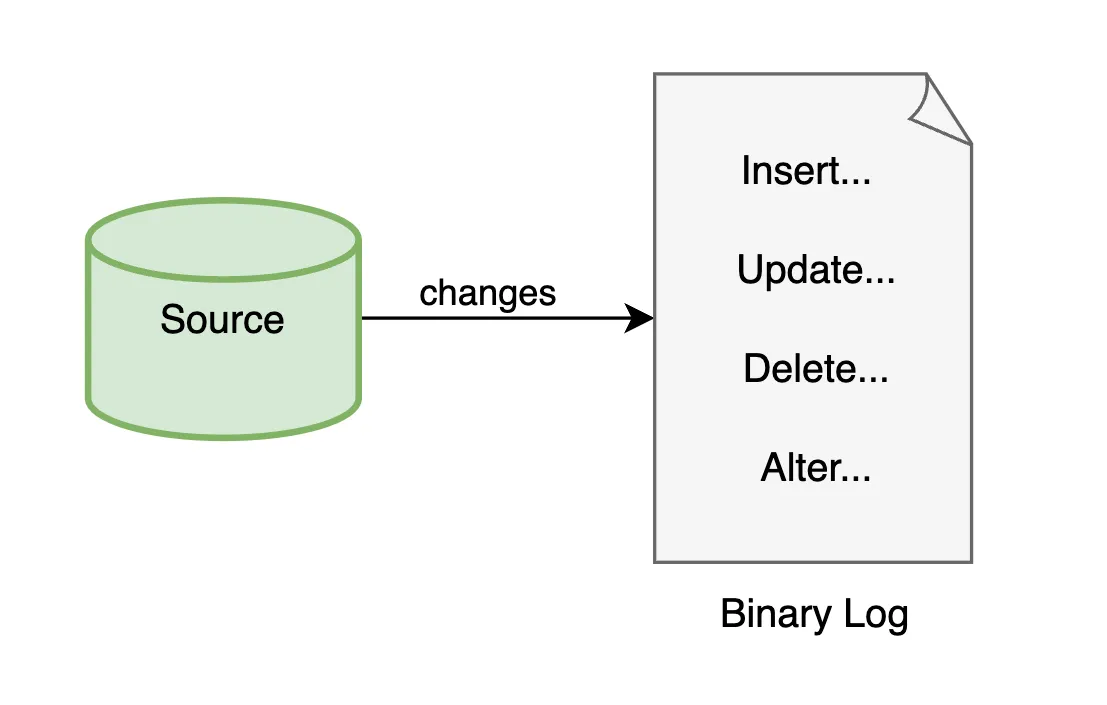
복제가 진행되면, 레플리카 서버들은 소스 서버에 특정 바이너리 로그 파일을 조회하고, 변경된 내역을 레플리카 서버에서 다시 실행하여 동기화를 진행합니다. 그렇다면 이 동기화 과정을 누가 담당할까요?
복제가 진행되면서 MySQL에서는 총 3개의 스레드가 사용됩니다. 그 중 하나는 소스 서버에서 사용되며, 나머지 2개는 레플리카 서버에서 사용됩니다.
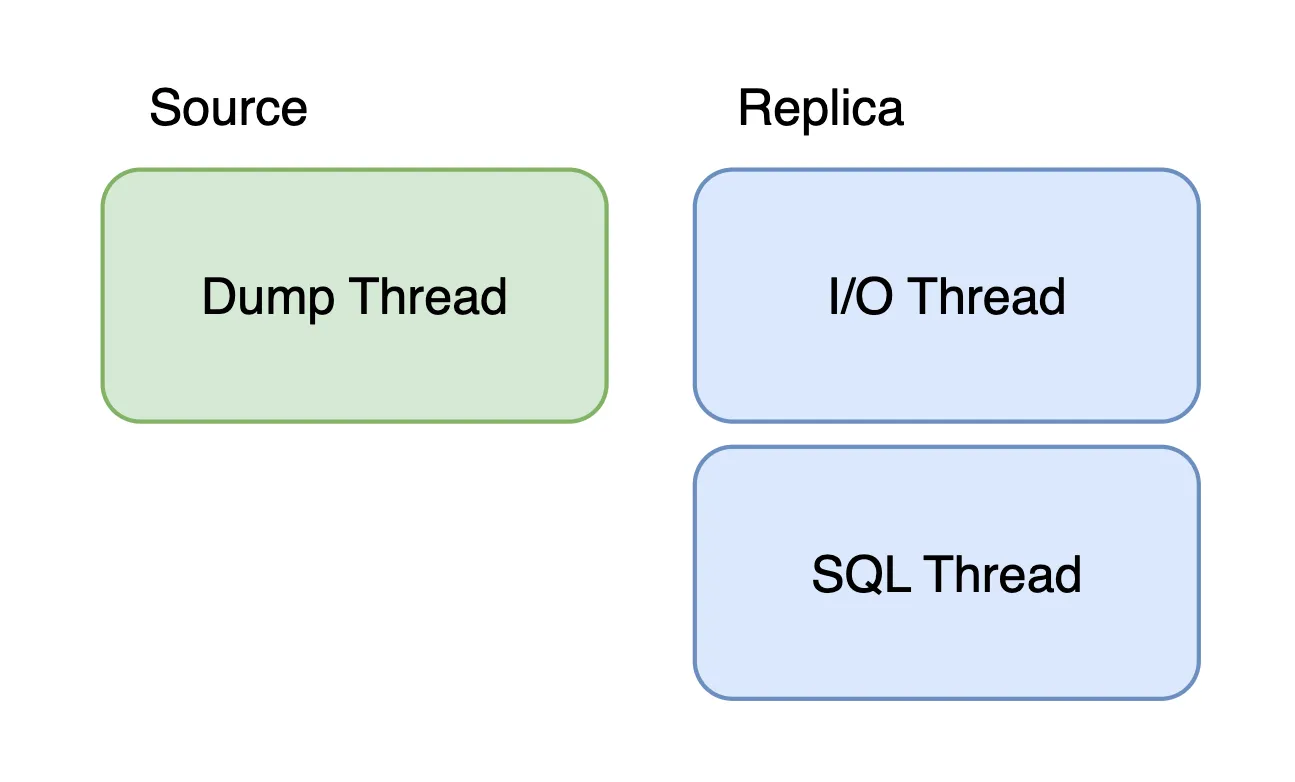
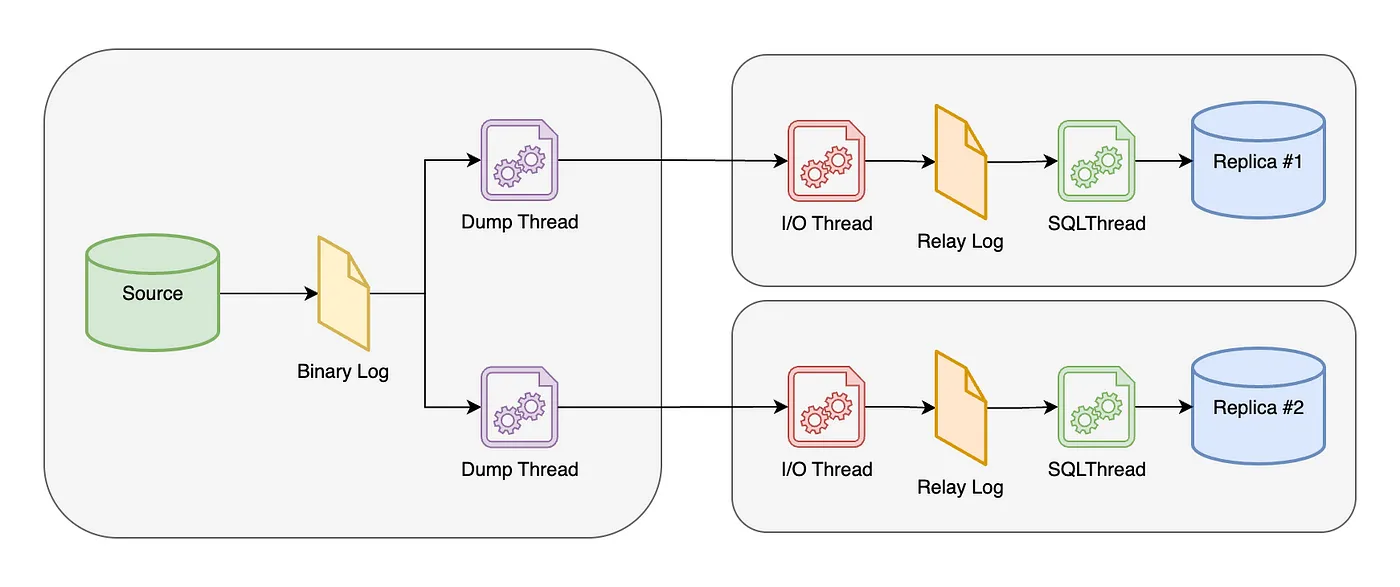
소스 서버의 경우 Dump Thread를 통해 레플리카 서버로 바이너리 로그 파일 전송합니다.
반면, 레플리카 서버는 I/O 스레드를 만들어 소스 서버로 복제 요청을 보내며, Dump Thread로부터 받은 바이너리 로그를 릴레이 로그(relay log) 파일에 기록합니다. 그러면 레플리카 서버의 SQL Thread가 릴레이 로그를 조회하고 변경된 내역을 실행합니다. 추가로, 앞선 레플리카 서버의 두 스레드(I/O Thread, SQL Thread)는 서로서로 독립적으로 동작합니다.
복제 데이터 포맷
바이너리 로그를 통해 복제하는 방법을 알아봤습니다. 그러면, 바이너리 로그에 도대체 뭐가 저장되는걸까요?
바이너리 로그는 실행된 SQL문을 기록하는 Statement 방식과 변경된 데이터 자체를 기록하는 Row 방식으로 두 종류의 포맷을 제공합니다.
Statement 방식
Statement 방식은 앞에서 말했듯이 소스 서버에서 실행된 SQL 그 자체를 저장하는 방식입니다. 이러한 방식은 바이너리 로그 파일의 용량을 효율적으로 관리할 수 있으며, 용량이 작기 때문에 복제를 빠르게 처리할 수 있습니다. 근데 왜? 용량이 작을까요?
예를 들어서 생각해봅시다. 특정 조건을 만족하는 여러 레코드들을 수정하는 쿼리가 있다고 가정해보겠습니다.
update table set b = b + 1 where b = 10;위 쿼리 결과 1만개의 레코드가 수정되었다면, 각 변경된 레코드를 바이너리 로그 파일에 저장하는 것보다 하나의 SQL문을 기록하는 것이 더 효율적입니다. 하지만 단점도 존재합니다.
첫번째로는 비확정적(Non-Deterministic)으로 처리될 수 있는 쿼리가 실행된 경우 Statement 방식에서는 복제 시 소스 서버와 레플리카 서버 간에 데이터 불일치가 발생할 수 있습니다. 다음은 비확정적 쿼리 유형의 몇 가지 예입니다.
- delete/update 쿼리에서 order by 절 없이 limit 사용
- select ... for update, select ... for share 쿼리에서 nowait이나 skip locked 옵션을 사용한 경우
- MySQL에서 제공하는
NOW(),RAND()와 같은 함수 또는 매 순간 다른 값을 반환하는 사용자 정의 함수, 스토어드 프로시저를 사용할 경우
두번째로는 Row 방식으로 복제될 때보다 데이터에 락을 더 많이, 더 오래 겁니다. 예를들면 특정 레코드 수정 요청에 대해, 이를 처리할 적절한 인덱스가 없다면 풀 테이블 스캔을 진행하며, 오랜시간동안 락을 점유할 수 있습니다. 하지만 이 단점은 쿼리 그 자체를 저장하고 실행하는 방식에서 오는 단점이라 어쩔 수 없습니다.
마지막으로, Statement 방식을 사용할 경우 트랜잭션 격리 수준을 REPEATABLE-READ 이상이어야 합니다. 그 이하의 격리 수준에서는 트랜잭션 내에서도 각 쿼리가 실행되는 시점마다 반환하는 데이터가 달라질 수 있기 때문에, 소스 서버와 레플리카 서버간 데이터 불일치가 발생할 수 있습니다.
Row 방식
Row 방식은 변경된 값 자체를 바이너리 로그에 저장하는 방식이며 MySQL 5.7.7 버전부터 바이너리 로그의 기본 포맷으로 사용됩니다. Row 방식의 값 자체를 저장하는 방식의 예를 들면 다음과 같은 방식으로 저장됩니다.
update table set b = b + 1 where id = 1;Row 방식은 변경된 데이터 그 자체를 저장하기 때문에 Statement 방식에서 발생하는 데이터 불일치는 Row 방식에서는 발생하지 않습니다. 즉, 소스 서버와 레플리카 서버간 데이터를 일관되게 하는 가장 안전한 방식입니다. 또한 Statement 방식과 달리 레코드 자체를 변경하기 때문에 락의 범위를 최소한으로 그리고 짧은 시간동안만 점유할 수 있습니다.
하지만 변경된 데이터를 저장하기 때문에 많은 데이터 변경이 발생할 경우 갑작스럽게 바이너리 로그 파일의 크기가 커질 수 있습니다.
Mixed 방식
마지막으로 Statement 방식과 Row 방식을 혼합해서 사용할 수 있습니다.
Mixed 방식은 기본적으로 Statement 방식을 사용하다가 레플리카 서버에서 쿼리가 실행될 때 안전하지 않다면 Row 방식으로 전환하여 기록합니다. 여기서 안전하지 않은 쿼리는 비확정적으로 처리될 수 있는 쿼리입니다.
데이터 일관성
레플리카 서버가 소스 서버로 복제하던 중 장애가 발생하여 다시 시작될 때, 레플리카 서버는 소스 서버의 어느 바이너리 로그 파일의 어느 위치에서 시작해야할지 어떻게 알 수 있을까요?
MySQL은 복제를 할 때 소스 서버의 특정 바이너리 로그 파일 이름과 위치를 저장해 둡니다.
+------------------+----------+
| File | Position |
+------------------+----------+
| mysql-bin.000003 | 73 |
+------------------+----------+그래서 레플리카 서버가 다시 시작될 때 서버에 저장된 복제 대상 바이너리 로그 파일 이름과 위치를 기반으로 복제를 다시 시작합니다. 그러면 소스 서버에 장애가 발생해서 종료되면 어떻게 될까요? 레플리카 서버 중 하나가 소스 서버가 되서 나머지 레플리카 서버가 새 소스 서버로부터 데이터를 받아오면 될까요?
가능할수도 불가능할수도 있습니다.
바이너리 로그는 저장될 때 모든 서버가 동일한 이름에 동일한 위치에 저장되는것을 보장하지 않습니다. 그래서 새 소스 서버와 이전 소스 서버의 바이너리 로그 파일이 달라 나머지 레플리카 서버들이 복제에 실패할 수 있습니다. 물론 새 소스 서버에 릴레이 로그가 삭제되지 않고 남아있다면 해당 정보를 통해 필요한 부분만 실행하면 복구할 수 있습니다. 하지만 릴레이 로그는 주기적으로 제거되기 때문에 이 방법은 상당히 제한적인 방법입니다. 그러면 어떻게하면 데이터 일관성을 보장할 수 있을까요?
글로벌 트랜잭션 아이디(GTID)
글로벌 트랜잭션 아이디(GTID)는 물리적인 파일 위치에 기반하지 않고 논리적으로 위치를 기록합니다.
MySQL의 GTID는 서버에서 커밋된 각 트랜잭션과 각 서버가 가지는 고유 식별자(UUID)로 구성됩니 다. 트랜잭션 아이디는 서버에서 커밋된 트랜잭션 순서대로 부여되는 값입니다.
GTID = {source_id}:{transation_id}그러면 GTID는 어디에 저장될까요? GTID는 바이너리 로그에서 SQL문이 저장되기 전에 저장됩니다. 예를들어 간단하게 데이터베이스를 생성하고 user 테이블을 생성해보겠습니다.
mysql> create database test;
mysql> create table user( id varchar(255) not null primary key, name varchar(50) );쿼리 실행 후 바이너리 로그 파일을 조회해보면 각 트랜잭션 시작 전 GTID를 기록하는 것을 확인할 수 있습니다.
mysql> show binlog events in 'binlog.000002';
+---------------+-----+----------------+-----------+-------------+------------------------------------------------------------------------------------------------------+
| Log_name | Pos | Event_type | Server_id | End_log_pos | Info |
+---------------+-----+----------------+-----------+-------------+------------------------------------------------------------------------------------------------------+
| binlog.000002 | 127 | Previous_gtids | 1111 | 198 | db6bf043-4e37-11ef-abf1-0242ac150003:1-5 |
| binlog.000002 | 198 | Gtid | 1111 | 275 | SET @@SESSION.GTID_NEXT= 'db6bf043-4e37-11ef-abf1-0242ac150003:6' |
| binlog.000002 | 275 | Query | 1111 | 383 | create database test /* xid=4 */ |
| binlog.000002 | 383 | Gtid | 1111 | 460 | SET @@SESSION.GTID_NEXT= 'db6bf043-4e37-11ef-abf1-0242ac150003:7' |
| binlog.000002 | 460 | Query | 1111 | 623 | use `test`; create table user(id varchar(255) not null primary key,name varchar(50)) /* xid=11 */ |이렇듯 바이너리 로그에 GTID를 기록하기 때문에 소스 서버가 교채되더라도 레플리카 서버들은 자신이 마지막으로 조회한 GTID를 기준으로 복제를 시작하면 되기 때문에 문제 없이 데이터 일관성을 달성할 수 있게 됩니다.
요약
- 복제는 바이너리 로그를 소스 서버와 레플리카 서버간 교환을 통해 이뤄진다.
- 복제 방법으로는 GTID를 사용하는 방법과 사용하지 않는 방법이 존재한다.
- GTID를 사용하면 failover 시 문제 없이 동기화를 다시 진행할 수 있다.
- GTID를 사용하지 않으면 물리적으로 바이너리 로그 파일을 식별하기 때문에 동기화시 문제가 발생할 수 있다.
- 바이너리 로그 파일의 저장방식은 SQL문 자체를 저장하는 Statement 방식과 변경된 레코드를 저장하는 Row 방식이 존재한다.

그냥 ctrl c ctrl v 하면 안되는건가요?