
자료구조(1)
자료구조란 ?
데이터에 편리하게 접근하고 변경하기 위해서 데이터를 저장하거나 조직하는 방법. 문제 해결을 위해 여러가지 형태의 자료구조가 활용됨.
자료구조의 분류
대표적으로 선형구조와 비선형구조로 나누어진다.
- 선형 구조
- 배열
- 연결 리스트
- 스택
- 큐
- 비선형 구조
- 트리
- 그래프
1. 배열(Array)
가장 기본적인 순차적인 자료구조. 번호(인덱스)와 그 번호에 대응하는 데이터들로 이루어져 있다. 기본적으로 배열의 크기는 고정이며, 선언할 때에 배열의 크기를 지정한다.
배열은 연속된 메모리 주소를 할당받아서 데이터가 순차적으로 저장되기 때문에 데이터가 인덱스를 가지게 되면서 임의 접근(random access) 이 가능해진다
배열 내에서 이루어지는 연산은 접근, 검색, 추가, 제거 등이 있다.

접근
배열 내에서 i번째의 인덱스에 해당하는 값을 찾아내는 연산
배열의 접근은 O(1) 의 시간복잡도를 갖는다.
배열의 첫번째 주소에는 시작 주소값이 저장되고, A[i] 의 값을 찾기 위해서는 시작 주소 + (i * 값 하나의 메모리 크기) 를 하면 원하는 값에 접근할 수 있다.
예를 들어 A[0] 의 시작 주소를 1000 이라고 한다면 A[1] 의 주소는 1004, A[2] 의 주소는 1008 ... 으로 표현할 수 있다. 즉 A[2] 의 주소는 A[0] 의 주소 + (2 * 4byte(정수)) 로 구할 수 있다. 따라서 단순히 사칙연산만이 수행되기 때문에 배열의 접근은 O(1) 의 시간복잡도를 가진다.
추가
배열에 새로운 변수를 추가하기 위한 전제 조건은 배열에 빈 칸이 있다는 것이다.
동적 배열은 예외.
빈 칸이 존재한다면 가장 마지막 값 다음 칸에 값을 삽입하기만 하면 되므로 기본적으로 O(1) 의 시간복잡도를 가진다.

단순하게 A[5] 다음인 A[6]에 삽입하기만 하면 된다.
하지만 제일 앞에 삽입을 하기 위해서는 A[0] ~ A[5] 의 데이터를 한 칸씩 뒤로 밀고 삽입을 해야하기 때문에 O(n) 의 시간복잡도를 가진다.
삭제
추가와 동일
검색
배열에서의 검색은 기본적으로는 순차 검색이다.

A[3]의 값을 찾기 위해서는 A[0], A[1], ... 순서로 검색을 한다. 따라서 최대 O(n) 의 시간복잡도를 가진다.
이진 탐색
2. 연결 리스트(Linked List)

연결 리스트는 크기를 미리 정할 필요가 없는 동적인 자료구조이다. 배열처럼 연속된 메모리 주소를 할당받지 않기 때문에 임의 접근은 불가능하고 순차 접근(sequential access) 방식을 사용한다.
연결 리스트는 노드로 이루어져 있고 각 노드는 데이터와 다른 노드를 가리키는 포인터로 구성되어 있다. 연결 리스트의 첫 노드를 Head 마지막 노드를 Tail 이라고 하는데 Tail 의 포인터는 null 을 가르킨다. 이처럼 연결 리스트는 노드의 포인터 덕분에 메모리에 불연속적으로 저장이 되어 있어도 선형구조로 데이터를 저장할 수 있다.
접근
순차 접근을 사용하기 때문에 항상 처음부터 탐색하기 때문에 최악의 경우 O(n) 의 시간복잡도를 가진다.
추가
각각의 원소들은 다음에 어떤 원소인지를 기억하고 있는데 이 부분을 바꿔주기만 하면 쉽게 O(1) 의 시간복잡도로 추가가 가능하다. (이전 노드의 포인터를 새로운 노드로, 새로운 노드의 포인터를 다음 노드의 포인터로). 하지만 원하는 위치에 추가를 하기 위해서는 이전 노드의 위치를 알아야하는데 순차 접근을 사용하기 때문에 O(n) 의 시간복잡도를 가진다.

삭제
추가와 동일
해당하는 원소를 찾기 위해서 추가로 O(n) 의 시간이 걸린다.

검색
순차 접근이므로 O(n) 의 시간복잡도를 가진다.
3. 스택(Stack)
Stack 은 사전적 정의로는 쌓다 라는 뜻이 있다.
스택은 한 쪽 끝에서만 자료를 넣거나 뺄 수 있는(LIFO - Last In First Out) 선형 구조로 되어 있다.
가장 먼저 들어간 데이터가 가장 나중에 나온다.

삽입(push)
스택의 맨 위에 데이터를 추가하는 것이다.
무조건 맨 위에 데이터를 추가하기 때문에 O(1) 의 시간복잡도를 가진다.
삭제(pop)
마지막으로 스택에 삽입된 데이터를 제거한다.
O(1) 의 시간복잡도를 가진다.
검색(search)
스택은 한 쪽에서만 연산이 일어나기 때문에 스택의 중간에는 접근을 할 수 없다.
즉, 데이터를 다 제거했다가 다시 복구하는 방법으로 검색을 하기 때문에 제거할 때 O(n), 복구할 때 O(n) 으로 O(2n) 이지만 편하게 O(n) 이라고 표시한다.
4. 큐(Queue)
큐는 한쪽에서는 삽입, 다른 한쪽에서는 삭제가 일어나는 FIFO(First In First Out) 구조로 저장하는 형식이다.
가장 먼저 들어온 데이터 먼저 나온다.

큐에는 Front 와 Back(Rear) 부분이 있는데 Front 에서는 Dequeue(삭제) 연산만 가능하고 Back 에서는 Enqueue(삽입) 연산만 가능하다.
삽입
언제나 Back 에서만 삽입할 수 있으므로 O(1) 의 시간복잡도를 가진다.
삭제
삽입과 동일.
O(1)
검색
스택과 동일하게 데이터들을 제거했다가 다시 복구하는 방법으로 검색을 하기 때문에 O(n) 의 시간복잡도를 가진다.
4-1. 우선순위 큐(Priority Queue)
우선순위 큐에서 각 원소는 우선순위를 가지고 있어서 들어간 순서에 상관없이 우선순위가 높은 데이터가 먼저 나온다.
우선순위 큐 = 힙 이라는 말들이 있는데 잘못된 말이다. 우선순위 큐를 구현하는 방법 중에 하나가 힙일 뿐이다.
우선순위 큐를 구현하는 방법은 3가지가 존재한다.
배열
1.정렬되지 않은 배열
삽입
기존의 요소들을 배열의 맨 끝에 추가하면 되기 때문에 O(1) 의 시간복잡도를 가진다.
삭제
가장 우선순위가 높은 데이터를 찾아야 하는데
배열에서는 기본적으로 순차 검색이므로 O(n) 의 시간복잡도를 가진다. 해당하는 데이터를 삭제하고 뒤에 있는 데이터들을 앞으로 이동까지 시켜야한다.
2.정렬된 배열
삽입
정렬된 배열일 경우에 배열 안의 데이터들과 우선순위를 비교해서 삽입 위치를 찾아야 한다. 삽입 위치 다음에 있는 데이터들을 한 칸씩 뒤로 이동 시키고 삽입을 해야한다.
O(n) 의 시간복잡도를 가진다.
삭제
배열이 정렬되어 있으므로 배열의 맨 끝에 위치한 데이터를 삭제하면 된다. O(1) 의 시간복잡도를 가진다.
연결 리스트
1.정렬되지 않은 연결리스트
삽입
삽입은 정렬되지 않은 상태에서는 어느 위치도 상관이 없기 때문에 O(1) 의 시간복잡도를 가진다.
삭제
포인터를 따라서 모든 노드들을 탐색해서 가장 우선순위가 높은 노드를 찾아야 하기 때문에 O(n) 의 시간복잡도를 가진다.
2.정렬된 연결리스트
삽입
우선순위를 비교해서 삽입 위치를 찾아야 하므로 O(n) 의 시간복잡도를 가진다.
삭제
우선순위가 가장 높은 데이터가 첫 번째 노드로 정렬을 했다면 첫 번째 노드를 삭제하면 되므로 O(1) 의 시간복잡도를 가진다.
힙
삽입
삭제
둘 다 O(logn) 의 시간복잡도를 가진다.
아래 참고
5. 힙(Heap)
힙은 최댓값 및 최솟값을 찾아내는 연산을 빠르게 하기 위해 고안된 완전이진트리를 기본으로 한 자료구조이다.
힙은 최댓값, 최솟값을 알아내는 용도이기 때문에 느슨한 정렬 상태 를 유지한다. 즉 큰 값이 상위 레벨이고 작은 값이 하위 레벨에 있다는 정도의 정렬 상태이다.
힙에는 부모 노드의 키 값이 자식 노드보다 항상 큰 최대 힙 과 부모 노드의 키 값이 자식 노드보다 항상 작은 최소 힙 이 있다.
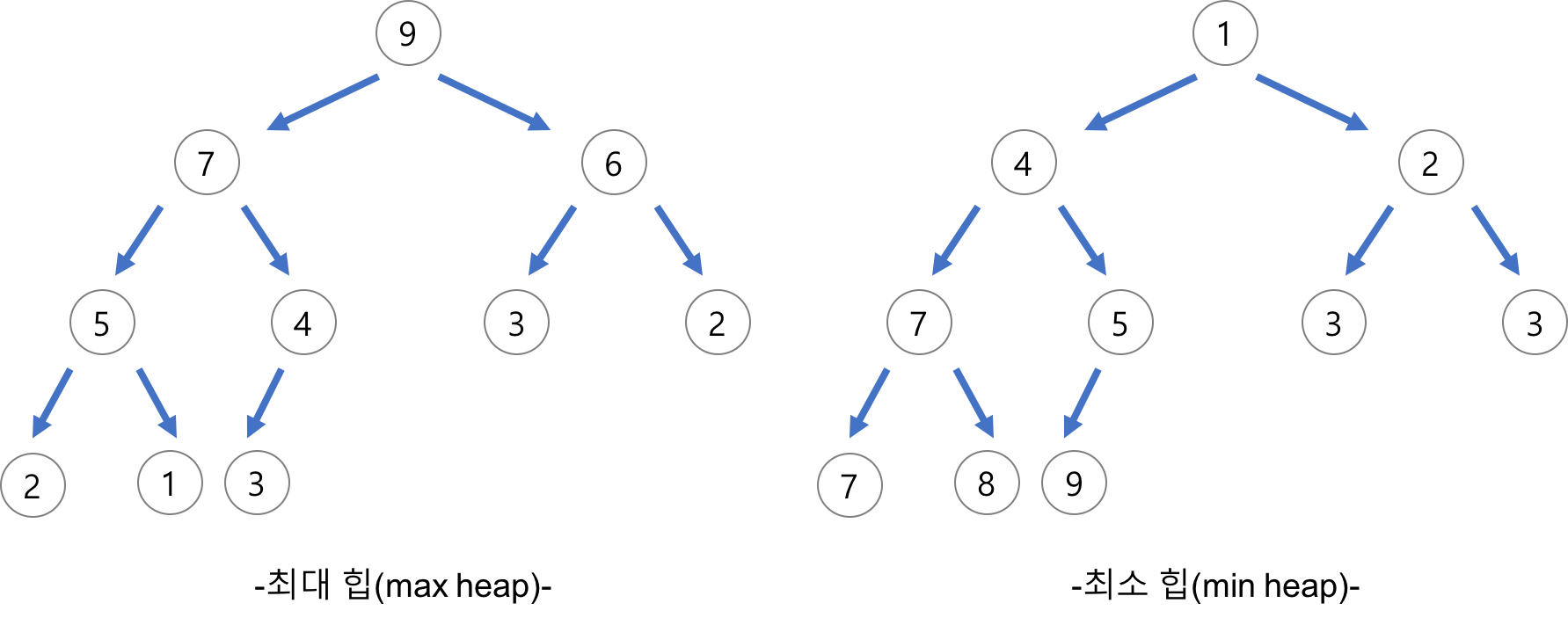
힙은 완전 이진 트리이기 때문에 각각의 노드에 번호를 붙여서 배열처럼 생각할 수 있다.
그림을 보면 루트 노드가 1번이면 왼쪽 자식 노드는 항상 2번이고 오른쪽 자식 노드는 항상 3번이 된다.
즉,
왼쪽 자식 노드 인덱스 = 부모 노드 인덱스 * 2
오른쪽 자식 노드 인덱스 = 부모 노드 인덱스 * 2 + 1
부모 노드 인덱스 = 자식 노드 인덱스 / 2
임을 알 수 있다.

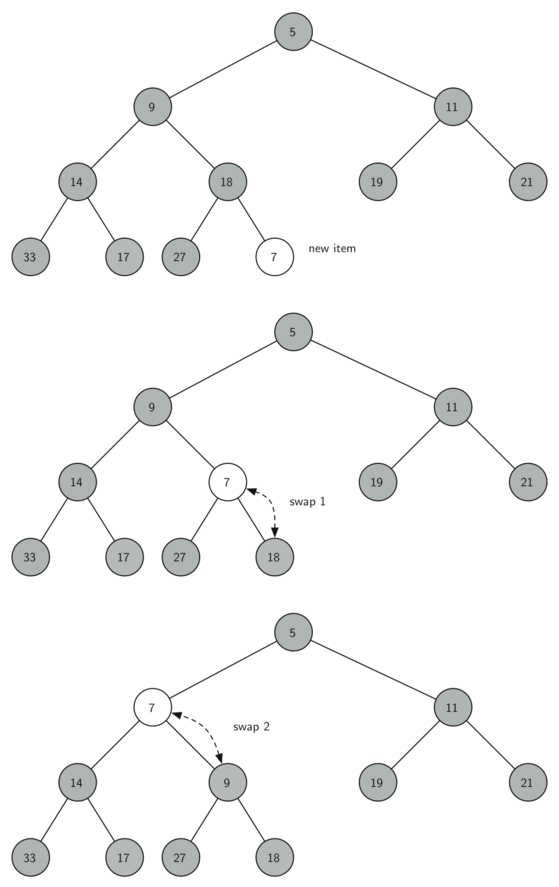
삽입
새로운 데이터를 삽입하면 힙의 마지막 노드에 삽입한다. 삽입 후 새로운 노드를 부모 노드들과 비교한 후 자리를 교환하며 적절한 위치를 찾아간다.
7, 18 비교, 교환, 7, 9 비교, 교환, 7, 5 비교 ... 끝
교환 할 때마다 인덱스는 1/2 씩 줄어들기 때문에 O(logN) 의 시간복잡도를 가진다.
(부모 노드 인덱스 = 자식 노드 인덱스 / 2)
(증명)
주어진 데이터가 개일 때 1/2 씩 줄어들고 최악의 경우 1개가 남을 때까지 이 작업을 반복한다면 아래와 같은 수열을 만들 수 있다.
여기서 연산의 횟수를 라고 하면, 이 1일 경우 의 값은 어떻게 될까.
을 번 2로 나누면 1이 된다. 를 식으로 나타내면
이 나오고,
이 수식 양 변에 를 취해주면
우리가 원하는 이 나온다.
삭제
삭제는 최대 힙에서는 최댓값 최소 힙에서는 최솟값을 삭제하는 작업이다.
먼저 root 의 값을 제거하고 가장 마지막 노드(그림에서는 27)를 root 노드로 위치시킨다. 그 다음 삽입과 마찬가지로 최대 힙, 최소 힙에 맞게 정렬을 수행한다.
O(logn) 의 시간복잡도를 가진다.
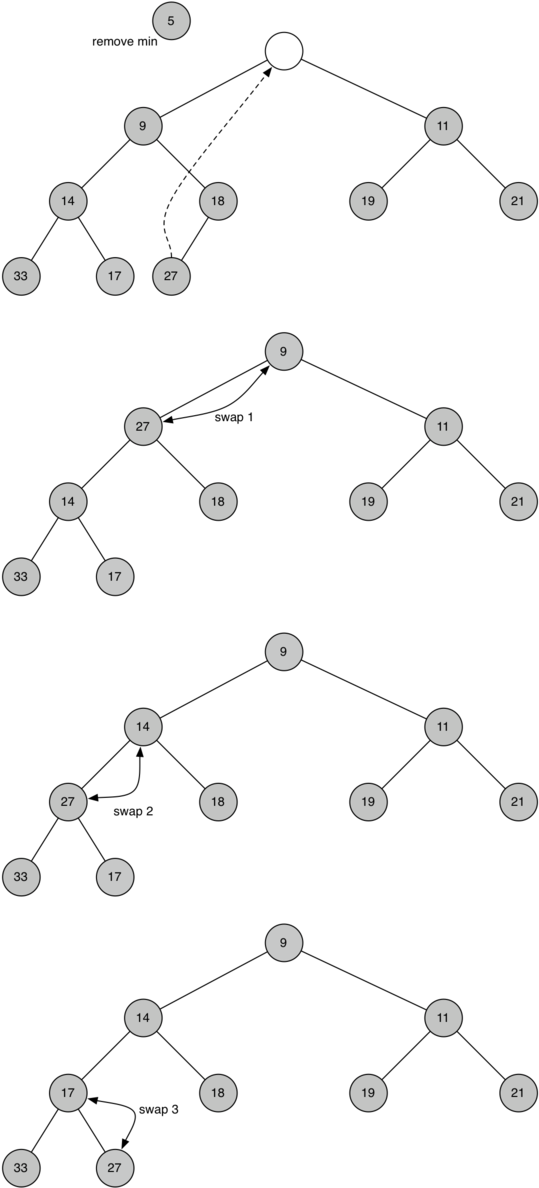
삽입과 삭제 연산 그 자체만으로는 O(1) 의 시간복잡도를 가지지만 그 후 정렬을 하기 때문에 둘 다 O(logn) 의 시간복잡도를 가지게 된다.
