SQL 문법
[ workbench 활용 ]
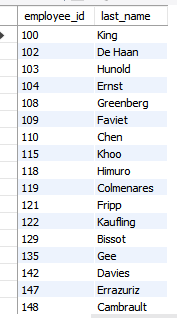
1. select 구문을 사용한 데이터 검색
-- DB 선택
use hr;
-- DB 내 테이블 목록 확인
show tables;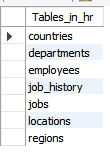
-- 테이블 구조 확인
describe employees;
= desc employees;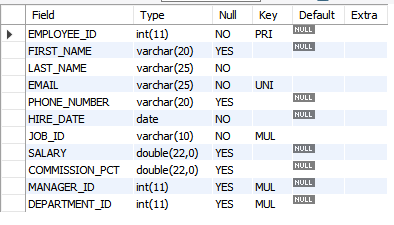
desc departments;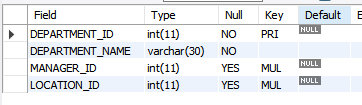
[문법] select * | 컬럼명 from 테이블명
-- 모든 컬럼 출력
select *
from departments;
-- 특정 컬럼 출력
select department_id, location_id
from departments;
-- 컬럼 순서 변경 가능
select department_name, department_id, location_id
from departments;select 구문에 산술식 포함하기
- 산술연산자 : +, -, *, /
- 산술연산자 우선순위 규칙 : *, / >> +, -
- 우선순위 지정 시 괄호 사용하면 됨
- 산술식(계산식, 표현식) : 산술 연산자를 활용한 계산식
select last_name, salary, 12*salary+100
from employees;
select last_name, salary, 12*(salary+100)
from employees;
null값
- 모르는 값, 알 수 없는 값, 정의되지 않은 값, 알려지지 않은 값
- 0(숫자) 또는 공백(문자)이 아닌 하나의 특수한 값
int(22) = double(22,0)
int(전체 자리수)
double(전체 자리수, 소수점 이하 자리수)- [데이터 수정] employees 테이블의 commission_pct 컬럼 : 데이터타입 및 데이터 변경
commission_pct의 데이터타입이 double(22,0) 되어 있음.
[왼쪽] 수정 메뉴 활용 : double(22,2) 수정함.
-- commission_pct가 0인 직원들을 0.1로 데이터 변경함.
update employees
set commission_pct = 0.1
where commission_pct = 0;-
null값이 산술식이 포함된 경우 결과는 무조건 null이다!!
- 100 + null = null
- 100 - null = null
- 100 * null = null
- 100 / null = null
- 12 * 24000 + null / 7 + 500 = null -
employees 테이블에서 사원들의 employee_id, last_name, salary, commission_pct, 1년동안의 커미션값을 출력하시오.
select employee_id, last_name, salary, commission_pct,
12*salary*commission_pct
from employees;
commission_pct가 null값이면 12*salary*commission_pct 값도 null이다.
** 결과 : 커미션을 받는 사원들은 정상 결과가 나오나, 커미션을 받지 않는(null) 사원들은은 0이 아닌 null 값이 출력.(0으로 출력을 원한다면 특정 함수 사용해야 함)
colum alias
컬럼명이나 표현식으로 작성된 컬럼을 재명명할때 사용됨
[문법]
- 컬럼명 as alias
- 컬럼명 alias
- 컬럼명 [as] "Alias name" => 대소문자, 공백, 특수문자(한글) 포함 가능함.
select last_name as name, commission_pct comm
from employees;
select last_name "Name", salary*12 "Annual Salary"
from employees;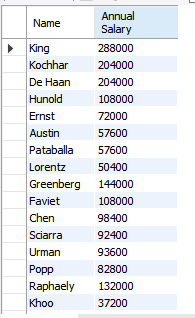
select employee_id as "사번", last_name as "이름", salary as "급여",
commission_pct "수당비율", 12*salary "연간급여"
from employees;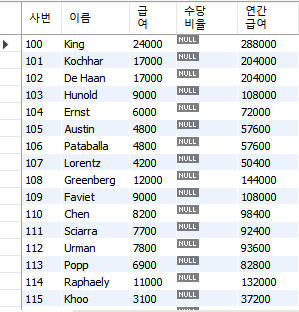
distinct 키워드
중복값을 제거하고 한번만 출력해주는 구문
- employees 테이블에서 사원들이 소속된 부서 종류(리스트)를 출력하시오.
select department_id
from employees;
중복값 多
select distinct department_id
from employees;
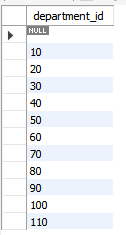
-- 여러 컬럼 기준 중복값 제거할 때
select distinct department_id, job_id
from employees; 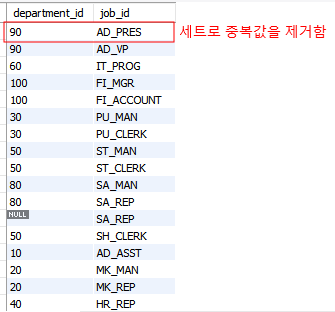
연습문제 1)employees 테이블로부터 employee_id, last_name, job_id, hire_date를 출력하되 컬럼 제목을 각각
Emp #, Employee, Job, Hire Date로 지정하여 출력하시오.
select employee_id "Emp #", last_name "Employees", job_id "Job", hire_date "Hire Date"
from employees;연습문제 2) employees 테이블로부터 사원들이 담당하고 있는 업무 리스트를 출력하시오.
select distinct job_id
from employees;where 조건문
-- DB 선택
use hr;
select *
from employees; -- 모든 컬럼 + 모든 행 출력됨
select employee_id, last_name, salary, department_id
from employees; -- 특정 컬럼 + 모든 행 출력됨WHERE절(조건절)
-
테이블의 특정 행을 출력할 때 사용함.
[문법] select * | 컬럼명 from 테이블명 [where 좌변(컬럼명) =(비교연산자) 우변(값] ;
값 -> 숫자 '문자', '날짜(YYYY-MM-DD)' -
employees테이블에서 employees_id, last_name, job_id, department_id를 출력하되 90번 부서에 소속된 직원만 출력하시오.
select employee_id, last_name, job_id, department_id
from employees
where department_id = 90;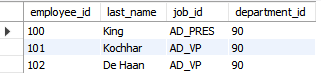
- employees 테이블에서 employee_id, last_name, job_id, salary 출력하되 last_name이 whalen인 사원만 출력하시오.
select employee_id, last_name, job_id, salary
from employees
where last_name = 'whalen';
- employees 테이블에서 employee_id, last_name, hire_date, department_id를 출력하되 입사일이 1996년 2월 17일인 사원만 출력하시오.
select employee_id, last_name, hire_date, department_id
from employees
where hire_date = '1996-2-17';
비교연산자
비교연산자1 =, >, >=, <, <=, <>, !=
단일행비교연산자
select last_name, salary
from employees
where salary <= 3000;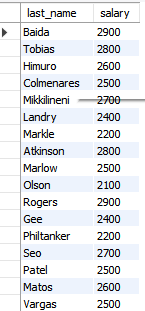
비교연산자2 between A and B
A이상 B이하의 값을 비교하는 연산자, 범위검색을 할 때 사용함.
숫자, 문자, 날짜 다 사용됨
select employee_id, last_name, salary, department_id
from employees
where salary between 2500 and 3500;
-- (==)
select employee_id, last_name, salary, department_id
from employees
where salary >= 2500 and salary <= 3500;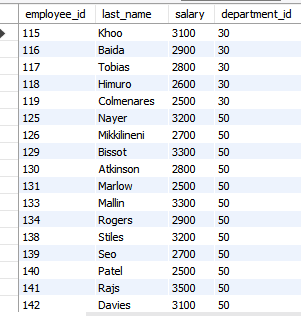
select employee_id, last_name, hire_date, department_id
from employees
where hire_date between '1996-01-01' and '1997-12-31';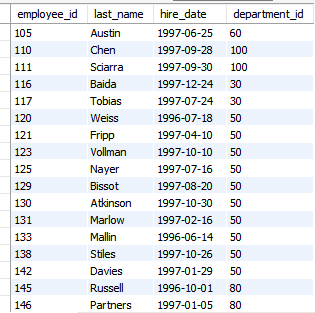
select employee_id, last_name
from employees
where last_name between 'Bell' and 'King';