- any 예제
select employee_id, last_name, job_id, salary
from employees
where salary < all
(select salary from employees
where job_id = 'it_prog')
and job_id <> 'it-prog';job_id가 it_prog인 사람의 급여의 최소값보다 작은 사람들

다중컬럼 서브쿼리
- 서브쿼리로부터 메인쿼리로 여러 컬럼을 기준으로 값이 반환되는 경우
- 메인쿼리의 좌변에서 다중 컬럼을 작성해야함 (좌변과 우변이 짝이 맞아야함!)
select employee_id, first_name, department_id, salary
from employees
where (department_id, salary) in
(select department_id, min(salary)
from employees
group by department_id)
order by department_id;다중컬럼서브쿼리 + 다중행서브쿼리
- 결과가 안나오는 이유?
자기 자신이 매니저가 아닌 직원(말단 직원)
select last_name
from employees
where employee_id not in
(select manager_id
from employees);결과값이 없음
-- 서브쿼리 출력해보기
select manager_id
from employees;
null 값이 있음
not in = <>, and 의미.
서브쿼리로부터 반환되는 값리스트에 null값이 포함되어 있는 경우, 메인쿼리에 and 성격을 가지는 비교연산자 사용 시 메인 쿼리 결과도 null임.
-- [수정]
select last_name
from employees
where employee_id not in
(select manager_id
from employees
where manager_id is not null);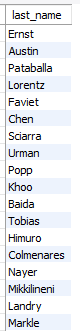
연습문제
- employees 테이블에서 Abel과 동일한 부서에 소속된 사원들의 last_name과 hire_date를 출력하되 비교의 대상인 Abel은 제외하시오.
select last_name, hire_date
from employees
where job_id =
(select job_id
from employees
where last_name = 'abel')
and last_name <> 'abel';
- employees 테이블에서 평균 이상의 급여를 받는 사원들의 employee_id, last_name, salary를 출력하되 급여를 기준으로 오름차순 하시오.
select employee_id, last_name, salary
from employees
where salary >=
(select avg(salary)
from employees)
order by salary;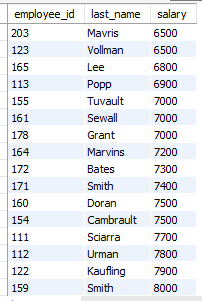
- employees 테이블에서 last_name에 ‘u’가 포함된 사원과 같은 부서에 근무하는 모든 사원의 employee_id, last_name을 출력하시오.
select employee_id, last_name
from employees
where job_id = any
(select job_id
from employees
where last_name like '%u%');
- employees 테이블과 departments 테이블을 사용하여 구문을 작성하시오. location_id가 1700인 부서에 소속된 사원들의 employee_id, last_name, department_id, job_id를 출력하시오.
select employee_id, last_name, department_id, job_id
from employees
where department_id = any
(select department_id
from departments
where location_id = 1700);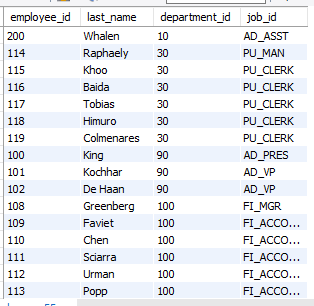
- employees 테이블에서 평균 이상의 급여를 받으면서 last_name에 ‘u’가 포함된 사원과 동일한 부서에 소속된 사원들의 employee_id, last_name, salary를 출력하시오.
select employee_id, last_name, salary
from employees
where department_id in
(select department_id
from employees
where last_name like '%u%')
and salary >=(select avg(salary) from employees);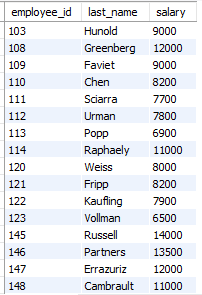
- employees 테이블에서 본인이 매니저의 역할을 하는 사원들의 employee_id, last_name을 출력하시오.
select employee_id, last_name
from employees
where employee_id =any
(select manager_id
from employees);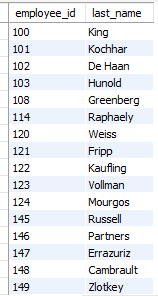
- employees 테이블과 departments 테이블을 사용하여 구문을 작성하시오. 직원이 소속되어 있지 않은 빈 부서의 department_id, department_name을 출력하시오.
select department_id, department_name
from departments
where department_id not in
(select department_id
from employees
where department_id is not null);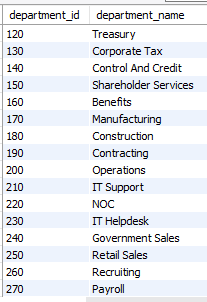
데이터조작어(DML)
use hr;
데이터삽입 : insert
테이블에 새로운 행을 추가하는 명령어
[문법] insert into 테이블명[(컬럼명1, 컬럼명2, 컬럼명3, ...)]
values (값1, 값2, 값3, ...);
- departments 테이블에 삽입
desc departments;
select *
from departments;
insert into departments
values (280, 'Java', 108, 1700);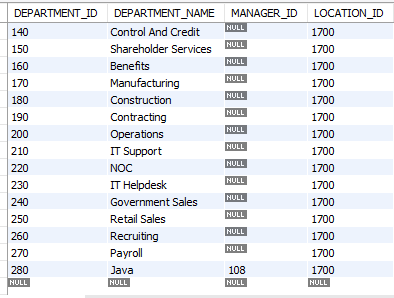
** 테이블명 뒤에 컬럼리스트 생략 시에는 values절에 테이블 기본 컬럼 순서대로 모든 값 나열해야함.
insert into departments(department_name, location_id, manager_id, department_id)
values('Jsp', 1700, 201, 290);
** insert 작업 시 테이블명 뒤에 컬럼리스트를 작성한 경우에는 values절에 컬럼 순서, 컬럼 개수를 맞춰서 값 나열해야함.
insert into departments(department_id, department_name)
values (300, 'Mysql');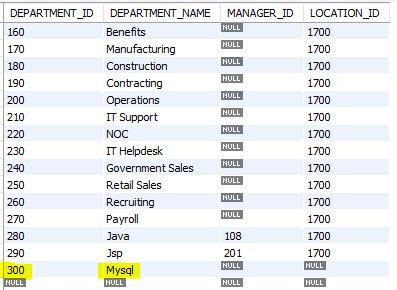
** null값을 암시적(자동)으로 삽입하는 방법
insert into departments
values (310, 'Oracle', null, null);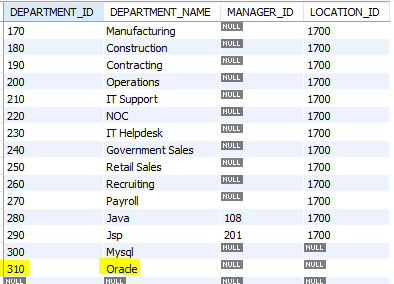
** null값을 명시적(수동)으로 삽입하는 방법
- insert + 서브쿼리(subquery)
다른 테이블로부터 데이터를 복사하는 작업이므로 한번에 여러행을 삽입할 수 있음.
sale_reps 예제 테이블 생성하기
create table sales_reps
(id int,
name varchar(20),
salary int,
commission_pct double(20,2));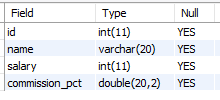
insert into sales_reps(id, name, salary, commission_pct)
select employee_id, last_name, salary, commission_pct
from employees
where job_id like '%rep%';select *
from sales_reps;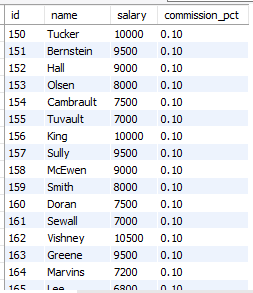
예제) employees 테이블과 구조가 동일한 copy_emp 테이블 생성 후 employees 테이블의 107명의 사원 정보를 copy_emp 테이블에 복사할 예정
- copy_emp 테이블 생성
create table copy_emp
as select *
from employees
where 1=2; -- 조건 무조건 false
-- 구조만 넘어감- copy_emp 테이블에 데이터 복사하기
insert into copy_emp
select *
from employees;- 다중행 insert
insert into departments
values (320, 'HTML', 126, 1700),
(3320, 'CSS', 127, null);데이터 수정 : update
테이블의 특정 행을 수정하는 명령어
[문법] update 테이블명
set 컬럼명 1= 값1[, 컬럼명2 = 값2,...]
where 조건문
예제1)
select employee_id, last_name, department_id
from employees
where employee_id = 113;
update employees
set department_id = 50
where employee_id = 113;
select employee_id, last_name, departement_id
from employees
where employee_id = 113;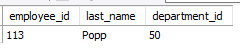
예제2)
** 자동 커밋 해제하기 : [Query] - [Auto commit] 체크 해제
update copy_emp
set department_id = 110;
-- where절 없이 update한 결과 모든 행이 변경됨. (작업실수)
select *
from copy_emp;
-- 작업한 결과 확인(저장X, 미리보기)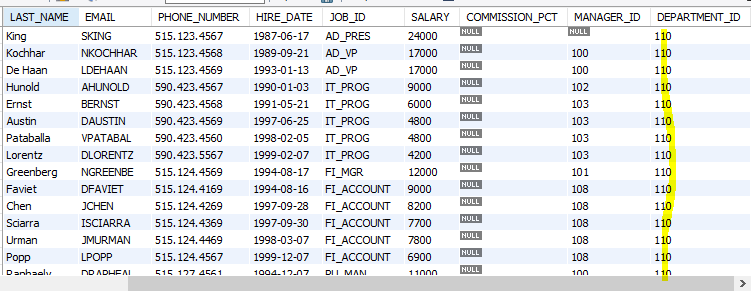
rollback;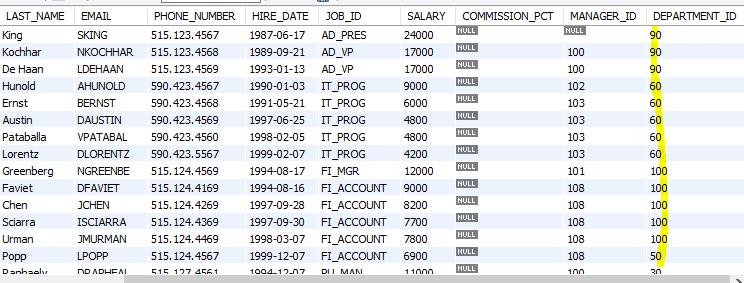
다시 자동 커밋 설정하기 : [Query] - [Auto commit] 체크하기
예제3) update + 서브쿼리(subquery)
copy_emp 테이블의 113번 사원의 job_id와 salary를 employees 테이블에 있는 205번 사원의 job_id, salary와 동일하게 변경하는 작업을 수행하시오.
select employee_id, last_name, job_id, salary
from employees
where employee_id = 205;
select employee_id, last_name, job_id, salary
from copy_emp
where employee_id = 113;
update copy_emp
set job id = (205번의 job id),
salary = (205번의 salary)
where employee_id = 113;
update copy_emp
set job_id =
(select job_id
from employees
where employee_id = 205),
salary =
(select salary
from employees
where employee_id = 205)
where employee_id = 113;
select employee_id, last_name, job_id, salary
from copy_emp
where employee_id = 113;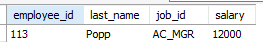
예제4) update + 서브쿼리(subquery)
location_id가 1800인 부서에 소속된 사원들의 급여를 10% 인상하시오.
select *
from departments;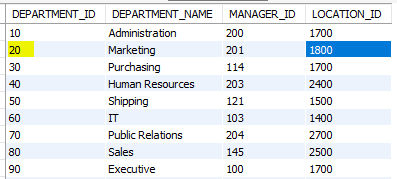
select *
from copy_emp;
update copy_emp
set salary = salary * 1.1
where department_id = (location_id가 1800인 부서);
update copy_emp
set salary = salary * 1.1
where department_id =
(select department_id
from departments
where location_id = 1800);
select employee_id, last_name, salary, department_id
from copy_emp
where department_id =
(select department_id
from departments
where location_id = 1800);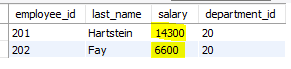
데이터삭제 : delete
데이블의 특정행을 삭제하는 명령어
where절 생략 시 모든 행이 삭제되는 명령어
[문법] delete from 테이블명
[where 조건문];
예제1)
delete from departments
where department_name = 'html';
select *
from departments;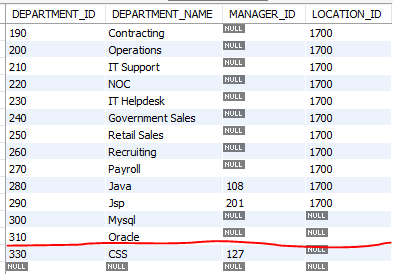
예제2)
** 자동 커밋 해제하기 : [Query] - [Auto commit] 체크 해제
delete from copy_emp;
-- where절 생략 시 모든 행 삭제됨.select *
from copy_emp;
-- 작업 결과 확인(저장 X, 미리보기)
rollback;
-- 작업 취소
delete from copy_emp
where employee_id = 105;
select *
from copy_emp
where employee_id = 105;
commit;
-- 작업 저장다시 자동 커밋 설정하기 : [Query] - [Auto commit] 체크하기
예제3) delete + 서브쿼리(subquery)
copy_emp 테이블로부터 location_id가 1800인 부서에 소속된 사원들을 삭제하시오.
delete from copy_emp
where department_id =
(select department_id
from departments
where location_id = 1800);
select *
from copy_emp
where department_id =
(select department_id
from departments
where location_id = 1800);** 조회결과 없음 = 삭제됨
트랜잭션
-
하나의 논리적인 작업단위로 여러개의 DML이 모여서 구성이 됨.
-
트랜잭션제어어(TCL) - commit(저장), rollback(취소), savepoint(저장점)
-
트랜잭션 시작 : 첫번째 DML이 실행될 때
-
트랜잭션 종료 : commit, rollback 명령어가 실행될 때
-
[상황1] auto-commit 설정된 상태
DML(insert, update, delete) 하나가 하나의 트랜잭션임!
(트랜잭션 시작) insert -----;
(트랜잭션 종료) (autocommit 바로 발생됨)
(트랜잭션 시작) update -----;
(트랜잭션 종료) (autocommit 바로 발생됨) -
[상황2] auto-commit 해제된 상태
(트랜잭션 시작) insert -----;
----------------- update -----;
----------------- update -----;
(트랜잭션 종료) commit;
(트랜잭션 시작) delete -----;
----------------- delete
(트랜잭션 종료) rollback; -
[상황3] auto-commit 해제된 상태
(트랜잭션 시작) insert -----;
----------------- update -----;
----------------- savepoint 포인트명1; -- 저장안됨
----------------- update -----;
----------------- savepont 포인트명2;
----------------- delete -----; ==> 작업 실수
----------------- rollback to 포인트명2;
----------------- 작업 다시하기
(트랜잭션 종료) commit;
예제) Auto-commit 해제하고 작업하기
-- 트랜잭션 시작
update copy_emp
set salary = 29000
where employee_id = 100;
select employee_id, last_name, salary
from copy_emp
where employee_id = 100; -- 미리보기
savepoint test01; -- 저장점 생성됨update copy_emp
set salary = 34000
where employee_id = 101; -- DML 작업
select employee_id, last_name, salary
from copy_emp
where employee_id = 101; -- 미리보기
rollback to test01;select employee_id, last_name, salary
from copy_emp
where employee_id in(100, 101);
-- 101번 원래대로 돌아옴
<연습문제>
- MY_EMPLOYEE라는 테이블을 생성합니다.
CREATE TABLE my_employee
(id int PRIMARY Key,
last_name VARCHAR(25),
first_name VARCHAR(25),
userid VARCHAR(8),
salary int);- 열 이름을 식별하도록 MY_EMPLOYEE 테이블의 구조를 기술합니다.
DESC my_employee;- 다음 데이터를 MY_EMPLOYEE 테이블에 추가하는 INSERT문을 작성하시오.
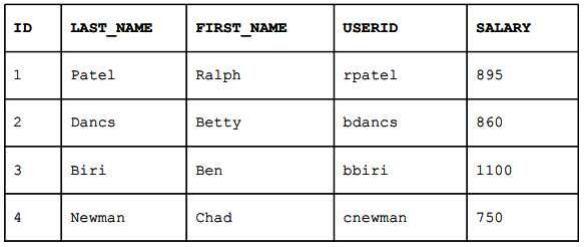
insert into my_employee
value(1, 'Patel','Ralph', 'rpatel', 895),
(2, 'Dancs', 'Betty', 'bdancs', 860),
(3, 'Biri', 'Ben', 'bbiri', 1100),
(4, 'Newman', 'Chad', 'cnewman', 750);- 테이블에 추가한 내용을 확인하시오.
select *
from my_employee;- 테이블에 삽입한 내용을 영구히 저장하시오.
commit;※ MY_EMPLOYEE 테이블에서 데이터를 갱신하고 삭제합니다.
6. ID가 3인 사원의 last_name을 Drexler로 변경하시오.
update my_employee
set last_name = 'Drexler'
where id = 3;- 급여가 $900 미만인 모든 사원에 대해 급여를 $1000로 변경하시오.
update my_employee
set salary = 1000
where salary < 900;- 테이블에 변경 작업한 내용을 확인하시오.
select *
from my_employee;- MY_EMPLOYEE 테이블에서 Betty Dancs란 사원을 삭제하시오.
delete from my_employee
where first_name = 'Betty'
and last_name = 'Dancs';- 테이블에 변경 작업한 내용을 확인하시오.
select *
from my_employee;- 보류 중인 모든 변경 사항을 커밋하시오.
commit;※ MY_EMPLOYEE 테이블에 대한 데이터 트랜잭션을 제어합니다.
12. 다음 데이터를 MY_EMPLOYEE 테이블에 추가하는 INSERT문을 작성하시오.

insert into my_employee
value (5, 'Ropeburn', 'Audrey', 'aropebur', 1550);- 테이블에 추가한 내용을 확인하시오.
select *
from my_employee;- insert 작업까지 진행한 현재 위치에 저장점(savepoint)을 생성하시오.
savepoint point1;- MY_EMPLOYEE 테이블에서 모든 행을 삭제하시오.
delete from my_employee;- 테이블이 비어 있는지 확인하시오.
select *
from my_employee;- 이전의 INSERT 작업은 삭제하지 않은 채로 최근의 DELETE 작업만 취소하시오.
rollback to point1;- INSERT 작업은 삭제하지 않은 채로 최근의 DELETE 작업만 취소되었는지 확인하시오.
select *
from my_employee;- 작업한 내용을 영구히 저장하시오
commit;데이터정의어(DDL) - Table
SQL구문의 유형
- 데이터질의어(DQL) : select
- 데이터조작어(DML) : insert, update, delete
- 데이터정의어(DDL) : create, alter, drop, truncate
- 데이터제어어(DCL) : grant, revoke
- 트랜잭션제어어(TCL) : commit, rollback, savepoint
테이블 생성 : create table
[문법] create table 테이블명
(컬럼명1 데이터타입(컬럼사이즈),
컬럼명2 데이터타입(컬럼사이즈) 제약조건,
컬럼명3 데이터타입(컬럼사이즈) default 기본값,
컬럼명4 데이터타입(컬럼사이즈));
- 테이블명, 컬럼명 : 문자로 시작, 문자/숫자/특수문자(_,#,$) 혼합가능
- 데이터타입
- 문자 : char(고정), varchar(가변)
- 숫자
- 정수 : int, bigint
- 실수 : double
- 날짜
- 년/월/일 : date
- 년/월/일/시/분/초 : datetime
- 옵션 : 제약조건, default값
- DDL, DCL : 무조건 autocommit 내포하는 명령어
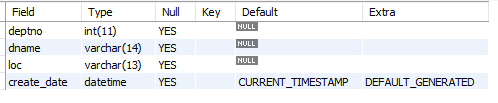
create table dept
(deptno int,
dname varchar(14),
loc varchar(13),
create_date datetime default now());
desc dept;
insert into dept
values (10, 'AAA', 'A100', '2022-10-25 13:51:05');
insert into dept(deptno, dname)
values ( 20, 'BBB');- default값이 선언되어 있지 않은 컬럼은 생략이 null값 삽입됨.
- default값이 선언된 컬럼은 생략시 default값 삽입됨.
- 명시적(수동)으로 default값 삽입하는 방법
insert into dept
values (30, 'CCC', 'C100', default);
select *
from dept;
insert into dept
values (40, 'DDD', 'D100', null);insert into dept
values (50, 'EEE', default, default);
select *
from dept;- 3번째 컬럼은 default값 설정되어 있지 않음. null로 자동 입력 됨

