학습 정리
PyTorch
1강 Introduction to PyTorch
PyTorch vs TensorFlow
Computational Graph 방식의 차이
PyTorch : Define by Run (Dynamic Computational Graph) - 실행을 하면서 그래프를 생성
TensorFlow : Define by Run - 그래프를 정의한 후 실행 시점에 데이터 feed
요즘은 PyTorch를 많이 쓰는 추세PyTorch
Numpy 구조의 Tensor 객체
자동미분
DL 지원하는 다양한 함수와 모델
2강 PyTorch Basics
- Numpy와 Tensor는 사용법이 대부분 유사
# Data to Tensor data = [[3,5],[10,5]] ex_data = torch.tensor(data) # ndarray to tenstor nd_array_ex = np.array(data) tensor_array = torch.from_numpy(nd_array_ex)
- Tensor를 GPU에 올려서 사용 가능
example_data.device: 올라간 장치(cpu or cuda) 확인
example_data.to('cuda'): gpu에 올리기- Tensor Handling
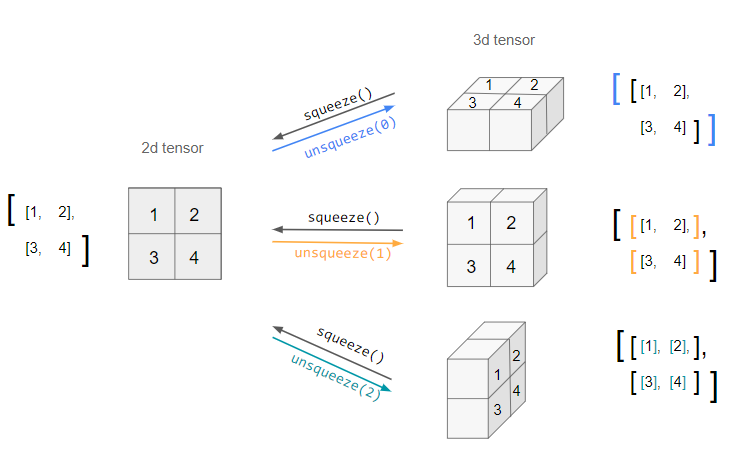
example_tensor.view([2,3]): numpy의reshape과 유사, tensor의 shape 변환 (reshape도 되지만view권장)
example_tensor.squeeze(): 차원 압축
example_tensor.unsqueeze(dim): dim 차원 추가
- 기본적인 tensor operation은 numpy array와 동일
행렬 곱셈 연산의 경우a.mm(b)혹은a.matmul(b)사용(mm권장)torch.nn.functional모듈의 함수들 통해 수식 변환
.softmax(),.one_hot()등등- 자동미분(AutoGrad) 지원
.backward(): 자동 미분 해주는 함수
requires_grad = True: AutoGrad의 대상 정해주기w = torch.tensor(2.0, requires_grad=True) y = w ** 2 z = 10 * y + 25 z.backward() # dz/dw w.grad # tensor(40.)
3강 PyTorch 프로젝트 구조 이해하기
- https://github.com/victoresque/pytorch-template 의 PyTorch 템플릿을 통해 프로젝트 구조에 대한 학습
- VSCode와 SSH로 연결해서 Colab을사용하는 방법
4강 AutoGrad & Optimizer
torch.nn.Module: 딥러닝의 Layer를 구성하는 base 모듈, in_features, out_features, forward, backward, parameters 정의nn.Parameter: 네트워크에서 gradient가 계산되는 파라미터 설정loss.backward: Layer에 있는 Parameter들의 미분을 자동으로 수행, forward의 결과값과 실제값의 차이인 loss에 대한 미분 후 parameter update
5강 PyTorch datasets & dataloaders
- Dataset :
from torch.utils.data import Dataset, 데이터 입력 형태를 정의하는 클래스
__init__: 초기 데이터 생성 방법을 지정__len__: 데이터의 전체 길이 정의__getitem__: index 값을 주었을 때 반환되는 데이터의 형태- DataLoader :
from torch.utils.data import DataLoader, Data의 변환과 Batch를 생성해주는 클래스
shuffle: 데이터를 DataLoader에서 섞어서 사용하겠는지를 설정num_workers: 데이터를 불러올때 사용하는 서브 프로세스(subprocess) 개수collate_fn: 보통 map-style 데이터셋에서 sample list를 batch 단위로 바꾸기 위해 필요한 기능. zero-padding이나 Variable Size 데이터 등 데이터 사이즈를 맞추기 위해 사용.DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None, num_workers=0, collate_fn=None, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None)
6강 모델 불러오기
model.save(): 학습 결과를 저장, 모델의 형태와 파라미터를 저장, 모델 학습 중간 과정의 저장을 통해 최선의 결과 모델 선택 가능, 모델 공유 가능
torch.save(model.state_dict(), os.path.join(MODEL_PATH, "model.pt")): 모델의 파라미터를 저장new_model.load_state_dict(torch.load(os.path.join(MODEL_PATH,"model.pt"))): 같은 모델의 형태에서 파라미터만 loadmodel = torch.load(os.path.join(MODEL_PATH, "model_pickle.pt")): 모델의 architercure와 함께 load- Checkpoints
- 학습의 중간 결과를 저장하여 최선의 결과를 선택
- earlystopping 기법 사용시 이전 학습의 결과물을 저장
- loss와 metric 값을 지속적으로 확인 저장
- 일반적으로 epoch, loss, metric을 함께 저장하여 확인
- 지속적인 학습을 위해 필요
torch.save({ 'epoch': e, 'model_state_dict': model.state_dict(), 'optimizer_state_dict': optimizer.state_dict(), 'loss': epoch_loss, }, f"saved/checkpoint_model_{e}_{epoch_loss/len(dataloader)}_{epoch_acc/len(dataloader)}.pt") print(f'Epoch {e+0:03}: | Loss: {epoch_loss/len(dataloader):.5f} | Acc: {epoch_acc/len(dataloader):.3f}')
- Transfer learning : 다른 데이터셋으로 만든 모델을 현재 데이터에 적용, 일반적인 학습기법
vgg = models.vgg16(pretrained=True).to(device): vgg16 모델 가져오기- Freezing : pretrained model을 활용시 모델의 일부분을 frozen 시켜 파라미터 값이 안바뀌게 고정시키기
7강 Monitoring tools for PyTorch
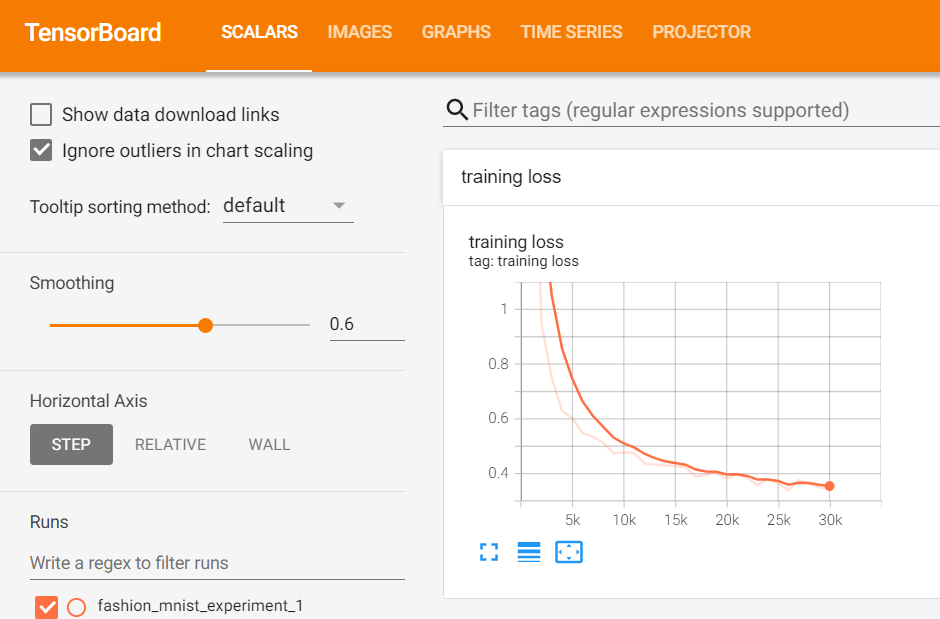
- Tensorboard : TensorFlow의 프로젝트로 만들어진 시각화 도구 -> 학습 그래프, metric, 학습 결과의 시각화 지원
from torch.utils.tensorboard import SummaryWriter
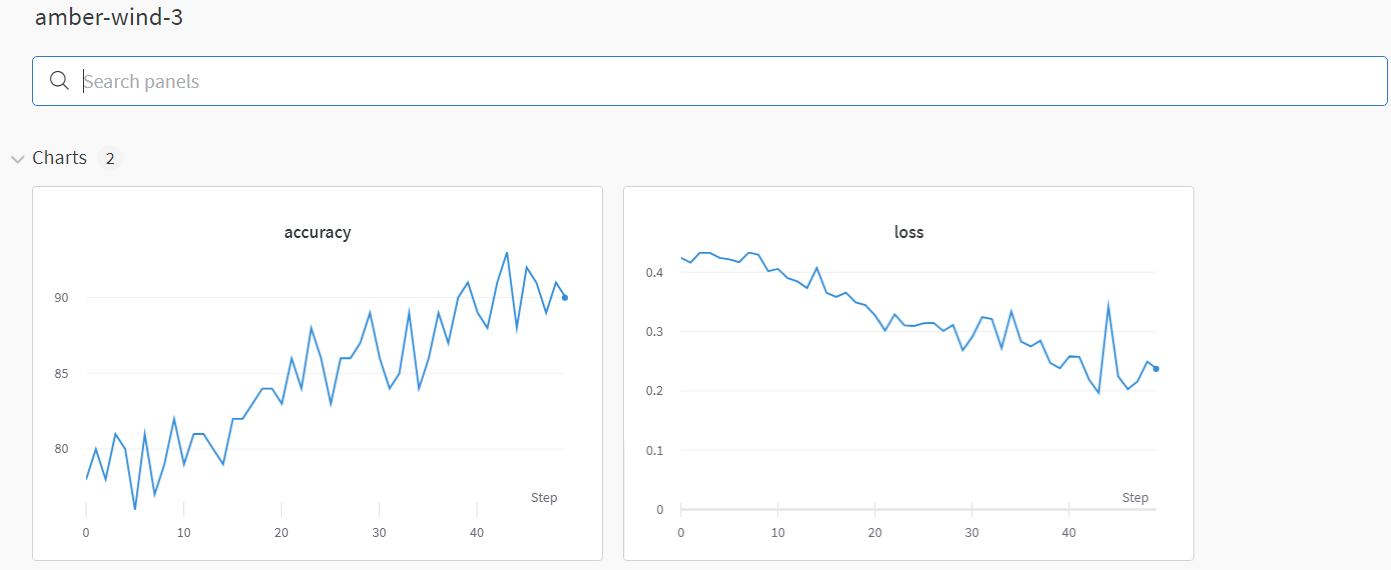
- weight & biases : 머신러닝 실험을 원활히 지원하기 위한 상용도구, 협업, code versioning, 실험 결과 기록 등 제공
8강 Multi-GPU 학습
다중 GPU에 학습을 분산하는 두 가지 방법 : 모델을 나누기 / 데이터를 나누기
- Model parallel : 모델 나누기 - 모델의 병목, 파이프라인의 어려움 등으로 인해 모델 병렬화는 고난이도 과제
- Data parallel : 데이터를 나눠 GPU에 할당후 결과의 평균을 취하는 방법, minibatch 수식과 유사한데 한번에 여러 GPU에서 수행
9강 Hyperparameter Tuning
- Hyperparameter : 모델 스스로 학습하지 않는, 사람이 지정해줘야 하는 값들 (learning rate, 모델의 크기, optimizer 등)
- Grid Search : 일정한 범위를 정해서 Hyperparameter 정하기
- Random Layout : 아무 값이나 넣어봐서 Hyperparameter 정하기
- Random으로 하다가 학습이 잘되는 구간 있으면 그 구간에서 Grid Search 한다
- Ray : multi-node multi processing 지원 모듈, Hyperparameter Search를 위한 다양한 모듈 제공
10강 PyTorch Troubleshooting
- OOM (Out of Memory)
- Iteration 돌면서 많이 발생
- 왜 발생했는지 알기 어려움
- 어디서 발생했는지 알기 어려움
- Error backtracking 이 이상한데로 감
- 메모리의 이전상황의 파악이 어려움
- 대부분 Batch Size를 줄이고 GPU Clean 후 돌리면 해결...?
- GPUUtil : GPU의 상태를 보여주는 모듈,
GPUtil.showUtilization()- torch.cuda.empty_cache() : 사용되지 않은 GPU상 cache를 정리, 학습 loop이 시작되지 전에 하고 시작해도 괜찮다
- tensor로 축적 되는 변수 확인 : tensor로 처리된 변수는 GPU 상에 메모리 사용, 1-d tensor의 경우 python 기본 객체로 변환하여 처리할 것
del: 필요가 없어진 변수는 적절한 삭제가 필요함- batch 사이즈를 1로 해서 실험해보기
- torch.no_grad() 사용하기 : Inference 시점에서는 torch.no_grad() 구문을 사용
회고
- 과제 양이 상당했다. 부덕이 친구가 이것저것 알려주려 하는데 정신 나갈 뻔 했다. 과제에서 알려주는 내용이 많았다. PyTorch의 전체적인 사용법을 과제 실습을 통해 배웠다. 과제 양이 많아 엄청 오래 걸리기는 했지만 그만큼 정리된 자료를 받아 실습해 볼 수 있었던 것은 매우 좋았다. 과제를 잘 정리해 놓으면 큰 도움이 될 것 같다.
- 과제를 하느라 다른 것들을 많이 못한 것이 아쉬웠다. 학습 정리도 제때 하지 못했고 강의도 밀리지 않기 위해 급하게 들은 감이 있다. 공휴일이었던 월요일에도 강의를 듣고 공부를 했음에도 시간이 부족하다고 느껴졌다. (공휴일이 의미가 있나...)
