학습 정리
DL Basics & Data Visualization (1)
DL Basic
1강 Historical Review
- DL Basic 강의들의 전체적인 overview, 딥러닝의 역사 및 주요 논문들에 대한 간단한 설명
2강 Neural Networks & Multi-Layer Perceptron
- Neural Network란? - 인간의 뇌를 모방한 시스템 but 사실 좀 방향성이 갈라졌다.
-> '행렬 변환과 비선형 연산을 쌓아 만든 근사 함수 시스템'이 담백한 정의가 아닐까- Linear Neural Networks
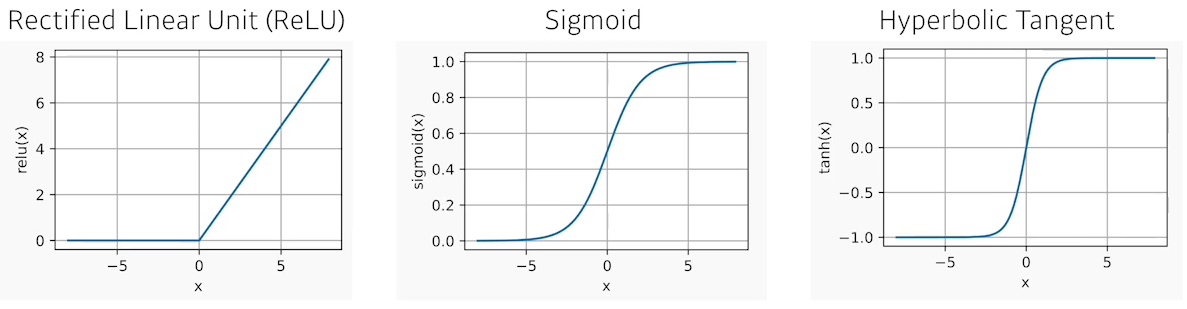
층을 더 쌓고 싶다면?로 해도 이 하나의 행렬과 다르지 않기 때문에 여러 층을 쌓는 의미가 없다. 어차피 하나의 층과 똑같다. 그러므로 Non-Linear Transform()이 필요한 것.- Non-Linear Transform을 위한 활성함수 (Activation Function)
ReLu :
Sigmoid :
Hyperbolic Tangent :
- (실습) PyTorch로 Multi-Layer Perceptron 구현하기
3강 Optimization
- 여러 용어들
Generalization Pefromance(일반화 성능) : Training error와 Test error 사이에 얼마나 차이가 나는가
Underfitting(과소적합) vs Overfitting(과적합)
Cross-validation(k-fold validation) : Train data를 개의 fold로 나눠 개로 학습, 나머지 개로 validation하는 과정 -> 주로 최적의 hyperparameter 찾는 과정에서 쓰임. 최적의 hyperparameter를 찾은 후에는 전체 train data로 학습(Test data는 절대 건들지 말것)
Bias and Variance Tradeoff : 학습 데이터에 noise가 껴 있다고 했을 때 bias와 variance를 둘 다 줄일 수는 없다는 이론
Bootstrapping : 학습 데이터를 random subsampling 해서 여러 model을 만들어서 활용하는 것
Bagging : 학습 데이터를 나눠 random subsampling 해서 여러 model을 만든 후 결과를 평균이나 voting을 통해 결과를 내는 방식 (ex. 앙상블)
Boosting : 학습 데이터를 통해 model을 만든 후 학습이 잘 안되는 데이터를 따로 빼내 그 데이터로만 학습한 모델을 만드는 방식. 이러한 모델들을 이어서 하나의 strong learner를 만듦
- Optimizers
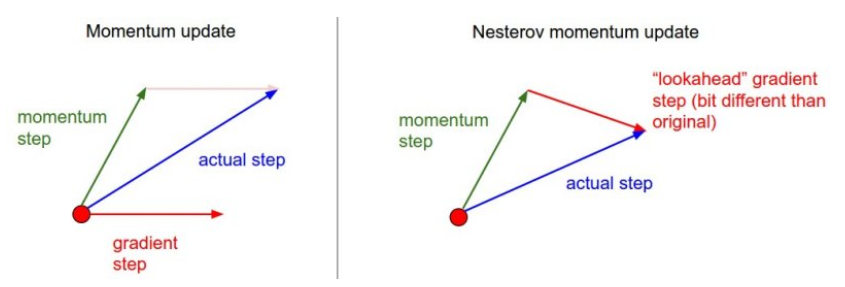
Momentum : gradient 방향이 흐르던 방향을 고려하여 계산
Nesterov Accelerated Gradient : look ahead gradient(momentum 방향으로 이동 후 계산한 gradient)를 활용
Adagrad : 많이 변한 파라미터는 적게 변화시키고 적게 변한 파라미터는 많이 변화시키는 Adaptive learning rate을 적용, 는 지점까지의 gradient의 총합
Adadelta : 가 계속 커지면서 학습이 안되는 문제가 있는 Adagrad를 보완, learning rate가 없음
RMSprop : Adagrad와 Adadelta를 합친 느낌...? learning rate가 생김,
정확하게는... 잘...
Adam : Adaptive learning rate과 Momentum을 모두 활용
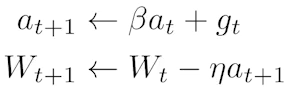
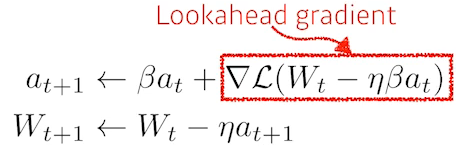
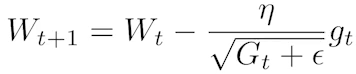
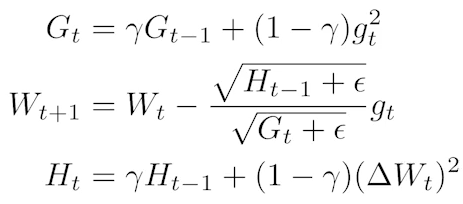
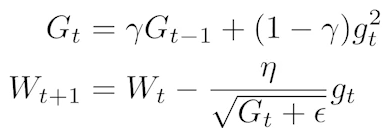
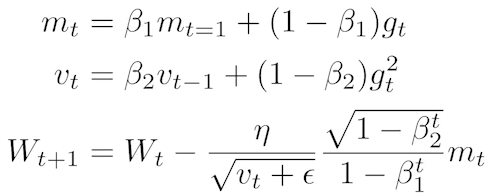
- Regularization - 성능을 높이는 방법들?
-Early Stopping : 학습이 지속될 수록 overfitting 되는 경우 일찍 학습을 멈춰 Generalization Performance를 높인다.
-Parameter Norm Penalty : 파라미터의 크기가 너무 크지 않게 한다. -> 함수를 최대한 부드럽게해서 Generalization Performance를 높인다.
-Data Augmentation : 적은 학습 데이터를 지지고 볶아서 학습 데이터 수를 늘린다.
-Noise Robustness : 학습 데이터에 노이즈를 넣어 정확도를 높인다.
-Label Smoothing : Data Augmentation과 유사, 데이터 두 개를 뽑아서 섞어준다.(CutMix, Mixup, Cutout 등등)
-Dropout : 일정 비율의 파라미터를 0으로 만들어준다.
-Batch Normalization : 적용하려는 layer를 정규화시킨다.
4강 Convolutional Neural Networks
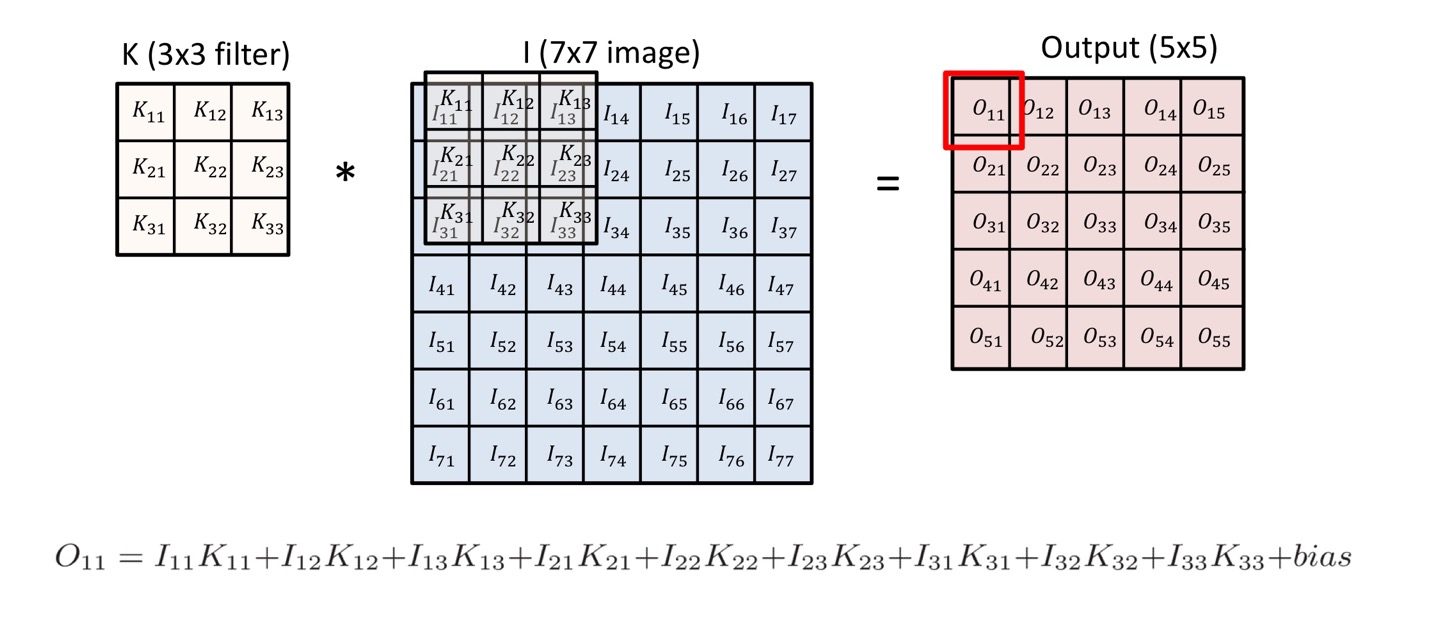
- 2D Image Convolution - : 전체 이미지, : convolution filter
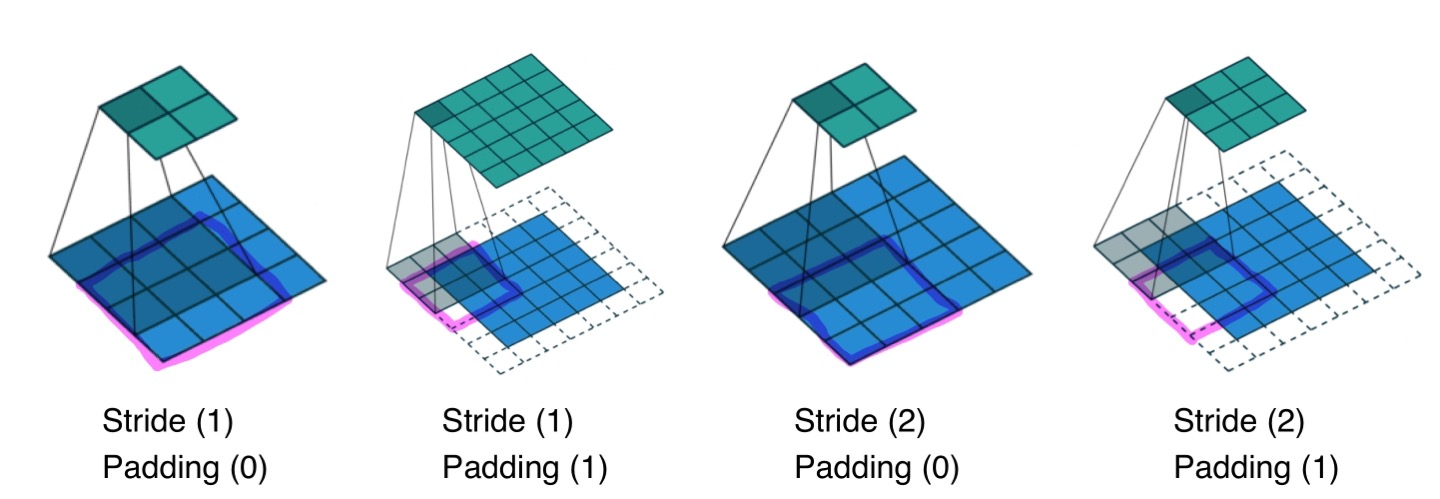
- Stride : 건너뛰는 step 수
- Padding : Boundary 정보를 활용하기 위해 데이터에 임의의 수를 덧대는 것
- Parameters 수 : kernal size input channel kenral 갯수
모델이 학습해야하는 파라미터가 늘어날수록 학습이 어렵고 Generalizatin Performance가 떨어진다고 알려져있다.- 1 1 Convolution : Channel 크기 줄여서 파라미터 수를 줄인다. (Spacial dimension은 유지)
5강 Modern Convolutional Neural Networks
- CNN의 주요 논문들에 대한 간단한 뽀인트 설명
- KeyPoints :
AlexNet : ReLU, Data augmentation, Dropout (CNN의 기준을 잡아준 논문)
VGGNet : 3 3 kernal 만을 사용
GoogLeNet : 1 1 Convolution을 통해 파라미터 수를 대폭 줄임
ResNet : Skip-Connection(차이만 학습하는 방법)을 통해 파라미터 수 줄임
DenseNet : Concatnation을 통해 성능 높임
6강 Computer Vision Applications
- Sementic Segmentation : 픽셀마다 이미지 분류
Fully Convolutional Network : 기존 CNN의 flatten 단계를 kernal로 차원을 맞추는 것으로 대체 (Convolutionalization) -> Heatmap 형식으로 분류할 수 있게 해준다.
Deconvolution : Convolution의 반대 과정 느낌으로 줄인 spacial dimension을 키워줄 수 있다.
- Detection : 이미지에서 Bounding Box 찾아서 분류
R-CNN : 이미지에서 2000개의 region을 막 뽑고 CNN과 SVM을 통해 분류 (2000번 돌려야돼서 매우 오래걸린다)
SPPNet : CNN을 한 번만 돌리고 region을 뽑는다.
Fast R-CNN : SPPNet과 유사, Neural Network를 통해 분류
Faster R-CNN : Bounding Box를 뽑아내는 과정도 학습시켜 활용한다.(Region Proposal Network)
YOLO : Bounding Box를 예측하는 것과 Class 찾기를 동시에 한다.
7강 Recurrent Neural Networks
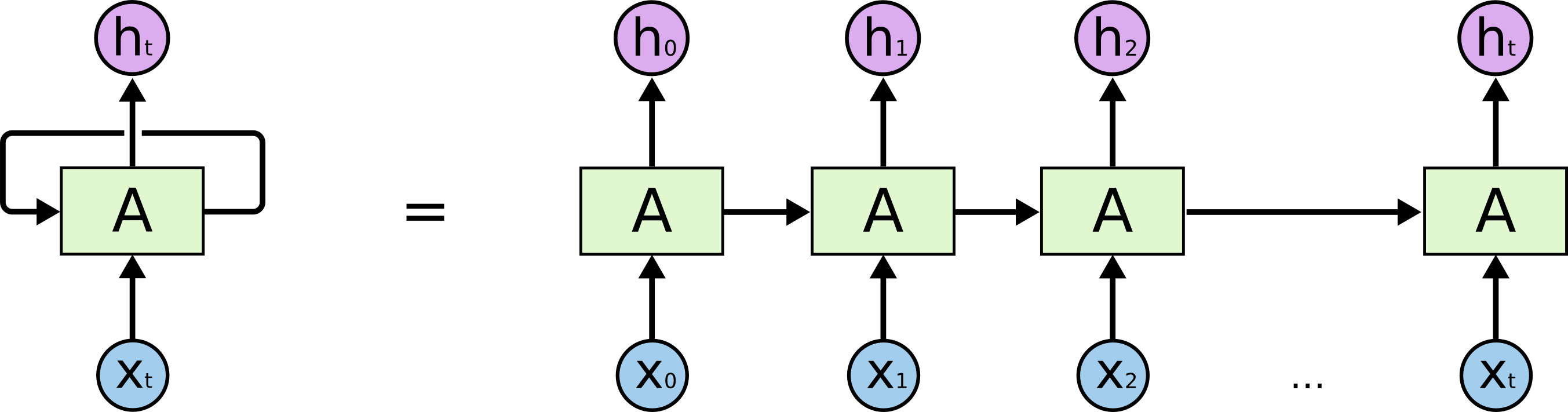
길이를 알 수 없는 (input 차원을 알 수 없는) Sequential Model들은 CNN이나 MLP를 사용할 수 없음 -> 몇 개의 input이 들어오던 동작하는 model이 필요 -> RNN
- RNN (Recurrent Neural Networks)
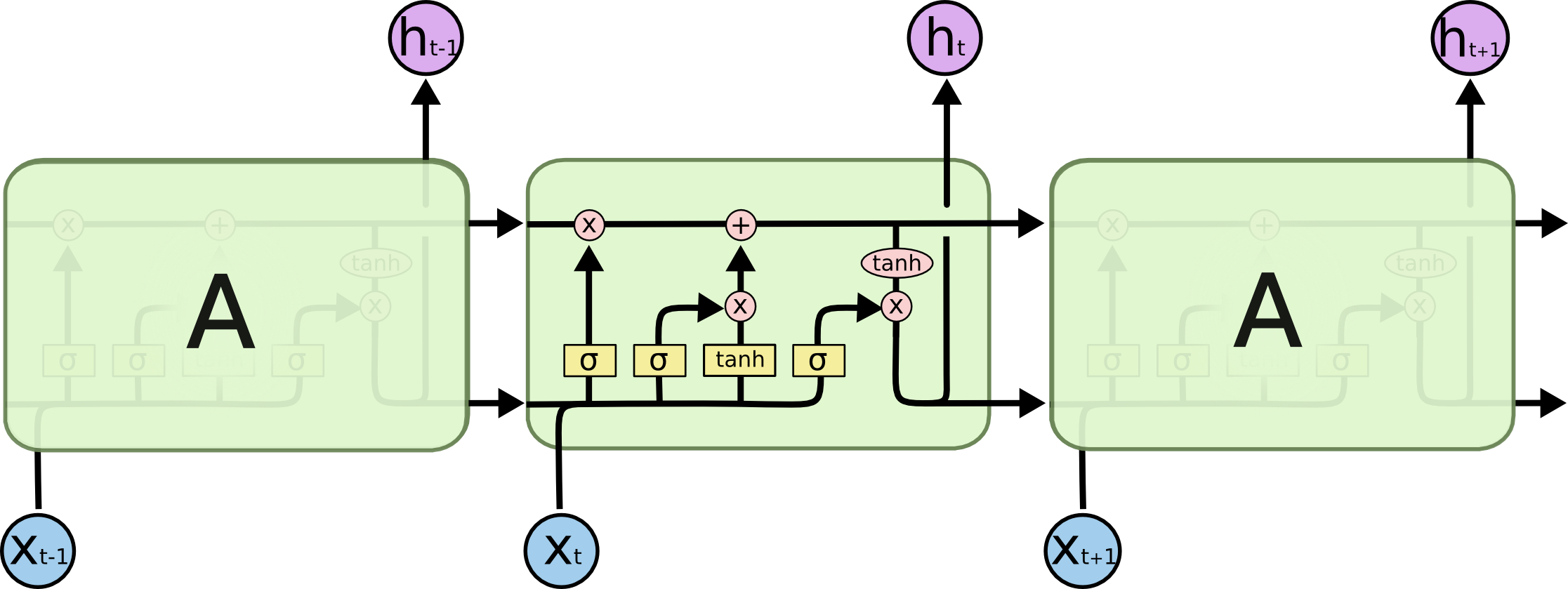
- Vanishing / Exploding Gradient 문제로 인해 Long-term input들의 과거 정보들이 학습이 잘 안됨- LSTM (Long Short Term Memory)
- Cell State와 Hidden State를 계속 넘겨 주며 과거의 정보를 활용 할 수 있음
- Forget Gate, Input Gate, Output Gate의 3개의 Gate를 통해 정보를 버리거나 기억하고 다음 단계로 전달함- GRU (Gated Recurrent Unit)
- Reset Gate와 Update gate의 2개의 Gate만 활용함
- Cell state가 없고 Hidden state 하나로 두 역할 모두 수행

8강 Transformer
- Transformer : Sequential Data를 처리하고 Encoding, Decoding 하는 방법을 사용, 다양한 분야에 활용됨
왜 잘될까? : model과 하나의 input이 고정되어 있더라고 내가 encoding 하려는 data와 그 옆에 있는 data에 따라서 encoding 된 값이 달라지게 됨 -> flexible한 구조가 되어 훨씬 더 많은 것으로 활용할 수 있게 됨
- 한번에 n개의 단어들을 Encoding 처리 할 수 있음
- Attention : Transformer의 가장 중요한 부분, Encoder와 Decoder에 모두 사용 -> 문장의 경우 각각의 단어가 서로 다른 단어들과 얼마나 연관성(Attention Score)을 가지고 있는지 구함
- Multi-Head Attention : Attention을 여러 세트 만들어서 처리
9강 Generative Models Part 1
- Generative Model : 학습 데이터를 토대로 그와 유사한 데이터를 생성하는 모델 (ex.강아지 사진 생성 모델)
- Generation : 강아지 사진들을 학습 했을 때, 새로운 강아지의 모습을 생성해내는 일
- Density Estimation : 어떤 사진이 주어졌을 때 그 사진이 강아지 같은지 아닌지 구분하는 일- Independence Assumption : 표현하려는 데이터의 parameter 수를 줄이기 위해 각 데이터가 서로 아무런 영향을 미치지 않는 Independent한 상태임을 가정하는 것
- 파라미터의 수를 줄여 어떤 현상을 모델링하기에는 굉장히 효과적, but 표현할 수 있는 표현력을 굉장히 줄임, 유의미한 분포를 모델링하기에는 좋지 않음- Conditional Independence - Markov Assumption : 바로 직전의 데이터에만 dependent하다고 가정하면 필요한 파라미터 수를 효과적으로 줄이면서 유의미한 분포를 모델링 할 수 있게 됨
- Autoregressive Model : Markov Assumption을 이용, 순차적으로 정의되는 모델, 1차원의 sequence가 필요(ordering)
- Sampling이 쉬움. Sequential 하게 Sampling을 함
- n개의 픽셀로 되어있으면 n개의 Neural Net을 통과해야하기 때문에 병렬적 구조가 불가능 -> Generation이 오래걸림
- 새로운 입력의 분포를 구하기 쉬움
10강 Generative Models Part 2
- VAE(Variational AutoEncoder) : 내가 찾고자하는 분포가 너무 복잡해서 사람이 모델링 할 수 없음 -> 그 분포를 찾을 수 있는 간단한 분포로 근사하고 싶은거임 (KL Divergence 최소화), Encoder를 학습시키는 것이 목표.
- GAN(Generative Adversarial Networks) : Generator와 Discriminator를 경쟁시키며 학습시키는 느낌
- Diffusion Models : 노이즈에서 이미지를 생성해내는 모델, 이미지에 노이즈를 넣고 그걸 denoise하는 과정을 학습
Data Visualization
1강 Introduction to Visualization
- 데이터 시각화 : 데이터를 그래픽 요소로 매핑하여 시각적으로 표현하는 것.
- 시각화는 다양한 요소가 포함된 Task
o 목적 : 왜 시각화 하나요?
o 독자 : 시각화 결과는 누구를 대상으로 하나요?
o 데이터 : 어떤 데이터를 시각화할 것인가요?
o 스토리 : 어떤 흐름으로 인사이트를 전달할 것인가요
o 방법 : 전달하고자 하는 내용에 맞게 효과적인 방법을 사용하고 있나요?
o 디자인 : UI에서 만족스러운 디자인을 가지고 있나요?
- Matplotlib
import matplotlib as mpl import matplotlib.pyplot as plt-matplotlib에서 그리는 시각화는 Figure라는 큰 틀에 Ax라는 서브플롯을 추가해서 만든다.
fig = plt.figure() # fig 라는 Figure 만들기 ax = fig.add_subplot() # ax 라는 서브플롯 추가 plt.show() # 보여주기-
plt.figure(figsize=(가로크기, 세로크기)):fig의 크기 조정
-fig.add_subplot(1, 2, 1): (1,2)로fig를 쪼개고 1번째에 ax를 추가
-plt로 그래프 그리기fig = plt.figure() ax = fig.add_subplot() x = np.array([1, 3, 2]) plt.plot(x) plt.show()2개 그리기
fig = plt.figure() x1 = [1, 2, 3] x2 = [3, 2, 1] ax1 = fig.add_subplot(211) plt.plot(x1) # ax1에 그리기 ax2 = fig.add_subplot(212) plt.plot(x2) # ax2에 그리기 plt.show()3개 동시에 그리기 & 색 지정하기 & 범례 추가하기
fig = plt.figure() ax = fig.add_subplot(111) # 3개의 그래프 동시에 그리기 및 색 지정하기 ax.plot([1, 1, 1], color='r') # 한 글자로 정하는 색상 (red, green blue, yellow, black, white 등등) ax.plot([1, 2, 3], color='forestgreen') # color name ax.plot([3, 3, 3], color='#000000') # hex code (BLACK) -> RGB값으로 나타내기 ('#RRGGBB' 로 16진수로 나타낸다) # 같은 종류의 그래프를 그리면 자동으로 색상을 구분해준다. # 다른 종류의 그래프를 그리면 색상이 구분되지 않는다. -> 색을 직접 정해주는게 좋다 ax.plot([4, 4, 4], label='4') # 범례 추가 plt.show()
ax.legend(): 그래프에 범례 목록 보이기
ax.set_title('Ax 제목'): Ax의 제목 붙이기
fig.suptitle('figfigfig'): Figure의 제목 붙이기
ax.set_xticks([0, 1, 2]): 축에 적히는 수 위치 지정
ax.set_xticklabels(['zero', 'one', 'two']): 축에 적히는 텍스트 수정
ax.text(x=1, y=2, s='This is Text'): 원하는 위치에 text 적어주기
ax.annotate(text='This is Annotate', xy=(1, 2)): 주석적기 , 원하는 위치에 text 지정
2강 기본적인 차트의 사용
- Bar Plot
.bar(범주, 값): 수직 barplot - x축에 범주, y축에 값을 표기
.barh(범주, 값): 수평 barplot - y축에 범주, x축에 값을 표기 (범주가 많을 때 적합)
- Multiple Bar Plot
sharey=True: subplot을 만들 때 y축의 범위 공유
.set_ylim(0, 200): y 축의 범위를 고정- Stacked Bar Plot
bottom=데이터: 그래프 아래 공간을 다른 그래프로 채우기ax.bar(group['male'].index, group['male'], color='royalblue') ax.bar(group['female'].index, group['female'], bottom=group['male'], color='tomato')
- Percentage Stacked Bar Plot
group = group.sort_index(ascending=False) # 역순 정렬해야 위에서부터 정렬됨 total=group['male']+group['female'] # 각 그룹별 합 ax.barh(group['male'].index, group['male']/total, # 비율 color='royalblue') ax.barh(group['female'].index, group['female']/total, # 비율 left=group['male']/total, # 왼쪽 채우기 color='tomato')
- Overlapped Bar Plot
ax.bar(group['male'].index, group['male'], color='royalblue', alpha=alpha) # 투명도 설정해서 겹치게 보이도록 하기 ax.bar(group['female'].index, group['female'], color='tomato', alpha=alpha) # 투명도 설정해서 겹치게 보이도록 하기
- Grouped Bar Plot
의 위치를 조정해서 표현 ( : 그룹의 갯수, : index)
좌표 계산 법 :x = np.arange(len(group_list)) width=0.12 for idx, g in enumerate(edu_lv): ax.bar(x+(-len(edu_lv)+1+2*idx)*width/2, group[g], width=width, label=g) ax.set_xticks(x) # 그룹 index ax.set_xticklabels(group_list) # 그룹 index 정보 넣기
- 정확한 Bar Plot
Principle of Proportion Ink : 실제 값과 그에 표현되는 그래픽으로 표현되는 잉크 양은 비례해야 함
데이터 정렬하기 : 더 정확한 정보를 전달하기 위해서는 정렬해주는 것이 좋음 (Pandas 이용)
적절한 공간 활용 : 여백과 공간을 조정하면 가독성이 높아진다.
-.spines[spine].set_visible(): 테두리 제거
-width: 막대 그래프 두께 조절
-linewidth: 막대 테두리 두께 조절
-.margins(): 그래프 마진 조절 (기본 값은 )
복잡함과 단순함 : 어떤 것을 보여줄 것인가
-.grid(): 눈금 추가
-.text(): 텍스트 추가
- Line Plot : 선 그래프
-.plot(): Line Plot 그리기
-marker='*': 다양한 마커로 점 표현 가능 ('o', '.', '^', '*' 등등) - 그래프 내용이 방해되지 않는 한 넣어주는 것이 좋다
-linestyle='--': 선의 종류,solid,dashed,dashdot,dotted,None등
-MultipleLocator(): 각 축에 대한 디테일한 정보(그리드 간격)를 어떤 단위로 나타낼 것인가
- Smoothing : 데이터의 추세를 위주로 보기위해 노이즈를 없애주는 작업. 데이터 전처리 혹은scipy.interpolate이용해서 할 수 있음
- 이중축 사용 :twinx()사용, 정말 필요할 때 아니면 지양해라...
- Scatter Plot : 산점도
-scatter(): 산점도 그리기
-s=10: 점의 크기 - 배열로 지정하면 개별로 지정이 가능하다
-c='white': None으로 하면 기본 색으로 나온다 - 배열로 지정하면 개별로 지정이 가능하다
-edgecolor='black': 점 테두리 색for species in iris['Species'].unique(): # color로 나누는게 아니라 for 문으로 세번 나눠서 그리기 iris_sub = iris[iris['Species']==species] ax.scatter(x=iris_sub['SepalLengthCm'], y=iris_sub['SepalWidthCm'], label=species)
3강 차트의 요소
- Text
Title : 가장 큰 주제를 설명
Label : 축에 해당하는 데이터 정보를 제공
Tick Label : 축에 눈금을 사용하여 스케일 정보를 추가
Legend : 한 그래프에서 2개 이상의 서로 다른 데이터를 분류하기 위해서 사용하는 보조 정보
Annotation(Text) : 그 외의 시각화에 대한 설명을 추가- 글꼴 관련
-family: 글씨체
-sizeorfontsize: 글씨 크기
-styleorfontstyle: italic - 기울임
-weightorfontweight: 글씨 굵기
- 기타 요소들
-color
-linespacing: 줄과 줄 간의 간격
-backgroundcolor: 배경색
-alpha: 투명도
-zorder: 텍스트 앞뒤 순서
-visible: 보이기/안보이기- 위치 조정
-ha: horizontal alignment -> text 위치 기준 잡기 / 정렬
-va: vertical alignment -> text 위치 기준 잡기
-rotation: 회전 (기본은 horizontal), vertical, 숫자로 각도 설정 가능
-multialignment
bbox: boundary box, dict 형태로 전달해야함ax.text(x=0.5, y=0.5, s='Text\nis Important', fontsize=20, # 'large' 이런식으로도 가능 fontweight='bold', fontfamily='serif', # 글씨체 color='royalblue', linespacing=2, va='center', # top, bottom, center ha='center', # left, right, center rotation='vertical' # horizontal bbox=dict(boxstyle='round', facecolor='wheat', ec='blue', alpha=0.4, pad=2) )
- Title & Legend
ax.set_title('Score Relation', loc='left', va='bottom', # location left : 제목 위치 조정 fontweight='bold', fontsize=15 ) ax.legend( title='Gender', # 범례 제목 shadow=True, # 그림자 넣기 labelspacing=1.2, loc='lower right' # 원래 위치 자동으로 되는데 location지정도 가능 bbox_to_anchor=[1.2, 0.5] # 원하는 좌표에 지정도 가능 ncol=2 # nrow등으로 범례 생긴거 조정 가능 )
- 화살표
ax.annotate(text=f'This is #{i} Studnet', xy=(student['math score'][i], student['reading score'][i]), xytext=[80, 40], # text 위치 바꿔주기 bbox=bbox, arrowprops=arrowprops, # 화살표 만들기 zorder=9 )

- Color
Hue(색조) : 빨강, 파랑, 초록 등 색상으로 생각하는 부분
- 빨강에서 보라색까지 있는 스펙트럼에서 0-360으로 표현
Saturate(채도) : 무채색과의 차이
- 선명도라고 볼 수 있음 (선명하다와 탁하다.)
Lightness(광도) : 색상의 밝기- 다양한 컬러맵
-from matplotlib.colors import ListedColormap: 컬러맵 사용
- 'Pastel1', 'Pastel2', 'Accent', 'Dark2', 'Set1', 'Set2', 'Set3', 'tab10' 등이 있다. 굉장히 많다
-c=: 어떤걸 기준으로 색을 정할지
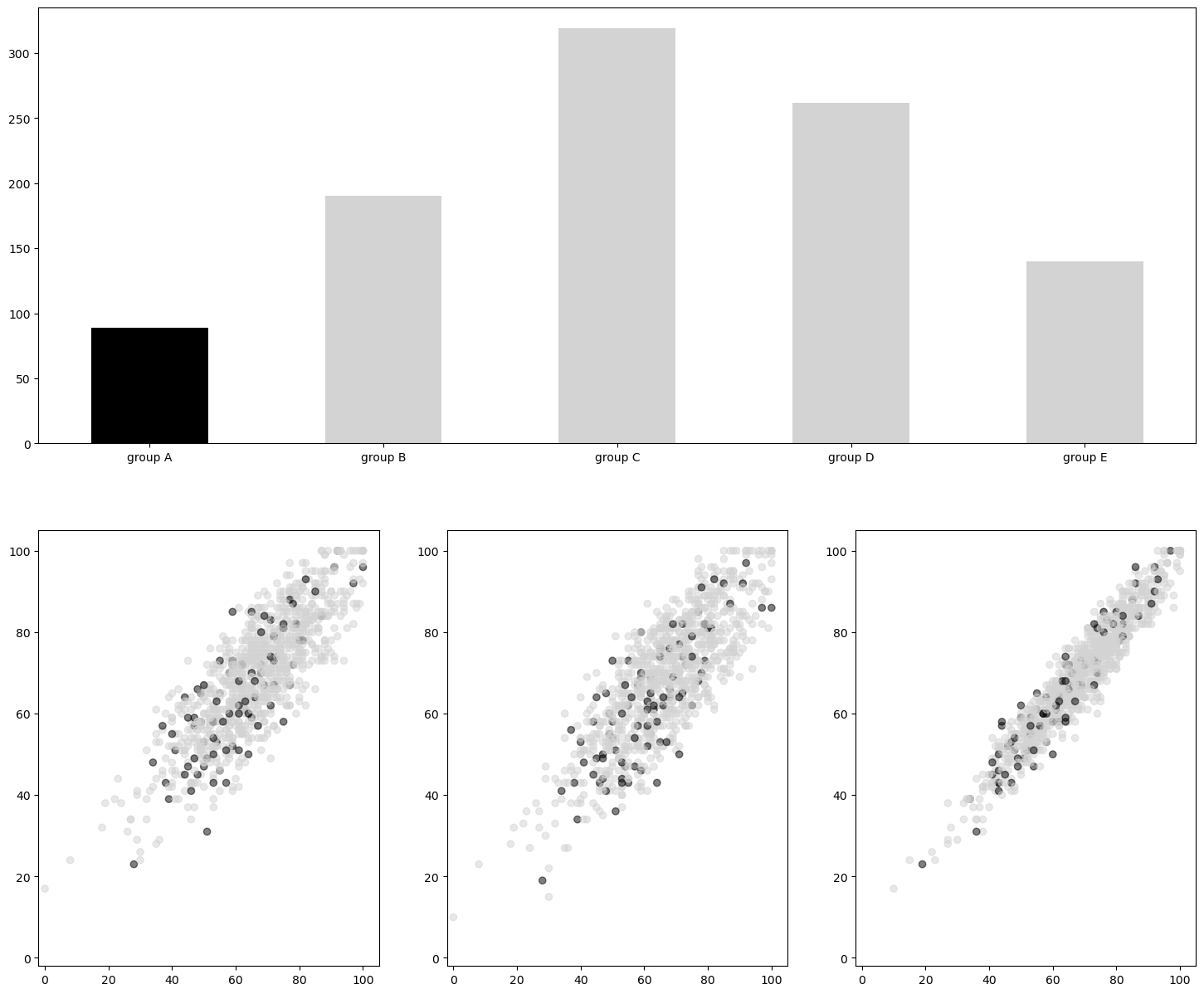
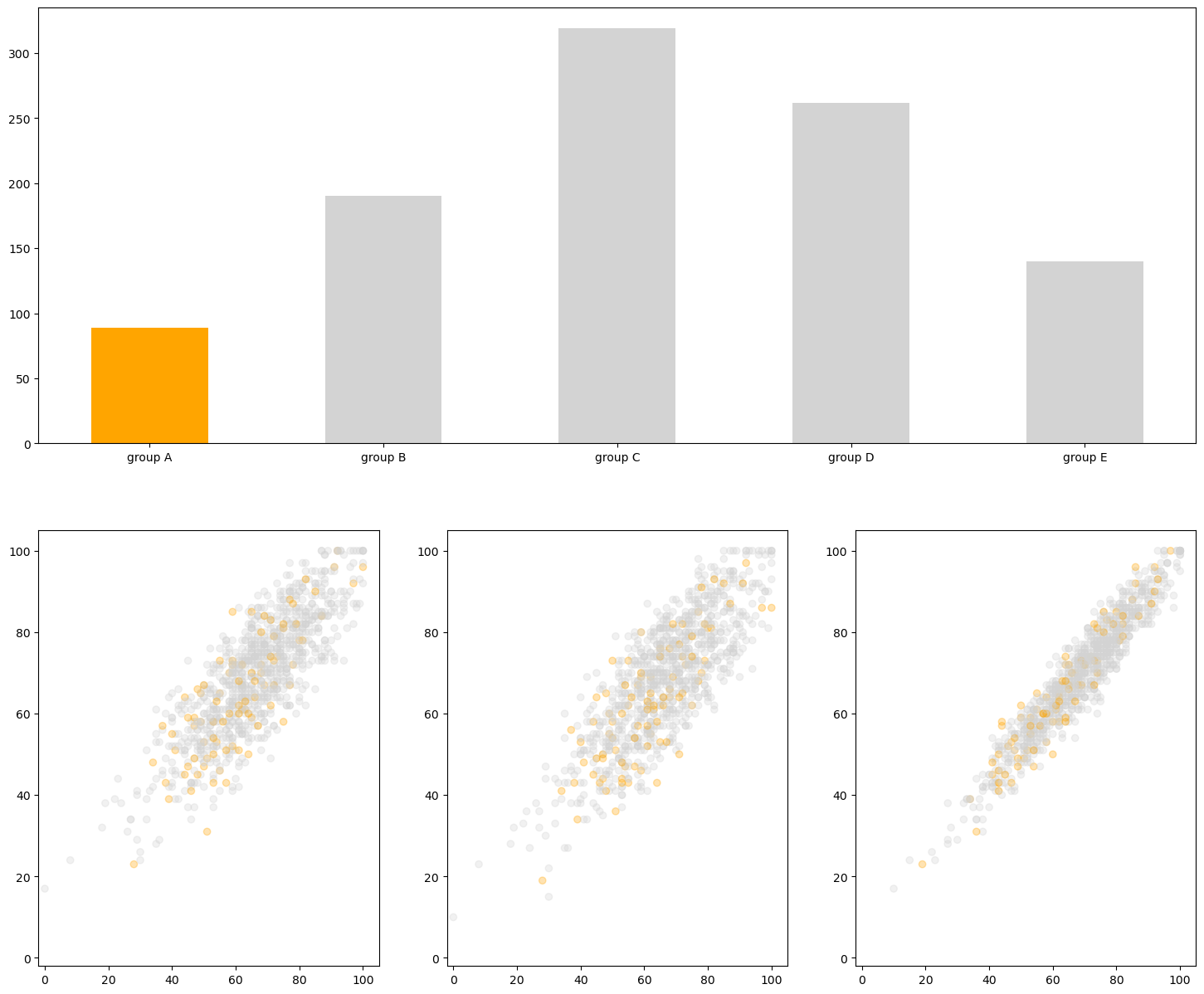
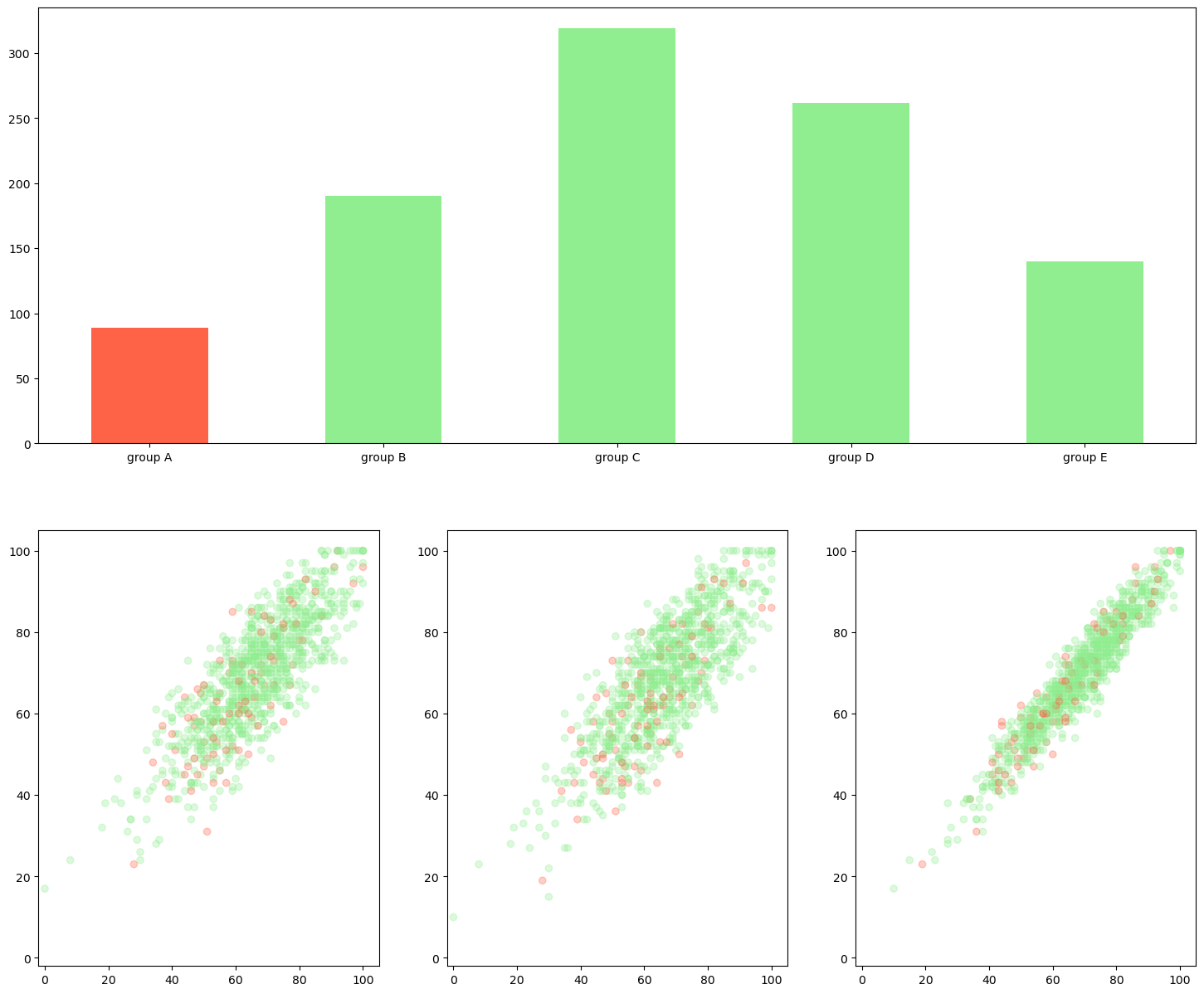
-cmap=ListedColormap(plt.cm.get_cmap('tab10').colors[:5]: 컬러맵에서 5개 색 사용pcm = axes[idx].scatter(student['math score'], student['reading score'], c=student['reading score'], # 어떤걸 기준으로 색 정할지 cmap=cm, # 컬러맵 지정 vmin=0, # 색상의 값을 최대 최소로 지정 가능 vmin보다 작으면 다 최소 색상으로, vmax=100 # vmax보다 큰 값은 최대 색상으로 나타냄 )
- 발산형 색상
-from matplotlib.colors import TwoSlopeNorm: 어떠한 기준점을 바탕으로 정규화from matplotlib.colors import TwoSlopeNorm offset = TwoSlopeNorm(vmin=0, vcenter=student['reading score'].mean(), vmax=100) # 0부터 읽기 성적평균을 0~0.5로 정규화, 읽기성적평균부터 100을 0.5~1로 정규화 pcm = axes[idx].scatter(student['math score'], student['reading score'], c=offset(student['math score']), # 이런식으로 설정해준다 cmap=cm )- 색 대비를 통해 강조 표현
- 명도 대비
- 채도 대비
- 보색 대비
- Facet
-fig.set_facecolor('lightgray'): 차트 배경 색 조정
-dpi: Dots per Inch, 해상도 조정
-sharex,sharey: 개별 ax에 대해서나subplots함수를 사용할 때 사용하여 축을 공유
-aspect: 비율 -> 원래는 자동적으로 맞춰줌- squeeze, flatten
subplots()로 생성하면 기본적으로 다음과 같이 서브플롯 ax 배열이 생성된다.
- 1 x 1 : 객체 1개 (ax)
- 1 x N 또는 N x 1 : 길이 N 배열 (axes[i])
- N x M : N by M 배열 (axes[i][j])
numpy ndarray에서 각각 차원이 0, 1, 2로 나타게 됨.
이렇게 되면 경우에 따라 반복문을 사용할 수 있거나, 없거나로 구분된다.
squeeze를 사용하면 항상 2차원으로 배열을 받을 수 있고, 가변 크기에 대해 반복문을 사용하기에 유용하다.n, m = 2, 3 fig, axes = plt.subplots(n, m, squeeze=False, figsize=(m*2, n*2)) idx = 0 for i in range(n): for j in range(m): axes[i][j].set_title(idx) axes[i][j].set_xticks([]) axes[i][j].set_yticks([]) idx+=1 plt.show()1중 반복문을 쓰고 싶다면
flatten()메서드를 사용할 수 있다.n, m = 2, 3 fig, axes = plt.subplots(n, m, figsize=(m*2, n*2)) for i, ax in enumerate(axes.flatten()): ax.set_title(i) ax.set_xticks([]) ax.set_yticks([]) plt.show()
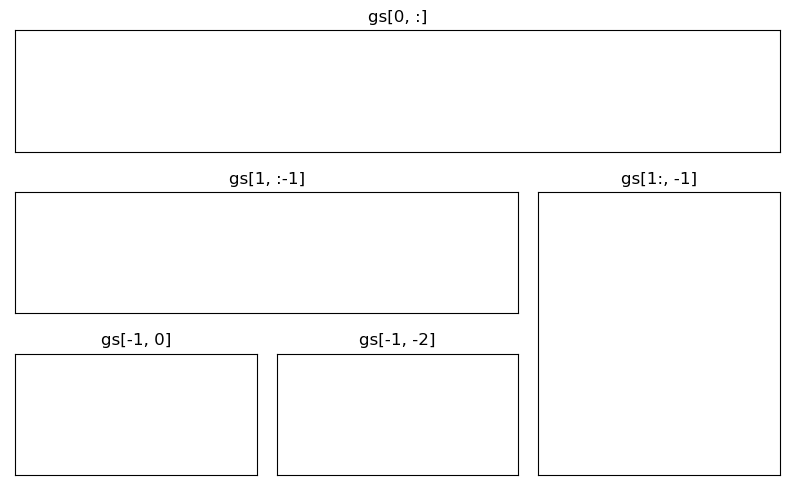
- Gridspec
fig = plt.figure(figsize=(8, 5)) gs = fig.add_gridspec(3, 3) # make 3 by 3 grid (row, col) -> figure를 3 by 3으로 쪼갠다 ax = [None for _ in range(5)] ax[0] = fig.add_subplot(gs[0, :]) ax[0].set_title('gs[0, :]') ax[1] = fig.add_subplot(gs[1, :-1]) ax[1].set_title('gs[1, :-1]') ax[2] = fig.add_subplot(gs[1:, -1]) ax[2].set_title('gs[1:, -1]') ax[3] = fig.add_subplot(gs[-1, 0]) ax[3].set_title('gs[-1, 0]') ax[4] = fig.add_subplot(gs[-1, -2]) ax[4].set_title('gs[-1, -2]') for ix in range(5): ax[ix].set_xticks([]) ax[ix].set_yticks([]) plt.tight_layout() plt.show()
-inset axesfig, ax = plt.subplots() axin = ax.inset_axes([0.8, 0.8, 0.2, 0.2]) # (0.8, 0.8) 에다가 (0.2, 0.2) 크기의 ax 만들어라 plt.show()
-make_axes_locatablefrom mpl_toolkits.axes_grid1.axes_divider import make_axes_locatable fig, ax = plt.subplots(1, 1) ax_divider = make_axes_locatable(ax) # color bar 만드는데 유용하다 ax = ax_divider.append_axes("right", size="7%", pad="2%") # 전체 사이즈의 7%로 subplot 만들고 2%를 간격으로 쓴다 plt.show()
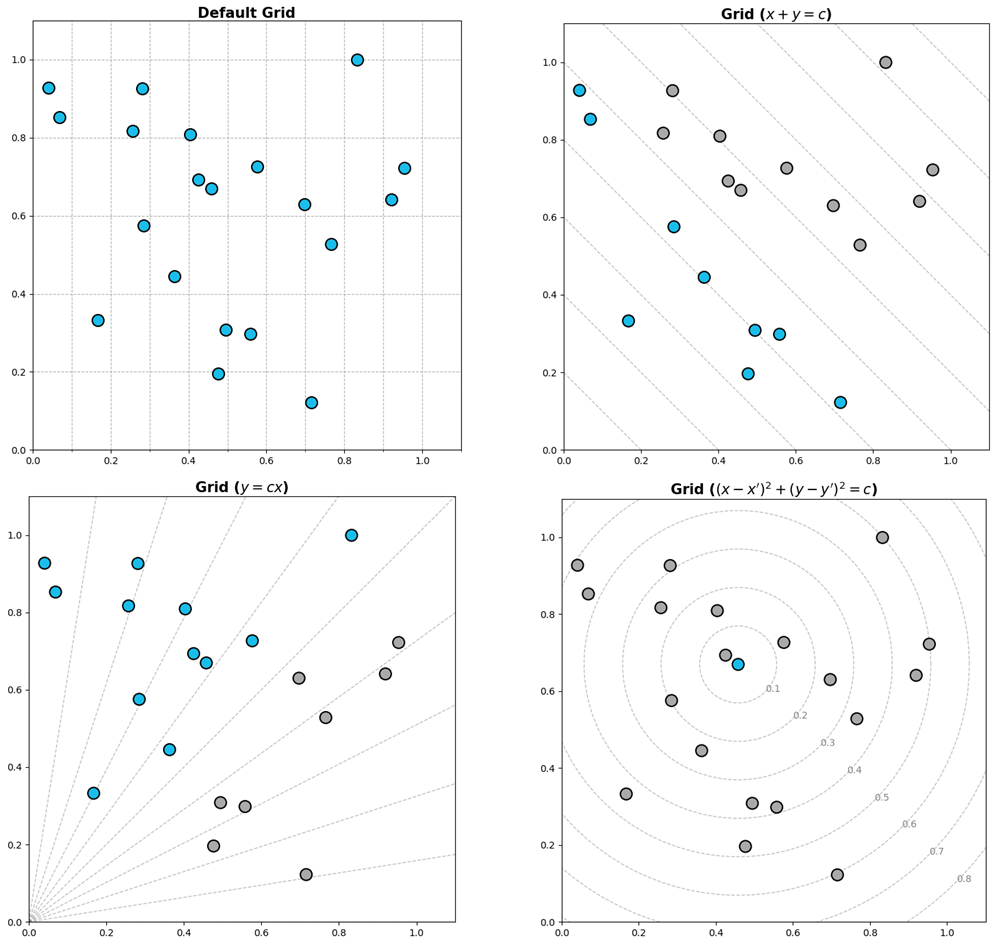
- 추가 Tips
- Grid
which: major ticks, minor ticks -> 큰 격자, 세부 격자axis: x, ylinestyle: grid 선 종류linewidth: grid 두께zorder: 데이터와 겹치지 않게 하기 위해 zorder 설정- 다양한 그리드 스킬
- Line
axvline(),axhline(): 직교좌표계에서 평행선 그리기- Span
axvspan,axhspan: 특정 부분 면적을 표시- Spines,
ax.spines: 축을 조정하는 방법
set_visible: 축 보이기 / 숨기기set_linewidth: 축 굵기set_position: 축 위치 조정- 설정
mpl.rc,plt.rc: 설정하기plt.rcParams['lines.linewidth'] = 2 # 기본두께 2 plt.rcParams['lines.linestyle'] = ':' # 기본 선 스타일 점선 plt.rcParams['figure.dpi'] = 150 # 기본 해상도 바꾸기 plt.rcParams.update(plt.rcParamsDefault) # 기본 세팅으로 다시 만들기
mpl.style.use('seaborn'): 테마 설정
회고
- 이번주 강의는 Deep Learning Basic과 Data Visualization의 두 강의가 병렬적으로 진행되었다. 그렇다보니 강의량이 많았는데 그래도 금요일까지 밀리지 않고 다 수강할 수 있어서 다행이었다.
- 다만 아쉬운 점은 DL Basic 강의에서 많은 내용들을 짧은 강의 시간에 맞추다 보니 내용을 자세하게 보다는 간단히 짚고 넘어갔던 것이 아쉽다. 물론 그래도 내용이 어려웠다... 자세한 설명을 뛰어넘고 가다보니 이해가 안되는 부분들이 있었던 것이 아쉬웠다.
- 심화과제를 하지 못했던 것도 아쉬웠다. 이번주 기본과제는 비교적 간단해 심화과제도 해볼만 할 것 같다고 생각했는데 그렇지 않았다. 강의를 듣고 그걸 보충하는 자료들을 찾아보다 보니 심화과제를 할 시간이 많지 않았다. 심화과제와 오피스아워 해설을 다시 보며 이해해봐야겠다.
