데이터 제작 프로젝트
12주차와 13주차, 2주에 걸쳐 데이터 제작 프로젝트(혹은 대회)가 진행되었다. 이번 대회는 한정된 데이터를 가지고 모델링을 통해 성능이 좋은 모델을 제출하는 것이 아닌, 하나의 고정된 모델을 가지고 직접 데이터를 수집하고 제작해보며 데이터만으로 모델의 성능을 높이는 대회였다.
프로젝트 개요

- 프로젝트 주제
스마트폰으로 카드를 결제하거나, 카메라로 카드를 인식할 경우 자동으로 카드 번호가 입력되는 경우가 있습니다. 또 주차장에 들어가면 차량 번호가 자동으로 인식되는 경우도 흔히 있습니다. 이처럼 OCR (Optimal Character Recognition) 기술은 사람이 직접 쓰거나 이미지 속에 있는 문자를 얻은 다음 이를 컴퓨터가 인식할 수 있도록 하는 기술로, 컴퓨터 비전 분야에서 현재 널리 쓰이는 대표적인 기술 중 하나입니다.
OCR task는 글자 검출 (text detection), 글자 인식 (text recognition), 정렬기 (Serializer) 등의 모듈로 이루어져 있습니다.- 개요 및 기대효과
학교나 수업에서 다루는 AI 모델 연구과정에서는 일반적으로 데이터와 평가 방법이 주어지고, 모델 구조를 변경하면서 해당 데이터와 평가방식에 가장 잘맞는 모델을 찾아나가는 과정을 배우게 됩니다. 하지만 실무에서는 서비스의 기획만 존재할 뿐, 데이터, 베이스라인 모델, 평가방법 모두 제공되지 않는 경우가 일반적입니다. 모델의 성능을 개선하기 위하여 정답 라벨링 노이즈가 없는 양질의 데이터를 확보해야 하고, 또한 모델을 공정하게 평가하기 위해선 테스트 데이터의 정답이 정확해야 하는 등 전체 프로세스에서 데이터 제작 작업이 차지하는 비중이 높고 매우 중요한 작업입니다. 이번 프로젝트를 통해 실무에서 활용되는 AI 프로젝트 과정의 전반적인 이해(데이터 제작, 모델 개발, 성능 평가)와, 피드백 사이클을 통하여 점진적으로 모델 성능을 개선해나가는 전체적인 프로세스를 경험해 볼 수 있습니다.
- 데이터 개요
- 학습 데이터
학습 데이터는 기본적으로 "ICDAR17_Korean"이라는 이름의 데이터셋이 제공됩니다.input/data/ICDAR17_Korean의 경로에 위치하고 있으며 하위에는 UFO 형식의 annotation 파일인ufo/train.json과 이미지 파일들이 포함되어있는images/폴더로 구성되어 있습니다.
ICDAR17_Korean데이터셋은ICDAR17-MLT데이터셋에서 언어가 한글인 샘플들만 모아서 재구성한 것으로 원본 MLT 데이터셋의 부분집합입니다.
본 대회는 데이터를 수집하고 활용하는 방법이 주요 내용이기 때문에, 성능 향상을 위해 공공 데이터셋 혹은 직접 수집한 데이터셋을 추가적으로 이용하는 것을 제한하지 않습니다. 예를 들어ICDAR17-MLT원본 데이터셋은 총 9000개의 샘플(training 7200 + validation 1800)로 구성되어 있으며ICDAR17_Korean은 이 중 536개의 샘플로만 구성된 부분 데이터셋입니다. 원본 데이터셋을 받고convert_mlt.py의 필터링 조건을 변경해 새로운 데이터셋을 만들어 이용할 수도 있습니다. 또한 강의에서 제공되는 annotation tool을 이용해 직접 생성한 데이터를 함께 이용하는 것도 좋은 방법이 될 수 있습니다. (모델 및 기학습 가중치는 이미지넷으로 고정됩니다)
- 평가 데이터
평가 데이터는 크롤링된 다양한 이미지 (손글씨, 간판, 책표지 등) 총 300장으로 구성되어 있습니다.
이미지 내 단어 수의 평균이 17.5개, 최대 약 400개까지 있는 데이터로 다양하게 구성되어 있고, 가로쓰기 글자 외에도 세로쓰기, 진행방향이 불규칙한 글자, 휘어진 글자 등이 있습니다.
언어는 주로 한국어이고, 영어, 그 외 다른 언어도 있습니다.
한국어, 영어가 아닌 다른 언어는 don't care 처리하므로 검출하지 않아도 됩니다.
진행
데이터 추가
이번 대회는 모델링이 아닌 데이터만으로 모델의 성능을 높이는 것이 Task 이므로 많은 데이터를 활용하는 것이 유리하다고 생각하여 기본적으로 주어진 데이터 외의 외부 데이터를 추가하였다.
- ICDAR17_English
- 영어와 한글을 검출해야하므로 영어 글자 데이터가 더 필요하다고 생각하여 ICDAR_MLT 원본 데이터셋에서 영어 데이터를 추출하여 학습 데이터에 추가하였음
- ICDAR15
- 1000장의 영어 글자 데이터 추가
- Upstage 데이터
- 강의에서 주어진 annotation tool을 활용하여 캠퍼들이 직접 제작한 글자 데이터, 한글과 영어가 섞여있음
- ICDAR 데이터와는 달리 다각형의 annotation이 존재
- 원활한 학습을 위해 upstage 데이터 중 사각형이 아닌 다각형 형태로 이루어진 bbox를 포함한 이미지를 제외함
- 제외한 이미지들에 대해 annotation 파일을 편집함
- 야외 실제 촬영 한글 이미지
- Test Data가 주로 한글로 이루어졌으므로 AI-Hub에 있는 야외 실제 촬영 한글 이미지를 추가하여 활용하고자 함
- Data annotation 파일이 이미지당 하나의 txt 파일로 이루어져 통합하여 UFO 형태로 바꾸는 python 파일을 작성함
- 그러나 원데이터가 너무 큰 용량을 가져서 전체 데이터를 활용할 수 없고, 샘플데이터는 bias가 너무 커서 실제로 데이터를 활용하진 못함
학습에 활용한 데이터
- 전체 이미지 개수 : ICDAR17(2970장) + ICDAR15(1000장) + Upstage_data(702장)
- Input : 글자가 포함된 전체 이미지
- Format : bbox 좌표가 포함된 UFO Format
EDA
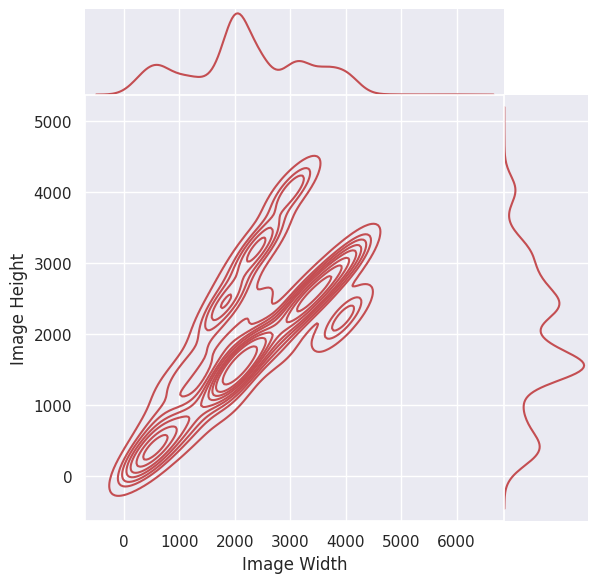
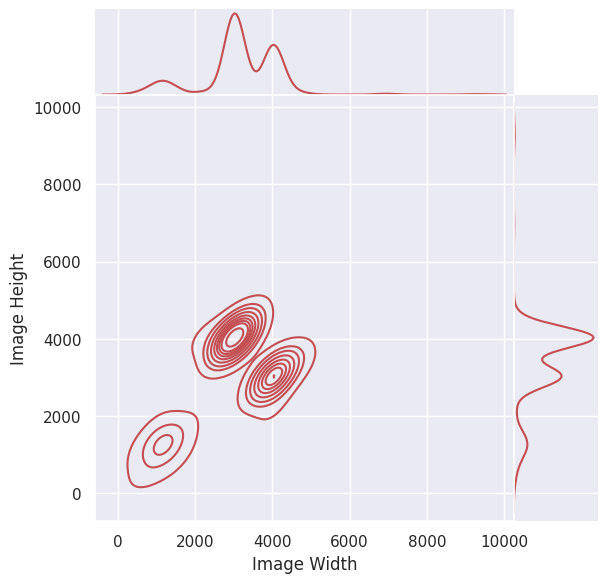
- 이미지 크기 분포
ICDAR15 ICDAR17 Upstage 모든 데이터의 크기가 1280 X 720 ICDAR17의 이미지 크기가 다양하게 분포하고 있음
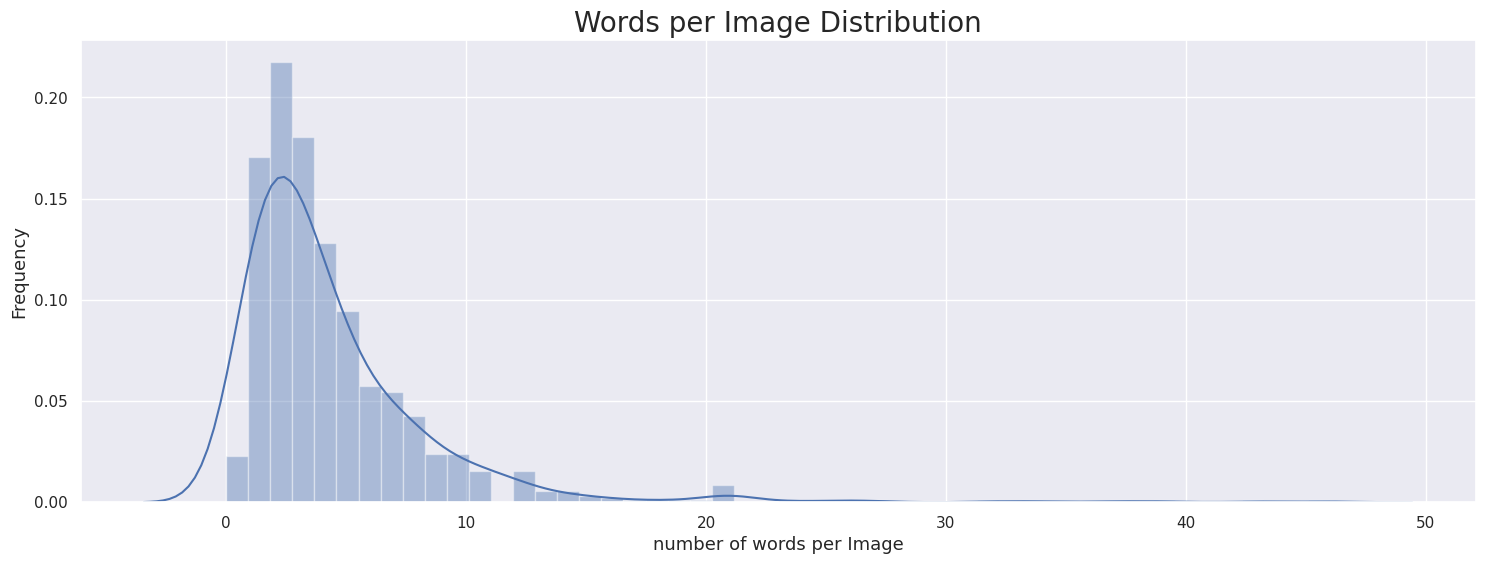
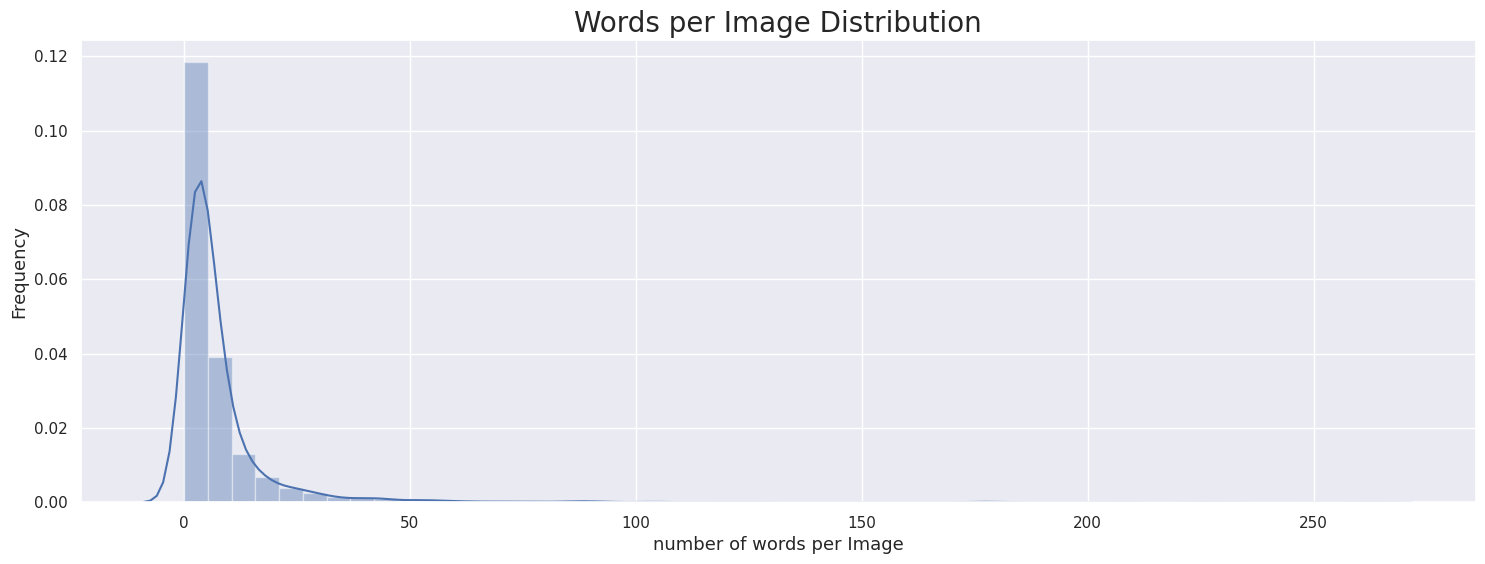
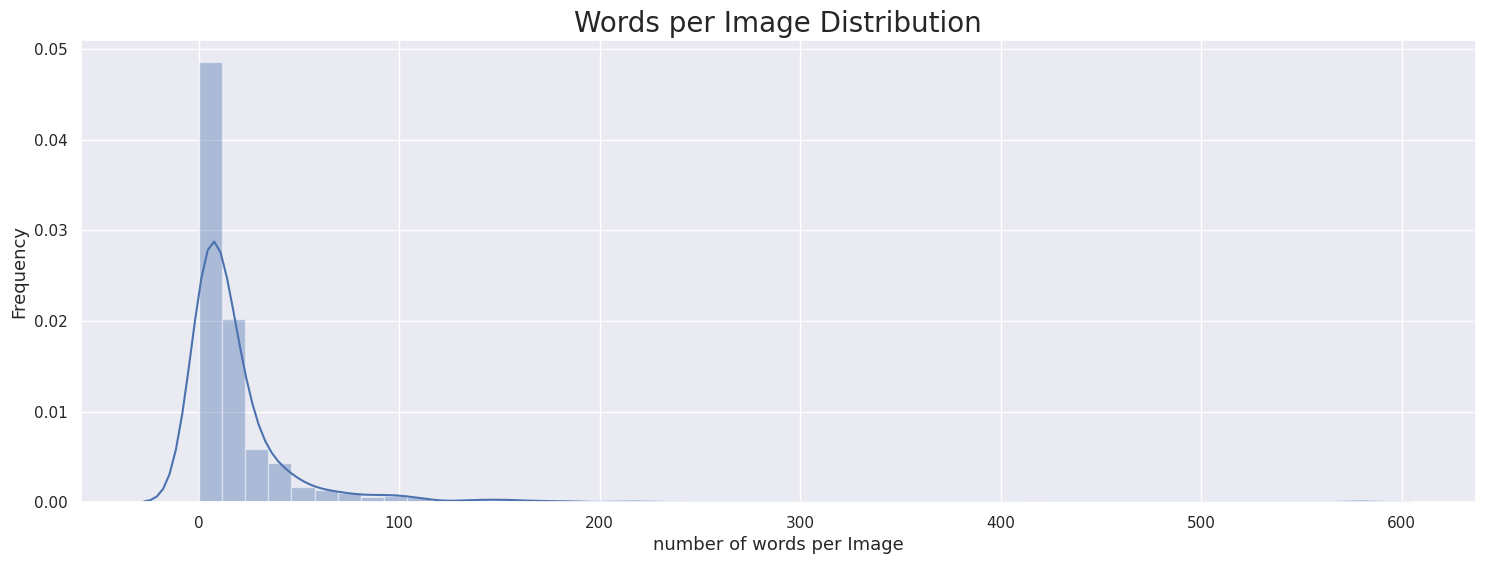
- 이미지당 단어 개수
ICDAR15 ICDAR17 Upstage 이미지당 단어는 0~10개 사이의 분포가 가장 많았음
- 언어 분포
ICDAR15 ICDAR17 Upstage ICDAR15와 ICDAR17 데이터는 영어의 비중이 매우 많았고 Upstage 데이터는 한글과 영어의 비중이 1:1의 비율을 보여주었다.
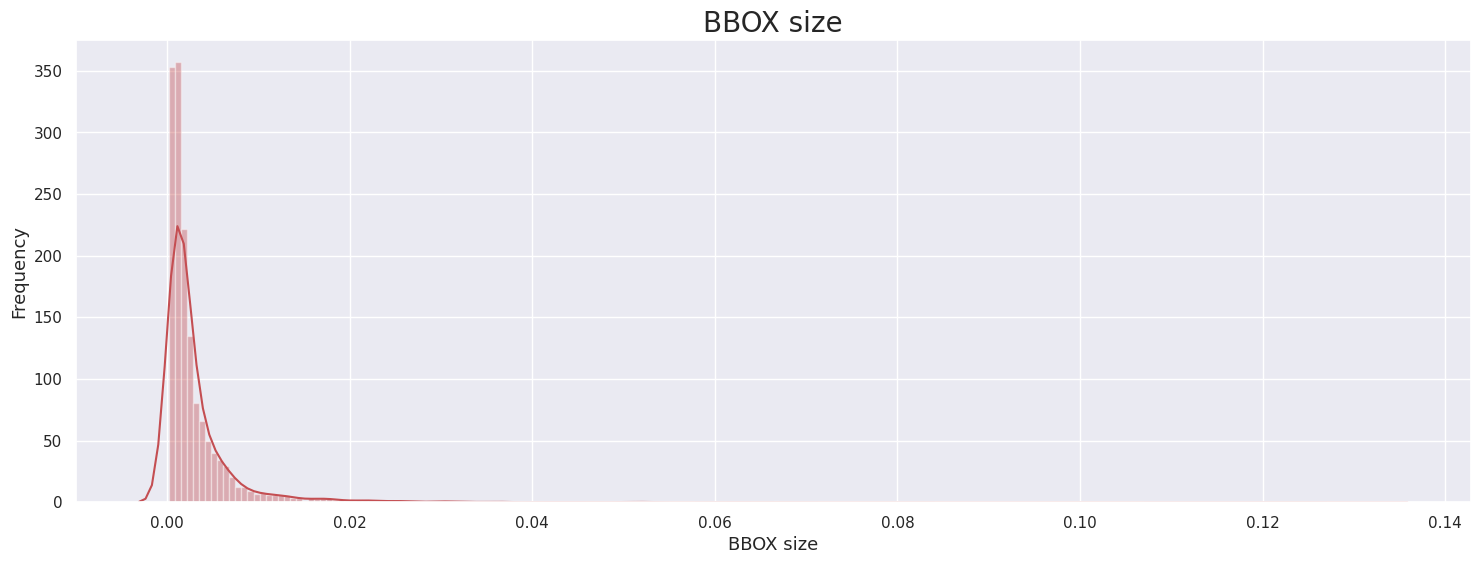
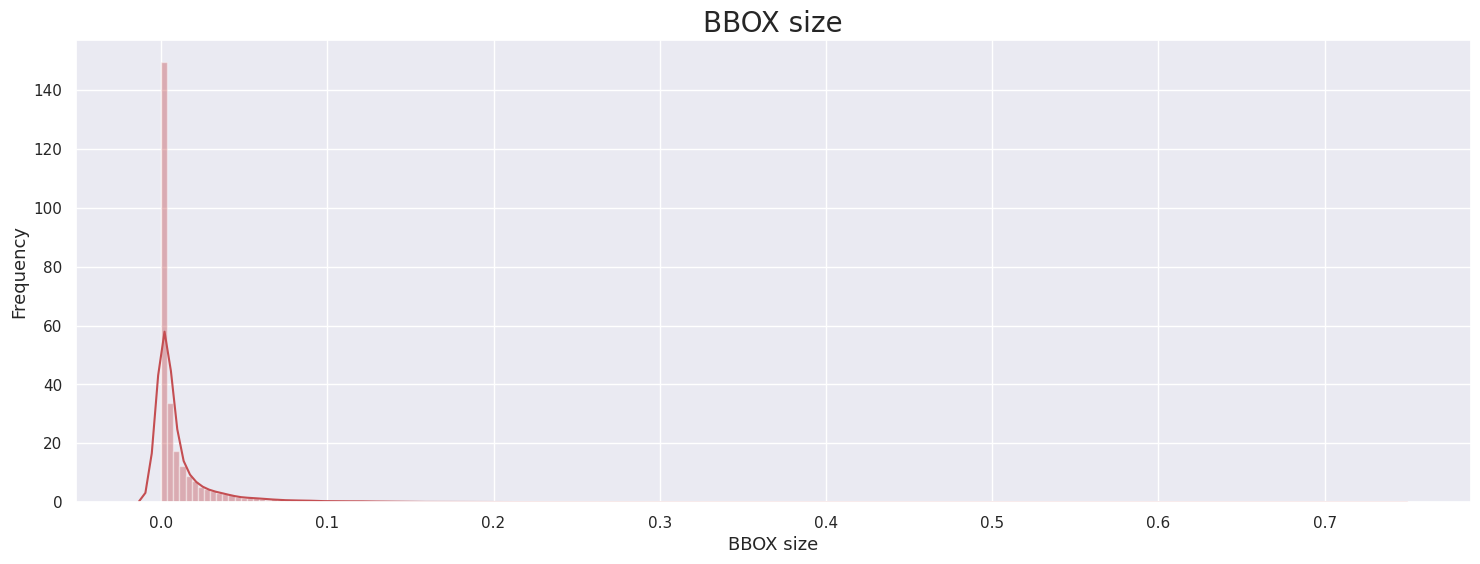
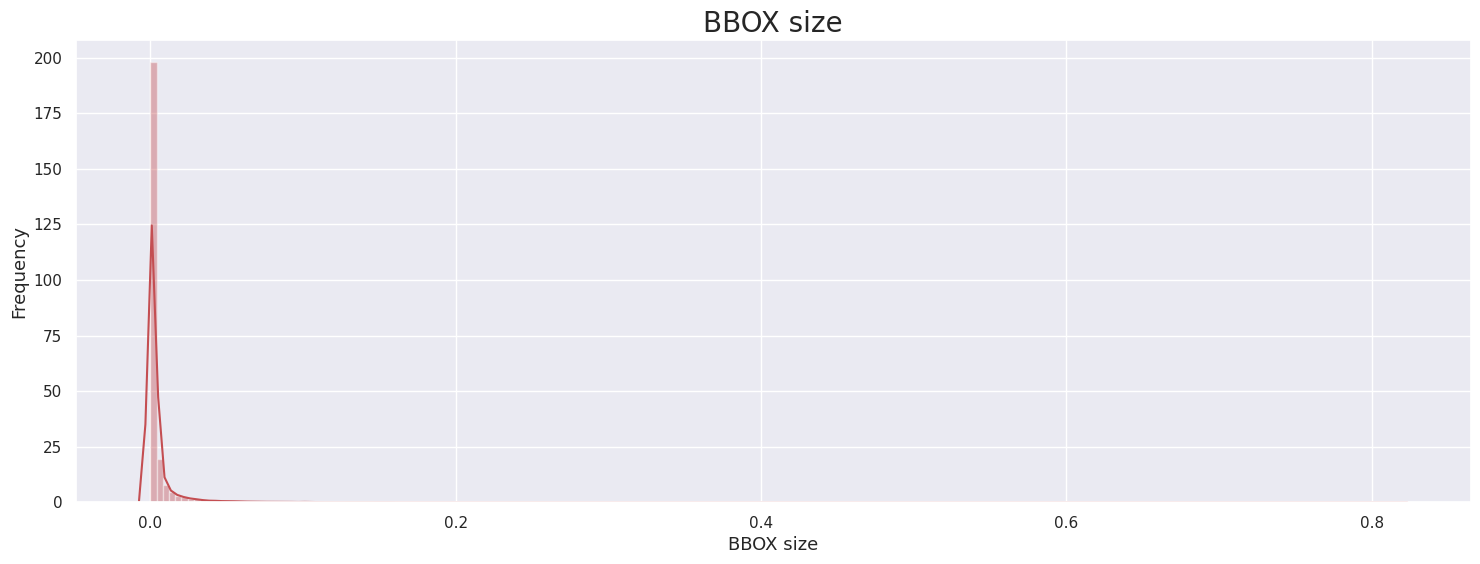
- BBOX size
ICDAR15 ICDAR17 Upstage 대부분의 이미지의 BBox 1프로보다 작은 크기의 BBox가 대부분임을 확인.
Augmentation
Metric: F1-Score
| None | Distort | +MotionBlur | +GaussianNoise | All |
|---|---|---|---|---|
| 0.4621 | 0.4939 | 0.4934 | 0.5398 | 0.5627 |
최종 시연결과
Metric: F1-Score
| F1-Score | Recall | Precision |
|---|---|---|
| 0.6364 | 0.5689 | 0.7220 |
아쉬운점
- 하지만 대회 막판 점수를 끌어올리지 못한 것이 아쉬웠다. 대회 첫 주차에 학습을 위한 셋팅과 데이터 추가를 마친 후 지속적으로 다양한 Augmentation에 대한 실험을 하였는데, 성능 향상으로 이어지지 않았다. Augmentation이 의도한대로 작용하지 않았던 것이 아쉬웠다.
- 더 많고 다양한 데이터를 가지고 학습을 시켜보았으면 좋았겠다는 아쉬움이 남았다. 앞서 말한 것처럼 Augmentation을 통해 성능 향상을 해보고자 하였으나 그러지 못하였고, 차라리 다른 데이터를 더 추가해 보았으면 어땠을까 하는 아쉬움이 남는다.
- GitHub를 저번 프로젝트보다는 활용을 좀 더 많이 했으나 아직 GitHub Project 활용도가 높지 않았다. Project 탭을 통해 To Do, In Progress, Done을 구분하여 협업 해보고자 하였는데 많이 활용하지는 못하였다. 아무래도 매일 회의를 하다보니 Project를 활용하기보다는 대화를 통해 정리를 하는 경우가 많아서 그랬던 것 같다.
- 학습 도중에 갑자기 학습이 멈추는 상황이 종종 발생하여 원하는 결과를 보는데에 어려움이 있었다. 알 수 없는 이유로 학습이 아예 멈춰버리는 현상이 발생하여 학습을 돌리다가 다시 돌리는 경우가 꽤 있었다. 그로 인해 시간을 낭비하게 되었ㅎ고 실험을 더 많이 하지 못해 아쉬움이 남았다.
- 기업 연계 프로젝트 준비를 위해 이번 대회에 전적으로 집중 할 수 없었던 것 또한 아쉬웠다. 대회 기간과 기업 연계 프로젝트 지원 기간이 겹쳤는데, 기업 연계 프로젝트 지원서 작성을 하느라 팀원들과의 회의를 길게 하다보니 이번 대회에 대한 이야기를 나눌 수 있는 시간이 적었다. 대회보다는 지원서 작성에 집중하다보니 대회를 온전히 즐기지 못한 것이 아쉬웠다.
배운점
- 직접 이미지에서 글자 데이터를 annotation 해 볼 수 있어서 좋았다. Upstage 측에서 제공해주신 OCR data annotation tool을 이용해 직접 데이터 제작을 해 볼 수 있었다. 이미지에서 글자를 직접 박스쳐서 어떤 글자인지, 어떤 언어인지, 어떤 tag를 달아야하는지 직접 annotation을 할 수 있었다. 실제로 annotation 툴을 활용하여 데이터를 제작해보고 제작된 데이터를 실제로 활용을 어떻게 하는지 경험해보았다.
- 일관성 있는 데이터와 라벨링의 중요성을 알게 되었다. 여러 캠퍼분들이 해주신 annotation을 취합하여 데이터를 제공해주셨는데, 해당 데이터에는 정말 혼란이 가득했다. 강의에서 마스터님과 조교님께서 알려주신 자세한 annotation convention이 있었음에도 불구하고 annotation 방식이 매우 다양했다. 작업하는 기준이 사람마다 달랐고, 그로인해 noise가 될만한 데이터도 굉장히 많았다. 그런 데이터들을 한 번 걸러주는 과정이 필요했고, 그로 인해 일관성 있는 데이터와 라벨링의 중요성을 알게 되었다.
- 전반적인 OCR Task에 대한 이해도를 높일 수 있었다.
데이터 제작 프로젝트 대회 - 팀 GitHub Repository
https://github.com/boostcampaitech4lv23cv2/level2_dataannotation_cv-level2-cv-09
