Semantic Segmentation 대회
14주차부터 16주차까지 3주에 걸쳐 Semantic Segmentation 대회가 진행되었다. Object Detection 대회와 같이 재활용 품목 분류 task가 주어졌다.
대회 개요

바야흐로 대량 생산, 대량 소비의 시대. 우리는 많은 물건이 대량으로 생산되고, 소비되는 시대를 살고 있습니다. 하지만 이러한 문화는 '쓰레기 대란', '매립지 부족'과 같은 여러 사회 문제를 낳고 있습니다.
분리수거는 이러한 환경 부담을 줄일 수 있는 방법 중 하나입니다. 잘 분리배출 된 쓰레기는 자원으로서 가치를 인정받아 재활용되지만, 잘못 분리배출 되면 그대로 폐기물로 분류되어 매립 또는 소각되기 때문입니다.
따라서 우리는 사진에서 쓰레기를 Detection 하는 모델을 만들어 이러한 문제점을 해결해보고자 합니다. 문제 해결을 위한 데이터셋으로는 일반 쓰레기, 플라스틱, 종이, 유리 등 10 종류의 쓰레기가 찍힌 사진 데이터셋이 제공됩니다.
여러분에 의해 만들어진 우수한 성능의 모델은 쓰레기장에 설치되어 정확한 분리수거를 돕거나, 어린아이들의 분리수거 교육 등에 사용될 수 있을 것입니다. 부디 지구를 위기로부터 구해주세요! 🌎
Input : 쓰레기 객체가 담긴 이미지가 모델의 인풋으로 사용됩니다. segmentation annotation은 COCO format으로 제공됩니다.
Output : 모델은 pixel 좌표에 따라 카테고리 값을 리턴합니다. 이를 submission 양식에 맞게 csv 파일을 만들어 제출합니다.
데이터 개요
우리는 수많은 쓰레기를 배출하면서 지구의 환경파괴, 야생동물의 생계 위협 등 여러 문제를 겪고 있습니다. 이러한 문제는 쓰레기를 줍는 드론, 쓰레기 배출 방지 비디오 감시, 인간의 쓰레기 분류를 돕는 AR 기술과 같은 여러 기술을 통해서 조금이나마 개선이 가능합니다.
제공되는 이 데이터셋은 위의 기술을 뒷받침하는 쓰레기를 판별하는 모델을 학습할 수 있게 해줍니다.
데이터셋 통계
이미지 크기 : (512, 512)
11 class : Background, General trash, Paper, Paper pack, Metal, Glass, Plastic, Styrofoam, Plastic bag, Battery, Clothing
Annotation file
annotation file은 coco format 으로 이루어져 있습니다.
coco format은 크게 2가지 (images, annotations)의 정보를 가지고 있습니다.
- images :
- id : 파일 안에서 image 고유 id, ex) 1
- height : 512
- width : 512
- filename : ex) batch01_vt/002.jpg
- annotations :
- id : 파일 안에 annotation 고유 id, ex) 1
- segmentation: masking 되어 있는 고유의 좌표
- category_id : 객체가 해당하는 class의 id
- image_id : annotation이 표시된 이미지 고유 id
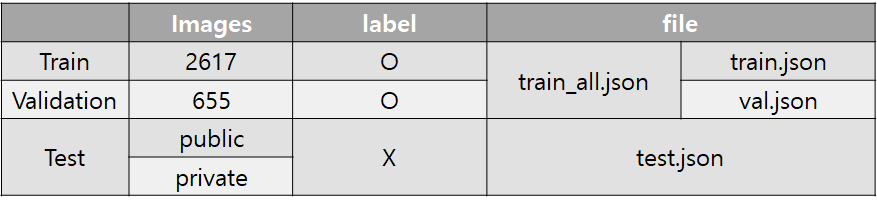
진행
EDA
- Class 당 Annotation 분포
General trash, Paper, Plastic bag의 비율이 매우 높은 반면, Battery의 비율이 굉장히 낮음을 알 수 있음.
- 이미지 당 Annotation 수
이미지가 대체로 10개 이하의 적은 수의 annotation을 가짐. 간혹 하나의 이미지에 지나치게 많은 Annotation이 존재하기도 한다는 것을 알 수 있음.
- 하나의 이미지가 가지는 class 수 분포
최소 1가지 종류의 class만 포함된 이미지가 가장 많고 최대 8가지 class를 포함한 이미지가 있음.
- Annotation의 크기 분포
대체로 Annotation의 크기가 작지만 간혹 매우 큰 크기도 존재한다는 것을 알 수 있음.
- Class별 Annotation의 크기 분포
대체로 class별 비슷한 크기 분포를 가지며 clothing의 경우 다른 class들에 비해 큰 크기의 분포를 가지고 있음.
모델 선정
나는 주어진 baseline 코드를 활용하여 학습하기로 하였다.
기본 Pytorch 내장 Segmenation 모델들을 활용해보고, 그 외의 모델들은 segmentation_models_pytorch(SMP) 라는 라이브러리로 모델을 불러와 사용하였다.
https://github.com/qubvel/segmentation_models.pytorch
여러 Decoder와 Backbone 모델들을 실험해보며 성능이 좋은 모델을 활용해보고자 하였다.
| Decoder | Encoder | Test mIoU |
|---|---|---|
| FCN | ResNet50 | 0.4898 |
| ResNet101 | 0.5140 | |
| DeeplabV3 | ResNet50 | 0.5101 |
| ResNet101 | 0.5349 | |
| UNet | ResNet101 | 0.4937 |
| EfficientNet-b5 | 0.5450 | |
| EfficientNet-b6 | 0.5618 | |
| EfficientNet-b7 | 0.5563 | |
| MiT-b3 | 0.5872 | |
| MiT-b4 | 0.5981 | |
| MiT-b5 | 0.5891 | |
| PAN | MiT-b4 | 0.6253 |
| SwinT-L | 0.6614 |
Scheduler 적용
| Scheduler | Valid mIoU | Test mIoU |
|---|---|---|
| None | 0.7144 | 0.6614 |
| StepLR | 0.7209 | 0.6798 |
| StepLR + AUG | 0.7240 | 0.6980 |
| CosineAnnealingWarmUpRestarts + AUG | 0.7263 | 0.6901 |
참고 : https://gaussian37.github.io/dl-pytorch-lr_scheduler/
Augmentation
| Augmentation | Valid mIoU | Test mIoU |
|---|---|---|
| None | 0.7209 | 0.6798 |
| + Flip + RandomSizedCrop | 0.7281 | 0.6754 |
| + MaskDropOut | 0.7240 | 0.6980 |
- MaskDropOut
 기존 주어진 Mask 중 일부를 삭제하여 없애는 방식
기존 주어진 Mask 중 일부를 삭제하여 없애는 방식
Criterion 선정
- Model 1
| Criterion | Valid mIoU | Test mIoU |
|---|---|---|
| CrossEntropy Loss | 0.7209 | 0.6798 |
| Focal Loss | 0.7313 | 0.6673 |
| Dice Loss | 0.6740 | 0.6335 |
- Model 2
| Criterion | Valid mIoU | Test mIoU |
|---|---|---|
| CrossEntropy Loss | 0.7240 | 0.6980 |
| DiceFocal Loss | 0.7273 | 0.6743 |
| CDB Loss | 0.7163 | 0.6671 |
여러 Criterion을 실험해본 결과, CrossEntropy Loss를 사용한 모델들의 Test 성능이 좋아 CrossEntropy Loss를 사용하였다.
Ensemble
여러 모델들의 예측 결과를 Hard Voting을 통한 앙상블을 하여 성능을 올리고자 하였다.
| Model1 | Model2 | Model3 | Ensemble | |
|---|---|---|---|---|
| 0.7234 | 0.7143 | 0.6961 | 0.7342 |
해보았지만 잘 안 된 것
다양한 Criterion 실험
- Focal Loss
- Dice Loss
- DiceFocal Loss
DiceFocal Loss는 Semantic Segmentation Task에서 많이 쓰이는 Dice Loss와 불균형한 학습 데이터를 사용할 때 많이 쓰이는 Focal Loss를 결합한 형태이다. - Class-Wise Difficulty-Balanced Loss (CDB Loss)
각 클래스의 예측 난이도에 따라서 학습 중에 클래스별 Loss의 가중치를 조절하는 방식
참고 : https://arxiv.org/abs/2010.01824
Model Soup
여러 모델들의 Weight를 평균내어 새로운 모델 제안, 더욱 accurate/robust한 모델을 만들기 위한 방식
Criterion만을 다르게 하여 학습한 세 모델을 활용하여 Model Soup을 통한 Ensemble을 해봤는데 성능 향상으로 이어지지는 않았다.
| Loss | Test mIoU |
|---|---|
| CrossEntropy Loss | 0.6980 |
| DiceFocal Loss | 0.6743 |
| CDB Loss | 0.6671 |
| Model Soup - Uniform Soup | 0.5816 |
TTA (Test Time Augmentation)
모델의 성능을 끌어올리기 위해 TTA를 활용해 보았으나 성능 향상으로 이어지지는 않았다. 오히려 크게 떨어지기도 하였다.
| Before Test mIoU | TTA Augmentations | After Test mIoU |
|---|---|---|
| 0.6980 | HorizontalFlip(2)Rotate90(4)Scale(3) | 0.5270 |
| 0.6989 | HorizontalFlip(2)Rotate90(3)Scale(3) | 0.6967 |
참고 : https://github.com/qubvel/ttach
아쉬운점
- TTA 혹은 Model Soup, Voting Ensemble 등dmf 조합의 실험을 여러번 해보고 싶었는데 제출 횟수 제한과 시간의 부족으로 여러 실험을 해 볼 수 없었던 점이 아쉬웠다. 앞선 세 방식 모두 여러 파라미터로 실험을 하여 최적의 파라미터를 찾고 싶었지만 그렇지 못한 것이 아쉬웠다.
- Copy Paste Augmentation을 써보고 싶었는데 실패하여 아쉬웠다. Copy Paste는 다른 이미지의 Mask를 현재 이미지로 붙여넣는 Augmentation이다. 이로써 더 많은 데이터를 활용하고, 또한 background와의 correlation을 줄이고자 하였지만, 구현의 난이도와 시간의 부족으로 사용하지 못한 점이 아쉬웠다.
배운점
- Semantic Segmentation Task에 대한 전반적인 이해를 가질 수 있었다. 다양한 모델들과 기법들을 활용해보며 모델링을 진행하였고, 성능을 높여가며 Task에 대한 이해와 실습을 할 수 있었다.
- 이전에는 활용해보지 못했던 TTA, Model Soup, Voting Ensemble 등의 다양한 방법론 등을 적용해보고자 하였고, 그를 통해 이런 방법론들에 대해 공부해 볼 수 있었다.
- GitHub를 지난 대회보다 체계적으로 사용해보았다. 지난 대회에서는 GitHub Projects를 사용해보고자 하였지만 제대로 활용하지 못했다. 이번 대회에서는 GitHub Projects를 비교적 적극적으로 활용하였다. To Do를 남겨 놓으면 팀원들이 알아서 본인의 할 일을 찾아서 프로젝트를 진행하여 더욱 효율적인 협업이 가능했었던 것 같다.
- 앞선 대회들보다 더욱 체계적인 실험 관리를 하였다고 생각한다. 앞서서는 실험 결과를 서로 공유하고 대회 페이지 내에서만 기록하였지만, 이번 대회에서는 따로 SpreadSheet를 만들어 실험 기록을 관리하였다. SpreadSheet에 모델, Augmentation 등을 꼼꼼히 기록하여 실험과 실험을 비교하기 훨씬 편해졌다. 체계적인 실험 관리의 중요성에 대해 알게되었다.
재활용 품목 분류를 위한 Semantic Segmenation 대회 - 팀 GitHub Repository
https://github.com/boostcampaitech4lv23cv2/level2_semanticsegmentation_cv-level2-cv-09
